# 大数据生态概论
大数据通常指的是规模巨大、类型多样、增长速度快的数据集合,这些数据集合难以使用传统的数据处理应用软件进行管理。大数据的特点通常被概括为 “4V”:
-
Volume(体量):数据量巨大,从 TB 级别跃升至 PB 级别甚至更高。
-
Velocity(速度):数据产生和处理的速度非常快,需要实时分析而非事后分析。
-
Variety(多样性):数据类型繁多,包括结构化数据(如数据库)和非结构化数据(如文本、音频、视频)。
-
Veracity(真实性):数据的质量和准确性,这是确保分析结果可靠的关键。
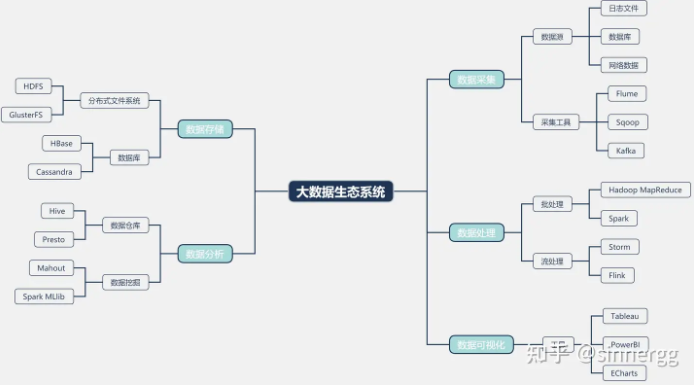
大数据生态系统是指一系列相互关联的技术、工具和服务,它们共同支持大数据的收集、存储、处理、分析和可视化。这个生态系统包括以下几个关键组成部分:
-
数据源:包括各种内部和外部数据源,如企业数据库、社交媒体、物联网设备等。
-
数据存储:用于存储大数据的基础设施,如分布式文件系统(HDFS)、NoSQL 数据库(Cassandra)和数据仓库(Amazon Redshift)。
-
数据处理:用于处理和分析大数据的框架和工具,如 Hadoop 的 MapReduce、Spark 的 Spark Core 等。
-
数据分析与挖掘:用于从大数据中提取有价值信息的工具和技术,如数据挖掘、机器学习、统计分析等。
-
数据可视化:将分析结果以图表、仪表板等形式展现,帮助用户更好地理解和利用数据。
-
数据安全与治理:确保数据安全和合规性的技术和策略,如数据加密、访问控制、数据治理框架等。

# hadoop 生态系统
- Hadoop 简介
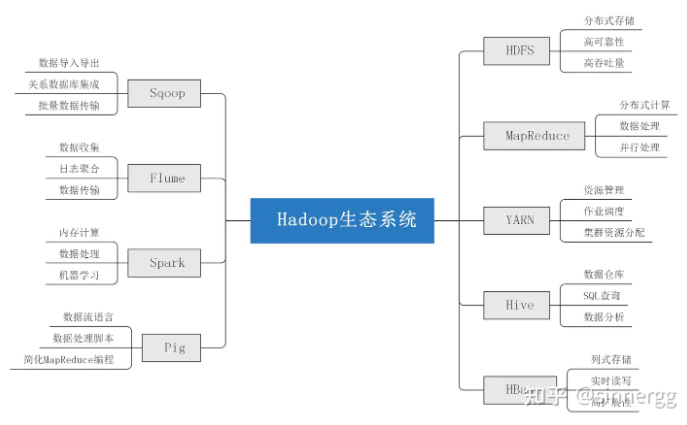
Hadoop 是一个开源的分布式存储和计算框架,由 Apache 软件基金会开发。它旨在处理大规模数据集,并能够在计算机集群上分布式处理这些数据。Hadoop 的设计理念是 “移动计算比移动数据更经济”,这意味着它将计算任务分配到数据所在的节点上,而不是将数据移动到计算节点。
Hadoop 的核心优势在于其高度的可扩展性、容错性和成本效益。它可以在廉价的硬件上运行,通过冗余存储和自动故障转移来保证数据的可靠性。
- Hadoop 的核心组件
- HDFS(Hadoop Distributed File System):
HDFS 是 Hadoop 的分布式文件系统,它提供了对应用程序数据的高吞吐量访问。HDFS 设计用于存储非常大的文件,并采用 “一次写入,多次读取” 的模型。它将文件分割成块,并在集群的多个节点上存储这些块的副本,以提高数据的可靠性和访问性能。
- MapReduce:
MapReduce 是 Hadoop 的编程模型,用于处理和生成大数据集。它允许用户编写并行处理数据的程序,而不需要关心底层的并行化和分布式细节。MapReduce 作业通常包括两个阶段:Map 阶段和 Reduce 阶段。Map 阶段将输入数据转换成键值对,Reduce 阶段则对这些键值对进行聚合操作。
- YARN(Yet Another Resource Negotiator):
YARN 是 Hadoop 2.0 引入的资源管理器,它负责集群资源的管理和作业调度。YARN 将 Hadoop 的资源管理功能从 MapReduce 中分离出来,使得其他数据处理框架(如 Spark)也可以在 Hadoop 集群上运行。YARN 通过将资源管理和作业调度分离,提高了集群的利用率和灵活性。
# spark 生态系统

- Spark 简介
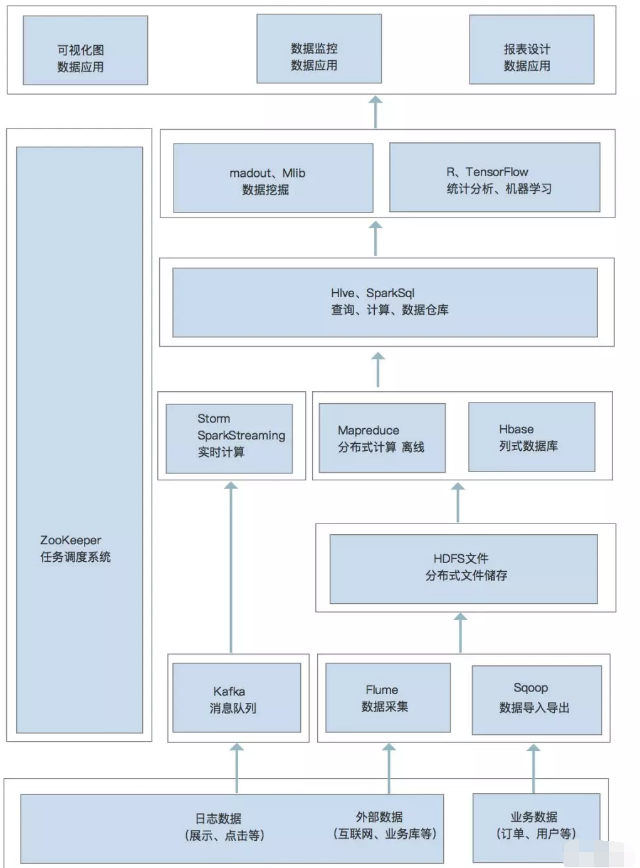
Apache Spark 是一个开源的分布式计算系统,它提供了高效的数据处理能力和易用的 API。Spark 旨在加速大数据处理任务,特别适用于需要多次迭代的机器学习和图形处理算法。与 Hadoop 的 MapReduce 相比,Spark 提供了内存计算能力,这使得它在处理迭代算法时速度更快。
Spark 支持多种编程语言,包括 Scala、Java、Python 和 R,这使得它对不同技术背景的开发者都很友好。Spark 可以在多种环境中运行,包括独立的 Spark 集群、Hadoop YARN、Apache Mesos 以及云环境。
- Spark 的核心组件
- Spark Core:
Spark Core 是 Spark 的基础引擎,负责任务调度、内存管理、错误恢复、与存储系统交互等核心功能。Spark Core 还提供了 RDD(Resilient Distributed Datasets)的概念,这是一种容错的、可以并行操作的数据集合。
- Spark SQL:
Spark SQL 是 Spark 用来处理结构化数据的模块。它允许用户通过 SQL 或 DataFrame API 来查询数据,这些查询会被转换成高效的 Spark 作业。Spark SQL 支持多种数据源,包括 Hive、Parquet、JSON 等,并且可以与现有的 Hive 仓库集成。
- Spark Streaming:
Spark Streaming 是 Spark 的实时数据处理模块,它允许用户构建可扩展、高吞吐量、容错的实时数据处理应用。Spark Streaming 接收实时输入数据流,并将数据分割成批次,然后由 Spark 引擎处理,生成最终的批次结果流。
- Spark 生态系统中的其他工具
- MLlib(Machine Learning Library):
MLlib 是 Spark 的可扩展机器学习库,它提供了一套通用的机器学习算法和工具,包括分类、回归、聚类、协同过滤等。MLlib 的设计目标是让机器学习变得简单且可扩展,它与 Spark 的 RDD 和 DataFrame API 紧密集成。
- GraphX:
GraphX 是 Spark 的图形处理库,它提供了一套图形计算 API,允许用户进行并行图形操作。GraphX 扩展了 RDD 的概念,引入了弹性分布式属性图(Resilient Distributed Property Graph),这是一种有向多重图,其属性附加到每个顶点和边上。
Spark 生态系统还包括其他工具,如 SparkR(一个用于 R 语言的 Spark 包)、Spark Streaming Kafka(用于与 Kafka 集成)、Spark Streaming Flume(用于与 Flume 集成)等。这些工具和库共同构成了一个强大的数据处理和分析平台,适用于各种大数据应用场景。
# flink
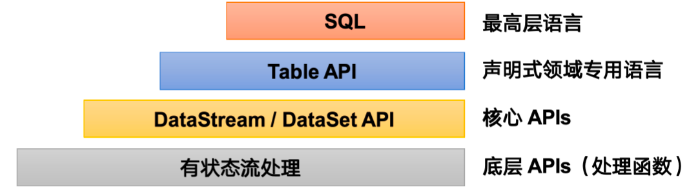
Flink,由 Apache Software Foundation 开发,是一个支持流式和批处理的大数据框架。它的低延迟、高吞吐量和良好的容错性使其适用于复杂的数据处理应用。
DataStream API
DataStream API 是 Flink 用于处理实时数据流的核心组件,支持多种数据源(如 Kafka、Kinesis)的数据流输入,提供丰富的转换操作,包括 map、flatMap、filter、aggregate 等,方便开发人员进行实时数据处理。
DataSet API
DataSet API 用于批处理任务,支持对静态数据集合(如文件系统或数据库表)的处理。DataSet API 提供了丰富的数据转换和操作功能,支持大规模的数据处理任务。
CEP**(复杂事件处理)**
CEP 是 Flink 用于复杂事件处理的组件,它通过定义事件模式和匹配规则,支持从实时数据流中提取和处理复杂事件序列,适合用于实时监控、告警和事件分析等应用场景。
Table API 和 ****SQL
Table API 和 SQL 是 Flink 提供的高级数据处理接口,支持开发人员使用 SQL 语法进行数据查询和分析。Table API 和 SQL 可以无缝集成 Flink DataStream 和 DataSet API,支持流式和批处理任务。
# kafka
Kafka,由 Apache Software Foundation 开发,是一个分布式的流处理平台,具有高吞吐量、低延迟、高可扩展和高容错等特点。Kafka 广泛用于实时数据流的采集、传输和处理。
Producer
Producer 是 Kafka 中负责数据生产的组件,它将数据写入 Kafka 的主题中。Producer 支持大规模并发写入,保证数据的高效传输和存储。
Consumer
Consumer 是 Kafka 中负责数据消费的组件,它从 Kafka 的主题中读取数据,并将数据传输到后续的处理系统或存储系统中。Consumer 支持多种消费模式,如点对点和发布订阅等。
Broker
Broker 是 Kafka 的核心组件,负责数据的存储、复制和分发。Kafka 集群由多个 Broker 组成,它们协同工作,保证数据的高可用性和可靠性。
Zookeeper
Zookeeper 是 Kafka 用来进行集群状态管理和协同操作的工具,负责 Broker 的协调、状态监控和元数据管理。通过 Zookeeper,Kafka 能够实现高效的节点管理和任务调度。
# hive
由 Apache Software Foundation 开发,是一个基于 Hadoop 的数据仓库工具,它提供了类似 SQL 的查询语言 HiveQL,支持大规模结构化数据的存储、查询和分析。
HiveQL
HiveQL 是 Hive 提供的查询语言,支持 SQL 语法的查询和操作。通过 HiveQL,用户可以方便地进行数据查询、插入和更新等操作,无需复杂的编程。
SerDe
SerDe 是 Hive 的数据序列化和反序列化组件,它负责将数据从 HDFS 等存储系统中读取,并转换为可供查询的数据格式。SerDe 支持多种数据格式,如 JSON、CSV、Avro 等。
Metastore
Metastore 是 Hive 的元数据管理组件,它存储了表的定义、列的信息以及数据的位置等元数据。Metastore 通过 API 与其他组件交互,支持数据的高效管理和查询。
Optimizer
Optimizer 是 Hive 的查询优化器,它通过分析查询计划,选择最优的执行路径,提升查询的性能和效率。Optimizer 使用多种技术,如索引、分区和并行计算等,优化数据查询和处理任务。
# hbase
HBase,由 Apache Software Foundation 开发,是一个开源的、分布式的、面向列的数据库,用于实时随机读写大规模的结构化数据。HBase 基于 HDFS 构建,具有高并发、高可靠和高可扩展性。
Data Model
HBase 的数据模型是基于表、行和列族的。每个表由多个行组成,每行包含一个唯一的行键,行中的数据按列族进行存储和管理。HBase 的数据模型支持大规模数据的灵活存储和查询。
Region Server
Region Server 是 HBase 的核心组件,负责管理数据的存储和读取。每个 Region Server 管理多个 Region(表的子集),对数据进行分片和负载均衡,确保集群的高并发性能。
Master Server
Master Server 是 HBase 的管理节点,负责表的创建、删除和元数据管理等操作。Master Server 通过协调 Region Server,保证数据的高可用性和一致性。
Zookeeper
HBase 使用 Zookeeper 进行集群管理和协调,负责节点的状态管理、配置分发和故障恢复等任务,通过 Zookeeper,HBase 实现了高效的分布式协调和任务调度。
# flume
Flume,Apache 下的一个顶级开源项目,一个分布式、可靠的数据收集组件。能够高效的收集,整合数据,还可以将来自不同源的大量数据汇聚到数据中心存储落地。 目前常用于企业内收集整合日志数据,但由于其数据源的可自定义特性,还可用于传输结构化数据 (oracle, mysql 等),也常被用于流式数据的采集输入工具。
# 数据处理框架
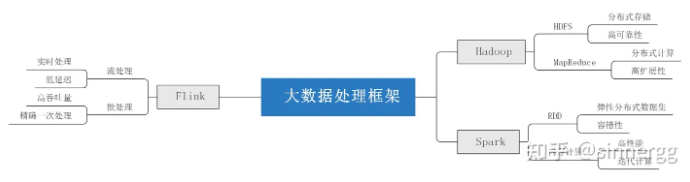
- 批处理框架
- MapReduce:
MapReduce 是 Hadoop 的核心处理框架,它提供了一种编程模型,用于处理和生成大数据集。MapReduce 作业通常包括两个阶段:Map 阶段和 Reduce 阶段。Map 阶段将输入数据转换成键值对,Reduce 阶段则对这些键值对进行聚合操作。MapReduce 适合批量处理,但它的迭代处理性能较差,不适合需要快速响应的场景。
- Tez:
Apache Tez 是一个构建在 YARN 之上的应用框架,它旨在提供一个灵活、高性能的批处理和交互式数据处理引擎。Tez 通过优化 DAG(有向无环图)的执行来提高处理效率,它允许开发者定义复杂的处理流程,并且可以与 Hive、Pig 等 Hadoop 生态系统工具集成。
- 流处理框架
- Storm:
Apache Storm 是一个分布式实时计算系统,它设计用于处理无界数据流。Storm 可以实时处理数据,保证每个消息都会被处理,即使是在出现故障的情况下。Storm 的拓扑结构定义了数据流的处理逻辑,可以用于实时分析、在线机器学习、持续计算等场景。
- Flink:
Apache Flink 是一个开源的流处理框架,它提供了一个高吞吐量、低延迟的数据处理引擎。Flink 支持事件时间处理和状态管理,可以处理无界和有界数据流。Flink 还提供了批处理 API,使得它既可以作为流处理框架,也可以作为批处理框架使用。
- 混合处理框架
- Kafka Streams:
Kafka Streams 是一个轻量级的客户端库,用于构建应用程序和微服务,其中输入和输出数据存储在 Kafka 集群中。Kafka Streams 结合了流处理和批处理的优点,允许开发者构建实时的、可扩展的数据处理应用。它提供了高级的 API 来处理数据流,并且与 Kafka 紧密集成,提供了高度的可靠性和容错性。
这些大数据处理框架各有特点,适用于不同的应用场景。批处理框架适合处理大规模的静态数据集,流处理框架适合实时数据处理,而混合处理框架则结合了两者的优点,提供了更灵活的处理能力。随着大数据技术的不断发展,新的处理框架也在不断涌现,为用户提供了更多的选择和可能性。
# 集成管理工具 HUE
HUE 是基于 Web 形式发布的集成管理工具,可以与大数据相关组件进行集成。通过 HUE 可以管理 Hadoop 中的相关组件,也可以管理 Spark 中的相关组件。
https://blog.csdn.net/itcast_cn/article/details/128551327
# iceberg
介于上层计算引擎和底层存储格式之间的一个中间层。这个中间层不是数据存储的方式,只是定义了数据的元数据组织方式,并向计算引擎提供统一的类似传统数据库中 “表” 的语义。它的底层仍然是 Parquet、ORC 等存储格式。
Iceberg 是一种开放的数据湖表格式。可以简单理解为是基于计算层(Flink、Spark)和存储层(ORC,Parquet,Avro)的一个中间层,用 Flink 或者 Spark 将数据写入 Iceberg,然后再通过其他方式来读取这个表,比如 Spark,Flink,Presto 等。
https://blog.csdn.net/be_racle/article/details/132637428
# starrocks
https://blog.csdn.net/m0_64261982/article/details/138709958
https://docs.mirrorship.cn/zh/docs/quick_start/shared-nothing/
# OLAP OLTP
https://zhuanlan.zhihu.com/p/647306436
https://blog.csdn.net/sxsAffable/article/details/139835022
# ETL ELT
https://www.zhihu.com/question/420519750/answer/3461220691
# 数据库 数据仓库 数据湖 数据集市 湖仓一体
https://baijiahao.baidu.com/s?id=1780063068985929108&wfr=spider&for=pc
https://mbd.baidu.com/newspage/data/landingsuper?context={"nid"%3A"news_9725025101841404659"}&n_type=1&p_from=4
https://mbd.baidu.com/newspage/data/landingsuper?context={"nid"%3A"news_9426720441749666754"}&n_type=1&p_from=4
https://cloud.tencent.com/developer/article/2409056
# 大数据平台 数据中台
https://blog.csdn.net/ccddtomato/article/details/140891284
https://blog.csdn.net/m0_57344393/article/details/139646617
https://cloud.tencent.com/developer/article/2089566
https://zhuanlan.zhihu.com/p/706908780
https://www.fanruan.com/blog/article/520/
https://developer.baidu.com/article/detail.html?id=293510
https://blog.csdn.net/2401_83817024/article/details/137803691
https://zhuanlan.zhihu.com/p/653973251