# 微调# 开源基础大模型闭源 **** 模型局限性
缺乏灵活性 :无法定制,限制业务创新与优化。依赖供应商 :受制于第三方,存在价格波动和服务中断风险。隐私风险 :数据需上传外部,可能不符合法规要求。成本高昂 :按量计费,长期使用成本较高。
开源大模型的优势
可定制 :灵活调整,满足业务需求。低成本 :减少对高费用 API 的依赖。数据安全 :私有部署防止数据泄露,符合合规要求。
国外开源大模型:Llama,Mistral
国内开源大模型:Qwen,ChatGLM,Deepseek
微调最好在通用模型是做微调,不在行业 / 垂直大模型上做微调
大模型微调
目的:使大模型能够理解并遵循人类的指令,具备对话的能力。
数据格式:指令 (instruction)、输入 (input, 可选) 和输出 (ouitput )。
1 2 3 4 { "input(instruction)" :"根据给定的描述,生成一个创意的营销文案旨在吸引年轻人购买最新款智能手机。描述:这款手机拥有超强的摄像头和全天候的电池续航,适合喜欢拍照和玩游戏的年轻人。" , "output" :"探索无限可能!这款全新智能手机,不仅拥有顶级摄像头记录每个瞬间,还有持久电力陪伴你畅玩每一刻。立即拥有,让生活更精彩!" }
数据收集 -》 模型选择 -》 模型微调 -》 模型评估
# 数据收集通用微调数据:提供基础的通用问答能力。
领域微调数据:帮助模型更精确地理解和生成领域相关的内容。
通用数据:领域数据
微调效果
1 : 0
模型仅具备通用问答能力,无法处理领域任务。
1 : 1
模型在保持一定通用能力的同时,能够完成领域相关任务。
0 : 1
模型发生灾难性遗忘,仅能完成领域任务,丧失通用能力。
通用数据
名称
语言
数据量
数据内容
质量
alpaca_dataset
中 / 英文
52K
常规问答数据集
高
COIG
中文
191k
通用翻译指令、考试指令、代码指令数据集等
高
ShareGPT
中 / 英文
90K
中英文平行双语优质人机问答数据集
中
HC3
中 / 英文
40K/8.4K
人类真实回复结果与 ChatGPT 回复结果的 QA 数据集
中
firefly
中文
1.1M
23 种常见的中文 NLP 任务
高
ultrachat
英文
1.4M
英文多轮对话数据
中
大模型推理能力来源于代码数据和数学数据
领域数据收集
网页爬取
1、提取网页数据:确定领域相关的网页。提取网页中的标题、段落、评论等文本数据。
2、数据清洗:清理特殊字符、空格、和人名等不需要的信息,处理过长的文本。采用正则匹配、关键词过滤、人名识别模型等技术处理不需要的信息。采用语义分割小模型、自动截断等
技术处理过长的文本。
3、构建数据:提取网页中用户的问题和相关回复,填充到指令微调模板,整理成微调数据,进行人工审查和校验,确保数据质量。 将提取出来的问题填充到 instruction, 相关回复填充到 output 字段。
大模型蒸馏
1、指令设计:设计合适的指令,需要明确表达任务目标。
2、问题收集:收集领域内常用且具有代表性的问题。
3、生成回答:将指令和问题拼接在一起,作为输入,调用其它大模型生成答案。
4、构建数据:将指令、问题和答案配对,整理成微调数据集,确保数据格式规范并进行人工审查。
基于下游任务数据集构造
1、指令设计:人工编写 instruction, 需要介绍任务的具体内容 (即任务描述)
2、构造数据:将已有输入和输出的下游任务数据集,分别来匹配微调数据格式中的 input 和 output 字段。
# 基座模型选择基于领域选择:假设需要微调一个医疗领域模型。
流程:
应用场景确定:临床医疗问答,术语标准化。
确定备选模型:chatglm3-6B、qwen-7B。
测试题收集:收集 10 道临床医疗、术语标准化问题。
模型评估:收集备选模型对测试题的回复,根据回复进行打分选择得分较高的模型做基模型。
需要根据模型参数和人工打分进行均衡,参数多需要的算力也多,但是分数提升不明显的情况下效果不大。
# 模型微调全参数微调:更新模型全部参数
成本较高:nB 的模型全参微调所需显存~8nGB (包括模型参数、梯度、优化器参数等), 硬件要求苛刻
效率较低:全参数微调训练耗时较长,导致效率低下
过拟合:在数据量相对较少时,容易导致模型在训练集上表现得非常好,但在测试集或新数据上的泛化能力较差
PEFT:仅训练少量参数,大部分参数冻结
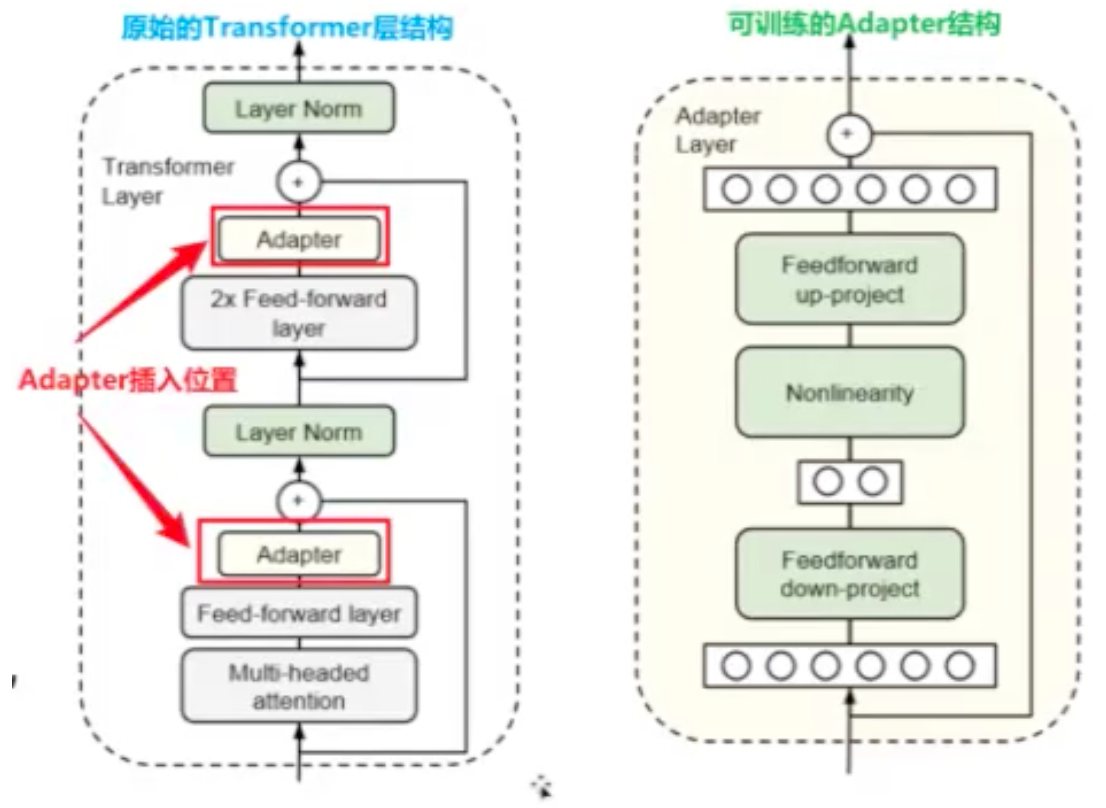
添加型方法 - 适配器 (Adapters) : 在常规 Transformer 块中插入小型、可训练的模块 (即 Adapter 层), 而不改变原模型的大部分参数
代表性方法:BNAdapter
插入位置:两个前馈层 (Feed-forward layer) 后
Adapter 架构:先通过 "down-project" 进行降维,应用激活函数,最后通过 "up-project" 投影回原始维度
添加型方法 - 软提示:在模型输入嵌入中添加可训练的张量 (软提示), 改变输入数据的表示方式,从而实现特定任务微调
代表性方法:Prefix-Tuning
Soft Prompts 做法 (u1-u5 为特殊单词):[u1][u2][u3][u4][u5] 这部电影令人振奋。
选择型方法 - 冻结 (Freeze): 冻结部分模型参数,冻结的参数部分不参与梯度计算,只训练模型的其他部分
代表性方法:Freeze
做法:模型通常由多个 Transformer 层组成,冻结前几层 Transformer 层,仅训练最后几层
科学依据:实验表明,Transformer 的浅层倾向于提取出通用特征,深层倾向于提取语义特征
重参数化方法 - 低秩适配微调:对模型参数进行特定的变换或替换,将原始的模型参数以某种形式重新表示或调整,以减少训练成本、提高训练效率
代表性方法:LoRA (目前最受欢迎的 PEFT 方法
做法:对指定参数增加额外的低秩矩阵,也就是在原始 PLM 旁边增加一个旁路,做一个降维再升维的操作
LoRA 训练参数优化效果:
数学表达:h=Wox+AWx=Wox+BAx
设置值:设原始模型参数矩阵大小 d=768, 降维的大小 r=16
参数规模:全参数 = dd=589824,Lora=768 16 (降维)+16*768 (升维)=24576
优化效果:训练参数降低为原始的 4.2%
LoRA 优势:
更长输入:不用在输入上加额外的 prompts, 能支持更长的输入 (vsSoft prompts)
无延迟:增加的参数和基座模型计算是并行的,推理时没有增加额外的延迟 (vsAdapters)
高适用性:训练完成后,可以与模型原始参数合并,合并后模模型使用代码与原始模型相同
全参数微调:适合 GPU 算力充足,大规模训练数据场景
PEFT 微调:适合 GPU 算力不足,小规模训练数据场景
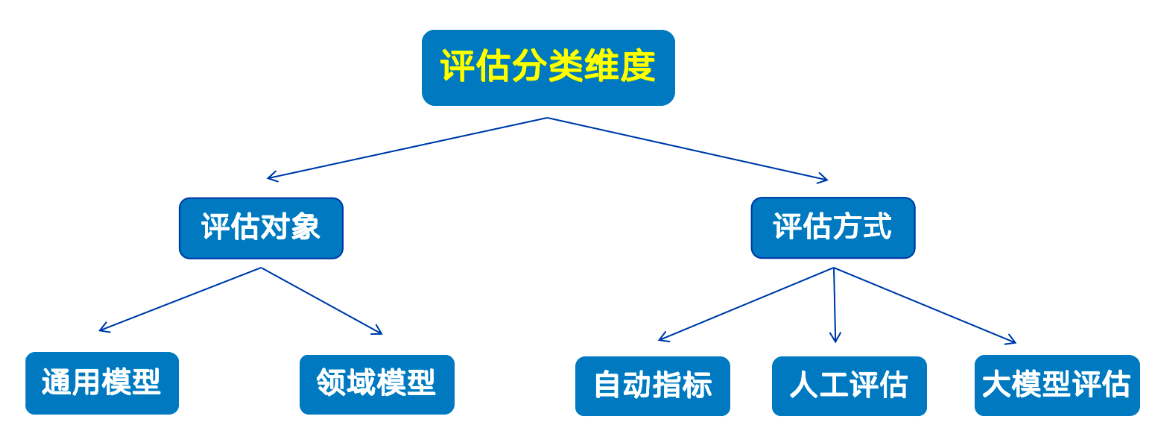
# 模型评测大语言模型评估是对模型的语言理解、生成能力、逻辑推理等多维度性能进行量化分析的过程。
通用评估
基准名称
评测目标
国家
时间
题目类型
MMLU
理解、知识
美国
2021
客观
C-Eval
理解、知识
中国
2023
客观
SOCKET
知识能力
美国
2023
主观
GAOKAO
学科能力
中国
2023
主观 / 客观
LongBench
长文本
中国
2023
主观
ToolQA
工具使用能力
中国
2023
主观
代表性通用基准
SuperCLUE
侧重点:知识技能、语言理解、安全、智能体
评测任务:文本分类、阅读理解、意图识别
题目数量:20,000+
C-Eval
侧重点:学科知识
评测任务:涵盖人文、社科、理工等 52 个
学科的官方试题
题目数量:14,000+
领域模型评测
基准名称
行业
国家
时间
题目类型
FinEval
金融
中国
2023
主观 / 客观
FINANCEBENCH
金融
美国
2023
主观
PubMedQA
医疗
美国
2019
主观 / 客观
MedBench
医疗
中国
2023
主观 / 客观
SCIBENCH
科研
美国
2023
客观
CGAEval
政务
中国
2023
主观 / 客观
开源模型评估方式
大模型生成内容的评估方式分为自动化评估、人工评估、大模型评估 。
评估方式
描述
关键指标 / 方法
适用场景
自动化评估
使用数学公式计算的自动化指标,用于量化模型输出和标准答案之间的一致性
Accuracy:分类任务准确率 BLEU:机器翻译质量 ROUGE:摘要生成质量 METEOR:翻译质量 F1 Score:文本分类 Perplexity:困惑度
单选题、文本分类、机器翻译、摘要生成
人工 / 大模型评估
使用人工或大模型对生成结果的质量进行多维度评估,更适用于主观题任务
流畅度:语言流畅性相关性:与上下文的相关性一致性:文本一致性创造性:文本创新性信息完整性:答案全面性
对话系统、创意生成任务、文本生成
场景
分类任务(如情感分析、新闻分类、垃圾邮件识别 )
信息抽取(如实体抽取、关系抽取、事件抽取 )
推荐系统(如商品推荐、电影推荐 )
常用指标
精确度 (Precision):表示分类预测是正例的结果中,确实是正例的比例
召回率 (Recall):表示所有正例样本被正确找出的比例
F1 值(F1-Score):表示精确度和召回率的调和均值
准确率(Accuracy):表示分类正确的样本占全部样本的比例
使用指南
对于单选题,通常使用准确率评估,因其反映整体分类效果。
对于异常检测,召回率更为重要,以确保尽可能多的正类被识别。
对于垃圾邮件识别,精确度更为关键,确保预测为正类的结果确实为正。
对于类别不均衡任务,F1 值更加适用,综合衡量精确度和召回率的平衡,避免偏向某一指标。
自动化评估
场景:
生成任务 (如机器翻译、文本摘要、对话系统)
常用指标:
BLEU: 计算生成文本与参考文本之间的 n-gram 重叠程度
ROUGE: 计算参考文本的 n-gram 在生成文本中的召回率
Bertscore: 基于 BERT 语言模型,计算生成文本与参考文本在嵌入空间中的相似度
使用指南:
BLEU 和 ROUGE 侧重于文本层面的相似度,常用于机器翻译和文本摘要等任务
Bertscore 更侧重于语义层面的相似度,常用于对话系统的评估
大模型评估
基于大模型的逐点评估:
定义:逐点评估是指利用大模型对生成内容逐个进行评估的过程。
流程:和人工评估类似,需要将任务说明、评估维度、评估指南、单个待评估样本一起作为 prompt 输入到大模型中,之后解析大模型的回复以获取双评分。
基于大模型的对比评估:
定义:对比评估是指对多个模型进行两两之间的多轮比较,通过评判它们的相对性能最终确定综合排名。
流程:使用大模型对比两个生成内容,评估并选择更优内容,根据评估结果为每个模型赋予相应分值。
# 模型量化总显存需求 = 模型参数显存 + 激活显存 + 优化器显存
https://apxml.com/tools/vram-calculator
精度
数据类型大小
总显存占用
全精度(FP32)
4 字节 / 参数
97GB
FP16
2 字节 / 参数
49GB
FP8
1 字节 / 参数
25GB
INT8
1 字节 / 参数
16GB
INT4
0.5 字节 / 参数
13GB
精度越低的数据占用的空间越小,但对模型效果影响会越大
目的:
参数压缩:减少模型所需的存储空间,降低模型加载时间。
计算加速:降低计算复杂度,提高模型的推理速度。
减少显存:减少显存占用,使大模型能在更小的设备上运行。
核心思想:
在尽可能不影响模型性能的前提下,将参数从高精度数值 (如 FP16,16 位浮点数) 转化为比特数更低的格式 (如 FP8,8 位浮点数), 减少存储占用和计算时间。
主要分类:
训练时量化:在训练模型时进行量化操作。通常量化效果软校好。
训练后量化:对训练后的模型进行量化操作。通常量化资源需求较小。
训练时量化:QAT
定义:在训练过程中就引入低精度运算,以确保量化后的模型性能不会下降太多。
原理:在每一轮训练中,先将权重和计算结果量化成低精度格式然后根据量化后的计算结果更新模型的参数,使得模型学会如何在低精度条件下依然保持良好的性能。
训练后量化:PTQ
定义:训练好模型后,再把参数从高精度转换成低精度,来让模型更小、计算更快。
原理:用一些示例参数来确定模型的数值范围,然后把原来的参数 "压缩" 到更小的范围。
举例:假设示例参数的输入范围在 float 型的 - 3.0 到 3.0, 我们要把它缩放到 int 型的 - 128 到 127 (对于 INT8), 可以计算出缩放比例 scale=3.0/127, 将所有参数按这个比例压缩即可。
训练后量化
定义:专用于大语言模型的量化技术。通过分析并选择性地优化数据,来减少关键部分的损失。
原理:逐层量化,在模型的每一层中找到对结果影响不太大的权重,并对其量化。然后,对该层因量化产生的误差进行补偿,来防止误差积累,保持模型的计算精度。
QAT: 在高精度场景下表现最佳,但训练成本高。
PTQ: 适合快速部署和低计算资源,但可能会影响精度。
GPTQ (最常用): 适合大规模模型,精度较高,且也比较适合快速部署和低计算资源环境,但是仅适用于语言模型。
量化效果优化 :smoothquant
引入:波动较大的参数在量化时可能会溢出导致影响量化效果。因此我们可以在量化前使用 SmoothQuant 方法来对参数作初步调整。
定义:在用 PTQ、QAT 等方法量化之前,先对参数范围做调整,让模型更容易被量化。
原理:重新分配参数的范围,使其在量化时更加均衡,从而减少少信息损失。加入 SmoothQuant 的量化推理流程:输入→平滑处理→量化处理并计算 输出
# 大模型量化推理框架BitsAndBytes
主要用于减少大模型的显存占用,并在低资源设备 (如消费级 GPU) 上进行推理或微调
如果你是新手,或在以下场景下,推荐使用 Bitsandbytes:
想在消费级显卡 (如 RTX4080/4090) 上加载大模型。
进行模型微调 (如 LoRA 微调)。
想要快速测试和研究 LLMS。
TensorRT-LLM :
NVIDIA 提供的深度学习推理优化工具,专门用于极致优化哇理性能
如果你希望在以下场景下优化部署,推荐使用 TensorRT:
生产环境,要求极低延迟和高吞吐量。
在云服务器或边缘设备上高效运行模型。
需要对模型进行深度优化,减少推理时间。
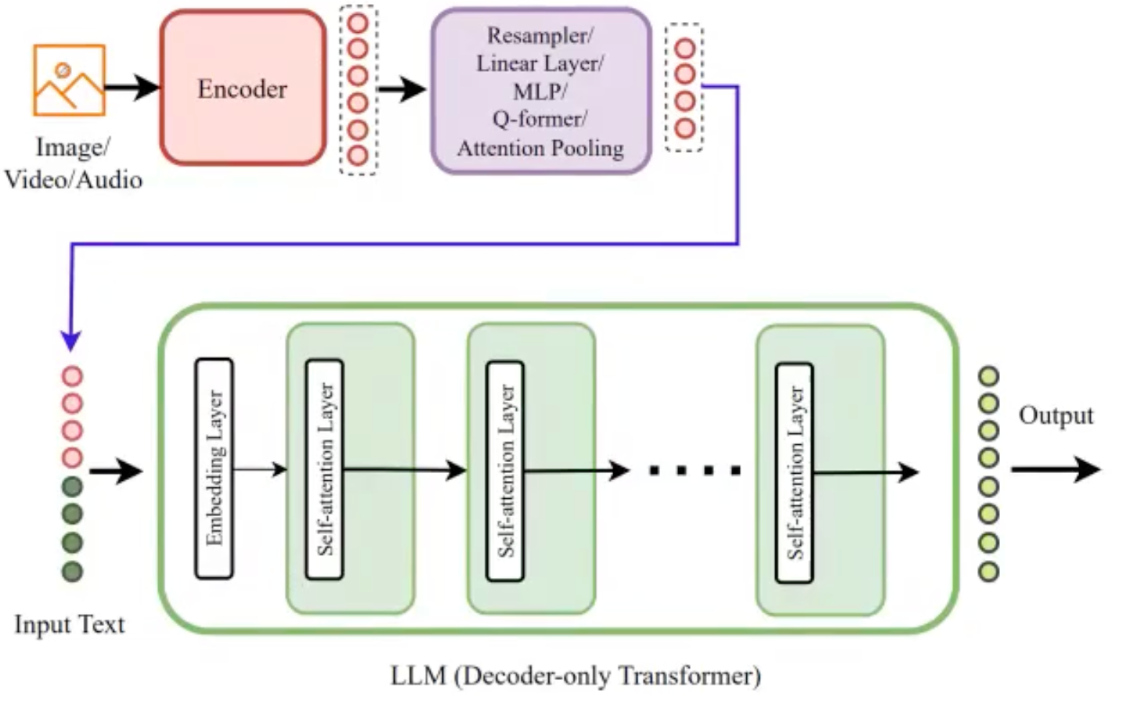
# 多模态大模型# 多模态大模型架构:核心差异:各结构之间不同的主要体现在融合的时间点以及具体的融合方法上。
模态融合时期
融合方式
案例模型
早期融合(输入阶段进行融合)
非标记化
BLIP2
早期融合(输入阶段进行融合)
非标记化
Qwen2-VL
早期融合(输入阶段进行融合)
标记化(原生)
Chameleon
深度融合(模型内部进行融合)
标准交叉注意力
Flamingo
深度融合(模型内部进行融合)
专门设计融合层
CogVLM
# 早期融合模态转换:将图片、声音等信息通过模态编码器转换为特征向量。
特征融合:经过连接层将图像特征向量转换为文本空间向量后和文本向量拼接,一起输入模型。
结果生成:模型处理后生成文本结果。
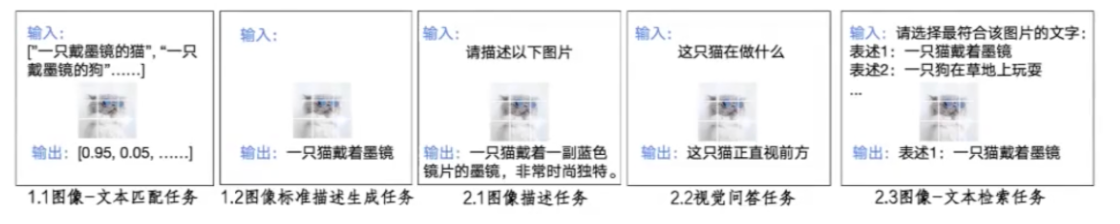
预训练阶段:训练 Qformer。有以下两种任务:
图像 - 文本匹配 (图文匹配和特征匹配)
图像 - 文本描述生成
微调阶段:训练 Qformer 和全连接层。利用自回归生成完成以下三三个任务
图像描述任务
视觉问答任务
图像 - 文本检索任务
早期融合使用比较多,其中非标记,比如 qwen2 就是
领域多模态大模型
1、先多模态再领域
训练策略:先用大量的多模态数据训练通用文本大模型,然后用少量领域图文数据训练多模态大模型
典型案例:LLaVA-Med;Med-Flamingo
2、先领域再多模态:
训练策略:文本大模型 + 领域文本数据 = 领域大模型 + 领域图文数据 = 领域多模态
典型案例:RadFM
总结:先领域再多模态训练需要大量领域数据,适合处理领域内多任务的场景;先多模态再领域训练对领域数据需求较少,更适合解决特定领域内的单一任务。
# finetune微调作为一种技术手段,是在已具备广泛知识基础的大型预训练语言模型上,利用针对性的数据集实施额外的训练过程,旨在使模型更精准地契合特定任务需求或深入某一专业领域。微调的核心目标在于实现知识的精细化灌输与指令系统的精确匹配 。
SFT 的理论基础之一是迁移学习(Transfer Learning)。迁移学习是指将一个领域(源领域)中学到的知识应用到另一个领域(目标领域)中。在 SFT 中,预训练模型在源领域(通常是大规模无标签数据)上进行了训练,而微调过程则是在目标领域(特定任务的有标签数据)上进行的。通过迁移学习,模型可以将源领域的知识迁移到目标领域,从而提高目标任务的性能。
在 SFT 过程中,损失函数的选择和优化算法的使用对模型的性能有着重要影响。常用的损失函数包括交叉熵损失、均方误差损失等,具体选择取决于任务类型。优化算法则通常采用随机梯度下降(SGD)或其变种(如 Adam、RMSprop 等),通过迭代更新模型参数,最小化损失函数。
微调策略包括学习率设置、批量大小选择、训练轮数等。学习率是微调过程中最重要的超参数之一,过高的学习率可能导致模型无法收敛,过低的学习率则可能导致训练速度过慢。批量大小和训练轮数的选择也需要根据具体任务进行调整,以达到最佳的训练效果。
为了防止模型过拟合,SFT 过程中通常采用正则化技术,如 L2 正则化、Dropout 等。此外,早停(Early Stopping)也是一种常用的防止过拟合的方法,通过在验证集上监控模型性能,当性能不再提升时提前停止训练。
监督式微调包括以下几个步骤:
预训练: 首先在一个大规模的数据集上训练一个深度学习模型,例如使用自监督学习或者无监督学习算法进行预训练;微调: 使用目标任务的训练集对预训练模型进行微调。通常,只有预训练模型中的一部分层被微调,例如只微调模型的最后几层或者某些中间层。在微调过程中,通过反向传播算法对模型进行优化,使得模型在目标任务上表现更好;评估: 使用目标任务的测试集对微调后的模型进行评估,得到模型在目标任务上的性能指标。
大模型的 SFT(Supervised Fine-Tuning)方式主要包括以下几种:
全参数微调(Full Parameter Fine Tuning) :全参数微调涉及对模型的所有权重进行调整,以使其完全适应特定领域或任务。这种方法适用于拥有大量与任务高度相关的高质量训练数据的情况,通过更新所有参数来最大程度地优化模型对新任务的理解和表现。
原理:更新预训练模型的所有参数(包括 Transformer 的所有层、注意力机制等)。
优点:理论上能最大化模型对特定任务的适配能力,尤其适合数据量大、任务差异显著的场景。
缺点:计算资源消耗极大(需存储所有参数的梯度),易过拟合,需大量训练数据。
部分参数微调 (Sparse Fine Tuning / Selective Fine Tuning):部分参数微调策略仅选择性地更新模型中的某些权重,尤其是在需要保留大部分预训练知识的情况下。这包括:
LoRA(Low-Rank Adaptation):通过向模型权重矩阵添加低秩矩阵来进行微调,既允许模型学习新的任务特定模式,又能够保留大部分预训练知识,从而降低过拟合风险并提高训练效率。
原理:通过低秩矩阵分解近似参数更新,仅训练分解后的矩阵。
优点:参数量少(如 7B 模型仅需约 4MB 可训练参数),支持快速部署。
P-tuning v2:这是一种基于 prompt tuning 的方法,仅微调模型中与 [prompt] 相关的部分参数(例如,额外添加的可学习 prompt 嵌入),而不是直接修改模型主体的权重。
QLoRA:可能是指 Quantized Low-Rank Adaptation 或其他类似技术,它可能结合了低秩调整与量化技术,以实现高效且资源友好的微调。
冻结(Freeze)监督微调 :在这种微调方式中,部分或全部预训练模型的权重被冻结(即保持不变不再训练),仅对模型的部分层(如最后一层或某些中间层)或新增的附加组件(如任务特定的输出层或注意力机制)进行训练。这样可以防止预训练知识被过度覆盖,同时允许模型学习针对新任务的特定决策边界。
优点:减少训练参数,降低计算成本,缓解过拟合。
缺点:可能限制模型对复杂任务的适应能力,需人工选择冻结层。
原理:冻结预训练模型的底层(通常是前几层,负责基础语言理解),只训练顶层或特定模块。
原文链接:https://blog.csdn.net/qq_46094651/article/details/142457139
在进行领域任务的 SFT 的时候我们通常会有以下训练模式进行选择,根据领域任务、领域样本情况、业务的需求我们可以选择合适的训练模式。
模式一:基于 base 模型 + 领域任务的 SFT;
模式二:基于 base 模型 + 领域数据 continue pre-train + 领域任务 SFT;
模式三:基于 base 模型 + 领域数据 continue pre-train + 通用任务 SFT + 领域任务 SFT;
模式四:基于 base 模型 + 领域数据 continue pre-train + 通用任务与领域任务混合 SFT;
模式五:基于 base 模型 + 领域数据 continue pre-train(混入 SFT 数据) + 通用任务与领域任务混合 SFT;
模式六:基于 chat 模型 + 领域任务 SFT;
模式六:基于 chat 模型 + 领域数据 continue pre-train + 领域任务 SFT
会采用直接使用 python 的 transformer 包和 LLama-Factory 进行微调
# 环境准备1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 3.10 .x python --version pip install torch==2.4 .1 torchvision==0.19 .1 torchaudio==2.4 .1 -f https: pip install transformers jsonlines openpyxl modelscope pandas tqdm bert-score datasets git clone --depth 1 https: cd LLaMA-Factory pip install -e ".[metrics]" -i https: # 使用jupyter时需要注册内核 pip install ipykernel python -m ipykernel install --name llamafactory --display-name "llamafactory" # 模型下载, Qwen2.5 用于微调,bert用于微调后评测 modelscope download --model Qwen/Qwen2.5 -0.5 B-Instruct --local_dir ../model/Qwen2.5 -0.5 B-Instruct modelscope download --model tiansz/bert-base-chinese --local_dir ../model/bert-base-chinese
# 指令微调格式指令微调数据通常采用 JSON 或 JSONL 格式,每个样本 (item) 的基本格式为包含以下字段
instruction: 描述任务要求或问题,明确指令的目的。
input: 具体输入内容,可选 (例如给定文本,给定标题)。
output: 期望的回复或答案。
注意:现在为了保持灵活性,通常将任务描述与输入内容一起放在 instruction 中,设置 input 字段为空
1 2 3 4 5 { "instruction" : "将以下英文翻译成中文。\nHillo,how are yyou?" "input" : "" , "output" : "你好,你好吗?" }
“将以下英文翻译成中文。\nHello, how are you?”(输入在后)
“Hello, how are you?\n 将以下英文翻译成中文。”(输入在前)
“翻译任务 \n 原文本:Hello, how are you?\n 目标语言:中文。”(输入在中间)
1 2 3 4 5 6 7 8 9 10 # 多轮对话 { "instruction" : "你觉得今天的天气怎么样?" , "input" : "" , "output" : "我觉得今天天气很好。" , "history" : [ { "role" : "user" , "content" : "你好!" } , { "role" : "assistant" , "content" : "你好!有什么可以帮你的吗?" } ] }
数据在转换为指令形式时,通常会加入一些特殊符号,其目的主要有三个方面
1. 任务标记:表示当前是问答任务,而非预训练的续写任务。
2. 划分每一轮对话的边界:方便模型理解对话的结构与上下文切换
3. 表明每一轮的说话主体:指示某一句是用户发问还是模型回复
在实际应用中,很多环境已经内置了大量模型的指令模板,可以直接调用,例如使用 tokenizer.apply_chat_template 来转换原始数据为目标格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import jsonfrom transformers import AutoTokenizermodel_path = './model/Qwen2.5-0.5B-Instruct' tokenizer = AutoTokenizer.from_pretrained(model_path) print ('tokenizer加载完成' )print ('一个单轮对话样例测试' )data = { "instruction" : "将以下英文翻译成中文。\nHello, how are you?" , "input" : "" , "output" : "你好,你好吗?" } messages = [ {"role" : "user" , "content" : data['instruction' ]}, {"role" : "assistant" , "content" : data['output' ]} ] chat_template = tokenizer.apply_chat_template( messages, add_generation_prompt= False , tokenize=False ) print ('转换后的数据:\n{}' .format (chat_template))转换后的数据: <|im_start|>system You are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|> <|im_start|>user 将以下英文翻译成中文。 Hello, how are you?<|im_end|> <|im_start|>assistant 你好,你好吗?<|im_end|>
1.<|im_start|>/<|im_end|> 标记对话边界
2.user/assistant 区分对话角色
测试是否使用 apply_chat_template 的效果
- 不转换成模板:模型通常进行续写任务,尝试基于当前的内容进行续写 或补充
- 转换成模板:模型通常进行问答任务,尝试回答问题
# 数据处理一共下载三份数据集,用于微调医疗领域大模型
Chinese-medical-dialogue:医疗对话数据集
norm:临床术语标准化数据集
IMCS-V2-MRG:报告生成
数据下载
1 2 3 4 5 6 7 8 9 10 modelscope download --dataset xiaofengalg/Chinese-medical-dialogue --local_dir ../dataset/Chinese-medical-dialogue modelscope download --dataset xueqiao111/IMCS-V2-MRG --local_dir ../dataset/IMCS-V2-MRG unzip ../dataset/IMCS-V2-MRG/IMCS-V2-MRG.zip -d ../dataset/IMCS-V2-MRG cd ..cd datasetwget http://data.openkg.cn/dataset/99e3fa10-c5f3-4af8-b147-fe689e67e260/resource/01424eb2-b5e6-441e-9c90-216079343d8d/download/yidu-n7k.zip unzip ./yidu-n7k.zip -d ./yidu-n7k mv yidu-n7k.zip ./yidu-n7k/mkdir output_dir = './dataset/sft_dataset'
# 处理医疗对话数据1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import jsonimport randomrandom.seed(42 ) dataset_name = 'dialog' read_file = './dataset/Chinese-medical-dialogue/data/train_0001_of_0001.json' with open (read_file, 'r' ) as f: datas = json.load(f) ''' {'instruction': '孕妇感冒发烧38度应该怎么办呢', 'input': '我怀孕了我的身体最近变得很差,现在我总是感冒发烧非常的严重。最近一次发烧38度,我感觉头非常的疼痛又不敢打针吃药,现在非常得难受痛苦.想得到怎样的帮助:孕妇感冒发烧38度应该怎办的呢?', 'output': '孕妇发烧时,要寻出发烧的病因,对症下药,若是一般由感冒引来的发烧,不论对妈妈或胎儿而言,预后应该是很好的。孕妇若必须动用药物,必须考量药物对胎儿健康的干扰,因此必须与妇产科医师充分谈论后再动用。可以物理降温,把毛巾放到装温水的盆中,然后把水拧出,全身擦试,特别是额头、手臂弯,大腿根部,手脚心处擦试,这样效果会很好的,要多喝生姜和大枣熬的热水,然后消肿。以上是对“孕妇感冒发烧38度应当怎办的呢?”这个问题的建议,期望对您有协助,祝您健康!', 'history': None } ''' random.shuffle(datas) datas = datas[:5000 ] processed_datas = [] for data in datas: inp = '主题:{}\n内容:{}' .format (data['instruction' ], data['input' ]) processed_data = { 'instruction' : inp, 'input' :'' , 'output' : data['output' ] } processed_datas.append(processed_data) print ('全部数据量:{}' .format (len (processed_datas)))with jsonlines.open (os.path.join(output_dir, '{}_train.jsonl' .format (dataset_name)), 'w' ) as f: for data in processed_datas: f.write(data) max_len = 0 for data in processed_datas: now_len = len (tokenizer(data['instruction' ]+'\n' +data['output' ])['input_ids' ]) if now_len > max_len: max_len = now_len print ('最大长度为:{}' .format (max_len))
# 临床术语标准处理1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 import pandas as pdread_files = [ './dataset/yidu-n7k/train.xlsx' ,'./dataset/yidu-n7k/val.xlsx' ] out_types = [ 'train' , 'test' ] ''' |原始词|标准词| |---|---| |右侧甲状腺叶切除术|单侧甲状腺叶切除术| ''' pd.read_excel('./dataset/yidu-n7k/train.xlsx' ) dataset_name = 'norm' prompt = '''你是一个医疗专家,你的任务是临床术语标准化。 具体来说,针对给出的通用语,转换为相应的标准化医学术语,确保转换后的内容符合医学专业标准,直接输出转换后的临床标准术语。 原始词:{word} 该词的标准术语为:''' for read_file, out_type in zip (read_files, out_types): processed_datas = [] datas = pd.read_excel(read_file) for i in range (datas.shape[0 ]): before_word = datas.iloc[i,0 ] after_word = datas.iloc[i,1 ] instruction = prompt.format (word = before_word) output = after_word processed_data = { 'instruction' : instruction, 'input' : '' , 'output' : output } processed_datas.append(processed_data) if out_type == 'train' : processed_datas = processed_datas[:5000 ] else : processed_datas = processed_datas[:100 ] with jsonlines.open (os.path.join(output_dir, '{}_{}.jsonl' .format (dataset_name, out_type)), 'w' ) as f: for data in processed_datas: f.write(data) max_len = 0 for read_file, out_type in zip (read_files, out_types): with jsonlines.open (os.path.join(output_dir, '{}_{}.jsonl' .format (dataset_name, out_type)), 'r' ) as f: processed_datas = [data for data in f] for data in processed_datas: now_len = len (tokenizer(data['instruction' ]+'\n' +data['output' ])['input_ids' ]) if now_len > max_len: max_len = now_len print ('最大长度为:{}' .format (max_len))
# 病例报告生成1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 read_files = [ './dataset/IMCS-V2-MRG/IMCS-V2-MRG/IMCS-V2_train.json' ,'./dataset/IMCS-V2-MRG/IMCS-V2-MRG/IMCS-V2_dev.json' ,] out_types = [ 'train' , 'test' ] '' ' { ' dialogue': [{' sentence_id': ' 1', ' speaker': ' 医生', ' sentence': ' 你好,咳嗽是连声咳吗?有痰吗?有没流鼻涕,鼻塞?', ' dialogue_act': ' Request-Symptom', ' BIO_label': ' O O O B-Symptom I-Symptom O O O B-Symptom O O O B-Symptom O O O O B-Symptom I-Symptom I-Symptom O B-Symptom I-Symptom O', ' symptom_norm': [' 咳嗽', ' 咳嗽', ' 痰', ' 鼻流涕', ' 鼻塞'], ' symptom_type': [' 1', ' 1', ' 0', ' 2', ' 0'], ' local_implicit_info': {' 咳嗽': ' 1', ' 痰': ' 0', ' 鼻流涕': ' 2', ' 鼻塞': ' 0'}}, {' sentence_id': ' 2', ' speaker': ' 医生', ' sentence': ' 咳嗽有几天了?', ' dialogue_act': ' Request-Symptom', ' BIO_label': ' B-Symptom I-Symptom O O O O O', ' symptom_norm': [' 咳嗽'], ' symptom_type': [' 1'], ' local_implicit_info': {' 咳嗽': ' 1'}}, ...... ], ' report': [{' 主诉': ' 晚上咳嗽,磨牙。', ' 现病史': ' 患儿夜间咳嗽三天,磨牙,大便干。未服用药物。', ' 辅助检查': ' 暂缺。', ' 既往史': ' 不详。', ' 诊断': ' 消化不良。', ' 建议': ' 小儿消积止咳口服液,益生菌,到医院化验血常规。'}, {' 主诉': ' 咳嗽、磨牙3天。', ' 现病史': ' 患儿3天前出现夜间咳嗽、磨牙,无发热、咳痰、流涕等症状,未诊治。', ' 辅助检查': ' 暂缺。', ' 既往史': ' 否认过敏史。', ' 诊断': ' 考虑消化不良。', ' 建议': ' 口服消积止咳药物3天,若无好转需查血常规。'}] } ' '' dataset_name = 'mrg' prompt = '' '问诊对话历史: {dialog} 根据上述对话,给出诊疗报告 说明:诊疗报告分为主诉, 现病史, 辅助检查, 既往史, 诊断, 建议这六个章节,以标准的json格式输出。 答:' '' for read_file, out_type in zip(read_files, out_types): processed_datas = [] with open(read_file, 'r' ) as f: datas = json.load(f) for data in datas.values(): dialog = data['dialogue' ] dialog = ['{}:{}' .format(item['speaker' ],item['sentence' ]) for item in dialog] instruction = prompt.format(dialog = '\n' .join (dialog)) output = json.dumps(data['report' ][0], ensure_ascii = False,indent=2) processed_data = { 'instruction' : instruction, 'input' : '' , 'output' : output } processed_datas.append(processed_data) if out_type == 'train' : processed_datas = processed_datas[:5000] else : processed_datas = processed_datas[:100] with jsonlines.open(os.path.join(output_dir, '{}_{}.jsonl' .format(dataset_name, out_type)), 'w' ) as f: for data in processed_datas: f.write(data) max_len = 0 for read_file, out_type in zip(read_files, out_types): with jsonlines.open(os.path.join(output_dir, '{}_{}.jsonl' .format(dataset_name, out_type)), 'r' ) as f: processed_datas = [data for data in f] for data in processed_datas: now_len = len(tokenizer(data['instruction' ]+'\n' +data['output' ])['input_ids' ]) if now_len > max_len: max_len = now_len print ('最大长度为:{}' .format(max_len))
将数据集格式化,并分为 train set 和 test set
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 { "instruction" : "问诊对话历史:\n医生:你好\n医生:在吗\n患者:这个粑粑正常吗?\n医生:从你发的图片看,这个孩子的大便有点稀,大便当中有粘液\n患者:不正常的话和吃的奶粉有关吗\n医生:最主要的问题就是大便当中有粘液,需要进行大便常规的检查\n医生:跟奶粉关系不是特别的大\n医生:这个孩子使用这种奶粉多长时间了\n患者:那是怎么回事啊\n医生:现在这个孩子的年龄多大了\n医生:需要考虑消化功能不良所引起的\n患者:刚开始没多久四十天\n医生:每天大便几次啊\n患者:四五次吧\n医生:这个年龄段的孩子出现这种大便,首先应该考虑的就是吃奶过多,另外还需要注意妈妈的饮食\n医生:有没有进行大便常规的检查\n医生:需要进行大便常规的检查,主要是看一下大便当中有没有炎症\n医生:如果大便当中没有炎症,那就应该考虑单纯的消化功能不良\n患者:我这两天吃了海鲜还有辣的\n患者:他每次都要吃不给就哭\n医生:可能与这个有关系的\n患者:我还听到肚子咕咕的\n医生:这就是肠蠕动更快的声音呢\n医生:妈妈尽可能避免吃海鲜辛辣刺激的食物\n患者:那这个情况我该怎么办要去医院吗\n医生:吃这些食物就会影响奶的质量,就会导致这个孩子出现拉肚子\n医生:这个孩子需要到医院进行大便常规的检查\n医生:如果大便当中没有炎症,那就应该问题不大的\n医生:可以给孩子口服思密达保护肠粘膜,妈咪爱改善肠道微生态环境\n患者:好的谢谢你医生要对宝宝做什么吗\n医生:应该给孩子采用少量多次的喂养方式,适当的按摩腹部,改善胃肠功能\n患者:好的知道了谢谢\n根据上述对话,给出诊疗报告\n说明:诊疗报告分为主诉, 现病史, 辅助检查, 既往史, 诊断, 建议这六个章节,以标准的json格式输出。\n答:" , "input" : "" , "output" : "{\n \"主诉\": \"稀便,便中有粘液。\",\n \"现病史\": \"患儿出现稀便,每天大便次数为四五次。\",\n \"辅助检查\": \"暂缺。\",\n \"既往史\": \"不详。\",\n \"诊断\": \"消化不良。\",\n \"建议\": \"思密达,妈咪爱,粪便常规检查。\"\n}" } { "instruction" : "问诊对话历史:\n医生:您好,宝宝现在体温正常了吗?\n医生:宝宝嗓子哑吗?有没有气喘?什么时候咳嗽频繁?\n患者:现在正常了\n医生:好的\n患者:有气揣\n医生:睡眠怎么样?\n患者:睡不好\n医生:夜间咳嗽吗?有没有呼吸困难?\n患者:输了液之后晚上到是不太咳嗽了\n医生:宝宝精神怎么样?身上有没有皮疹?\n患者:精神不太好,身上没有皮疹\n医生:宝宝最近有没有呛到?起过湿疹吗?\n患者:没有\n医生:医生给宝贝诊断的什么疾病?\n患者:支气管炎\n医生:是毛细支气管炎,还是支气管炎?\n医生:现在是住院治疗吗?\n患者:看了两个医生一个说是毛细支气管炎,一个说是支气管炎到支气管肺炎之间\n患者:没有住院\n医生:嗯嗯,现在还输液吗?\n患者:明天还要输一次\n患者:但我觉得没效果,要怎么办\n医生:宝宝咳嗽比之前是减轻了吧?\n患者:恩\n患者:减轻了\n患者:但痰还是严重\n医生:嗯呢,一般输液三天看效果\n医生:宝宝支气管炎是一星期左右疗程,治疗是控制感染,解痉平喘止咳化痰治疗。\n患者:他这个是不是细菌感染了呢\n医生:宝宝白细胞增多,中性粒细胞增高提示有细菌感染\n患者:那他这个大概要多久才能好\n医生:现在宝宝用的都是什么药呢?\n患者:盐酸氨溴索\n医生:这个是化痰药\n医生:还有吗?\n患者:还有桔贝合剂\n医生:这个是中成药止咳化痰\n患者:氨茶碱片\n医生:这个是平喘药物\n患者:那还需要用什么药呢\n医生:输液是什么?_?\n医生:克林霉素就是控制感染的哦,喜炎平是止咳化痰的\n患者:谢谢了\n医生:积极配合医生治疗,跟医生多沟通孩子病情。\n医生:注意清淡饮食,给宝贝多喝水,避免呛咳\n根据上述对话,给出诊疗报告\n说明:诊疗报告分为主诉, 现病史, 辅助检查, 既往史, 诊断, 建议这六个章节,以标准的json格式输出。\n答:" , "input" : "" , "output" : "{\n \"主诉\": \"喉咙有痰,咳嗽,发烧。\",\n \"现病史\": \"患儿十天前出现喉咙有痰,后出现咳嗽,发烧。 现服用桔贝合剂,盐酸氨溴索、氨茶碱片,输液克林霉素和喜炎平。\",\n \"辅助检查\": \"血常规。\",\n \"既往史\": \"不详。\",\n \"诊断\": \"小儿支气管炎。\",\n \"建议\": \"继续输液,配合医生治疗,注意饮食。\"\n}" } { "instruction" : "问诊对话历史:\n医生:你好,发热不,小便量多不\n患者:不发热,小便量也不多\n医生:恩,用布拉氏酵母菌片和思密达\n医生:思密达严格按说明服用\n医生:和其他药间隔2小时\n患者:我用思密达了但是没用呀\n患者:一天一袋分三次服用\n医生:思密达这是肠粘膜保护剂,还需要布拉氏改善肠道菌群\n医生:一次一袋,50ml水冲服,喝多少是多少\n患者:用了两天没用,今天给用了鞣酸蛋白酵母散和双歧杆菌四联活菌片\n医生:建议查大便常规,看是否有感染,再考虑怎么用抗生素\n医生:用布拉氏酵母菌和思密达\n患者:两个配合吃?先吃思密达两小时后吃酵母菌?\n医生:对\n患者:那今天先吃上,一天能有改善吗?\n医生:没有那么快,疾病前3到5天是发展期\n患者:还是得观察多长时间?\n患者:今天吃上,明天如果还不行再去查大便常规?\n医生:最多2天\n医生:还需要查大便常规,看有没有感染\n医生:如果没有感染,就这么处理就可以\n医生:如果有感染,还需要抗感染\n患者:好的,谢谢\n根据上述对话,给出诊疗报告\n说明:诊疗报告分为主诉, 现病史, 辅助检查, 既往史, 诊断, 建议这六个章节,以标准的json格式输出。\n答:" , "input" : "" , "output" : "{\n \"主诉\": \"腹泻3天。\",\n \"现病史\": \"患儿腹泻3天,大便次数多,黄便偶伴有奶瓣。现服用丁桂儿脐贴和思密达蒙脱石散。\",\n \"辅助检查\": \"暂缺。\",\n \"既往史\": \"不详。\",\n \"诊断\": \"腹泻待查。\",\n \"建议\": \"布拉氏酵母菌片,思密达,大便常规。\"\n}" } { "instruction" : "问诊对话历史:\n医生:你好,家长宝宝的咳嗽情况怎么样?多大的孩子\n患者:3岁了,不怎么咳了,有痰\n医生:白天咳还是晚上咳啊\n医生:没有鼻塞流鼻涕打喷嚏呀\n患者:没有,白天晚上都会\n医生:雾化不是公用的呀,都有消毒的,这个不要担心。\n患者:咳的不算厉害\n患者:能消毒干净啊,镇上的卫生院\n医生:咳嗽有痰没有鼻塞流鼻涕打喷嚏的情况考虑是支气管炎,痰是炎症的分泌物。\n患者:现在一般不都是一次性管子了吗,怎么还有这种公用的\n医生:医院应该消毒就是干净的呀。\n医生:现在一般的都是自己买一个,如果没有的话,公用的,也会进行消毒。\n患者:卫生院也算是医院吧\n医生:嗯嗯\n患者:那里没有自己买的\n医生:那就没有关系啊,他们肯定会消毒的,只要是看病的地方消毒都会做到的。\n医生:不要担心。\n患者:所以我听到心里都难受的不行,就怕不干净,得什么传染病\n医生:理解\n医生:还没有听说雾化有过传染,那确实嘛,以前是集体消毒,现在都是每人买一个。\n患者:好的,谢谢医生\n医生:那现在咳嗽有痰,加强保暖,多喝水,勤拍背。\n医生:可以口服一点消炎药和化痰止咳药。\n根据上述对话,给出诊疗报告\n说明:诊疗报告分为主诉, 现病史, 辅助检查, 既往史, 诊断, 建议这六个章节,以标准的json格式输出。\n答:" , "input" : "" , "output" : "{\n \"主诉\": \"咳嗽两天。\",\n \"现病史\": \"患儿咳嗽两天,做过雾化。\",\n \"辅助检查\": \"暂缺。\",\n \"既往史\": \"不详。\",\n \"诊断\": \"咳嗽待查。\",\n \"建议\": \"消炎药,化痰止咳药,保暖,多喝水,勤拍背。\"\n}" } { "instruction" : "你是一个医疗专家,你的任务是临床术语标准化。\n具体来说,针对给出的通用语,转换为相应的标准化医学术语,确保转换后的内容符合医学专业标准,直接输出转换后的临床标准术语。\n原始词:横结肠造口还纳术\n该词的标准术语为:" , "input" : "" , "output" : "横结肠造口闭合术" } { "instruction" : "你是一个医疗专家,你的任务是临床术语标准化。\n具体来说,针对给出的通用语,转换为相应的标准化医学术语,确保转换后的内容符合医学专业标准,直接输出转换后的临床标准术语。\n原始词:右肾上腺巨大肿瘤切除术\n该词的标准术语为:" , "input" : "" , "output" : "肾上腺病损切除术" } { "instruction" : "你是一个医疗专家,你的任务是临床术语标准化。\n具体来说,针对给出的通用语,转换为相应的标准化医学术语,确保转换后的内容符合医学专业标准,直接输出转换后的临床标准术语。\n原始词:左侧单侧乳房根治性切除术\n该词的标准术语为:" , "input" : "" , "output" : "单侧根治性乳房切除术" } { "instruction" : "主题:孕妇感冒发烧38度应该怎么办呢\n内容:我怀孕了我的身体最近变得很差,现在我总是感冒发烧非常的严重。最近一次发烧38度,我感觉头非常的疼痛又不敢打针吃药,现在非常得难受痛苦.想得到怎样的帮助:孕妇感冒发烧38度应该怎办的呢?" , "input" : "" , "output" : "孕妇发烧时,要寻出发烧的病因,对症下药,若是一般由感冒引来的发烧,不论对妈妈或胎儿而言,预后应该是很好的。孕妇若必须动用药物,必须考量药物对胎儿健康的干扰,因此必须与妇产科医师充分谈论后再动用。可以物理降温,把毛巾放到装温水的盆中,然后把水拧出,全身擦试,特别是额头、手臂弯,大腿根部,手脚心处擦试,这样效果会很好的,要多喝生姜和大枣熬的热水,然后消肿。以上是对“孕妇感冒发烧38度应当怎办的呢?”这个问题的建议,期望对您有协助,祝您健康!" } { "instruction" : "主题:女性患上输卵管性不孕不育症怎么办?\n内容:女性患上输卵管性不孕不育症怎么办?去北京燕竹医院治疗怎么样?" , "input" : "" , "output" : "您好:这可以明确了病情后及时有针对性治疗即可,祝您健康!E" } { "instruction" : "主题:怎么用排卵纸测孕\n内容:本人下体特别痒,而且内衣上总是黄黄的,怎么回事?请问怎么用排卵纸测孕" , "input" : "" , "output" : "用排卵试纸测不能测怀孕的,建议月经推迟一周后查一下血HCG看看,确定是否怀孕,或者在月经推迟一周后用早孕试纸试一下,一般能确定是否怀孕,你好,胎动一般会在怀孕4个月到5个月之间出现。胎儿这个时间会在母体内出现蹬腿、伸臂、转身、眨眼、吞咽等动作" }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 import osos.environ['CUDA_VISIBLE_DEVICES' ] = '0' import jsonfrom transformers import ( AutoTokenizer, AutoModelForCausalLM, Seq2SeqTrainer, Seq2SeqTrainingArguments, DataCollatorForSeq2Seq ) from datasets import Datasetimport torchimport jsonlinesmodel_path = './model/Qwen2.5-0.5B-Instruct' tokenizer = AutoTokenizer.from_pretrained(model_path, padding_side = 'left' ) model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype = torch.bfloat16, device_map = 'auto' ) data_files = [ './dataset/sft_dataset/dialog_train.jsonl' , './dataset/sft_dataset/norm_train.jsonl' , './dataset/sft_dataset/mrg_train.jsonl' , ] all_datas = [] for data_file in data_files: print ('加载数据集:{}' .format (data_file)) with jsonlines.open (data_file, 'r' ) as f: datas = [data for data in f] print (len (datas)) all_datas.extend(datas) print ('全部数据数量:{}' .format (len (all_datas)))def preprocess_example (example ): """ 利用 tokenizer.apply_chat_template 构造 prompt_text 和 full_text: 整条数据为 instruction + output, 然后将 prompt 部分的 label 置为 -100,这样只用剩余的output部分计算损失。 """ messages = [ {'role' :'user' , 'content' : example['instruction' ]} ] prompt_ids = tokenizer.apply_chat_template( messages, add_generation_prompt=True , tokenize = True ) messages = [ {'role' :'user' , 'content' : example['instruction' ]}, {'role' :'assistant' , 'content' : example['output' ]}, ] label_ids = tokenizer.apply_chat_template( messages, add_generation_prompt=False , tokenize = True ) prompt_length = len (prompt_ids) input_ids = label_ids.copy() label_ids[:prompt_length] = [-100 ] * prompt_length tokenized = {} tokenized["input_ids" ] = input_ids tokenized["labels" ] = label_ids return tokenized dataset = Dataset.from_list(all_datas) processed_dataset = dataset.map (preprocess_example, remove_columns=list (dataset[0 ].keys())) print ("处理完成。" )data_collator = DataCollatorForSeq2Seq(tokenizer, model=model) training_args = Seq2SeqTrainingArguments( output_dir=None , save_strategy = 'no' , num_train_epochs=2.0 , per_device_train_batch_size=1 , gradient_accumulation_steps=8 , learning_rate = 1e-4 , logging_steps=100 , bf16=True , ) trainer = Seq2SeqTrainer( model=model, args=training_args, train_dataset=processed_dataset, data_collator=data_collator, tokenizer=tokenizer, ) trainer.train() trainer.save_model("./model/finetune/Qwen2.5-0.5B_med_2" )
Swift 工具
LLaMA-Factory 工具
适合人群
有一定模型训练相关经验
没有模型训练相关经验,需要快速上手对模型进行微调,提供可视化操作页面
微调效率
追求极致的微调速度和内存使用效率,需要快速微调可选择此工具。
微调速度较慢,内存使用较高
适用模型
针对 LLaMA 优化,效果更佳
适用于大部分模型,若有微调多个模型需求,可选择此工具
部署与测试
未提供快速部署测试工具
提供一键式部署测试工具,若有快速测试需求,可选择此工具
维护效率
工具更新较慢
工具更新较快,若要微调最新大模型,一般选择此工具
https://swift.readthedocs.io/zh-cn/latest/Instruction/ 推理和部署.html
# 使用 LLama-factory 实现https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
https://llamafactory.readthedocs.io/zh-cn/latest/advanced/trainers.html
https://llamafactory.cn/vscode-debug-llm.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 在`LLaMA-Factory`的`data`目录下,修改`dataset_info.json`文件,将处理后的数据集加入 { , "med_dialog" : { "file_name" : "/ai/deployment/20250417/dataset/sft_dataset/dialog_train.jsonl" } , "med_norm" : { "file_name" : "/ai/deployment/20250417/dataset/sft_dataset/norm_train.jsonl" } , "med_mrg" : { "file_name" : "/ai/deployment/20250417/dataset/sft_dataset/mrg_train.jsonl" } }
创建.sh 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #! /bin/sh export NCCL_P2P_DISABLE=1 export NCCL_IB_DISABLE=1 CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \ --stage sft \ --do_train \ --model_name_or_path /ai/deployment/20250417 /model/Qwen2.5 -0.5 B-Instruct \ --dataset med_dialog, med_norm, med_mrg \ --template qwen \ --finetuning_type full \ --output_dir /ai/deployment/20250417 /model/finetune/Qwen2.5 -0.5 B_med_sft_2 \ --overwrite_cache \ --per_device_train_batch_size 2 \ --gradient_accumulation_steps 4 \ --lr_scheduler_type cosine \ --logging_steps 10 \ --save_strategy no \ --learning_rate 1e-4 \ --num_train_epochs 0.1 \ --plot_loss \ --preprocessing_num_workers 16 \ --bf16 \ --cutoff_len 4000
训练结束后,可以在 /ai/deployment/20250417/model/finetune/Qwen2.5-0.5B_med_sft/training_loss.png 看到整个训练的 loss 情况
优点:
简单易用
扩展性强,该框架适配多种训练方法以及工具
缺点:
灵活性受限,比如数据集的处理与读取
# 微调后评估1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 import osos.environ['CUDA_VISIBLE_DEVICES' ] = '0' from transformers import AutoModelForCausalLM,AutoTokenizerimport jsonimport jsonlinesimport torchfrom tqdm import tqdmmodel_path_1 = '/ai/deployment/20250417/model/Qwen2.5-0.5B-Instruct' model_path_2 = '/ai/deployment/20250417/model/finetune/Qwen2.5-0.5B_med_1' tokenizer = AutoTokenizer.from_pretrained(model_path_1, padding_side = 'left' ) model_1 = AutoModelForCausalLM.from_pretrained(model_path_1, torch_dtype = torch.bfloat16, device_map = 'auto' ) model_2 = AutoModelForCausalLM.from_pretrained(model_path_2, torch_dtype = torch.bfloat16, device_map = 'auto' ) assert tokenizer.padding_side == 'left' print ('模型加载完成' )def get_output (datas, tokenizer, model, batch_size=16 ,max_new_tokens=2000 ): """ 对输入数据分批处理,生成输出文本 参数: - datas: 一个字符串列表,每个字符串为一个输入句子或文本。 - tokenizer: 使用的分词器,用于将文本转换为模型输入。 - model: 用于生成文本的模型。 - batch_size: 每个批次处理的样本数,默认为4。 返回: - outputs: 包含生成文本的列表。 """ outputs = [] for i in tqdm(range (0 , len (datas), batch_size)): batch_data = datas[i:i + batch_size] inputs = tokenizer(batch_data, return_tensors="pt" , padding=True , truncation=True ).to(model.device) output_sequences = model.generate(**inputs, max_new_tokens=max_new_tokens) processed_output_sequences = [output_sequences[j][len (inputs[j]):] for j in range (len (output_sequences))] batch_outputs = tokenizer.batch_decode(processed_output_sequences, skip_special_tokens=True ) outputs.extend(batch_outputs) return outputs test_file = '/ai/deployment/20250417/dataset/sft_dataset/norm_test.jsonl' with jsonlines.open (test_file, 'r' ) as f: test_datas = [data for data in f] inputs = [] for data in test_datas: messages = [{'role' : 'user' , 'content' : data['instruction' ]}] processed_input_text = tokenizer.apply_chat_template( messages, add_generation_prompt= True , tokenize=False ) inputs.append(processed_input_text) outputs_model_1 = get_output(inputs, tokenizer, model_1, batch_size=16 , max_new_tokens = 100 ) outputs_model_2 = get_output(inputs, tokenizer, model_2, batch_size=16 , max_new_tokens = 100 ) corr_1 = 0 corr_2 = 0 for output_model_1,test_data in zip (outputs_model_1, test_datas): if output_model_1 == test_data['output' ]: corr_1 += 1 for output_model_2,test_data in zip (outputs_model_2, test_datas): if output_model_2 == test_data['output' ]: corr_2 += 1 print ('Accuracy' )print ('微调前:{}%' .format (round (corr_1/len (test_datas)*100 ,2 )))print ('微调后:{}%' .format (round (corr_2/len (test_datas)*100 ,2 )))import retest_file = '/ai/deployment/20250417/dataset/sft_dataset/mrg_test.jsonl' with jsonlines.open (test_file, 'r' ) as f: test_datas = [data for data in f] inputs = [] for data in test_datas: messages = [{'role' : 'user' , 'content' : data['instruction' ]}] processed_input_text = tokenizer.apply_chat_template( messages, add_generation_prompt= True , tokenize=False ) inputs.append(processed_input_text) outputs_model_1 = get_output(inputs, tokenizer, model_1, batch_size=16 , max_new_tokens = 2000 ) outputs_model_2 = get_output(inputs, tokenizer, model_2, batch_size=16 , max_new_tokens = 2000 ) for index,(data, model_1_result, model_2_result) in enumerate (zip (test_datas, outputs_model_1, outputs_model_2)): print ('||输入:||{}' .format (data['instruction' ])) print ('||原始模型输出:||\n{}' .format (model_1_result)) print ('||微调后模型输出:||\n{}' .format (model_2_result)) print ('----------------------------------------------------' ) if index==2 : break pred_extract = re.compile (r'```json(.*?)```' , flags=re.DOTALL) keys = [ '主诉' ,'现病史' ,'辅助检查' ,'既往史' ,'诊断' ,'建议' ,] all_golds_1 = [] all_preds_1 = [] all_golds_2 = [] all_preds_2 = [] for output_model_1,test_data in zip (outputs_model_1, test_datas): gold_json = json.loads(test_data['output' ]) try : if '```' in output_model_1: output_model_1 = pred_extract.findall(output_model_1)[0 ] pred_json = json.loads(output_model_1) else : pred_json = json.loads(output_model_1) except : pred_json = {} for key in keys: all_golds_1.append(gold_json[key]) all_preds_1.append(str (pred_json.get(key, "" ))) for output_model_2,test_data in zip (outputs_model_2, test_datas): gold_json = json.loads(test_data['output' ]) try : pred_json = json.loads(output_model_2) except : pred_json = {} for key in keys: all_golds_2.append(gold_json[key]) all_preds_2.append(str (pred_json.get(key, "" ))) corr_1 = 0 corr_2 = 0 for pred,gold in zip (all_preds_1, all_golds_1): if pred.strip() == gold.strip(): corr_1 += 1 for pred,gold in zip (all_preds_2, all_golds_2): if pred.strip() == gold.strip(): corr_2 += 1 print ('Accuracy' )print ('微调前:{}%' .format (round (corr_1/len (all_golds_1)*100 ,2 )))print ('微调后:{}%' .format (round (corr_2/len (all_golds_2)*100 ,2 )))P, R, F1 = score(all_preds_1, all_golds_1, model_type='bert-base-chinese' ,lang="zh" , verbose=True ) print ('微调前' )print ("BERTScore Precision: {}" .format (round (P.mean().item()*100 ,2 )))print ("BERTScore Recall: {}" .format (round (R.mean().item()*100 ,2 )))print ("BERTScore F1: {}" .format (round (F1.mean().item()*100 ,2 )))P, R, F1 = score(all_preds_2, all_golds_2, model_type='bert-base-chinese' ,lang="zh" , verbose=True ) print ('微调后' )print ("BERTScore Precision: {}" .format (round (P.mean().item()*100 ,2 )))print ("BERTScore Recall: {}" .format (round (R.mean().item()*100 ,2 )))print ("BERTScore F1: {}" .format (round (F1.mean().item()*100 ,2 )))
# RAG,SFT,Prompt 对比好的,若将 PE 理解为 Prompt Engineering(提示工程) ,它与 微调(Fine-tuning) 、RAG(检索增强生成) 在大模型理解特殊领域时的区别如下:
# 核心区别对比表
技术维度
微调(Fine-tuning)
RAG(检索增强生成)
提示工程(Prompt Engineering)
技术本质 修改模型参数
外部知识注入
优化输入提示设计
知识来源 训练数据中的隐含知识
实时检索外部知识库
预训练模型的已有知识
是否修改模型 是
否(仅增强输入)
否
领域适配成本 高(需标注数据、算力)
中(需构建知识库、优化检索)
低(仅需设计提示模板)
推理成本 高(模型体积可能增大)
中(需额外检索开销)
低(与基础模型一致)
知识时效性 受限于训练数据截止时间
可实时更新(取决于知识库)
受限于预训练知识(除非动态提示)
可解释性 低(知识嵌入模型权重中)
高(可追溯检索源)
中(提示设计可解释,但模型黑箱)
典型应用 医疗诊断、金融预测
法律文书生成、实时问答
快速领域适配、零样本学习
# 1. 微调(Fine-tuning)
核心逻辑 :使用领域内的标注数据(如医疗报告、金融财报)更新模型参数,使模型显式学习领域特定的语言模式和知识。优势 :
深度整合领域知识,适合复杂任务(如医疗诊断、代码生成)。
模型自主推理能力强,无需外部依赖。
局限性 :
需大量标注数据和计算资源。
知识更新需重新训练,周期长。
可能过拟合特定领域,泛化能力下降。
# 2. RAG(检索增强生成)
核心逻辑 :将模型生成与外部知识库检索结合:先通过检索器获取相关知识片段,再将其作为上下文输入给模型生成回答。优势 :
知识实时性强,支持动态更新(如插入 202x 年最新政策)。
无需修改模型,部署灵活。
可解释性高(用户可查看引用的知识来源)。
局限性 :
依赖高质量知识库和检索算法,存在检索偏差风险。
架构复杂度增加,需维护额外检索系统。
# 3. 提示工程(Prompt Engineering)
核心逻辑 :通过精心设计输入提示(如指令、示例、格式要求),引导模型利用已有知识生成符合领域需求的回答,无需修改模型参数。优势 :
零样本 / 少样本学习,无需训练数据。
快速迭代(修改提示比重新训练模型快得多)。
支持多任务切换(通过不同提示适配不同场景)。
局限性 :
效果依赖提示设计技巧,需反复调优。
受限于预训练模型的知识范围(无法注入新知识)。
复杂任务可能需要超长提示,增加推理成本。
# 适用场景对比
场景特征
微调(Fine-tuning)
RAG(检索增强生成)
提示工程(Prompt Engineering)
领域数据丰富且标注充足
✅
❌
❌
需实时知识更新
❌
✅
❌(除非结合动态检索)
快速验证领域可行性
❌
✅
✅
资源受限(算力 / 时间)
❌
✅
✅
知识需深度整合
✅
❌
❌(依赖模型已有知识)
多领域灵活切换
❌
✅
✅
# 典型应用案例
医疗领域 :
微调 :用数万份病例微调 BioGPT,构建诊断助手。RAG :检索最新医学指南作为上下文,生成治疗建议。提示工程 :设计 “医生视角” 提示,让 GPT-4 解释检查结果。
金融领域 :
微调 :用历史财报数据微调 T5,预测股价走势。RAG :实时检索新闻和政策,分析市场影响。提示工程 :通过 Few-Shot 示例,让模型生成投资报告摘要。
法律领域 :
微调 :用法律文书微调 LLM,自动生成合同。RAG :检索相关法条和判例作为生成依据。提示工程 :设计 “法律专家” 角色提示,提高回答专业性。
# 组合策略 实际应用中,三种技术常结合使用:
提示工程 + RAG :用提示工程优化模型对检索结果的利用(如指示模型 “基于以下法条,分析…)。微调 + 提示工程 :先用领域数据微调模型,再用提示工程进一步引导输出风格(如医疗问答的人文关怀)。分层方案 :简单问题用提示工程直接解决,复杂问题触发微调模型或 RAG(如法律系统)。
# 总结
微调 :通过重训练模型 “记忆” 领域知识,适合数据充足、长期使用的场景;RAG :通过外部检索 “注入” 实时知识,适合知识更新快、需可解释性的场景;提示工程 :通过优化输入 “唤醒” 模型已有知识,适合快速验证、资源受限的场景。
选择时需权衡:数据量、时效性要求、计算资源、可解释性需求等因素。在特殊领域落地大模型时,往往需要混合使用多种技术以达到最佳效果。
大语言模型微调技术全解析
https://www.nowcoder.com/discuss/510221094205272064?sourceSSR=dynamic
https://zhuanlan.zhihu.com/p/715250294
https://blog.csdn.net/qq_46094651/article/details/142457139
# LoraLoRA(Low-Rank Adaptation)是一种参数高效的微调方法,它的核心思想是:在保持预训练模型原始权重不变的情况下,通过引入少量可训练的低秩矩阵来调整模型行为 。
传统的微调方法(全量微调)需要更新模型的所有参数,这对于现代大型语言模型(如 GPT-3、LLaMA 等)来说,计算资源需求极高。例如,对一个拥有 175B 参数的模型进行全量微调,需要数百 GB 的 GPU 内存,这超出了大多数商用硬件的能力范围。
# Lora 数学实现Lora 涉及线性代数中很多内容,比如矩阵的秩
https://blog.csdn.net/weixin_47552266/article/details/140996357
在深度神经网络中,线性变换(如全连接层或注意力层中的权重矩阵)可以表示为:
y = W x y = Wx
y = W x
其中:
W \in \mathbb{R}^{d \times k}$$ 是权重矩阵
y \in \mathbb{R}^d$$ 是输出向量
W ′ = W + Δ W = W + B A W' = W + \Delta W = W + BA
W ′ = W + Δ W = W + B A
其中:
y = W ′ x = W x + B A x y = W'x = Wx + BAx
y = W ′ x = W x + B A x
这里的 W 是预训练模型中的原始权重矩阵,△W 是权重的更新,B 和 A 是在训练过程中学习的低秩矩阵,x 是输入向量,y 是经过修改后的层的输出向量。
通过这种低秩分解方法,需要训练的参数量从原来的 $$d \times $$ 减少到 $$r \times (d + k)$$。
例如,对于一个典型的权重矩阵 $$W \in \mathbbR}【 {4096 \times 4096 】 $$:
全量微调需要训练 $$4096 \times 4096 = 16,777,216$$ 个参数
当使用 LoRA 且 $$r = $$ 时,仅需训练 $$8 \times (4096 + 4096) = 65,536$$ 个参数
这意味着参数量减少了约 256 倍,同时内存需求也大幅降低。
在实际实现中,LoRA 通常引入一个缩放因子 $$\alpha$$,修改前向传播为:
y = W x + α r B A x y = Wx + \frac{\alpha}{r}BAx
y = W x + r α B A x
其中 $$\alpha$$ 是一个可调超参数。这个缩放因子使得我们可以在不改变初始化方差的情况下控制 LoRA 更新的强度。通常 $$\alpha$$ 设置为 $$r$$ 的倍数(如 $$2r$$ 或 $$4r$$)。
LoRA 的初始化策略对训练稳定性有重要影响:
矩阵 $$A$$ 通常使用高斯分布初始化:$$A \sim \mathcal {N}(0, \sigma^2)$$
矩阵 $$B$$ 通常初始化为零矩阵:B = 0
这种初始化确保了训练开始时 $$\Delta W = BA = 0$$,即模型的初始行为与原始预训练模型完全相同,避免了训练初期的剧烈变化。
在训练过程中,我们只更新 A 和 B,而不是整个 W 矩阵 。这样,我们通过优化这两个小矩阵来间接地调整 W 的行为,使其更好地适应特定的下游任务。这种方法显著减少了模型参数的数量,从而降低了训练和部署所需的计算资源。
在部署阶段,我们可以将 A 和 B 与 W 合并,得到一个新的权重矩阵 W + AB ,这个新矩阵可以直接用于推理过程,而不会引入任何额外的推理延迟。这种方法允许我们快速地在不同任务之间切换,只需简单地替换 A 和 B 矩阵即可。
# Lora 关键参数秩 r 决定了 LoRA 矩阵的维度 ,直接影响模型容量和参数量:
较小的 r(如 4 或 8) :参数量少,训练速度快,但模型容量有限较大的 r(如 32 或 64) :模型容量增加,性能可能提升,但训练更慢,过拟合风险增加
α 控制 LoRA 更新的强度 :通常设置为 r 的 2-4 倍
较大的 α 会增强 LoRA 的影响,加速适应但可能导致不稳定
较小的 α 会减弱 LoRA 的影响,训练更稳定但可能收敛较慢
LoRA 微调通常使用比全量微调更高的学习率 :
全量微调:1e-5 ~ 2e-5
LoRA 微调:1e-4 ~ 2e-4
选择应用 LoRA 的模块 会影响性能和训练参数量:
只应用于注意力层(查询、键、值矩阵):参数量最少,但可能限制性能
同时应用于注意力层和前馈网络层:参数量增加,通常性能更好
应用于所有线性层:参数量最大,接近全量微调的性能
LoRA 微调技术原理与数学实现
https://blog.csdn.net/lvaolan168/article/details/142219400
https://zhuanlan.zhihu.com/p/27070717054
https://ar5iv.labs.arxiv.org/html/2106.09685?_immersive_translate_auto_translate=1#S1.F1
https://nexla.com/enterprise-ai/low-rank-adaptation-of-large-language-models/
# 量化pip install bitsandbytes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 import BitsAndBytesConfigimport torchbnb_config = BitsAndBytesConfig( load_in_4bit=use_4bit, bnb_4bit_quant_type=bnb_4bit_quant_type, bnb_4bit_compute_dtype=compute_dtype, bnb_4bit_use_double_quant=use_nested_quant, ) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto" , device_map="auto" , quantization_config=bnb_config ) from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfigimport torchmodel_name = "/ai/data/DeepSeek-R1-Distill-Qwen-1.5B" use_4bit = True bnb_4bit_compute_dtype = "float16" bnb_4bit_quant_type = "nf4" use_nested_quant = False compute_dtype = getattr (torch, bnb_4bit_compute_dtype) bnb_config = BitsAndBytesConfig( load_in_4bit=use_4bit, bnb_4bit_quant_type=bnb_4bit_quant_type, bnb_4bit_compute_dtype=compute_dtype, bnb_4bit_use_double_quant=use_nested_quant, ) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto" , device_map="auto" , quantization_config=bnb_config ) tokenizer = AutoTokenizer.from_pretrained(model_name) history, response = [], "" query = input ("请输入内容:" ) messages = [{"role" : "system" , "content" : "你是一个智能助手,擅长用中文回答用户的提问。" }] while query: for query_h, response_h in history: messages.append({"role" : "user" , "content" : query_h}) messages.append({"role" : "assistant" , "content" : response_h}) messages.append({"role" : "user" , "content" : query}) text = tokenizer.apply_chat_template( messages, tokenize=False , add_generation_prompt=True ) model_inputs = tokenizer([text], return_tensors="pt" ).to(model.device) generated_ids = model.generate( **model_inputs, max_new_tokens=1024 , temperature = 0.7 , top_p = 0.8 , repetition_penalty=1.1 ) generated_ids = [ output_ids[len (input_ids):] for input_ids, output_ids in zip (model_inputs.input_ids, generated_ids) ] response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True )[0 ] print (response) history.append([query, response]) query = input ("请输入内容:" )