# spark分布式计算引擎框架,基于 mapreduce 开发
单机:单进程,单节点
伪分布式:多进程,单节点
分布式:多进程,多节点
分布式计算核心:切分数据,减少数据规模
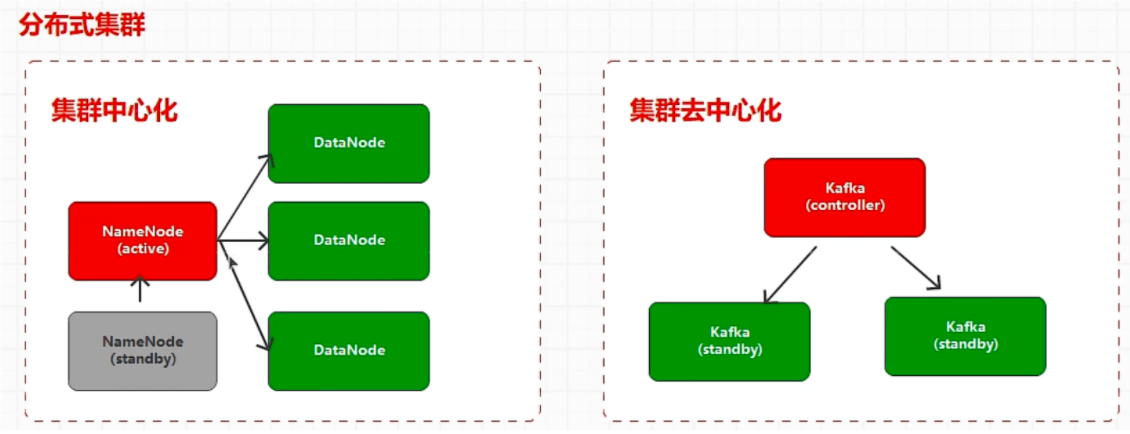
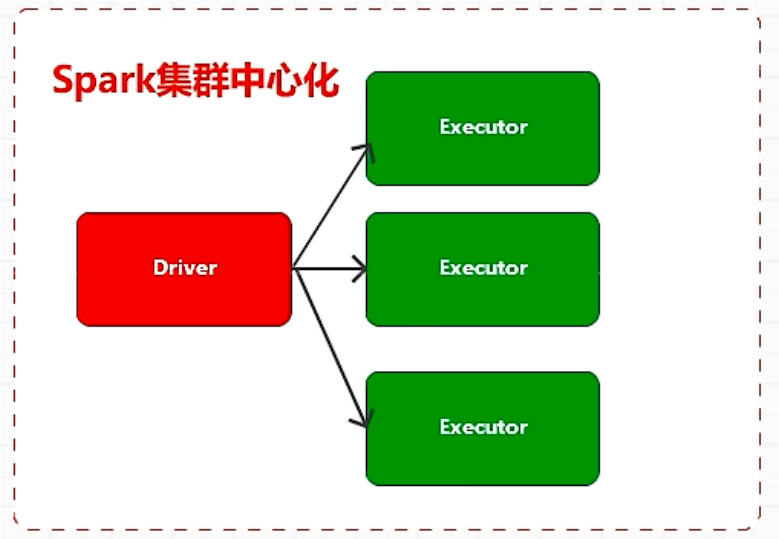
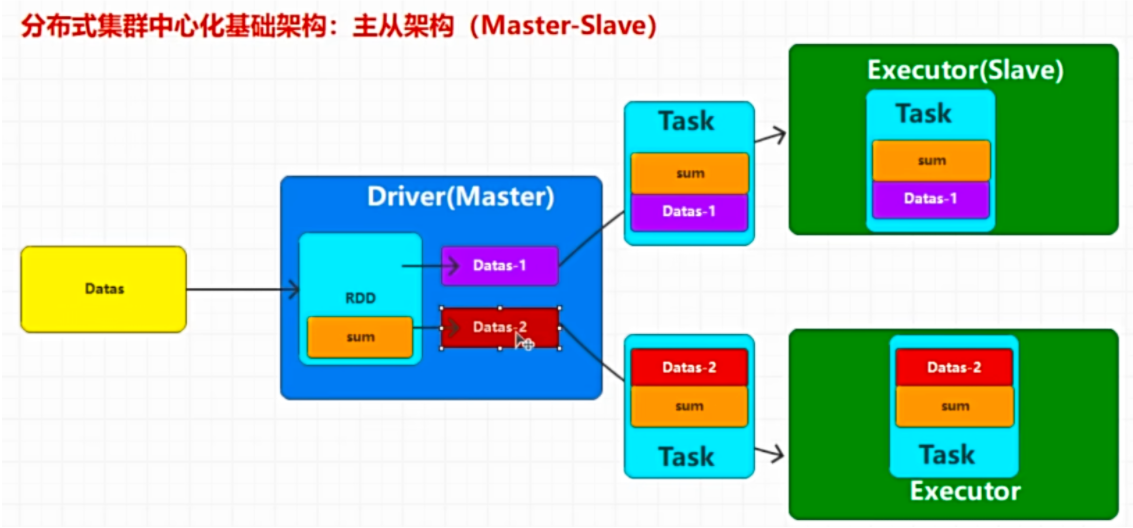
spark 分布式集群采用集群中心化
框架:不完整的计算机程序 (核心功能已经开发完毕,但是是和业务相关的代码未开发)(MR,spark)
系统:完整的计算机程序 (HDFS,Kafka)
引擎:核心功能
spark 基于 mr 开发,两者区别
1. 开发语言:mr:java,不适合进行大量数据处理。spark:scala,适合大量数据处理,封装大量功能
2. 处理方式:hadoop 出现的早,只考虑单一的计算操作
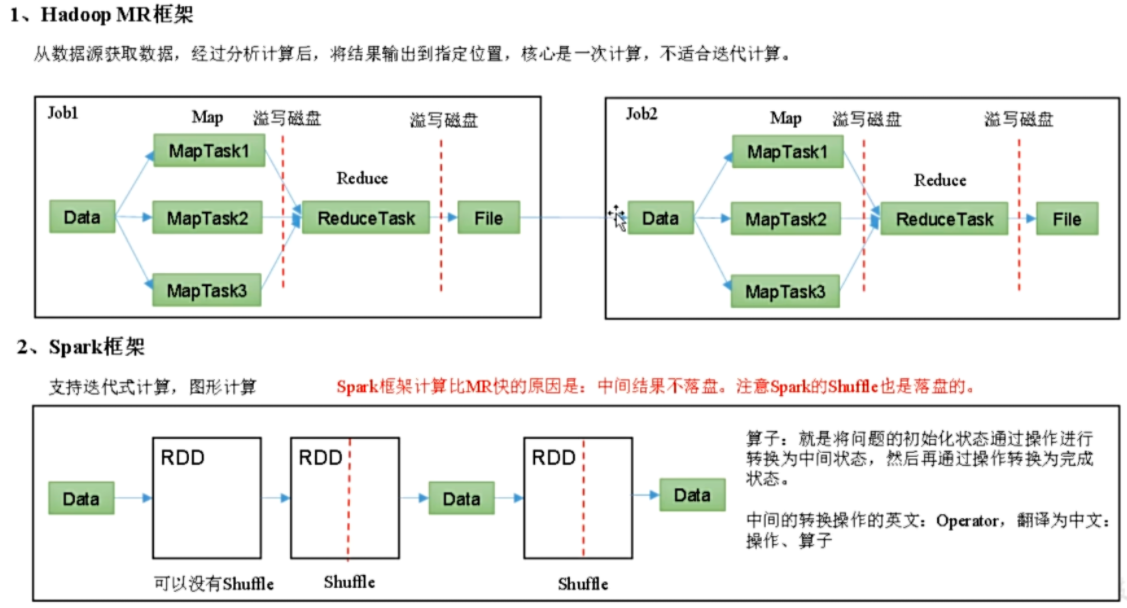
spark 优化了计算过程
回顾:Hadoop 主要解决,海量数据的存储和海量数据的分析计算。
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
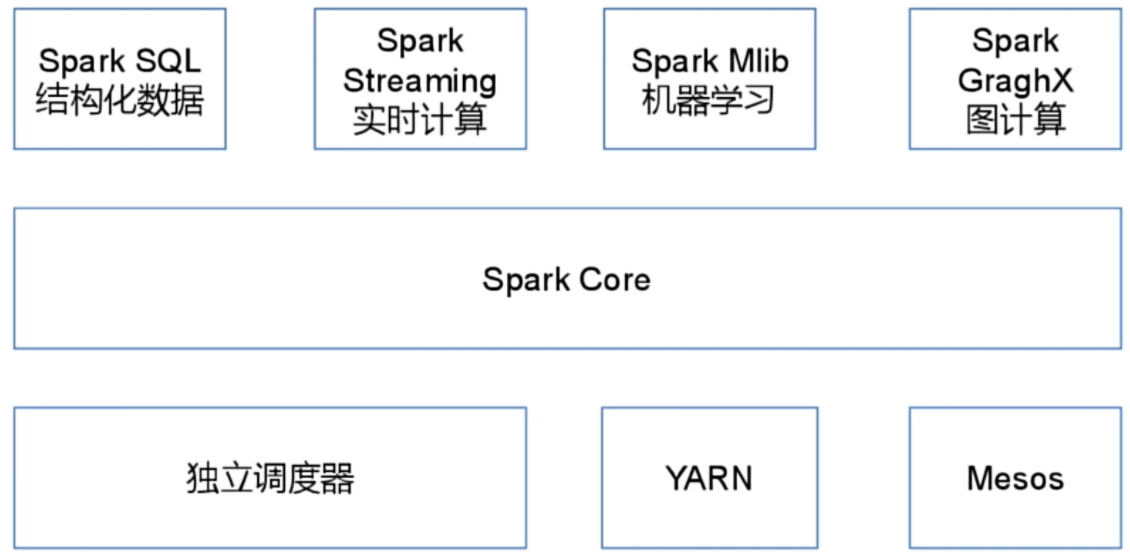
spark 内置模块
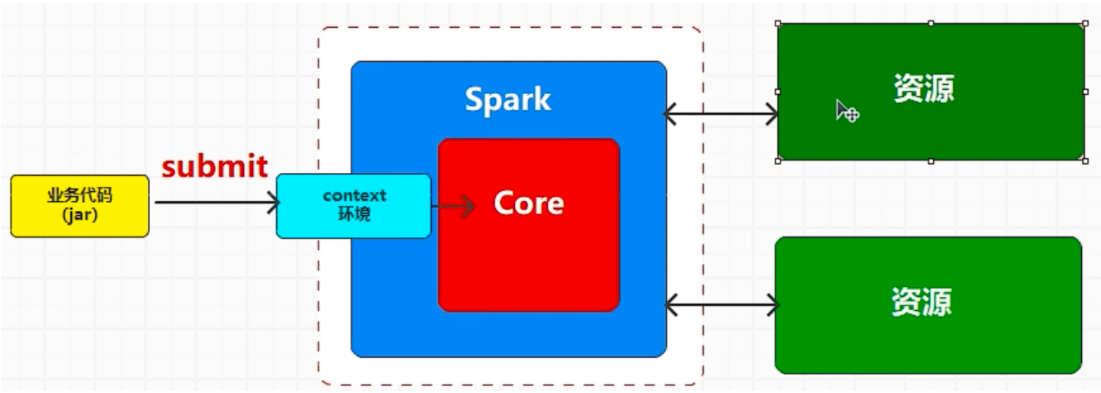
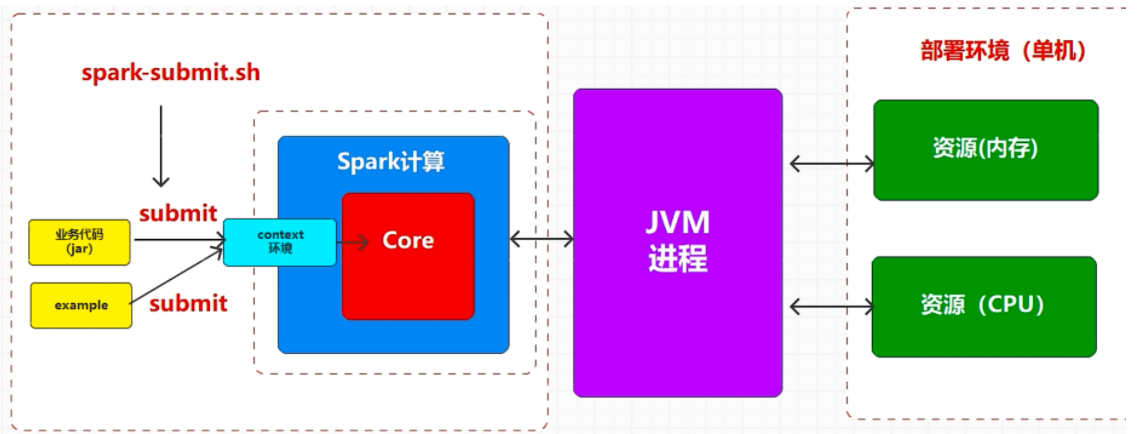
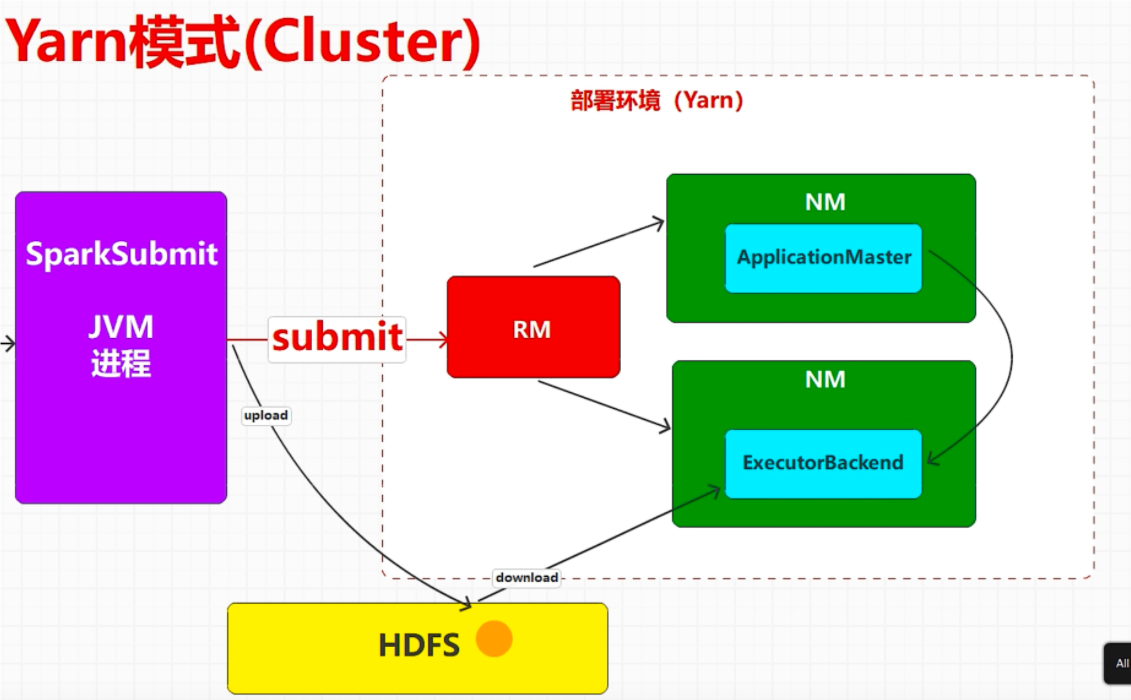
# 部署 spark 集群部署 Spark 其实指的就是 Spark 的程序逻辑在什么资源中执行
如果资源是当前单节点提供的,那么就称之为单机模式
如果资源是当前多节点提供的,那么就称之为分布式模式
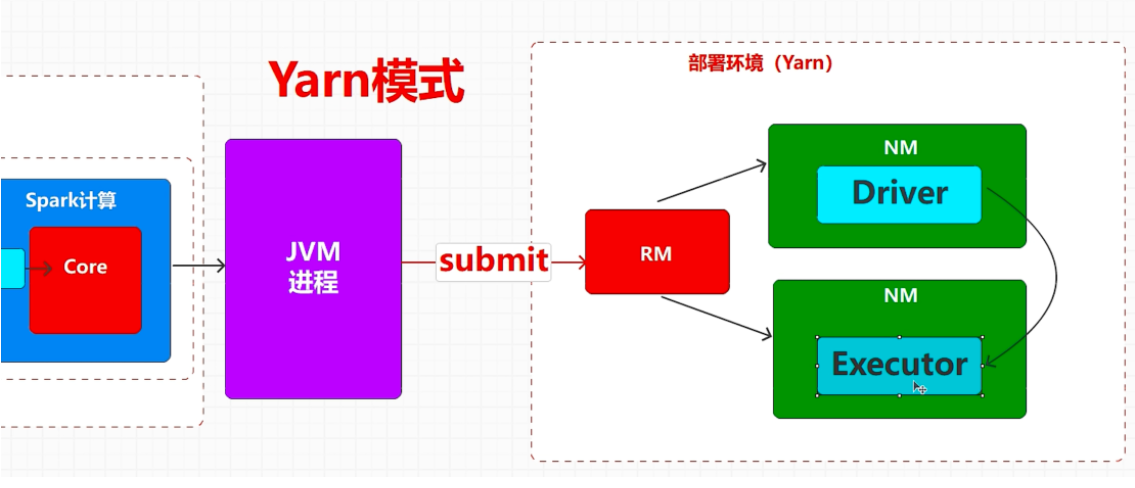
如果资源是由 Yarn 提供的,那么就称之为 Yarn 部署环境
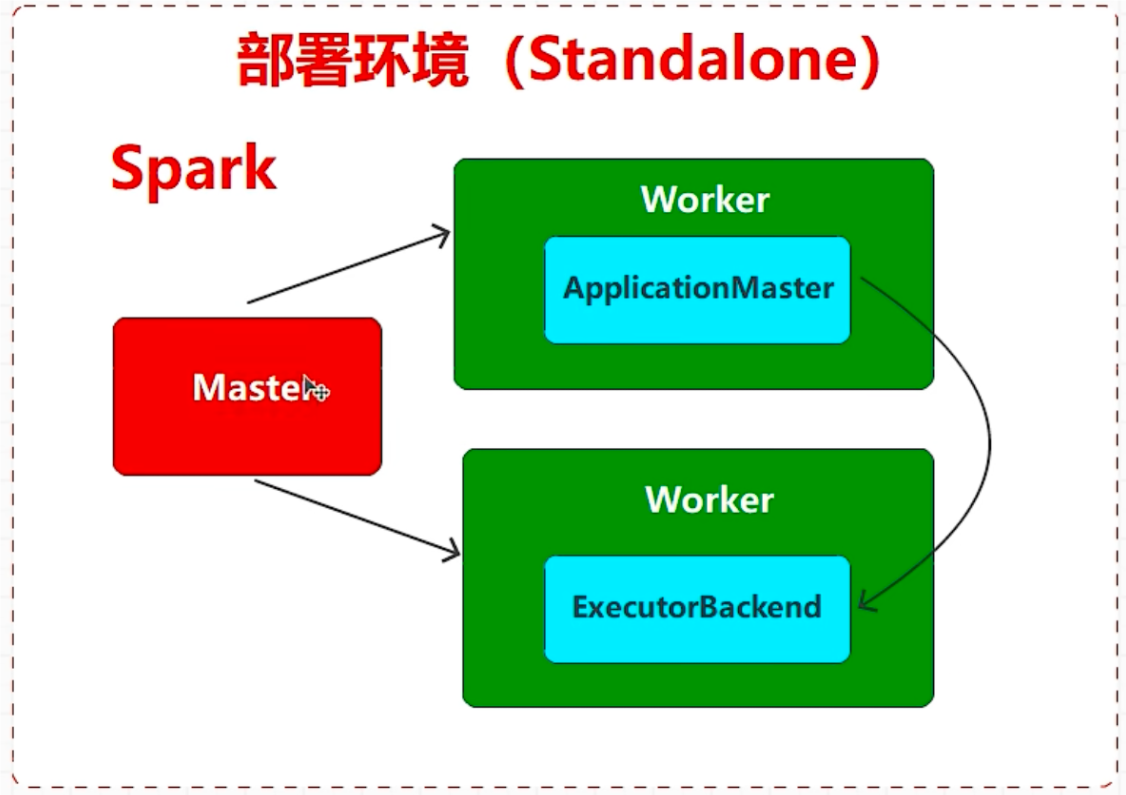
如果资源是由 Spark 提供的,那么就称之为 Spark 部署环境 (Standalone
生产环境中主要采用:yarn+spark 也称之为(spark on yarna)
(1) Local 模式:在本地部署单个 Spark 服务
(2) Standalone 模式:Spark 自带的任务调度模式。(国内不常用)
(3) YARN 模式:Spark 使用 Hadoop 的 YARN 组件进行资源与任务调度。(国内最常用)
(4) Mesos 模式:Spark 使用 Mesos 平台进行资源与任务的调度。(国内很少用)
# 部署 local1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 wget https: tar xzvf spark-3.4 .3 -bin-hadoop3.tgz bin/spark-submit --class org .apache.spark.examples.SparkPi --master local[2 ] ./examples/jars/spark-examples_2.12 -3.4 .3 .jar 10 --master 指定资源提供者 local 单线程 local[2 ] 两个线程执行 local[*] 使用全部核 24 /06 /12 08:09:06 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38 , took 1.055199 sPi is roughly 3.1425071142507113 24 /06 /12 08:09:06 INFO SparkContext: SparkContext is stopping with exitCode 0. 24 /06 /12 08:09:06 INFO SparkUI: Stopped Spark web UI at http:24 /06 /12 08:09:06 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!24 /06 /12 08:09:06 INFO MemoryStore: MemoryStore cleared24 /06 /12 08:09:06 INFO BlockManager: BlockManager stopped24 /06 /12 08:09:06 INFO BlockManagerMaster: BlockManagerMaster stopped24 /06 /12 08:09:06 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!24 /06 /12 08:09:06 INFO SparkContext: Successfully stopped SparkContext24 /06 /12 08:09:06 INFO ShutdownHookManager: Shutdown hook called
Spark 在运行时,会启动进程,申请资源,执行计算,但是一旦计算完毕,那么进程会停止,资源会释放掉
Stopped Spark web UI at http://hadoop100:4040
# yarn 模式编辑启动关闭脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #!/bin/bash echo "========hadoop100==========" ssh root@hadoop100 "/root/jdk8u352-b08/bin/jps" echo "========hadoop101==========" ssh root@hadoop101 "jps" echo "========hadoop102==========" ssh root@hadoop102 "jps" #!/bin/bash ssh root@hadoop100 "source /root/admin-openrc;/root/hadoop-3.3.6/sbin/start-dfs.sh" ssh root@hadoop101 "source /root/admin-openrc;/root/hadoop-3.3.6/sbin/start-yarn.sh" ssh root@hadoop100 "source /root/admin-openrc;/root/hadoop-3.3.6/bin/mapred --daemon start historyserver" #!/bin/bash ssh root@hadoop100 "source /root/admin-openrc;/root/hadoop-3.3.6/bin/mapred --daemon stop historyserver" ssh root@hadoop101 "source /root/admin-openrc;/root/hadoop-3.3.6/sbin/stop-yarn.sh" ssh root@hadoop100 "source /root/admin-openrc;/root/hadoop-3.3.6/sbin/stop-dfs.sh" vim spark-env.sh YARN_CONF_DIR=/root/hadoop-3.3 .6 /etc/hadoop/ hadoop-start.sh bin/spark-submit --class org .apache.spark.examples.SparkPi --master yarn ./examples/jars/spark-examples_2.12 -3.4 .3 .jar 10 root@hadoop100 :~# jpsall ========hadoop100========== 42388 DataNode42683 NodeManager43820 Jps42894 JobHistoryServer43583 SparkSubmit42191 NameNode========hadoop101========== 37904 Jps37169 NodeManager36818 ResourceManager36610 DataNode37843 YarnCoarseGrainedExecutorBackend37721 ExecutorLauncher========hadoop102========== 37362 DataNode37509 SecondaryNameNode37626 NodeManager38093 Jps
配置历史服务
1 2 3 4 5 6 7 8 9 10 11 vim spark-defaults.conf spark.eventLog.enabled true spark.eventLog.dir hdfs: vim spark-env.sh export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://hadoop100:8020/directory -Dspark.history.retainedApplications=30" vim spark-defaults.conf spark.yarn.historyServer.address=hadoop100:18080 spark.history.ui.port=18080
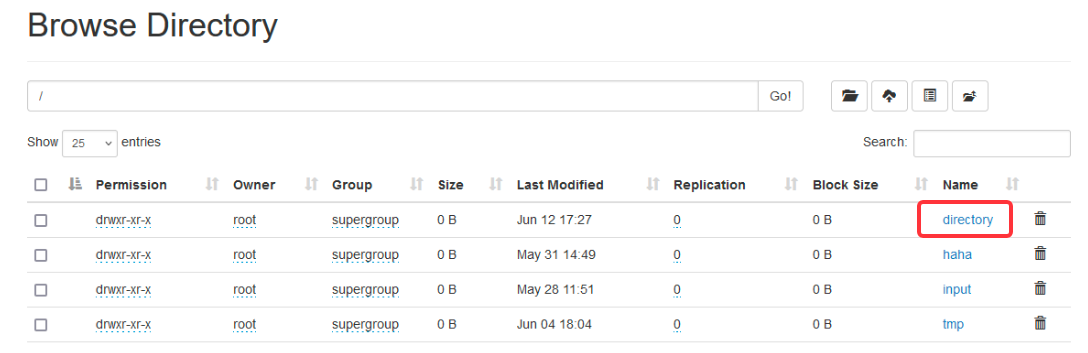
hdfs 中创建 /directory
1 2 3 4 5 6 sbin/start-history-server.sh bin/spark-submit --class org .apache.spark.examples.SparkPi --master yarn ./examples/jars/spark-examples_2.12 -3.4 .3 .jar 10 将spark历史记录保存到了hadoop history中
运行时,会将 yarn 需要用到的 lib 和 conf 上传到 hdfs 中
1 2 24 /06 /14 06 :32 :57 INFO Client: Uploading resource file:/tmp/spark-4dbf287c-9986 -44f0-89c1-7ede052800c0/__spark_libs__5882056198812431005.zip -> hdfs:24 /06 /14 06 :32 :58 INFO Client: Uploading resource file:/tmp/spark-4dbf287c-9986 -44f0-89c1-7ede052800c0/__spark_conf__3646583648306474590.zip -> hdfs:
运行结束会删除文件
1 2 24 /06 /14 06 :33 :07 INFO ShutdownHookManager: Deleting directory /tmp/spark-f3d8debb-7304 -4251 -b80b-11b1ab91f45c24 /06 /14 06 :33 :07 INFO ShutdownHookManager: Deleting directory /tmp/spark-4dbf287c-9986 -44f0-89c1-7ede052800c0
yarn 模式中有 client 和 cluster 模式,主要区别在于:Driver 程序的运行节点。
yarn-client:Driver 程序运行在客户端,适用于交互、调试,希望立即看到 Japp 的输出。
yarn-cluster:Driver 程序运行在由 ResourceManager 启动的 APPIMaster, 适用于生产环境。
默认使用的客户端模式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # 使用cluster模式 bin/spark-submit --class org .apache.spark.examples.SparkPi --master yarn --deploy-mode cluster ./examples/jars/spark-examples_2.12 -3.4 .3 .jar 10 ========hadoop100========== 42388 DataNode51081 Jps42683 NodeManager44508 HistoryServer42894 JobHistoryServer50959 SparkSubmit42191 NameNode========hadoop101========== 37169 NodeManager36818 ResourceManager36610 DataNode40596 Jps========hadoop102========== 37362 DataNode37509 SecondaryNameNode42121 Jps37626 NodeManager41995 ApplicationMaster
# standalone 模式Standalone 模式是 Spark 自带的资源调度引擎,构建一个由 Master+VVorker 构成的 Spark 集群,Spark 运行在集群中。
这个要和 Hadoop 中的 Standalone 区别开来。这里的 Standalone 是指只用 Spark 来搭建一个集群,不需要借助 Hadoop 的 Yarn 和 Mesos 等其他框架。
# mesos 模式Spark 客户端直接连接 Mesos; 不需要额外构建 Spark 集群。国内应用比较少,更多的是运用 Yarn 调度。
# 模式对比
# 端口号1) Spark 查看当前 Spark-shell 运行任务情况端口号:4040
2) Spark 历史服务器端口号:18080 (类比于 Hadoop 历史服务器端口号:19888)
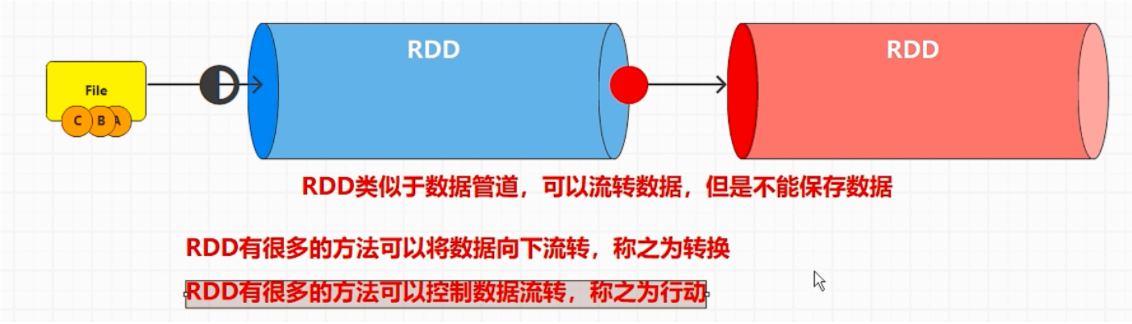
# rddRDD: 分布式计算模型
1. 一定是一个对象
2. 一定封装了大量方法和属性
3. 一定需要适合进行分布式处理 (减小数据规模,并行计算算)
# RDD 编程在 Spark 中创建 RDD 的创建方式可以分为三种:从集合中创建] RDD、从外部存储创建 RDD、从其他 RDD 创建。
RDD 的处理方式和 JavalO 流完全一样,也采用装饰者设计式来实现功能的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12 </artifactId> <version>3.3 .1 </version> </dependency> </dependencies> package org.example;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaSparkContext;public class Main { public static void main (String[] args) { System.out.println("Hello world!" ); SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); javaSparkContext.close(); } }
# 对接内存数据构建 RDD 对象parallelize 方法可以传递参数:集合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 package org.example ; import org.apache .spark .SparkConf ;import org.apache .spark .api .java .JavaRDD ;import org.apache .spark .api .java .JavaSparkContext ;import java.util .Arrays ;import java.util .List ;public class Main { public static void main (String [] args System .out .println ("Hello world!" ); SparkConf sparkConf = new SparkConf (); sparkConf.setMaster ("local" ); sparkConf.setAppName ("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); List <String > names = Arrays .asList ("zhangsan" , "lisi" ); JavaRDD <String > rdd = javaSparkContext.parallelize (names); List <String > collect = rdd.collect (); collect.forEach (System .out ::println); javaSparkContext.close (); } }
# 对接磁盘数据1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class Main1 { public static void main (String [] args System .out .println ("Hello world!" ); SparkConf sparkConf = new SparkConf (); sparkConf.setMaster ("local" ); sparkConf.setAppName ("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); JavaRDD <String > stringJavaRDD = javaSparkContext.textFile ("C:\\Users\\Administrator\\IdeaProjects\\MapReduceDemo\\data\\text" ); List <String > collect = stringJavaRDD.collect (); collect.forEach (System .out ::println); javaSparkContext.close (); } }
# 磁盘数据分区1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class partition { public static void main (String[] args) { System.out.println("Hello world!" ); SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); JavaRDD<String> stringJavaRDD = javaSparkContext.textFile("data\\text" ); stringJavaRDD.saveAsTextFile("output1222" ); javaSparkContext.close(); } }
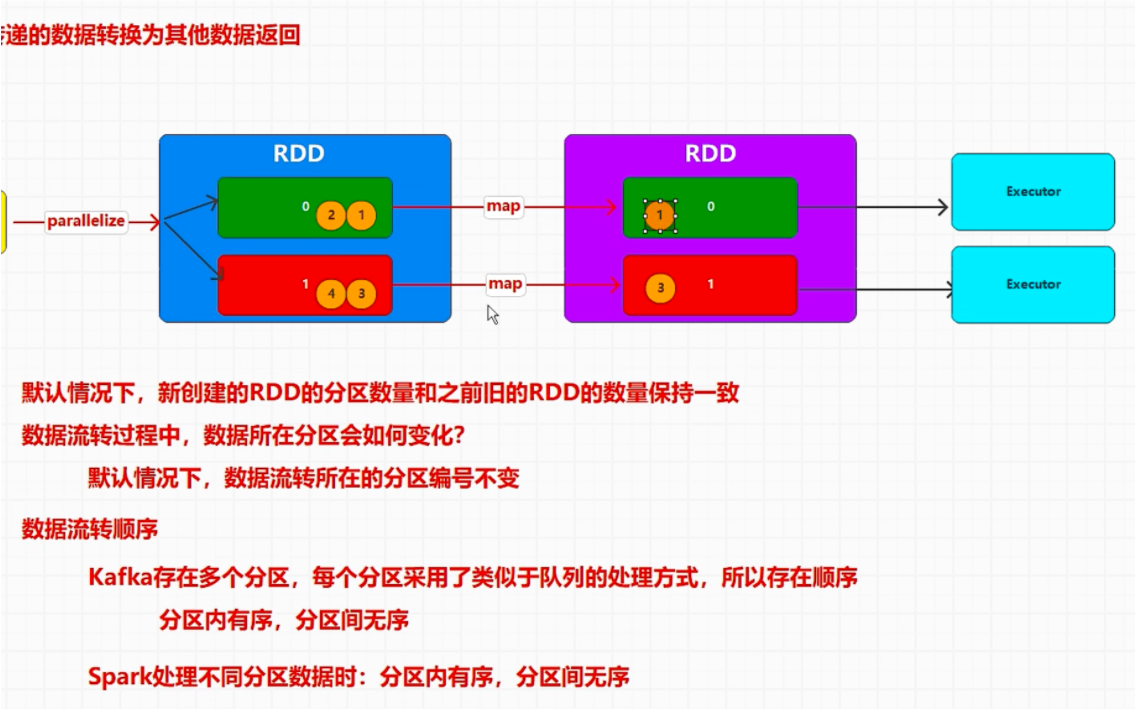
# 内存数据源,分区数据分配 数据分配方式 (i*length)/numSlices,(((i + 1) * 1) * length) /numSlices)
# 磁盘数据源Spark 不支持文件操作的。文件操作都是由 Hadoop 完成的
Hadoop 进行文件切片数量的计算和文件数据存储计算规则不样
1. 分区数量计算的时候,考虑的是尽可能的平均:按字节来计算
2. 分区数据的存储是考虑业务数据的完整性:按照行来读取
读取数据时,还需要考虑数据偏移量,偏移量从 0 开始的。
读取数据时,相同的偏移量不能重复读取。
使用 spark 时,数据不能全放一行,会造成数据倾斜
# map
1 2 3 4 5 6 7 8 9 10 11 12 13 Scala 语言中可以将无关的数据封装在一起,形成一个整体,称之为元素的组合,简称为【元组】如果想要访问元组中的数据,必须采用顺序号 var kv1 = ("haha" ,1 ,2 ) JDK1 .8 以后也存在元组,采用特殊的类:TupleX Tuple2 <String ,String > tuple2 = new Tuple2 <>("abc" , "1" ); System .out.println(tuple2._1); System .out.println(tuple2._2()); tuple中最大容量为22 使用时可以 ._1 也可以 ._1()
# 函数式编程1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package org.example.rdd;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaSparkContext;import java.util.Arrays;public class operator3 { public static void main (String[] args) { SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); javaSparkContext.parallelize(Arrays.asList(1 ,2 ,3 ,4 ),2 ).map(NumberTest::mul2).collect().forEach(System.out::println); } } class NumberTest { public static int mul2 (Integer num2) { return num2 *= 2 ; } }
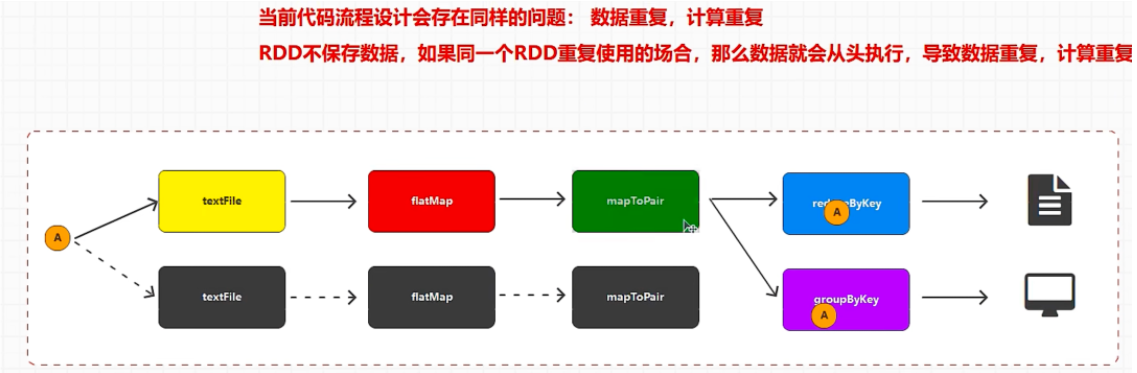
RDD 不会保存数据,不会等每一个 rdd 执行完再执行下一个
# filter1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class filter { public static void main (String[] args) { SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); JavaRDD<Integer> parallelize111 = javaSparkContext.parallelize(Arrays.asList(1 , 2 , 3 ),2 ); JavaRDD<Integer> filterrdd = parallelize111.filter( num -> true ); filterrdd.collect().forEach(System.out::println); javaSparkContext.close(); } }
# flatmap数据扁平化,扁平映射(整体变为个体)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 public class flatmap { public static void main (String[] args) { SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); JavaRDD<List<Integer>> parallelizerdd = javaSparkContext.parallelize(Arrays.asList(Arrays.asList(1 , 2 ), Arrays.asList(3 , 4 )), 2 ); JavaRDD<Integer> integerJavaRDD = parallelizerdd.flatMap(new FlatMapFunction <List<Integer>, Integer>() { @Override public Iterator<Integer> call (List<Integer> integers) throws Exception { List<Integer> objectArrayList = new ArrayList <>(); integers.forEach(num -> objectArrayList.add(num * 2 )); return objectArrayList.iterator(); } } ); integerJavaRDD.collect().forEach(System.out::println); javaSparkContext.close(); } } data/text: hadoop python java php golang B V D public class flatmap { public static void main (String[] args) { SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); JavaRDD<List<Integer>> parallelizerdd = javaSparkContext.parallelize(Arrays.asList(Arrays.asList(1 , 2 ), Arrays.asList(3 , 4 )), 2 ); JavaRDD<String> stringJavaRDD = javaSparkContext.textFile("data/text" ); JavaRDD<String> stringJavaRDD1 = stringJavaRDD.flatMap( line -> Arrays.asList(line.split(" " )).iterator() ); stringJavaRDD1.collect().forEach(System.out::println); javaSparkContext.close(); } }
# groupby1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class groupby { public static void main (String[] args) { SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); JavaRDD <Integer> parallelizerdd = javaSparkContext.parallelize(Arrays.asList(1 , 2 , 4 ,6 ), 2 ); parallelizerdd.groupBy(num -> num % 2 == 0 ).collect().forEach(System.out::println); javaSparkContext.close(); }
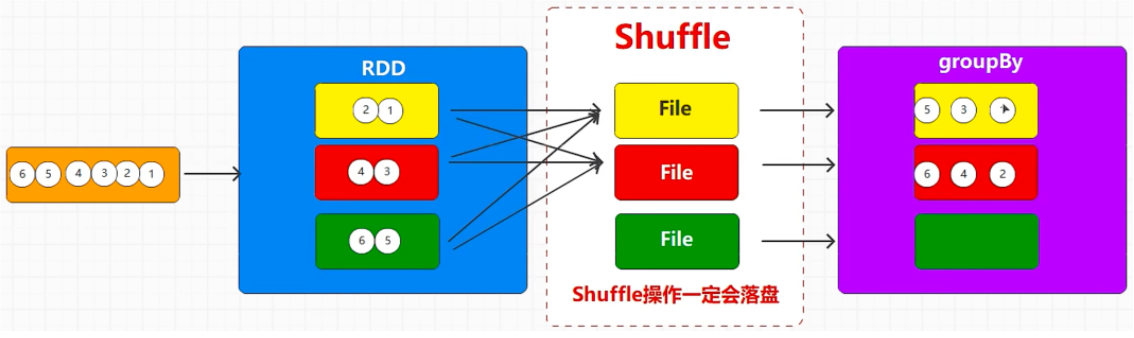
# shuffle默认情况下,数据处理后,所在的分区不会发生变化,但是 groupBy 方法例外
Spark 在数据处理中,要求同一个组的数据必须在同一个分区中
所以分组操作会将数据分区打乱重新组合,在 spark 中称为 shuffle
一个分区可以存放多个组,,所有数据必须分组后才能继续执行操作
RDD 对象不能保存数据,当前 groupBy 操作会将数据保存到磁盘文件中,保证数据全部分组后执行后续操作
shuffle 操作一定会落盘
shuffle 操作有可能会导致资源浪费
Spark 中含有 shuffle 操作的方法都有改变分区的能力
RDD 的分区和 task 有关系
1 2 3 4 5 6 7 8 9 10 11 12 public class groupby2 { public static void main (String[] args) throws InterruptedException { SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local[*]" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); JavaRDD <Integer> parallelizerdd = javaSparkContext.parallelize(Arrays.asList(1 , 2 , 4 ,6 , 7 , 8 ), 3 ); parallelizerdd.groupBy(num -> num % 2 == 0 ,2 ).collect().forEach(System.out::println); Thread.sleep(100000L ); javaSparkContext.close(); } }
shuffle 会将完整的计算流程一分为二,其中一部分任务会写磁盘,另外一部分的任务会读磁盘
写磁盘的操作不完成,不允许读磁盘
# distincthashset 是单点去重
distinct 是分布式去重,采用分组 + shuffle 方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class distinct { public static void main (String[] args) throws InterruptedException { SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local[*]" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); JavaRDD <Integer> parallelizerdd = javaSparkContext.parallelize(Arrays.asList(1 , 2 , 4 ,6 , 7 , 8 , 1 , 2 ), 3 ); parallelizerdd.distinct().collect().forEach(System.out::println); javaSparkContext.close(); } }
# sortby按照指定规则排序
第一个参数表示排序规则
Spark 会为每一个数据增加一个标记,然后按照标记对数据进行排序
第二个参数表示排序的方式:升序 (true), 降序 (false)
第三个参数表示分区数量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class sortby { public static void main (String[] args) throws InterruptedException { SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local[*]" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); JavaRDD <Integer> parallelizerdd = javaSparkContext.parallelize(Arrays.asList(12 , 52 , 4 ,6 , 7 , 8 , 1 , 2 ), 3 ); parallelizerdd.saveAsTextFile("sort222" ); parallelizerdd.sortBy(new Function <Integer, Object>() { @Override public Object call (Integer integerssss) throws Exception { return integerssss; } },true ,2 ) .saveAsTextFile("sort333" ); javaSparkContext.close(); } }
return “”+integerssss; // 按照字典排序
# coalesce缩减分区
coalesce 方法默认没有 shuffle 功能,所以数据不会被打击乱重新组合,所以如果要扩大分区是无法实现的
1 filterrdd.coalesce(3 ,true );
# repartition重分区,就是设定 shuffle=true 的 coalesce 方法
1 filterrdd.repartition(3 )
# kvSpark RDD 会整体数据的处理就称之为单值类型的数据处理
Spark RDD 会 KV 数据个体的处理就称之为 KV 类型的数据处理:K 和 V 不作为整体使用
mapValues 方法只对 V 进行处理,K 不做任何操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class kv { public static void main (String[] args) throws InterruptedException { SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local[*]" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); Tuple2<String, Integer> a = new Tuple2 <>("a" , 1 ); Tuple2<String, Integer> b = new Tuple2 <>("b" , 2 ); List<Tuple2<String, Integer>> list = Arrays.asList(a, b); JavaPairRDD<String, Integer> parallelized = javaSparkContext.parallelizePairs(list); parallelized.mapValues(num -> num*2 ).collect().forEach(System.out::println); javaSparkContext.close(); } } public class kv2 { public static void main (String[] args) throws InterruptedException { SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local[*]" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); List<Integer> integerList = Arrays.asList(1 , 2 , 3 , 4 ); JavaRDD<Integer> integerJavaRDD = javaSparkContext.parallelize(integerList); integerJavaRDD.mapToPair( num -> new Tuple2 <>(num, num*2 ) ).collect().forEach(System.out::println); javaSparkContext.close(); } }
# mapvalue# groupbykey1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class kv3_groupbykey { public static void main (String[] args) throws InterruptedException { SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local[*]" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); javaSparkContext.parallelizePairs((Arrays.asList(new Tuple2 <>("a" , 1 ), new Tuple2 <>("b" , 2 ), new Tuple2 <>("a" , 3 ), new Tuple2 <>("b" , 4 )))).groupByKey().collect().forEach(System.out::println); javaSparkContext.close(); } }
groupby 底层调用 greoupbykey
groupbykey 有 shuffle
# reducebykeyreduceByKey 方法的作用:将 KV 类型的数据按照 K 对 V 进行 reduce (将多个值聚合成 1 个值) 操作
基本思想:两两计算
1 JavaPairRDD<String ,Integer> wordcountrdd = parallelized.reduceByKey(Integer::sum);
# sortbykeygroupByKey : 按照 K 对 V 进行分组
reduceByKey 按照 K 对进行两两聚合
sortByKey 按照 K 排序
1 JavaPairRDD<String ,Integer> sortrdd = parallelized.sortByKey();
# RDD 行动算子RDD 的行动算子会触发作业 (Job) 的执行
转换算子的目的:将旧的 RDD 转换成新的 RDD, 为了组合多个 RDD 的功能
返回值是 rdd,是转换算子。具体值是行动算子
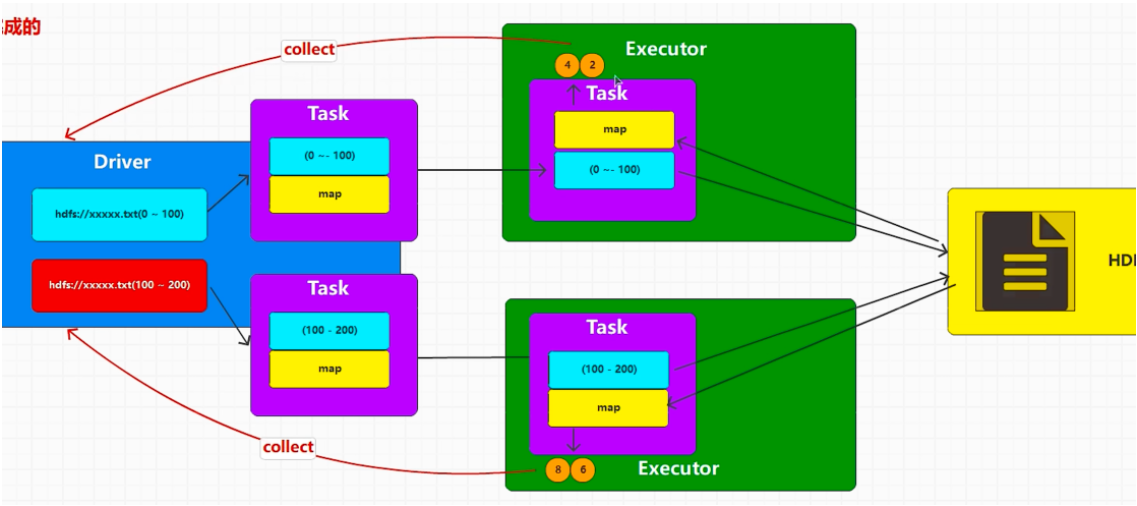
collect 将 executor 执行的结果按照分区的数据拉取回到 driver,将结果组合成集合对象
1 2 3 4 JavaRDD<Integer> integerJavaRDD = parallelize111.map(num -> num * 2 ); List<Integer> collect = integerJavaRDD.collect(); collect.forEach(System.out::println);
Spark 在编写代码时,调用转换算子,并不会真正执行,因为只是在 Driver 端组合功能
所以当前的代码其实就是在 Driver 端执行
所以当前 main 方法也称之为 driver 方法,当前运行 main 纟我程,也称之 Driver 线程
转换算子中的逻辑代码是在 Executor 端执行的。并不会在 tDriver 端调用和执行。
RDD 封装的逻辑其实就是转换算子中的逻辑
集合数据
文件:读取切片
collect 方法就是将 Executor 端执行的结果按照分区的顺序位取 (采集) 回到 Driver 端,将结果组合成集合对象
collect 方法可能会导致多个 Executor 的大量数据拉取到 Driiver 端,导致内存溢出,所以生成环境慎用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 JavaRDD<Integer> parallelize111 = javaSparkContext.parallelize(Arrays.asList(1 , 2 , 3 , 4 ),2 ); JavaRDD<Integer> integerJavaRDD = parallelize111.map(num -> num * 2 ); List<Integer> collect = integerJavaRDD.collect(); collect.forEach(System.out::println); long count = integerJavaRDD.count(); Integer first = integerJavaRDD.first(); List<Integer> take = integerJavaRDD.take(3 ); JavaPairRDD<Integer, Integer> integerIntegerJavaPairRDD = parallelize111.mapToPair(num -> new Tuple2 <>(num, num)); Map<Integer, Long> integerLongMap = integerIntegerJavaPairRDD.countByKey(); integerIntegerJavaPairRDD.saveAsTextFile("a" ); integerIntegerJavaPairRDD.saveAsObjectFile("bb" ); parallelize111.collect().forEach(System.out::println); parallelize111.foreach( System.out::println ); parallelize111.foreachPartition(System.out::println); javaSparkContext.close();
main 方法也叫 driver 方法,foreach 是在 executor 执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class action_serialize { public static void main (String[] args) { SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); JavaRDD<Integer> parallelize111 = javaSparkContext.parallelize(Arrays.asList(1 , 2 , 3 , 4 ), 2 ); Student1 s = new Student1 (); parallelize111.foreach( num -> { System.out.println(s.age + num); } ); javaSparkContext.close(); } } class Student1 implements Serializable { public int age = 30 ; }
Student 想 new ,得在 executor 上拉取
在 Executor 端循环遍历的时候使用到了 Driver 端对象
运行过程中,就需要将 Driver 端的对象通过网络传递到 Executor 端,否则无法使用
传输的对象必须要实现可序列化接口,否则无法传递
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 JavaRDD<String> parallelize111 = javaSparkContext.parallelize(Arrays.asList("haha" ,"Haha" ), 2 ); Search search = new Search ("H" ); search.match(parallelize111); javaSparkContext.close(); } } class Search implements Serializable { private String query; public Search (String query) { this .query = query; } public void match (JavaRDD<String> rdd) { rdd.filter( s -> s.startsWith(query) ).collect().forEach(System.out::println); } }
rdd 算子 (方法) 的逻辑代码是在 executo 执行的,其他的是在 driver 执行的
collect 是行动算子,没有逻辑代码
filter 中的成为逻辑代码
1 2 3 4 5 6 7 8 9 10 11 12 parallelize111.foreach( System.out::println );
# kryoSpark 出于性能的考虑,Spark2.0 开始支持另外一种 Kryo 序列化机制。Kryo 速度是 Serializable 的 10 倍。当 RDD 在 Shuffle 数据的时候,简单数据类型、数组和字符串类型已经在 Spark 内部使用 Kryo 来序列化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 <dependency> <groupId>com.esotericsoftware</groupId> <artifactId>kryo</artifactId> <version>5.0 .3 </version> </dependency> import com.atguigu.bean.User;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.Function; import java.util.Arrays; public class Test02_Kryo { public static void main (String[] args) throws ClassNotFoundException { SparkConf conf = new SparkConf ().setMaster("local[*]" ).setAppName("sparkCore" ) .set("spark.serializer" , "org.apache.spark.serializer.KryoSerializer" ) .registerKryoClasses(new Class []{Class.forName("com.atguigu.bean.User" )}); JavaSparkContext sc = new JavaSparkContext (conf); User zhangsan = new User ("zhangsan" , 13 ); User lisi = new User ("lisi" , 13 ); JavaRDD<User> userJavaRDD = sc.parallelize(Arrays.asList(zhangsan, lisi), 2 ); JavaRDD<User> mapRDD = userJavaRDD.map(new Function <User, User>() { @Override public User call (User v1) throws Exception { return new User (v1.getName(), v1.getAge() + 1 ); } }); mapRDD. collect().forEach(System.out::println); sc.stop(); } }
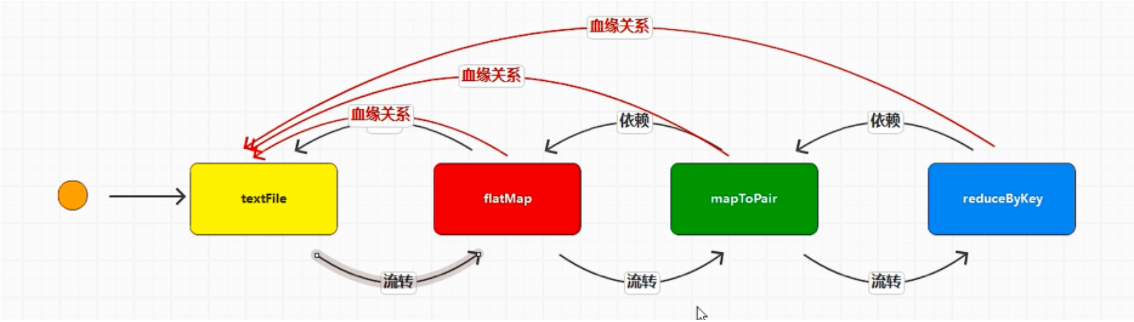
# 依赖RDD 转换算子 (方法):RDD 可以通过方法将旧的 RDD 转换成新的 RDD
RDD 依赖:Spark 中相邻的 2 个 RDD 之间存在的依赖关系
连续的依赖关系称为血缘关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public class flatmap { public static void main (String[] args) { SparkConf sparkConf = new SparkConf (); sparkConf.setMaster("local" ); sparkConf.setAppName("spark" ); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf); JavaRDD<String> stringJavaRDD = javaSparkContext.textFile("data/text" ); System.out.println(stringJavaRDD.toDebugString()); System.out.println("============" ); JavaRDD<String> stringJavaRDD1 = stringJavaRDD.flatMap( line -> Arrays.asList(line.split(" " )).iterator() ); System.out.println(stringJavaRDD1.toDebugString()); stringJavaRDD1.collect().forEach(System.out::println); javaSparkContext.close(); } } (1 ) data/text MapPartitionsRDD[1 ] at textFile at flatmap.java:20 [] | data/text HadoopRDD[0 ] at textFile at flatmap.java:20 [] ============ (1 ) MapPartitionsRDD[2 ] at flatMap at flatmap.java:23 [] | data/text MapPartitionsRDD[1 ] at textFile at flatmap.java:20 [] | data/text HadoopRDD[0 ] at textFile at flatmap.java:20 [] shuffle +- 代表两段流程 JavaRDD<String> stringJavaRDD = javaSparkContext.textFile("data/text" ); System.out.println(stringJavaRDD.rdd().dependencies()); System.out.println("============" ); JavaRDD<String> stringJavaRDD1 = stringJavaRDD.flatMap( line -> Arrays.asList(line.split(" " )).iterator() ); System.out.println(stringJavaRDD1.rdd().dependencies()); stringJavaRDD1.groupBy(num -> num); System.out.println(stringJavaRDD1.rdd().dependencies()); stringJavaRDD1.collect().forEach(System.out::println); javaSparkContext.close(); List(org.apache.spark.OneToOneDependency@4b5a078a) ============ List(org.apache.spark.OneToOneDependency@33f2df51) 24 /06 /25 17 :16 :52 INFO FileInputFormat: Total input files to process : 1 List(org.apache.spark.OneToOneDependency@33f2df51)
onetoonedep 窄依赖
shuffledep 宽依赖
rdd 的依赖关系是 rdd 对象中分区数据的关系
窄依赖:如果上游 rdd 一个分区的数据被下游 rdd 的一个分区独享
宽依赖:如果上游 rdd 一个分区的数据被下游 rdd 的多个分区共享。会将分区数据打乱重新组合,所以此层存在 shuffle 操作
依赖关系和任务数量,阶段数量
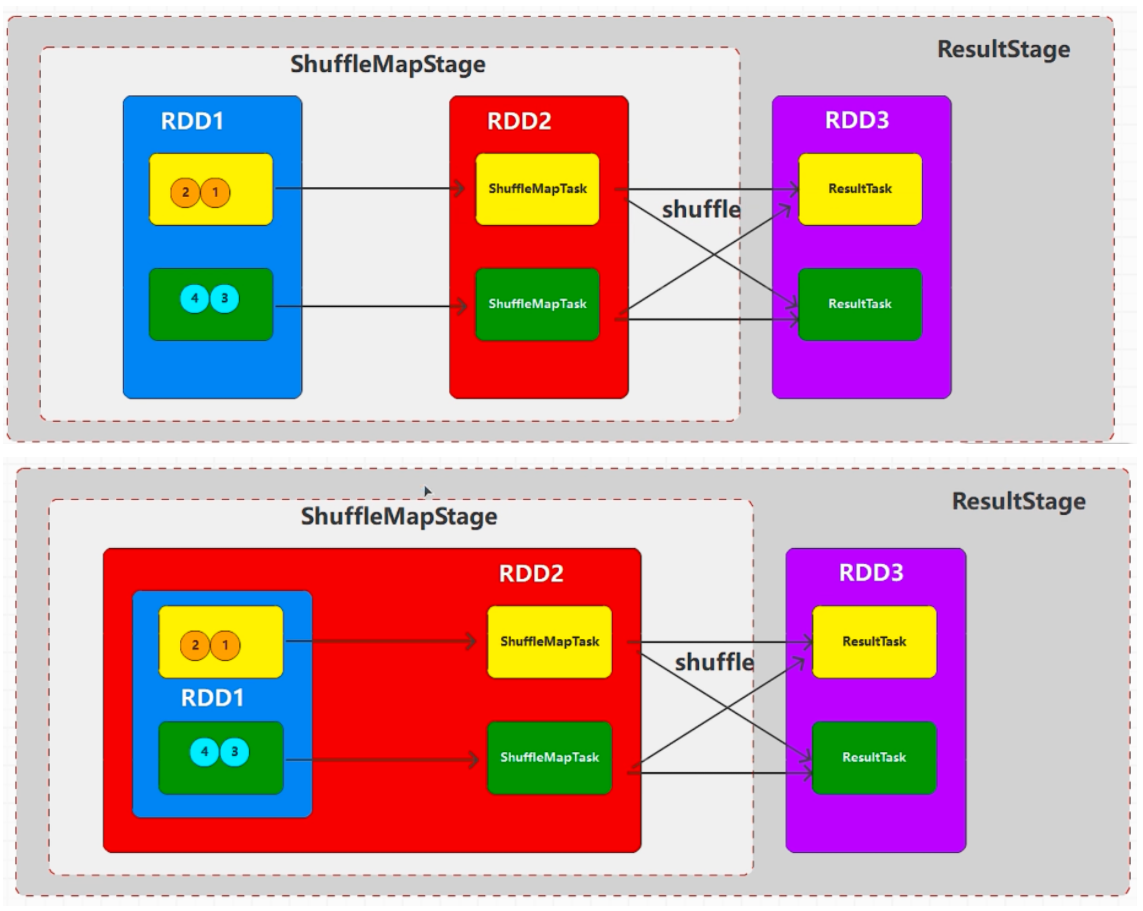
作业 (Job): 行动算子执行时,会触发作业的执行 (ActiveJob)
阶段 (Stage): 一个 job 中 RDD 的计算流程,默认就一个完整的阶段,但是如果计算流程中存在 shuffle, 那么流程就会一分为二。分开的每一段就称之为 stage,前一个阶段不执行完,后一个阶段不允许执行
任务 (Task): 每个 Executor 执行的计算单元
阶段的数量和 shuffle 依赖的数量有关系:1+shuffle 依赖的数量
任务(分区)的数量就是每个阶段分区的数量之和,一般推荐分区数量为资源核数的 2-3 倍
任务 (Task): 每个 Executor 执行的计算单元
任务的数量其实就是每个阶段最后一个 RDD 分区的数量之和
移动数据不如移动计算
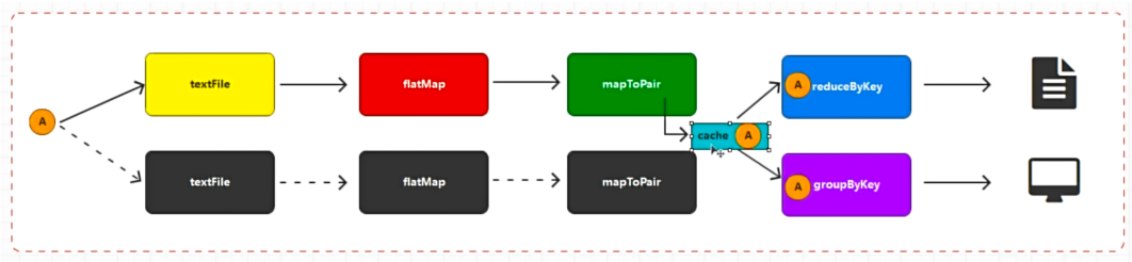
# 持久化持久化:将对象长时间的保存
序列化:内存中对象 =>byte 序列 (byte 数组)
maprdd.cache();
maprdd.persist(Storage.MEMORY_ONLY());
cache 方法底层调用 persist. maprdd.persist (Storage.MEMORY_ONLY ()); === cache ()
// 落盘持久化
maprdd.persist(Storage.DISK_ONLY());
MEMORY_ONLY 超出数据直接丢弃
MEMORY_AND_DISK. 内存满了放磁盘
MEMORY_ONLY_SER 序列化后再存内存
MEMORY_ONLY_SER_2. 副本 2 份
# checkpoint将计算结果保存到 hdfs 或者本地文件路径,实现不同进程共享
1 2 3 4 5 JavaSparkContext javaSparkContext = new JavaSparkContext (sparkConf);javaSparkContext.setCheckpointDir("cp" ); mapRDD.cache(); mapRDD.checkPoint();
检查点目的是 rdd 结果长时间保存,所以需要保证数据安全,会从头再跑一遍。把第二遍结果放到里面
性能比较低,可以在检查点之前执行 cache,将数据缓存
cache 方法会在血缘关系中增加依赖关系
checkpoint 方法改变血缘关系
每个 shuffle 都自动带有缓存,为了提高 shuffle 算子的性能
如果重复调用相同规则的 shuffle 算子,第二个 shfulle 算子不会有相同 shuffle 操作
使用完缓存,可以使用 unpersist 释放缓存
# 分区器数据分区的规则
计算后数据所在的分区是通过 Spark 的内部计算 (分区) 完成我。尽可能均衡一些(hash)
reducebykey 需要传递两个参数,第一个参数是数据分区的规则,第二个参数是数据聚合逻辑
第一个参数可以不用传递,使用时会使用默认分区规则。默认分区规则中使用 HashPartitioner
hashpartitioner 中有一个方法叫 getpartition,需要传递一个参数 key,返回一个值,表示分区编号,从 0 开始
得到一个分区编号,key.hashcode % partnum (hash 取余)
只有 kv 类型的有分区器
rdd.partitioner()
Spark 目前支持 Hash 分区、Range 分区和用户自定义分区。Hash 分区为当前的默认分区。分区器直接决定了 RDD 中分区的个数、RDD 中每条数据经过 Shuffle 后进入哪个分区和 Reduce 的个数。
自定义分区器
1. 创建自定义类
2. 继承抽象类 Partitioner
3. 重写方法 (2)
4. 构建对象,在算子中使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 class Part extends Partitioner { @Override public int numPartitions () { return 3 ; } @Override public int getPartition (Object key) { if ("a" .equals(key)) return 0 ; else if ("b" .equals(key)) { return 1 ; } else { return 2 ; } } } mapRDD.reduceByKey(new Part (),Integer::sum) class Part extends Partitioner { private int numPart; public Part (int num) { this .numPart = num; } @Override public int numPartitions () { return 3 ; } @Override public int getPartition (Object key) { if ("a" .equals(key)) return 0 ; else if ("b" .equals(key)) { return 1 ; } else { return 2 ; } } @Override public int hashCode () { return numPart; } @Override public boolean equals (Object obj) { if (obj instanceof Part) { Part other = (Part)obj; return this .numPart == other.numPart; } else { return false ; } } }
RDD 在 foreach 循环时,逻辑代码和操作全部都是在 Executor 端完成的,那么结果不会拉取回到 Driver 端
RDD 无法实现数据拉取操作
如果 Executor 端使用了 Driver 端数据,那么需要从 Driver 端将数据拉取到 Executor 端
数据拉取的单位是 Task (任务)
默认数据传输以 Task 为单位进行传输,如果想要以 Executor 为单位传输,那么需要进行包装 (封装)
Spark 需要采用特殊的数据模型实现数据传输:广播变量
jsc.broadcast(list);
rdd.filter(s -> broadcast.value())
# sparksqlSpark SQL: 结构化数据处理模块
SQL: 为了数据库数据访问开发的语言
Spark 封装模块的目的就是在结构化数据的场合,处理起来方便
结构化数据:特殊结构的数据 =>(table,json)
半结构化数据:xml,html
非结构化数据:压缩文件,图形文件,视频,音频文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12 </artifactId> <version>3.3 .1 </version> </dependency> public class envv { public static void main (String[] args) { final SparkSession sparkSession = SparkSession.builder().master("local" ).appName("sparkSQL" ).getOrCreate(); sparkSession.close(); } } public static void main (String[] args) { final SparkSession sparkSession = SparkSession.builder().master("local" ).appName("sparkSQL" ).getOrCreate(); Dataset<Row> rowDataset = sparkSession.read().json("data/user.json" ); rowDataset.createOrReplaceTempView("user" ); String sql = "select avg(age) from user" ; Dataset<Row> rowDataset1 = sparkSession.sql(sql); rowDataset1.show(); sparkSession.close(); }
# 环境之间转换1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 new sparkSession ( new SparkContect (conf));sparksession.sparkContext().parallelize(); SparkContext sparkContext = sparkSession.sparkContext(); JavaSparkContext javaSparkContext = new JavaSparkContext (sparkContext); javaSparkContext.parallelize(Arrays.asList(1 ,2 ,3 ,4 )); public static void main (String[] args) { final SparkSession sparkSession = SparkSession.builder().master("local" ).appName("sparkSQL" ).getOrCreate(); Dataset<Row> rowDataset = sparkSession.read().json("data/user.json" ); Dataset<User> userDataset = rowDataset.as(Encoders.bean(User.class)); userDataset.foreach( user -> { System.out.println(user.getname()); } ); sparkSession.close(); } } class User implements Serializable { private int id; private int age; private String name; User(int id, int age, String name) { this .id = id; this .age = age; this .name = name; } } public class model { public static void main (String[] args) { final SparkSession sparkSession = SparkSession.builder().master("local" ).appName("sparkSQL" ).getOrCreate(); Dataset<Row> rowDataset = sparkSession.read().json("data/user.json" ); rowDataset.createOrReplaceTempView("user" ); sparkSession.sql("select * from user" ).show(); sparkSession.close(); } } public class model2 { public static void main (String[] args) { final SparkSession sparkSession = SparkSession.builder().master("local" ).appName("sparkSQL" ).getOrCreate(); Dataset<Row> rowDataset = sparkSession.read().json("data/user.json" ); rowDataset.select("*" ).show(); sparkSession.close(); } }
# 自定义 UDF1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 public class sql_3 { public static void main (String[] args) { final SparkSession sparkSession = SparkSession.builder().master("local" ).appName("sparkSQL" ).getOrCreate(); Dataset<Row> rowDataset = sparkSession.read().json("data/user.json" ); rowDataset.createOrReplaceTempView("user" ); sparkSession.udf().register("prefixName" , new UDF1 <String, String>() { @Override public String call (String s) throws Exception { return "Name:" + s; } }, StringType$.MODULE$); String sql = "select prefixName(name) from user" ; Dataset<Row> rowDataset1 = sparkSession.sql(sql); rowDataset1.show(); sparkSession.close(); } } import static org.apache.spark.sql.types.DataTypes.StringType;public class sql_udf { public static void main (String[] args) { final SparkSession sparkSession = SparkSession.builder().master("local" ).appName("sparkSQL" ).getOrCreate(); Dataset<Row> rowDataset = sparkSession.read().json("data/user.json" ); rowDataset.createOrReplaceTempView("user" ); sparkSession.udf().register("prefixName" , new UDF1 <String, String>() { @Override public String call (String s) throws Exception { return "Name:" + s; } }, StringType); String sql = "select prefixName(name) from user" ; Dataset<Row> rowDataset1 = sparkSession.sql(sql); rowDataset1.show(); sparkSession.close(); } }
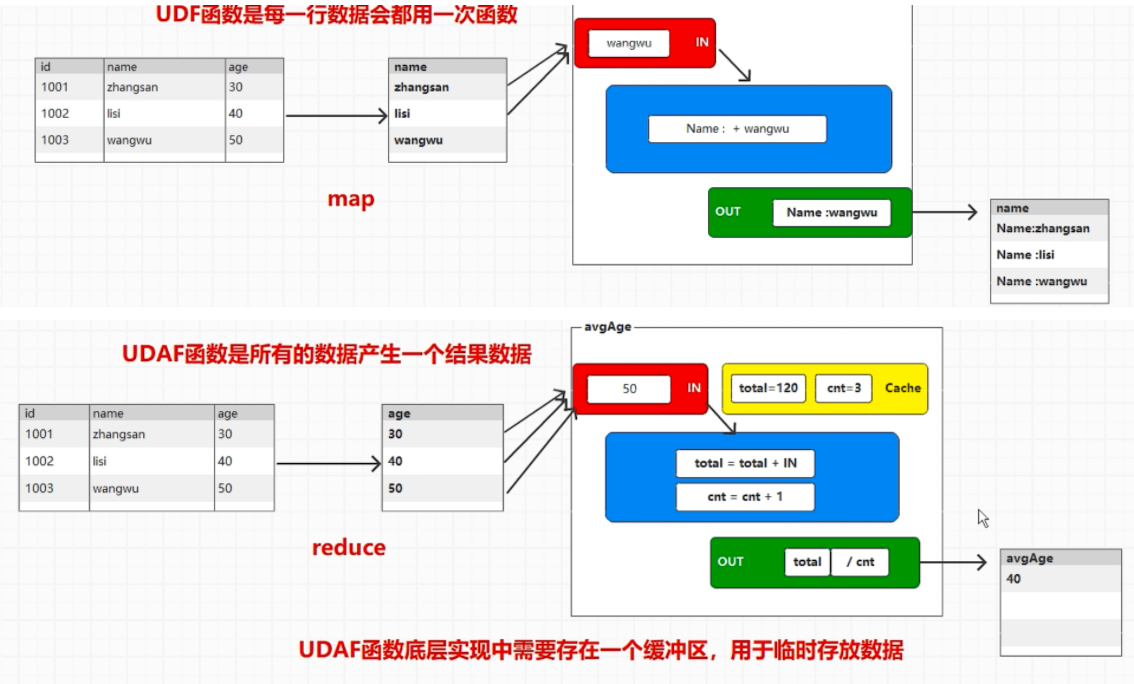
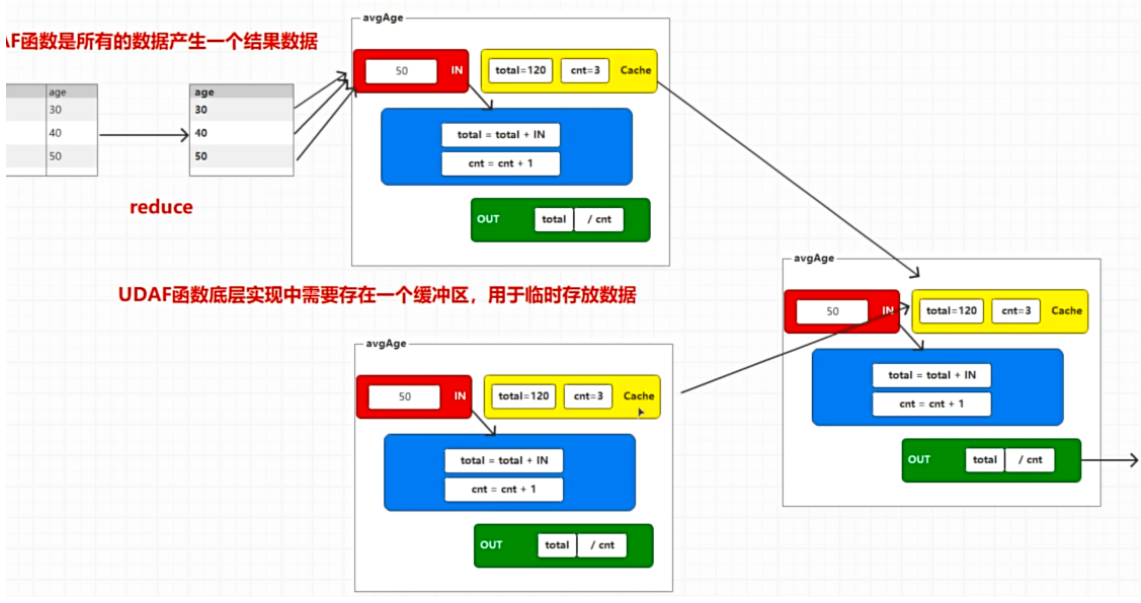
UDF 函数是每一行数据会都用一次函数
UDAF 函数是所有的数据产生一个结果数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 package org.example.sparksql;import java.io.Serializable;public class AvgAgeBuffer implements Serializable { private long total; private long count; AvgAgeBuffer() { } AvgAgeBuffer(long total, long count) { this .total = total; this .count = count; } public long getCount () { return count; } public void setCount (long count) { this .count = count; } public long getTotal () { return total; } public void setTotal (long total) { this .total = total; } } package org.example.sparksql;import org.apache.spark.sql.Encoder;import org.apache.spark.sql.Encoders;import org.apache.spark.sql.expressions.Aggregator;public class MyAvgAgeUDAF extends Aggregator <Long, AvgAgeBuffer, Long> { @Override public AvgAgeBuffer zero () { return new AvgAgeBuffer (0L , 0L ); } @Override public AvgAgeBuffer reduce (AvgAgeBuffer buffer, Long age) { buffer.setTotal(buffer.getTotal() + age); buffer.setCount(buffer.getCount()+1 ); return buffer; } @Override public AvgAgeBuffer merge (AvgAgeBuffer b1, AvgAgeBuffer b2) { b1.setTotal(b1.getTotal()+b2.getTotal()); b1.setCount(b1.getCount()+b2.getCount()); return b1; } @Override public Long finish (AvgAgeBuffer reduction) { return reduction.getTotal() / reduction.getCount(); } @Override public Encoder<AvgAgeBuffer> bufferEncoder () { return Encoders.bean(AvgAgeBuffer.class); } @Override public Encoder<Long> outputEncoder () { return Encoders.LONG(); } } package org.example.sparksql;import org.apache.spark.sql.*;import org.apache.spark.sql.expressions.Aggregator;import java.io.Serializable;public class sql_udaf { public static void main (String[] args) { final SparkSession sparkSession = SparkSession.builder().master("local" ).appName("sparkSQL" ).getOrCreate(); Dataset<Row> rowDataset = sparkSession.read().json("data/user.json" ); rowDataset.createOrReplaceTempView("user" ); sparkSession.udf().register("avgage" , functions.udaf(new MyAvgAgeUDAF (),Encoders.LONG())); String sql = "select avgage(age) from user" ; sparkSession.sql(sql).show(); sparkSession.close(); } }
# 数据加载与保存SparkSQL 读取和保存的文件一般为三种,JSON 文件、CSV 文文件和列式存储的文件,同时可以通过添加参数,来识别不同的存储和压缩格式。
csv
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 public class sql_source { public static void main (String[] args) { final SparkSession sparkSession = SparkSession.builder().master("local[*]" ).appName("sparkSQL" ).getOrCreate(); Dataset<Row> csv = sparkSession.read().option("header" ,"true" ).option("sep" ,"," ).csv("data/user.csv" ); csv.write().mode("append" ).option("header" ,"true" ).csv("output" ); sparkSession.close(); } }
json
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class sql_source_json { public static void main (String[] args) { final SparkSession sparkSession = SparkSession.builder().master("local[*]" ).appName("sparkSQL" ).getOrCreate(); Dataset<Row> rowDataset = sparkSession.read().json("data/user.json" ); rowDataset.write().json("output" ); sparkSession.close(); } }
行式存储
存在主键,可以快速定位。查询快,统计慢
列式存储
查询快,统计快
mysql 行存储,hive 列存储
spark 列存储 parquet
列存储可以被压缩,snappy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ublic class sql_source_parquet { public static void main (String[] args) { final SparkSession sparkSession = SparkSession.builder().master("local[*]" ).appName("sparkSQL" ).getOrCreate(); Dataset<Row> rowDataset = sparkSession.read().parquet("data/user" ); rowDataset.write().json("output" ); sparkSession.close(); } }
# mysql 交互1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0 .18 </version> </dependency> public class sql_source_mysql { public static void main (String[] args) { final SparkSession sparkSession = SparkSession.builder().master("local[*]" ).appName("sparkSQL" ).getOrCreate(); Properties properties = new Properties (); properties.setProperty("user" ,"admin" ); properties.setProperty("password" ,"Chaitin@123" ); Dataset<Row> jdbc = sparkSession.read().jdbc("jdbc:mysql://hadoop100:3306/metastore?useSSL=false" ,"TYPES" ,properties); jdbc.write().mode("append" ).jdbc("jdbc:mysql://hadoop100:3306/metastore?useSSL=false" ,"TYPES_123" ,properties); jdbc.show(); sparkSession.close(); } }
# hive 交互复制 hive-site.yaml 到 resources 中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12 </artifactId> <version>3.3 .1 </version> </dependency> public class sql_hive { public static void main (String[] args) { System.setProperty("HADOOP_USER_NAME" ,"root" ); final SparkSession sparkSession = SparkSession .builder() .enableHiveSupport() .master("local[*]" ) .appName("sparkSQL" ) .getOrCreate(); sparkSession.sql("show tables" ).show(); sparkSession.sql("create table user_info(name string, age int)" ); sparkSession.sql("insert into table user_info values ('haha',100)" ); sparkSession.sql("select * from user_info" ).show(); sparkSession.close(); } }
如果 reources 中有 hive-site.xml 但是 target/classes 中没有,需要手工拷贝到改目录
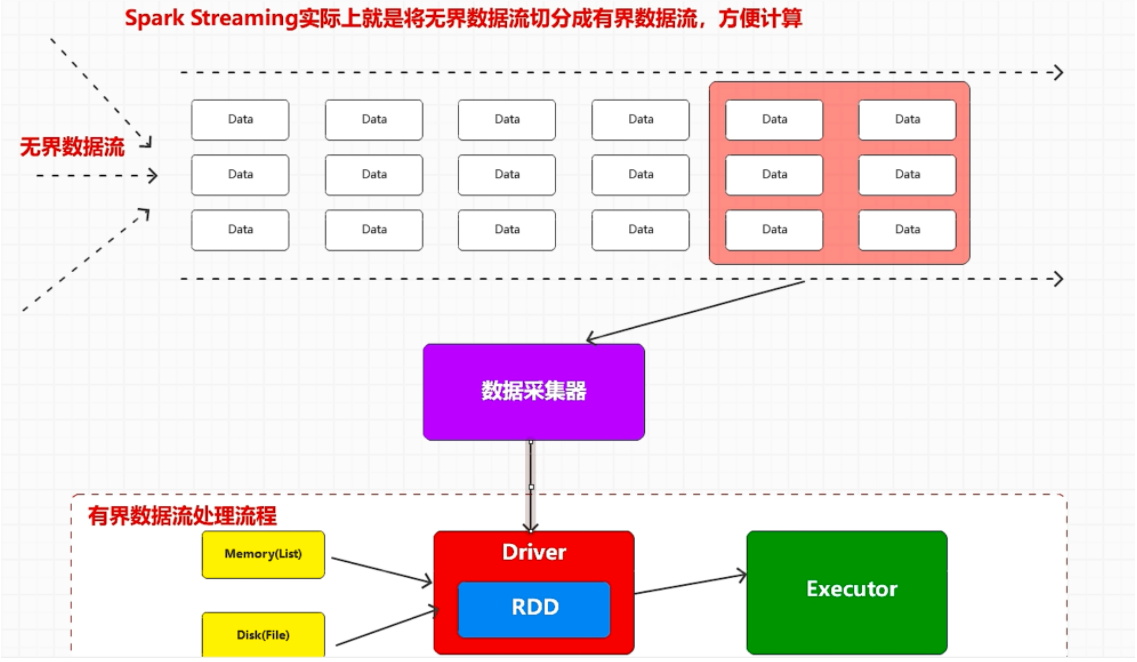
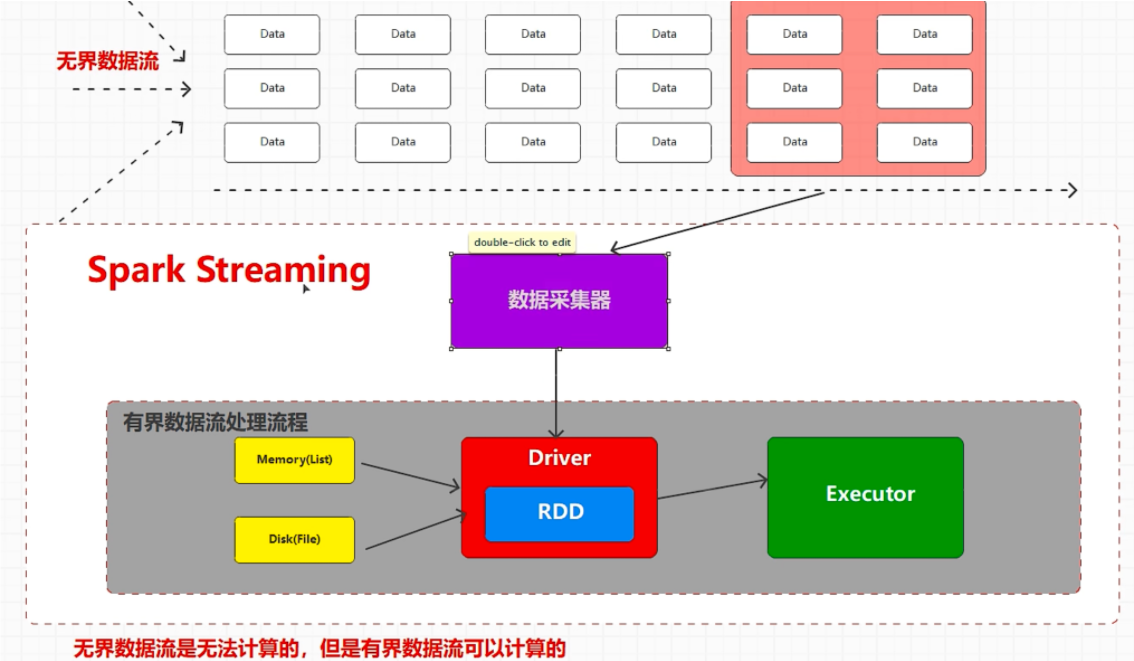
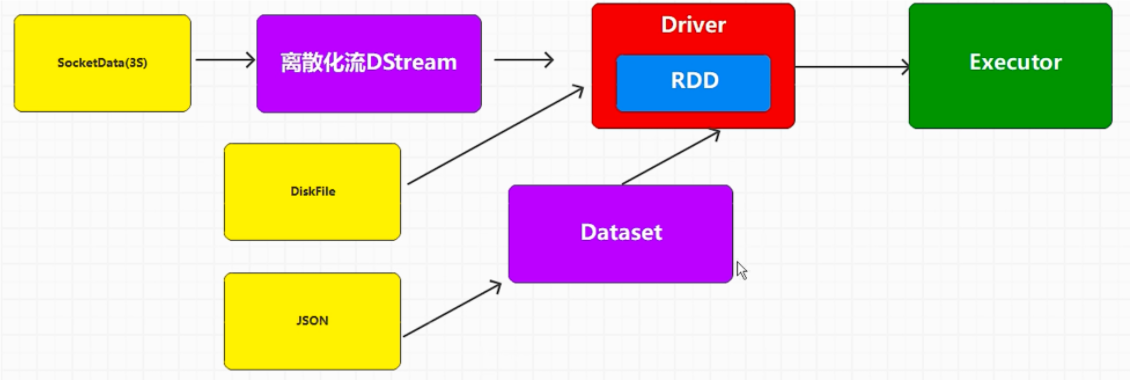
# spark streaming有界数据流
无界数据流
spark streaming 底层还是 spark core,在流式数据处理中进行的封装
从数据处理方式的角度
流式数据处理:一个数据一个数据的处理
微批量数据处理:一小批数据处理
批量数据处理:一批数据一批数据的处理
从数据处理延迟的角度
实时数据处理:数据处理的延迟以毫秒为单位
准实时处理:以秒和分钟为单位
离线数据处理:数据处理的延迟以小时,天为单位
Spark 是批量,离线数据处理框架
spark streaming 是个 微批量 准实时数据处理框架
streaming 按照时间来定义一小批
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class env { public static void main (String[] args) throws InterruptedException { SparkConf sparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("sparkstreaming" ); JavaStreamingContext javaStreamingContext = new JavaStreamingContext (sparkConf, new Duration (3000 )); javaStreamingContext.start(); javaStreamingContext.awaitTermination(); } }
socket
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 python -m http.server 8001 public class socket { public static void main (String[] args) throws InterruptedException { SparkConf sparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("sparkstreaming" ); JavaStreamingContext javaStreamingContext = new JavaStreamingContext (sparkConf, new Duration (3000 )); JavaReceiverInputDStream<String> socketTextStream = javaStreamingContext.socketTextStream("localhost" , 9999 ); socketTextStream.print(); javaStreamingContext.start(); javaStreamingContext.awaitTermination(); } }
kafka
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.apache.spark.SparkConf;import org.apache.spark.api.java.function.Function;import org.apache.spark.streaming.Duration;import org.apache.spark.streaming.api.java.*;import org.apache.spark.streaming.kafka010.ConsumerStrategies;import org.apache.spark.streaming.kafka010.KafkaUtils;import org.apache.spark.streaming.kafka010.LocationStrategies;import java.util.*;public class kafka { public static void main (String[] args) throws InterruptedException { SparkConf sparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("sparkstreaming" ); JavaStreamingContext javaStreamingContext = new JavaStreamingContext (sparkConf, new Duration (3000 )); HashMap<String, Object> map = new HashMap <>(); map.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092,hadoop104:9092" ); map.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer" ); map.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer" ); map.put(ConsumerConfig.GROUP_ID_CONFIG,"atguigu" ); map.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest" ); ArrayList<String> strings = new ArrayList <>(); strings.add("topic_db" ); JavaInputDStream<ConsumerRecord<String, String>> directStream = KafkaUtils.createDirectStream(javaStreamingContext, LocationStrategies.PreferBrokers(), ConsumerStrategies.<String, String>Subscribe(strings,map)); directStream.map(new Function <ConsumerRecord<String, String>, String>() { @Override public String call (ConsumerRecord<String, String> v1) throws Exception { return v1.value(); } }).print(100 ); javaStreamingContext.start(); javaStreamingContext.awaitTermination(); } }
Dstream
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class function { public static void main (String[] args) throws InterruptedException { SparkConf sparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("sparkstreaming" ); JavaStreamingContext javaStreamingContext = new JavaStreamingContext (sparkConf, new Duration (3000 )); JavaReceiverInputDStream<String> socketTextStream = javaStreamingContext.socketTextStream("localhost" , 9999 ); socketTextStream.print(); JavaDStream<String> stringJavaDStream = socketTextStream.flatMap( line -> Arrays.asList(line.split(" " )).iterator() ); JavaPairDStream<String, Integer> stringIntegerJavaPairDStream = stringJavaDStream.mapToPair( word -> new Tuple2 <>(word, 1 ) ); JavaPairDStream<String, Integer> stringIntegerJavaPairDStream1 = stringIntegerJavaPairDStream.reduceByKey( Integer::sum ); stringIntegerJavaPairDStream1.foreachRDD( rdd -> { rdd.sortByKey().collect().forEach(System.out::println); } ); javaStreamingContext.start(); javaStreamingContext.awaitTermination(); } }
window
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 窗口是可以移动的,成为移动窗口,但是窗口移动是有复幅度的,默认移动幅度就是采集周期 窗口:其实就是数据的范围(时间) window方法可以改变窗口的数据范围(默认数据范围为采集周期 window方法可以传递2 个参数 第一个参数表示窗口的数据范围(时间) 第二个参数表示窗口的移动幅度(时间),可以不用传递,默认使用的就是采集周期 数据窗口范围和窗口移动幅度一致(3s),数据不会有重复 数据窗口范围比窗口移动幅度大,数据可能会有重复 数据窗口范围比窗口移动幅度小,数据可能会有遗漏
close
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 public class close { public static void main (String[] args) throws InterruptedException { SparkConf sparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("sparkstreaming" ); JavaStreamingContext javaStreamingContext = new JavaStreamingContext (sparkConf, new Duration (3000 )); JavaReceiverInputDStream<String> socketTextStream = javaStreamingContext.socketTextStream("localhost" , 9999 ); socketTextStream.print(); javaStreamingContext.start(); new Thread (new Runnable () { @Override public void run () { try { Thread.sleep(000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } javaStreamingContext.stop(true ,true ); } }).start(); javaStreamingContext.awaitTermination(); } } new Thread (new Runnable () { @Override public void run () { try { Thread.sleep(3000 ); boolean flag = false ; } catch (InterruptedException e) { throw new RuntimeException (e); } javaStreamingContext.stop(true ,true ); } }).start(); javaStreamingContext.awaitTermination(); } } public void run () { try { FileSystem fs = FileSystem.get(new URI ("hdfs://hadoop102:8020" ), new Configuration (), "atguigu" ); while (true ){ Thread.sleep(5000 ); boolean exists = fs.exists(new Path ("hdfs://hadoop102:8020/stopSpark" )); if (exists){ StreamingContextState state = javaStreamingContext.getState(); if (state == StreamingContextState.ACTIVE){ javaStreamingContext.stop(true , true ); System.exit(0 ); } } } }catch (Exception e){ e.printStackTrace(); } } } }