# Deepseek 汇总
NVIDIA GPU info
# 开源模型
DeepSeek 官方开源的 R1 内容仅限于模型权重(DeepSeek-R1-0528),并提供标准接口支持调用,完整训练体系仍属非公开状态。
DeepSeek-R1 未开源的内容:
- 训练代码(Training Code)和完整训练流程;
- RLHF(强化学习)框架;
- 原始训练数据;
- 配套的底层系统如 FlashMLA、DeepGEMM、3FS 等(这些属于独立开源项目,归在 2 月 “开源周” 系列发布)。
DeepSeek-R1 已开源内容:
- 模型权重(Model Weights)
- 版本名称:DeepSeek-R1-0528(或写作 R1-0528)
- 开源时间:2025 年 5 月 29 日
- 发布平台:Hugging Face(模型仓库)
- 是否完整开源:仅开放模型权重文件(非训练代码 / 框架)
- 功能表现:
- 在编程、逻辑推理、语言交互能力显著提升;
- 实测媲美 OpenAI 的 o3 模型及 Claude 4 水平(参考 Live CodeBench);
- 32K 上下文准确率提高(但更长上下文中仍有限制)。
- 相关 API 与使用接口
为什么只需要权重就可以部署模型
DeepSeek-R1 这类大模型基本都基于 Transformer 架构(如 Llama、GPT、BERT 框架),其结构(层数、维度、注意力头)在训练前就确定了。
PyTorch / TensorFlow / JAX 等框架都能描述这类结构,并提供一致的接口。
神经网络 = 结构 + 参数: 权重文件里保存了训练后模型每一个神经元的参数 —— 这些参数决定了语言能力高低。
部署 ≠ 重新训练: 部署时不需要原始代码(像数据预处理、训练器、loss 函数等),只需要 “用权重复现结构”。部署模型的目的不是为了继续训练它,而是为了使用它来对新的、未见过的数据进行预测(推理)。
模型配置描述: 权重文件配套的 .json 配置文件中已清楚写明了:
权重文件是知识的载体: 因此,要复现一个训练好的模型进行推理,你只需要:
- 拥有或知道模型的架构代码(
.py文件或库调用)。 - 拥有训练好的权重文件(通常是
.pt,.pth,.h5,.ckpt,.bin,.safetensors等格式),这个文件只包含那些巨大的数值矩阵,不包含架构信息。
从 huggingface 下载模型和的时候,会现在模型权重文件 (xxxx.safetensors),config.json (模型配置描述)
| 组件 | 内容 | 作用 |
|---|---|---|
| 权重张量 | FP16/BF16 格式的数值矩阵(如 .bin) | 存储线性层权重、归一化层参数等 |
| 配置文件 | config.json | 描述隐藏层维度、头数、层数等结构 |
| 分词器配置 | tokenizer.json | 文本到 Token 的编解码规则 |
| 模型元数据 | pytorch_model.bin.index.json | 分布式权重分片信息(如有) |
- 前向 **** 推理的确定性 训练代码包含反向传播优化器(如 AdamW)、Loss 函数等组件,而推理仅需 **** 前向传播: 该过程仅依赖矩阵乘法(GEMM)与激活函数等确定性算子。
- 框架原生支持 **** 算子 Transformer 基础算子(如 LayerNorm、Softmax)已由 PyTorch CUDA 内核实现,无需自定义代码。
黑盒优化 **** 细节丢失
如 FlashAttention-4 算子实现、MoE 路由策略等底层优化不可见。
开源权重的局限性
- 无法重新训练 缺少以下训练关键组件: ▶︎ 数据预处理 Pipeline ▶︎ 分布式通信策略(如 ZeRO-3) ▶︎ 混合精度缩放器(GradScaler) ▶︎ RLHF 奖励模型结构
https://blog.csdn.net/CV_Autobot/article/details/126925999
# 蒸馏模型
使用 Deepseek-R1-distill-Llama-70B 举例,说明模型蒸馏
教师模型:DeepSeek-R1(671B MoE 模型),基于 DeepSeek-V3-Base 架构,通过多阶段强化学习训练
学生模型: DeepSeek-R1-Distill-Llama-70B ,由社区团队基于蒸馏技术从 DeepSeek-R1 衍生而来
| 基础模型架构 | 学生模型基于 Llama 架构(非原版 DeepSeek-V3),通过结构适配实现轻量化。 |
|---|---|
| 训练数据来源 | 主要使用 DeepSeek-R1 生成的领域伪数据(数学 / 编程 / 科学),结合少量人工标注冷启动数据优化表达质量。 |
| 蒸馏技术策略 | 采用分阶段蒸馏: 1. 教师模型生成软标签; 2. 学生模型学习软标签分布 + 真实标签。 |

# 预训练与后训练
# 预训练(Pre-training):构建通用知识基座
- 核心任务:在海量无标注文本上训练模型,学习语言内在规律(语法、语义、常识)。
- 输出:具备基础语言理解 / 生成能力的 通用基座模型(如 GPT、LLaMA、DeepSeek-V2)。
- 类比:相当于 “通识教育”,让模型掌握人类语言的基本规则。
- 自监督学习(Self-supervised Learning)、高效训练架构
# 后训练(Post-training):对齐人类意图与专业化
- 核心任务:在预训练模型基础上,微调其行为模式,使其: 遵循指令(Instruction Following) 生成安全 / 有帮助的内容(Safety Alignment) 适配垂直领域(如医疗、法律)
| 阶段 | 目标 | 关键技术 | 代表方法 / 模型 |
|---|---|---|---|
| 1. 指令微调 | 理解并执行指令 | - 监督微调(SFT):人工标注指令 - 答案对 - 合成数据生成(Self-Instruct) | Alpaca、DeepSeek-RLHF- |
| 2. 对齐训练 | 使输出符合人类偏好 | - RLHF(基于人类反馈的强化学习) - DPO(直接偏好优化) - KTO(Kahneman-Tversky 优化) | ChatGPT、DeepSeek-R1 |
| 3. 领域适配 | 提升专业任务能力 | - 继续预训练(领域文本) - 适配器微调(LoRA、QLoRA) - 专家模型集成 | Meditron(医疗)、CodeLL |
https://seed.bytedance.com/zh/direction/llm
Deepseek-V3 和 Deepseek-R1 都是 MoE 语言模型。
- DeepSeek-V3 是一个拥有 671B 参数的大型混合专家(MoE)语言模型,每 token 激活 37B 参数。采用 fp8 混合精度,在 14.8 万亿个高质量 token 上进行预训练,训练过程非常稳定,训练成本为 2.788M H800 GPU 小时,成本优化显著。
- DeepSeek-R1-Zero 是一个通过大规模强化学习(RL)训练的模型,没有使用监督微调(SFT)作为初步步骤,展示了显著的推理能力。通过强化学习,DeepSeek-R1-Zero 自然涌现出许多强大且有趣的推理行为。然而,它也面临一些挑战,如可读性差和语言混合问题。为了解决这些问题并进一步提升推理性能,我们引入了 DeepSeek-R1,它在强化学习之前加入了多阶段训练和冷启动数据。DeepSeek-R1 在推理任务上的表现与 OpenAI-o1-1217 相当。为了支持研究社区,我们开源了 DeepSeek-R1-Zero、DeepSeek-R1 以及基于 Qwen 和 Llama 的六个密集模型(1.5B、7B、8B、14B、32B、70B)。
| Benchmark (Metric) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 | Qwen2.5 72B | LLaMA3.1 405B | DeepSeek-V2 | DeepSeek V2.5-0905 | DeepSeek V2-0506 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Architecture | - | - | MoE | - | - | MoE | Dense | Dense | MoE | MoE | MoE |
| # Activated Params | - | - | 37B | - | - | 37B | 72B | 405B | 21B | 21B | 21B |
| # Total Params | - | - | 671B | - | - | 671B | 72B | 405B | 236B | 236B | 236B |
| Context Length | 128K | 128K |
- 推理模型 & 非推理模型:
- 推理模型: Deepseek-R1、 GPT-o3
- 非推理模型:Deepseek-V3
# 推理模型(Reasoning Models)
推理模型专注于处理需要多步骤逻辑推导和复杂思维过程的任务。它们能够在回答问题之前,进行深度思考,生成中间推理步骤,从而得出最终答案。推理模型的特点主要包括:
- 多步骤推理能力:推理模型能够处理需要多步骤逻辑推导的任务,如解谜、高级数学问题和复杂的编码任务。它们能够生成中间推理步骤,展示其思考过程。
- 高可解释性:由于推理模型能够展示其推理过程,用户可以理解模型的思考方式,从而增强对模型的信任度。
- 技术增强:推理模型通常具备额外的技术,如强化学习、神经符号推理、元学习等,来增强其推理和问题解决能力。
- 资源消耗大:由于需要进行多步骤的推导,推理模型在计算资源消耗和推理时间上可能较长。
推理模型的应用场景包括但不限于:
- 复杂问题解决:如高级数学问题、逻辑推理题等。
- 编码任务:在编写复杂算法时,推理模型能够理解问题的深层含义,生成高效且准确的代码解决方案。
- 决策支持:在需要复杂决策的场景中,推理模型可以提供基于逻辑和数据的决策建议。
# 非推理模型(Non-Reasoning Models)
非推理模型则侧重于语言生成、上下文理解和自然语言处理,而不强调深度推理能力。它们通常通过对大量文本数据的训练,掌握语言规律并生成合适的内容。非推理模型的特点包括:
- 语言生成能力:非推理模型能够根据给定的主题或上下文,生成连贯且富有创意的文章、故事或对话。
- 上下文理解:它们能够理解文本中的上下文信息,从而生成符合语境的回复或建议。
- 广泛应用:非推理模型适用于大多数任务,如语言生成、文本分类、翻译、摘要生成等。
- 较低的资源消耗:相比于推理模型,非推理模型在计算资源消耗和推理时间上通常较低。
非推理模型的应用场景包括但不限于:
- 语言生成:如撰写文章、创作诗歌、生成对话等。
- 文本分类:如新闻分类、情感分析等。
- 机器翻译:将一种语言翻译成另一种语言。
- 摘要生成:从长篇文本中提取关键信息,生成简洁的摘要。
# 深度学习中的语音模型
# 因果语言模型 (Causal Language Models)
因果语言模型 (causal Language Models),也被称为自回归语言模型 (autoregressive language models) 或仅解码器语言模型 (decoder-only language models) ,是一种机器学习模型,旨在根据序列中的前导 token 预测下一个 token 。换句话说,它使用之前生成的 token 作为上下文,一次生成一个 token 的文本。” 因果” 方面指的是模型在预测下一个 token 时只考虑过去的上下文(即已生成的 token ),而不考虑任何未来的 token 。
因果语言模型被广泛用于涉及文本补全和生成的各种自然语言处理任务。它们在生成连贯且具有上下文关联性的文本方面尤其成功,这使得它们成为现代自然语言理解和生成系统的基础。
# 序列到序列模型 (sequence-to-sequence models)
T5 及其类似模型
序列到序列模型同时使用编码器来捕获整个输入序列,以及解码器来生成输出序列。它们广泛应用于诸如机器翻译、文本摘要等任务。
# 双向模型 (bidirectional models) 或仅编码器模型 (encoder-only models)
BERT 及其类似模型
双向模型在训练期间可以访问序列中的过去和未来上下文。由于需要未来上下文,它们无法实时生成顺序输出。它们广泛用作嵌入模型,并随后用于文本分类。
# DS 创新
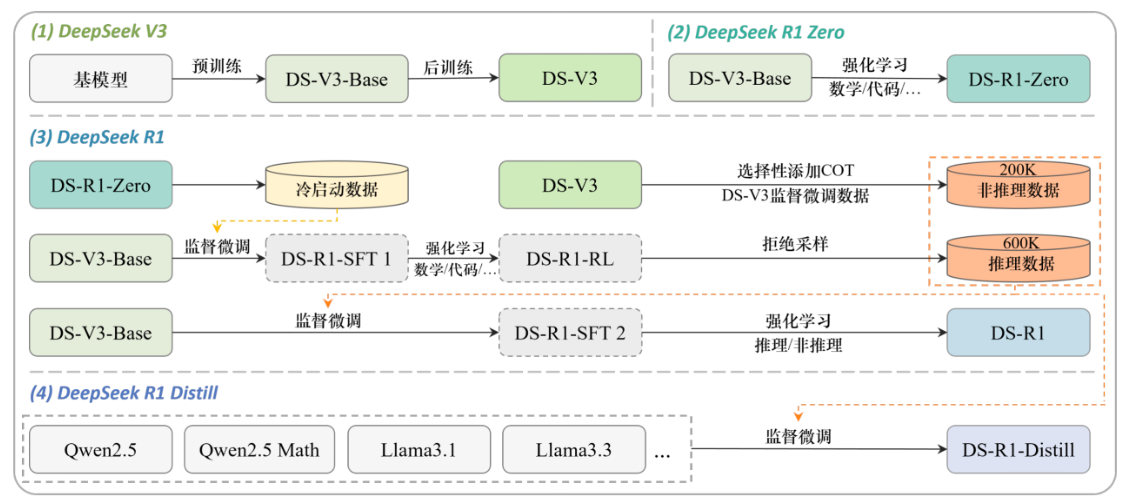
Base Model -> V3
V3 -> R1-zero
v3+R1_zero -> R1
R1 -> R1_distll
# DS-v3
训练过程:
① 预训练:基模型 + 大型语料库 [14.8T] = V3-Base
② 后训练:V3-Base + 监督微调 [推理 / 非推理数据] + 强化学习 = V3
核心技术:
① 多头潜在注意力(MLA)-> 降低推理内存占用,提高推理和训练的效率。
② 混合专家(MoE)-> 提高计算资源的利用效率,增强模型表达能力。
③ 多词元预测(MTP)-> 提高数据利用效率,增强模型的推理性能。
# R1-zero
核心技术:
分组相对策略优化(GRPO)-> 改进现有强化学习算法,降低计算成本

训练模板:背景提示 + 格式约束 + 实际交互
奖励设计:
① 准确性奖励:评估最终答案是否正确
② 格式奖励:评估回复是否遵从格式约束
R1-zero 是这些模型中推理能力最强的模型
# 大模型架构
大模型主要分为稠密(dense)模型与稀疏(sparse)模型,两者的区别主要在于模型进行计算时,被调用的参数数量,参数全部生效使用的是稠密模型,比如 OpenAI 从第一代到第三代即 GPT-1、 GPT-2、 GPT-3,以及 Meta 的 Llama 系列都是稠密模型;只使用其中一部分参数的是稀疏模型,比如基于 MoE 架构的模型,而这些被使用的参数称为「激活参数」。
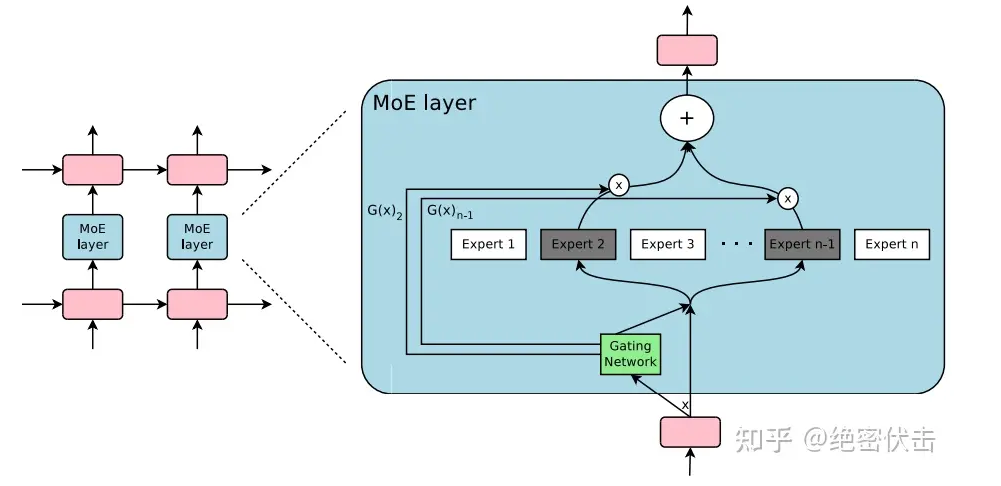
基于此,对于特定输入,MoE 只需激活少数 expert,让其参数处于激活状态,从而实现稀疏激活。而具体激活哪些 expert、哪部分参数,MoE 还会引入一个 Router(门控网络或路由),根据特定输入进行动态选择。
作为一种基于 Transformer 架构的模型,混合专家模型主要由两个关键部分组成:
- 稀疏 MoE 层:这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干 “专家”(例如 8 个),每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构,甚至可以是 MoE 层本身,从而形成层级式的 MoE 结构。
- 门控网络或路由:这个部分用于决定哪些令牌 (token) 被发送到哪个专家。例如,在下图中,“More” 这个令牌可能被发送到第二个专家,而 “Parameters” 这个令牌被发送到第一个专家。有时,一个令牌甚至可以被发送到多个专家。令牌的路由方式是 MoE 使用中的一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。
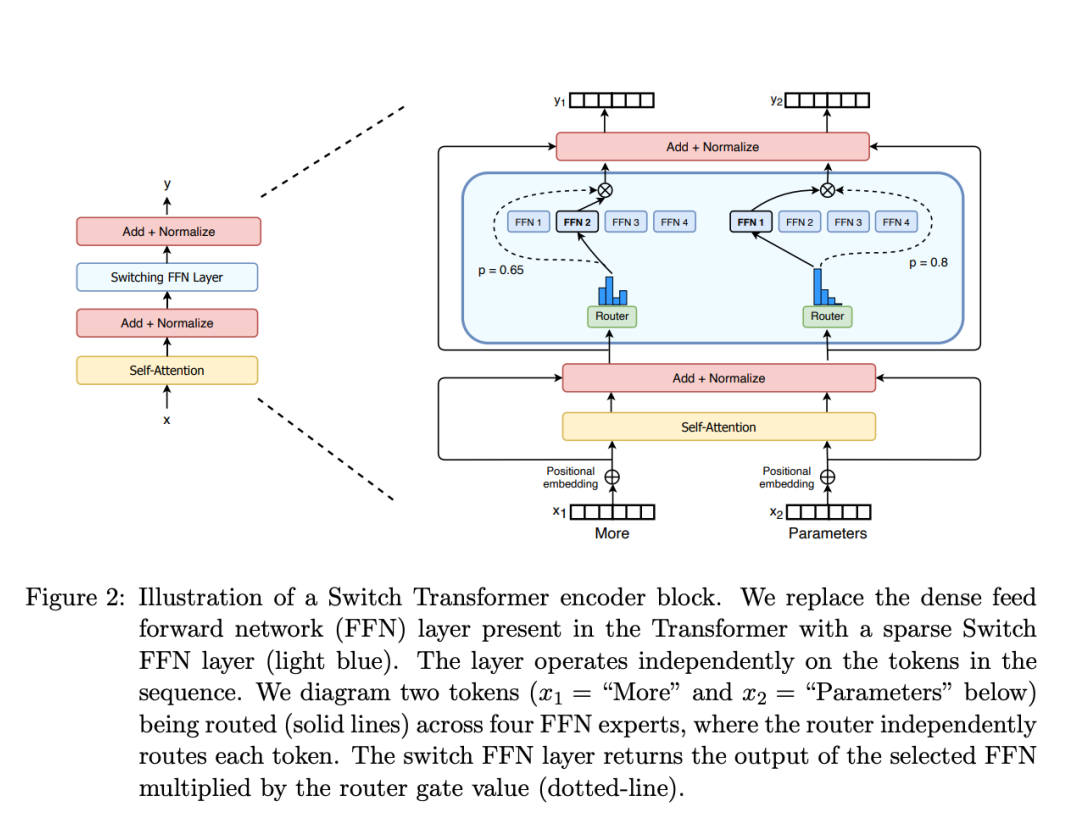
MoE 作为一种模块化的稀疏激活,可以在模型总参数量不变的情况下,大幅降低计算总量,高效计算、降低成本。这是 MoE 最为显著的优势,也是为什么它作为一个并不「新鲜」的技术又在此时此刻重新焕发活力的原因所在。
具体来看,MoE 模型的优势主要体现为专家化、动态化、稀疏化。
一是具有更强的表现力:MoE 架构融合多个各有所长的专家模型,既有分工,又有合作,能够动态地适应不同输入样本的特点,提高模型的表达能力。
二是训练和推理速度更快:相比于同参数的稠密模型架构,MoE 是稀疏的,训练的时候计算量更小,推理的时候同时激活的参数量更小,因此能够更高效地利用计算资源。
一般来说,现在的 MoE 路径选择主要分为两种 —— 基于一个已有模型开始训练,还是从头开始训练。
基于已有模型开始训练,是通过一个众所周知的取巧方案 ——upcycle(向上复用)进行的。具体来说,是将一个已经训练好的大模型的前馈神经网络权重复制若干份,每一份作为一个 expert,然后组合在一起,这样就可以把一个非 MoE 模型变成一个 MoE 模型,参数量很快就能变得特别大,但算力需求会小几个量级。
这种方法的最大优势在于可以节省很多成本,因为初始模型就有很多知识。但同时,这样也存在很大的弊端,比如基于拷贝复制得到的 MoE 模型,expert 之间会有很多知识重叠,权重、参数的冗余导致对各 expert 的支持是重叠的,如果做得不好,就不能充分发挥 MoE 架构的潜力,是一个很具考验性的路径。
从头开始训练的话,虽然训练起来会更难,但上述问题会有所缓解,且它的自由度更高,避免传统 MoE 架构模型的潜在问题,争取达到 MoE 架构模型的上限
目前市面上的 MoE 模型又分为两个流派,一种就是类似 Mistrial AI 的传统 MoE 流派,还另外就是千问和 DeepSeek MoE 这种 expert 切分更细、设置共享 expert 的架构。
https://baijiahao.baidu.com/s?id=1800190491424326934&wfr=spider&for=pc
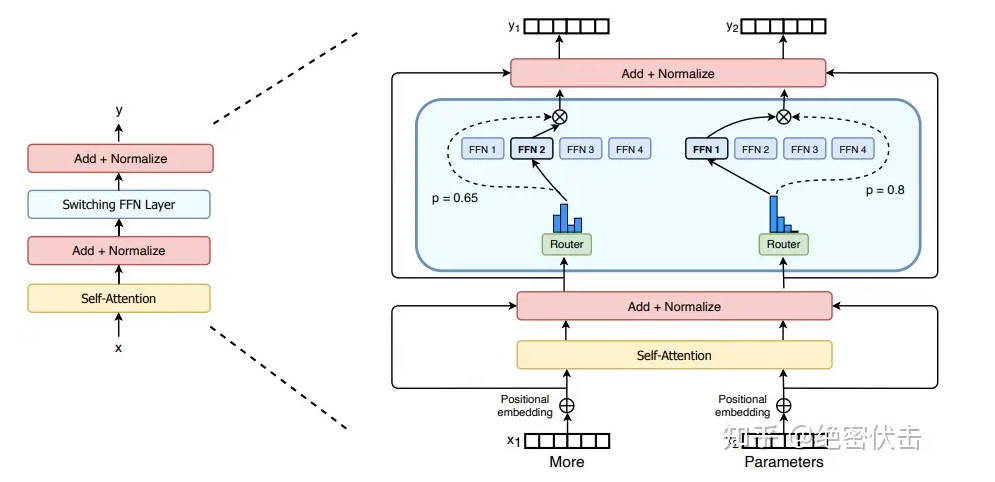
门控网络(Gating Network)的设计和实现,这是 Sparsely-Gated MoE 层的核心组成部分。门控网络负责为每个输入 token 选择一个稀疏的专家组合。
https://www.zhihu.com/tardis/bd/art/677638939
https://www.cnblogs.com/smartloli/p/18577833###
https://zhuanlan.zhihu.com/p/674698482
# PD 分离
P 是指 Prefill, D 是指 Decode,P 的特点是计算密集型,D 的特点是访存密集型。P 有静态特征,就是用户输入的 Prompt,可以批量处理,D 是动态特征,处理起来是 token-by-token。
Prefill 阶段主要负责预填充相关的计算工作,这是一个计算密集型的任务。而 Decode 阶段则专注于解码和生成任务,它接收 Prefill 阶段传递过来的计算结果,并进一步处理以生成最终的结果。
Level -1:P 和 D 在一张卡上融合,算是和 PD 分离反着来的一种设计 Level 0:P 和 D 分别计算,但还是在一张卡上调度,这是目前主流框架的默认玩法 Level 1:在同构设备同构网络中分离 P 和 D,比如在一个 H20 节点内搞,不用改造现有集群 Level 2:把 P 和 D 分到同构设备但异构网络中,比如 P 和 D 各占一个 H20 节点,需要高速互联但不用改造集群 Level 3:干脆把 P 和 D 放在异构设备上,比如用昇腾 910 跑 P,H20 跑 D,这个就得改造集群加高速互联了
https://support.huaweicloud.com/bestpractice-modelarts/modelarts_llm_infer_91215.html
# 蒸馏
一种知识迁移技术,旨在将一个复杂的大型模型(通常被称为 “教师模型”)中的知识传递给一个较小、更简洁的模型(即 “学生模型”)。这种技术的核心思想在于利用教师模型的输出,特别是其输出的软标签(即概率分布而非单一的硬标签),来指导学生模型的训练过程。通过这种方式,学生模型不仅能够学习到数据的类别信息,还能捕捉到类别之间的相似性和关系,从而有可能在保持甚至超越教师模型大部分性能的同时,显著降低计算成本和模型参数规模。
- 教师模型的训练:首先,需要有一个已经训练好的、性能优异的大型教师模型。
- 蒸馏过程:在蒸馏阶段,教师模型的输出被用作学生模型训练的参考。通过调整 softmax 函数的温度参数,使得教师模型和学生模型的输出分布更加接近,从而更有效地传递知识。
- 学生模型的训练:学生模型在蒸馏过程中学习,目标是模仿教师模型的输出分布。这通常涉及到设计一个损失函数,该函数既考虑学生模型预测与真实标签之间的差异(硬标签损失),也考虑学生模型预测与教师模型输出概率分布之间的差异(软标签损失)。
模型蒸馏的优点包括:
- 模型压缩:通过蒸馏,可以将复杂教师模型的知识迁移到小型学生模型中,大大降低计算和存储成本,便于在资源受限的设备(如手机、嵌入式设备)上部署。
- 性能提升:学生模型不仅学习了硬标签中的类别信息,还通过软标签学习了类别之间的相关性,因此其性能通常优于直接用硬标签训练的模型。
- 知识迁移:模型蒸馏可用于跨架构迁移,例如将复杂的神经网络知识迁移到更简单的网络中。
# 量化
一种模型压缩技术,其核心思想在于通过对模型参数进行量化处理,大幅度减小模型的体积,从而提高模型的运行速度和存储效率。量化过程通常涉及将高精度的浮点数(如 32 位浮点数 FP32)转换为较低精度的表示形式(如 16 位浮点数 FP16、8 位整数 INT8 或 4 位整数 INT4)。
量化的主要目的是减少模型的内存占用和提高推理速度。量化后的模型权重和激活值占用更少的内存,使得模型可以在有限的硬件资源上部署和运行。同时,低精度计算通常比高精度计算更快,尤其是在支持低精度运算的硬件上,量化可以显著提高模型的推理速度。
量化技术主要包括训练后量化(PTQ)和量化感知训练(QAT)两种方法。训练后量化是在模型训练完成后进行量化,这种方法简单且不需要额外的训练数据,但可能会引入较大的精度损失。量化感知训练则是在训练过程中模拟量化效果,使模型在训练时就适应量化带来的影响,这种方法通常能获得更好的量化效果,但需要额外的训练步骤和数据。
# 剪枝
剪枝是一种大模型压缩技术的关键技术,旨在保持推理精度的基础上,减少模型的复杂度和计算需求,以便大模型推理加速。
剪枝的一般步骤是:1、对原始模型调用不同算法进行剪枝,并保存剪枝后的模型;2、使用剪枝后的模型进行推理部署。
常用的剪枝技术包括:结构化稀疏剪枝、半结构化稀疏剪枝、非结构化稀疏剪枝。
https://zhuanlan.zhihu.com/p/717584633
# 缓存
# kvcache
在大模型推理中,KV Cache 通过缓存 key 和 value 向量,避免重复计算,从而显著提高推理效率。
在自注意力层的计算中,对于给定的输入序列,模型会计算每个 token 的 key 和 value 向量。这些向量的值在序列生成过程中是不变的,因此,通过缓存这些向量,可以避免在每次生成新 token 时重复计算。具体来说,decoder 一次推理只输出一个 token,输出 token 会与输入 tokens 拼接在一起,然后作为下一次推理的输入,这样不断反复直到遇到终止符。在推理过程中,每一轮输入数据只比上一轮新增了一个 token,其他部分完全相同,因此可以通过缓存上一轮的 key 和 value 向量,来减少下一轮的计算量。
KV Cache 主要应用于仅解码器 Transformer 架构的模型中,如 GPT 等。这些模型采用自回归生成方式,逐个生成文本的每个 token,因此每一轮推理都需要依赖上一轮的结果。在这种场景下,KV Cache 能够显著减少重复计算,提高推理效率。同时,KV Cache 也适用于需要生成长文本或进行多次推理的应用场景,如文本生成、机器翻译等。
尽管 KV Cache 带来了显著的推理效率提升,但它也带来了内存占用的问题。KV 缓存的大小随着序列长度的增加而线性增长,有时甚至可以达到模型大小的数倍。这种内存占用在推理场景中尤为常见,尤其是在显存受限的情况下,KV 缓存的大小可能成为制约模型性能的瓶颈。为了解决这一问题,提出了多种优化策略,如量化技术、模型并行技术、KV 缓存的压缩和内存管理等。
# 上下文缓存
上下文缓存(Context API)是方舟提供的一个高效的缓存机制,旨在为您优化生成式 AI 在不同交互场景下的性能和成本。它通过缓存部分上下文数据,减少重复加载或处理,提高响应速度和一致性。
- Session 缓存:保留初始信息,同时自动管理上下文,在动态对话尤其是超长轮次对话场景的可用性更强,搭配模型使用,可以获得高性能和低成本。
- 前缀缓存:持续保留初始信息,适合静态 Prompt 模板的反复使用场景。
# Session Cache
Session 缓存(Session Cache,会话级别的缓存),是针对模型性能和成本的优化。它将 Session 中的上下文(Context)进行缓存(Caching),在多轮对话等场景中,可以减少计算和存储重复内容的开销。您开通 Session 缓存后,在多轮对话场景下模型的服务可以达到更低的时延,同时对于缓存中的内容使用也会给予您一定的折扣,进一步降低您使用模型推理服务的成本。
Session 缓存保存 Context(上下文,通常指历史的对话记录),同时在后续的对话中复用这部分信息。简要的工作流程如下图所示:
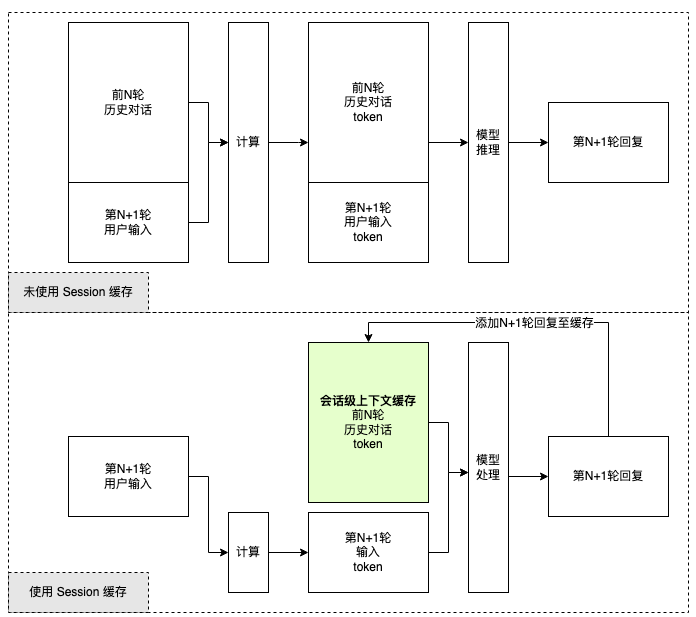
- 创建一个会话级上下文缓存,唯一的 Context ID 作为键(Key),方舟缓存会话上下文信息至关联的值(Value)。
- 方舟收到新请求时,会根据请求的 Context ID 匹配缓存中的上下文信息(历史对话)。
- 方舟只需计算和存储新输入的信息,再结合缓存中的上下文信息,交由模型推理。
- 模型输出回复信息,并将回复信息添加到 Session 缓存中,供下次请求时使用。
https://www.volcengine.com/docs/82379/1396491
# Prefix Cache
使用前缀缓存可以提高模型应用的效率并降低成本。您可以预先存储常用信息如角色、背景等信息作为初始化信息,后续调用模型时无需重复发送此信息给模型,从而加快响应速度并降低使用成本,尤其适用于具有重复提示或标准化开头文本的应用。
前缀缓存保存初始信息(通常指系统信息,前置对话等等),同时在后续的对话中复用这部分信息。简要的工作流程如下图所示
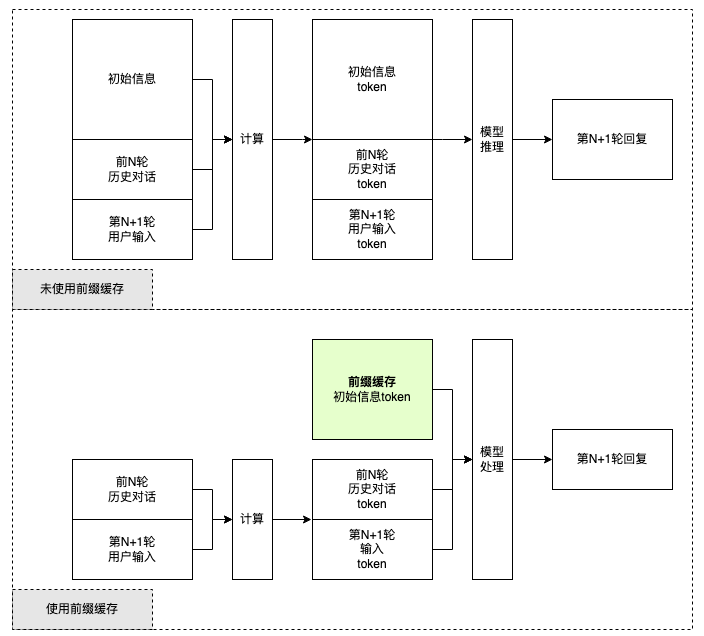
- 创建一个前缀缓存,唯一的 Context ID 作为键(Key),方舟缓存初始信息至关联的值(Value)。
- 方舟收到对话请求时,会根据请求的 Context ID 匹配缓存中的初始化信息。
- 方舟只需计算和存储新输入和历史信息,再结合缓存中的初始信息,交由模型推理。
- 模型输出回复信息。
https://www.volcengine.com/docs/82379/1396490
# 推理引擎
大模型推理引擎(Inference Engine)应运而生,它们通过优化算法、硬件加速和分布式计算等技术手段,显著提升了大模型在实际应用中的推理速度和效率。这些引擎不仅能够加速模型的推理过程,还能在保证推理质量的前提下,降低计算资源的消耗,从而使得大模型在更多场景中得以广泛应用。
在实际应用中,大模型推理引擎的重要性体现在以下几个方面:
性能优化:大模型推理引擎通过各种优化技术(如量化、剪枝、低精度计算等),显著降低了模型的推理时间,提高了系统的吞吐量。
资源利用:在多 GPU 或多节点环境下,推理引擎能够有效地分配计算资源,确保各个节点之间的负载均衡,从而最大化硬件资源的利用率。
灵活部署:推理引擎通常支持多种部署方式,如云端部署、边缘计算等,能够适应不同的应用场景和需求。
成本控制:通过优化推理过程,推理引擎能够在保证模型性能的前提下,降低硬件成本和能耗,为企业节省大量的运营成本。
常见的大模型推理引擎:vLLM,SGLang
# SGLang
https://docs.sglang.ai/
SGLang 是一种结构化生成语言,专为大型语言模型设计(LLMs)。它通过共同设计前端语言和运行时系统,使用户与大型语言模型(LLMs)的交互更快且更可控。 核心功能包括: 灵活的前端语言:允许使用链式生成调用、高级提示、控制流、多模态、并行处理和外部交互轻松编写 LLM 应用程序。 高性能后端运行时:RadixAttention 特性通过在多个调用中重用 KV 缓存加速复杂的 LLM 程序。它还可以作为独立的推理引擎使用,实现所有常见技术(例如,连续批处理和张量并行性)
# vLLM
https://docs.vllm.ai/en/latest/getting_started/quickstart.html
https://vllm.hyper.ai/docs/
vLLM,一款高效推理与服务引擎,专为大型语言模型打造,提供高吞吐量、内存优化服务,轻松实现便捷、快速、经济的 LLM 体验。
- 特点
- 高效注意力机制:采用 PagedAttention 算法,能有效减少内存碎片,提高内存利用率,显著提升推理速度和吞吐量。
- 流式输出:支持流式输出功能,在生成文本时可逐步返回结果,适合实时交互场景,如聊天机器人,能让用户更快获取部分内容,提升体验。
- 分布式推理:具备分布式推理能力,可在多个 GPU 或节点上并行计算,充分利用集群资源,进一步增强推理性能。
- API 兼容性:提供与 OpenAI API 兼容的接口,方便开发者将基于 OpenAI API 开发的应用迁移到 vLLM 上,降低开发和迁移成本。
- 适用场景:适用于对实时性要求高、需处理大规模推理任务的场景,如在线客服、智能对话系统等。
使用 vllm 部署模型:https://blog.csdn.net/qq_35082030/article/details/138225284
https://blog.csdn.net/m0_48891301/article/details/145491228
# xLLM
xLLM 是火山方舟全自研的高效推理框架,支持 PD 分离( Prefiling、Decoding)、弹性扩缩等特性,性能显著领先开源框架。 在火山引擎机器学习平台(veMLP)的推理服务中,已产品化支持使用 xLLM 推理引擎实现 PD 分离部署功能。通过本文,您可使用 xLLM 预置镜像,部署方舟同款的 DeepSeek-R1 模型推理服务;同时这里会给出 xLLM 镜像相较于 SGLang 社区开源版的性能数据对比。
# 使用 xllm 部署 Deepseek-1.5B
1 | # 使用vllm部署 Deepseek-1.5B |
# 细节详解
- 启动命令解释:
整体功能
此命令的主要目的是启动一个基于
vllm库的 OpenAI 风格的 API 服务器,该服务器会加载指定的大语言模型并提供 API 服务,让用户能够通过 API 与模型进行交互。参数详解
python3 -m vllm.entrypoints.openai.api_server:
python3:指定使用 Python 3 解释器来执行脚本。-m:将一个 Python 模块作为脚本运行,这里运行的是vllm.entrypoints.openai.api_server模块,它是vllm库中用于启动 OpenAI 风格 API 服务器的脚本。--port 1001:指定 API 服务器监听的端口号为1001,客户端可通过该端口与服务器通信。--model /root/DeepSeek-R1-Distill-Qwen-1.5B:指定要加载的大语言模型的路径,服务器会从/root/DeepSeek-R1-Distill-Qwen-1.5B路径下加载DeepSeek-R1-Distill-Qwen-1.5B模型。--served-model-name DeepSeek-R1-Distill-Qwen-1.5B:设置在 API 响应中返回的模型名称,方便客户端识别使用的是哪个模型。--tensor-parallel-size 1:指定张量并行的大小为1,即不进行多 GPU 的张量并行计算,仅使用单个设备(通常是单个 GPU)进行计算。--max-num-seqs 8:设置服务器同时处理的最大序列数量为8,限制了同一时间服务器可以处理的最大请求数量,防止服务器过载。--max_model_len=1024:指定模型能够处理的最大输入长度为1024个 token(词元),超过该长度的输入可能会被截断或导致错误。--dtype=half:使用半精度浮点数(通常是float16)来存储和处理模型的参数与计算,可减少显存占用并利用 GPU 半精度计算加速功能,但可能会有一定精度损失。
一些其他的模型部署工具,lm studio,cherry studio,ollama
# 模型部署
# FP(Full Precision)、HP(Half Precision)
Full Precision(全精度)通常指使用 32 位浮点数(即单精度,Single Precision)来存储模型权重并进行计算。单精度浮点数由 1 位符号位、8 位指数位和 23 位尾数位构成,可提供约 7 位有效数字的精度。
在深度学习模型里,GPU 以全精度模式运行能确保较高的计算精度和模型准确性,不过也会占用更多存储空间和计算资源。这在对精度要求严苛的场景中十分重要,比如医疗影像分析,精准的计算能帮助医生更准确地判断病情;还有金融风险评估,高精度计算有助于更可靠地预测风险 。
与之相对的是半精度(Half Precision),即使用 16 位浮点数进行模型权重存储和计算。半精度能显著减小模型大小、降低内存占用、加快数据传输并减少能耗,但可能带来精度损失。
- FP64:即双精度浮点数(Double - Precision Floating - Point),表示 GPU 在处理 64 位双精度浮点数运算时的性能指标,常用于对精度要求极高的科学计算领域。
- FP64 Tensor Core:代表 GPU 中张量核心处理双精度浮点数运算的能力。张量核心是 GPU 中专门用于加速深度学习张量运算的硬件单元,该指标体现了在深度学习场景下双精度计算的性能。
- FP32:单精度浮点数(Single - Precision Floating - Point),是 GPU 处理 32 位单精度浮点数运算的性能指标,在图形处理、一般科学计算和深度学习中较为常用。
- TF32 Tensor Core²:TF32 即 TensorFloat - 32,是 NVIDIA 推出的一种针对深度学习优化的计算格式。该指标表示 GPU 的张量核心处理 TF32 格式数据的运算能力,相比 FP32,它在保持一定精度的同时能显著提升计算速度。
- BFLOAT16 Tensor Core²:BFLOAT16 即 Brain Floating - Point 16,是一种 16 位的浮点数格式,主要用于深度学习。此指标反映了 GPU 张量核心处理 BFLOAT16 格式数据的运算能力,在深度学习训练和推理中可有效平衡精度和计算效率。
- FP16 Tensor Core²:FP16 即半精度浮点数(Half - Precision Floating - Point),该指标表示 GPU 张量核心处理 16 位半精度浮点数的运算能力,在深度学习中可以加快运算速度,减少内存占用。
- FP8 Tensor Core²:FP8 即 8 位浮点数,是一种更为紧凑的数值表示格式。此指标体现了 GPU 张量核心处理 FP8 格式数据的运算能力,有助于进一步提升计算效率和降低内存带宽需求。
- INT8 Tensor Core²:INT8 即 8 位整数,该指标表示 GPU 张量核心处理 8 位整数运算的能力。在深度学习推理阶段,INT8 量化可以在不损失太多精度的情况下大幅减少计算量和内存占用。
# TP(Tensor Parallelism)
张量并行是一种并行计算技术,用于在多个计算设备(通常是 GPU)之间并行处理张量操作。在深度学习模型中,张量(Tensor)是多维数组,像模型的权重、输入数据等都是以张量的形式存在。当模型规模非常大时,单个 GPU 的显存可能无法容纳整个模型,或者为了提高计算效率,就会采用张量并行技术。
优点
- 显存扩展:能够将大模型分布到多个 GPU 上,从而突破单个 GPU 显存的限制。
- 计算加速:多个 GPU 同时进行计算,减少了推理所需的时间。
# 性能指标
| 指标 | 解释 |
|---|---|
| max-concurrency | 最大并发数,是个限制 |
| Request throughput (req/s) | 请求吞吐量,单位是每秒请求数。表示系统在每秒内能够成功处理的请求数量 |
| throughput(output tokens/s) | 输出 token 吞吐量,单位是每秒输出 token 数 |
| Total token throughput(tok/s) | 总输入输出 token 吞吐量,单位是每秒 token 数 |
| Total token throughput (单卡 /s) | 总输入输出 token 吞吐量,单位是每单卡 token 数 |
| TTFT | 首 Token 延迟,反映服务质量 |
| Mean TPOT(Time Per Output Tokens) | 平均生成 Token 延迟,反映服务质量 |
| P99 TPOT | 第 99 百分位数的生成 Token 延迟 |
| E2E Latency(TTFT + TPOT * output_length) | 端到端时延分析 |
| IPS (VLM 场景) | image per second |
# 训练与推理
在机器学习和深度学习中,训练(Training)和推理(Inference)是两个完全不同的阶段,目标、流程和资源需求差异显著。以下是两者的核心区别:
# 一、目标与定义
| 训练 | 推理 |
|---|---|
| 目标:让模型从数据中学习规律,优化参数,使模型能对未知数据做出正确预测。本质:通过算法(如反向传播)调整模型参数,最小化损失函数。 | 目标:使用已训练好的模型,对新输入数据进行预测或推断。本质:将输入数据输入模型,输出结果(如分类标签、生成文本等)。 |
| 关键动作:输入标注数据 → 计算预测误差 → 更新参数 → 迭代优化。 | 关键动作:输入未标注数据 → 通过模型前向传播 → 输出结果。 |
# 二、数据与输入
| 训练 | 推理 |
|---|---|
| - 数据要求:必须使用标注数据(有输入和对应的正确输出)。 数据量:通常需要大量数据(如数万到数十亿样本)。 数据处理:需进行数据增强、洗牌(Shuffle)、分批(Batch)等预处理,以提升模型泛化能力。 | - 数据要求:使用未标注数据(仅需输入,无需标签)。 数据量:单次推理可能仅处理单条数据(如用户查询),或小批量数据。 数据处理:需与训练时的预处理逻辑一致(如归一化、分词等),但无需增强或洗牌。 |
# 三、计算流程与资源
| 训练 | 推理 |
|---|---|
| - 计算方向:双向计算(前向传播计算损失,反向传播更新参数)。 计算复杂度:极高,涉及大量参数梯度计算和优化(如 billions 参数的大模型)。 资源需求: ✅ 需要高性能硬件(如多 GPU/TPU 集群)、大显存(因需存储中间变量用于反向传播)。 ✅ 耗时久(小模型可能几小时,大模型如 GPT-4 需数周甚至数月)。 | - 计算方向:单向计算(仅前向传播,无需反向传播)。 计算复杂度:较低,仅需前向传播计算输出。资源需求: ✅ 硬件要求较低(可在 CPU、边缘设备或小显存 GPU 上运行)。 ✅ 耗时短(实时响应,如毫秒到秒级)。 |
# 四、模型状态与参数
| 训练 | 推理 |
|---|---|
| - 模型状态:参数可更新,处于 “学习” 状态。正则化:通常启用 Dropout、数据增强等正则化手段,防止过拟合。 输出:无直接可用结果,需通过迭代优化逐步接近目标。 | - 模型状态:参数固定不变,处于 “应用” 状态。正则化:关闭 Dropout 等训练时的正则化操作,确保输出稳定。 输出:直接生成预测结果(如文本、图像、分类标签等)。 |
# 五、应用场景举例
| 训练场景 | 推理场景 |
|---|---|
| - 训练 ChatGPT:使用海量文本数据,通过 Transformer 架构学习语言规律,优化数万亿参数。训练图像分类模型:用 ImageNet 数据集调整 CNN 参数,使模型能识别不同物体。 | - ChatGPT 回答用户问题:用训练好的模型对用户输入的文本进行前向传播,生成回答。医学影像诊断:用已训练的 AI 模型分析 CT 图像,自动检测肿瘤区域。 |
# 六、核心差异总结
| 维度 | 训练 | 推理 |
|---|---|---|
| 目的 | 学习规律,优化参数 | 应用模型,生成预测结果 |
| 数据 | 标注数据,大量且需预处理 | 未标注数据,少量或实时输入 |
| 计算方向 | 双向(前向 + 反向传播) | 单向(仅前向传播) |
| 资源消耗 | 高(大显存、长耗时、多设备) | 低(可轻量化部署) |
| 模型状态 | 参数动态更新 | 参数固定不变 |
| 典型工具 | PyTorch/TensorFlow(训练框架) | TensorRT/ONNX(推理优化工具) |
# 为什么区分训练和推理很重要?
- 资源优化:训练需昂贵的算力资源(如 GPU 集群),推理可部署在低成本设备(如手机、服务器)。
- 效率提升:推理阶段可针对前向传播优化(如模型量化、剪枝),牺牲少量精度换取速度,而训练需保留完整计算图。
- 生产落地:实际应用中,用户只关心推理速度(如实时翻译),训练通常在后台完成。
理解两者的差异有助于合理设计机器学习系统,例如:
- 训练时选择高算力框架(如 PyTorch),推理时使用轻量级引擎(如 ONNX Runtime)。
- 对大模型进行 “训练 - 推理分离” 部署,降低生产环境的资源成本。