# 秋招总结
# 0x00 废话~
秋招从七月份投的第一家特斯拉开始,到目前 (2022.10.15),已经投了快 170 家了,有安全,网络,运维岗,我只能投这三个岗,因为我也只会这三个。我常因为自己太菜与你们格格不入~。目前 offer 有四家。
我先叠个 buff,下面说的除了技术纯熟虚构,不要对号入座,要是真想展开聊聊可以到主页上找有一篇文章有我的 qq
1. 信锐 (技术支持)
通过三面拿到的 offer,一面基本技术面,二面半技术半问答 (文章接下来的问答指的均是聊天,比如有女朋友吗,对技服了解吗这类非技术相关的问题),三面纯问答聊天。最终想薪资也是目前到现在最高的,年薪可以达到 20,因为他在官网写了 20 起步,我就不打码了
2. 兴唐通信 (系统集成)
这是一家国企,带有一些保密性质,因此入职三年之内不能离职,这可能是我最不能接受的点,因为子曾经曰过:“安全人,安全魂,安全人都是人上人”,我的计划是今年经济形势不好先随便找个给的多的企业苟着,来年再战,混到安全去!因此我拒绝了这家的 offer。第二个原因就是给的是在有点少,虽然 base 在上海,我立即推当场回家,但上海不到 xxW (具体多少也不能透露,反正没有 xxW,大概 xxk),着实有些难受,而且他的风评也有些诡异,告辞,惹不起。补充一句,这家也有三面,好像三面都没怎么问技术
3. 中海达 (技术支持)
这是一家鸽王,第一批面试的时候鸽了我 20 分钟,当时还在实习,是在是等不起,于是到了第二批。第二批又鸽了我二十分钟,上午的面试,中午才给我打电话,说改到下午五点,五点又迟到 8 分钟大无语事件。但那天一面面完第二天还是第三天直接发 offer 了。offer 上面没写薪资没写待遇福利,实在难以下咽,遂告辞。更新 1.0:offer 是九月底发的,但十月中旬突然又来和我探讨薪资的事,您这个跨度有些大啊~,而且给的和兴唐差不多,难顶 (薪资水平 xk-xk 左右)
4. 保融科技 (技术支持)
这家公司只有二面,两次面试都没咋问技术,但聊得很开心,是秋招目前为止聊得最开心的公司,一面的小姐姐也很好看好评,但无奈薪资问题和预期差距过大,毕竟第一个信锐 offer 拿到后,后面面的给的都没信锐多,厂商规模也没信锐大,这家 base 在杭州,但我的 offer 是实施,就是全国出差的那种,那其实和信锐没啥区别了,两家做的东西都相同的情况下,肯定是找大厂和工资高的,保融啊我对不起你啊 (2,3,4 这三家其实薪资都差不多)(记一下吧反正不发出去,这个基本薪资 x500,也有烂七八糟的补贴)
10.20 补充今天又拿了两家 offer,再来废话两句
5. 宏杉科技 (技术支持)
这是个存储的公司,在全国大部分城市都有办事处,工作地点也和信锐一样,结合自己的意愿和公司实际情况分配。这家是目前为止除了信锐给的第一多的,一个月基本工资能有 xxk,还有乱七八糟的房补,和其他补贴。但他不讲武德的地方在于,如果你把它违约了你需要支付违约金,但如果你因为他把别人违约了他是一分不给。(学学信锐,哪有这么白嫖的),而且常住地,户籍所在地是没有房补的。没有必要,拒了。面试一共两次,第一次问了点技术,第二次也问了点,但比第一次少很多,第二次多了很多职场题目。
6. 东方日升 (运维工程师)
这家应该是做经济的,我投的好像是啥技术类管培生,他的 offer 上是这么写的,我也不记得我投了啥了。这家一共只有一面,是 hr 和一个问技术的一起面的,但技术没问啥,全问的项目实习,这种回答了几千遍的题目是在没意思,我全程输出,他根本插不上嘴,我一堆 span-leaf,border-leaf 把它杀穿。然后第二天就给 offer 了,问题在于实习 x000,转正 x800。难顶啊~拒了拒了
10.21 补充,又拿了一家 offer 再来 bb 两句 ,说实话,每次拿到 offer 都把我搞的精疲力尽
7. 中科闻歌 (运维工程师)
这家是面到现在最心动的一家公司,面试只有一面,但三个面试官,第一个问网络,第二个问项目,第三个 hr 随便问点,但他们给人一种很重视应届毕业生的感觉,也可能是错觉,而且这家公司规模其实能比信锐更大一些,我投的是做运维的,据他们说他们公司会让网络和搞云计算的一起工作,达成一些目的。但无奈薪资实在尴尬,北京 xw,没有房补,我真的要露宿街头了,当场贷款上班,告辞,最不巧的是给信锐寄方法和给中科翁工决定是同一天的同一个下午,但凡他有个房补,我当场违约。
10.25 补充,这是昨天还是前天的 offer 了
8. 石化盈科 (网络安全工程师)
非常奇葩的面试,只有一面,但一面包车的面试官,一个腾讯会议进去十几个人,每个人都应该是部门的经理一类的,然后 hr 是先和你进行讨论的人,讲到哪个技术部门负责人感兴趣会对你进行追问,比如当时有个部门应该是搞渗透测试的,还有个应该是搞二进制的。这个 offer 也很奇葩,hr 告诉部门经理 offer 已经给我了,让他来找我沟通,结果我没有收到 offer,听这个人一顿讲,最后不知道薪资多少。最后还是他帮我问的,一个月 xk+,还是包含房补的,工作地点在北六环附近,那边租房也得 2k-3k,抢钱啊~,但听那人最后的意思是找我去做数据中心运维…
10.29 补充
9. 上海汉得信息 (云解决方案工程师)
这个虽然名字很高级,什么云方案,但其实就是运维 + 技术支持,在上海总部,这是他比信锐唯一好的一点,薪资的话 ([xk-xk]+ 房补),有培训期,2-3weeks,有实习期,你拿到毕业证之前都算实习期,还有试用期,6 months,最后才是转正,每一级都会比上一级至少少 80%,就是转正之后每天还要为 2k 奋斗,因为如果只拿 xk 容易饭都吃不起,40|80 是项目补贴,每天都有,试用 x,转正 x,x 好像是餐补,房补不会真给你,但他会在公司附近帮你租房,或者住员工宿舍,其实算下来在北京租完房剩的和这差不多了,但我还想等等大厂,毕竟这家。。不是特别有想法。
11.2 更新
10. 中科曙光(云平台网络研发工程师)
这家特别离谱,让我做了三遍测评,说是前两遍没过,hr 甚至还找不部门的人为了给我第三次机会,然鹅,我做完了第三次,他们就不鸟我了,我记得 10.31 看到了中科曙光毁约在牛客上,我 emmmm,结果他们今天又来找我了,还来沟通 offer,xw 年薪,每个月还有 x00 餐补,一天 10 块钱,我喝西北风去吧还有七险两金,说自己是国企性质,呵呵呵,谁都说自己国企性质,国企性质和国企是两码事,别被骗了,我拖了两天,给他和我都留个台阶下,不如意外肯定拒了,他 base 在成都,其实成都这个价还行,但我纠结汉得和信锐,可恶啊,Amazon 不理我,云智也不理我,难顶~
11.18 更新 之前装逼遭报应了,整整半个月没一个 offer
11. 迪普科技(技术支持工程师)
这是一家搞安全的公司,看深信服 hr 朋友圈发的安全厂商里面市值排名第八,还行吧,但他产品线真的广,从网络到无线到安全,他都有。昨天接到的 offer,昨天也把汉得拒了,今天准备违约信锐签迪普,信锐产品线太少了,只有路由器和交换机,而且迪普我以后能搞到安全的概率会更大,但 tm 违约信锐要交 xk,我去 tm 的,之前有个朋友让我去 boss 直聘上面看看,投了十几家,面了几家,得出的结论是 boss 直聘狗都不去,面试官素质极低,面试质量极差,真的无语了,这家待遇 [xx000+(x000-x000)]*(x)
11.21 补充
12. 缔安科技(网络工程师)
这家给的实在太少了,x-1xk,呜呜呜,面试倒还行,一面面了三面的活,一个人问技术,一个人问项目,一个人问情商题,还有一个主持人,技术问的很有趣,秋招到现在第一次有人问 mpls vpn,稀客呀~,项目就那样吧,回答的麻了,重复了上百遍的回答,最后那个情商题我回答的和狗屎一样,同时他也问了对公司的了解,这就要骂人了,你这么小公司,逼乎都搜不到,我去哪了解你,还说我没充分了解,我 g。
13. 吉祥航空 (通信网络工程师)
一共一面,两个面试官,一个主持一个问技术,技术问的都是些项目,比如控制出口选路,昨天面得今天发的 offer,但给的太少了,全包 x.8w,告辞,少的离谱
12.2 补充
14. 长亭科技 (技术支持)
长亭好啊,一面 10/6,二面 11.9,三面 11.21,四面 11.25,offer12.2,这个面试过程实在是太长了,中途差点就和迪普签了,但还好有 yq 的因素拖了 dp 很久,等来了长亭,但长亭在上海,给的 x000+x00(餐补)*x-x 我的 offer 的年薪越来越少,人家越拿越多,离大谱,但长亭逼乎上的的评价基本都是正向的,而某些迪普全是差评和喷 hr 的。。。本来打算过完年就去实习,结果西安 zf 发病,非要立马把人全放了,考试下学期考。。。我 tm 下学期要去实习了还要考试?你在想什么啊??
15. 石化盈科 (网络安全)
在北京 x00+x000,这他妈还包含住房补贴,我去北京贷款上班吧,还 x000 违约金,offer 拿多了就会发现越是垃圾的公司违约金越高,长亭就 xk,这某些盈科怎么敢要 xk 的啊,真大无语,告辞,惹不起
12.6 补充
16. 嘉兴银行(科技管培生)
笔试和测评环节超多,已经加起来有五场,后面还有一个 ai 面和两个面试,那两个面试都是群殴类型,你一个打对面五六个,offer 发的很晚,面试流程很长,你忍一下,他 offer 只有一个短信,没有薪资没有其他任何信息,只有让你在五个小时以内回复同意 offer,过期作废,金融企业面子是真大,没回复他们,拒了拒了。看了一下 xxxxxshow 说是 **W (研究生)
12.20 补充
17. 腾讯云智 (网络技术类)
面过程非常非常长,10.28 一面,最后 offer12.20 发的,虽然是从池子里捞出来的。当时面完三面就没结果了,结果 12 月初又给我发面试。在西安,投的时候都叫技术支持,实际在入职时的岗位会变,比如我就变成了网络类,我朋友变成了运维。他第一年给的真的很多,第一年 2* = xx000 + xx000 + xx000 + xx*13 ,但第二年 xx00 白送的没了,xx000 房补也没了,第二年就很拉了,但这是在西安,这个年薪还是非常可观的要是没有更好的或者你们不搞安全可以去。反正因人而异吧,反正我去长亭了告辞,顺便说下,那个 x2000 的年终奖是评级最高档的,dddd
再废话两句,1. 有能投的就投,千万别看大小,举个栗子,谁都没想到今年最高的是个没听过名字的机器人公司,你认为的小厂不一定是小厂,一般有机构看机构的就业群,没有找公众号,公众号的企业虽然多,但不是所有企业都要我这种 IT 的,秋招群里的信息实际上是老师们过滤之后的,有针对性了很多
2. 笔试和测评可能很多很多,但还是要好好做的,万一呢~
3. 考研,考研,考研,重要的事情说八百遍,今天面试的哥们问我你有 ie 为啥不去华为,我:…,华为是不会要双非的本科的,考研最好也往 211 考。
4. 最好对自己投的企业做个详细记录,同时对面试过程也做个详细记录,方便后续复盘,我今天的复盘的全部内容来自于我每次面完写的 CSDN,最好每次面完就复盘,这样对你下一家类似岗位的很有帮助,人不能在一个地方疯狂翻车
5. 不要死磕运维 / 安全岗,有给的多的,差不多能干的就先跑,不雅等春招,某个企业的 HR 在和我聊得时候透露等春招他们就剩个位数岗位或者直接不招了,而且春招还要再加几百万研究生们,难度直接上天
总结到这,废话说完了,开始正题,预计文章会有两大部分。 1.网络岗,技术支持岗,运维岗面试总结 2.安全岗面试总结
项目实习啥的就不说了问的基本上都一样,还有一些你遇到的困难,印象深刻的事啦,随缘临场发挥吧
安全岗包括但不限于安服,网络安全管培生等职位,和安全相关的都在下面列举
# 0x01 网络,技术支持,运维岗总结
# 1.DHCP 工作原理,报文种类
出现厂家:特斯拉一面(ip helper address),信锐(获取地址方法,问的其实还是这个),中科曙光,宏杉
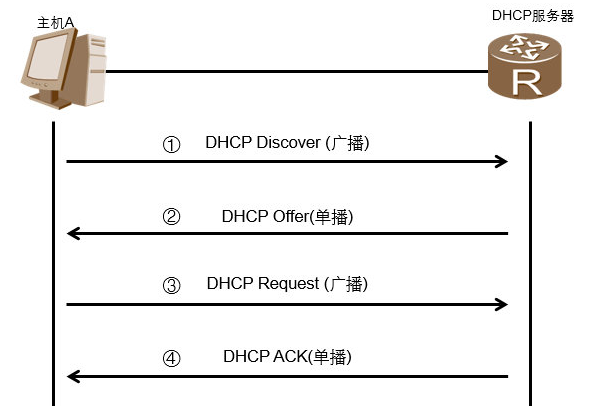
1 | 1.四次交互获取IP |
# dhcp 中继 (云智)
1 | DHCP中继,其实就是在与DHCP Server不同而又需要申请DHCP服务的网络内,设置一个中继器,中继器在该网络中代替DHCP Server服务器接收DHCP Client的请求,并将DHCP Client发给DHCP Server的DCHP报文,以单播的形式发送给DHCP Server。DHCP Server在收到由DHCP发送来的DHCP 报文后,同样会把响应的DHCP报文发送给DHCP 中继。这样,DHCP其实是充当了一个中间人的作用,起到了在不同的网络中运行DHCP的目的。 |
# 3.TCP/UDP 相关
# tcp 滑动窗口初始值,慢启动,流控 (快手)
1 | 滑动窗口 |
# TCP syn flood 防御 (快手)
1 | 利用TCP三次握手协议,大量与服务器建立半连接,服务器默认需要重试5次,耗时63s才会断开接,这样,攻击者就可以把服务器的syn连接队列耗尽,让正常的连接请求不能处理。 |
# tcp 和 UDP 区别 (茄子,汉得)
1 | 1. |
# tcp 四次挥手 timewait 作用 (长亭)
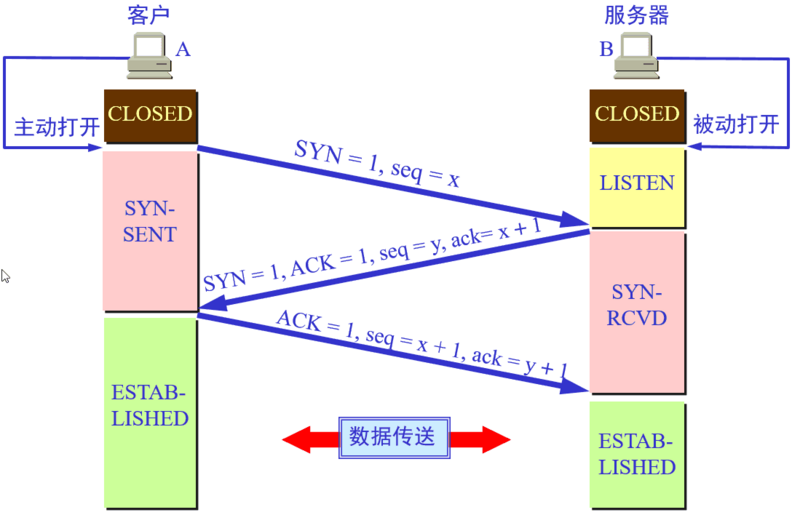
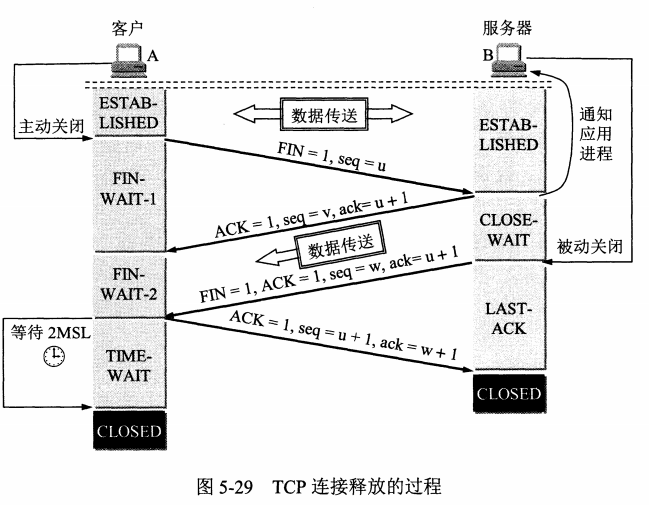
1 | timewait的作用: |
# 为啥挥四次握三次 (长亭)
1 | 为了保证A发送的最有一个ACK报文段能够到达B。 |
# 接下来是八股文时间:~
1 | 0x00 TCP第一次握手SYN包丢包 |
# 连续收到三个 ack 怎么办(云智)
1 | 即,当TCP源端收到3个相同的ACK确认时,即认为有数据包丢失,则源端重传丢失的数据包,而不必等待RTO(Retransmission Timeout)超时。 |
# 4.OSI 相关
# 路由协议分类 (宏杉,中科曙光,信锐)
1 | 从大类分,分为BGP和IGP 即内部网关和边界网关协议 |
# osi/tcpip 区别
1 | OSI: TCP/IP |
# 二层三层交换机的区别 (深信服)
1 | 二层交换机属数据链路层设备 |
# OSI 每层协议 (长亭,招联,中科曙光)
1 | 应用层: |
1 | 顺带着我就把常见端口写了 |
# 封装解封装 (长亭)
1 | 应用层,人机交互接口,接收用户输入 |
# 5.OSPF 相关
# ospf 负载分担 (快手)
1 | 华为产品文档ospf cost命令原话 |
# 需要 A->B 不负载分担,回程不管,在哪配开销,来回路径不一致有问题吗(快手)
1 | 在A配,因为A发送时需要查看路由表,只有路由表中没有开销相同的路由才不会负载分担 |
# 单区域网络类型 P2P 有几种 LSA (快手)
1 | 只有1类 |
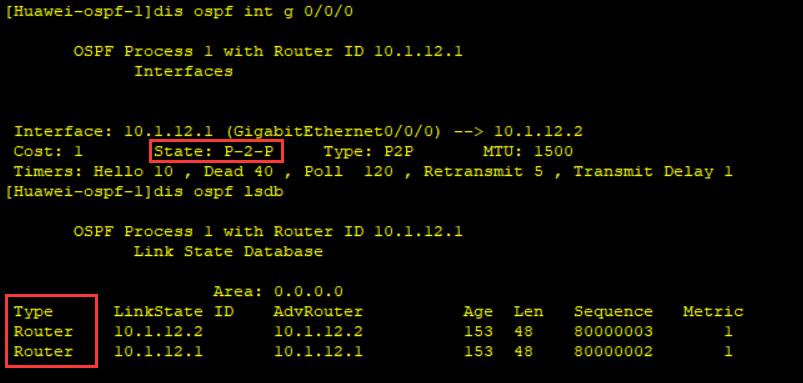
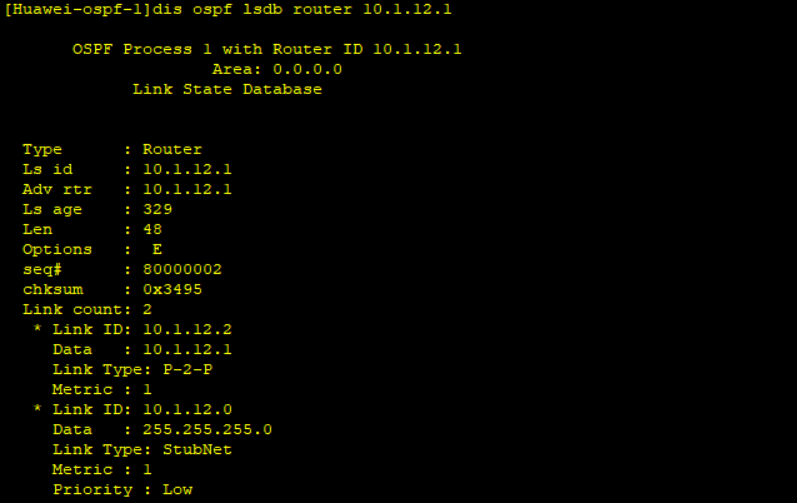
# 5.4LSA 常见类型 (快手)
1 | 1类LSA 每台运行ospf协议的路由器都会产生,用于描述加入到OSPF进程中自身直连链路的状态。有路由和拓扑信息 |
# 5.5OSPF 防环 (快手)
1 | 区域内通过spf防环 |
# 5.6SPF 算法 (快手)
1 | https://blog.csdn.net/qq_57686163/article/details/123466172 |
# 5.7DR,BDR (宏杉)
1 | 基于链路选择。即在每一条广播型链路或NBMA链路都需要进行DR,BDR选举,BDR可选存在。即在每一条广播型链路或NBMA链路上DR只有一个,BDR如果存在有且只有一个 |
# 5.8ospf 建立邻居
Down: 这是邻居的初始状态,表示没有从邻居收到任何信息。
Init: 判断邻居参数可以建立邻居后 init。在此状态下,路由器已经从邻居收到了 Hello 报文,但是自己的 router-id 不在所收到的 Hello 报文的邻居列表中,表示尚未与邻居建立双向通信关系,可以称为 one-way。在此状态下的邻居要被包含在自己所发送的 Hello 报文的邻居列表中。
2-Way: 在此状态下,收到邻居 hello 包,并从 hello 包中发现自己 router-id。两台路由器已确认可以双向通信,邻居关系已经建立;但是还没有建立邻接关系。若发送方收到的 hello 包中有自己 id,可以直接进入 two-way。这是建立邻接关系以前的最高级状态。如果网络为广播网络或者 NBMA 网络则选举 DR/BDR。drother 之间停留此状态,不会进行 LSDB 同步,其他情况会继续进行 LSDB 同步
exstart 状态,开始发送 DBD 报文。主要完成主从选举,为可靠的 LSDB 同步做准备工作,不会携带任何 LSDB 中 LSA 头部信息
exchange 主从选举完成后,一旦发送携带 LSA 头部的 DD 报文,则进入 exchange,slave 路由器开始发送携带自身 LSDB 中 LSA 的头部信息的 DBD 报文,并使用
loading 状态发送 LSR,LSU,LSACK ,LSACK 中会将 LSU 的 Seq 作为自己的 seq,同时携带摘要作为显示确认
FUll:LSR 重传列表为空,发送和接受 LSACK 报文后,防止同步出现问题。
attempt— 过度状态,在某些不能发送的 hello 包的网络中,不能主动建立邻居。通过单播邻居方式建立,需要选 DR 时,等待选举状态为 attempt 状态
停留 attempt 状态说明单播指邻居邻居指错
# 5.9ospf 卡在 exstart 状态的原因(迪普)
1 | 卡在down状态:OSPF没有运行; |
# 5.10ospf 影响邻居建立因素(迪普)
1 | router-id冲突 |
# 5.11p2mp 和 p2p 能建邻居吗(迪普)
可以建立邻居,P2MP 以组播形式发送 hello 报文,P2P 以组播形式发送所有报文
但 P2P hello 时间 10s,P2MPhello 时间 40s,需要手动修改 hello 时间一致
# 6.BGP 相关
# 6.1origin 属性,network 和 import 都是什么属性,优先级,origin 控制选路 (快手)
1 | 定义路径信息的来源。描述该路由是用什么方式成为BGP路由的,公认必尊 |
# bgp 选路(中科闻歌,绿盟)
1. 优选协议首选值 (PrefVal) 最高的路由
2. 优选本地优先级 (Local_Pref) 最高的路由
3. 优选本地生成的路由,解决路由冲突,agg > auto > network > import > peer
4. 优选 AS 路径 (AS_Path)最短的路由
5. 比较 Origin 属性,依次优选 Origin 类型为 IGP、EGP、Incomplete 的路由
6. 优选 MED 值最低的路由
7. 优选从 EBGP 邻居学来的路由 (EBGP 路由优先级高于 IBGP 路由)
8. 优选到下一跳 IGP Metric 较小的路由
----------------------------
9. 优选 Cluster_List 最短的路由,没有簇列表簇列表为空,没有簇列表一定更优
10. 优选起源 ID,越小越优
11. 优选 Router lD 最小的路由器发布的路由
12. 比较对等体的 IP Address,优选从具有较小 IP Address 的对等体学来的路由
简单来说
P L L A O M E N 漂亮老男人
Pref LocalPre Local AS origin MED EBGP next_cost
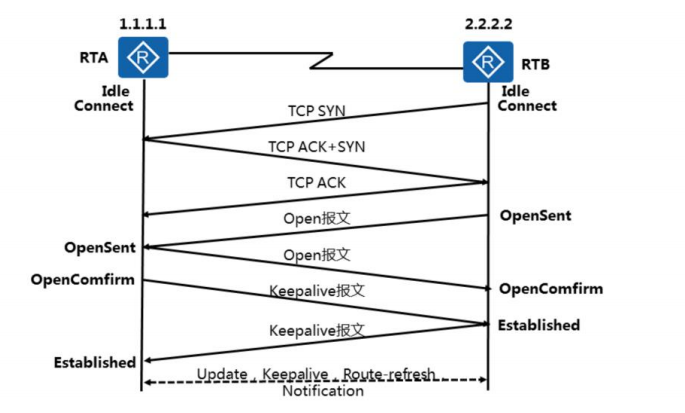
BGP 邻居建立 (迪普)
ldle (空闲) : ldle 是 BGP 连接的第一个状态,在空闲状态,BGP 在等待一个启动事件,启动事件出现以后,BGP 初始化资源,复位连接重试计时器 (Connect-Retry),发起一条 TCP 连接,同时转入 Connect (连接)状态。
Connect (连接)︰在 Connect 状态,BGP 发起第一个 TCP 连接,如果连接重试计时器 (Connect-Retry) 超时,就重新发起 TCP 连接,并继续保持在 Connect 状态,如果 TCP 连接成功,就转入 OpenSent 状态,如果 TCP 连接失败,就转入 Active 状态。
Active (活跃)︰在 Active 状态,BGP 总是在试图建立 TCP 连接,如果连接重试计时器 (Connect-Retry) 超时,就退回到 Connect 状态,如果 TCP 连接成功,就转入 OpenSent 状态,如果 TCP 连接失败,就继续保持在 Active 状态,并继续发起 TCP 连接,没有收到对 open-send 报文的确认报文。
TCP 三次握手建立。自己发送 open,等待接收正确的 open。接收正确 open 的进入 openconfirm,发 keepalive,收到对方 keepalive 进入 established。对方也是这个过程
BGP 路由刷新 (迪普)
Route-Refresh
用于手动实现 BGP 触发更新。不中断 TCP 会话触发更新,可以针对邻居触发更新
refresh bgp all (peer) export 向对方发送 update message,更新对方路由信息
refresh import 向对方发送 route-refresh,对方收到后回复 update message 完成路由刷新
route-refresh 报文中携带 AFI 和 SAFI

BGP 路由撤销 (迪普)
1.IPV4 路由撤销
通过 update 报文 NLRI 字段中的 withdraw route 实现,其中不携带任何属性
2.VPNV4 路由撤销
不携带路由属性,在 update 报文 path attribute 中 MP_UNREACH_NLRI 携带撤销路由
不携带路由属性,只携带 RD 和标签栈
# 7. 双点双向重发布 (快手)
1 | 在多点双向重发布中,若A协议的优先级大于(次)B协议,此时若将A协议通过一台ASBR引入到B协议时,那此优先级会降低(变优),会导致另一台ASBR路由表的生成,此时另一台ASBR再次将B往A协议重发布时,原先A协议的路由会再次回到A协议中--路由回馈 |
# 8.http/https 相关问题
# http 状态码 (汉得,曙光)
1 | 常见状态码 |
# 访问网页过程 (信锐,汉得)
1 | 1.首先在浏览器地址栏中输入URL或者域名。 |
# https (长亭)
1 | HTTPS是一种透过计算机网络进行安全通信的传输协议。HTTPS 经由 HTTP 进行通信,但利用 SSL/TLS 来加密数据包。 |
1、客户端发起 HTTPS 请求
就是用户在浏览器里输入一个 https 网址,然后连接到 server 的 443 端口。
2、服务端的配置
采用 HTTPS 协议的服务器必须要有一套数字证书,可以自己制作,也可以向组织申请,区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面 (startssl 就是个不错的选择,有 1 年的免费服务)。
这套证书其实就是一对公钥和私钥,如果对公钥和私钥不太理解,可以想象成一把钥匙和一个锁头,只是全世界只有你一个人有这把钥匙,你可以把锁头给别人,别人可以用这个锁把重要的东西锁起来,然后发给你,因为只有你一个人有这把钥匙,所以只有你才能看到被这把锁锁起来的东西。
3、传送证书
这个证书其实就是公钥,只是包含了很多信息,如证书的颁发机构,过期时间等等。
4、客户端解析证书
这部分工作是有客户端的 TLS 来完成的,首先会验证公钥是否有效,比如颁发机构,过期时间等等,如果发现异常,则会弹出一个警告框,提示证书存在问题。
如果证书没有问题,那么就生成一个随机值,然后用证书对该随机值进行加密,就好像上面说的,把随机值用锁头锁起来,这样除非有钥匙,不然看不到被锁住的内容。
5、传送加密信息
这部分传送的是用证书加密后的随机值,目的就是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加密解密了。
6、服务端解密信息
服务端用私钥解密后,得到了客户端传过来的随机值 (私钥),然后把内容通过该值进行对称加密,所谓对称加密就是,将信息和私钥通过某种算法混合在一起,这样除非知道私钥,不然无法获取内容,而正好客户端和服务端都知道这个私钥,所以只要加密算法够彪悍,私钥够复杂,数据就够安全。
7、传输加密后的信息
这部分信息是服务段用私钥加密后的信息,可以在客户端被还原。
8、客户端解密信息
客户端用之前生成的私钥解密服务段传过来的信息,于是获取了解密后的内容,整个过程第三方即使监听到了数据,也束手无策。
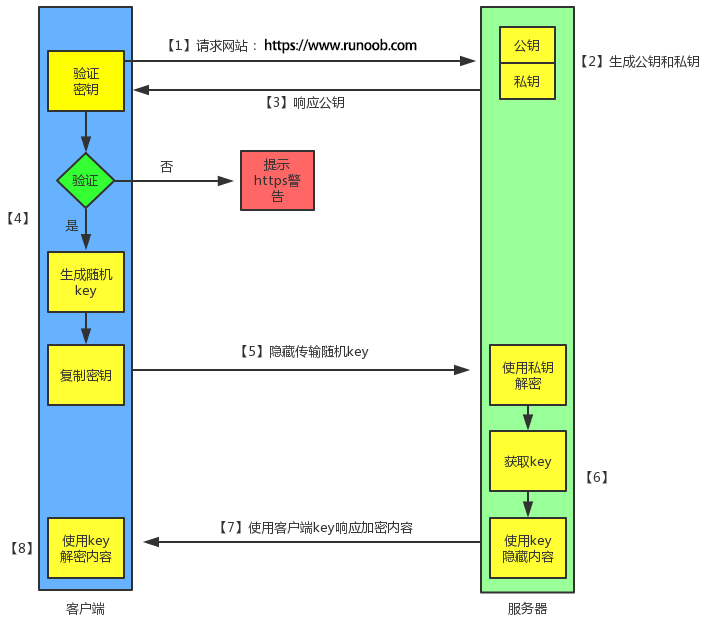
HTTP 与 HTTPS 的区别 | 菜鸟教程 (runoob.com)
# http/https 区别 (没人问,我自己问着玩)
1 | HTTP 明文传输,数据都是未加密的,安全性较差,HTTPS(SSL+HTTP) 数据传输过程是加密的,安全性较好。 |
# http1.0,1,1 和 2.0 区别 (长亭)
1 | 1.1.0和1.1之间的区别 |
# http 报文组成 (长亭) 头行
HTTP 请求报文是由三部分组成: 请求行,请求报头和请求正文。
后端从在固定的端口接收到 TCP 报文开始,这一部分对应于编程语言中的 socket。它会对 TCP 连接进行处理,对 HTTP 协议进行解析,并按照报文格式进一步封装成 HTTP Request 对象,供上层使用。
HTTP 响应报文也是由三部分组成: 状态码,响应报头和响应报文。

①是请求方法,GET 和 POST 是最常见的 HTTP 方法,除此以外还包括 DELETE、HEAD、OPTIONS、PUT、TRACE。不过,当前的大多数浏览器只支持 GET 和 POST
②为请求对应的 URL 地址,它和报文头的 Host 属性组成完整的请求 URL。
③是协议名称及版本号。
④是 HTTP 的报文头,报文头包含若干个属性,格式为 “属性名:属性值”,服务端据此获取客户端的信息。
⑤是报文体,它将一个页面表单中的组件值通过 param1=value1&m2=value2 的键值对形式编码成一个格式化串,它承载多个请求参数的数据。不但报文体可以传递请求参数,请求 URL 也可以通过类似于 “/chapter15/user.html? param1=value1&m2=value2” 的方式传递请求参数。


①报文协议及版本;
②状态码及状态描述;
③响应报文头,也是由多个属性组成;
④响应报文体,服务器返回给浏览器的文本信息,通常 HTML, CSS, JS, 图片等文件就放在这一部分。
# get 和 post 区别(汉得)
Form 中的 get 和 post 方法,在数据传输过程中分别对应了 HTTP 协议中的 GET 和 POST 方法。二者主要区别如下:
- 1、Get 是用来从服务器上获得数据,而 Post 是用来向服务器上传递数据。
- 2、Get 将表单中数据的按照 variable=value 的形式,添加到 action 所指向的 URL 后面,并且两者使用 “?” 连接,而各个变量之间使用 “&” 连接;Post 是将表单中的数据放在 form 的数据体中,按照变量和值相对应的方式,传递到 action 所指向 URL。
- 3、Get 是不安全的,因为在传输过程,数据被放在请求的 URL 中,而如今现有的很多服务器、代理服务器或者用户代理都会将请求 URL 记录到日志文件中,然后放在某个地方,这样就可能会有一些隐私的信息被第三方看到。另外,用户也可以在浏览器上直接看到提交的数据,一些系统内部消息将会一同显示在用户面前。Post 的所有操作对用户来说都是不可见的。
- 4、Get 传输的数据量小,这主要是因为受 URL 长度限制;而 Post 可以传输大量的数据,所以在上传文件只能使用 Post(当然还有一个原因,将在后面的提到)。
- 5、Get 限制 Form 表单的数据集的值必须为 ASCII 字符;而 Post 支持整个 ISO10646 字符集。
- 6、Get 是 Form 的默认方法。
使用 Post 传输的数据,可以通过设置编码的方式正确转化中文;而 Get 传输的数据却没有变化。在以后的程序中,我们一定要注意这一点。
# session 和 cookie 区别(汉得)
1.Cookie 的工作原理
(1)浏览器端第一次发送请求到服务器端(2)服务器端创建 Cookie,该 Cookie 中包含用户的信息,然后将该 Cookie 发送到浏览器端
(3)浏览器端再次访问服务器端时会携带服务器端创建的 Cookie
(4)服务器端通过 Cookie 中携带的数据区分不同的用户
————————————————
2.Session 的工作原理
(1)浏览器端第一次发送请求到服务器端,服务器端创建一个 Session,同时会创建一个特殊的 Cookie(name 为 JSESSIONID 的固定值,value 为 session 对象的 ID),然后将该 Cookie 发送至浏览器端
(2)浏览器端发送第 N(N>1)次请求到服务器端,浏览器端访问服务器端时就会携带该 name 为 JSESSIONID 的 Cookie 对象
(3)服务器端根据 name 为 JSESSIONID 的 Cookie 的 value (sessionId), 去查询 Session 对象,从而区分不同用户。
name 为 JSESSIONID 的 Cookie 不存在(关闭或更换浏览器),返回 1 中重新去创建 Session 与特殊的 Cookie
name 为 JSESSIONID 的 Cookie 存在,根据 value 中的 SessionId 去寻找 session 对象
value 为 SessionId 不存在 **(Session 对象默认存活 30 分钟)**,返回 1 中重新去创建 Session 与特殊的 Cookie
value 为 SessionId 存在,返回 session 对象
————————————————
(1) cookie 数据存放在客户的浏览器上,session 数据放在服务器上,但是服务端的 session 的实现对客户端的 cookie 有依赖关系的;
(2) cookie 不是很安全,别人可以分析存放在本地的 COOKIE 并进行 COOKIE 欺骗,如果主要考虑到安全应当使用 session
(3) session 会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用 COOKIE
(4) 单个 cookie 在客户端的限制是 3K,就是说一个站点在客户端存放的 COOKIE 不能 3K。
(5) 所以:将登陆信息等重要信息存放为 SESSION; 其他信息如果需要保留,可以放在 COOKIE 中
# 9. 一些 linux 命令
# 0.Liunx 查看内核版本,发行版 (特斯拉,茄子)
1 | 1. |
# crontab * 的含义 (茄子)
1 | # Example of job definition: |
# 查看 linux 文件夹大小 (茄子)
先来说明一件事:
drwxr-xr-x 5 root root 4.0K Apr 5 2022 src
drwxr-xr-x 2 www www 4.0K Apr 5 2022 maomao
- 文件储存在硬盘上,硬盘的最小存储单位叫做 “扇区”(Sector)。每个扇区储存 512 字节(相当于 0.5KB)。
- 操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个 “块”(block)。这种由多个扇区组成的 “块”,是文件存取的最小单位。“块” 的大小,最常见的是 4KB,即连续八个 sector 组成一个 block。
- 文件数据都储存在 “块” 中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做 inode,中文译名为 “索引节点”。
- 每一个文件都有对应的 inode,里面包含了与该文件有关的一些信息。
而 Linux 系统中,目录(directory)也是一种文件。打开目录,实际上就是打开目录文件。目录文件的结构非常简单,就是一系列目录项(dirent)的列表。每个目录项,由两部分组成:所包含文件的文件名,以及该文件名对应的 inode 号码。
所以 ls -al 命令实际显示的就是目录文件的大小。又因为 OS 定义的文件最小存取单位 “块”(block)是 4KB,所以目录一般显示为 4096B。
[svc] 为何 linux ext4 文件系统目录默认大小是 4k? - _毛台 - 博客园 (cnblogs.com)

[lighthouse@VM-16-11-centos ]$ du -h -d 0 sqllab/
9.2M sqllab/
- -h , 简单可读的现实大小,自动判断 B,K,M,G…
- -d 0 , 现实列表深度为 0,就是只现实.kde 目录的占用,如果 - d 1 会显示第一级文件的大小,以此类推
du -sh 命令,可查看当前文件夹的总大小
du -h --max-depth=1
9.2M ./sqllab
32K ./maomao
59M ./wordpress
199M ./besides
13M ./src
5.6M ./sqli
223M ./vulhub
377M ./keshe
44M ./html
942M .
# 分区挂载过程 (茄子)
1 | (1)虚拟机添加硬盘 |
# 查看历史命令,查看自己的和别人的 (深信服)
1 | history |
# 定时任务有哪些 (宏杉)
1 | crontab //前面讲过 |
# linux 启动过程 (宏杉)
1 | Linux系统的启动过程并不是大家想象中的那么复杂,其过程可以分为5个阶段: |
# linux 运行级别 (amazon)
Linux 系统有 7 个运行级别 (runlevel):
- 运行级别 0:系统停机状态,系统默认运行级别不能设为 0,否则不能正常启动
- 运行级别 1:单用户工作状态,root 权限,用于系统维护,禁止远程登录
- 运行级别 2:多用户状态 (没有 NFS)
- 运行级别 3:完全的多用户状态 (有 NFS),登录后进入控制台命令行模式
- 运行级别 4:系统未使用,保留
- 运行级别 5:X11 控制台,登录后进入图形 GUI 模式
- 运行级别 6:系统正常关闭并重启,默认运行级别不能设为 6,否则不能正常启动
# linux 进程状态(汉得)
3 running, 144 sleeping, 0 stopped, 1 zombie
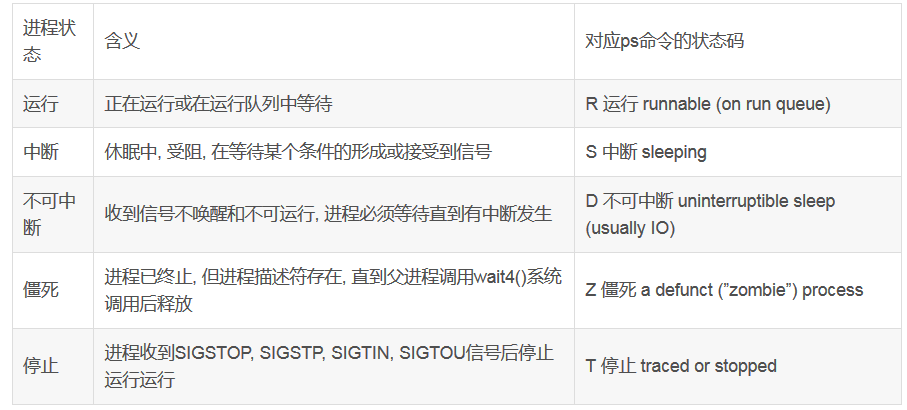
# 查看服务是否运行(汉得)
ps ef 和 ps aux
[root@VM-16-11-centos ~]# ps -ef | grep sshd
root 2896 1 0 Mar22 ? 00:01:56 /usr/sbin/sshd -D
root 11786 2896 0 09:52 ? 00:00:00 sshd: lighthouse [priv]
lightho+ 11800 11786 0 09:52 ? 00:00:00 sshd: lighthouse@pts/0
root 13538 11930 0 09:57 pts/0 00:00:00 grep --color=auto sshdps aux 最初用到 Unix Style 中,而 ps -ef 被用在 System V Style 中,两者输出略有不同。
其中 STAT 状态位常见的状态字符有
D // 无法中断的休眠状态(通常 IO 的进程);
R // 正在运行可中在队列中可过行的;
S // 处于休眠状态;
T // 停止或被追踪;
W // 进入内存交换 (从内核 2.6 开始无效);
X // 死掉的进程 (基本很少见);
Z // 僵尸进程;
< // 优先级高的进程
N // 优先级较低的进程
L // 有些页被锁进内存;
s // 进程的领导者(在它之下有子进程);
l // 多线程,克隆线程(使用 CLONE_THREAD, 类似 NPTL pthreads);
+ // 位于后台的进程组;
# 查看服务器 CPU,内存,磁盘利用率,linux 版本(汉得)
1 | 1.查看内存使用率 |
Linux 系统查看 CPU、机器型号、内存等信息 - 腾讯云开发者社区 - 腾讯云 (tencent.com)
# chmod (改变文件所属者)(汉得)
1 | chmod 777 /home/aaa/aaa.sh |
# LVM(宏杉,吉利英伦)
LVM 是逻辑盘卷管理(Logical Volume Manager)的简称,它是 Linux 环境下对磁盘分区进行管理的一种机制,LVM 是建立在硬盘和分区之上的一个逻辑层,来提高磁盘分区管理的灵活性。
LVM 最大的特点就是可以对磁盘进行动态管理。因为逻辑卷的大小是可以动态调整的,而且不会丢失现有的数据。如果我们新增加了硬盘,其也不会改变现有上层的逻辑卷。作为一个动态磁盘管理机制,逻辑卷技术大大提高了磁盘管理的灵活性。
PV(Physical Volume)- 物理卷
物理卷在逻辑卷管理中处于最底层,它可以是实际物理硬盘上的分区,也可以是整个物理硬盘。
VG(Volumne Group)- 卷组
卷组建立在物理卷之上,一个卷组中至少要包括一个物理卷,在卷组建立之后可动态添加物理卷到卷组中。一个逻辑卷管理系统工程中可以只有一个卷组,也可以拥有多个卷组。
LV(Logical Volume)- 逻辑卷
逻辑卷建立在卷组之上,卷组中的未分配空间可以用于建立新的逻辑卷,逻辑卷建立后可以动态地扩展和缩小空间。系统中的多个逻辑卷可以属于同一个卷组,也可以属于不同的多个卷组PV 物理卷常用操作
pvcreate /dev/DEVICE: 创建 PV
pvs:简要 PV 信息显示
pvdisplay:显示 PV 的详细信息
pvremove /dev/DEVICE: 移除 PV
pvscan: 扫描系统中连接的所有硬盘,列出找到的物理卷列表VG 常用操作
vgcreate /dev/DEVICE: 创建 VG 卷组
vgs: 简要 VG 信息显示
vgextend:动态扩展 LVM 卷组,它通过向卷组中添加物理卷来增加卷组的容量
vgreduce:通过删除 LVM 卷组中的物理卷来减少卷组容量,不能删除 LVM 卷组中剩余的最后一个物理卷
vgdisplay:显示 VG 的详细信息
vgscan:查找系统中存在的 LVM 卷组,并显示找到的卷组列表
vgremove:删除卷组,其上的逻辑卷必须处于离线状态4、LV 常用操作
lvcreate : 用来创建 LVM 的逻辑卷
lvcreate -L #[mMgGtT] -n NAME VolumeGroup
lvs : 显示逻辑卷信息
lvscan:扫描当前系统中的所有逻辑卷,及其对应的设备文件
lvdisplay:显示逻辑卷属性
lvextend:可在线扩展逻辑卷空间
lvreduce:缩减逻辑卷空间,一般离线使用
lvremove:删除逻辑卷,需要处于离线(卸载)状态缺点:
在从卷组中移除一个磁盘的时候必须使用 reducevg 命令(这个命令要求 root 权限,并且不允许在快照卷组中使用)。
当卷组中的一个磁盘损坏时,整个卷组都会受到影响。
因为加入了额外的操作,存储性能受到影响
不能减小文件系统大小(受文件系统类型限制
# 压缩,解压缩 (迪普,汉得)
Linux 中可以识别的常见压缩格式,".zip"、".gz"、".bz2"、“tar”、".tar.gz"、".tar.bz2" 等等
1.zip 压缩
zip mytxt.zip abc.txt abd.txt bcd.txt # 把三个 txt 文件压缩成一个 zip 文件
unzip -d /home/hepingfly/abc/mytxt.zip # 如果不指定 -d 参数,默认解压到当前目录下
2.gz
gzip 压缩文件后会把源文件删除掉,它是不支持保留源文件的
选项:
-c:将压缩数据输出到标准输出中,可以用于保留源文件
-d:解压缩
- r:压缩目录gzip abc.txt # 将 abc.txt 压缩为 abc.txt.gz
gzip -d # 解压 gzip
gunzip # 解压 gzip
3.bz2
bzip2 [选项] 源文件
选项:
-d:解压缩
-k:压缩时保留源文件
-v:显示压缩的详细信息bzip2 -k bcd.txt #压缩
bzip2 -d 压缩包 # 解压
bunzip2 压缩包 # 解压
4.tar
tar [选项] [-f 压缩包名] 源文件或目录
选项:
-c:打包
-z:压缩和解压缩 “.tar.gz” 格式
-f:指定压缩包的文件名。压缩包的扩展名是用来给管理员识别格式的,所以一定要正确指定扩展名。
-v:显示打包文件过程
tar [选项] 压缩包
选项:
-x:解打包
-f:指定压缩包的文件名
-v:显示解打包文件过程
-j: 压缩和解压缩 “.tar.bz2” 格式
# awk
1 | # 每行按空格或TAB分割,输出文本中的1、4项 |
# selinux
Linux 下默认的接入控制是 DAC,其特点是资源的拥有者可以对他进行任何操作(读、写、执行)。当一个进程准备操作资源时,Linux 内核会比较进程和资源的 UID 和 GID,如果权限允许,就可以进行相应的操作。
SELinux 属于 MAC 的具体实现,增强了 Linux 系统的安全性。MAC 机制的特点在于,资源的拥有者,并不能决定谁可以接入到资源。具体决定是否可以接入到资源,是基于安全策略。而安全策略则是有一系列的接入规则组成,并仅有特定权限的用户有权限操作安全策略。
Security Enhanced Linux (SELinux) 为 Linux 提供了一种增强的安全机制,其本质就是回答了一个 “Subject 是否可以对 Object 做 Action?” 的问题,例如 Web 服务可以写入到用户目录下面的文件吗?其中 Web 服务就是 Subject 而文件就是 Object,写入对应的就是 Action。
- Subject: 在 SELinux 里指的就是进程,也就是操作的主体。
- Object: 操作的目标对象,例如 文件
- Action: 对 Object 做的动作,例如 读取、写入或者执行等等
- Context: Subject 和 Object 都有属于自己的 Context,也可以称作为 Label。Context 有几个部分组成,分别是 SELinux User、SELinux Role、SELinux Type、SELinux Level
进程和文件都有属于自己的 Context 信息,Context 分为几个部分,分别是 SELinux User、Role、Type 和一个可选的 Level 信息。SELinux 在运行过程中将使用这些信息查询安全策略进行决策。
显示进程的 Context ps -z
显示文件的 Context 信息 ls -z
临时修改文件的 SELinux Type 为
htttpd_sys_content_tchcon -t httpd_sys_content_t file-nameSELinux 有三个运行状态,分别是 disabled, permissive 和 enforcing
- Disable: 禁用 SELinux,不会给任何新资源打 Label,如果重新启用的话,将会给资源重新打上 Lable,过程会比较缓慢。
- Permissive:如果违反安全策略,并不会真正的执行拒绝操作,替代的方式是记录一条 log 信息。
- Enforcing: 默认模式,SELinux 的正常状态,会实际禁用违反策略的操作
SELinux 的 Log 日志默认记录在
/var/log/audit/audit.logSELinux 的配置文件位于
/etc/selinux/configBooleans 允许在运行时修改 SELinux 安全策略。
理解 Linux 下的 SELinux - 知乎 (zhihu.com)
# 10.mysql 相关
# mysql 新建用户 (茄子)
CREATE USER user_account IDENTIFIED BY password; #CREATE USER dbadmin@localhost IDENTIFIED BY ‘pwd123’;
CREATE USER superadmin@’%’ IDENTIFIED BY ‘mypassword’; # 要允许用户帐户从任何主机连接,请使用百分比 (
%) 通配符CREATE USER remote_user; #可以从任何主机连接到数据库服务器:
可以使用 INSERT 语句将用户的信息添加到 mysql.user 表中,但必须拥有对 mysql.user 表的 INSERT 权限。通常 INSERT 语句只添加 Host、User 和 authentication_string 这 3 个字段的值。
INSERT INTO mysql.user(Host, User, authentication_string, ssl_cipher, x509_issuer, x509_subject) VALUES (‘hostname’, ‘username’, PASSWORD(‘password’), ‘’, ‘’, ‘’);
GRANT SELECT ON*.* TO ‘test3’@localhost IDENTIFIED BY ‘test3’;
4. 删除用户
DROP USER ‘username’@‘host’;
5. 更改密码
SET PASSWORD FOR ‘username’@‘host’ = PASSWORD(‘newpassword’);
# mysql 查看权限 (茄子)
SHOW GRANTS FOR dbadmin@localhost;
GRANT privileges ON databasename.tablename TO ‘username’@‘host’
REVOKE privilege ON databasename.tablename FROM ‘username’@‘host’;
# mysql 备份 (中海达)
mysqldump -h 主机名 -P 端口 -u 用户名 -p 密码 –database 数据库名 > 文件名.sql
mysqldump –all-databases > allbackupfile.sql // 备份所有数据库
直接将 MySQL 数据库压缩备份
mysqldump -hhostname -uusername -ppassword -database databasename | gzip > backupfile.sql.gz
备份 MySQL 数据库某个 (些) 表
mysqldump -hhostname -uusername -ppassword databasename specific_table1 specific_table2 > backupfile.sql
免费的 MySQl 热备份软件 Percona XtraBackup
恢复数据库
source /opt/all.sql;
学习 MySQL 备份一篇就够了!!!(完全备份、增量备份、备份恢复)_下一个艺术家的博客 - CSDN 博客_mysql 备份文件
# mysql 可靠 (中海达)
… 这个问题超标了,自己看吧
五大常见的 MySQL 高可用方案 - 知乎 (zhihu.com)
# acid (汉得)
数据库管理系统在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性
- Atomicity(原子性):一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
- Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
# mysql 锁 (汉得)
先挖个坑
MySQL 锁总结 - 知乎 (zhihu.com)
# 隔离级别 (汉得)
再挖个坑
彻底搞懂 MySQL 事务的隔离级别 - 阿里云开发者社区 (aliyun.com)
# 主键,外键区别,主键,索引区别 (汉得)
1、主键用来保证数据完整性,外键用来和其他表建立联系用;
2、主键只能有一个,而一个表可以有多个外键;
3、主键不能有重复,不允许为空,而外键可以有重复,可以是空值。
主键、外键和索引的区别:
a. 定义
主键:唯一标识一条记录,不能有重复,不允许为空。
外键:表的外键是另一表的主键,外键是可以有重复的,可以是空值。
索引:该字段没有重复值,但可以有一个空值。b. 作用
主键:用来保证数据完整性
外键:用来和其他表建立联系用
索引:用来提高查询排序的速度c. 个数
主键:主键只能有一个。
外键:一个表可以有多个外键。
索引:一个表可以有多个唯一索引。提高了查询效率,缺点是在插入、更新和删除记录时,需要同时修改索引,因此,索引越多,插入、更新和删除记录的速度就越慢。
通过
UNIQUE关键字我们就添加了一个唯一索引
# 10. 云计算相关问题
# 使用过公有云吗,对公有云了解吗,中科还问了 OpenStack 了解吗 (中海达,茄子,中科曙光)
OpenStack 入门科普,看这一篇就够啦! - 知乎 (zhihu.com)
OpenStack 入门 —— 理论篇(一):OpenStack 的概念、概览以及核心组件概述_51CTO 博客_openstack 的技术核心
表示层:负责与用户交互,主要包含一些图形化界面的 web 门户网站(用于提供给非开发人员进行界面操作),同时该部分还提供了供开发人员进行二次开发的 API 接口。该部分还包括一些更高级的特性,例如:负载均衡、控制台代理安全和命名服务。
逻辑层:提供云服务的智能控制功能,如:orchestration(负责任务的工作流管理)、scheduling(任务到资源的调度管理)、policy(配额等服务)、image registry(镜像实例的元数据管理)和 logging(事件计费管理)。
资源层:包含计算、网络和存储等物理资源。
什么是公有云?和私有云什么区别? - 华为 (huawei.com)
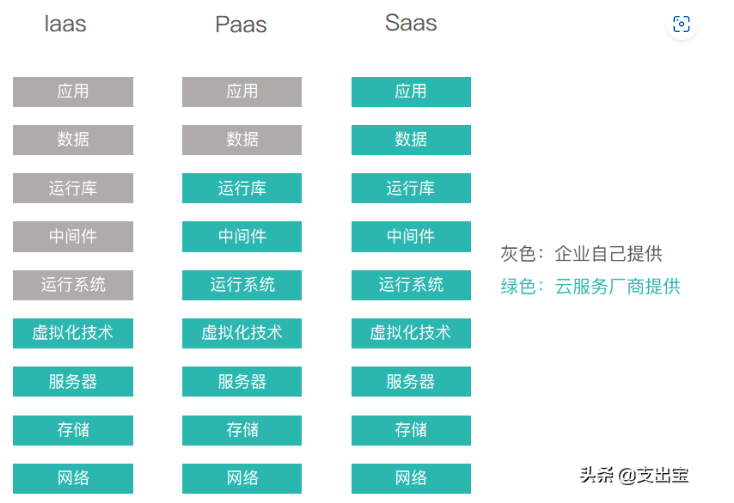
# IAAS,PAAS,SAAS (吉利英伦)
Infrastructure-as-a-service
Platform-as-a-service
Software-as-a-service![image-20221029101351518]()
![image-20221029101444881]()

# VPC 之间网络隔离(云智)
安全组是一个逻辑上的分组,由一个区域内具有相同安全需求的 ECS 组成。安全组和 ECS 绑定,可以实现如防火墙一样的功能,不同安全组的实例默认不相通,但可以授权两个安全组之间互访。
网络 ACL 与安全组类似,也是安全防护策略,若想增加额外的安全防护层时,就可以启用网络 ACL。网络 ACL 是对子网的一个保护,通过与子网关联的出方向、入方向规则控制出入子网的数据流。安全组只有 “允许” 策略,但网络 ACL 可以 “拒绝” 和 “允许”。
vpc 网络隔离_云计算中 VPC 的由来及浅析_爱吃生菜的鱼的博客 - CSDN 博客
(66 条消息) vpc 网络隔离_一文秒懂云中安全 VPC_英俊潇洒你冲哥的博客 - CSDN 博客
# 11. 负载均衡相关
# 有哪些负载均衡器 (茄子)
1 | LVS、Nginx、Haproxy |
# LVS(云智)
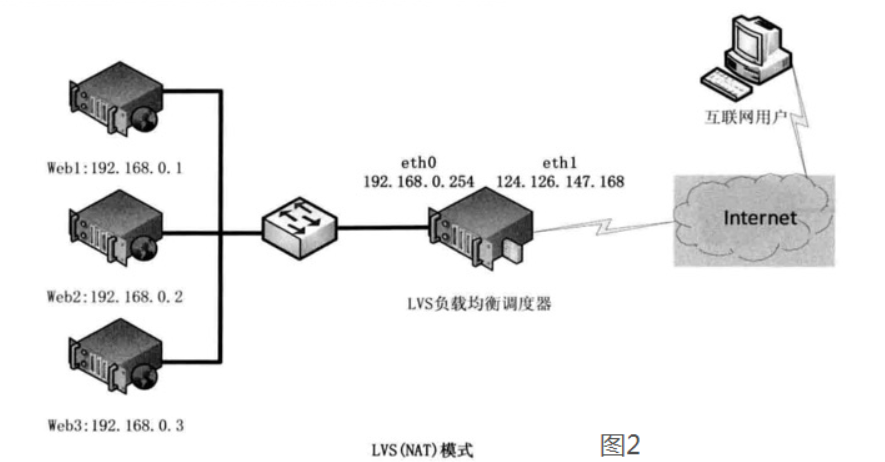
LVS(Linux Virtual Server)即 Linux 虚拟服务器,是开源负载均衡项目,目前 LVS 已经被集成到 Linux 内核模块中。该项目在 Linux 内核中实现了基于 IP 的数据请求负载均衡调度方案,其体系结构如图 1 所示,终端互联网用户从外部访问公司的外部负载均衡服务器,终端用户的 Web 请求会发送给 LVS 调度器,调度器根据自己预设的算法决定将该请求发送给后端的某台 Web 服务器,比如,轮询算法可以将外部的请求平均分发给后端的所有服务器,终端用户访问 LVS 调度器虽然会被转发到后端真实的服务器,但如果真实服务器连接的是相同的存储,提供的服务也是相同的服务,最终用户不管是访问哪台真实服务器,得到的服务内容都是一样的,整个集群对用户而言都是透明的。最后根据 LVS 工作模式的不同,真实服务器会选择不同的方式将用户需要的数据发送到终端用户,LVS 工作模式分为 NAT 模式、TUN 模式、以及 DR 模式。
1、基于 NAT 的 LVS 模式负载均衡在 LVS(NAT)模式的集群环境中,由于所有的数据请求及响应的数据包都需要经过 LVS 调度器转发,如果后端服务器的数量大于 10 台,则调度器就会成为整个集群环境的瓶颈。
2. 基于 TUN 的 LVS 负载均衡
LVS(TUN)的思路就是将请求与响应数据分离,让调度器仅处理数据请求,而让真实服务器响应数据包直接返回给客户端。
LVS(TUN)模式要求真实服务器可以直接与外部网络连接,真实服务器在收到请求数据包后直接给客户端主机响应数据。
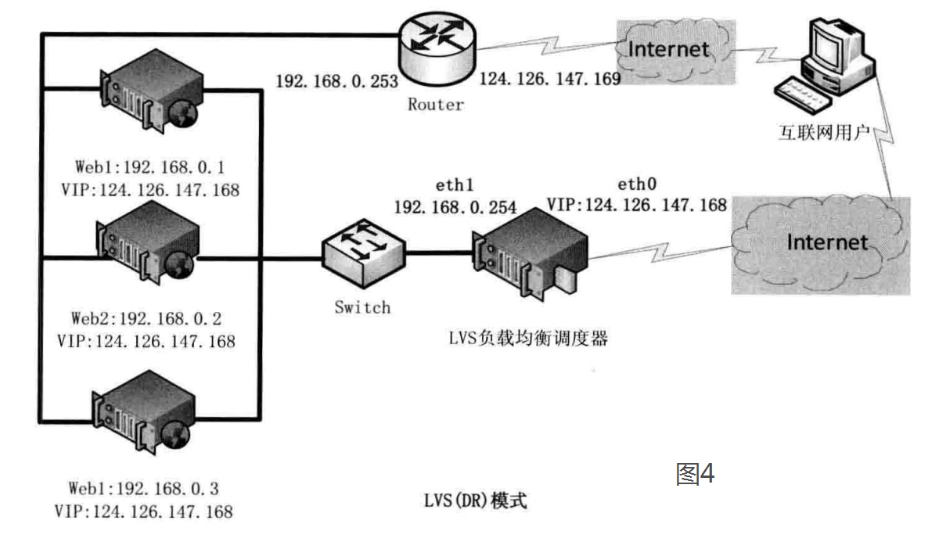
3、基于 DR 的 LVS 负载均衡
直接路由模式(DR 模式)要求调度器与后端服务器必须在同一个局域网内,VIP 地址需要在调度器与后端所有的服务器间共享,因为最终的真实服务器给客户端回应数据包时需要设置源 IP 为 VIP 地址,目标 IP 为客户端 IP,这样客户端访问的是调度器的 VIP 地址,回应的源地址也依然是该 VIP 地址(真实服务器上的 VIP),客户端是感觉不到后端服务器存在的。
调度器根据算法在选出真实服务器后,在不修改数据报文的情况下,将数据帧的 MAC 地址修改为选出的真实服务器的 MAC 地址,通过交换机将该数据帧发给真实服务器。整个过程中,真实服务器的 VIP 不需要对外界可见。
LVS 负载均衡(LVS 简介、三种工作模式、十种调度算法)_chenhuyang 的博客 - CSDN 博客_lvs 负载均衡

# 12. 有哪些监控软件 (中海达,茄子)
Prometheus(普罗米修斯)
Zabbix
Cacti
Nagios
Grafana
Open-falcon
https://blog.csdn.net/t8116189520/article/details/81737694
# 13. 中间件相关
# Nginx 了解吗,Nginx 特性,正向代理和反向代理,负载均衡模式 (中海达,长亭,品高)
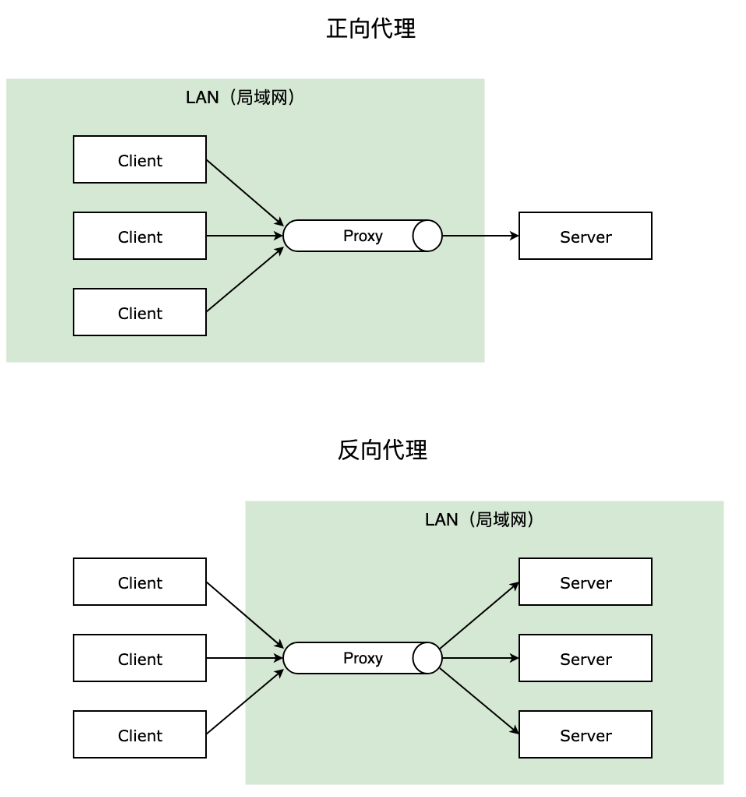
1. 正向代理和反向代理
正向代理: 一般的访问流程是客户端直接向目标服务器发送请求并获取内容,使用正向代理后,客户端改为向代理服务器发送请求,并指定目标服务器(原始服务器),然后由代理服务器和原始服务器通信,转交请求并获得的内容,再返回给客户端。正向代理隐藏了真实的客户端,为客户端收发请求,使真实客户端对服务器不可见;比如你访问 Google 时用的代理服务器就是正向代理
反向代理: 与一般访问流程相比,使用反向代理后,直接收到请求的服务器是代理服务器,然后将请求转发给内部网络上真正进行处理的服务器,得到的结果返回给客户端。反向代理隐藏了真实的服务器,为服务器收发请求,使真实服务器对客户端不可见。一般在处理跨域请求的时候比较常用。现在基本上所有的大型网站都设置了反向代理。Nginx 可以根据不同的正则匹配,采取不同的转发策略,比如图片文件结尾的走文件服务器,动态页面走 web 服务器。并且 Nginx 对返回结果进行错误页跳转,异常判断等。如果被分发的服务器存在异常,他可以将请求重新转发给另外一台服务器,然后自动去除异常服务器。
![image-20221101094821621]()
2. 负载均衡
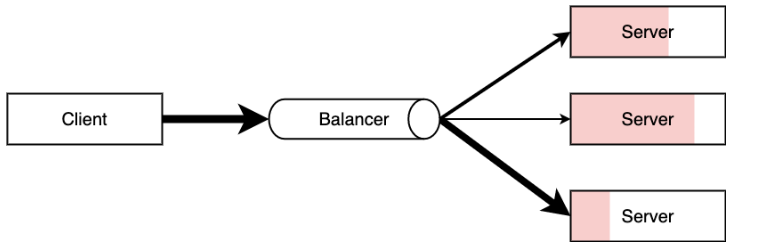
单个服务器解决不了的问题,可以使用多个服务器,然后将请求分发到各个服务器上,将负载分发到不同的服务器,这就是负载均衡,核心是「分摊压力」。Nginx 实现负载均衡,一般来说指的是将请求转发给服务器集群。
Nginx 提供的负载均衡策略有 2 种:内置策略和扩展策略。内置策略为轮询,加权轮询,Ip hash。扩展策略,就天马行空,只有你想不到的没有他做不到的啦,你可以参照所有的负载均衡算法,给他一一找出来做下实现。
![image-20221101095012272]()
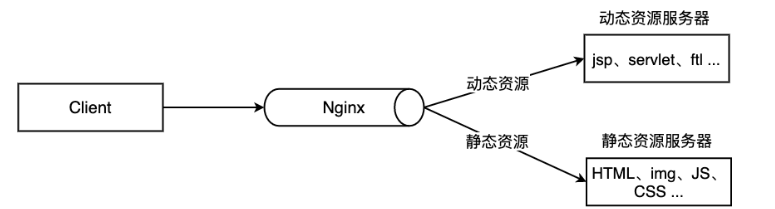
3. 动静分离
为了加快网站的解析速度,可以把动态页面和静态页面由不同的服务器来解析,加快解析速度,降低原来单个服务器的压力。
由于 Nginx 的高并发和静态资源缓存等特性,经常将静态资源部署在 Nginx 上。如果请求的是静态资源,直接到静态资源目录获取资源,如果是动态资源的请求,则利用反向代理的原理,把请求转发给对应后台应用去处理,从而实现动静分离。
使用前后端分离后,可以很大程度提升静态资源的访问速度,即使动态服务不可用,静态资源的访问也不会受到影响。
![image-20221101095048519]()
4.web 缓存
Nginx 可以对不同的文件做不同的缓存处理,配置灵活,并且支持 FastCGI_Cache,主要用于对 FastCGI 的动态程序进行缓存。配合着第三方的 ngx_cache_purge,对制定的 URL 缓存内容可以的进行增删管理。
Nginx 从入门到实践,万字详解! - NGINX 开源社区
Nginx 配置详解 | 菜鸟教程 (runoob.com)
# 14. 连通性 /toubleshooting 问题
# 14.1 判断和主机建立了连接的 IP (茄子)
netstat -ano
netstat -lntup
nbtstat -A 10.129.52.207
NBTSTAT [ [-a RemoteName] [-A IP address] [-c] [-n] [-r] [-R] [-RR] [-s] [-S] [interval] ]
-a (适配器状态) 列出指定名称的远程机器的名称表 -A (适配器状态) 列出指定 IP 地址的远程机器的名称表。 -c (缓存) 列出远程[计算机]名称及其 IP 地址的 NBT 缓存 -n (名称) 列出本地 NetBIOS 名称。 -r (已解析) 列出通过广播和经由 WINS 解析的名称 -R (重新加载) 清除和重新加载远程缓存名称表 -S (会话) 列出具有目标 IP 地址的会话表 -s (会话) 列出将目标 IP 地址转换成计算机 NETBIOS 名称的会话表。 -RR (释放刷新) 将名称释放包发送到 WINS,然后启动刷新
# 14.2 主机间是否连通,端口是否开放 (茄子)
连通:
ping
traceroute
端口:
telnet 192.192.193.211 3389
nc -z 192.192.193.211 22 //tcp
nc –uz 192.192.193.211 22 //udp
nmap // 看我写的安全那块
netstat -ano
ssh 10.0.250.3 -p 80 -v
wget …:
# 15. 怎么保证安全和可靠 (信锐)
可靠的接入层应提供以下主要特性:
- 使用冗余引擎和冗余电源获得系统级冗余,为关键用户群提供高可靠性;
- 与具备冗余系统的汇聚层进行双归属连接,获得缺省网关冗余,支持在汇聚层的主备交换机间快速实现故障切换;
- 通过链路汇聚提高带宽利用率,同时降低复杂性;
- 通过配置 802.1X,动态 ARP 检查及 IP 源地址保护等功能增加安全性,有效防止非法访问。
接入层到汇聚层选择三角形组网,由于接入层三角形组网存在二层环路,所以需要在交换机上使能多生成树协议 MSTP。汇聚层交换机部署虚拟路由器冗余协议 VRRP,将 VRRP 组的虚拟 IP 地址作为服务器网关。
汇聚层应使用与核心层相同结构的冗余节点备份连接,以实现最快速的路由收敛并避免黑洞产生。汇聚层做三层接入网关时,还需要通过 VRRP 等协议实现网关的冗余备份和流量的负载分担。汇聚层边界发生链路或节点故障时,收敛速度取决于缺省网关冗余与故障切换,通过合理地配置协议定时器,可达到秒级的收敛速度。
汇聚层到核心层间采用 OSPF 等动态路由协议进行路由层面高可用保障。
核心层设备作为网络的骨干,需要能提供快速的数据交换和极高的永续性。从备份和负载分担的角度可选用双核心或多核心;从单台设备考虑,选用交换性能和可靠性高的设备,支持双主控、电源冗余、风扇冗余、分布式转发等特性。并降低核心设备配置的复杂度,减少出现错误的几率。
传统架构为保证网络高可靠性通常采用 MSTP+VRRP,这种组网需要在接入交换机与汇聚交换机间运行 MSTP 协议,管理和维护较复杂。但当接入交换机和汇聚交换机都采用 H3C IRF 智能弹性架构技术之后,可将每两台交换机(也可以是多台)配置成一个 IRF 堆叠组,两台汇聚交换机也配置成一个堆叠组,接入交换机与汇聚交换机之间通过捆绑链路连接,如图 3 所示。从逻辑上看,一个堆叠组就是一台设备,因此接入交换机和汇聚交换机间不存在二层环路,可以避免 MSTP 的配置管理,简化网络设计。
(67 条消息) 网络的可靠性是设计出来的_半遮雨的博客 - CSDN 博客_网络可靠性
如何保证网络安全 (cnfla.com)
# 16.DNS
# DNS 原理,端口 (特斯拉,长亭)
![img]()
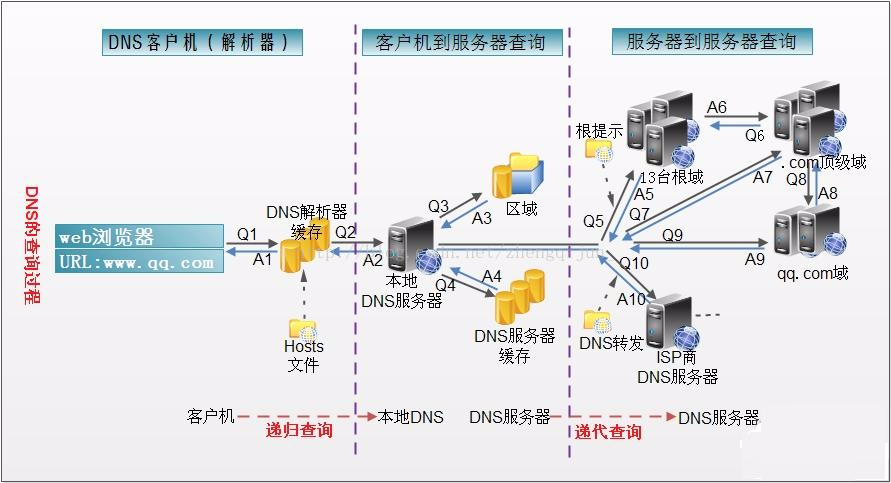
1、在浏览器中输入 www . qq .com 域名,操作系统会先检查自己本地的 hosts 文件是否有这个网址映射关系,如果有,就先调用这个 IP 地址映射,完成域名解析。
2、如果 hosts 里没有这个域名的映射,则查找本地 DNS 解析器缓存,是否有这个网址映射关系,如果有,直接返回,完成域名解析。
3、如果 hosts 与本地 DNS 解析器缓存都没有相应的网址映射关系,首先会找 TCP/ip 参数中设置的首选 DNS 服务器,在此我们叫它本地 DNS 服务器,此服务器收到查询时,如果要查询的域名,包含在本地配置区域资源中,则返回解析结果给客户机,完成域名解析,此解析具有权威性。
4、如果要查询的域名,不由本地 DNS 服务器区域解析,但该服务器已缓存了此网址映射关系,则调用这个 IP 地址映射,完成域名解析,此解析不具有权威性。
5、如果本地 DNS 服务器本地区域文件与缓存解析都失效,则根据本地 DNS 服务器的设置(是否设置转发器)进行查询,如果未用转发模式,本地 DNS 就把请求发至 13 台根 DNS,根 DNS 服务器收到请求后会判断这个域名 (.com) 是谁来授权管理,并会返回一个负责该顶级域名服务器的一个 IP。本地 DNS 服务器收到 IP 信息后,将会联系负责.com 域的这台服务器。这台负责.com 域的服务器收到请求后,如果自己无法解析,它就会找一个管理.com 域的下一级 DNS 服务器地址 (http://qq.com) 给本地 DNS 服务器。当本地 DNS 服务器收到这个地址后,就会找 http://qq.com 域服务器,重复上面的动作,进行查询,直至找到 www . qq .com 主机。
6、如果用的是转发模式,此 DNS 服务器就会把请求转发至上一级 DNS 服务器,由上一级服务器进行解析,上一级服务器如果不能解析,或找根 DNS 或把转请求转至上上级,以此循环。不管是本地 DNS 服务器用是是转发,还是根提示,最后都是把结果返回给本地 DNS 服务器,由此 DNS 服务器再返回给客户机。
从客户端到本地 DNS 服务器是属于递归查询,而 DNS 服务器之间就是的交互查询就是迭代查询。下面我们列出几条常用的资源记录类型:
SOA: Start Of Authority, 起始授权记录,一个区域解析库仅能有一个 SOA 记录,而且必须为解析库的第一条
NS:Name Server,域名服务器,专用于标明当前区域的 DNS 服务器
MX: Mail eXchange, 邮件交换器,MX 记录有优先级属性(0-99)
A:internet Address,FQDN --> IP,专用于正向解析,用于实现将 FQDN 解析为 IP 地址
PTR: PoinTeR,IP --> FQDN,专用于反向解析,将 IP 地址解析为 FQDN
AAAA:FQDN --> IPv6,专用于正向解析,将 FQDN 解析为 IPv6 地址
CNAME: Canonical Name,别名记录
TXT:Text
SRV:Service
DNS 的工作原理及解析_zhengqijun_的博客 - CSDN 博客_dns 的工作原理
面试官:讲讲 DNS 的原理? - 知乎 (zhihu.com)
https://cloud.tencent.com/developer/article/1618781
DNS 中也有一个地方用到了 TCP 协议。那就是区域传送!
DNS 的规范规定了 2 种类型的 DNS 服务器,一个叫主 DNS 服务器,一个叫辅助 DNS 服务器。在一个区中主 DNS 服务器从自己本机的数据文件中读取该区的 DNS 数据信息,而辅助 DNS 服务器则从区的主 DNS 服务器中读取该区的 DNS 数据信息。当一个辅助 DNS 服务器启动时,它需要与主 DNS 服务器通信,并加载数据信息,这就叫做区传送(zone transfer)。 这种情况下,使用 TCP 协议。
UDP 的 DNS 协议只要一个请求、一个应答就好了。而使用基于 TCP 的 DNS 协议要三次握手、发送数据以及应答、四次挥手。但是 UDP 协议传输内容不能超过 512 字节。不过客户端向 DNS 服务器查询域名,一般返回的内容都不超过 512 字节,用 UDP 传输即可。
# 递归和迭代区别 (这个目前还没人问,我闲着蛋疼自己问自己)
1 | (1)递归查询 |
17. 二层相关
stp 作用 (宏杉)
super vlan (宏杉)
stp 选举 (中科闻歌)
18 链路聚合 (宏杉,中科曙光)
19. 防火墙硬件实现,IPSEC 了解过吗 (中科曙光)
防火墙用过吗,啥型号的,A 访问 B 时在防火墙配置单向还是双向,如果是交换机,需要配置单向还是双向 (中科闻歌)
20. 项目题
小型星星网络
1. 确定网络设备
2. 交换机设备和接口数量,交换机选型 (吞吐量)
# 21.docker/k8s
# k8s 四层网络架构
Node 节点网络
Pod 网络
Service
2
由此引入了服务发现以及负载均衡等问题深入理解 K8S 网络原理上 - 知乎 (zhihu.com)


中型
大型
ping 丢包
# 0x02 安全岗总结
1. 反序列化相关
PHP 反序列化的魔法方法,wakeup 绕过 (理想)
shrio 反序列化,fastjson 反序列化,struct S062 (深信服)
java 反序列化 (深信服)
2. 逻辑漏洞类
逻辑漏洞任意邮箱注册怎么修复 (理想)
登录框有啥漏洞 (安天)
3.XSS 类
富文本编辑器 XSS 怎么解决 (理想)
说说看 xss (长亭)
4.SQL 注入类
SQL 注入怎么防,PDO 在 order by 场景怎么防 (理想)
sql 注入有几种 (深信服)
union select 后面可以加 insert 吗,union select 叫啥名字 (深信服)
怎么通过数据库获取系统权限,mysql,sqlserver (深信服)
mysql 写 shell 命令 (深信服)
堆叠注入原理,和 union select 有啥区别 (深信服)
报错注入语句 (深信服)
时间盲注原理,语句 (深信服)
5. 入侵排查怎么查,netstat 怎么看,怎么找进程 (理想,安天)
6.discuz 漏洞复现 (可能因为我简历里写了)(理想)
7.cookie 对单个参数长度限制 (理想)
8. 出现 0day,资产排查 (理想)
10. 文件上传 shell 成功但不能连接,怎么办 (深信服)
11. 内网渗透相关
内网隧道怎么搭,earthworm 三种模式 (深信服)
内网横向 (深信服)
wmin 端口,横向之后啥权限 (深信服)
12. 权限维持 (深信服)
13.waf 是干啥的,哪一层的 (长亭)
14. 工具使用类
nmap 参数,操作系统 (理想)