# Kubernetes[TOC]
VPC 私有网络,不同 VPC 之间相互隔离
k8s 大规模容器编排系统
master/node 模式
# k8s 特性
服务发现和负载均衡 存储编排 自动部署和回滚 自动完成装箱计算 自我修复 密钥与配置管理
# 架构主节点 (master) + 工作节点 (worker)
K8s 集群至少需要一个主节点 (Master) 和多个工作节点 (Worker),Master 节点是集群的控制节点,负责整个集群的管理和控制,主节点主要用于暴露 API,调度部署和节点的管理。工作节点主要是运行容器的。
多 master 节点高可用架构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 kubectl:管理K8s的命令行工具,可以操作K8s中的资源对象。 etcd: 是一个高可用的键值数据库,存储K8s的资源状态信息和网络信息的,etcd中的数据变更是通过api server进行的。 apiserver: 提供K8s api,是整个系统的对外接口,提供资源操作的唯一入口,供客户端和其它组件调用,提供了K8s各类资源对象(pod,deployment,Service等)的增删改查,是整个系统的数据总线和数据中心,并提供认证、授权、访问控制、API注册和发现等机制,并将操作对象持久化到etcd中。相当于“营业厅”。 scheduler:负责K8s集群中pod的调度的 , scheduler通过与apiserver交互监听到创建Pod副本的信息后,它会检索所有符合该Pod要求的工作节点列表,开始执行Pod调度逻辑。调度成功后将Pod绑定到目标节点上,相当于“调度室”。 controller-manager:与apiserver交互,实时监控和维护K8s集群的控制器的健康情况,对有故障的进行处理和恢复,相当于“大总管”。 kubelet: 每个Node节点上的kubelet定期就会调用API Server的REST接口报告自身状态,API Server接收这些信息后,将节点状态信息更新到etcd中。kubelet也通过API Server监听Pod信息,从而对Node机器上的POD进行管理,如创建、删除、更新Pod kube-proxy:提供网络代理和负载均衡,是实现service的通信与负载均衡机制的重要组件,kube-proxy负责为Pod创建代理服务,从apiserver获取所有service信息,并根据service信息创建代理服务,实现service到Pod的请求路由和转发,从而实现K8s层级的虚拟转发网络,将到service的请求转发到后端的pod上。 calico:网络插件,提供IP,策略隔离 coredns:域名解析
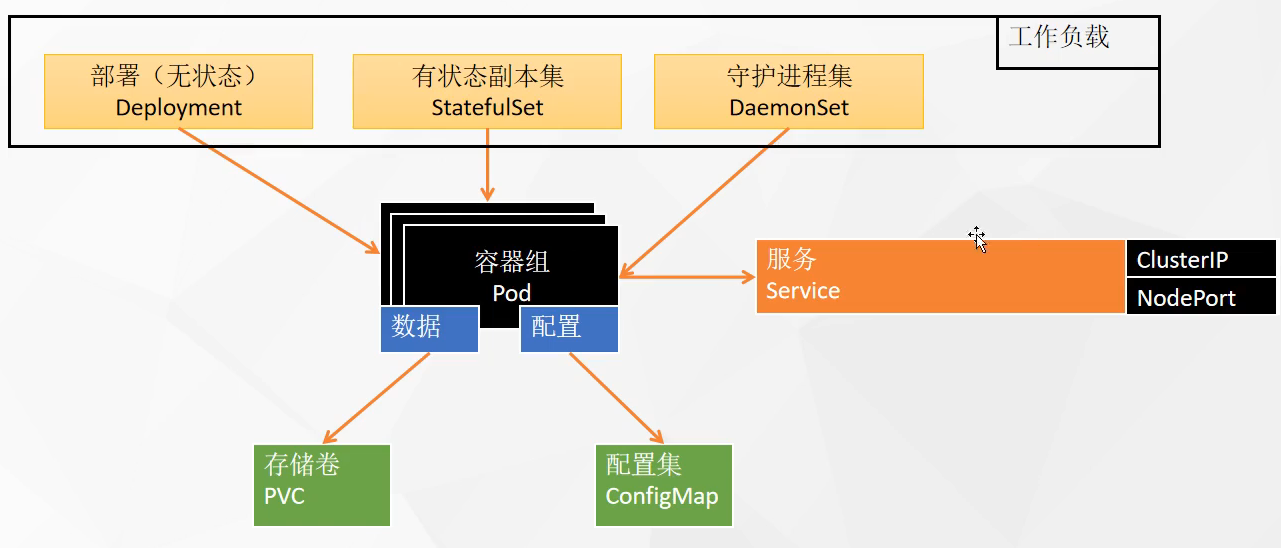
# 资源对象1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Pod是Kubernetes中的最小调度单元,当指派容器时,容器实际上并不会指派到物理硬件上,容器会被分配到一个Pod里。Pod代表集群上正在运行的一个进程,一个Pod封装一个容器(也可以封装多个容器),Pod里的容器共享存储、网络等。也就是说,应该把整个pod看作虚拟机,然后每个容器相当于运行在虚拟机的进程。 Replicaset Kubernetes中的副本控制器,管理Pod,使pod副本的数量始终维持在预设的个数。 Deployment管理Replicaset和Pod的副本控制器,Deployment可以管理多个Replicaset,是比Replicaset更高级的控制器,也即是说在创建Deployment的时候,会自动创建Replicaset,由Replicaset再创建Pod,Deployment能对Pod扩容、缩容、滚动更新和回滚、维持Pod数量。 Service 在kubernetes中,Pod是有生命周期的,如果Pod重启IP很有可能会发生变化。如果我们的服务都是将Pod的IP地址写死,Pod的挂掉或者重启,和刚才重启的pod相关联的其他服务将会找不到它所关联的Pod,为了解决这个问题,在kubernetes中定义了service资源对象,Service 定义了一个服务访问的入口,客户端通过这个入口即可访问服务背后的应用集群实例,service是一组Pod的逻辑集合,这一组 Pod 能够被 Service 访问到,通常是通过 Label Selector实现的。 Statefulset Job & CronJob Ingress Configmap和Secret
开发代码 -> 提交代码到代码仓库 ->Jenkins 调 K8s API-> 动态生成 Jenkins Slave Pod->Slave Pod 拉取 git 上的代码 -> 编译代码 -> 打包镜像 -> 推送镜像到镜像仓库 harbor 或者 docker hub-> 通过 K8s 编排服务发布到测试、生产平台 -> Slave Pod 工作完成之后自动删除 > 通过 Ingress 发布服务。
# kubeadm 安装 k8s 多 master 高可用集群
kubeadm 是官方提供的开源工具,是一个开源项目,用于快速搭建 kubernetes 集群,目前是比较方便和推荐使用的。kubeadm init 以及 kubeadm join 这两个命令可以快速创建 kubernetes 集群。Kubeadm 初始化 k8s,所有的组件都是以 pod 形式运行的,具备故障自恢复能力。
kubeadm 是工具,可以快速搭建集群,也就是相当于用程序脚本帮我们装好了集群,属于自动部署,简化部署操作,自动部署屏蔽了很多细节,使得对各个模块感知很少,如果对 k8s 架构组件理解不深的话,遇到问题比较难排查。
kubeadm 适合需要经常部署 k8s,或者对自动化要求比较高的场景下使用。
二进制:在官网下载相关组件的二进制包,如果手动安装,对 kubernetes 理解也会更全面。
Kubeadm 和二进制都适合生产环境,在生产环境运行都很稳定,具体如何选择,可以根据实际项目进行评估。
1 2 ./configure --prefix=/usr/share/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib64/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --http-client-body-temp-path=/var/lib/nginx/tmp/client_body --http-proxy-temp-path=/var/lib/nginx/tmp/proxy --http-fastcgi-temp-path=/var/lib/nginx/tmp/fastcgi --http-uwsgi-temp-path=/var/lib/nginx/tmp/uwsgi --http-scgi-temp-path=/var/lib/nginx/tmp/scgi --pid-path=/run/nginx.pid --lock-path=/run/lock/subsys/nginx --user=nginx --group=nginx --with-compat --with-debug --with-file-aio --with-google_perftools_module --prefix= --with-http_addition_module --with-http_auth_request_module --with-http_dav_module --with-http_degradation_module --with-http_flv_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_image_filter_module=dynamic --with-http_mp4_module --with-http_perl_module=dynamic --with-http_random_index_module --with-http_realip_module --with-http_secure_link_module --with-http_slice_module --with-http_ssl_module --with-http_stub_status_module --with-http_sub_module --with-http_v2_module --with-http_xslt_module=dynamic --with-mail=dynamic --with-mail_ssl_module --with-pcre --with-pcre-jit --with-stream=dynamic --with-stream_ssl_module --with-stream_ssl_preread_module --with-threads --with-cc-opt='-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -specs=/usr/lib/rpm/redhat/redhat-hardened-cc1 -m64 -mtune=generic' --with-ld-opt='-Wl,-z,relro -specs=/usr/lib/rpm/redhat/redhat-hardened-ld -Wl,-E' --with-stream
1 2 3 4 5 auto eth0 iface eth0 inet static address 192.168.13.198 gateway 192.168.13.2 netmask 255.255.255.0
# 安装1. 安装 docker
2. 安装 kubelet
3. 安装 kubectl
4. 安装 kubeadm
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 预配环境: #各个机器设置自己的域名 hostnamectl set-hostname xxxx # 将 SELinux 设置为 permissive 模式(相当于将其禁用) sudo setenforce 0 sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config #关闭swap swapoff -a sed -ri 's/.*swap.*/#&/' /etc/fstab #允许 iptables 检查桥接流量 cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf br_netfilter EOF cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sudo sysctl --system
安装 kubelet、kubeadm、kubectl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg exclude=kubelet kubeadm kubectl EOF sudo yum install -y kubelet-1.20.9 kubeadm-1.20.9 kubectl-1.20.9 --disableexcludes=kubernetes sudo systemctl enable --now kubelet
安装 kubelet、kubeadm、kubectl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 sudo tee ./images.sh <<-'EOF' images=( kube-apiserver:v1.20.9 kube-proxy:v1.20.9 kube-controller-manager:v1.20.9 kube-scheduler:v1.20.9 coredns:1.7.0 etcd:3.4.13-0 pause:3.2 ) for imageName in ${images[@]} ; do docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/$imageName done EOF chmod +x ./images.sh && ./images.sh
初始化主节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 echo "172.23.142.216 k8s-master" >> /etc/hostskubeadm init \ --apiserver-advertise-address=172.23.142.216 \ --control-plane-endpoint=k8s-master \ --image-repository registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images \ --kubernetes-version v1.20.9 \ --service-cidr=10.96.0.0/16 \ --pod-network-cidr=192.168.0.0/16 Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME /.kube sudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/config sudo chown $(id -u):$(id -g) $HOME /.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of control-plane nodes by copying certificate authorities and service account keys on each node and then running the following as root: kubeadm join cluster-endpoint:6443 --token 902kx7.ic9ncjvtuksmf2rw \ --discovery-token-ca-cert-hash sha256:753403dbd24f4cef391a276ad67e8c9c8d91cec64467998426e3021123381b36 \ --control-plane Then you can join any number of worker nodes by running the following on each as root: kubeadm join cluster-endpoint:6443 --token 902kx7.ic9ncjvtuksmf2rw \ --discovery-token-ca-cert-hash sha256:753403dbd24f4cef391a276ad67e8c9c8d91cec64467998426e3021123381b36
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 主节点 mkdir -p $HOME /.kube sudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/config sudo chown $(id -u):$(id -g) $HOME /.kube/config 主节点 下载calico https://docs.tigera.io/archive/v3.22/getting-started/kubernetes/self-managed-onprem/onpremises curl https://projectcalico.docs.tigera.io/archive/v3.22/manifests/calico.yaml -O kubectl apply -f calico.yaml [root@i-taf5qf6u ~] NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-57c7b58f66-jq7lm 0/1 ContainerCreating 0 22m kube-system calico-node-4bttn 1/1 Running 0 22m kube-system coredns-5897cd56c4-2fhkm 1/1 Running 0 55m kube-system coredns-5897cd56c4-2l59f 1/1 Running 0 55m kube-system etcd-master 1/1 Running 0 55m kube-system kube-apiserver-master 1/1 Running 0 55m kube-system kube-controller-manager-master 1/1 Running 0 55m kube-system kube-proxy-d4sgz 1/1 Running 0 55m kube-system kube-scheduler-master 1/1 Running 0 55m tigera-operator tigera-operator-57cb64cf85-kqsvh 1/1 Running 0 37m [root@i-taf5qf6u ~] NAME STATUS ROLES AGE VERSION master Ready control-plane,master 56m v1.20.9
1 2 3 4 5 6 7 8 9 kubectl get nodes kubectl appy -f xxx.yml kubectl get pods -A
1 2 3 kubeadm join cluster-endpoint:6443 --token 902kx7.ic9ncjvtuksmf2rw \ --discovery-token-ca-cert-hash sha256:753403dbd24f4cef391a276ad67e8c9c8d91cec64467998426e3021123381b36
1 2 kubeadm token create --print-join-command
==== new =====
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 apiserver controller-manager scheduler etcd kube-proxy docker calico coredns calico kubelet kube-proxy docker Swap是交换分区,如果机器内存不够,会使用swap分区,但是swap分区的性能较低,k8s设计的时候为了能提升性能,默认是不允许使用交换分区的。Kubeadm初始化的时候会检测swap是否关闭,如果没关闭,那就初始化失败。如果不想要关闭交换分区,安装k8s的时候可以指定--ignore-preflight-errors=Swap来解决。 free -m 1.24之后使用contained Kubeadm: kubeadm是一个工具,用来初始化k8s集群的 kubelet: 安装在集群所有节点上,用于启动Pod的 kubectl: 通过kubectl可以部署和管理应用,查看各种资源,创建、删除和更新各种组件 [root@master1 ~] apiVersion: v1 clusters: - cluster: certificate-authority-data: DATA+OMITTED server: https://192.168.13.249:16443 name: kubernetes contexts: - context: cluster: kubernetes user: kubernetes-admin name: kubernetes-admin@kubernetes current-context: kubernetes-admin@kubernetes kind: Config preferences: {} users :- name: kubernetes-admin user: client-certificate-data: REDACTED client-key-data: REDACTED kubeadm 在执行安装之前进行了相当细致的环境检测 1) 检查执行 init 命令的用户是否为 root,如果不是 root,直接快速失败(fail fast); 2) 检查待安装的 k8s 版本是否被当前版本的 kubeadm 支持(kubeadm 版本 >= 待安装 k8s 版本); 3) 检查防火墙,如果防火墙未关闭,提示开放端口 10250; 4) 检查端口是否已被占用,6443(或你指定的监听端口)、10257、10259; 5) 检查文件是否已经存在,/etc/kubernetes/manifests/*.yaml; 6) 检查是否存在代理,连接本机网络、服务网络、Pod网络,都会检查,目前不允许代理; 7) 检查容器运行时,使用 CRI 还是 Docker,如果是 Docker,进一步检查 Docker 服务是否已启动,是否设置了开机自启动; 8) 对于 Linux 系统,会额外检查以下内容: 8.1) 检查以下命令是否存在:crictl、ip、iptables、mount、nsenter、ebtables、ethtool、socat、tc、touch ; 8.2) 检查 /proc/sys/net/bridge/bridge-nf-call-iptables、/proc/sys/net/ipv4/ip-forward 内容是否为 1; 8.3) 检查 swap 是否是关闭状态; 9) 检查内核是否被支持,Docker 版本及后端存储 GraphDriver 是否被支持; 对于 Linux 系统,还需检查 OS 版本和 cgroup 支持程度(支持哪些资源的隔离); 10) 检查主机名访问可达性; 11) 检查 kubelet 版本,要高于 kubeadm 需要的最低版本,同时不高于待安装的 k8s 版本; 12) 检查 kubelet 服务是否开机自启动; 13) 检查 10250 端口是否被占用; 14) 如果开启 IPVS 功能,检查系统内核是否加载了 ipvs 模块; 15) 对于 etcd,如果使用 Local etcd,则检查 2379 端口是否被占用, /var/lib/etcd/ 是否为空目录; 如果使用 External etcd,则检查证书文件是否存在(CA、key、cert),验证 etcd 服务版本是否符合要求; 16) 如果使用 IPv6, 检查 /proc/sys/net/bridge/bridge-nf-call-iptables、/proc/sys/net/ipv6/conf/default/forwarding 内容是否为 1; 完成安装前的配置 1) 在 kube-system 命名空间创建 ConfigMap kubeadm-config,同时对其配置 RBAC 权限; 2) 在 kube-system 命名空间创建 ConfigMap kubelet-config-<version>,同时对其配置 RBAC 权限; 3) 为当前节点(Master)打标记:node-role.kubernetes.io/master=; 4) 为当前节点(Master)补充 Annotation; 5) 如果启用了 DynamicKubeletConfig 特性,设置本节点 kubelet 的配置数据源为 ConfigMap 形式; 6) 创建 BootStrap token Secret,并对其配置 RBAC 权限; 7) 在 kube-public 命名空间创建 ConfigMap cluster-info,同时对其配置 RBAC 权限; 8) 与 apiserver 通信,部署 DNS 服务; 9) 与 apiserver 通信,部署 kube-proxy 服务; 10) 如果启用了 self-hosted 特性,将 Control Plane 转为 DaemonSet 形式运行; 11) 打印 join 语句; Kubeadm生成的k8s证书内容说明: 一、证书分组 Kubernetes把证书放在了两个文件夹中 /etc/kubernetes/pki /etc/kubernetes/pki/etcd 二、Kubernetes 集群根证书 Kubernetes 集群根证书CA(Kubernetes集群组件的证书签发机构) /etc/kubernetes/pki/ca.crt /etc/kubernetes/pki/ca.key 以上这组证书为签发其他Kubernetes组件证书使用的根证书, 可以认为是Kubernetes集群中证书签发机构之一 由此根证书签发的证书有: 1、kube-apiserver apiserver证书 /etc/kubernetes/pki/apiserver.crt /etc/kubernetes/pki/apiserver.key 2、kubelet客户端证书, 用作 kube-apiserver 主动向 kubelet 发起请求时的客户端认证 /etc/kubernetes/pki/apiserver-kubelet-client.crt /etc/kubernetes/pki/apiserver-kubelet-client.key 三、kube-apiserver 代理根证书(客户端证书) 用在requestheader-client-ca-file配置选项中, kube-apiserver 使用该证书来验证客户端证书是否为自己所签发 /etc/kubernetes/pki/front-proxy-ca.crt /etc/kubernetes/pki/front-proxy-ca.key 由此根证书签发的证书只有一组: 代理层(如汇聚层aggregator)使用此套代理证书来向 kube-apiserver 请求认证 代理端使用的客户端证书, 用作代用户与 kube-apiserver 认证 /etc/kubernetes/pki/front-proxy-client.crt /etc/kubernetes/pki/front-proxy-client.key 三、etcd 集群根证书 etcd集群所用到的证书都保存在/etc/kubernetes/pki/etcd这路径下, 很明显, 这一套证书是用来专门给etcd集群服务使用的, 设计以下证书文件 etcd 集群根证书CA(etcd 所用到的所有证书的签发机构) /etc/kubernetes/pki/etcd/ca.crt /etc/kubernetes/pki/etcd/ca.key 由此根证书签发机构签发的证书有: 1、etcd server 持有的服务端证书 /etc/kubernetes/pki/etcd/server.crt /etc/kubernetes/pki/etcd/server.key 2、peer 集群中节点互相通信使用的客户端证书 /etc/kubernetes/pki/etcd/peer.crt /etc/kubernetes/pki/etcd/peer.key 注: Peer:对同一个etcd集群中另外一个Member的称呼 3、pod 中定义 Liveness 探针使用的客户端证书 kubeadm 部署的 Kubernetes 集群是以 pod 的方式运行 etcd 服务的, 在该 pod 的定义中, 配置了 Liveness 探活探针 /etc/kubernetes/pki/etcd/healthcheck-client.crt /etc/kubernetes/pki/etcd/healthcheck-client.key 当你 describe etcd 的 pod 时, 会看到如下一行配置: Liveness: exec [/bin/sh -ec ETCDCTL_API=3 etcdctl --endpoints=https://[127.0.0.1]:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt --key=/etc/kubernetes/pki/etcd/healthcheck-client.key get foo] delay=15s timeout =15s period=10s 4、配置在 kube-apiserver 中用来与 etcd server 做双向认证的客户端证书 /etc/kubernetes/pki/apiserver-etcd-client.crt /etc/kubernetes/pki/apiserver-etcd-client.key
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 Calico网络模型主要工作组件: 1.Felix:运行在每一台 Host 的 agent 进程,主要负责网络接口管理和监听、路由、ARP 管理、ACL 管理和同步、状态上报等。保证跨主机容器网络互通。 2.etcd:分布式键值存储,相当于k8s集群中的数据库,存储着Calico网络模型中IP地址等相关信息。主要负责网络元数据一致性,确保 Calico 网络状态的准确性; 3.BGP Client(BIRD):Calico 为每一台 Host 部署一个 BGP Client,即每台host上部署一个BIRD。 主要负责把 Felix 写入 Kernel 的路由信息分发到当前 Calico 网络,确保 Workload 间的通信的有效性; 4.BGP Route Reflector:在大型网络规模中,如果仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,因为所有节点之间俩俩互联,需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,通过一个或者多个 BGP Route Reflector 来完成集中式的路由分发。 扩展:calico的IPIP模式和BGP模式对比分析 1)IPIP 把一个IP数据包又套在一个IP包里,即把IP层封装到IP层的一个 tunnel,它的作用其实基本上就相当于一个基于IP层的网桥,一般来说,普通的网桥是基于mac层的,根本不需要IP,而这个ipip则是通过两端的路由做一个tunnel,把两个本来不通的网络通过点对点连接起来; calico以ipip模式部署完毕后,node上会有一个tunl0的网卡设备,这是ipip做隧道封装用的,也是一种overlay模式的网络。当我们把节点下线,calico容器都停止后,这个设备依然还在,执行 rmmodipip命令可以将它删除。 2)BGP BGP模式直接使用物理机作为虚拟路由路(vRouter),不再创建额外的tunnel 边界网关协议(BorderGateway Protocol, BGP)是互联网上一个核心的去中心化的自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而是基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议,通俗的说就是将接入到机房的多条线路(如电信、联通、移动等)融合为一体,实现多线单IP; BGP 机房的优点:服务器只需要设置一个IP地址,最佳访问路由是由网络上的骨干路由器根据路由跳数与其它技术指标来确定的,不会占用服务器的任何系统; 常见网络插件 Flannel Calico Weave canal kubeadm init --config kubeadm.yaml --ignore-preflight-errors=SystemVerification apiVersion: kubeadm.k8s.io/v1beta2 kind: ClusterConfiguration kubernetesVersion: v1.20.6 controlPlaneEndpoint: 192.168.13.249:16443 imageRepository: registry.aliyuncs.com/google_containers apiServer: certSANs: - 192.168.13.211 - 192.168.13.177 - 192.168.13.188 - 192.168.13.249 networking: podSubnet: 10.244.0.0/16 serviceSubnet: 10.96.0.0/16 --- apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration mode: ipvs kubectl label node xianchaonode1 node-role.kubernetes.io/worker=worker
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 . /etc/init.d/functions ip= hostName=master dockerVersion=20.10.6 k8sVersion=1.23.0 podSubnet="10.244.0.0/16" serviceSubnet="10.10.0.0/16" openNetwork ping -c 1 www.baidu.com > /dev/null 2>&1 if [ $? -eq 0 ];then action "外网权限:" else action "外网权限:" echo "此脚本需要访问外网权限才可成功执行,退出脚本" exit 5 fi } stopFirewall systemctl disable firewalld --now &>/dev/null setenforce 0 &>/dev/null sed -i.$(date +%F) -r 's/SELINUX=[ep].*/SELINUX=disabled/g' /etc/selinux/config if (grep SELINUX=disabled /etc/selinux/config) &>/dev/null;then action "关闭防火墙:" else action "关闭防火墙:" false fi } hostName if [[ -z ${ip} ]];then ip=$(ip addr | grep -oP '(?<=inet\s)\d+\.\d+\.\d+\.\d+' |egrep -v "127.0.0.1|172.17.0.1" |awk NR==1) fi if [[ -z ${hostName} ]];then hostName="${HOSTNAME} " fi if ! (egrep -w "${ip} +${hostName} " /etc/hosts) &>/dev/null;then hostnamectl set-hostname ${hostName} echo "${ip} ${hostName} " >> /etc/hosts fi if (egrep -w "${ip} +${hostName} " /etc/hosts) &>/dev/null;then action "添加本地域名解析:" else action "添加本地域名解析:" false fi } timeSync if ! (which ntpdate &>/dev/null);then echo -e "\033[32m# ntpdate未安装,开始进行安装....\033[0m" (yum -y install ntpdate) &>/dev/null;sleep 0.3 if (which ntpdate &>/dev/null);then action "ntpdate安装成功:" fi fi if (ntpdate ntp1.aliyun.com &>/dev/null);then if ! (egrep "ntpdate +ntp1.aliyun.com" /var/spool/cron/root &>/dev/null);then echo "0 1 * * * ntpdate ntp1.aliyun.com" >> /var/spool/cron/root fi action "时间同步:" else action "时间同步:" false fi } swapOff swapoff --all sed -i -r '/swap/ s/^/#/' /etc/fstab if [[ $(free | grep -i swap | awk '{print $2}' ) -eq 0 ]]; then action "关闭交换分区:" else action "关闭交换分区:" false fi } addKernelArg KernelArg=("net.bridge.bridge-nf-call-ip6tables" "net.bridge.bridge-nf-call-iptables" "net.ipv4.ip_forward" ) for ((i=0;i<${#KernelArg[@]} ;i++))do if [[ $(sysctl -n ${KernelArg[i]} ) -ne 1 ]];then echo "${KernelArg[i]} = 1" >> /etc/sysctl.d/kubernetes.conf fi done modprobe br_netfilter &>/dev/null sysctl -p /etc/sysctl.d/kubernetes.conf &>/dev/null if [[ $(sysctl -n ${KernelArg[0]} ) -eq 1 && $(sysctl -n ${KernelArg[1]} ) -eq 1 && $(sysctl -n ${KernelArg[2]} ) -eq 1 ]]; then action "添加内核参数" else action "添加内核参数" false fi } ipvs if (command -v ipset &>/dev/null && command -v ipvsadm &>/dev/null);then cat > /etc/sysconfig/modules/ipvs.modules <<EOF modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack_ipv4 EOF chmod +x /etc/sysconfig/modules/ipvs.modules /etc/sysconfig/modules/ipvs.modules else echo -e "\033[32m# ipvs未安装,开始进行安装....\033[0m" yum -y install ipset ipvsadm &>/dev/null if (command -v ipset &>/dev/null && command -v ipvsadm &>/dev/null);then action "ipvs安装成功:" cat > /etc/sysconfig/modules/ipvs.modules <<EOF modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack_ipv4 EOF chmod +x /etc/sysconfig/modules/ipvs.modules /etc/sysconfig/modules/ipvs.modules fi fi modprobe br_netfilter &>/dev/null if (lsmod | grep -q -e ip_vs -e nf_conntrack_ipv4)&>/dev/null; then action "启用ipvs模块:" else action "启用ipvs模块:" false fi } dockerInstall if ! (command -v docker &>/dev/null);then echo -e "\033[32m# Docker未安装,开始进行安装....\033[0m" (curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo) &>/dev/null (wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo) &>/dev/null (yum install -y yum-utils) &>/dev/null (yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo) &>/dev/null (yum install docker-ce-${dockerVersion} docker-ce-cli-${dockerVersion} -y) &>/dev/null if (command -v docker &>/dev/null);then action "Docker安装成功:" else action "Docker安装成功:" false fi fi mkdir /etc/docker &>/dev/nullif [[ -f /etc/docker/daemon.json ]];then mv /etc/docker/daemon.json{,.$(date +%F)} fi cat <<EOF > /etc/docker/daemon.json { "registry-mirrors": ["https://aoewjvel.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"] } EOF (systemctl enable docker --now) &>/dev/null if [[ -f /etc/docker/daemon.json ]];then action "Docker镜像加速源:" else action "Docker镜像加速源:" fi } k8sInstall k8scommand=("kubeadm" "kubelet" "kubectl" ) if [[ -f /etc/yum.repos.d/kubernetes.repo ]];then mv /etc/yum.repos.d/kubernetes.repo{,.$(date +%F)} fi cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=0 EOF echo -e "\033[32m# 正在安装K8S,请耐心等待......\033[0m" (yum -y install --setopt =obsoletes=0 kubeadm-${k8sVersion} kubelet-${k8sVersion} kubectl-${k8sVersion} ) &>/dev/null systemctl enable kubelet.service --now &>/dev/null for ((i=0;i<${#k8scommand[@]} ;i++))do if (command -v ${k8scommand[i]} &>/dev/null);then action "安装${k8scommand[i]} 组件:" else action "安装${k8scommand[i]} 组件:" false fi done } k8sInit if [[ -z ${ip} ]];then ip=$(grep ${HOSTNAME} /etc/hosts|awk '{print $1}' | awk NR==1) fi if [[ -f /root/kubeadm-config.yaml ]];then mv /root/kubeadm-config.yaml{,.$(date +%F)} fi cat >> /root/kubeadm-config.yaml << EOF apiVersion: kubeadm.k8s.io/v1beta3 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: ${ip} bindPort: 6443 nodeRegistration: imagePullPolicy: IfNotPresent name: node taints: null --- apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {} dns: {} etcd: local: dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/google_containers kind: ClusterConfiguration kubernetesVersion: ${k8sVersion} networking: dnsDomain: cluster.local serviceSubnet: ${serviceSubnet} podSubnet: ${podSubnet} scheduler: {} --- apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration mode: ipvs --- apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration cgroupDriver: systemd EOF if [[ -f /root/kubeadm-config.yaml ]];then action "生成K8s初始化文件:" else action "生成K8s初始化文件:" false fi echo -e "\033[32m# K8s初始化中,时间可能较长,可以使用 tailf k8s_init.log 可追踪整个过程....\033[0m" echo kubeadm init --config /root/kubeadm-config.yaml --ignore-preflight-errors=SystemVerification &>k8s_init.log if [[ $? -eq 0 ]];then action "K8s初始化:" mkdir -p $HOME /.kube sudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/config sudo chown $(id -u):$(id -g) $HOME /.kube/config else action "K8s初始化:" false exit 5 fi } k8sNetwork (wget -O /root/calico.yaml http://120.48.34.146/calico.yaml) &>/dev/null (kubectl apply -f /root/calico.yaml) &>/dev/null if [[ $? -eq 0 ]];then action "K8s网络插件:" else action "K8s网络插件:" false fi } k8sTaint (kubectl taint nodes --all node-role.kubernetes.io/master-) &>/dev/null if [[ $? -eq 0 ]];then action "设置Master节点可调度:" else action "设置Master节点可调度:" false fi } initEnv clear;echo "一键部署单机版K8S脚本" openNetwork hostName stopFirewall swapOff timeSync ipvs addKernelArg dockerInstall } k8s clear;k8sInstall k8sInit k8sNetwork k8sTaint echo echo -e "\033[32m# K8s单机版部署完成,等待Pod全部运行成功即可使用 使用 kubectl get pods -n kube-system 关注Pod状态...\033[0m" bash } initEnv k8s
# 部署 dashboard1 kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
1 2 3 kubernetes-dashboard dashboard-metrics-scraper-79c5968bdc-24bws 1/1 Running 0 2m5s kubernetes-dashboard kubernetes-dashboard-658485d5c7-9hpsc 1/1 Running 0 2m5s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 设置访问端口 kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard :/type 改为 NodePort kubectl get svc -A |grep kubernetes-dashboard [root@master ~] kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.96.232.147 <none> 8000/TCP 6m7s kubernetes-dashboard kubernetes-dashboard NodePort 10.96.28.103 <none> 443:31882/TCP 6m7s [root@master ~] apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kubernetes-dashboard --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kubernetes-dashboard [root@master ~] serviceaccount/admin-user created clusterrolebinding.rbac.authorization.k8s.io/admin-user created kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}" ) -o go-template="{{.data.token | base64decode}}" eyJhbGciOiJSUzI1NiIsImtpZCI6IkY5LU9Jc0pnblNNOVJhM1dlWVl6c09DTjNnbFNQa1hzcWhOSThHVENEdlUifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLXp3NmRzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJkOTRmMDZlNi1kNTkxLTRmMzktODMxNC0zNzI2MDVhM2RkN2MiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.TMTc8QDTIo3qhsGTYD05c8txOyq2op7xW9ZQB5ICVw5x4fg-L0iUnn1jGyo4REP6ci63zBR-xmirqHy1eQ5GgT1nwGZnv4oKqNElm8-wkAit5rEgVN7ATo5GN3VrRQgNyBsHwqFhe1SsrK47flCZcmBvWbgmU4ugFfrNZ8xHkSURKrLAPUPjsYUC6ugyrEMqfwhcxzMiZcSKxG20jjLgVK7Pd_T01NAObUb_lCjq7mrEV0KdHcYTtSYwVwV88mTu5vwb39k-10V0s6HOqiDx87lp7fPtctrcR3mRiT1PkEvsyhCb8qAuFDPuaJZtESFu2dCXP_fVmv5g7AhSO_qUHg
如果页面没有接受风险,换浏览器或者空白输入 thisisunsafe
通过 token 访问 dashboard
1 2 3 4 [root@master1 ~] [root@master1 ~] [root@master1 ~]
通过 kubeconfig 访问 dashborad
1 2 3 4 5 6 7 cd /etc/kubernetes/pki/kubectl config set-cluster kubernetes --certificate-authority=./ca.crt --server="https://192.168.40.249:6443" --embed-certs=true --kueconfig=/root/dashboard-admin.conf DEF_NS_ADMIN_TOKEN=$(kubectl get secret kubernetes-dashboard-token-dmv8x -n kubernetes-dashboard -o jsonpath={.data.token}|base64 -d kubectl config set-credentials dashboard-admin --token=$DEF_NS_ADMIN_TOKEN --kubeconfig=/root/dashboard-admin.conf kubectl config set-context dashboard-admin@kubernetes --cluster=kubernetes --user=dashboard-admin --kubeconfig=/root/dashboard-admin.onf kubectl config use-context dashboard-admin@kubernetes --kubeconfig=/root/dashboard-admin.conf vim /root/dashboard-admin.conf
# 安装 containerd对于 1.24 以上的版本,使用 containerd 管理和运行容器,在此版本之前使用的是 docker
Kubernetes 中的容器运行时就像一个保姆一样,它负责管理容器的生命周期和资源隔离,确保容器能够在节点上稳定地运行。其中,containerd 就是一个常用的容器运行时,它实现了 Kubernetes 规定的 CRI 接口,因此可以被 Kubernetes 作为容器运行时来使用。简单来说,就是 Kubernetes 需要容器运行时来管理和运行容器,而 containerd 就是 Kubernetes 中常用的一种容器运行时,能够让 Kubernetes 更加高效、稳定地运行容器化应用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 yum install containerd.io-1.6.6 -y mkdir -p /etc/containerdcontainerd config default > /etc/containerd/config.toml vim /etc/containerd/config.toml SystemdCgroup = true sandbox_image="registry.aliyuncs.com/google_containers/pause:3.7" 相比 cgroupfs,systemd-cgroup 在资源隔离方面提供了更好的性能和更多的特性。例如,systemd-cgroup 可以使用更多的内存压缩算法,以便更有效地使用内存。此外,systemd-cgroup 还提供了更好的 cgroup 监控和控制机制,可以更精确地调整容器的资源使用量。 总之,使用 systemd-cgroup 作为容器运行时的 cgroup 驱动程序,可以提高 Kubernetes 集群中容器的资源管理效率,从而提升整个集群的性能。 在 Kubernetes 中,每个 Pod 中都有一个 pause 容器,这个容器不会运行任何应用,只是简单地 sleep 。它的作用是为了保证 Pod 中所有的容器共享同一个网络命名空间和 IPC 命名空间。pause 容器会在 Pod 的初始化过程中首先启动,然后为 Pod 中的其他容器创建对应的网络和 IPC 命名空间,并且在其他容器启动之前保持运行状态,以保证其他容器可以加入到共享的命名空间中。 简单来说,pause 容器就是一个占位符,它为 Pod 中的其他容器提供了一个共享的环境,使它们可以共享同一个网络和 IPC 命名空间。这也是 Kubernetes 实现容器间通信和网络隔离的重要机制之一。 创建/etc/crictl.yaml文件 [root@xianchaomaster1 ~] runtime-endpoint: unix:///run/containerd/containerd.sock image-endpoint: unix:///run/containerd/containerd.sock timeout : 10debug: false EOF 这个文件是 crictl 工具的配置文件,用于指定与 containerd 交互的相关设置: 指定unix:///run/containerd/containerd.sock 是为了告诉 crictl 使用 Unix 域套接字的方式来连接 containerd 的 API。containerd 提供了一个 socket 文件 /run/containerd/containerd.sock,crictl 通过连接该 socket 文件,可以与 containerd 进行通信,管理容器和镜像等操作。 1)runtime-endpoint:指定 containerd 的运行时接口地址,以便 crictl 可以与 containerd 通信来管理容器生命周期和资源隔离。 2)image-endpoint:指定 containerd 的镜像接口地址,以便 crictl 可以与 containerd 通信来管理镜像的拉取和推送。 3)timeout :指定 crictl 等待 containerd 响应的最大时间,避免出现无响应的情况。 4)debug:开启或关闭 crictl 的调试模式,方便排查问题。 配置containerd镜像加速器,k8s所有节点均按照以下配置: 编辑vim /etc/containerd/config.toml文件 找到config_path = "" ,修改成如下目录: config_path = "/etc/containerd/certs.d" mkdir /etc/containerd/certs.d/docker.io/ -pvim /etc/containerd/certs.d/docker.io/hosts.toml [host."https://vh3bm52y.mirror.aliyuncs.com" ,host."https://registry.docker-cn.com" ] capabilities = ["pull" ,"push" ] 重启containerd: systemctl restart containerd yum install docker-ce -y vim /etc/docker/daemon.json 写入如下内容: { "registry-mirrors" :["https://vh3bm52y.mirror.aliyuncs.com" ,"https://registry.docker-cn.com" ,"https://docker.mirrors.ustc.edu.cn" ,"https://dockerhub.azk8s.cn" ,"http://hub-mirror.c.163.com" ] } 重启docker: systemctl restart docker
1 2 3 1.ctr是containerd自带的CLI命令行工具,crictl是k8s中CRI(容器运行时接口)的客户端,k8s使用该客户端和containerd进行交互; 2.ctr和crictl命令具体区别如下,也可以--help查看。crictl缺少对具体镜像的管理能力,可能是k8s层面镜像管理可以由用户自行控制,能配置pod里面容器的统一镜像仓库,镜像的管理可以有habor
1 2 3 K8s官方文档:https://kubernetes.io/ K8s中文官方文档: https://kubernetes.io/zh/ K8s Github地址:https://github.com/kubernetes/kubernetes
# NamespaceKubernetes 支持多个虚拟集群,它们底层依赖于同一个物理集群。 这些虚拟集群被称为命名空间。
命名空间 namespace 是 k8s 集群级别的资源,可以给不同的用户、租户、环境或项目创建对应的命名空间
命名空间适用于存在很多跨多个团队或项目的用户的场景。默认存放在 default 空间下
隔离资源,不隔离网络
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 [root@master ~] NAME STATUS AGE calico-system Active 41h default Active 41h kube-node-lease Active 41h kube-public Active 41h kube-system Active 41h kubernetes-dashboard Active 27m tigera-operator Active 41h [root@master ~] [root@master ~] [root@master ~] kubectl delete ns 111 kubectl create ns 111 kubectl get ns apiVersion: v1 kind: Namespace metadata: name: hello kubectl explain ResourceQuota apiVersion: v1 kind: ResourceQuota metadata: name: mem-cpu-quota namespace: testing spec: hard: requests.cpu: "2" requests.memory: 2Gi limits.cpu: "4" limits.memory: 4Gi [root@master1 ~] NAME AGE REQUEST LIMIT mem-cpu-quota 18s requests.cpu: 0/2, requests.memory: 0/1Gi limits.cpu: 0/4, limits.memory: 0/2Gi request node必须有空闲的request指定的内存才会调度pod到该node上 limit 是限制不能超过指定的内存和CPUapiVersion: v1 kind: Pod metadata: name: pod-test namespace: test labels: app: tomcat-pod-test spec: containers: - name: tomcat-test ports: - containerPort: 8080 image: tomcat-8.5-jre8 imagePullPolicy: IfNotPresent resources: requests: memory: "100Mi" cpu: "500m" limits: memory: "2Gi" cpu: "2"
# pod运行中的一组容器,Pod 是 kubernetes 中应用的最小调度单元 k8s 是通过定义一个 Pod 的资源,然后在 Pod 里面运行容器,容器需要指定一个镜像,这样就可以用来运行具体的服务。
一个 Pod 封装一个容器(也可以封装多个容器),Pod 里的容器共享存储、网络等 。也就是说,应该把整个 pod 看作虚拟机,然后每个容器相当于运行在虚拟机的进程。
Pod 是需要调度到 k8s 集群的工作节点来运行的,具体调度到哪个节点,是根据 scheduler 调度器实现的。
# pod 管理多个容器pod 之间隔离,pod 中可以运行多个容器,pod 中共享资源
Pod 中可以同时运行多个容器。同一个 Pod 中的容器会自动的分配到同一个 node 上。同一个 Pod 中的容器共享资源、网络环境,它们总是被同时调度,在一个 Pod 中同时运行多个容器是一种比较高级的用法,只有当你的容器需要紧密配合协作的时候才考虑用这种模式。
例如,你有一个容器作为 web 服务器运行,需要用到共享的 volume,有另一个 “sidecar” 容器来从远端获取资源更新这些文件。
一些 Pod 有 init 容器和应用容器。 在应用程序容器启动之前,运行初始化容器。比如 es 就需要有 init 容器修改 es 内核参数
# Pod 网络1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [root@master1 pki] NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE default nginx-7f466444dc-jbhpm 1/1 Running 0 77m 10.244.166.134 node1 <none> kube-system calico-kube-controllers-57c7b58f66-b7pw7 1/1 Running 0 24h 10.244.166.132 node1 <none> kube-system calico-node-fdzw9 1/1 Running 1 24h 192.168.13.188 master2 <none> kube-system calico-node-hz96l 1/1 Running 1 24h 192.168.13.199 node1 <none> Pod是有IP地址的,假如pod不是共享物理机ip,由网络插件(calico、flannel、weave)划分的ip,每个pod都被分配唯一的IP地址 控制节点组件 pod ip和物理机ip一样 如果pod由calico分配,且不共享物理机IP,那么IP唯一,ip地址段在配置时指定 docker 容器间通信,通过--net container参数,指定其和已经存在的某个容器共享一个 Network Namespace。 docker run --name container2 --net=container:none -it --privileged=true centos Kubernetes中容器共享的方式 在k8s中,启动Pod时,会先启动⼀个pause 的容器,然后将后续的所有容器都 link 到这个pause 的容器,以实现⽹络共享
# pod 存储创建 Pod 的时候可以指定挂载的存储卷。 POD 中的所有容器都可以访问共享卷,允许这些容器共享数据。 Pod 只要挂载持久化数据卷,Pod 重启之后数据还是会存在的
volume 可以是 nfs,cefs,或者云存储
Pod 中的所用容器会被一致调度、同节点部署,并且在一个 “共享环境” 中运行。
1)所有容器共享一个 IP 地址和端口空间,意味着容器之间可以通过 localhost 高效访问,不能有端口冲突
2)允许容器之间共享存储卷,通过文件系统交互信息
些容器需要紧密联系,需要一起工作。Pod 提供了比容器更高层次的抽象, Pod 中的所有容器使用同一个网络的 namespace,即相同的 IP 地址和 Port 空间。它们可以直接用 localhost 通信。同样的,这些容器可以共享存储,当 K8s 挂载 Volume 到 Pod 上,本质上是将 volume 挂载到 Pod 中的每一个容器里。
通过 pod 可以实现代码自动更新和日志收集
1 生产环境部署了一个go的应用,而且部署了几百个节点,希望这个应用可以定时的同步最新的代码,以便自动升级线上环境。这时,我们不希望改动原来的go应用,可以开发一个Git代码仓库的自动同步服务,然后通过Pod的方式进行编排,并共享代码目录,就可以达到更新java应用代码的效果。
pod 实现日志收集并 aggregate
使用 Pod 的方式,通过简单的编排,既可以保持原有服务逻辑、部署方式不变,又可以增加新的日志收集服务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 1. kubectl run 命令行创建 (不常用) 2. yaml文件创建 1 .自主式pod:直接定义一个pod资源 apiVersion: v1 kind: Pod metadata: name: tomcat-test namespace: default labels: app: tomcat spec: containers: - name: tomcat-java ports: - containerPort: 8080 image: tomcat:latest imagePullPolicy: IfNotPresent [root@master1 ~ ] [root@master1 ~ ] NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES default tomcat-test 0 /1 ContainerCreating 0 66s <none> node1 <none> <none> pod被删之后不会在重启 kubectl delete pod 2 .控制器管理pod 常见的管理Pod的控制器:Replicaset、Deployment、Job、CronJob、Daemonset、Statefulset。 控制器管理的Pod可以确保Pod始终维持在指定的副本数运行。 kind: Deployment、Job... apiVersion: apps/v1 kind: Deployment metadata: name: nginx-test labels: app: nginx-deploy spec: selector: matchLabels: app: nginx replicas: 2 template: metadata: labels: app: nginx spec: containers: - name: my-nginx image: xianchao/nginx:v1 imagePullPolicy: IfNotPresent ports: - containerPort: 80
# pod 创建机制kubectl 执行的时候先找 kubeconfig 的环境变量,如果没有就找~/.kube/config
kubectl config view 查看不带 key 的 config
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@master1 ~ ] apiVersion: v1 clusters: - cluster: certificate-authority-data: DATA+OMITTED server: https://192.168.13.249:16443 name: kubernetes contexts: - context: cluster: kubernetes user: kubernetes-admin name: kubernetes-admin@kubernetes current-context: kubernetes-admin@kubernetes kind: Config preferences: {}users: - name: kubernetes-admin user: client-certificate-data: REDACTED client-key-data: REDACTED
1 2 3 4 5 6 7 8 9 10 11 12 13 14 kubectl apply -f nginx-deploy.yaml->找到config文件,基于config文件指定的用户访问指定的集群,这样就找到了apiserver 第一步: 通过 kubectl 命令向 apiserver 提交创建pod的请求,apiserver接收到pod创建请求后,会将pod的属性信息(metadata)写入etcd。 第二步: apiserver触发watch机制准备创建pod,信息转发给调度器scheduler,调度器使用调度算法选择node,调度器将node信息给apiserver,apiserver将绑定的node信息写入etcd 第三步: apiserver又通过watch机制,调用kubelet,指定pod信息,调用容器运行时创建并启动pod内的容器。 第四步: 创建完成之后反馈给kubelet, kubelet又将pod的状态信息给apiserver, apiserver又将pod的状态信息写入etcd。
# yaml 创建 pod1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 [root@master2 ~ ] KIND: Pod VERSION: v1 DESCRIPTION: Pod is a collection of containers that can run on a host. This resource is created by clients and scheduled onto hosts. FIELDS: apiVersion <string> APIVersion defines the versioned schema of this representation of an object. Servers should convert recognized schemas to the latest internal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources kind <string> Kind is a string value representing the REST resource this object represents. Servers may infer this from the endpoint the client submits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds metadata <Object> Standard object's metadata. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata spec <Object> Specification of the desired behavior of the pod. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status status <Object> Most recently observed status of the pod. This data may not be up to date. Populated by the system. Read-only. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status [root@master2 ~ ] KIND: Pod VERSION: v1 RESOURCE: metadata <Object> DESCRIPTION: Standard object's metadata. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata ObjectMeta is metadata that all persisted resources must have, which includes all objects users must create. FIELDS: annotations <map[string]string> Annotations is an unstructured key value map stored with a resource that may be set by external tools to store and retrieve arbitrary metadata. They are not queryable and should be preserved when modifying objects. More info: http://kubernetes.io/docs/user-guide/annotations [root@master2 ~ ] KIND: Pod VERSION: v1 RESOURCE: spec <Object> DESCRIPTION: Specification of the desired behavior of the pod. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status PodSpec is a description of a pod. FIELDS: activeDeadlineSeconds <integer> Optional duration in seconds the pod may be active on the node relative to StartTime before the system will actively try to mark it failed and kill associated containers. Value must be a positive integer. affinity <Object> If specified, the pod's scheduling constraints [root@master2 ~ ] KIND: Pod VERSION: v1 RESOURCE: containers <[]Object> DESCRIPTION: List of containers belonging to the pod. Containers cannot currently be added or removed. There must be at least one container in a Pod. Cannot be updated. A single application container that you want to run within a pod. FIELDS: args <[]string> Arguments to the entrypoint. The docker image's CMD is used if this is not provided. Variable references $(VAR_NAME) are expanded using the container's environment. If a variable cannot be resolved, the reference in the input string will be unchanged. The $(VAR_NAME) syntax can be escaped with a double $$, ie: $$(VAR_NAME). Escaped references will never be expanded, regardless of whether the variable exists or not. Cannot be updated. More info: https://kubernetes.io/docs/tasks/inject-data-application/define-command-argument-container/#running-a-command-in-a-shell [root@master2 ~ ] KIND: Pod VERSION: v1 RESOURCE: ports <[]Object> DESCRIPTION: List of ports to expose from the container. Exposing a port here gives the system additional information about the network connections a container uses, but is primarily informational. Not specifying a port here DOES NOT prevent that port from being exposed. Any port which is listening on the default "0.0.0.0" address inside a container will be accessible from the network. Cannot be updated. ContainerPort represents a network port in a single container. FIELDS: containerPort <integer> -required- Number of port to expose on the pod's IP address. This must be a valid port number, 0 < x < 65536 . [root@master1 ~ ] apiVersion: v1 apiVersion: v1 kind: Pod metadata: labels: app: tomcat name: tomcat-cattt namespace: default spec: activeDeadlineSeconds: 10000 containers: - name: tomcat-doggg image: tomcat:9.0 imagePullPolicy: IfNotPresent ports: - containerPort: 8080 [root@master1 ~ ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 [root@master ~] NAMESPACE NAME READY STATUS RESTARTS AGE default mynginx 1/1 Running 0 84s [root@master ~] Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 2m17s default-scheduler Successfully assigned default/mynginx to node2 Normal Pulling 2m16s kubelet Pulling image "nginx" Normal Pulled 71s kubelet Successfully pulled image "nginx" in 1m5.193735599s Normal Created 67s kubelet Created container mynginx Normal Started 67s kubelet Started container mynginx [root@master ~] [root@master ~] [root@master1 ~] [root@master1 ~] [root@master ~] apiVersion: v1 kind: Pod metadata: labels: run: mynginx name: mynginx spec: containers: - image: nginx name: mynginx [root@master ~] [root@master ~] [root@master ~] /docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration /docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/ /docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh 10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf 10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf /docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh /docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh /docker-entrypoint.sh: Configuration complete; ready for start up 2023/04/10 07:09:42 [notice] 1 2023/04/10 07:09:42 [notice] 1 2023/04/10 07:09:42 [notice] 1 2023/04/10 07:09:42 [notice] 1 2023/04/10 07:09:42 [notice] 1 2023/04/10 07:09:42 [notice] 1 2023/04/10 07:09:42 [notice] 1 2023/04/10 07:09:42 [notice] 1 [root@master ~] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES mynginx 1/1 Running 0 3m55s 192.168.104.4 node2 <none> <none> [root@master ~] [root@master ~] [root@master1 ~] 集群中的任意一个机器,任意一个应用都能通过pod分配的ip访问pod NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES busybox 1/1 Terminating 0 127m 10.244.166.130 node1 <none> <none> 10.244网段只能在集群内访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 apiVersion: v1 kind: Pod metadata: labels: run: myapp name: myapp spec: containers: - image: nginx name: nginx - image: tomcat:8.5.68 name: tomcat pod内只需要通过127.0.0.1即可访问 pod内两个容器占用同一个端口会导致error
# labels标签其实就一对 key/value ,被关联到对象上,比如 Pod, 标签的使用我们倾向于能够表示对象的特殊特点,就是一眼就看出了这个 Pod 是干什么的,标签可以用来划分特定的对象(比如版本,服务类型等),标签可以在创建一个对象的时候直接定义,也可以在后期随时修改,每一个对象可以拥有多个标签,但是,key 值必须是唯一的。创建标签之后也可以方便我们对资源进行分组管理。如果对 pod 打标签,之后就可以使用标签来查看、删除指定的 pod。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 [root@master1 ~] [root@master1 ~] NAME READY STATUS RESTARTS AGE LABELS tomcat-cattt 1/1 Running 0 69m app=tomcat [root@master1 ~] pod/tomcat-cattt labeled [root@master1 ~] NAME READY STATUS RESTARTS AGE LABELS tomcat-cattt 1/1 Running 0 70m app=tomcat,hahaha=shabi [root@master1 ~] NAME READY STATUS RESTARTS AGE LABELS tomcat-cattt 1/1 Running 0 72m app=tomcat,hahaha=shabi [root@master1 ~] NAME READY STATUS RESTARTS AGE tomcat-cattt 1/1 Running 0 72m [root@master1 ~] NAME READY STATUS RESTARTS AGE LABELS tomcat-cattt 1/1 Running 0 73m app=tomcat,hahaha=shabi [root@master1 ~] NAME READY STATUS RESTARTS AGE HAHAHA tomcat-cattt 1/1 Running 0 73m shabi [root@master1 ~] NAME READY STATUS RESTARTS AGE HAHAHA APP tomcat-cattt 1/1 Running 0 74m shabi tomcat tomcat-test 1/1 Running 0 21h tomcat [root@master1 ~] NAMESPACE NAME READY STATUS RESTARTS AGE LABELS default busybox 1/1 Running 0 46h run=busybox default nginx-7f466444dc-8pbkp 1/1 Running 0 23h k8s-app=nginx,pod-template-hash=7f466444dc default nginx-7f466444dc-jbhpm 1/1 Running 0 23h k8s-app=nginx,pod-template-hash=7f466444dc default tomcat-cattt 1/1 Running 0 75m app=tomcat,hahaha=shabi default tomcat-test 1/1 Running 0 21h app=tomcat kube-system calico-kube-controllers-57c7b58f66-b7pw7 1/1 Running 0 46h k8s-app=calico-kube
# node 节点选择器我们在创建 pod 资源的时候,pod 会根据 schduler 进行调度,那么默认会调度到随机的一个工作节点,如果我们想要 pod 调度到指定节点或者调度到一些具有相同特点的 node 节点,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiVersion: v1 kind: Pod metadata: name: demo-pod namespace: default labels: app: myapp env : dev spec: nodeName: master3 containers: - name: tomcat-pod-java ports: - containerPort: 8080 image: tomcat:9.0 imagePullPolicy: IfNotPresent - name: busybox image: busybox:latest imagePullPolicy: IfNotPresent command : - "/bin/sh" - "-c" - "sleep 3600" default demo-pod 2/2 Running 0 2m20s 10.244.136.2 master3 <none> <none>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 apiVersion: v1 kind: Pod metadata: name: demo-pod-1 namespace: default labels: app: myapp env : dev spec: nodeSelector: disk: ceph containers: - name: tomcat-pod-java ports: - containerPort: 8080 image: tomcat:9.0 imagePullPolicy: IfNotPresent demo-pod-1 0/1 Pending 0 17s <none> <none> <none> <none> [root@master1 ~] NAME STATUS ROLES AGE VERSION LABELS master1 Ready control-plane,master 47h v1.20.6 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master1,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master= master2 Ready control-plane,master 47h v1.20.6 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master2,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master= [root@master1 ~] apply -f 0/4 nodes are available: 1 node(s) didn't match Pod' s node affinity, 3 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate. [root@master1 ~]# kubectl label nodes node1 disk=ceph [root@master1 ~]# kubectl apply -f demo-pod-1 1/1 Running 0 95s 10.244.166.139 node1 <none> <none> # 删除节点标签 [root@master1 ~]# kubectl label nodes master1 disk- node/master1 labeled # 只有nodename可以强行调度到master,nodeselector不能强行调度到master即使label匹配 # kubectl delete -f x.yaml --force --grace-period=0 强行删除pod
1 2 3 4 5 6 7 8 9 10 11 12 13 spec: nodeName: node2 nodeSelector: disk: ceph 总结:同一个yaml文件里定义pod资源,如果同时定义了nodeName和NodeSelector,那么条件必须都满足才可以,有一个不满足都会调度失败
# 节点亲和性、反亲和性node 节点亲和性调度:nodeAffinity
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 [root@master1 ~] KIND: Pod VERSION: v1 RESOURCE: affinity <Object> DESCRIPTION: If specified, the pod's scheduling constraints Affinity is a group of affinity scheduling rules. FIELDS: nodeAffinity <Object> Describes node affinity scheduling rules for the pod. podAffinity <Object> Describes pod affinity scheduling rules (e.g. co-locate this pod in the same node, zone, etc. as some other pod(s)). podAntiAffinity <Object> Describes pod anti-affinity scheduling rules (e.g. avoid putting this pod in the same node, zone, etc. as some other pod(s)). # node亲和性 [root@prometheus-master ~]# kubectl explain pods.spec.affinity.nodeAffinity KIND: Pod VERSION: v1 FIELDS: preferredDuringSchedulingIgnoredDuringExecution <[]Object> requiredDuringSchedulingIgnoredDuringExecution <Object> prefered表示有节点尽量满足这个位置定义的亲和性,这不是一个必须的条件,软亲和性 require表示必须有节点满足这个位置定义的亲和性,这是个硬性条件,硬亲和性 可以使用operator字段来为Kubernetes设置在解释规则时要使用的逻辑操作符。你可以使用In、NotIn, Exists , DoesNotExist,Gt和Lt之一作为操作符。 NotIn和 DoesNotExist可用来实现节点反亲和性行为。你也可以使用节点污点将Pod从特定节点上驱逐。 # 硬亲和性 vim pod6.yaml apiVersion: v1 kind: Pod metadata: name: pod-affinity namespace: default labels: app: myapp spec: containers: - name: pod-affinity image: tomcat-8.5-jre8 imagePullPolicy: IfNotPresent affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: zone # label key operator: In # condition values: # label value - foo - bar 由于初始没有node有zone这个label,所以会pending,一定有某个node被label对应的标签,pod会被立刻创建 pod-affinity 0/1 Pending 0 78s <none> prometheus-node2 pod-affinity 0/1 ContainerCreating 0 78s <none> prometheus-node2 pod-affinity 0/1 ContainerCreating 0 79s <none> prometheus-node2 pod-affinity 1/1 Running 0 80s 10.244.64.44 prometheus-node2 由于是硬亲和性,因此如果没有node有对应的label就不调度 [root@master1 ~]# kubectl apply -f pod6.yaml 0/4 nodes are available: 1 node(s) didn' t match Pod's node affinity, 3 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn' t tolerate.vim pod7.yaml apiVersion: v1 kind: Pod metadata: name: pod-node-affinity-demo-2 namespace: default labels: app: myapp tier: frontend spec: containers: - name: myapp image: tomcat-8.5-jre8 imagePullPolicy: IfNotPresent affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - preference: matchExpressions: - key: zone1 operator: In values: - foo1 - bar1 weight: 10 - preference: matchExpressions: - key: zone2 operator: In values: - foo2 - bar2 weight: 20 [root@master1 ~] NAME READY STATUS RESTARTS AGE pod-node-affinity-demo-2 1/1 Running 0 5s [root@master1 ~] [root@master1 ~] [root@master1 ~] [root@master1 ~] [root@master1 ~]
pod 节点亲和性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 pod自身的亲和性调度有两种表示形式: podaffinity:pod和pod更倾向在一起,把相近的pod结合到相近的位置,如同一区域,同一机架,这样的话pod和pod之间更好通信,比方说有两个机房,这两个机房部署的集群有1000台主机,那么我们希望把nginx和tomcat都部署同一个地方的node节点上,可以提高通信效率; podunaffinity:pod和pod更倾向不j在一起,如果部署两套程序,那么这两套程序更倾向于反亲和性,这样相互之间不会有影响。 prefer:软亲和性 required:硬亲和性 topologyKey:判断pod是否在同一位置 位置拓扑的键,这个是必须字段 怎么判断是不是同一个位置: rack=rack1 row=row1 使用rack的键是同一个位置 使用row的键是同一个位置 labelSelector: 我们要判断pod跟别的pod亲和,跟哪个pod亲和,需要靠labelSelector,通过labelSelector选则一组能作为亲和对象的pod资源 namespace: labelSelector需要选则一组资源,那么这组资源是在哪个名称空间中呢,通过namespace指定,如果不指定namespaces,那么就是当前创建pod的名称空间 vim pod8.yaml apiVersion: v1 kind: Pod metadata: name: pod-first labels: app2: myapp2 tier: frontend spec: containers: - name: myapp image: tomcat-8.5-jre8 imagePullPolicy: IfNotPresent vim pod9.yaml apiVersion: v1 kind: Pod metadata: name: pod-second labels: app: backend tier: db spec: containers: - name: busybox image: busybox:latest imagePullPolicy: IfNotPresent command: ["sh" ,"-c" ,"sleep 3600" ] affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - {key: app2 , operator: In , values: ["myapp2" ]} topologyKey: kubernetes.io/hostname pod-first 1 /1 Running 0 19m 10.244 .166 .145 node1 <none> <none> pod-second 1 /1 Running 0 101s 10.244 .166 .146 node1 <none> <none> 先判断标签是否一样,来决定pod是否调度到一起,在根据topologyKey决定调度到那个node apiVersion: v1 kind: Pod metadata: name: pod-second labels: app: backend tier: db spec: containers: - name: busybox image: busybox:latest imagePullPolicy: IfNotPresent command: ["sh" ,"-c" ,"sleep 3600" ] affinity: podAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 10 podAffinityTerm: topologyKey: kubernetes.io/hostname labelSelector: matchExpressions: - {key: app1 , operator: In , values: ["myapp1" ]}
pod 反亲和性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 vim pod10.yaml apiVersion: v1 kind: Pod metadata: name: pod-first labels: app1: myapp1 tier: frontend spec: containers: - name: myapp image: tomcat-8.5-jre8 imagePullPolicy: IfNotPresent [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-first 1 /1 Running 0 28s 10.244 .166 .147 node1 <none> <none> vim pod11.yaml apiVersion: v1 kind: Pod metadata: name: pod-second labels: app: backend tier: db spec: containers: - name: busybox image: busybox:latest imagePullPolicy: IfNotPresent command: ["sh" ,"-c" ,"sleep 3600" ] affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - {key: app1 , operator: In , values: ["myapp1" ]} topologyKey: kubernetes.io/hostname pod-first 1 /1 Running 0 4m26s 10.244 .166 .147 node1 <none> <none> pod-second 0 /1 Pending 0 25s <none> <none> <none> <none> pod-first 1 /1 Running 0 52s 10.244 .216 .124 prometheus-node1 <none> <none> pod-second 1 /1 Running 0 10s 10.244 .64 .48 prometheus-node2 <none> <none> kubectl label node node1 zone=foo kubectl label node node2 zone=foo vim po12.yaml apiVersion: v1 kind: Pod metadata: name: pod-first labels: app3: myapp3 tier: frontend spec: containers: - name: myapp image: tomcat-8.5-jre8 imagePullPolicy: IfNotPresent vim pod13.yaml apiVersion: v1 kind: Pod metadata: name: pod-second labels: app: backend tier: db spec: containers: - name: busybox image: busybox:latest imagePullPolicy: IfNotPresent command: ["sh" ,"-c" ,"sleep 3600" ] affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - {key: app3 ,operator: In , values: ["myapp3" ]} topologyKey: zone pod-first 1 /1 Running 0 62s 10.244 .216 .125 prometheus-node1 <none> <none> pod-second 0 /1 Pending 0 5s <none> <none> <none> <none> apiVersion: v1 kind: Pod metadata: name: pod-second labels: app: backend tier: db spec: containers: - name: busybox image: busybox:latest imagePullPolicy: IfNotPresent command: ["sh" ,"-c" ,"sleep 3600" ] affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 10 podAffinityTerm: topologyKey: zone labelSelector: matchExpressions: - {key: app3 , operator: In , values: ["myapp3" ]} pod-first 1 /1 Running 0 6m43s 10.244 .216 .125 prometheus-node1 <none> <none> pod-second 1 /1 Running 0 21s 10.244 .216 .126 prometheus-node1 <none> <none>
podaffinity:pod 节点亲和性,pod 倾向于哪个 pod podantiaffinity:pod 反亲和性 nodeaffinity:node 节点亲和性,pod 倾向于哪个 node
# 污点,容忍度给了节点选则的主动权,我们给节点打一个污点,不容忍的 pod 就运行不上来,污点就是定义在节点上的键值属性数据,可以定决定拒绝那些 pod;
tolerations 是键值数据,用在 pod 上,定义容忍度,能容忍哪些污点
pod 亲和性是 pod 属性;但是污点是 node 的属性,污点定义在 k8s 集群的节点上的一个字段
master 上会有污点Taints: node-role.kubernetes.io/master:NoSchedule
taints 的 effect 用来定义对 pod 对象的排斥等级(效果):
NoSchedule:
NoExecute:
PreferNoSchedule:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 [root@master1 ~] calico-node-mptp2 1/1 Running 1 5d4h 192.168.13.177 master1 <none> <none> coredns-7f89b7bc75-gtmmh 1/1 Running 1 5d4h 10.244.137.67 master1 <none> <none> coredns-7f89b7bc75-hc7ns 1/1 Running 1 5d4h 10.244.137.68 master1 <none> <none> etcd-master1 1/1 Running 3 5d4h 192.168.13.177 master1 <none> <none> kube-apiserver-master1 1/1 Running 5 5d4h 192.168.13.177 master1 <none> <none> kube-controller-manager-master1 1/1 Running 2 5d4h 192.168.13.177 master1 <none> <none> kube-proxy-t9td4 1/1 Running 1 5d4h 192.168.13.177 master1 <none> <none> kube-scheduler-master1 1/1 Running 2 5d4h 192.168.13.177 master1 <none> <none> [root@master1 ~] Tolerations: :NoExecute op=Exists [root@master1 ~] node/node1 tainted vim pod14.yaml apiVersion: v1 kind: Pod metadata: name: taint-pod namespace: default labels: tomcat: tomcat-pod spec: containers: - name: taint-pod ports: - containerPort: 8080 image: tomcat-8.5-jre8 imagePullPolicy: IfNotPresent taint-pod 1/1 Running 0 3s 10.244.216.127 prometheus-node1 <none> <none> 重新创建pod,pod无法忍受node1的污点 taint-pod 1/1 Running 0 4s 10.244.64.49 prometheus-node2 <none> <none> [root@master1 ~] default nginx-7f466444dc-klcl9 1/1 Terminating 0 4m32s 10.244.166.152 node1 <none> <none> vim pod15.yaml apiVersion: v1 kind: Pod metadata: name: myapp-deploy namespace: default labels: app: myapp release: canary spec: containers: - name: myapp image: tomcat-8.5-jre8 imagePullPolicy: IfNotPresent ports: - name: http containerPort: 8080 tolerations: - key: "node-type" operator: "Equal" value: "dev" effect: "NoExecute" tolerationSeconds: 3600 myapp-deploy 1/1 Running 0 2m27s 10.244.166.154 node1 <none> <none> [root@master1 ~] myapp-deploy 0/1 Pending 0 3s apiVersion: v1 kind: Pod metadata: name: myapp-deploy namespace: default labels: app: myapp release: canary spec: containers: - name: myapp image: tomcat-8.5-jre8 imagePullPolicy: IfNotPresent ports: - name: http containerPort: 8080 tolerations: - key: "node-type" operator: "Equal" value: "dev" effect: "NoSchedule" myapp-deploy 1/1 Running 0 28s 10.244.166.157 node1 <none> <none> tolerations: - key: "node-type" operator: "Exists" value: "" effect: "NoSchedule" tolerations: - key: "node-type" operator: "Exists" value: "" effect: "" myapp-deploy 1/1 Running 0 6s 10.244.166.158 node1 <none> <none>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 当某种条件为真时,节点控制器会自动给节点添加一个污点。当前内置的污点包括: node.kubernetes.io/not-ready:节点未准备好。这相当于节点状况 Ready 的值为 "False"。 node.kubernetes.io/unreachable:节点控制器访问不到节点. 这相当于节点状况 Ready 的值为 "Unknown"。 node.kubernetes.io/memory-pressure:节点存在内存压力。 node.kubernetes.io/disk-pressure:节点存在磁盘压力。 node.kubernetes.io/pid-pressure: 节点的 PID 压力。 node.kubernetes.io/network-unavailable:节点网络不可用。 node.kubernetes.io/unschedulable: 节点不可调度。 node.cloudprovider.kubernetes.io/uninitialized:如果 kubelet 启动时指定了一个“外部”云平台驱动, 它将给当前节点添加一个污点将其标志为不可用。在 cloud-controller-manager 的一个控制器初始化这个节点后,kubelet 将删除这个污点。 在节点被驱逐时,节点控制器或者 kubelet 会添加带有 NoExecute 效果的相关污点。 如果异常状态恢复正常,kubelet 或节点控制器能够移除相关的污点。 在某些情况下,当节点不可达时,API 服务器无法与节点上的 kubelet 进行通信。 在与 API 服务器的通信被重新建立之前,删除 Pod 的决定无法传递到 kubelet。 同时,被调度进行删除的那些 Pod 可能会继续运行在分区后的节点上。 这些值都可以修改,比如在内存剩余不足指定数量后会自动打上node.kubernetes.io/disk-pressure的污点,且不能手工删除,除非空出指定大小的内存之后
# pod 常见状态和重启策略
第一阶段:Pending ):
2、我们在请求创建 pod 时,条件不满足,调度没有完成,没有任何一个节点能满足调度条件,已经创建了 pod 但是没有适合它运行的节点叫做挂起,调度没有完成。
失败( Failed ):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非 0 状态退出或者被系统终止。
未知( Unknown ):未知状态,所谓 pod 是什么状态是 apiserver 和运行在 pod 节点的 kubelet 进行通信获取状态信息的,如果节点之上的 kubelet 本身出故障,那么 apiserver 就连不上 kubelet,得不到信息了,就会看 Unknown,通常是由于与 pod 所在的 node 节点通信错误。
Error 状态:Pod 启动过程中发生了错误
成功( Succeeded ):Pod 中的所有容器都被成功终止,即 pod 里所有的 containers 均已 terminated。
第二阶段:Unschedulable :Pod 不能被调度, scheduler 没有匹配到合适的 node 节点
PodScheduled :pod 正处于调度中,在 scheduler 刚开始调度的时候,还没有将 pod 分配到指定的 node,在筛选出合适的节点后就会更新 etcd 数据,将 pod 分配到指定的 node
Initialized :所有 pod 中的初始化容器已经完成了
ImagePullBackOff :Pod 所在的 node 节点下载镜像失败
Running :Pod 内部的容器已经被创建并且启动。
Ready
扩展:还有其他状态,如下:
Evicted 状态:出现这种情况,多见于系统内存或硬盘资源不足,可 df-h 查看 docker 存储所在目录的资源使用情况,如果百分比大于 85%,就要及时清理下资源,尤其是一些大文件、docker 镜像。
CrashLoopBackOff:容器曾经启动了,但可能又异常退出了
查看内存,CPU,磁盘:
free -mh
top
df -hl
kubectl describe pod_name
kubectl logs pod_name
Pod 重启策略
Pod 的重启策略(RestartPolicy)应用于 Pod 内的所有容器,当某个容器异常退出或者健康检查失败时,kubelet 将根据 重启策略来进行相应的操作。
Pod 的 spec 中包含一个 restartPolicy 字段,其可能取值包括 Always、OnFailure 和 Never。默认值是 Always。
Always:只要容器异常退出,kubelet 就会自动重启该容器。(这个是默认的重启策略)
OnFailure:当容器终止运行且退出码不为 0 时,由 kubelet 自动重启该容器。
Never:不论容器运行状态如何,kubelet 都不会重启该容器。
(重启的不是 pod,是 pod 中的容器)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 apiVersion: v1 kind: Pod metadata: name: demo-pod namespace: default labels: app: myapp spec: restartPolicy: Always containers: - name: tomcat-pod-java ports: - containerPort: 8080 image: tomcat-8.5-jre8 imagePullPolicy: IfNotPresent
1 2 3 4 5 6 7 8 9 10 kubectl exec -it demo-pod -- /bin/bash /usr/local/tomcat/bin/shutdown.sh # always - complete - 重启 # onFailure - complete - 不会重启 # never - complete状态,不会重启 kill 1 # always error - 立刻重启 # onFailure - error - 重启 # never - error - 不重启
# pod 生命周期pod 从开始创建到终止退出的时间范围称为 Pod 生命周期
生命周期包含以下几个重要流程:
其中 initcontainers、容器启动后钩子、探测、容器终止前钩子这些是可选项 -
pod 在整个生命周期的过程中总会处于以下几个状态:
Pending:创建了 pod 资源并存入 etcd 中,但尚未完成调度。
ContainerCreating:Pod 的调度完成,被分配到指定 Node 上。处于容器创建的过程中。通常是在拉取镜像的过程中。
Running:Pod 包含的所有容器都已经成功创建,并且成功运行起来。
Succeeded:Pod 中的所有容器都已经成功终止并且不会被重启(重启策略是 never)
Failed:所有容器都已经终止,但至少有一个容器终止失败,也就是说容器返回了非 0 值的退出状态或已经被系统终止。
Unknown:因为某些原因无法取得 Pod 的状态。这种情况通常是因为与 Pod 所在主机通信失败。
pod 生命周期的重要行为:
1、在启动任何容器之前,先创建 pause 基础容器,它初始化 Pod 的环境并为后续加⼊的容器提供共享的名称空间。
2. 初始化容器(initcontainer):
一个 pod 可以拥有任意数量的 init 容器。init 容器是按照顺序以此执行的,并且仅当最后一个 init 容器执行完毕才会去启动主容器。
3. 生命周期钩子:
pod 允许定义两种类型的生命周期钩子,启动后 (post-start) 钩子和停止前 (pre-stop) 钩子
这些生命周期钩子是基于每个容器来指定的,和 init 容器不同的是,init 容器是应用到整个 pod。而这些钩子是针对容器的,是在容器启动后和停止前执行的。比如启动时复制文件到容器中,结束后发送信息到监控
4. 容器探测:
对 Pod 健康状态诊断。分为三种: Startupprobe、Livenessprobe (存活性探测), Readinessprobe (就绪性检测)
Startup(启动探测): 探测容器是否正常运行
Liveness (存活性探测):判断容器是否处于 runnning 状态,根据重启策略决定是否重启容器
Readiness (就绪性检测):判断容器是否准备就绪并对外提供服务,将容器设置为不可用,不接受 service 转发的请求
三种探针用于 Pod 检测:
ExecAction:在容器中执行一个命令,并根据返回的状态码进行诊断,只有返回 0 为成功
TCPSocketAction:通过与容器的某 TCP 端口尝试建立连接
HTTPGetAction:通过向容器 IP 地址的某指定端口的 path 发起 HTTP GET 请求。
6.pod 的终止过程
终止过程主要分为如下几个步骤:
(1) 用户发出删除 pod 命令:kubectl delete pods ,kubectl delete -f yaml
(2) Pod 对象随着时间的推移更新,在宽限期(默认情况下 30 秒),pod 被视为 “dead” 状态
(3) 将 pod 标记为 “Terminating” 状态
(4) 第三步同时运行,监控到 pod 对象为 “Terminating” 状态的同时启动 pod 关闭过程
(5) 第三步同时进行,endpoints 控制器监控到 pod 对象关闭,将 pod 与 service 匹配的 endpoints 列表中删除
(6) 如果 pod 中定义了 preStop 钩子处理程序,则 pod 被标记为 “Terminating” 状态时以同步的方式启动执行;若宽限期结束后,preStop 仍未执行结束,第二步会重新执行并额外获得一个 2 秒的小宽限期
(7) Pod 内对象的容器收到 TERM 信号
(8) 宽限期结束之后,若存在任何一个运行的进程,pod 会收到 SIGKILL 信号
(9) Kubelet 请求 API Server 将此 Pod 资源宽限期设置为 0 从而完成删除操作
# initcontainerspec 字段下有个 initContainers 字段 (初始化容器),Init 容器就是做初始化工作的容器。可以有一个或多个,如果多个按照定义的顺序依次执行,先执行初始化容器 1,再执行初始化容器 2 等,等初始化容器执行完具体操作之后初始化容器就退出了,只有所有的初始化容器执行完后,主容器才启动。
由于一个 Pod 里容器存储卷是共享的,所以 Init Container 里产生的数据可以被主容器使用到,Init Container 可以在多种 K8S 资源里被使用到,如 Deployment、DaemonSet, StatefulSet、Job 等,但都是在 Pod 启动时,在主容器启动前执行,做初始化工作。
初始化容器与主容器区别是:
初始化容器的官方地址:https://kubernetes.io/docs/concepts/workloads/pods/init-containers/#init-containers-in-use
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 apiVersion: v1 kind: Pod metadata: name: myapp-pod labels: app: myapp spec: initContainers: - name: init-myservice image: busybox:1.28 imagePullPolicy: IfNotPresent command : ['sh' , '-c' , "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace) .svc.cluster.local; do echo waiting for myservice; sleep 2; done" ] - name: init-mydb image: busybox:1.28 imagePullPolicy: IfNotPresent command : ['sh' , '-c' , "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace) .svc.cluster.local; do echo waiting for mydb; sleep 2; done" ] containers: - name: myapp-container image: busybox:1.28 command : ['sh' , '-c' , 'echo The app is running! && sleep 3600' ] myapp-pod 0/1 Init:0/2 0 4s 由于两个初始化容器一直无法解析nslookup的域名,导致主容器一致不会创建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 apiVersion: v1 kind: Pod metadata: name: initnginx spec: initContainers: - name: install image: docker.io/library/busybox:1.28 imagePullPolicy: IfNotPresent command : - wget - "-O" - "/work-dir/index.html" - "https://www.baidu.com" volumeMounts: - name: workdir mountPath: /work-dir containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 volumeMounts: - name: workdir mountPath: /usr/share/nginx/html dnsPolicy: Default volumes: - name: workdir emptyDir: {} [root@master1 ~] <!DOCTYPE html> <!--STATUS OK--><html> <head ><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type =text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title>
# 主容器1、容器钩子
初始化容器启动之后,开始启动主容器,在主容器启动之后有一个 post start hook(容器启动后钩子)和 pre stop hook(容器结束前钩子),无论启动后还是结束前所做的事我们可以把它放两个钩子,这个钩子就表示用户可以用它来钩住一些命令,非必须选项
postStart:该钩子在容器被创建后立刻执行,如果该钩子对应的探测执行失败,则该容器会被杀死,并根据该容器的重启策略决定是否要重启该容器,这个钩子不需要传递任何参数。
preStop:该钩子在容器被删除前执行,主要用于释放资源和优雅关闭程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 containers: - image: sample:v2 name: war lifecycle: postStart: exec: command: - "cp" - "/sample.war" - "/app" prestop: httpGet: host: monitor.com path: /waring port: 8080 scheme: HTTP
以上示例中,定义了一个 Pod,包含一个 JAVA 的 web 应用容器,其中设置了 PostStart 和 PreStop 回调函数。即在容器创建成功后,复制 /sample.war 到 /app 文件夹中。而在容器终止之前,发送 HTTP 请求到 http://monitor.com:8080/waring,即向监控系统发送警告。
优雅的删除资源对象
当用户请求删除含有 pod 的资源对象时(如 RC、deployment 等),K8S 为了让应用程序优雅关闭(即让应用程序完成正在处理的请求后,再关闭软件),K8S 提供两种信息通知:
1)、默认:K8S 通知 node 执行 docker stop 命令,docker 会先向容器中 PID 为 1 的进程发送系统信号 SIGTERM,然后等待容器中的应用程序终止执行,如果等待时间达到设定的超时时间,或者默认超时时间(30s),会继续发送 SIGKILL 的系统信号强行 kill 掉进程。
2)、使用 pod 生命周期(利用 PreStop 回调函数),它执行在发送终止信号之前。
1 2 3 4 5 6 7 8 9 10 11 12 13 spec: containers: - name: nginx-demo image: centos:nginx lifecycle: preStop: exec: command: ["/usr/local/nginx/sbin/nginx" ,"-s" ,"quit" ] ports: - name: http containerPort: 80
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 apiVersion: v1 kind: Pod metadata: name: life-demo spec: containers: - name: lifecycle-demo-container image: nginx imagePullPolicy: IfNotPresent lifecycle: postStart: exec: command: ["/bin/sh" , "-c" ,"echo 'lifecycle hookshandler' > /usr/share/nginx/html/test.html" ] preStop: exec: command: - "/bin/sh" - "-c" - "nginx -s stop" [root@prometheus-master pod ] root@life-demo:/# ls /usr/share/nginx/html/ 50x.html index.html test.html root@life-demo:/# cat /usr/share/nginx/html/test.html lifecycle hookshandler kubectl get event 0s Normal Killing pod/life-demo Stopping container lifecycle-demo-container 0s Normal Killing pod/life-demo Stopping container lifecycle-demo-container
pod 在整个生命周期中有非常多的用户行为:
1、初始化容器完成初始化
2、主容器启动后可以做启动后钩子
3、主容器结束前可以做结束前钩子
4、在主容器运行中可以做一些健康检测,如 startupprobe、livenessprobe,readnessprobe
# 容器探测在 Kubernetes 中 Pod 是最小的计算单元,而一个 Pod 又由多个容器组成,相当于每个容器就是一个应用,应用在运行期间,可能因为某些意外情况致使程序挂掉。那么如何监控这些容器状态稳定性,保证服务在运行期间不会发生问题,发生问题后进行重启等机制,就成为了重中之重的事情,考虑到这点 kubernetes 推出了活性探针机制。有了存活性探针能保证程序在运行中如果挂掉能够自动重启,但是还有个经常遇到的问题,比如说,在 Kubernetes 中启动 Pod,显示明明 Pod 已经启动成功,且能访问里面的端口,但是却返回错误信息。还有就是在执行滚动更新时候,总会出现一段时间,Pod 对外提供网络访问,但是访问却发生 404,这两个原因,都是因为 Pod 已经成功启动,但是 Pod 的的容器中应用程序还在启动中导致,考虑到这点 Kubernetes 推出了就绪性探针机制。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 apiVersion: v1 kind: Pod metadata: name: check namespace: default labels: app: check spec: containers: - name: check image: busybox:1.28 imagePullPolicy: IfNotPresent command: - /bin/sh - -c - sleep 10 ;exit
k8s 提供了三种来实现容器探测的方法,分别是:
1、startupProbe:探测容器中的应用是否已经启动。如果提供了启动探测 (startup probe),则暂时禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功 Success。
2、livenessprobe:用指定的方式(exec、tcp、http)检测 pod 中的容器是否正常运行 ,如果检测失败,则认为容器不健康,那么 Kubelet 将根据 Pod 中设置的 restartPolicy 策略来判断 Pod 是否要进行重启操作,如果容器配置中没有配置 livenessProbe,Kubelet 将认为存活探针探测一直为 success(成功)状态。
3、readnessprobe:就绪性探针,用于检测容器中的应用是否可以接受请求 ,当探测成功后才使 Pod 对外提供网络访问,将容器标记为就绪状态,可以加到 pod 前端负载,如果探测失败,则将容器标记为未就绪状态,会把 pod 从前端负载移除。
可以自定义在 pod 启动时是否执行这些检测,如果不设置,则检测结果均默认为通过,如果设置,则顺序为 startupProbe>readinessProbe 和 livenessProbe,readinessProbe 和 livenessProbe 是并发关系
目前 LivenessProbe 和 ReadinessProbe、startupprobe 探测都支持下面三种探针:
1、exec:在容器中执行指定的命令,如果执行成功,退出码为 0 则探测成功。
2、TCPSocket:通过容器的 IP 地址和端口号执行 TCP 检 查,如果能够建立 TCP 连接,则表明容器健康。
3、HTTPGet:通过容器的 IP 地址、端口号及路径调用 HTTP Get 方法,如果响应的状态码大于等于 200 且小于 400,则认为容器健康
探针探测结果有以下值:
1、Success:表示通过检测。
2、Failure:表示未通过检测。
3、Unknown:表示检测没有正常进行。
Pod 探针相关的属性:
探针 (Probe) 有许多可选字段,可以用来更加精确的控制 Liveness 和 Readiness 两种探针的行为
initialDelaySeconds:容器启动后要等待多少秒后探针开始工作,单位 “秒”,默认是 0 秒,最小值是 0
periodSeconds: 执行探测的时间间隔(单位是秒),默认为 10s,单位 “秒”,最小值是 1
timeoutSeconds: 探针执行检测请求后,等待响应的超时时间,默认为 1,单位 “秒”。
successThreshold:连续探测几次成功,才认为探测成功,默认为 1,在 Liveness 探针中必须为 1,最小值为 1。
failureThreshold: 探测失败的重试次数,重试一定次数后将认为失败,在 readiness 探针中,Pod 会被标记为未就绪,默认为 3,最小值为 1
两种探针区别:
ReadinessProbe 和 livenessProbe 可以使用相同探测方式,只是对 Pod 的处置方式不同:
readinessProbe 当检测失败后,将 Pod 的 IP:Port 从对应的 EndPoint 列表中删除。
livenessProbe 当检测失败后,将杀死容器并根据 Pod 的重启策略来决定作出对应的措施。
# 启动探测1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 apiVersion: v1 kind: Pod metadata: name: startupprobe spec: containers: - name: startup image: tomcat-8.5-jre8 imagePullPolicy: IfNotPresent ports: - containerPort: 8080 startupProbe: exec: command: - "/bin/sh" - "-c" - "ps aux | grep tomcat" initialDelaySeconds: 20 periodSeconds: 20 timeoutSeconds: 10 successThreshold: 1 failureThreshold: 3 initialDelaySeconds + (periodSeconds + timeoutSeconds) * failureThreshold
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiVersion: v1 kind: Pod metadata: name: startupprobe spec: containers: - name: startup image: tomcat:9.0 imagePullPolicy: IfNotPresent ports: - containerPort: 8080 startupProbe: tcpSocket: port: 8080 initialDelaySeconds: 20 periodSeconds: 20 timeoutSeconds: 10 successThreshold: 1 failureThreshold: 3 startupprobe 0 /1 ContainerCreating 0 0s <none> node1 <none> <none> startupprobe 0 /1 ContainerCreating 0 1s <none> node1 <none> <none> startupprobe 0 /1 Running 0 2s 10.244 .166 .168 node1 <none> <none> startupprobe 0 /1 Running 0 36s 10.244 .166 .168 node1 <none> <none> startupprobe 1 /1 Running 0 78s 10.244 .166 .168 node1 <none> <none>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 apiVersion: v1 kind: Pod metadata: name: startupprobe spec: containers: - name: startup image: tomcat:9.0 imagePullPolicy: IfNotPresent ports: - containerPort: 8080 startupProbe: httpGet: path: / port: 8080 initialDelaySeconds: 20 periodSeconds: 20 timeoutSeconds: 10 successThreshold: 1 failureThreshold: 3
# 存活探测1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 apiVersion: v1 kind: Pod metadata: name: liveness-exec labels: app: liveness spec: containers: - name: liveness image: busybox:1.28 imagePullPolicy: IfNotPresent args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600 livenessProbe: initialDelaySeconds: 10 periodSeconds: 5 exec : command : - cat - /tmp/healthy liveness-exec 1/1 Running 0 2s 10.244.166.171 node1 <none> <none> liveness-exec 1/1 Running 1 76s 10.244.166.171 node1 <none> <none> liveness-exec 1/1 Running 2 2m30s 10.244.166.171 node1 <none> <none> 10 + 20 * 3
容器启动设置执行的命令:
/bin/sh -c “touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600”
容器在初始化后,首先创建一个 /tmp/healthy 文件,然后执行睡眠命令,睡眠 30 秒,到时间后执行删除 /tmp/healthy 文件命令。而设置的存活探针检检测方式为执行 shell 命令,用 cat 命令输出 healthy 文件的内容,如果能成功执行这条命令,存活探针就认为探测成功,否则探测失败。在前 30 秒内,由于文件存在,所以存活探针探测时执行 cat /tmp/healthy 命令成功执行。30 秒后 healthy 文件被删除,所以执行命令失败,Kubernetes 会根据 Pod 设置的重启策略来判断,是否重启 Pod。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 apiVersion: v1 kind: Pod metadata: name: liveness-http labels: test: liveness spec: containers: - name: liveness image: mydlqclub/springboot-helloworld:0.0.1 imagePullPolicy: IfNotPresent livenessProbe: initialDelaySeconds: 20 periodSeconds: 5 timeoutSeconds: 10 httpGet: scheme: HTTP port: 8081 path: /actuator/health
上面 Pod 中启动的容器是一个 SpringBoot 应用,其中引用了 Actuator 组件,提供了 /actuator/health 健康检查地址,存活探针可以使用 HTTPGet 方式向服务发起请求,请求 8081 端口的 /actuator/health 路径来进行存活判断:
任何大于或等于 200 且小于 400 的代码表示探测成功。
任何其他代码表示失败。
如果探测失败,则会杀死 Pod 进行重启操作。
httpGet 探测方式有如下可选的控制字段:
scheme: 用于连接 host 的协议,默认为 HTTP。
host:要连接的主机名,默认为 Pod IP,可以在 http request head 中设置 host 头部。
port:容器上要访问端口号或名称。
path:http 服务器上的访问 URI。
httpHeaders:自定义 HTTP 请求 headers,HTTP 允许重复 headers。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 apiVersion: v1 kind: Pod metadata: name: liveness-tcp labels: app: liveness spec: containers: - name: liveness image: nginx imagePullPolicy: IfNotPresent livenessProbe: initialDelaySeconds: 15 periodSeconds: 20 tcpSocket: port: 80
# 就绪探测Pod 的 ReadinessProbe 探针使用方式和 LivenessProbe 探针探测方法一样,也是支持三种,只是一个是用于探测应用的存活,一个是判断是否对外提供流量的条件。这里用一个 Springboot 项目,设置 ReadinessProbe 探测 SpringBoot 项目的 8081 端口下的 /actuator/health 接口,如果探测成功则代表内部程序以及启动,就开放对外提供接口访问,否则内部应用没有成功启动,暂不对外提供访问,直到就绪探针探测成功。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 当检测失败后,将 Pod 的 IP:Port 从对应的 EndPoint 列表中删除。 检测成功后才会加到service的endpoint中 apiVersion: v1 kind: Service metadata: name: springboot labels: app: springboot spec: type : NodePort ports: - name: server port: 8080 targetPort: 8080 nodePort: 31180 - name: management port: 8081 targetPort: 8081 nodePort: 31181 selector: app: springboot --- apiVersion: v1 kind: Pod metadata: name: springboot labels: app: springboot spec: containers: - name: springboot image: mydlqclub/springboot-helloworld:0.0.1 imagePullPolicy: IfNotPresent ports: - name: server containerPort: 8080 - name: management containerPort: 8081 readinessProbe: initialDelaySeconds: 20 periodSeconds: 5 timeoutSeconds: 10 httpGet: scheme: HTTP port: 8081 path: /actuator/health
# 混合使用三种探测1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 apiVersion: v1 kind: Service metadata: name: springboot-live labels: app: springboot spec: type : NodePort ports: - name: server port: 8080 targetPort: 8080 nodePort: 31180 - name: management port: 8081 targetPort: 8081 nodePort: 31181 selector: app: springboot --- apiVersion: v1 kind: Pod metadata: name: springboot-live labels: app: springboot spec: containers: - name: springboot image: mydlqclub/springboot-helloworld:0.0.1 imagePullPolicy: IfNotPresent ports: - name: server containerPort: 8080 - name: management containerPort: 8081 readinessProbe: initialDelaySeconds: 20 periodSeconds: 5 timeoutSeconds: 10 httpGet: scheme: HTTP port: 8081 path: /actuator/health livenessProbe: initialDelaySeconds: 20 periodSeconds: 5 timeoutSeconds: 10 httpGet: scheme: HTTP port: 8081 path: /actuator/health startupProbe: initialDelaySeconds: 20 periodSeconds: 5 timeoutSeconds: 10 httpGet: scheme: HTTP port: 8081 path: /actuator/health
# ReplicasetPod 类型的自主式 pod,但是这存在一个问题,假如 pod 被删除了,那这个 pod 就不能自我恢复,就会彻底被删除,线上这种情况非常危险,pod 的控制器,所谓控制器就是能够管理 pod,监测 pod 运行状况,当 pod 发生故障,可以自动恢复 pod。也就是说能够代我们去管理 pod 中间层,并帮助我们确保每一个 pod 资源始终处于我们所定义或者我们所期望的目标状态,一旦 pod 资源出现故障,那么控制器会尝试重启 pod 或者里面的容器,如果一直重启有问题的话那么它可能会基于某种策略来进行重新布派或者重新编排;如果 pod 副本数量低于用户所定义的目标数量,它也会自动补全;如果多余,也会自动终止 pod 资源。
kubectl explain rs
ReplicaSet 是 kubernetes 中的一种副本控制器,简称 rs,主要作用是控制由其管理的 pod,使 pod 副本的数量始终维持在预设的个数。它的主要作用就是保证一定数量的 Pod 能够在集群中正常运行,它会持续监听这些 Pod 的运行状态,在 Pod 发生故障时重启 pod,pod 数量减少时重新运行新的 Pod 副本。官方推荐不要直接使用 ReplicaSet,用 Deployments 取而代之,Deployments 是比 ReplicaSet 更高级的概念,它会管理 ReplicaSet 并提供很多其它有用的特性,最重要的是 Deployments 支持声明式更新,声明式更新的好处是不会丢失历史变更。所以 Deployment 控制器不直接管理 Pod 对象,而是由 Deployment 管理 ReplicaSet,再由 ReplicaSet 负责管理 Pod 对象。
Replicaset 控制器主要由三个部分组成:
1、用户期望的 pod 副本数:用来定义由这个控制器管控的 pod 副本有几个
2、标签选择器:选定哪些 pod 是自己管理的,如果通过标签选择器选到的 pod 副本数量少于我们指定的数量,需要用到下面的组件
3、pod 资源模板:如果集群中现存的 pod 数量不够我们定义的副本中期望的数量怎么办,需要新建 pod,这就需要 pod 模板,新建的 pod 是基于模板来创建的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 apiVersion: apps/v1 kind: ReplicaSet metadata: name: frontend labels: app: shabi tier: zhizhang spec: replicas: 3 selector: matchLabels: tier1: frontend1 template: metadata: labels: tier1: frontend1 spec: containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 readinessProbe: initialDelaySeconds: 20 periodSeconds: 5 timeoutSeconds: 10 httpGet: scheme: HTTP port: 80 path: / startupProbe: initialDelaySeconds: 20 periodSeconds: 5 timeoutSeconds: 10 httpGet: scheme: HTTP port: 80 path: / livenessProbe: initialDelaySeconds: 20 periodSeconds: 5 timeoutSeconds: 10 httpGet: scheme: HTTP port: 80 path: / [root@prometheus-master replicaset ] NAME DESIRED CURRENT READY AGE frontend 3 3 3 8s pod名字 = repset名字 - 随机数,所以在template中只需要定义标签,不需要名字 删除pod之后,pod ip会变,会产生一个IP不同的新的pod repset永远让pod数量维持 [root@prometheus-master replicaset ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES frontend-8t7jx 1 /1 Running 0 56s 10.244 .216 .104 prometheus-node1 <none> <none> frontend-qx7dx 1 /1 Running 0 56s 10.244 .64 .21 prometheus-node2 <none> <none> frontend-s8jgx 1 /1 Running 0 56s 10.244 .216 .103 prometheus-node1 <none> <none>
# pod 动态扩缩容replicaset 可以实现动态变更副本数和镜像
变更镜像的时候需要手动删除原来的 pod (delete pods) 不会滚动更新,如果增加副本数只需要在原有基础上增加 pod 即可,删除副本是随机删除 pod
ReplicaSet 最核心的功能是可以动态扩容和回缩,如果我们觉得两个副本太少了,想要增加,只需要修改配置文件 replicaset.yaml 里的 replicas 的值即可,原来 replicas: 3,现在变成 replicaset: 4,修改之后,执行如下命令更新:
生产环境如果升级,可以删除一个 pod,观察一段时间之后没问题再删除另一个 pod,但是这样需要人工干预多次;实际生产环境一般采用蓝绿发布,原来有一个 rs1,再创建一个 rs2(控制器),通过修改 service 标签,修改 service 可以匹配到 rs2 的控制器,这样才是蓝绿发布,这个也需要我们精心的部署规划,我们有一个控制器就是建立在 rs 之上完成的,叫做 Deployment
# deploymentDeployment 是 kubernetes 中最常用的资源对象,为 ReplicaSet 和 Pod 的创建提供了一种声明式的定义方法,在 Deployment 对象中描述一个期望的状态,Deployment 控制器就会按照一定的控制速率把实际状态改成期望状态,通过定义一个 Deployment 控制器会创建一个新的 ReplicaSet 控制器,通过 ReplicaSet 创建 pod,删除 Deployment 控制器,也会删除 Deployment 控制器下对应的 ReplicaSet 控制器和 pod 资源.
使用 Deployment 而不直接创建 ReplicaSet 是因为 Deployment 对象拥有许多 ReplicaSet 没有的特性,例如滚动升级、金丝雀发布、蓝绿部署和回滚。
声明式定义是指直接修改资源清单 yaml 文件,然后通过 kubectl apply -f 资源清单 yaml 文件,就可以更改资源
Deployment 控制器是建立在 rs 之上的一个控制器,可以管理多个 rs,每次更新镜像版本,都会生成一个新的 rs,把旧的 rs 替换掉,多个 rs 同时存在,但是只有一个 rs 运行。
Deployment 可以使用声明式定义,直接在命令行通过纯命令的方式完成对应资源版本的内容的修改,也就是通过打补丁的方式进行修改;Deployment 能提供滚动式自定义自控制的更新;对 Deployment 来讲,我们在实现更新时还可以实现控制更新节奏和更新逻辑。(先创建还是先删除)
通过 Deployment 对象,你可以做到以下事情:
1、创建 ReplicaSet 和 Pod
2、滚动升级(不停止旧服务的状态下升级)和回滚应用(将应用回滚到之前的版本)
3、平滑地扩容和缩容
4、暂停和继续 Deployment
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@ ~ ] maxSurge <string> 它有两种取值方式,第一种直接给定数量,第二种根据百分比,百分比表示原本是5个,最多可以超出20%,那就允许多一个,最多可以超过40%,那就允许多两个 maxUnavailable <string> 假设有5个副本,最多一个不可用,就表示最少有4个可用 假如pod数为5,surge和maxun都是2 那么最大超出的副本数是5+2 最少副本数为5-2 maxsurge 出现小数向上取整 maxunavailable 出现小数向下取整 ctr -n=k8s.io images import x.tar.gz
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 apiVersion: apps/v1 kind: Deployment metadata: name: myapp-v1 spec: replicas: 2 template: metadata: initialDelaySeconds: 20 timeoutSeconds: 10 httpGet: scheme: HTTP port: 80 path: / livenessProbe: periodSeconds: 5 initialDelaySeconds: 20 timeoutSeconds: 10 httpGet: scheme: HTTP port: 80 path: / readinessProbe: periodSeconds: 5 initialDelaySeconds: 20 timeoutSeconds: 10 httpGet: scheme: HTTP port: 80 path: / selector: matchLabels: app: myapp version: v1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [root@master1 ~] NAME READY UP-TO-DATE AVAILABLE AGE myapp-v1 2/2 2 2 57s [root@master1 ~] NAME DESIRED CURRENT READY AGE myapp-v1-b5d4c8b9d 2 2 2 72s [root@master1 ~] myapp-v1-b5d4c8b9d-cxcvr 1/1 Running 0 108s myapp-v1-b5d4c8b9d-ptsv4 1/1 Running 0 108s 1.NAME :列出名称空间中deployment的名称。 2.READY:显示deployment有多少副本数。它遵循ready/desired的模式。 3.UP-TO-DATE: 显示已更新到所需状态的副本数。 4.AVAILABLE: 显示你的可以使用多少个应用程序副本。 5.AGE :显示应用程序已运行的时间。 1.NAME: 列出名称空间中ReplicaSet资源 2.DESIRED:显示应用程序的所需副本数,这些副本数是在创建时定义的。这是所需的状态。 3.CURRENT: 显示当前正在运行多少个副本。 4.READY: 显示你的用户可以使用多少个应用程序副本。 5.AGE :显示应用程序已运行的时间。
1 2 3 4 spec: replicas: 3 声明式更新 - apply -f
# 滚动更新滚动更新是一种自动化程度较高的发布方式,用户体验比较平滑,是目前成熟型技术组织所采用的主流发布方式,一次滚动发布一般由若干个发布批次组成,每批的数量一般是可以配置的(可以通过发布模板定义),例如第一批 1 台,第二批 10%,第三批 50%,第四批 100%。每个批次之间留观察间隔,通过手工验证或监控反馈确保没有问题再发下一批次,所以总体上滚动式发布过程是比较缓慢的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 kubectl explain deploy.spec.strategy.rollingUpdate KIND: Deployment VERSION: apps/v1 RESOURCE: rollingUpdate <Object> DESCRIPTION: Rolling update config params. Present only if DeploymentStrategyType = RollingUpdate. Spec to control the desired behavior of rolling update. FIELDS: maxSurge <string> The maximum number of pods that can be scheduled above the desired number of pods. Value can be an absolute number (ex: 5 ) or a percentage of desired pods (ex: 10 %). This can not be 0 if MaxUnavailable is 0 . Absolute number is calculated from percentage by rounding up. Defaults to 25 %. Example: when this is set to 30 %, the new ReplicaSet can be scaled up immediately when the rolling update starts, such that the total number of old and new pods do not exceed 130 % of desired pods. Once old pods have been killed, new ReplicaSet can be scaled up further, ensuring that total number of pods running at any time during the update is at most 130 % of desired pods. 它有两种取值方式,第一种直接给定数量,第二种根据百分比,百分比表示原本是5个,最多可以超出20%,那就允许多一个,最多可以超过40%,那就允许多两个 maxUnavailable <string> The maximum number of pods that can be unavailable during the update. Value can be an absolute number (ex: 5 ) or a percentage of desired pods (ex: 10 %). Absolute number is calculated from percentage by rounding down. This can not be 0 if MaxSurge is 0 . Defaults to 25 %. Example: when this is set to 30 %, the old ReplicaSet can be scaled down to 70 % of desired pods immediately when the rolling update starts. Once new pods are ready, old ReplicaSet can be scaled down further, followed by scaling up the new ReplicaSet, ensuring that the total number of pods available at all times during the update is at least 70 % of desired pods. 假设有5个副本,最多一个不可用,就表示最少有4个可用 [root@master1 ~ ] deployment.apps/myapp-v1 REVISION CHANGE-CAUSE 1 <none> 2 <none> 滚动更新后会创建一个新的replicaset kubectl get rs NAME DESIRED CURRENT READY AGE myapp-v1-75fb478d6c 3 3 3 2m7s myapp-v1-67fd9fc9c8 0 0 0 25m kubectl rollout undo deployment/myapp-v1 --to-revision=1
# 自动滚动更新策略maxUnavailable: [0%, 100%] 向下取整,比如 10 个副本,5% 的话 0.5 个,但计算按照 0 个; 0.5 个,但计算按照 1 个;
建议配置,不少于目标副本数,但是 maxsurge 变大可以实现更快的更新
maxUnavailable == 0
maxSurge == 1
即 “一上一下,先上后下” 最平滑原则:
maxUnavailable:和期望的副本数比,不可用副本数最大比例(或最大值),这个值越小,越能保证服务稳定,更新越平滑;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 deploy.spec.strategy.type == Recreate == RollingUpdate(default) kubectl patch deployment myapp-v1 -p '{"spec":{"strategy":{"rollingUpdate": {"maxSurge":1,"maxUnavailable":1}}}}' apiVersion: apps/v1 kind: Deployment metadata: name: myapp-v1 spec: strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 1 replicas: 3 template: metadata: labels: app: myapp version: v1 apiVersion: apps/v1 kind: Deployment metadata: name: myapp-v1 spec: strategy: type: Recreate replicas: 3 template: metadata: labels: app: myapp version: v1 spec: containers: - name: myapp image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 myapp-v1-59c458cb84-zslxg 1 /1 Terminating 0 5m3s myapp-v1-59c458cb84-nvjhq 1 /1 Terminating 0 5m24s myapp-v1-59c458cb84-gglnb 1 /1 Terminating 0 5m24s myapp-v1-59c458cb84-gglnb 1 /1 Terminating 0 5m24s myapp-v1-59c458cb84-nvjhq 1 /1 Terminating 0 5m24s myapp-v1-59c458cb84-zslxg 1 /1 Terminating 0 5m3s myapp-v1-59c458cb84-gglnb 0 /1 Terminating 0 5m25s myapp-v1-59c458cb84-gglnb 0 /1 Terminating 0 5m25s myapp-v1-59c458cb84-gglnb 0 /1 Terminating 0 5m25s myapp-v1-59c458cb84-zslxg 0 /1 Terminating 0 5m4s myapp-v1-59c458cb84-zslxg 0 /1 Terminating 0 5m4s myapp-v1-59c458cb84-zslxg 0 /1 Terminating 0 5m4s myapp-v1-59c458cb84-nvjhq 0 /1 Terminating 0 5m25s myapp-v1-59c458cb84-nvjhq 0 /1 Terminating 0 5m25s myapp-v1-59c458cb84-nvjhq 0 /1 Terminating 0 5m25s
# 蓝绿部署蓝绿部署中,一共有两套系统:一套是正在提供服务系统,标记为 “绿色”;另一套是准备发布的系统,标记为 “蓝色”。两套系统都是功能完善的、正在运行的系统,只是系统版本和对外服务情况不同。
开发新版本,要用新版本替换线上的旧版本,在线上的系统之外,搭建了一个使用新版本代码的全新系统。 这时候,一共有两套系统在运行,正在对外提供服务的老系统是绿色系统,新部署的系统是蓝色系统。
用来做发布前测试,测试过程中发现任何问题,可以直接在蓝色系统上修改,不干扰用户正在使用的系统。(注意,两套系统没有耦合的时候才能百分百保证不干扰)
切换后的一段时间内,依旧是蓝绿两套系统并存,但是用户访问的已经是蓝色系统。这段时间内观察蓝色系统(新系统)工作状态,如果出现问题,直接切换回绿色系统。
当确信对外提供服务的蓝色系统工作正常,不对外提供服务的绿色系统已经不再需要的时候,蓝色系统正式成为对外提供服务系统,成为新的绿色系统。 原先的绿色系统可以销毁,将资源释放出来,用于部署下一个蓝色系统。
优点:
1、更新过程无需停机,风险较少
2、回滚方便,只需要更改路由或者切换 DNS 服务器,效率较高
缺点:
1、成本较高,需要部署两套环境。如果新版本中基础服务出现问题,会瞬间影响全网用户;如果新版本有问题也会影响全网用户。
2、需要部署两套机器,费用开销大
3、在非隔离的机器(Docker、VM)上操作时,可能会导致蓝绿环境被摧毁风险
4、负载均衡器 / 反向代理 / 路由 / DNS 处理不当,将导致流量没有切换过来情况出现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 apiVersion: apps/v1 kind: Deployment metadata: name: myapp-v2 namespace: blue-green spec: replicas: 3 selector: matchLabels: app: myapp version: v1 template: metadata: labels: app: myapp version: v1 spec: containers: - name: myapp image: janakiramm/myapp:v1 imagePullPolicy: IfNotPresent ports: - containerPort: 80
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 apiVersion: apps/v1 kind: Deployment metadata: name: myapp-v1 namespace: blue-green spec: replicas: 3 selector: matchLabels: app: myapp version: v2 template: metadata: labels: app: myapp version: v2 spec: containers: - name: myapp image: janakiramm/myapp:v2 imagePullPolicy: IfNotPresent ports: - containerPort: 80
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiVersion: v1 kind: Service metadata: name: myapp-lan-lv namespace: blue-green labels: app: myapp spec: type: NodePort ports: - port: 80 nodePort: 30062 name: http selector: app: myapp version: v2 selector: app: myapp version: v2 selector: app: myapp version: v1
# 金丝雀发布金丝雀发布(又称灰度发布、灰度更新):金丝雀发布一般先发 1 台,或者一个小比例,例如 2% 的服务器,主要做流量验证用,也称为金丝雀 (Canary) 测试 (国内常称灰度测试)。
简单的金丝雀测试一般通过手工测试验证,复杂的金丝雀测试需要比较完善的监控基础设施配合,通过监控指标反馈,观察金丝雀的健康状况,作为后续发布或回退的依据。 如果金丝测试通过,则把剩余的 V1 版本全部升级为 V2 版本。如果金丝雀测试失败,则直接回退金丝雀,发布失败。
优点:灵活,策略自定义,可以按照流量或具体的内容进行灰度 (比如不同账号,不同参数),出现问题不会影响全网用户
缺点:没有覆盖到所有的用户导致出现问题不好排查
1 2 3 4 5 6 7 8 9 kubectl apply -f .yaml kubectl set image deployment myapp-v1 myapp=nginx -n blue-green && kubectl rollout pause deployment myapp-v1 -n blue-green 上面的解释说明把myapp这个容器的镜像更新到nginx版本 更新镜像之后,创建一个新的pod就立即暂停,这就是我们说的金丝雀发布;如果暂停几个小时之后没有问题,那么取消暂停,就会依次执行后面步骤,把所有pod都升级。 kubectl rollout resume deployment myapp-v1 -n blue-green
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 kubectl run mynginx --image=nginx kubectl create deployment mytomcat --image=tomcat:8.5.68 [root@master ~] NAME READY UP-TO-DATE AVAILABLE AGE mytomcat 1/1 1 1 4m6s [root@master ~] kubectl create deployment my-dep --image=nginx --replicas=3
使用 web 页面
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 apiVersion: apps/v1 kind: Deployment metadata: labels: app: my-dep name: my-dep spec: replicas: 3 selector: matchLabels: app: my-dep template: metadata: labels: app: my-dep spec: containers: - image: nginx name: nginx
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 kubectl scale --replicas=5 deployment/my-dep [root@master ~] 自愈: 尝试重启pod 故障转移: 将pod从故障的机器转移到好的机器 [root@master ~] [root@master ~] kubectl get deploy my-dep -oyaml kubectl rollout history deployment/my-dep kubectl rollout history deployment/my-dep --revision=2 kubectl rollout undo deployment/my-dep kubectl rollout undo deployment/my-dep --to-revision=2
除了 Deployment,k8s 还有 StatefulSet 、 DaemonSet 、 Job 等 类型资源。我们都称为 工作负载 。
有状态应用使用 StatefulSet 部署,无状态应用使用 Deployment 部署
其他工作负载
Deployment: 无状态应用部署,比如微服务,提供多副本等功能
StatefulSet: 有状态应用部署,比如 redis,提供稳定的存储、网络等功能
DaemonSet: 守护型应用部署,比如日志收集组件,在每个机器都运行一份
Job/CronJob: 定时任务部署,比如垃圾清理组件,可以在指定时间运行
# service在 kubernetes 中,Pod 是有生命周期的,如果 Pod 重启它的 IP 很有可能会发生变化。如果我们的服务都是将 Pod 的 IP 地址写死,Pod 挂掉或者重启,和刚才重启的 pod 相关联的其他服务将会找不到它所关联的 Pod,为了解决这个问题,在 kubernetes 中定义了 service 资源对象,Service 定义了一个服务访问的入口,客户端通过这个入口即可访问服务背后的应用集群实例,service 是一组 Pod 的逻辑集合,这一组 Pod 能够被 Service 访问到,通常是通过 Label Selector 实现的。
创建 service 的时候会创建同名的 endpoint,会把 pod 的 ip 和端口加入到 endpoint 中
service 创建的时候有 service 的 ip,关联到 pod 的 ip 和端口,都保存在防火墙规则中:iptables 或者 ipvs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@master1 ~] IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 127.0.0.1:30821 rr -> 10.244.166.155:80 Masq 1 0 0 -> 10.244.166.156:80 Masq 1 0 0 TCP 127.0.0.1:31180 rr -> 10.244.166.172:8080 Masq 1 0 0 TCP 127.0.0.1:31181 rr -> 10.244.166.172:8081 Masq 1 0 0 TCP 127.0.0.1:31441 rr -> 10.244.180.1:8443 Masq 1 0 0 TCP 172.17.0.1:30821 rr -> 10.244.166.155:80 Masq 1 0 0 -> 10.244.166.156:80 Masq 1 0 0 TCP 172.17.0.1:31180 rr -> 10.244.166.172:8080 Masq 1 0 0 TCP 172.17.0.1:31181 rr -> 10.244.166.172:8081 Masq 1 0 0 TCP 172.17.0.1:31441 rr -> 10.244.180.1:8443 Masq 1 0 0 TCP 192.168.13.177:30821 rr -> 10.244.166.155:80 Masq 1 0 0 -> 10.244.166.156:80 Masq 1 0 0
kube-proxy 这个组件将始终监视着 apiserver 中有关 service 资源的变动信息,需要跟 master 之上的 apiserver 交互,随时连接到 apiserver 上获取任何一个与 service 资源相关的资源变动状态,这种是通过 kubernetes 中固有的一种请求方法 watch(监视)来实现的,一旦有 service 资源的内容发生变动(如创建,删除),kube-proxy 都会将它转化成当前节点之上的能够实现 service 资源调度,把我们请求调度到后端特定的 pod 资源之上的规则,这个规则可能是 iptables,也可能是 ipvs,取决于 service 的实现方式。
k8s 在创建 Service 时,会根据标签选择器 selector (lable selector) 来查找 Pod,据此创建与 Service 同名的 endpoint 对象,当 Pod 地址发生变化时,endpoint 也会随之发生变化,service 接收前端 client 请求的时候,就会通过 endpoint,找到转发到哪个 Pod 进行访问的地址。(至于转发到哪个节点的 Pod,由负载均衡 kube-proxy 决定)
kubernetes 集群中有三类 IP 地址
1、Node Network(节点网络):物理节点或者虚拟节点的网络,如 ens33 接口上的网路地址
2、Pod network(pod 网络),创建的 Pod 具有的 IP 地址
3、Cluster Network(集群地址,也称为 service network),这个地址是虚拟的地址(virtual ip),没有配置在某个接口上,只是出现在 service 的规则当中。
三个网段不能冲突
–type=ClusterIP 集群内部访问
–type=NodePort 集群外也能访问
–type=ExternalName
–type=LoadBalancer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@ ~]# kubectl explain service.spec.ports KIND: Service VERSION: v1 RESOURCE: ports <[]Object> DESCRIPTION: The list of ports that are exposed by this service. More info: https://kubernetes.io/docs/concepts/services-networking/service/#virtual-ips-and-service-proxies ServicePort contains information on service's port. FIELDS: appProtocol <string> name <string> #定义端口的名字 nodePort <integer> #service在物理机映射的端口,默认在 30000-32767 之间 port <integer> -required- #service的端口,这个是k8s集群内部服务可访问的端口 protocol <string> targetPort <string> # targetPort是pod上的端口,从port和nodePort上来的流量,经过kube-proxy流入到后端pod的targetPort上,最后进入容器。
# cluster-ip1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 apiVersion: apps/v1 kind: Deployment metadata: name: my-nginx spec: selector: matchLabels: run: my-nginx replicas: 2 template: metadata: labels: run: my-nginx spec: containers: - name: my-nginx image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 startupProbe: periodSeconds: 5 initialDelaySeconds: 60 timeoutSeconds: 10 httpGet: scheme: HTTP port: 80 path: / livenessProbe: periodSeconds: 5 initialDelaySeconds: 60 timeoutSeconds: 10 httpGet: scheme: HTTP port: 80 path: / readinessProbe: periodSeconds: 5 initialDelaySeconds: 60 timeoutSeconds: 10 httpGet: scheme: HTTP port: 80 path: / --- apiVersion: v1 kind: Service metadata: name: my-nginx labels: run: my-nginx spec: type : ClusterIP ports: - port: 80 protocol: TCP targetPort: 80 selector: run: my-nginx
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 [root@master1 ~] Name: my-nginx Namespace: default Labels: run=my-nginx Annotations: <none> Selector: run=my-nginx Type: ClusterIP IP Families: <none> IP: 10.96.60.147 IPs: 10.96.60.147 Port: <unset > 30080/TCP TargetPort: 80/TCP Endpoints: 10.244.166.180:80,10.244.166.181:80 Session Affinity: None Events: <none> You have new mail in /var/spool/mail/root [root@master1 ~] Name: my-nginx Namespace: default Labels: run=my-nginx Annotations: endpoints.kubernetes.io/last-change-trigger-time: 2023-05-10T12:28:47Z Subsets: Addresses: 10.244.166.180,10.244.166.181 NotReadyAddresses: <none> Ports: Name Port Protocol ---- ---- -------- <unset > 80 TCP Events: <none> [root@master1 ~]
service 只要创建完成,我们就可以直接解析它的服务名,每一个服务创建完成后都会在集群 dns 中动态添加一个资源记录,添加完成后我们就可以解析了,资源记录格式是:
SVC_NAME.NS_NAME.DOMAIN.LTD.
就像我们上面创建的 my-nginx 这个服务,它的完整名称解析就是
这个域名只能 service 关联的 pod 内访问
使用就绪探测防止容器还没能提供服务就加入 endpoint 中,不能通过 service 访问
pod 的发现与负载均衡
将一组 Pods 公开为网络服务的抽象方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 [root@master ~] service/my-dep exposed [root@master ~] [root@master ~] [root@master ~] NAME READY STATUS RESTARTS AGE LABELS my-dep-5b7868d854-29j5l 1/1 Running 0 21h app=my-dep,pod-template-hash=5b7868d854 my-dep-5b7868d854-67vg6 1/1 Running 0 21h app=my-dep,pod-template-hash=5b7868d854 my-dep-5b7868d854-9x4j8 1/1 Running 0 21h app=my-dep,pod-template-hash=5b7868d854 my-dep-5b7868d854-jtpbw 1/1 Running 0 21h app=my-dep,pod-template-hash=5b7868d854 my-dep-5b7868d854-nb4kn 1/1 Running 0 21h app=my-dep,pod-template-hash=5b7868d854 在集群内使用IP:port 可以实现负载均衡访问 也可以使用svc域名直接访问,域名规则: 服务名.所在namespace.svc 只能在pod内使用域名访问 curl my-dep.default.svc:8000 root@my-dep-5b7868d854-nb4kn:/ 127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback fe00::0 ip6-localnet fe00::0 ip6-mcastprefix fe00::1 ip6-allnodes fe00::2 ip6-allrouters 192.168.166.142 my-dep-5b7868d854-nb4kn
1 2 3 4 5 6 7 8 9 10 11 12 13 apiVersion: v1 kind: Service metadata: labels: app: my-dep name: my-dep spec: selector: app: my-dep ports: - port: 8000 protocol: TCP targetPort: 80
# NodePort1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 apiVersion: apps/v1 kind: Deployment metadata: name: my-nginx-nodeport spec: selector: matchLabels: run: my-nginx-nodeport replicas: 2 template: metadata: labels: run: my-nginx-nodeport spec: containers: - name: my-nginx-nodeport-container image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: my-nginx-nodeport labels: run: my-nginx-nodeport spec: type: NodePort ports: - port: 80 protocol: TCP targetPort: 80 nodePort: 30380 selector: run: my-nginx-nodeport
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@master1 ~ ] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE my-nginx-nodeport NodePort 10.96 .152 .128 <none> 80 :30380/TCP 4s [root@master1 ~ ] tcp LISTEN 0 128 *:30380 *:* users:(("kube-proxy",pid=14706,fd=10)) 会在每一个节点上监听这个端口 [root@master1 ~ ] NAME ENDPOINTS AGE my-nginx-nodeport 10.244 .166 .184 :80,10.244.166.185:80 5m2s curl节点中任何一个节点都能请求到 客户端请求http://192.168.13.177:30380->docker0虚拟网卡:172.17.0.1:30380-> 10.244 .166 .184 :80,10.244.166.185:80
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@master ~] [root@master ~] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d17h my-dep NodePort 10.96.206.111 <none> 8000:32666/TCP 6m59s 32666只是用于外部访问的端口,实现公网访问
# externalName跨名称空间访问
需求:default 名称空间下的 client 服务想要访问 nginx-ns 名称空间下的 nginx-svc 服务
service 正常情况只能代理自己 ns 下面的 pod
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 apiVersion: apps/v1 kind: Deployment metadata: name: nginx namespace: nginx-ns spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent --- apiVersion: v1 kind: Service metadata: name: nginx-svc namespace: nginx-ns spec: selector: app: nginx ports: - name: http protocol: TCP port: 80 targetPort: 80
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 apiVersion: apps/v1 kind: Deployment metadata: name: client spec: replicas: 1 selector: matchLabels: app: busybox template: metadata: labels: app: busybox spec: containers: - name: busybox image: busybox imagePullPolicy: IfNotPresent command: ["/bin/sh" ,"-c" ,"sleep 36000" ] --- apiVersion: v1 kind: Service metadata: name: client-svc spec: type: ExternalName externalName: nginx-svc.nginx-ns.svc.cluster.local ports: - name: http port: 80 targetPort: 80 wget -q -O client-svc [root@master1 ~ ] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE client-svc ExternalName <none> nginx-svc.nginx-ns.svc.cluster.local 80 /TCP 15s kubectl exec -it client-76b6556d97-xk7mg -- /bin/sh / wget -q -O - nginx-svc.nginx-ns.svc.cluster.local 上面两个请求的结果一样 此时client-svc相当于 nginx-svc.nginx-ns.svc.cluster.local的软链,可以不使用名称空间直接访问软链的资源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 https://zhuanlan.zhihu.com/p/623778183 apiVersion: v1 kind: Service metadata: name: mysql spec: type : ClusterIP ports: - port: 3306 [root@master1 ~] Name: mysql Namespace: default Labels: <none> Annotations: <none> Selector: <none> Type: ClusterIP IP Families: <none> IP: 10.96.96.21 IPs: 10.96.96.21 Port: <unset > 3306/TCP TargetPort: 3306/TCP Endpoints: <none>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiVersion: v1 kind: Endpoints metadata: name: mysql subsets: - addresses: - ip: 192.168 .13 .199 ports: - port: 3306 [root@master1 ~ ] Name: mysql Namespace: default Labels: <none> Annotations: <none> Selector: <none> Type: ClusterIP IP Families: <none> IP: 10.96 .159 .210 IPs: 10.96 .159 .210 Port: <unset> 3306 /TCP TargetPort: 3306 /TCP Endpoints: 192.168 .13 .199 :3306 Session Affinity: None Events: <none>
# corednsCoreDNS 其实就是一个 DNS 服务,而 DNS 作为一种常见的服务发现手段,所以很多开源项目以及工程师都会使用 CoreDNS 为集群提供服务发现的功能,Kubernetes 就在集群中使用 CoreDNS 解决服务发现的问题。
service fqdn == service_name.namespace.svc.cluster.local
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 apiVersion: v1 kind: Pod metadata: name: dig namespace: default spec: containers: - name: dig image: dig imagePullPolicy: IfNotPresent command: - sleep - "3600" restartPolicy: Always [root@ ] ~]# kubectl exec -it dig -- nslookup kubernetes Server: 10.96 .0 .10 Address: 10.96 .0 .10 Name: kubernetes.default.svc.cluster.local Address: 10.96 .0 .1 在k8s中创建service之后,service默认的FQDN是<servicename>.<namespace>.svc.cluster.local,那么k8s集群内部的服务就可以通过FQDN访问 [root@prometheus-master service ] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.96 .0 .10 <none> 53 /UDP,53/TCP,9153/TCP 16d [root@prometheus-master service ] Name: kube-dns Namespace: kube-system IP Families: IPv4 IP: 10.96 .0 .10 IPs: 10.96 .0 .10 Port: dns 53 /UDP TargetPort: 53 /UDP Endpoints: 10.244 .229 .92 :53,10.244.229.93:53 Port: dns-tcp 53 /TCP TargetPort: 53 /TCP Endpoints: 10.244 .229 .92 :53,10.244.229.93:53 Port: metrics 9153 /TCP TargetPort: 9153 /TCP Endpoints: 10.244 .229 .92 :9153,10.244.229.93:9153 coredns-6d8c4cb4d-jmstd 1 /1 Running 5 (30h ago) 16d 10.244 .229 .93 prometheus-master <none> <none> coredns-6d8c4cb4d-pg4sb 1 /1 Running 5 (30h ago) 16d 10.244 .229 .92 prometheus-master <none> <none> coredns 也可以解析外部域名 [root@xianchaomaster1 ~ ]
# ingressService 可以通过标签选择器找到它所关联的 Pod。但是属于四层代理,只能基于 IP 和端口代理。
Service 的 type 类型有很多,如 NodePort、clusterIp、loadbalancer、externalname,如果 Service 想要被 k8s 集群外部访问,需要用 NodePort 类型,但是 NodePort 类型的 svc 有如下几个问题:
四层负载和七层负载的区别:
2)七层的负载均衡就是基于虚拟的 URL 或主机 IP 的负载均衡:在四层负载均衡的基础上(没有四层是绝对不可能有七层的),再考虑应用层的特征,比如同一个 Web 服务器的负载均衡,除了根据 VIP 加 80 端口辨别是否需要处理的流量,还可根据七层的 URL、浏览器类别、语言来决定是否要进行负载均衡。举个例子,如果你的 Web 服务器分成两组,一组是中文语言的,一组是英文语言的,那么七层负载均衡就可以当用户来访问你的域名时,自动辨别用户语言,然后选择对应的语言服务器组进行负载均衡处理。
3)四层负载均衡工作在传输层,七层负载均衡工作在应用层
ingress 是 k8s 中的资源,主要是管理 ingress-controller 这个代理的配置文件
Ingress Controller 是一个七层负载均衡调度器,客户端的请求先到达这个七层负载均衡调度器,由七层负载均衡器在反向代理到后端 pod,常见的七层负载均衡器有 nginx、traefik,以我们熟悉的 nginx 为例,假如请求到达 nginx,会通过 upstream 反向代理到后端 pod 应用,但是后端 pod 的 ip 地址是一直在变化的,因此在后端 pod 前需要加一个 service,这个 service 只是起到分组的作用,那么我们 upstream 只需要填写 service 地址即可。
ingress-controller 封装的 nginx,ingress 维护配置,ingress 创建好之后,会自动的把配置文件传到 ingress-controller 这个 pod 里,会自动进行 reload,然后配置就生效了。
Ingress Controller
使用 Ingress Controller 代理 k8s 内部 pod 的流程
(1)部署 Ingress controller,我们 ingress controller 使用的是 nginx
# ingress 高可用Ingress Controller 是集群流量的接入层,对它做高可用非常重要,可以基于 keepalive 实现 nginx-ingress-controller 高可用,具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 [root@node1 ~ ] [root@node1 ~ ] [root@master1 ingress ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ingress-nginx-admission-create-g4qzz 0 /1 Completed 0 8m2s 10.244 .166 .180 node1 <none> <none> ingress-nginx-admission-patch-r62tp 0 /1 Completed 1 8m2s 10.244 .166 .181 node1 <none> <none> ingress-nginx-controller-6c8ffbbfcf-28tmg 1 /1 Running 0 82s 192.168 .13 .199 node1 <none> <none> kubectl delete -A ValidatingWebhookConfiguration ingress-nginx-admission user nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /run/nginx.pid; events { worker_connections 1024 ; } stream { log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent' ; access_log /var/log/nginx/k8s-access.log main; upstream k8s-ingress-controller { server 192.168 .40 .181 :80 weight=5 max_fails=3 fail_timeout=30s; server 192.168 .40 .182 :80 weight=5 max_fails=3 fail_timeout=30s; } server { listen 30080 ; proxy_pass k8s-ingress-controller; } } http { log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"' ; access_log /var/log/nginx/access.log main; sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65 ; types_hash_max_size 2048 ; include /etc/nginx/mime.types; default_type application/octet-stream; } 3 、keepalive配置 主keepalived [root@node1 ~ ] global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0 .0 .1 smtp_connect_timeout 30 router_id NGINX_MASTER } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168 .40 .199 /24 } track_script { check_nginx } } [root@node1 ~ ] counter=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$" ) if [ $counter -eq 0 ]; then service nginx start sleep 2 counter=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$" ) if [ $counter -eq 0 ]; then service keepalived stop fi fi [root@node1 ~ ] 备keepalive [root@node2 ~ ] global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0 .0 .1 smtp_connect_timeout 30 router_id NGINX_BACKUP } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 51 priority 90 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168 .1 .199 /24 } track_script { check_nginx } } [root@node2 ~ ] counter=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$" ) if [ $counter -eq 0 ]; then service nginx start sleep 2 counter=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$" ) if [ $counter -eq 0 ]; then service keepalived stop fi fi [root@node2 ~ ] 4 、启动服务: [root@node1 ~ ] [root@node1 ~ ] [root@node1 ~ ] [root@node1 ~ ] 4 、启动服务: [root@node2 ~ ] [root@node2 ~ ] [root@node2 ~ ] [root@node2 ~ ] 5 、测试vip是否绑定成功 [root@node1 ~ ] 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00 :00:00:00:00:00 brd 00 :00:00:00:00:00 inet 127.0 .0 .1 /8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00 :0c:29:79:9e:36 brd ff:ff:ff:ff:ff:ff inet 192.168 .40 .182 /24 brd 192.168 .40 .255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet 192.168 .40 .199 /24 scope global secondary ens33 valid_lft forever preferred_lft forever inet6 fe80::b6ef:8646:1cfc:3e0c/64 scope link noprefixroute valid_lft forever preferred_lft forever systemctl daemon-reload systemctl enable nginx keepalived systemctl start nginx systemctl start keepalived
(85 条消息) REK 安装 K8S 后,Ingress-nginx 一直状态为 ContainerCreating_ingress-nginx-controller 一直是 containercreating_Steady Ben 的博客 - CSDN 博客
# http 代理 pod1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 apiVersion: v1 kind: Service metadata: name: tomcat namespace: default spec: selector: app: tomcat release: canary ports: - name: http targetPort: 8080 port: 8080 - name: ajp targetPort: 8009 port: 8009 --- apiVersion: apps/v1 kind: Deployment metadata: name: tomcat-deploy namespace: default spec: replicas: 2 selector: matchLabels: app: tomcat release: canary template: metadata: labels: app: tomcat release: canary spec: containers: - name: tomcat image: tomcat:9.0 imagePullPolicy: IfNotPresent ports: - name: http containerPort: 8080 name: ajp containerPort: 8009 --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ingress-myapp namespace: default annotations: spec: ingressClassName: nginx rules: - host: tomcat.shabi.com http: paths: - backend: service: name: tomcat port: number: 8080 path: / pathType: Prefix [root@master1 ingress ] NAME CLASS HOSTS ADDRESS PORTS AGE ingress-myapp nginx tomcat.shabi.com 192.168 .13 .199 80 3m29s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 openssl genrsa -out tls.key 2048 openssl req -new -x509 -key tls.key -out tls.crt -subj /C=CN/ST=Beijing/L=Beijing/O=DevOps/CN=hhh.com kubectl create secret tls tomcat-ingress-secret --cert=tls.crt --key=tls.key [root@master1 ] [root@master1 ~ ] [root@master1 ~ ] (2)生成secret,在master1节点操作 [root@master1 ~ ] apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ingress-tomcat-tls namespace: default spec: ingressClassName: nginx tls: - hosts: - tomcat.shabi.com secretName: tomcat-ingress-secret rules: - host: tomcat.shabi.com http: paths: - path: / pathType: Prefix backend: service: name: tomcat port: number: 8080
# ingress 实现业务灰度发布假设线上运行了一套对外提供 7 层服务的 Service A 服务,后来开发了个新版本 Service A’ 想要上线,但又不想直接替换掉原来的 Service A,希望先灰度一小部分用户,等运行一段时间足够稳定了再逐渐全量上线新版本,最后平滑下线旧版本。这个时候就可以利用 Nginx Ingress 基于 Header 或 Cookie 进行流量切分的策略来发布,业务使用 Header 或 Cookie 来标识不同类型的用户,我们通过配置 Ingress 来实现让带有指定 Header 或 Cookie 的请求被转发到新版本,其它的仍然转发到旧版本,从而实现将新版本灰度给部分用户:
假设线上运行了一套对外提供 7 层服务的 Service B 服务,后来修复了一些问题,需要灰度上线一个新版本 Service B’,但又不想直接替换掉原来的 Service B,而是让先切 10% 的流量到新版本,等观察一段时间稳定后再逐渐加大新版本的流量比例直至完全替换旧版本,最后再滑下线旧版本,从而实现切一定比例的流量给新版本:
Ingress-Nginx 是一个 K8S ingress ingress-Nginx 是一个 K8S ingress 工具,支持配置 Ingress Annotations 来实现不同场景下的灰度发布和测试。 Nginx Annotations 支持以下几种 Canary 规则:
假设我们现在部署了两个版本的服务,老版本和 canary 版本工具,支持配置 Ingress Annotations 来实现不同场景下的灰度发布和测试。 Nginx Annotations 支持以下几种 Canary 规则:
假设我们现在部署了两个版本的服务,老版本和 canary 版本
nginx.ingress.kubernetes.io/canary-by-header:基于 Request Header 的流量切分,适用于灰度发布以及 A/B 测试。当 Request Header 设置为 always 时,请求将会被一直发送到 Canary 版本;当 Request Header 设置为 never 时,请求不会被发送到 Canary 入口。
nginx.ingress.kubernetes.io/canary-by-header-value:要匹配的 Request Header 的值,用于通知 Ingress 将请求路由到 Canary Ingress 中指定的服务。当 Request Header 设置为此值时,它将被路由到 Canary 入口。
nginx.ingress.kubernetes.io/canary-weight:基于服务权重的流量切分,适用于蓝绿部署,权重范围 0 - 100 按百分比将请求路由到 Canary Ingress 中指定的服务。权重为 0 意味着该金丝雀规则不会向 Canary 入口的服务发送任何请求。权重为 60 意味着 60% 流量转到 canary。权重为 100 意味着所有请求都将被发送到 Canary 入口。
nginx.ingress.kubernetes.io/canary-by-cookie:基于 Cookie 的流量切分,适用于灰度发布与 A/B 测试。用于通知 Ingress 将请求路由到 Canary Ingress 中指定的服务的 cookie。当 cookie 值设置为 always 时,它将被路由到 Canary 入口;当 cookie 值设置为 never 时,请求不会被发送到 Canary 入口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 apiVersion: apps/v1 kind: Deployment metadata: name: nginx-v1 spec: replicas: 1 selector: matchLabels: app: nginx version: v1 template: metadata: labels: app: nginx version: v1 spec: containers: - name: nginx image: "openresty/openresty:centos" imagePullPolicy: IfNotPresent ports: - name: http protocol: TCP containerPort: 80 volumeMounts: - mountPath: /usr/local/openresty/nginx/conf/nginx.conf name: config subPath: nginx.conf volumes: - name: config configMap: name: nginx-v1 --- apiVersion: v1 kind: ConfigMap metadata: labels: app: nginx version: v1 name: nginx-v1 data: nginx.conf: |- worker_processes 1; events { accept_mutex on; multi_accept on; use epoll; worker_connections 1024; } http { ignore_invalid_headers off; server { listen 80; location / { access_by_lua ' local header_str = ngx.say("nginx-v1") '; } } } --- apiVersion: v1 kind: Service metadata: name: nginx-v1 spec: type: ClusterIP ports: - port: 80 protocol: TCP name: http selector: app: nginx version: v1 apiVersion: apps/v1 kind: Deployment metadata: name: nginx-v2 spec: replicas: 1 selector: matchLabels: app: nginx version: v2 template: metadata: labels: app: nginx version: v2 spec: containers: - name: nginx image: "openresty/openresty:centos" imagePullPolicy: IfNotPresent ports: - name: http protocol: TCP containerPort: 80 volumeMounts: - mountPath: /usr/local/openresty/nginx/conf/nginx.conf name: config subPath: nginx.conf volumes: - name: config configMap: name: nginx-v2 --- apiVersion: v1 kind: ConfigMap metadata: labels: app: nginx version: v2 name: nginx-v2 data: nginx.conf: |- worker_processes 1; events { accept_mutex on; multi_accept on; use epoll; worker_connections 1024; } http { ignore_invalid_headers off; server { listen 80; location / { access_by_lua ' local header_str = ngx.say("nginx-v2") '; } } } --- apiVersion: v1 kind: Service metadata: name: nginx-v2 spec: type: ClusterIP ports: - port: 80 protocol: TCP name: http selector: app: nginx version: v2 apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: nginx annotations: kubernetes.io/ingress.class: nginx spec: rules: - host: canary.example.com http: paths: - path: / pathType: Prefix backend: service: name: nginx-v1 port: number: 80 curl -H "Host: canary.example.com" http://192.168.13.199
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiVersion: networking.k8s.io/v1 kind: Ingress metadata: annotations: kubernetes.io/ingress.class: nginx nginx.ingress.kubernetes.io/canary: "true" nginx.ingress.kubernetes.io/canary-by-header: "Region" nginx.ingress.kubernetes.io/canary-by-header-pattern: "cd|sz" name: nginx-canary spec: rules: - host: canary.example.com http: paths: - path: / pathType: Prefix backend: service: name: nginx-v2 port: number: 80 curl -H "Host: canary.example.com" -H "Region: cd" http://192.168.13.199 //v2 curl -H "Host: canary.example.com" -H "Region: sz" http://192.168.13.199 //v2 curl -H "Host: canary.example.com" -H "Region: cc" http://192.168.13.199 //v1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 与前面 Header 类似,不过使用 Cookie 就无法自定义 value 了,这里以模拟灰度成都地域用户为例,仅将带有名为 user_from_cd 的 cookie 的请求转发给当前 Canary Ingress 。先删除前面基于 Header 的流量切分的 Canary Ingress,然后创建下面新的 Canary Ingress: apiVersion: networking.k8s.io/v1 kind: Ingress metadata: annotations: kubernetes.io/ingress.class: nginx nginx.ingress.kubernetes.io/canary: "true" nginx.ingress.kubernetes.io/canary-by-cookie: "user_from_cd" name: nginx-canary spec: rules: - host: canary.example.com http: paths: - path: / pathType: Prefix backend: service: name: nginx-v2 port: number: 80 curl -s -H "Host: canary.example.com" --cookie "user_from_cd=always" http://192.168.13.199
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 基于服务权重的 Canary Ingress 直接定义需要导入的流量比例,这里以导入 10 % 流量到 v2 版本为例 (如果有,先删除之前的 Canary Ingress): apiVersion: networking.k8s.io/v1 kind: Ingress metadata: annotations: kubernetes.io/ingress.class: nginx nginx.ingress.kubernetes.io/canary: "true" nginx.ingress.kubernetes.io/canary-weight: "10" name: nginx-canary spec: rules: - host: canary.example.com http: paths: - path: / pathType: Prefix backend: service: name: nginx-v2 port: number: 80 for i in {1 ..10 }; do curl -H "Host: canary.example.com" http://192.168.13.199; done;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 apiVersion: v1 kind: Namespace metadata: name: ingress-nginx labels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx --- apiVersion: v1 kind: ServiceAccount metadata: labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: controller name: ingress-nginx namespace: ingress-nginx automountServiceAccountToken: true --- apiVersion: v1 kind: ConfigMap metadata: labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: controller name: ingress-nginx-controller namespace: ingress-nginx data: --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm name: ingress-nginx rules: - apiGroups: - '' resources: - configmaps - endpoints - nodes - pods - secrets verbs: - list - watch - apiGroups: - '' resources: - nodes verbs: - get - apiGroups: - '' resources: - services verbs: - get - list - watch - apiGroups: - extensions - networking.k8s.io resources: - ingresses verbs: - get - list - watch - apiGroups: - '' resources: - events verbs: - create - patch - apiGroups: - extensions - networking.k8s.io resources: - ingresses/status verbs: - update - apiGroups: - networking.k8s.io resources: - ingressclasses verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm name: ingress-nginx roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: ingress-nginx subjects: - kind: ServiceAccount name: ingress-nginx namespace: ingress-nginx --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: controller name: ingress-nginx namespace: ingress-nginx rules: - apiGroups: - '' resources: - namespaces verbs: - get - apiGroups: - '' resources: - configmaps - pods - secrets - endpoints verbs: - get - list - watch - apiGroups: - '' resources: - services verbs: - get - list - watch - apiGroups: - extensions - networking.k8s.io resources: - ingresses verbs: - get - list - watch - apiGroups: - extensions - networking.k8s.io resources: - ingresses/status verbs: - update - apiGroups: - networking.k8s.io resources: - ingressclasses verbs: - get - list - watch - apiGroups: - '' resources: - configmaps resourceNames: - ingress-controller-leader-nginx verbs: - get - update - apiGroups: - '' resources: - configmaps verbs: - create - apiGroups: - '' resources: - events verbs: - create - patch --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: controller name: ingress-nginx namespace: ingress-nginx roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: ingress-nginx subjects: - kind: ServiceAccount name: ingress-nginx namespace: ingress-nginx --- apiVersion: v1 kind: Service metadata: labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: controller name: ingress-nginx-controller-admission namespace: ingress-nginx spec: type: ClusterIP ports: - name: https-webhook port: 443 targetPort: webhook selector: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/component: controller --- apiVersion: v1 kind: Service metadata: annotations: labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: controller name: ingress-nginx-controller namespace: ingress-nginx spec: type: NodePort ports: - name: http port: 80 protocol: TCP targetPort: http - name: https port: 443 protocol: TCP targetPort: https selector: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/component: controller --- apiVersion: apps/v1 kind: Deployment metadata: labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: controller name: ingress-nginx-controller namespace: ingress-nginx spec: selector: matchLabels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/component: controller revisionHistoryLimit: 10 minReadySeconds: 0 template: metadata: labels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/component: controller spec: dnsPolicy: ClusterFirst containers: - name: controller image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/ingress-nginx-controller:v0.46.0 imagePullPolicy: IfNotPresent lifecycle: preStop: exec: command: - /wait-shutdown args: - /nginx-ingress-controller - --election-id=ingress-controller-leader - --ingress-class=nginx - --configmap=$(POD_NAMESPACE)/ingress-nginx-controller - --validating-webhook=:8443 - --validating-webhook-certificate=/usr/local/certificates/cert - --validating-webhook-key=/usr/local/certificates/key securityContext: capabilities: drop: - ALL add: - NET_BIND_SERVICE runAsUser: 101 allowPrivilegeEscalation: true env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: LD_PRELOAD value: /usr/local/lib/libmimalloc.so livenessProbe: failureThreshold: 5 httpGet: path: /healthz port: 10254 scheme: HTTP initialDelaySeconds: 10 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 1 readinessProbe: failureThreshold: 3 httpGet: path: /healthz port: 10254 scheme: HTTP initialDelaySeconds: 10 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 1 ports: - name: http containerPort: 80 protocol: TCP - name: https containerPort: 443 protocol: TCP - name: webhook containerPort: 8443 protocol: TCP volumeMounts: - name: webhook-cert mountPath: /usr/local/certificates/ readOnly: true resources: requests: cpu: 100m memory: 90Mi nodeSelector: kubernetes.io/os: linux serviceAccountName: ingress-nginx terminationGracePeriodSeconds: 300 volumes: - name: webhook-cert secret: secretName: ingress-nginx-admission --- apiVersion: admissionregistration.k8s.io/v1 kind: ValidatingWebhookConfiguration metadata: labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: admission-webhook name: ingress-nginx-admission webhooks: - name: validate.nginx.ingress.kubernetes.io matchPolicy: Equivalent rules: - apiGroups: - networking.k8s.io apiVersions: - v1beta1 operations: - CREATE - UPDATE resources: - ingresses failurePolicy: Fail sideEffects: None admissionReviewVersions: - v1 - v1beta1 clientConfig: service: namespace: ingress-nginx name: ingress-nginx-controller-admission path: /networking/v1beta1/ingresses --- apiVersion: v1 kind: ServiceAccount metadata: name: ingress-nginx-admission annotations: helm.sh/hook: pre-install,pre-upgrade,post-install,post-upgrade helm.sh/hook-delete-policy: before-hook-creation,hook-succeeded labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: admission-webhook namespace: ingress-nginx --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: ingress-nginx-admission annotations: helm.sh/hook: pre-install,pre-upgrade,post-install,post-upgrade helm.sh/hook-delete-policy: before-hook-creation,hook-succeeded labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: admission-webhook rules: - apiGroups: - admissionregistration.k8s.io resources: - validatingwebhookconfigurations verbs: - get - update --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: ingress-nginx-admission annotations: helm.sh/hook: pre-install,pre-upgrade,post-install,post-upgrade helm.sh/hook-delete-policy: before-hook-creation,hook-succeeded labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: admission-webhook roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: ingress-nginx-admission subjects: - kind: ServiceAccount name: ingress-nginx-admission namespace: ingress-nginx --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: ingress-nginx-admission annotations: helm.sh/hook: pre-install,pre-upgrade,post-install,post-upgrade helm.sh/hook-delete-policy: before-hook-creation,hook-succeeded labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: admission-webhook namespace: ingress-nginx rules: - apiGroups: - '' resources: - secrets verbs: - get - create --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: ingress-nginx-admission annotations: helm.sh/hook: pre-install,pre-upgrade,post-install,post-upgrade helm.sh/hook-delete-policy: before-hook-creation,hook-succeeded labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: admission-webhook namespace: ingress-nginx roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: ingress-nginx-admission subjects: - kind: ServiceAccount name: ingress-nginx-admission namespace: ingress-nginx --- apiVersion: batch/v1 kind: Job metadata: name: ingress-nginx-admission-create annotations: helm.sh/hook: pre-install,pre-upgrade helm.sh/hook-delete-policy: before-hook-creation,hook-succeeded labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: admission-webhook namespace: ingress-nginx spec: template: metadata: name: ingress-nginx-admission-create labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: admission-webhook spec: containers: - name: create image: docker.io/jettech/kube-webhook-certgen:v1.5.1 imagePullPolicy: IfNotPresent args: - create - --host=ingress-nginx-controller-admission,ingress-nginx-controller-admission.$(POD_NAMESPACE).svc - --namespace=$(POD_NAMESPACE) - --secret-name=ingress-nginx-admission env: - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace restartPolicy: OnFailure serviceAccountName: ingress-nginx-admission securityContext: runAsNonRoot: true runAsUser: 2000 --- apiVersion: batch/v1 kind: Job metadata: name: ingress-nginx-admission-patch annotations: helm.sh/hook: post-install,post-upgrade helm.sh/hook-delete-policy: before-hook-creation,hook-succeeded labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: admission-webhook namespace: ingress-nginx spec: template: metadata: name: ingress-nginx-admission-patch labels: helm.sh/chart: ingress-nginx-3.33.0 app.kubernetes.io/name: ingress-nginx app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/version: 0.47 .0 app.kubernetes.io/managed-by: Helm app.kubernetes.io/component: admission-webhook spec: containers: - name: patch image: docker.io/jettech/kube-webhook-certgen:v1.5.1 imagePullPolicy: IfNotPresent args: - patch - --webhook-name=ingress-nginx-admission - --namespace=$(POD_NAMESPACE) - --patch-mutating=false - --secret-name=ingress-nginx-admission - --patch-failure-policy=Fail env: - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace restartPolicy: OnFailure serviceAccountName: ingress-nginx-admission securityContext: runAsNonRoot: true runAsUser: 2000
# 创建 ingress1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@master ~] [root@master ~] NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE calico-system calico-typha ClusterIP 10.96.222.97 <none> 5473/TCP 2d17h default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d17h default my-dep NodePort 10.96.206.111 <none> 8000:32666/TCP 22m ingress-nginx ingress-nginx-controller NodePort 10.96.18.49 <none> 80:31625/TCP,443:31507/TCP 112s ingress-nginx ingress-nginx-controller-admission ClusterIP 10.96.19.25 <none> 443/TCP 112s ingress 就是一个nginx https://139.198.179.44:31507/ http://139.198.179.44:31625
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 apiVersion: apps/v1 kind: Deployment metadata: name: hello-server spec: replicas: 2 selector: matchLabels: app: hello-server template: metadata: labels: app: hello-server spec: containers: - name: hello-server image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/hello-server ports: - containerPort: 9000 --- apiVersion: apps/v1 kind: Deployment metadata: labels: app: nginx-demo name: nginx-demo spec: replicas: 2 selector: matchLabels: app: nginx-demo template: metadata: labels: app: nginx-demo spec: containers: - image: nginx name: nginx --- apiVersion: v1 kind: Service metadata: labels: app: nginx-demo name: nginx-demo spec: selector: app: nginx-demo ports: - port: 8000 protocol: TCP targetPort: 80 --- apiVersion: v1 kind: Service metadata: labels: app: hello-server name: hello-server spec: selector: app: hello-server ports: - port: 8000 protocol: TCP targetPort: 9000
1 eyJhbGciOiJSUzI1NiIsImtpZCI6IkY5LU9Jc0pnblNNOVJhM1dlWVl6c09DTjNnbFNQa1hzcWhOSThHVENEdlUifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLXp3NmRzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJkOTRmMDZlNi1kNTkxLTRmMzktODMxNC0zNzI2MDVhM2RkN2MiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.TMTc8QDTIo3qhsGTYD05c8txOyq2op7xW9ZQB5ICVw5x4fg-L0iUnn1jGyo4REP6ci63zBR-xmirqHy1eQ5GgT1nwGZnv4oKqNElm8-wkAit5rEgVN7ATo5GN3VrRQgNyBsHwqFhe1SsrK47flCZcmBvWbgmU4ugFfrNZ8xHkSURKrLAPUPjsYUC6ugyrEMqfwhcxzMiZcSKxG20jjLgVK7Pd_T01NAObUb_lCjq7mrEV0KdHcYTtSYwVwV88mTu5vwb39k-10V0s6HOqiDx87lp7fPtctrcR3mRiT1PkEvsyhCb8qAuFDPuaJZtESFu2dCXP_fVmv5g7AhSO_qUHg
# 域名访问1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ingress-host-bar spec: ingressClassName: nginx rules: - host: "hello.atguigu.com" http: paths: - pathType: Prefix path: "/" backend: service: name: hello-server port: number: 8000 - host: "demo.atguigu.com" http: paths: - pathType: Prefix path: "/nginx" backend: service: name: nginx-demo port: number: 8000
# 路径重写1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 apiVersion: networking.k8s.io/v1 kind: Ingress metadata: annotations: nginx.ingress.kubernetes.io/rewrite-target: /$2 name: ingress-host-bar spec: ingressClassName: nginx rules: - host: "hello.atguigu.com" http: paths: - pathType: Prefix path: "/" backend: service: name: hello-server port: number: 8000 - host: "demo.atguigu.com" http: paths: - pathType: Prefix path: "/nginx(/|$)(.*)" backend: service: name: nginx-demo port: number: 8000
# 流量限制1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ingress-limit-rate annotations: nginx.ingress.kubernetes.io/limit-rps: "1" spec: ingressClassName: nginx rules: - host: "haha.atguigu.com" http: paths: - pathType: Exact path: "/" backend: service: name: nginx-demo port: number: 8000
# 存储抽象在 k8s 中部署的应用都是以 pod 容器的形式运行的,假如我们部署 MySQL、Redis 等数据库,需要对这些数据库产生的数据做备份。因为 Pod 是有生命周期的,如果 pod 不挂载数据卷,那 pod 被删除或重启后这些数据会随之消失,如果想要长久的保留这些数据就要用到 pod 数据持久化存储。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [root@master1 ~] awsElasticBlockStore <Object> azureDisk <Object> azureFile <Object> cephfs <Object> cinder <Object> configMap <Object> csi <Object> downwardAPI <Object> emptyDir <Object> ephemeral <Object> fc <Object> flexVolume <Object> flocker <Object> gcePersistentDisk <Object> gitRepo <Object> glusterfs <Object> hostPath <Object> iscsi <Object> name <string> -required- nfs <Object> persistentVolumeClaim <Object> photonPersistentDisk <Object> portworxVolume <Object> projected <Object> quobyte <Object> rbd <Object> scaleIO <Object> secret <Object> storageos <Object> vsphereVolume <Object>
常用的如下:
我们想要使用存储卷,需要经历如下步骤
1、定义 pod 的 volume,这个 volume 指明它要关联到哪个存储上的
2、在容器中要使用 volumemounts 挂载对应的存储
# emptydiremptyDir 类型的 Volume 是在 Pod 分配到 Node 上时被创建,Kubernetes 会在 Node 上自动分配一个目录,因此无需指定宿主机 Node 上对应的目录文件。 这个目录的初始内容为空,当 Pod 从 Node 上移除时,emptyDir 中的数据会被永久删除。emptyDir Volume 主要用于某些应用程序无需永久保存的临时目录,多个容器的共享目录等。
emptyDir 的一些用途:
缓存空间,例如基于磁盘的归并排序。
为耗时较长的计算任务提供检查点,以便任务能方便地从崩溃前状态恢复执行。
在 Web 服务器容器服务数据时,保存内容管理器容器获取的文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 apiVersion: v1 kind: Pod metadata: name: pod-emptydir spec: containers: - name: container-emptydir image: nginx imagePullPolicy: IfNotPresent volumeMounts: - name: cache-volume mountPath: /cache volumes: - emptyDir: {} name: cache-volume
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Name: pod-emptydir Namespace: default Node: node1/192.168.13.199 Start Time: Thu, 18 May 2023 14:15:22 +0800 Labels: <none> Status: Running IP: 10.244 .166 .189 IPs: IP: 10.244 .166 .189 Containers: container-emptydir: Container ID: docker://4496b67a7a687a878e8f644d2064e45e6a1356cb7fc84b98093d6d37bb281a2a Image: nginx Image ID: docker-pullable://nginx@sha256:0d17b565c37bcbd895e9d92315a05c1c3c9a29f762b011a10c54a66cd53c9b31 Port: <none> Host Port: <none> State: Running Started: Thu, 18 May 2023 14:15:24 +0800 Ready: True Restart Count: 0 Environment: <none> Mounts: /cache from cache-volume (rw) /var/run/secrets/kubernetes.io/serviceaccount from default-token-sc5zb (ro) Volumes: cache-volume: Type: EmptyDir (a temporary directory that shares a pod's lifetime) Medium: SizeLimit: <unset>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [root@master1 ~ ] uid: d952eb75-575e-4bf3-b08f-c7faed4f4bbd [root@node1 ~ ] /var/lib/kubelet/pods/d952eb75-575e-4bf3-b08f-c7faed4f4bbd ├── containers │ └── container-emptydir │ └── 21760842 ├── etc-hosts ├── plugins │ └── kubernetes.io~empty-dir │ ├── cache-volume │ │ └── ready │ └── wrapped_default-token-sc5zb │ └── ready └── volumes ├── kubernetes.io~empty-dir │ └── cache-volume └── kubernetes.io~secret └── default-token-sc5zb ├── ca.crt -> ..data/ca.crt ├── namespace -> ..data/namespace └── token -> ..data/token 11 directories, 7 files
# hostpathhostPath Volume 是指 Pod 挂载宿主机上的目录或文件。 hostPath Volume 使得容器可以使用宿主机的文件系统进行存储,hostpath(宿主机路径):节点级别的存储卷,在 pod 被删除,这个存储卷还是存在的,不会被删除,所以只要同一个 pod 被调度到同一个节点上来,在 pod 被删除重新被调度到这个节点之后,对应的数据依然是存在的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 apiVersion: v1 kind: Pod metadata: name: test-hostpath spec: containers: - name: test-nginx image: nginx imagePullPolicy: IfNotPresent volumeMounts: - name: test-volume mountPath: /test-nginx - name: test-tomcat image: tomcat:9.0 imagePullPolicy: IfNotPresent volumeMounts: - name: test-volume mountPath: /test-tomcat volumes: - hostPath: type: DirectoryOrCreate path: /data1 name: test-volume [root@master1 ~ ] root@test-hostpath:/# cd /test-nginx/ https://kubernetes.io/zh-cn/docs/concepts/storage/volumes/ 不会删除宿主机目录,但是如果调度到不同node还是会丢失数据 nodeName: node2
可以用分布式存储:
nfs,cephfs,glusterfs
# nfsNFS:网络文件系统,英文 Network File System (NFS),是由 SUN 公司研制的 UNIX 表示层协议 (presentation layer protocol),能使使用者访问网络上别处的文件就像在使用自己的计算机一样。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@master1 ~ ] [root@master1 ~ ] mkdir: created directory ‘/data’ mkdir: created directory ‘/data/volumes’ [root@master1 ~ ] [root@master1 ~ ] /data/volumes *(rw,no_root_squash) exportfs -avr [root@master1 ~ ] [root@master1 ~ ] [root@master1 ~ ] yum install nfs-utils -y systemctl enable nfs –now showmount -e mount 192.168 .13 .177 :/data/volumes /test/ df -h umount /test
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 apiVersion: apps/v1 kind: Deployment metadata: name: nfs-test spec: replicas: 2 selector: matchLabels: cunchu: nfs template: metadata: labels: cunchu: nfs spec: containers: - image: nginx name: test-nfs imagePullPolicy: IfNotPresent ports: - containerPort: 80 protocol: TCP volumeMounts: - name: nfs-volumes mountPath: /usr/share/nginx/html volumes: - name: nfs-volumes nfs: server: 192.168 .13 .177 path: /data/volumes [root@master1 ~ ] [root@master1 volumes ] <h1>woshishabi<h1> [root@master1 volumes ] <h1>woshishabi</h1> 删除pod,pod重新创建后仍然存在挂载目录中的内容
假设我们使用 nfs 作为存储层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 yum install -y nfs-utils echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exportsmkdir -p /nfs/datasystemctl enable rpcbind --now systemctl enable nfs-server --now exportfs -r showmount -e 172.31.0.4 mkdir -p /nfs/datamount -t nfs 172.31.0.4:/nfs/data /nfs/data echo "hello nfs server" > /nfs/data/test.txt
# 原生方式挂载1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiVersion: apps/v1 kind: Deployment metadata: labels: app: nginx-pv-demo name: nginx-pv-demo spec: replicas: 2 selector: matchLabels: app: nginx-pv-demo template: metadata: labels: app: nginx-pv-demo spec: containers: - image: nginx name: nginx volumeMounts: - name: html mountPath: /usr/share/nginx/html volumes: - name: html nfs: server: 172.31 .0 .2 path: /nfs/data/nginx-pv
# 持久卷PV:持久卷(Persistent Volume),将应用需要持久化的数据保存到指定位置
PVC:持久卷申明(Persistent Volume Claim ),申明需要使用的持久卷规格
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 PersistentVolume(PV)是群集中的一块存储,由管理员配置或使用存储类动态配置。 它是集群中的资源,就像pod是k8s集群资源一样。 PV是容量插件,如Volumes,其生命周期独立于使用PV的任何单个pod。 PersistentVolumeClaim(PVC)是一个持久化存储卷,我们在创建pod时可以定义这个类型的存储卷。 它类似于一个pod。 Pod消耗节点资源,PVC消耗PV资源。 Pod可以请求特定级别的资源(CPU和内存)。 pvc在申请pv的时候也可以请求特定的大小和访问模式(例如,可以一次读写或多次只读)。 PV是群集中的资源。 PVC是对这些资源的请求。 PV和PVC之间的相互作用遵循以下生命周期: (1)pv的供应方式 可以通过两种方式配置PV:静态或动态。 静态的: 集群管理员创建了许多PV。它们包含可供群集用户使用的实际存储的详细信息。它们存在于Kubernetes API中,可供使用。 动态的: 当管理员创建的静态PV都不匹配用户的PersistentVolumeClaim时,群集可能会尝试为PVC专门动态配置卷。此配置基于StorageClasses,PVC必须请求存储类,管理员必须创建并配置该类,以便进行动态配置。 (2)绑定 用户创建pvc并指定需要的资源和访问模式。在找到可用pv之前,pvc会保持未绑定状态 (3)使用 a)需要找一个存储服务器,把它划分成多个存储空间; b)k8s管理员可以把这些存储空间定义成多个pv; c)在pod中使用pvc类型的存储卷之前需要先创建pvc,通过定义需要使用的pv的大小和对应的访问模式,找到合适的pv; d)pvc被创建之后,就可以当成存储卷来使用了,我们在定义pod时就可以使用这个pvc的存储卷 e)pvc和pv它们是一一对应的关系,pv如果被pvc绑定了,就不能被其他pvc使用了; f)我们在创建pvc的时候,应该确保和底下的pv能绑定,如果没有合适的pv,那么pvc就会处于pending状态。 (4)回收策略 当我们创建pod时如果使用pvc做为存储卷,那么它会和pv绑定,当删除pod,pvc和pv绑定就会解除,解除之后和pvc绑定的pv卷里的数据需要怎么处理,目前,卷可以保留,回收或删除: Retain Recycle (不推荐使用,1.15可能被废弃了) Delete 1、Retain 当删除pvc的时候,pv仍然存在,处于released状态,但是它不能被其他pvc绑定使用,里面的数据还是存在的,当我们下次再使用的时候,数据还是存在的,这个是默认的回收策略 Delete 删除pvc时即会从Kubernetes中移除PV,也会从相关的外部设施中删除存储资产
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 mkdir /data/volume_test/v{1,2,3,4,5,6,7,8,9,10} -p vim /etc/exports /data/volume_test/v1 *(rw,no_root_squash) /data/volume_test/v2 *(rw,no_root_squash) /data/volume_test/v3 *(rw,no_root_squash) /data/volume_test/v4 *(rw,no_root_squash) /data/volume_test/v5 *(rw,no_root_squash) /data/volume_test/v6 *(rw,no_root_squash) /data/volume_test/v7 *(rw,no_root_squash) /data/volume_test/v8 *(rw,no_root_squash) /data/volume_test/v9 *(rw,no_root_squash) /data/volume_test/v10 *(rw,no_root_squash) exportfs -arv apiVersion: v1 kind: PersistentVolume metadata: name: v1 labels: app: v1 spec: nfs: path: /data/volume_test/v1 server: 192.168 .13 .177 readOnly: false accessModes: ["ReadWriteOnce" ] capacity: storage: 1Gi --- apiVersion: v1 kind: PersistentVolume metadata: name: v2 labels: app: v2 spec: nfs: path: /data/volume_test/v2 server: 192.168 .13 .177 readOnly: false accessModes: ["ReadOnlyMany" ] capacity: storage: 2Gi --- apiVersion: v1 kind: PersistentVolume metadata: name: v3 labels: app: v3 spec: nfs: path: /data/volume_test/v3 server: 192.168 .13 .177 readOnly: false accessModes: ["ReadWriteMany" ] capacity: storage: 3Gi
1 2 3 4 5 6 7 8 9 RWO:readwariteonce: 单路读写,允许同一个node节点上的pod访问 ROX: readonlymany: 多路只读,允许不同node节点的pod以只读方式访问 RWX: readwritemany: 多路读写,允许不同的node节点的pod以读写方式访问 [root@master1 ~ ] NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE v1 1Gi RWO Retain Available 9m1s v2 2Gi ROX Retain Available 9m1s v3 3Gi RWX Retain Available 9m1s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 apiVersion: v1 kind: PersistentVolumeClaim metadata: name: pvc-v1 spec: accessModes: ["ReadWriteOnce" ] selector: matchLabels: app: v1 resources: requests: storage: 1Gi --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: pvc-v2 spec: accessModes: ["ReadOnlyMany" ] selector: matchLabels: app: v2 resources: requests: storage: 2Gi --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: pvc-v3 spec: accessModes: ["ReadWriteMany" ] selector: matchLabels: app: v3 resources: requests: storage: 3Gi [root@master1 ~ ] NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE pvc-v1 Bound v1 1Gi RWO 3m13s pvc-v2 Bound v2 2Gi ROX 43s pvc-v3 Bound v3 3Gi RWX 43s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 apiVersion: apps/v1 kind: Deployment metadata: name: pvc-test spec: replicas: 2 selector: matchLabels: cunchu: pvc template: metadata: labels: cunchu: pvc spec: containers: - image: nginx name: test-nfs imagePullPolicy: IfNotPresent ports: - containerPort: 80 protocol: TCP volumeMounts: - name: nginx-html mountPath: /usr/share/nginx/html volumes: - persistentVolumeClaim: claimName: pvc-v1 name: nginx-html 1 、我们每次创建pvc的时候,需要事先有划分好的pv,这样可能不方便,那么可以在创建pvc的时候直接动态创建一个pv这个存储类,pv事先是不存在的 2 、pvc和pv绑定,如果使用默认的回收策略retain,那么删除pvc之后,pv会处于released状态,我们想要继续使用这个pv,需要手动删除pv,kubectl delete pv pv_name,删除pv,不会删除pv里的数据,当我们重新创建pvc时还会和这个最匹配的pv绑定,数据还是原来数据,不会丢失。 删除pvc的步骤: 需要先删除使用pvc的pod 再删除pvc 回收策略为retain,删除pvc,pv状态release,需要删除pv重新创建才能为bound状态 Delete策略,删除pvc,pv状态Failed Delete策略,删除pv后端存储所用的数据目录不会被删除,与回收策略无关
创建 pv
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 apiVersion: v1 kind: PersistentVolume metadata: name: pv01-10m spec: capacity: storage: 10M accessModes: - ReadWriteMany storageClassName: nfs nfs: path: /nfs/data/01 server: 172.31 .0 .2 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv02-1gi spec: capacity: storage: 1Gi accessModes: - ReadWriteMany storageClassName: nfs nfs: path: /nfs/data/02 server: 172.31 .0 .2 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv03-3gi spec: capacity: storage: 3Gi accessModes: - ReadWriteMany storageClassName: nfs nfs: path: /nfs/data/03 server: 172.31 .0 .2
1 2 3 4 5 6 [root@master ~] NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pv01-10m 10M RWX Retain Available nfs 59s pv02-1gi 1Gi RWX Retain Available nfs 59s pv03-3gi 3Gi RWX Retain Available nfs 59s
创建 pvc
1 2 3 4 5 6 7 8 9 10 11 kind: PersistentVolumeClaim apiVersion: v1 metadata: name: nginx-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 200Mi storageClassName: nfs
1 2 3 4 5 6 7 8 9 10 11 [root@master ~] NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pv01-10m 10M RWX Retain Available nfs 3m48s pv02-1gi 1Gi RWX Retain Bound default/nginx-pvc nfs 3m48s pv03-3gi 3Gi RWX Retain Available nfs 3m48s [root@master ~] NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE nginx-pvc Bound pv02-1gi 1Gi RWX nfs 107s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiVersion: apps/v1 kind: Deployment metadata: labels: app: nginx-deploy-pvc name: nginx-deploy-pvc spec: replicas: 2 selector: matchLabels: app: nginx-deploy-pvc template: metadata: labels: app: nginx-deploy-pvc spec: containers: - image: nginx name: nginx volumeMounts: - name: html mountPath: /usr/share/nginx/html volumes: - name: html persistentVolumeClaim: claimName: nginx-pvc
# storageclass上面介绍的 PV 和 PVC 模式都是需要先创建好 PV,然后定义好 PVC 和 pv 进行一对一的 Bond,但是如果 PVC 请求成千上万,那么就需要创建成千上万的 PV,对于运维人员来说维护成本很高,Kubernetes 提供一种自动创建 PV 的机制,叫 StorageClass,它的作用就是创建 PV 的模板。k8s 集群管理员通过创建 storageclass 可以动态生成一个存储卷 pv 供 k8s pvc 使用。
每个 StorageClass 都包含字段 provisioner,parameters 和 reclaimPolicy。
具体来说,StorageClass 会定义以下两部分:
有了这两部分信息,Kubernetes 就能够根据用户提交的 PVC,找到对应的 StorageClass,然后 Kubernetes 就会调用 StorageClass 声明的存储插件,创建出需要的 PV。
provisioner:供应商,storageclass 需要有一个供应者,用来确定我们使用什么样的存储来创建 pv,常见的 provisioner 如下
(https://kubernetes.io/zh/docs/concepts/storage/storage-classes/):
provisioner 既可以由内部供应商提供,也可以由外部供应商提供,如果是外部供应商可以参考 https://github.com/kubernetes-incubator/external-storage/ 下提供的方法创建。
https://github.com/kubernetes-sigs/sig-storage-lib-external-provisioner
以 NFS 为例,要想使用 NFS,我们需要一个 nfs-client 的自动装载程序,称之为 provisioner,这个程序会使用我们已经配置好的 NFS 服务器自动创建持久卷,也就是自动帮我们创建 PV。
reclaimPolicy:回收策略
allowVolumeExpansion:允许卷扩展,PersistentVolume 可以配置成可扩展。将此功能设置为 true 时,允许用户通过编辑相应的 PVC 对象来调整卷大小。当基础存储类的 allowVolumeExpansion 字段设置为 true 时,以下类型的卷支持卷扩展。
注意:此功能仅用于扩容卷,不能用于缩小卷。
1 2 3 4 5 安装nfs provisioner,用于配合存储类动态生成pv [root@node2 ~ ] [root@node1 ~ ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 apiVersion: v1 kind: ServiceAccount metadata: name: nfs-provisioner 对sa授权 [root@master1 ] 安装nfs-provisioner程序 [root@master1 ~ ] [root@master1 ~ ] /data/nfs_pro 192.168 .40 .0 /24(rw,no_root_squash) [root@master1 ~ ] kind: Deployment apiVersion: apps/v1 metadata: name: nfs-provisioner spec: selector: matchLabels: app: nfs-provisioner replicas: 1 strategy: type: Recreate template: metadata: labels: app: nfs-provisioner spec: serviceAccount: nfs-provisioner containers: - name: nfs-provisioner image: registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner:v4.0.0 imagePullPolicy: IfNotPresent volumeMounts: - name: nfs-client-root mountPath: /persistentvolumes env: - name: PROVISIONER_NAME value: example.com/nfs - name: NFS_SERVER value: 192.168 .13 .180 - name: NFS_PATH value: /data/nfs_pro volumes: - name: nfs-client-root nfs: server: 192.168 .13 .180 path: /data/nfs_pro apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: nfs provisioner: example.com/nfs kind: PersistentVolumeClaim apiVersion: v1 metadata: name: test-claim1 spec: accessModes: ["ReadWriteMany" ] resources: requests: storage: 1Gi storageClassName: nfs [root@prometheus-master storage-class ] [root@prometheus-master nfs_pro ] default-test-claim1-pvc-85419aac-02d0-4790-a2ed-3eed433841b5
1 2 3 4 步骤总结: 1、供应商:创建一个nfs provisioner 2、创建storageclass,storageclass指定刚才创建的供应商 3、创建pvc,这个pvc指定storageclass
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 kind: Pod apiVersion: v1 metadata: name: read-pod spec: containers: - name: read-pod image: nginx imagePullPolicy: IfNotPresent volumeMounts: - name: nfs-pvc mountPath: /usr/share/nginx/html restartPolicy: "Never" volumes: - name: nfs-pvc persistentVolumeClaim: claimName: test-claim1
1 创建pvc时不需要先创建pv,只需要先创建sc,sc动态生成pv,pvc自动和pv绑定
# statefulsetStatefulSet 是为了管理有状态服务的问题而设计的
有状态服务
无状态服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 apiVersion: v1 kind: Service metadata: name: nginx labels: app: nginx spec: ports: - port: 80 name: web clusterIP: None selector: app: nginx --- apiVersion: apps/v1 kind: StatefulSet metadata: name: web spec: replicas: 2 selector: matchLabels: app: nginx serviceName: "nginx" template: metadata: labels: app: nginx spec: containers: - image: nginx imagePullPolicy: IfNotPresent name: nginx ports: - containerPort: 80 name: web volumeMounts: - name: www mountPath: /usr/share/nginx/html volumeClaimTemplates: - metadata: name: www spec: accessModes: ["ReadWriteMany" ] storageClassName: nfs resources: requests: storage: 1Gi [root@master1 ~ ] NAME READY AGE web 2 /2 66s [root@master1 ~ ] NAME READY STATUS RESTARTS AGE nfs-provisioner-68878cc575-zckvq 1 /1 Running 0 18 web-0 1 /1 Running 0 68s web-1 1 /1 Running 0 64s [root@master1 ~ ] NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE test-claim1 Bound pvc-c23b6e3e-6e95-47b7-9fba-98e97101a541 1Gi RWX nfs 16m www-web-0 Bound pvc-6b0fb835-f835-49cd-b6b8-8805d52af664 1Gi RWX nfs 73s www-web-1 Bound pvc-e4001db8-3ffe-4274-86db-2386933b3b1c 1Gi RWX nfs 69s [root@master1 ~ ] NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON pvc-6b0fb835-f835-49cd-b6b8-8805d52af664 1Gi RWX Delete Bound default/www-web-0 nfs pvc-c23b6e3e-6e95-47b7-9fba-98e97101a541 1Gi RWX Delete Bound default/test-claim1 nfs pvc-e4001db8-3ffe-4274-86db-2386933b3b1c 1Gi RWX Delete Bound default/www-web-1 nfs 使用busybox解析svc nslookup nginx
Statefulset 总结:
1、Statefulset 管理的 pod,pod 名字是有序的,由 statefulset 的名字 - 0、1、2 这种格式组成
2、创建 statefulset 资源的时候,必须事先创建好一个 service, 如果创建的 service 没有 ip,那对这个 service 做 dns 解析,会找到它所关联的 pod ip,如果创建的 service 有 ip,那对这个 service 做 dns 解析,会解析到 service 本身 ip。
3、statefulset 管理的 pod,删除 pod,新创建的 pod 名字跟删除的 pod 名字是一样的
4、statefulset 具有 volumeclaimtemplate 这个字段,这个是卷申请模板,会自动创建 pv,pvc 也会自动生成,跟 pv 进行绑定,那如果创建的 statefulset 使用了 volumeclaimtemplate 这个字段,那创建 pod,数据目录是独享的
5、ststefulset 创建的 pod,是有域名的(域名组成:pod-name.svc-name.svc-namespace.svc.cluster.local)
# statefulset 扩缩容1 2 3 replicas: + - 缩容删除pod顺序是由大到小,即每次删除序号最大的那个 扩容是从小到大
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@master1 ~ ] KIND: StatefulSet VERSION: apps/v1 RESOURCE: updateStrategy <Object> DESCRIPTION: updateStrategy indicates the StatefulSetUpdateStrategy that will be employed to update Pods in the StatefulSet when a revision is made to Template. StatefulSetUpdateStrategy indicates the strategy that the StatefulSet controller will use to perform updates. It includes any additional parameters necessary to perform the update for the indicated strategy. FIELDS: rollingUpdate <Object> RollingUpdate is used to communicate parameters when Type is RollingUpdateStatefulSetStrategyType. type <string> Type indicates the type of the StatefulSetUpdateStrategy. Default is RollingUpdate.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 apiVersion: v1 kind: Service metadata: name: nginx labels: app: nginx spec: ports: - port: 80 name: web clusterIP: None selector: app: nginx --- apiVersion: apps/v1 kind: StatefulSet metadata: name: web spec: updateStrategy: rollingUpdate: partition: 1 maxUnavailable: 0 replicas: 2 selector: matchLabels: app: nginx serviceName: "nginx" template: metadata: labels: app: nginx spec: containers: - image: nginx imagePullPolicy: IfNotPresent name: nginx ports: - containerPort: 80 name: web volumeMounts: - name: www mountPath: /usr/share/nginx/html volumeClaimTemplates: - metadata: name: www spec: accessModes: ["ReadWriteMany" ] storageClassName: nfs resources: requests: storage: 1Gi
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 web-0 1 /1 Running 0 57s web-1 1 /1 Running 0 55s web-1 1 /1 Terminating 0 71s web-1 1 /1 Terminating 0 71s web-1 0 /1 Terminating 0 72s web-1 0 /1 Terminating 0 73s web-1 0 /1 Terminating 0 73s web-1 0 /1 Pending 0 0s web-1 0 /1 Pending 0 0s web-1 0 /1 ContainerCreating 0 1s web-1 0 /1 ContainerCreating 0 2s web-1 1 /1 Running 0 3s partition:1 更新的时候会把pod序号>=1的进行更新 partition:0 所有和yaml不符的pod都会更新 type: OnDelte spec: updateStrategy: type: OnDelete pod不会自动更新,需要手动删除pod,statefulset会在自动用新的yaml创建新的pod
# DaemonSetDaemonSet 控制器能够确保 k8s 集群所有的节点都运行一个相同的 pod 副本,当向 k8s 集群中增加 node 节点时,这个 node 节点也会自动创建一个 pod 副本,当 node 节点从集群移除,这些 pod 也会自动删除;删除 Daemonset 也会删除它们创建的 pod
daemonset 的控制器会监听 kuberntes 的 daemonset 对象、pod 对象、node 对象,这些被监听的对象之变动,就会触发 syncLoop 循环让 kubernetes 集群朝着 daemonset 对象描述的状态进行演进。
在集群的每个节点上运行存储,比如:glusterd 或 ceph。
Deployment 部署的副本 Pod 会分布在各个 Node 上,每个 Node 都可能运行好几个副本。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd namespace: kube-system labels: k8s-app: fluentd-logging spec: selector: matchLabels: name: fluentd template: metadata: labels: name: fluentd spec: volumes: - name: varlog hostPath: path: /var/log - name: varcontainers hostPath: path: /var/lib/docker/containers tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule containers: - image: fluentd imagePullPolicy: IfNotPresent name: fluentd resources: requests: cpu: 100m memory: 200Mi limits: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log volumeMounts: - name: varcontainers mountPath: /var/lib/docker/containers [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES fluentd-gv4jk 1 /1 Running 0 87s 10.244 .136 .3 master3 <none> <none> fluentd-ttcgl 1 /1 Running 0 87s 10.244 .180 .2 master2 <none> <none> fluentd-w5vxw 1 /1 Running 0 87s 10.244 .166 .146 node1 <none> <none> fluentd-w9m2w 1 /1 Running 0 87s 10.244 .137 .70 master1 <none> <none> 四个pod因为集群是三主一从,且定义了容忍度容忍matser污点 [root@master1 ~ ] NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE fluentd 4 4 4 4 4 <none> 106s
# 滚动更新1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 spec: updateStrategy: rollingUpdate: maxUnavailable: 1 kubectl set image daemonset fluentd fluentd=nginx -n kube-system fluentd-55p5p 0 /1 Terminating 0 14s fluentd-55p5p 0 /1 Terminating 0 14s fluentd-55p5p 0 /1 Terminating 0 14s fluentd-55p5p 0 /1 Terminating 0 14s fluentd-qk56k 0 /1 Pending 0 0s fluentd-qk56k 0 /1 Pending 0 0s fluentd-qk56k 0 /1 ContainerCreating 0 1s fluentd-qk56k 0 /1 ContainerCreating 0 3s fluentd-qk56k 1 /1 Running 0 3s
# ConfigMapConfigmap 是 k8s 中的资源对象,用于保存非机密性的配置的,数据可以用 key/value 键值对的形式保存,也可通过文件的形式保存。
我们在部署服务的时候,每个服务都有自己的配置文件,如果一台服务器上部署多个服务:nginx、tomcat、apache 等,那么这些配置都存在这个节点上,假如一台服务器不能满足线上高并发的要求,需要对服务器扩容,扩容之后的服务器还是需要部署多个服务:nginx、tomcat、apache,新增加的服务器上还是要管理这些服务的配置,如果有一个服务出现问题,需要修改配置文件,每台物理节点上的配置都需要修改,这种方式肯定满足不了线上大批量的配置变更要求。 所以,k8s 中引入了 Configmap 资源对象,可以当成 volume 挂载到 pod 中,实现统一的配置管理。
1、Configmap 是 k8s 中的资源, 相当于配置文件,可以有一个或者多个 Configmap;
2、Configmap 可以做成 Volume,k8s pod 启动之后,通过 volume 形式映射到容器内部指定目录上;
3、容器中应用程序按照原有方式读取容器特定目录上的配置文件。
4、在容器看来,配置文件就像是打包在容器内部特定目录,整个过程对应用没有任何。
应用场景:
1、使用 k8s 部署应用,当你将应用配置写进代码中,更新配置时也需要打包镜像,configmap 可以将配置信息和 docker 镜像解耦,以便实现镜像的可移植性和可复用性,因为一个 configMap 其实就是一系列配置信息的集合,可直接注入到 Pod 中给容器使用。configmap 注入方式有两种,一种将 configMap 做为存储卷,一种是将 configMap 通过 env 中 configMapKeyRef 注入到容器中。
2、使用微服务架构的话,存在多个服务共用配置的情况,如果每个服务中单独一份配置的话,那么更新配置就很麻烦,使用 configmap 可以友好的进行配置共享。
configmap 局限性:
ConfigMap 在设计上不是用来保存大量数据的。在 ConfigMap 中保存的数据不可超过 1 MiB。如果你需要保存超出此尺寸限制的数据,可以考虑挂载存储卷或者使用独立的数据库或者文件服务。
# 创建 configMap1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 kubectl create configmap tomcat-config --from-literal=tomcat_port=8080 --from-literal=server_name=myapp.tomcat.com [root@master1 ~ ] NAME DATA AGE tomcat-config 2 6s [root@master1 ~ ] Name: tomcat-config Namespace: default Labels: <none> Annotations: <none> Data ==== server_name: ---- myapp.tomcat.com tomcat_port: ---- 8080
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 创建nginx.conf: server { listen 80 ; root html; } [root@master1 ~ ] configmap/www-nginx created [root@master1 ~ ] Name: www-nginx Namespace: default Labels: <none> Annotations: <none> Data ==== www: ---- server { listen 80 ; root html; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@master1 ~ ] configmap/mysql-config created [root@master1 ~ ] Name: mysql-config Namespace: default Labels: <none> Annotations: <none> Data ==== my-cnf: ---- server-id=1 my-slave-cnf: ---- server-id=2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 apiVersion: v1 kind: ConfigMap metadata: name: mysql labels: app: mysql data: master.cnf: | [mysqld] log-bin log_bin_trust_function_creators=1 lower_case_table_names=1 slave.cnf: | [mysqld] super-read-only log_bin_trust_function_creators=1
# yaml 文件创建 pod 中使用1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 apiVersion: v1 kind: ConfigMap metadata: name: mysql labels: app: mysql data: log : "1" lower: "2" apiVersion: v1 kind: Pod metadata: name: mysql-pod spec: containers: - name: mysql image: busybox command : [ "/bin/sh" , "-c" , "sleep 3600" ] env : - name: log_bin valueFrom: configMapKeyRef: name: mysql key: log - name: lower valueFrom: configMapKeyRef: name: mysql key: lower restartPolicy: Never [root@master1 ~] / log_bin=1 lower=2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 apiVersion: v1 kind: Pod metadata: name: mysql-pod-envfrom spec: containers: - name: mysql image: busybox imagePullPolicy: IfNotPresent command: [ "/bin/sh" , "-c" , "sleep 3600" ] envFrom: - configMapRef: name: mysql restartPolicy: Never [root@master1 ~ ] / lower=2 log=1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 apiVersion: v1 kind: ConfigMap metadata: name: mysql labels: app: mysql data: log: "1" lower: "1" my.cnf: | [mysqld] haha=shabi --- apiVersion: v1 kind: Pod metadata: name: mysql-pod-volume spec: containers: - name: mysql image: busybox imagePullPolicy: IfNotPresent command: [ "/bin/sh" ,"-c" ,"sleep 3600" ] volumeMounts: - name: mysql-config mountPath: /tmp/config volumes: - name: mysql-config configMap: name: mysql restartPolicy: Never [root@master1 ~ ] / /tmp/config log lower my.cnf /tmp/config [mysqld ] haha=shabi
1 2 configmap在以volume启动时可以热加载,cm修改,pod内配置也会自动更新,但需要一定时间 环境变量注入不会自动更新cm,即不能热加载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@master ~] [root@master ~] NAME DATA AGE kube-root-ca.crt 1 3d16h redis-conf 1 6s [root@master ~] [root@master ~] apiVersion: v1 data: redis.conf: | appendonly yes kind: ConfigMap metadata: name: redis-conf namespace: default
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiVersion: v1 kind: Pod metadata: name: redis spec: containers: - name: redis image: redis command: - redis-server - "/redis-master/redis.conf" ports: - containerPort: 6379 volumeMounts: - mountPath: /data name: data - mountPath: /redis-master name: config volumes: - name: data emptyDir: {} - name: config configMap: name: redis-conf items: - key: redis.conf path: redis.conf
1 2 3 4 5 6 7 8 9 [root@master ~ ] configmap/redis-conf edited redis-cli config get appendonly
# secretSecret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 将这些信息放在 secret 中比放在 Pod 的定义或者 容器镜像 中来说更加安全和灵活。
Configmap 一般是用来存放明文数据的,如配置文件,对于一些敏感数据,如密码、私钥等数据时,要用 secret 类型。
Secret 解决了密码、token、秘钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者 Pod Spec 中。Secret 可以以 Volume 或者环境变量的方式使用。
要使用 secret,pod 需要引用 secret。Pod 可以用两种方式使用 secret:作为 volume 中的文件被挂载到 pod 中的一个或者多个容器里,或者当 kubelet 为 pod 拉取镜像时使用。
secret 可选参数有三种:
generic: 通用类型,通常用于存储密码数据。
tls:此类型仅用于存储私钥和证书。
docker-registry: 若要保存 docker 仓库的认证信息的话,就必须使用此种类型来创建。
Secret 类型:
Service Account:用于被 serviceaccount 引用。serviceaccout 创建时 Kubernetes 会默认创建对应的 secret。Pod 如果使用了 serviceaccount,对应的 secret 会自动挂载到 Pod 的 /run/secrets/kubernetes.io/serviceaccount 目录中。
Opaque:base64 编码格式的 Secret,用来存储密码、秘钥等。可以通过 base64 --decode 解码获得原始数据,因此安全性弱
kubernetes.io/dockerconfigjson:用来存储私有 docker registry 的认证信息。
# 创建 secret1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@master1 secret ] secret/mysql-password created [root@master1 secret ] NAME TYPE DATA AGE mysql-password Opaque 1 11s [root@master1 secret ] Name: mysql-password Namespace: default Type: Opaque Data ==== password: 6 bytes
# 使用 secret1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiVersion: v1 kind: Pod metadata: name: pod-secret labels: app: myapp spec: containers: - name: myapp image: nginx imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 env : - name: MYSQL_ROOT_PASSWORD valueFrom: secretKeyRef: name: mysql-password key: password [root@master1 secret] MYSQL_ROOT_PASSWORD=123456
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 [root@master1 secret] YWRtaW4= [root@master1 secret] admin apiVersion: v1 kind: Secret metadata: name: mysecret type : Opaquedata: username: YWRtaW4= password: MTIzNDU2 [root@master1 secret] Name: mysecret Namespace: default Labels: <none> Annotations: <none> Type: Opaque Data ==== password: 6 bytes username: 5 bytes apiVersion: v1 kind: Pod metadata: name: pod-secret-volume spec: containers: - name: myapp image: nginx imagePullPolicy: IfNotPresent volumeMounts: - name: secret-volume mountPath: /etc/secret readOnly: true volumes: - name: secret-volume secret: secretName: mysecret [root@master1 secret] root@pod-secret-volume:/ root@pod-secret-volume:/etc/secret password username root@pod-secret-volume:/etc/secret 123456
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 [root@master ~] [root@master ~] NAME TYPE DATA AGE default-token-mlttj kubernetes.io/service-account-token 3 3d17h kbshire-docker kubernetes.io/dockerconfigjson 1 43s [root@master ~] apiVersion: v1 data: .dockerconfigjson: eyJhdXRocyI6eyJodHRwczovL2luZGV4LmRvY2tlci5pby92MS8iOnsidXNlcm5hbWUiOiJrYnNoaXJlIiwicGFzc3dvcmQiOiIxODMxMDg5MTNhYkMiLCJlbWFpbCI6Imtic2hpcmVAMTYzLmNvbSIsImF1dGgiOiJhMkp6YUdseVpUb3hPRE14TURnNU1UTmhZa009In19fQ== kind: Secret metadata: creationTimestamp: "2023-04-12T05:50:16Z" managedFields: - apiVersion: v1 fieldsType: FieldsV1 fieldsV1: f:data: .: {} f:.dockerconfigjson: {} f:type : {} manager: kubectl-create operation: Update time: "2023-04-12T05:50:16Z" name: kbshire-docker namespace: default resourceVersion: "621248" uid: 84367164-813e-4f1d-8641-da19acd151b7 type : kubernetes.io/dockerconfigjson
1 2 3 4 5 6 7 8 9 10 apiVersion: v1 kind: Pod metadata: name: private-nginx spec: containers: - name: private-nginx image: leifengyang/guignginx:v1.0 imagePullSecrets: - name: kbshire-docker
# RBAC认证
kubernetes 主要通过 APIserver 对外提供服务,那么就需要对访问 apiserver 的用户做认证,如果任何人都能访问 apiserver,那么就可以随意在 k8s 集群部署资源,这是非常危险的,也容易被黑客攻击渗透,所以需要我们对访问 k8s 系统的 apiserver 的用户进行认证,确保是合法的符合要求的用户。
授权
认证通过后仅代表它是一个被 apiserver 信任的用户,能访问 apiserver,但是用户是否拥有删除资源的权限, 需要进行授权操作,常见的授权方式有 rbac 授权。
准入控制
当用户经过认证和授权之后,最后一步就是准入控制了,k8s 提供了多种准入控制机制,它有点类似 "插件",为 apiserver 提供了很好的 "可扩展性"。请求 apiserver 时,通过认证、鉴权后、持久化 (“api 对象 "保存到 etcd) 前,会经过" 准入控制器”,让它可以做 "变更和验证"。
为什么需要准入控制器呢?
假如我们定义了一个名称空间叫做 test-aa,这个名称空间做下资源限制:限制最多可以使用 10vCPU、10Gi 内存,在这个名称空间 test-aa 下创建的所有 pod,定义 limit 的时候,所有 pod 的 limit 值不能超过 test-aa 这个名称空间设置的 limit 上线。
k8s 客户端访问 apiserver 的几种认证方式
1)客户端认证:
2)Bearertoken
Kubectl 访问 k8s 集群,要找一个 kubeconfig 文件,基于 kubeconfig 文件里的用户访问 apiserver
ServiceAccount
上面客户端证书认证和 Bearertoken 的两种认证方式,都是外部访问 apiserver 的时候使用的方式,那么我们这次说的 Serviceaccount 是内部访问 pod 和 apiserver 交互时候采用的一种方式。
Serviceaccount 包括了,namespace、token、ca,且通过目录挂载的方式给予 pod,当 pod 运行起来的时候,就会读取到这些信息,从而使用该方式和 apiserver 进行通信。
在 K8S 集群当中,当我们使用 kubectl 操作 k8s 资源时候,需要确定我们用哪个用户访问哪个 k8s 集群,kubectl 操作 k8s 集群资源会去 /root/.kube 目录下找 config 文件,可以通过 kubectl config 查看 config 文件配置,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@master1 ~ ] apiVersion: v1 clusters: - cluster: certificate-authority-data: DATA+OMITTED server: https://192.168.13.249:16443 name: kubernetes contexts: - context: cluster: kubernetes user: kubernetes-admin name: kubernetes-admin@kubernetes current-context: kubernetes-admin@kubernetes kind: Config preferences: {}users: - name: kubernetes-admin user: client-certificate-data: REDACTED client-key-data: REDACTED kubectl get pods --kubeconfig=/root/.kube/config
# 授权用户通过认证之后,什么权限都没有,需要一些后续的授权操作,如对资源的增删该查等,kubernetes1.6 之后开始有 RBAC(基于角色的访问控制机制)授权检查机制。
Kubernetes 的授权是基于插件形成的,其常用的授权插件有以下几种:
1)Node(节点认证)
2)ABAC (基于属性的访问控制)
3)RBAC(基于角色的访问控制)
4)Webhook(基于 http 回调机制的访问控制)
什么是 RBAC(基于角色的授权)
让一个用户(Users)扮演一个角色(Role),角色拥有权限,从而让用户拥有这样的权限,随后在授权机制当中,只需要将权限授予某个角色,此时用户将获取对应角色的权限,从而实现角色的访问控制。
另外,k8s 为此还有一种集群级别的授权机制,就是定义一个集群角色(ClusterRole),对集群内的所有资源都有可操作的权限,从而将 User2 通过 ClusterRoleBinding 到 ClusterRole,从而使 User2 拥有集群的操作权限。
Role、RoleBinding、ClusterRole 和 ClusterRoleBinding 的关系如下:
1. 用户基于 rolebinding 绑定到 role
2. 用户基于 rolebinding 绑定到 clusterrole
1 2 3 4 5 (1)用户通过rolebinding绑定role (2)用户通过rolebinding绑定clusterrole rolebinding绑定clusterrole的好处: 假如有6个名称空间,每个名称空间的用户都需要对自己的名称空间有管理员权限,那么需要定义6个role和rolebinding,然后依次绑定,如果名称空间更多,我们需要定义更多的role,这个是很麻烦的,所以我们引入clusterrole,定义一个clusterrole,对clusterrole授予所有权限,然后用户通过rolebinding绑定到clusterrole,就会拥有自己名称空间的管理员权限了
3、用户基于 clusterrolebinding 绑定到 clusterrole
用户基于 rbac 授权有几种方案:
基于 rolebinding 绑定到 role 上
基于 rolebinding 绑定到 clusterrole 上
基于 clusterrolebinding 绑定到 clusterrole 上
# 准入控制在 k8s 上准入控制器的模块有很多,其中比较常用的有 LimitRanger、ResourceQuota、ServiceAccount、PodSecurityPolicy (k8s1.25 废弃了) 等等,对于前面三种准入控制器系统默认是启用的,我们只需要定义对应的规则即可;对于 PodSecurityPolicy (k8s1.25 废弃了) 这种准入控制器,系统默认没有启用,如果我们要使用,就必需启用以后,对应规则才会正常生效;这里需要注意一点,对应 psp 准入控制器,一定要先写好对应的规则,把规则和权限绑定好以后,在启用对应的准入控制器,否则先启用准入控制器,没有对应的规则,默认情况它是拒绝操作,这可能导致现有的 k8s 系统跑的系统级 pod 无法正常工作;所以对于 psp 准入控制器要慎用,如果规则和权限做的足够精细,它会给我们的 k8s 系统安全带来大幅度的提升,反之,可能导致整个 k8s 系统不可用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 cat /etc/kubernetes/manifests/kube-apiserver.yaml apiVersion: v1 kind: Pod metadata: annotations: kubeadm.kubernetes.io/kube-apiserver.advertise-address.endpoint: 192.168.40.63:6443 creationTimestamp: null labels: component: kube-apiserver tier: control-plane name: kube-apiserver namespace: kube-system spec: containers: - command: - kube-apiserver - --advertise-address=192.168.40.180 … - --enable-admission-plugins=NodeRestriction # 开启准入插件,逗号分隔 LimitRanger、ResourceQuota、ServiceAccount 是自动开启的
apiserver 启用准入控制插件需要使用–enable-admission-plugins 选项来指定,该选项可以使用多个值,用逗号隔开表示启用指定的准入控制插件;这里配置文件中显式启用了 NodeRestrication 这个插件;默认没有写在这上面的内置准入控制器,它也是启用了的,比如 LimitRanger、ResourceQuota、ServiceAccount 等等;对于不同的 k8s 版本,内置的准入控制器和启用与否请查看相关版本的官方文档;对于那些没有启动的准入控制器,我们可以在上面选项中直接启用,分别用逗号隔开即可。
https://kubernetes.io/zh-cn/docs/reference/access-authn-authz/admission-controllers/
# useraccount 、serviceaccountkubernetes 中账户分为:UserAccounts(用户账户) 和 ServiceAccounts(服务账户) 两种:
ServiceAccount 是 Pod 使用的账号,Pod 容器的进程需要访问 API Server 时用的就是 ServiceAccount 账户;ServiceAccount 仅局限它所在的 namespace,每个 namespace 创建时都会自动创建一个 default service account;创建 Pod 时,如果没有指定 Service Account,Pod 则会使用 default Service Account。
ua 是 kubectl 访问集群的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 apiVersion: v1 kind: Pod metadata: name: sa-test namespace: default labels: app: sa spec: serviceAccountName: sa-test containers: - name: sa-tomcat ports: - containerPort: 80 image: nginx imagePullPolicy: IfNotPresent [root@master1 rbac ] root@sa-test:/# cd /var/run/secrets/kubernetes.io/serviceaccount/ root@sa-test:/var/run/secrets/kubernetes.io/serviceaccount# ls ca.crt namespace token root@sa-test:/var/run/secrets/kubernetes.io/serviceaccount# curl --cacert ./ca.crt -H "Authorization: Bearer $(cat ./token)" https://kubernetes/api/v1/namespaces/kube-system { "kind": "Status" , "apiVersion": "v1" , "metadata": { }, "status": "Failure" , "message": "namespaces \"kube-system\" is forbidden: User \"system:serviceaccount:default:sa-test\" cannot get resource \"namespaces\" in API group \"\" in the namespace \"kube-system\"" , "reason": "Forbidden" , "details": { "name": "kube-system" , "kind": "namespaces" }, "code": 403 } kubectl create clusterrolebinding sa-test-admin --clusterrole=cluster-admin --serviceaccount=default:sa-test root@sa-test:/var/run/secrets/kubernetes.io/serviceaccount# curl --cacert ./ca.crt -H "Authorization: Bearer $(cat ./token)" https://kubernetes/api/v1/namespaces/kube-system { "kind": "Namespace" , "apiVersion": "v1" , "metadata": { "name": "kube-system" , "uid": "b25c9a07-c34a-4ce7-8afe-a7b3b1fa6895" , "resourceVersion": "4" , "creationTimestamp": "2023-04-25T08:50:07Z" , "managedFields": [ { "manager": "kube-apiserver" , "operation": "Update" , "apiVersion": "v1" , "time": "2023-04-25T08:50:07Z" , "fieldsType": "FieldsV1" , "fieldsV1": {"f:status" : {"f:phase" : {}}} } ] }, "spec": { "finalizers": [ "kubernetes" ] }, "status": { "phase": "Active" } } /api/v1/pods
# rbac在 Kubernetes 中,所有资源对象都是通过 API 进行操作,他们保存在 etcd 里。而对 etcd 的操作我们需要通过访问 kube-apiserver 来实现,上面的 Service Account 其实就是 APIServer 的认证过程,而授权的机制是通过 RBAC:基于角色的访问控制实现。
RBAC 有四个资源对象,分别是 Role、ClusterRole、RoleBinding、ClusterRoleBinding
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 role: 一组权限的集合,在一个命名空间中,可以用其来定义一个角色,只能对命名空间内的资源进行授权。如果是集群级别的资源,则需要使用ClusterRole。 例如:定义一个角色用来读取Pod的权限 apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: namespace: rbac name: pod-read rules: - apiGroups: ["" ] resources: ["pods" ] resourceNames: [] verbs: ["get" ,"watch" ,"list" ] rules中的参数说明: 1 、apiGroups:支持的API组列表,例如:"apiVersion: apps/v1"等 2 、resources:支持的资源对象列表,例如pods、deployments、jobs等 3 、resourceNames: 指定resource的名称 4 、verbs:对资源对象的操作方法列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ClusterRole:集群角色 具有和角色一致的命名空间资源的管理能力,还可用于以下特殊元素的授权 1 、集群范围的资源,例如Node 2 、非资源型的路径,例如:/healthz 3 、包含全部命名空间的资源,例如Pods 例如:定义一个集群角色可让用户访问任意secrets apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: secrets-clusterrole rules: - apiGroups: ["" ] resources: ["secrets" ] resourceNames: [] verbs: ["get" ,"watch" ,"list" ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 RoleBinding:角色绑定、ClusterRolebinding:集群角色绑定 角色绑定和集群角色绑定用于把一个角色绑定在一个目标上,可以是User,Group,Service Account,使用RoleBinding为某个命名空间授权,使用ClusterRoleBinding为集群范围内授权。 例如:将在rbac命名空间中把pod-read角色授予用户es apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: pod-read-bind namespace: rbac subjects: - kind: User name: es apiGroup: rbac.authorization.k8s.io roleRef: - kind: Role name: pod-read apiGroup: rbac.authorizatioin.k8s.io RoleBinding也可以引用ClusterRole,对属于同一命名空间内的ClusterRole定义的资源主体进行授权, 例如:es能获取到集群中所有的资源信息 apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: es-allresource namespace: rbac subjects: - kind: User name: es apiGroup: rbac.authorization.k8s.io roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin
# 资源引用方式多数资源可以用其名称的字符串表示,也就是 Endpoint 中的 URL 相对路径,例如 pod 中的日志是 GET /api/v1/namaspaces/{namespace}/pods/{podname}/log
如果需要在一个 RBAC 对象中体现上下级资源,就需要使用 “/” 分割资源和下级资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 例如:若想授权让某个主体同时能够读取Pod和Pod log,则可以配置 resources为一个数组 [root@ ~ ] apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: logs-reader namespace: test rules: - apiGroups: ["" ] resources: ["pods" ,"pods/log" ] verbs: ["get" ,"list" ,"watch" ] [root@master1 rbac ] NAME CREATED AT logs-reader 2023-05-23T06:33:45Z [root@master1 rbac ] serviceaccount/sa-test created [root@master1 rbac ] rolebinding.rbac.authorization.k8s.io/sa-test-1 created apiVersion: v1 kind: Pod metadata: name: sa-test-pod namespace: test labels: app: sa spec: serviceAccountName: sa-test containers: - name: sa-tomcat ports: - containerPort: 80 image: nginx imagePullPolicy: IfNotPresent [root@master1 rbac ] root@sa-test-pod:/# cd /var/run/secrets/kubernetes.io/serviceaccount/ root@sa-test-pod:/var/run/secrets/kubernetes.io/serviceaccount# ls ca.crt namespace token root@sa-test-pod:/var/run/secrets/kubernetes.io/serviceaccount# curl --cacert ./ca.crt -H "Authorization: Bearer $(cat ./token)" https://kubernetes.default/api/v1/namespaces/test/pods/sa-test-pod/logs { "kind": "Status" , "apiVersion": "v1" , "metadata": { }, "status": "Failure" , "message": "pods \"sa-test-pod\" is forbidden: User \"system:serviceaccount:test:sa-test\" cannot get resource \"pods/logs\" in API group \"\" in the namespace \"test\"" , "reason": "Forbidden" , "details": { "name": "sa-test-pod" , "kind": "pods" }, "code": 403 } root@sa-test-pod:/var/run/secrets/kubernetes.io/serviceaccount# curl --cacert ./ca.crt -H "Authorization: Bearer $(cat ./token)" https://kuberntes.default/api/v1/namespaces/test/pods/sa-test-pod/log /docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration /docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/ /docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh 10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf 10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf /docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh /docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh /docker-entrypoint.sh: Configuration complete; ready for start up 2023 /05/23 06 :37:45 [notice ] 1 2023 /05/23 06 :37:45 [notice ] 1 2023 /05/23 06 :37:45 [notice ] 1 2023 /05/23 06 :37:45 [notice ] 1 2023 /05/23 06 :37:45 [notice ] 1 2023 /05/23 06 :37:45 [notice ] 1 2023 /05/23 06 :37:45 [notice ] 1 2023 /05/23 06 :37:45 [notice ] 1 2023 /05/23 06 :37:45 [notice ] 1 2023 /05/23 06 :37:45 [notice ] 1 资源还可以通过名称(ResourceName)进行引用,在指定ResourceName后,使用get、delete、update、patch请求,就会被限制在这个资源实例范围内 例如,下面的声明让一个主体只能对名为my-configmap的Configmap进行get和update操作: apiVersion: rabc.authorization.k8s.io/v1 kind: Role metadata: namaspace: default name: configmap-update rules: - apiGroups: ["" ] resources: ["configmaps" ] resourceNames: ["my-configmap" ] verbs: ["get" ,"update" ]
# 常见角色实例1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 (1)允许读取核心API组的Pod资源 rules: - apiGroups: ["" ] resources: ["pods" ] verbs: ["get" ,"list" ,"watch" ] (2)允许读写apps API组中的deployment资源 rules: - apiGroups: ["apps" ] resources: ["deployments" ] verbs: ["get" ,"list" ,"watch" ,"create" ,"update" ,"patch" ,"delete" ] (3)允许读取Pod以及读写job信息 rules: - apiGroups: ["" ] resources: ["pods" ] verbs: ["get" ,"list" ,"watch" ] - apiGroups: ["" ] resources: ["jobs" ] verbs: ["get" ,"list" ,"watch" ,"create" ,"update" ,"patch" ,"delete" ] (4)允许读取一个名为my-config的ConfigMap(必须绑定到一个RoleBinding来限制到一个Namespace下的ConfigMap): rules: - apiGroups: ["" ] resources: ["configmaps" ] resourceNames: ["my-configmap" ] verbs: ["get" ] (5)读取核心组的Node资源(Node属于集群级的资源,所以必须存在于ClusterRole中,并使用ClusterRoleBinding进行绑定): rules: - apiGroups: ["" ] resources: ["nodes" ] verbs: ["get" ,"list" ,"watch" ] (6)允许对非资源端点“/healthz”及其所有子路径进行GET和POST操作(必须使用ClusterRole和ClusterRoleBinding): rules: - nonResourceURLs: ["/healthz" ,"/healthz/*" ] verbs: ["get" ,"post" ]
# 常见的角色绑定示例1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 (1)用户名alice subjects: - kind: User name: alice apiGroup: rbac.authorization.k8s.io (2)组名alice subjects: - kind: Group name: alice apiGroup: rbac.authorization.k8s.io (3)kube-system命名空间中默认Service Account subjects: - kind: ServiceAccount name: default namespace: kube-system
# SA 授权1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Service Account也是一种账号,是给运行在Pod里的进程提供了必要的身份证明。需要在Pod定义中指明引用的Service Account,这样就可以对Pod的进行赋权操作。 例如:pod内可获取rbac命名空间的所有Pod资源,pod-reader-sc的Service Account是绑定了名为pod-read的Role [root@ ] [root@ ] [root@ ] apiVersion: v1 kind: Pod metadata: name: nginx namespace: rbac spec: serviceAccountName: pod-reader-sc containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 (1)my-namespace中的my-sa Service Account授予只读权限 kubectl create rolebinding my-sa-view --clusterrole=view --serviceaccount=my-namespace:my-sa --namespace=my-namespace (2)为一个命名空间中名为default的Service Account授权 如果一个应用没有指定 serviceAccountName,则会使用名为default的Service Account。注意,赋予Service Account “default”的权限会让所有没有指定serviceAccountName的Pod都具有这些权限 (3)为命名空间中所有Service Account都授予一个角色 如果希望在一个命名空间中,任何Service Account应用都具有一个角色,则可以为这一命名空间的Service Account群组进行授权 kubectl create rolebinding serviceaccounts-view --clusterrole=view --group=system:serviceaccounts:my-namespace --namespace=my-namespace (4)为集群范围内所有Service Account都授予一个低权限角色 如果不想为每个命名空间管理授权,则可以把一个集群级别的角色赋给所有Service Account。 kubectl create clusterrolebinding serviceaccounts-view --clusterrole=view --group=system:serviceaccounts (5)为所有Service Account授予超级用户权限 kubectl create clusterrolebinding serviceaccounts-view --clusterrole=cluster-admin --group=system:serviceaccounts
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 (1)在命名空间rbac中为用户es授权admin ClusterRole: kubectl create rolebinding bob-admin-binding --clusterrole=admin --user=es --namespace=rbac (2)在命名空间rbac中为名为myapp的Service Account授予view ClusterRole: kubctl create rolebinding myapp-role-binding --clusterrole=view --serviceaccount=rbac:myapp --namespace=rbac (3)在全集群范围内为用户root授予cluster-admin ClusterRole: kubectl create clusterrolebinding cluster-binding --clusterrole=cluster-admin --user=root (4)在全集群范围内为名为myapp的Service Account授予view ClusterRole: kubectl create clusterrolebinding service-account-binding --clusterrole=view --serviceaccount=myapp
# 限制不同用户访问 k8s1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 (1)生成一个私钥 cd /etc/kubernetes/pki/ (umask 077 ; openssl genrsa -out lucky.key 2048 ) (2)生成一个证书请求 openssl req -new -key lucky.key -out lucky.csr -subj "/CN=lucky" (3)生成一个证书 openssl x509 -req -in lucky.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out lucky.crt -days 3650 在kubeconfig下新增加一个lucky这个用户 (1)把lucky这个用户添加到kubernetes集群中,可以用来认证apiserver的连接 [root@xianchaomaster1 pki ] (2)在kubeconfig下新增加一个lucky这个账号 kubectl config set-context lucky@kubernetes --cluster=kubernetes --user=lucky kubectl config view contexts: - context: cluster: kubernetes user: kubernetes-admin name: kubernetes-admin@kubernetes - context: cluster: kubernetes user: lucky name: lucky@kubernetes current-context: lucky@kubernetes kind: Config preferences: {}users: - name: kubernetes-admin user: client-certificate-data: REDACTED client-key-data: REDACTED - name: lucky user: client-certificate-data: REDACTED client-key-data: REDACTED [root@master1 pki ] [root@master1 pki ] [root@master1 pki ] No resources found in lucky-test namespace. [root@master1 pki ] Error from server (Forbidden): pods is forbidden: User "lucky" cannot list resource "pods" in API group "" in the namespace "default" 添加一个test的普通用户 useradd test cp -ar /root/.kube /tmp/ 修改/tmp/.kube/config文件,把kubernetes-admin相关的删除,只留lucky用户 cp -ar /tmp/.kube/ /home/test/ chown -R test.test /home/test/ su - test kubectl get pods -n lucky test只能使用lucky的权限访问kubernetes 退出test用户,需要在把集群环境切换成管理员权限 kubectl config use-context kubernetes-admin@kubernetes
# 授权用户能查看所有名称空间 pod 权限1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 ssl认证 生成一个证书 (1)生成一个私钥 cd /etc/kubernetes/pki/ (umask 077 ; openssl genrsa -out lucky1.key 2048 ) (2)生成一个证书请求 openssl req -new -key lucky1.key -out lucky1.csr -subj "/CN=lucky66" (3)生成一个证书 openssl x509 -req -in lucky1.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out lucky1.crt -days 3650 在kubeconfig下新增加一个lucky这个用户 (1)把lucky这个用户添加到kubernetes集群中,可以用来认证apiserver的连接 [root@master1 pki ] (2)在kubeconfig下新增加一个lucky这个账号 kubectl config set-context lucky66@kubernetes --cluster=kubernetes --user=lucky66 (3)创建一个clusterrole [root@master1 sa ] apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: lucky66-get-pod rules: - apiGroups: ["" ] resources: ["pods" ] verbs: ["get" , "list" , "watch" ] [root@master1 ] (4)创建一个clusterrolebinding [root@master1 ] 添加一个test66的普通用户 useradd test66 rm -rf /tmp/.kube cp -ar /root/.kube /tmp/ 修改/tmp/.kube/config文件,把kubernetes-admin和lucky相关的删除,只留lucky66用户 cp -ar /tmp/.kube/ /home/test66/ chown -R test66.test66 /home/test66/ [root@master1 ] 把current-context变成如下: current-context: lucky66@kubernetes su - test66 kubectl get pods kubectl get pods -n kube-system kubectl get ns
# ResourceQuota 准入控制器 ResourceQuota 准入控制器是 k8s 上内置的准入控制器,默认该控制器是启用的状态,它主要作用是用来限制一个名称空间下的资源的使用,它能防止在一个名称空间下的 pod 被过多创建时,导致过多占用 k8s 资源,简单讲它是用来在名称空间级别限制用户的资源使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 apiVersion: v1 kind: ResourceQuota metadata: name: quota-test namespace: quota spec: hard: pods: "6" requests.cpu: "2" requests.memory: 2Gi limits.cpu: "4" limits.memory: 10Gi count/deployments.apps: "6" persistentvolumeclaims: "6" --- apiVersion: apps/v1 kind: Deployment metadata: name: quota namespace: quota spec: replicas: 2 template: metadata: labels: app: quota version: v1 spec: containers: - name: myapp image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 resources: requests: cpu: 1 memory: 1Gi limits: cpu: 2 memory: 2Gi selector: matchLabels: app: quota version: v1 [root@master1 rbac ] NAME READY STATUS RESTARTS AGE quota-8b9bc78cd-d2jcc 1 /1 Running 0 16s quota-8b9bc78cd-dzxp8 1 /1 Running 0 16s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 apiVersion: v1 kind: ResourceQuota metadata: name: quota-test namespace: quota spec: hard: pods: "6" requests.cpu: "2" requests.memory: 2Gi limits.cpu: "4" limits.memory: 10Gi count/deployments.apps: "6" persistentvolumeclaims: "6" --- apiVersion: apps/v1 kind: Deployment metadata: name: quota namespace: quota spec: strategy: type: Recreate replicas: 7 template: metadata: labels: app: quota version: v1 spec: containers: - name: myapp image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 resources: requests: cpu: 10m memory: 100Mi limits: cpu: 1 memory: 1Gi selector: matchLabels: app: quota version: v1 [root@master1 rbac ] NAME READY STATUS RESTARTS AGE quota-646fb6b848-c2h8z 1 /1 Running 0 24s quota-646fb6b848-v5pmr 1 /1 Running 0 24s quota-646fb6b848-z2p5k 1 /1 Running 0 24s quota-646fb6b848-zwwd7 1 /1 Running 0 24s
1 2 3 4 5 6 7 8 9 10 11 12 2 、限制存储空间大小 apiVersion: v1 kind: ResourceQuota metadata: name: quota-storage-test namespace: quota spec: hard: requests.storage: "5Gi" persistentvolumeclaims: "5" requests.ephemeral-storage: "1Gi" limits.ephemeral-storage: "2Gi"
requests.storage 用来限制对应名称空间下的存储下限总和,persistenvolumeclaims 用来限制 pvc 总数量,requests.ephemeral-storage 用来现在使用本地临时存储的下限总容量;limits.ephemeral-storage 用来限制使用本地临时存储上限总容量;以上配置表示在 default 名称空间下非停止状态的容器存储下限总容量不能超过 5G,pvc 的数量不能超过 5 个,本地临时存储下限容量不能超过 1G,上限不能超过 2G。
# LimitRanger 准入控制器LimitRanger 准入控制器是 k8s 上一个内置的准入控制器,LimitRange 是 k8s 上的一个标准资源,它主要用来定义在某个名称空间下限制 pod 或 pod 里的容器对 k8s 上的 cpu 和内存资源使用;它能够定义我们在某个名称空间下创建 pod 时使用的 cpu 和内存的上限和下限以及默认 cpu、内存的上下限。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 apiVersion: v1 kind: Namespace metadata: name: limit --- apiVersion: v1 kind: LimitRange metadata: name: cpu-memory namespace: limit spec: limits: - default: cpu: 1000m memory: 1000Mi defaultRequest: cpu: 500m memory: 500Mi min: cpu: 500m memory: 500Mi max: cpu: 2000m memory: 2000Mi maxLimitRequestRatio: cpu: 4 memory: 4 type: Container --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: limit subjects: - kind: ServiceAccount name: default namespace: limit roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io --- apiVersion: v1 kind: ServiceAccount metadata: name: default namespace: limit labels: app: default apiVersion: v1 kind: Pod metadata: name: nginx-pod-demo namespace: limit spec: containers: - image: nginx imagePullPolicy: IfNotPresent name: nginx kubectl describe pod Limits: cpu: 1 memory: 1000Mi Requests: cpu: 500m memory: 500Mi
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 apiVersion: v1 kind: Pod metadata: name: pod-request namespace: limit spec: containers: - image: nginx imagePullPolicy: IfNotPresent name: nginx resources: requests: cpu: 100m [root@master1 rbac ] Error from server (Forbidden): error when creating "haha.yaml": pods "pod-request" is forbidden: [minimum cpu usage per Container is 500m , but request is 100m , cpu max limit to request ratio per Container is 4 , but provided ratio is 10.000000 ]
# kubesphere建议配置: master:4c8g node:4c16g
# 平台安装1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME /.kube sudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/config sudo chown $(id -u):$(id -g) $HOME /.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of control-plane nodes by copying certificate authorities and service account keys on each node and then running the following as root: kubeadm join k8s-master:6443 --token butsu9.lcap4rmxigogjm3g \ --discovery-token-ca-cert-hash sha256:96ec447684310e31f9890dab205123d2081c5e1acbf025e88c727a1951fe0f54 \ --control-plane Then you can join any number of worker nodes by running the following on each as root: kubeadm join k8s-master:6443 --token butsu9.lcap4rmxigogjm3g \ --discovery-token-ca-cert-hash sha256:96ec447684310e31f9890dab205123d2081c5e1acbf025e88c727a1951fe0f54
# 配置前置存储类安装 nfs-server
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 yum install -y nfs-utils echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exportsmkdir -p /nfs/datasystemctl enable rpcbind systemctl enable nfs-server systemctl start rpcbind systemctl start nfs-server exportfs -r exportfs
配置 nfs-client
1 2 3 4 5 showmount -e 172.23.142.216 mkdir -p /nfs/data mount -t nfs 172.23.142.216:/nfs/data /nfs/data
配置默认存储
配置动态供应的默认存储类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: nfs-storage annotations: storageclass.kubernetes.io/is-default-class: "true" provisioner: k8s-sigs.io/nfs-subdir-external-provisioner parameters: archiveOnDelete: "true" --- apiVersion: apps/v1 kind: Deployment metadata: name: nfs-client-provisioner labels: app: nfs-client-provisioner namespace: default spec: replicas: 1 strategy: type: Recreate selector: matchLabels: app: nfs-client-provisioner template: metadata: labels: app: nfs-client-provisioner spec: serviceAccountName: nfs-client-provisioner containers: - name: nfs-client-provisioner image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2 volumeMounts: - name: nfs-client-root mountPath: /persistentvolumes env: - name: PROVISIONER_NAME value: k8s-sigs.io/nfs-subdir-external-provisioner - name: NFS_SERVER value: 172.23 .142 .216 - name: NFS_PATH value: /nfs/data volumes: - name: nfs-client-root nfs: server: 172.23 .142 .216 path: /nfs/data --- apiVersion: v1 kind: ServiceAccount metadata: name: nfs-client-provisioner namespace: default --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: nfs-client-provisioner-runner rules: - apiGroups: ["" ] resources: ["nodes" ] verbs: ["get" , "list" , "watch" ] - apiGroups: ["" ] resources: ["persistentvolumes" ] verbs: ["get" , "list" , "watch" , "create" , "delete" ] - apiGroups: ["" ] resources: ["persistentvolumeclaims" ] verbs: ["get" , "list" , "watch" , "update" ] - apiGroups: ["storage.k8s.io" ] resources: ["storageclasses" ] verbs: ["get" , "list" , "watch" ] - apiGroups: ["" ] resources: ["events" ] verbs: ["create" , "update" , "patch" ] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: run-nfs-client-provisioner subjects: - kind: ServiceAccount name: nfs-client-provisioner namespace: default roleRef: kind: ClusterRole name: nfs-client-provisioner-runner apiGroup: rbac.authorization.k8s.io --- kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: leader-locking-nfs-client-provisioner namespace: default rules: - apiGroups: ["" ] resources: ["endpoints" ] verbs: ["get" , "list" , "watch" , "create" , "update" , "patch" ] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: leader-locking-nfs-client-provisioner namespace: default subjects: - kind: ServiceAccount name: nfs-client-provisioner namespace: default roleRef: kind: Role name: leader-locking-nfs-client-provisioner apiGroup: rbac.authorization.k8s.io
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@master ~] storageclass.storage.k8s.io/nfs-storage created deployment.apps/nfs-client-provisioner created serviceaccount/nfs-client-provisioner created clusterrole.rbac.authorization.k8s.io/nfs-client-provisioner-runner created clusterrolebinding.rbac.authorization.k8s.io/run-nfs-client-provisioner created role.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created rolebinding.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created [root@master ~] NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE nfs-storage (default) k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 18s
1 2 3 4 5 6 7 8 9 10 kind: PersistentVolumeClaim apiVersion: v1 metadata: name: nginx-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 200Mi
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@master ~] persistentvolumeclaim/nginx-pvc created [root@master ~] NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE nginx-pvc Bound pvc-2f0e7123-3311-4045-bba9-acdcbad0a572 200Mi RWX nfs-storage 10s [root@master ~] NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pv01-10m 10M RWX Retain Available nfs 22h pv02-1gi 1Gi RWX Retain Released default/nginx-pvc nfs 22h pv03-3gi 3Gi RWX Retain Available nfs 22h pvc-2f0e7123-3311-4045-bba9-acdcbad0a572 200Mi RWX Delete Bound default/nginx-pvc nfs-storage 24s
# 安装 metrics-server1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server rbac.authorization.k8s.io/aggregate-to-admin: "true" rbac.authorization.k8s.io/aggregate-to-edit: "true" rbac.authorization.k8s.io/aggregate-to-view: "true" name: system:aggregated-metrics-reader rules: - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server name: system:metrics-server rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats - namespaces - configmaps verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: labels: k8s-app: metrics-server name: metrics-server-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server name: metrics-server:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server name: system:metrics-server roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:metrics-server subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: v1 kind: Service metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: ports: - name: https port: 443 protocol: TCP targetPort: https selector: k8s-app: metrics-server --- apiVersion: apps/v1 kind: Deployment metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: selector: matchLabels: k8s-app: metrics-server strategy: rollingUpdate: maxUnavailable: 0 template: metadata: labels: k8s-app: metrics-server spec: containers: - args: - --cert-dir=/tmp - --kubelet-insecure-tls - --secure-port=4443 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname - --kubelet-use-node-status-port image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/metrics-server:v0.4.3 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 httpGet: path: /livez port: https scheme: HTTPS periodSeconds: 10 name: metrics-server ports: - containerPort: 4443 name: https protocol: TCP readinessProbe: failureThreshold: 3 httpGet: path: /readyz port: https scheme: HTTPS periodSeconds: 10 securityContext: readOnlyRootFilesystem: true runAsNonRoot: true runAsUser: 1000 volumeMounts: - mountPath: /tmp name: tmp-dir nodeSelector: kubernetes.io/os: linux priorityClassName: system-cluster-critical serviceAccountName: metrics-server volumes: - emptyDir: {} name: tmp-dir --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: labels: k8s-app: metrics-server name: v1beta1.metrics.k8s.io spec: group: metrics.k8s.io groupPriorityMinimum: 100 insecureSkipTLSVerify: true service: name: metrics-server namespace: kube-system version: v1beta1 versionPriority: 100
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@master ~] [root@master ~] NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% master 258m 12% 1889Mi 49% node1 <unknown> <unknown> <unknown> <unknown> node2 <unknown> <unknown> <unknown> <unknown> [root@master ~] NAMESPACE NAME CPU(cores) MEMORY(bytes) default nfs-client-provisioner-786945db78-788mx 1m 11Mi kube-system calico-kube-controllers-57c7b58f66-jq7lm 3m 23Mi kube-system calico-node-4bttn 38m 150Mi kube-system coredns-5897cd56c4-2fhkm 2m 14Mi kube-system coredns-5897cd56c4-2l59f 3m 10Mi kube-system etcd-master 13m 49Mi kube-system kube-apiserver-master 54m 467Mi kube-system kube-controller-manager-master 22m 58Mi kube-system kube-proxy-d4sgz 1m 14Mi kube-system kube-scheduler-master 3m 23Mi kube-system metrics-server-6497cc6c5f-n4l62 3m 13Mi tigera-operator tigera-operator-57cb64cf85-kqsvh 3m 27Mi
# 全功能安装1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 wget https://github.com/kubesphere/ks-installer/releases/download/v3.3.2/kubesphere-installer.yaml wget https://github.com/kubesphere/ks-installer/releases/download/v3.3.2/cluster-configuration.yaml [root@master ~] [root@master ~] [root@master ~] customresourcedefinition.apiextensions.k8s.io/clusterconfigurations.installer.kubesphere.io created namespace/kubesphere-system created serviceaccount/ks-installer created clusterrole.rbac.authorization.k8s.io/ks-installer created clusterrolebinding.rbac.authorization.k8s.io/ks-installer created deployment.apps/ks-installer created [root@master ~] clusterconfiguration.installer.kubesphere.io/ks-installer created
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 --- apiVersion: installer.kubesphere.io/v1alpha1 kind: ClusterConfiguration metadata: name: ks-installer namespace: kubesphere-system labels: version: v3.1.1 spec: persistence: storageClass: "" authentication: jwtSecret: "" local_registry: "" etcd: monitoring: true endpointIps: 172.31.0.4 port: 2379 tlsEnable: true common: redis: enabled: true openldap: enabled: true minioVolumeSize: 20Gi openldapVolumeSize: 2Gi redisVolumSize: 2Gi monitoring: endpoint: http://prometheus-operated.kubesphere-monitoring-system.svc:9090 es: elasticsearchMasterVolumeSize: 4Gi elasticsearchDataVolumeSize: 20Gi logMaxAge: 7 elkPrefix: logstash basicAuth: enabled: false username: "" password: "" externalElasticsearchUrl: "" externalElasticsearchPort: "" console: enableMultiLogin: true port: 30880 alerting: enabled: true auditing: enabled: true devops: enabled: true jenkinsMemoryLim: 2Gi jenkinsMemoryReq: 1500Mi jenkinsVolumeSize: 8Gi jenkinsJavaOpts_Xms: 512m jenkinsJavaOpts_Xmx: 512m jenkinsJavaOpts_MaxRAM: 2g events: enabled: true ruler: enabled: true replicas: 2 logging: enabled: true logsidecar: enabled: true replicas: 2 metrics_server: enabled: false monitoring: storageClass: "" prometheusMemoryRequest: 400Mi prometheusVolumeSize: 20Gi multicluster: clusterRole: none network: networkpolicy: enabled: true ippool: type : calico topology: type : none openpitrix: store: enabled: true servicemesh: enabled: true kubeedge: enabled: true cloudCore: nodeSelector: {"node-role.kubernetes.io/worker" : "" } tolerations: [] cloudhubPort: "10000" cloudhubQuicPort: "10001" cloudhubHttpsPort: "10002" cloudstreamPort: "10003" tunnelPort: "10004" cloudHub: advertiseAddress: - "" nodeLimit: "100" service: cloudhubNodePort: "30000" cloudhubQuicNodePort: "30001" cloudhubHttpsNodePort: "30002" cloudstreamNodePort: "30003" tunnelNodePort: "30004" edgeWatcher: nodeSelector: {"node-role.kubernetes.io/worker" : "" } tolerations: [] edgeWatcherAgent: nodeSelector: {"node-role.kubernetes.io/worker" : "" } tolerations: []
检查日志
1 2 3 4 5 kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}' ) -f kubectl describe pod -n namespace name
etcd 监控证书
1 kubectl -n kubesphere-monitoring-system create secret generic kube-etcd-client-certs --from-file=etcd-client-ca.crt=/etc/kubernetes/pki/etcd/ca.crt --from-file=etcd-client.crt=/etc/kubernetes/pki/apiserver-etcd-client.crt --from-file=etcd-client.key=/etc/kubernetes/pki/apiserver-etcd-client.key
# linxu 安装 单节点1. 准备 kubekey
1 2 3 4 export KKZONE=cn curl -sfL https://get-kk.kubesphere.io | VERSION=v3.0.7 sh - chmod +x kk
2. 使用 kubekey 引导安装集群
1 2 3 ./kk create cluster [--with-kubernetes version] [--with-kubesphere version] ./kk create cluster --with-kubernetes v1.22.12 --with-kubesphere v3.3.2
这样不是全功能平台
安装后开启功能
以 admin 用户登录控制台,点击左上角的平台管理 ,选择集群管理 。
点击定制资源定义 ,在搜索栏中输入 clusterconfiguration ,点击搜索结果查看其详细页面。
信息
定制资源定义(CRD)允许用户在不新增 API 服务器的情况下创建一种新的资源类型,用户可以像使用其他 Kubernetes 原生对象一样使用这些定制资源。
在自定义资源 中,点击 ks-installer 右侧的 编辑 YAML 。
在该 YAML 文件中,搜索 devops ,将 enabled 的 false 改为 true 。完成后,点击右下角的确定 ,保存配置。
1 2 devops: enabled: true # 将“false”更改为“true”。
在 kubectl 中执行以下命令检查安装过程:
1 kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -f
# linux 多节点安装1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 export KKZONE=cncurl -sfL https://get-kk.kubesphere.io | VERSION=v3.0.7 sh - chmod +x kk ./kk create config --with-kubernetes v1.22.12 --with-kubesphere v3.3.2 vim config.sample spec: hosts: - {name: master, address: 192.168.0.2, internalAddress: 192.168.0.2, user: ubuntu, password: Testing123} - {name: node1, address: 192.168.0.3, internalAddress: 192.168.0.3, user: ubuntu, password: Testing123} - {name: node2, address: 192.168.0.4, internalAddress: 192.168.0.4, user: ubuntu, password: Testing123} roleGroups: etcd: - master control-plane: - master worker: - node1 - node2 controlPlaneEndpoint: domain: lb.kubesphere.local address: "" port: 6443 ./kk create cluster -f config-sample.yaml
多节点安装 (kubesphere.io)
# 部署应用# 使用镜像部署deploy:部署无状态应用
stateful:部署有状态应用,中间件
daemon:
工作负载 -> PVC -> configmap -> service -> ingress
pvc 建议现用现创
1 2 3 4 1.定义配置字典 2.应用负载-创建工作负载 3.创建工作负载时创建持久卷
# 使用应用市场部署
# 使用应用模板部署Helm
Artifact Hub
1 2 3 4 5 1.找到仓库地址 https://charts.bitnami.com/bitnami 2.找到对应的工作空间 添加应用仓库 创建应用时从应用模板创建
# 部署 ruoyi cloud# 本地部署1. 下载 ruoyi cloud 源码
RuoYi-Cloud: 🎉 基于 Spring Boot、Spring Cloud & Alibaba 的分布式微服务架构权限管理系统,同时提供了 Vue3 的版本 (gitee.com)
2. 下载 nacos
Nacos 快速开始
3. 修改配置文件
application.properties
1 2 3 4 5 6 7 8 9 10 spring.datasource.platform=mysql db.num=1 db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true &useUnicode=true &useSSL=false &serverTimezone=UTC db.user.0=root db.password.0=root123
创建数据库 nacos
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 /* * Copyright 1999-2018 Alibaba Group Holding Ltd. * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ /******************************************/ /* 数据库全名 = nacos_config */ /* 表名称 = config_info */ /******************************************/ CREATE TABLE `config_info` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id', `data_id` varchar(255) NOT NULL COMMENT 'data_id', `group_id` varchar(128) DEFAULT NULL, `content` longtext NOT NULL COMMENT 'content', `md5` varchar(32) DEFAULT NULL COMMENT 'md5', `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间', `src_user` text COMMENT 'source user', `src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip', `app_name` varchar(128) DEFAULT NULL, `tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段', `c_desc` varchar(256) DEFAULT NULL, `c_use` varchar(64) DEFAULT NULL, `effect` varchar(64) DEFAULT NULL, `type` varchar(64) DEFAULT NULL, `c_schema` text, `encrypted_data_key` text NOT NULL COMMENT '秘钥', PRIMARY KEY (`id`), UNIQUE KEY `uk_configinfo_datagrouptenant` (`data_id`,`group_id`,`tenant_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info'; /******************************************/ /* 数据库全名 = nacos_config */ /* 表名称 = config_info_aggr */ /******************************************/ CREATE TABLE `config_info_aggr` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id', `data_id` varchar(255) NOT NULL COMMENT 'data_id', `group_id` varchar(128) NOT NULL COMMENT 'group_id', `datum_id` varchar(255) NOT NULL COMMENT 'datum_id', `content` longtext NOT NULL COMMENT '内容', `gmt_modified` datetime NOT NULL COMMENT '修改时间', `app_name` varchar(128) DEFAULT NULL, `tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段', PRIMARY KEY (`id`), UNIQUE KEY `uk_configinfoaggr_datagrouptenantdatum` (`data_id`,`group_id`,`tenant_id`,`datum_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='增加租户字段'; /******************************************/ /* 数据库全名 = nacos_config */ /* 表名称 = config_info_beta */ /******************************************/ CREATE TABLE `config_info_beta` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id', `data_id` varchar(255) NOT NULL COMMENT 'data_id', `group_id` varchar(128) NOT NULL COMMENT 'group_id', `app_name` varchar(128) DEFAULT NULL COMMENT 'app_name', `content` longtext NOT NULL COMMENT 'content', `beta_ips` varchar(1024) DEFAULT NULL COMMENT 'betaIps', `md5` varchar(32) DEFAULT NULL COMMENT 'md5', `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间', `src_user` text COMMENT 'source user', `src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip', `tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段', `encrypted_data_key` text NOT NULL COMMENT '秘钥', PRIMARY KEY (`id`), UNIQUE KEY `uk_configinfobeta_datagrouptenant` (`data_id`,`group_id`,`tenant_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_beta'; /******************************************/ /* 数据库全名 = nacos_config */ /* 表名称 = config_info_tag */ /******************************************/ CREATE TABLE `config_info_tag` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id', `data_id` varchar(255) NOT NULL COMMENT 'data_id', `group_id` varchar(128) NOT NULL COMMENT 'group_id', `tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id', `tag_id` varchar(128) NOT NULL COMMENT 'tag_id', `app_name` varchar(128) DEFAULT NULL COMMENT 'app_name', `content` longtext NOT NULL COMMENT 'content', `md5` varchar(32) DEFAULT NULL COMMENT 'md5', `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间', `src_user` text COMMENT 'source user', `src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip', PRIMARY KEY (`id`), UNIQUE KEY `uk_configinfotag_datagrouptenanttag` (`data_id`,`group_id`,`tenant_id`,`tag_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_tag'; /******************************************/ /* 数据库全名 = nacos_config */ /* 表名称 = config_tags_relation */ /******************************************/ CREATE TABLE `config_tags_relation` ( `id` bigint(20) NOT NULL COMMENT 'id', `tag_name` varchar(128) NOT NULL COMMENT 'tag_name', `tag_type` varchar(64) DEFAULT NULL COMMENT 'tag_type', `data_id` varchar(255) NOT NULL COMMENT 'data_id', `group_id` varchar(128) NOT NULL COMMENT 'group_id', `tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id', `nid` bigint(20) NOT NULL AUTO_INCREMENT, PRIMARY KEY (`nid`), UNIQUE KEY `uk_configtagrelation_configidtag` (`id`,`tag_name`,`tag_type`), KEY `idx_tenant_id` (`tenant_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_tag_relation'; /******************************************/ /* 数据库全名 = nacos_config */ /* 表名称 = group_capacity */ /******************************************/ CREATE TABLE `group_capacity` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID', `group_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Group ID,空字符表示整个集群', `quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值', `usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量', `max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值', `max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数,,0表示使用默认值', `max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值', `max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量', `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间', PRIMARY KEY (`id`), UNIQUE KEY `uk_group_id` (`group_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='集群、各Group容量信息表'; /******************************************/ /* 数据库全名 = nacos_config */ /* 表名称 = his_config_info */ /******************************************/ CREATE TABLE `his_config_info` ( `id` bigint(20) unsigned NOT NULL, `nid` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `data_id` varchar(255) NOT NULL, `group_id` varchar(128) NOT NULL, `app_name` varchar(128) DEFAULT NULL COMMENT 'app_name', `content` longtext NOT NULL, `md5` varchar(32) DEFAULT NULL, `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP, `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP, `src_user` text, `src_ip` varchar(50) DEFAULT NULL, `op_type` char(10) DEFAULT NULL, `tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段', `encrypted_data_key` text NOT NULL COMMENT '秘钥', PRIMARY KEY (`nid`), KEY `idx_gmt_create` (`gmt_create`), KEY `idx_gmt_modified` (`gmt_modified`), KEY `idx_did` (`data_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='多租户改造'; /******************************************/ /* 数据库全名 = nacos_config */ /* 表名称 = tenant_capacity */ /******************************************/ CREATE TABLE `tenant_capacity` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID', `tenant_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Tenant ID', `quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值', `usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量', `max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值', `max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数', `max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值', `max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量', `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间', PRIMARY KEY (`id`), UNIQUE KEY `uk_tenant_id` (`tenant_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='租户容量信息表'; CREATE TABLE `tenant_info` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id', `kp` varchar(128) NOT NULL COMMENT 'kp', `tenant_id` varchar(128) default '' COMMENT 'tenant_id', `tenant_name` varchar(128) default '' COMMENT 'tenant_name', `tenant_desc` varchar(256) DEFAULT NULL COMMENT 'tenant_desc', `create_source` varchar(32) DEFAULT NULL COMMENT 'create_source', `gmt_create` bigint(20) NOT NULL COMMENT '创建时间', `gmt_modified` bigint(20) NOT NULL COMMENT '修改时间', PRIMARY KEY (`id`), UNIQUE KEY `uk_tenant_info_kptenantid` (`kp`,`tenant_id`), KEY `idx_tenant_id` (`tenant_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='tenant_info'; CREATE TABLE `users` ( `username` varchar(50) NOT NULL PRIMARY KEY, `password` varchar(500) NOT NULL, `enabled` boolean NOT NULL ); CREATE TABLE `roles` ( `username` varchar(50) NOT NULL, `role` varchar(50) NOT NULL, UNIQUE INDEX `idx_user_role` (`username` ASC, `role` ASC) USING BTREE ); CREATE TABLE `permissions` ( `role` varchar(50) NOT NULL, `resource` varchar(255) NOT NULL, `action` varchar(8) NOT NULL, UNIQUE INDEX `uk_role_permission` (`role`,`resource`,`action`) USING BTREE ); INSERT INTO users (username, password, enabled) VALUES ('nacos', '$2a$10$EuWPZHzz32dJN7jexM34MOeYirDdFAZm2kuWj7VEOJhhZkDrxfvUu', TRUE); INSERT INTO roles (username, role) VALUES ('nacos', 'ROLE_ADMIN');
1 2 startup.cmd -m standalone http://localhost:8848/nacos/#/configurationManagement?dataId=&group=&appName=&namespace=&pageSize=&pageNo=
1 2 3 4 5 6 7 8 导入 ry_config_20220929.sql # 修改配置文件 db.url.0=jdbc:mysql://127.0.0.1:3306/ry-config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user.0=root db.password.0=root123
启动 service
# 上云部署# 1. 移至 mysql将本地 mysql 使用 mysql workbench migrate 到云上
移植成功
# 2. 部署中间件 nacos
kubesphere 中创建 nacos service
1 2 nacos-v1-0.nacos.hos.svc.cluster.local:8848 nacos-v1-1.nacos.hos.svc.cluster.local:8848
# 部署微服务1 2 3 4 5 6 7 8 9 10 11 12 13 FROM openjdk:8-jdk LABEL maintainer=leifengyang ENV PARAMS="--server.port=8080 --spring.profiles.active=prod --spring.cloud.nacos.discovery.server-addr=his-nacos.his:8848 --spring.cloud.nacos.config.server-addr=nacos.hos:8848 --spring.cloud.nacos.config.namespace=prod --spring.cloud.nacos.config.file-extension=yml" RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo 'Asia/Shanghai' >/etc/timezone COPY target/*.jar /app.jar EXPOSE 8080 ENTRYPOINT ["/bin/sh" ,"-c" ,"java -Dfile.encoding=utf8 -Djava.security.egd=file:/dev/./urandom -jar app.jar ${PARAMS} " ]
打包:
制作镜像:docker 根据 Dockerfile 把包打成指定的镜像
推送镜像:将镜像推送给 docker hub(阿里云镜像仓库)
应用部署:给 k8s 部署应用,node1 节点部署应用
docker tag [ImageId] registry.cn-hangzhou.aliyuncs.com/shinya/ 镜像名:v1
若依管理系统
# DevOpsDevOps 是一系列做法和工具 ,可以使 IT 和软件开发团队之间的流程实现自动化 。其中,随着敏捷软件开发日趋流行,持续集成 (CI) 和持续交付 (CD) 已经成为该领域一个理想的解决方案。在 CI/CD 工作流中,每次集成都通过自动化构建来验证,包括编码、发布和测试,从而帮助开发者提前发现集成错误,团队也可以快速、安全、可靠地将内部软件交付到生产环境。
https://gitee.com/leifengyang/yygh-parent
https://gitee.com/leifengyang/yygh-admin
https://gitee.com/leifengyang/yygh-site
中间件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 sentinel.hos:8080 http://106.14.22.128:30395/#/login mongodb.hos:27017 http://106.14.22.128:30417 redis.hos mysql.hos rabbitm-j17f1z-rabbitmq.hos
mvn clean package -Dmaven.test.skip=true
使用 admin 登陆 ks
进入集群管理
进入配置中心
找到配置
ks-devops-agent 修改这个配置。加入 maven 阿里云镜像加速地址
使用 admin 登陆 ks
进入集群管理
进入配置中心
找到配置
ks-devops-agent 修改这个配置。加入 maven 阿里云镜像加速地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 pipeline { agent { node { label 'maven' } } stages { stage('拉取代码' ) { agent none steps { container('maven' ) { git(url: 'https://gitee.com/kbshire/yygh-parent' , credentialsId: 'giteeid' , branch: 'master' , changelog: true , poll: false ) sh 'ls -al' } } } stage('项目编译' ) { agent none steps { container('maven' ) { sh 'ls -al' sh 'mvn clean package -Dmaven.test.skip=true' } } } stage('default-2' ) { parallel { stage('构建hospital镜像' ) { agent none steps { container('maven' ) { sh 'docker build -t hospital-manage:latest -f hospital-manage/Dockerfile hospital-manage/' sh 'ls -al hospital-manage/target' } } } stage('构建server-gateway' ) { agent none steps { container('maven' ) { sh 'ls -al server-gateway/target' sh 'docker build -t server-gateway:latest -f server-gateway/Dockerfile server-gateway/' } } } stage('构建service-cmn镜像' ) { agent none steps { container('maven' ) { sh 'docker build -t service-cmn:latest -f service/service-cmn/Dockerfile ./service/service-cmn/' sh 'ls -al service/service-cmn/target' } } } stage('构建service-hosp镜像' ) { agent none steps { container('maven' ) { sh 'docker build -t service-hosp:latest -f service/service-hosp/Dockerfile ./service/service-hosp/' sh 'ls -al service/service-hosp/target' } } } stage('构建service-order镜像' ) { agent none steps { container('maven' ) { sh 'docker build -t service-order:latest -f service/service-order/Dockerfile ./service/service-order/' sh 'ls -al service/service-order/target' } } } stage('构建service-oss镜像' ) { agent none steps { container('maven' ) { sh 'docker build -t service-oss:latest -f service/service-oss/Dockerfile ./service/service-oss/' sh 'ls -al service/service-oss/target' } } } stage('构建service-sms镜像' ) { agent none steps { container('maven' ) { sh 'docker build -t service-sms:latest -f service/service-sms/Dockerfile ./service/service-sms/' sh 'ls -al service/service-sms/target' } } } stage('构建service-statistics镜像' ) { agent none steps { container('maven' ) { sh 'docker build -t service-statistics:latest -f service/service-statistics/Dockerfile ./service/service-statistics/' sh 'ls -al service/service-statistics/target' } } } stage('构建service-task镜像' ) { agent none steps { container('maven' ) { sh 'docker build -t service-task:latest -f service/service-task/Dockerfile ./service/service-task/' sh 'ls -al service/service-task/target' } } } stage('构建service-user镜像' ) { agent none steps { container('maven' ) { sh 'docker build -t service-user:latest -f service/service-user/Dockerfile ./service/service-user/' sh 'ls -al service/service-user/target' } } } } } stage('push latest' ) { when { branch 'master' } steps { container('maven' ) { sh 'docker tag $REGISTRY/$DOCKERHUB_NAMESPACE/$APP_NAME:SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER $REGISTRY/$DOCKERHUB_NAMESPACE/$APP_NAME:latest ' sh 'docker push $REGISTRY/$DOCKERHUB_NAMESPACE/$APP_NAME:latest ' } } } stage('deploy to dev' ) { steps { container('maven' ) { input(id : 'deploy-to-dev' , message: 'deploy to dev?' ) withCredentials([kubeconfigContent(credentialsId : 'KUBECONFIG_CREDENTIAL_ID' ,variable : 'KUBECONFIG_CONFIG' ,)]) { sh 'mkdir -p ~/.kube/' sh 'echo "$KUBECONFIG_CONFIG" > ~/.kube/config' sh 'envsubst < deploy/dev-ol/deploy.yaml | kubectl apply -f -' } } } } stage('deploy to production' ) { steps { container('maven' ) { input(id : 'deploy-to-production' , message: 'deploy to production?' ) withCredentials([kubeconfigContent(credentialsId : 'KUBECONFIG_CREDENTIAL_ID' ,variable : 'KUBECONFIG_CONFIG' ,)]) { sh 'mkdir -p ~/.kube/' sh 'echo "$KUBECONFIG_CONFIG" > ~/.kube/config' sh 'envsubst < deploy/prod-ol/deploy.yaml | kubectl apply -f -' } } } } } environment { //定义的所有变量可以在任意位置使用 DOCKER_CREDENTIAL_ID = 'dockerhub-id' GITHUB_CREDENTIAL_ID = 'github-id' KUBECONFIG_CREDENTIAL_ID = 'demo-kubeconfig' REGISTRY = 'docker.io' DOCKERHUB_NAMESPACE = 'docker_username' GITHUB_ACCOUNT = 'kubesphere' APP_NAME = 'devops-java-sample' } parameters { string(name: 'TAG_NAME' , defaultValue: '' , description: '' ) } }
1 2 3 4 5 registry.cn-hangzhou.aliyuncs.com/shinya_hello/ruoyi-visual-monitor: sh 'docker tag hospital-manage:latest $registry/$DOCKERHUB_NAMESPACE/hospital-manage:SNAPSHOT-$BUILD_NUMBER' sh 'docker push $REGISTRY/$DOCKERHUB_NAMESPACE/hospital-manage:SNAPSHOT-$BUILD_NUMBER'
加载阿里云镜像密钥
http://106.14.22.128:30880/devops_webhook/git/?url=https://gitee.com/kbshire/yygh-site
http://106.14.22.128:30880/devops_webhook/git/?url=https://gitee.com/kbshire/yygh-admin

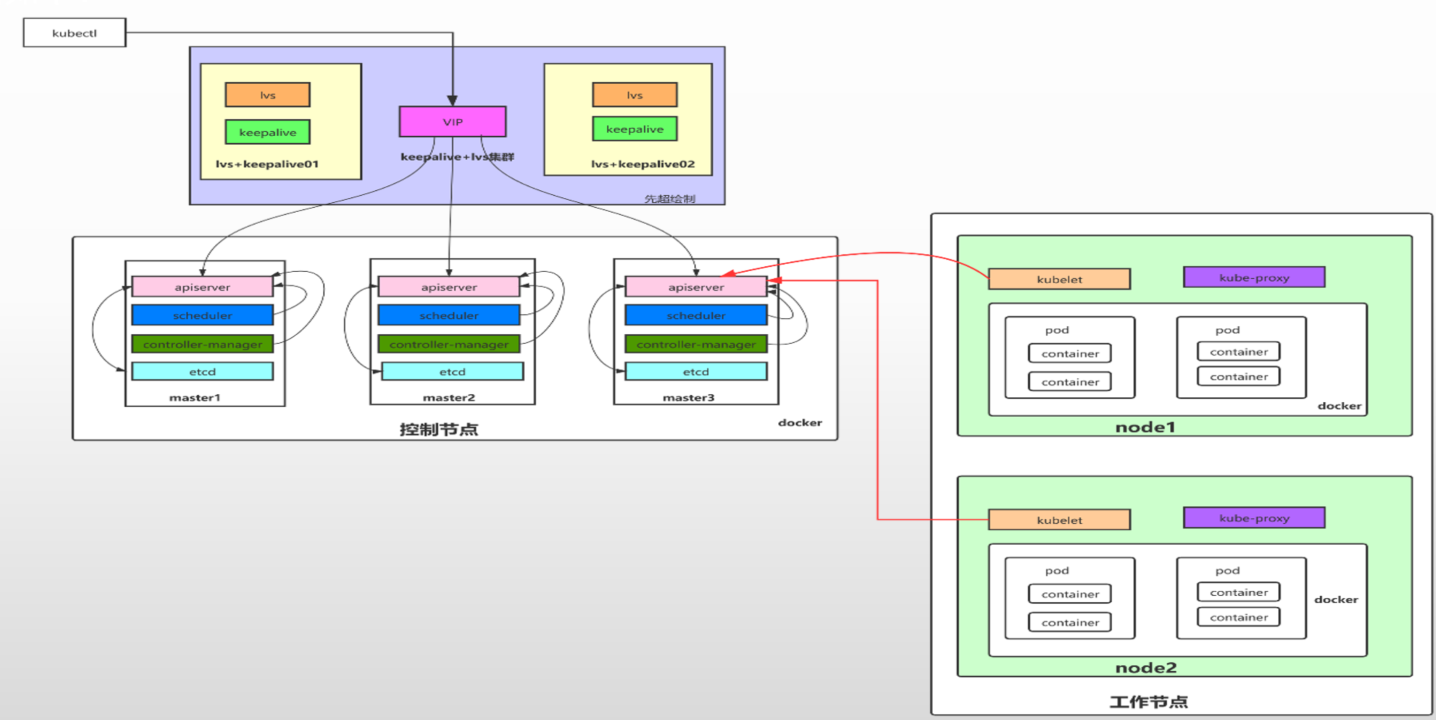
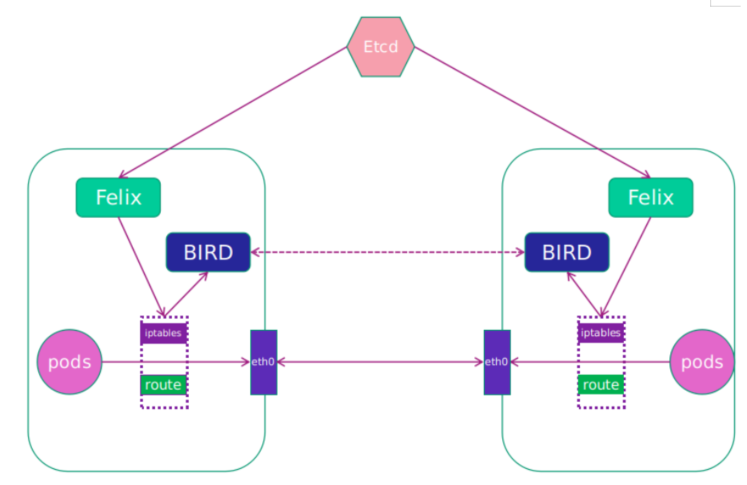
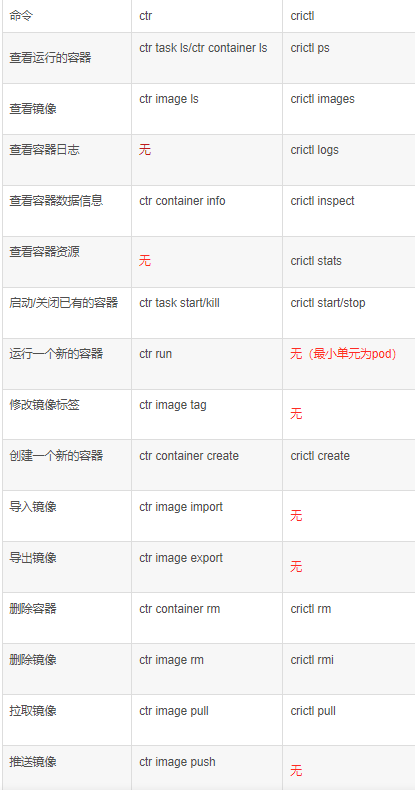



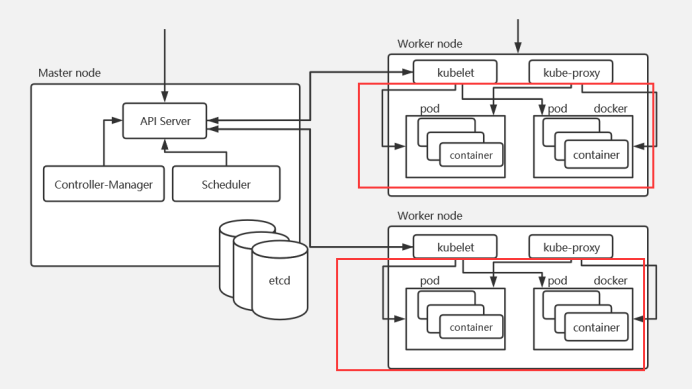
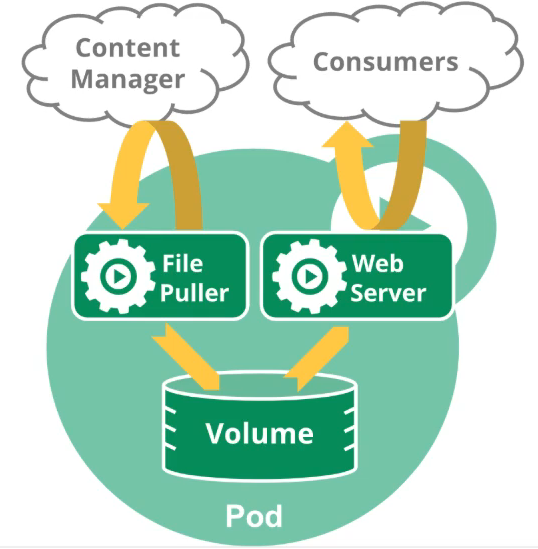
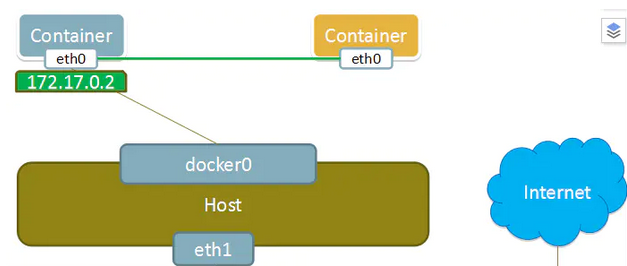

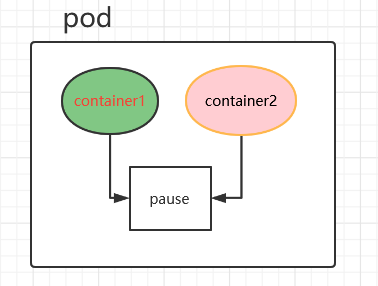
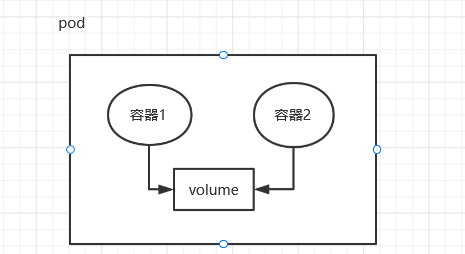
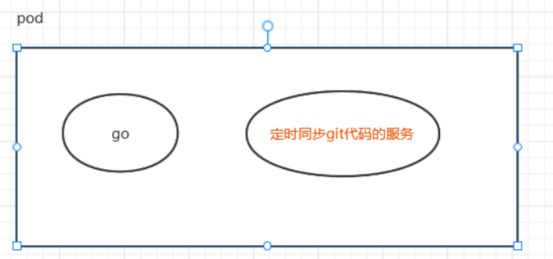
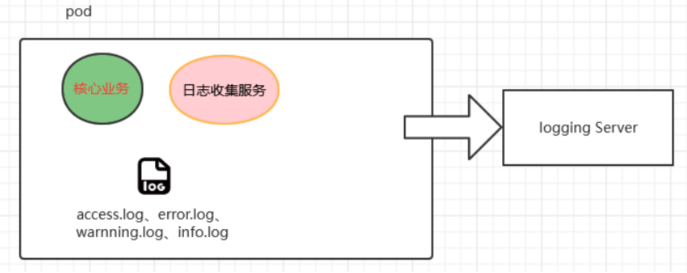
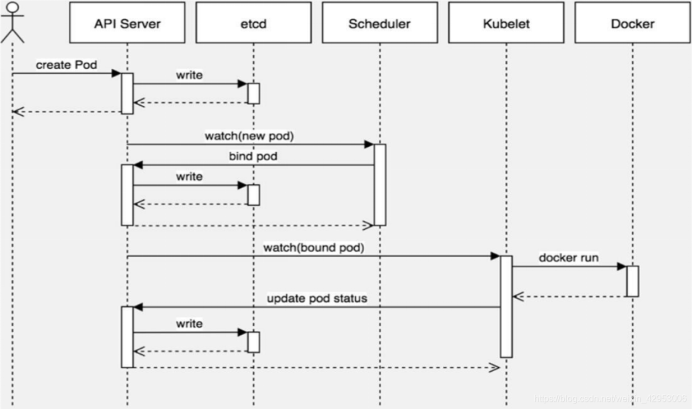

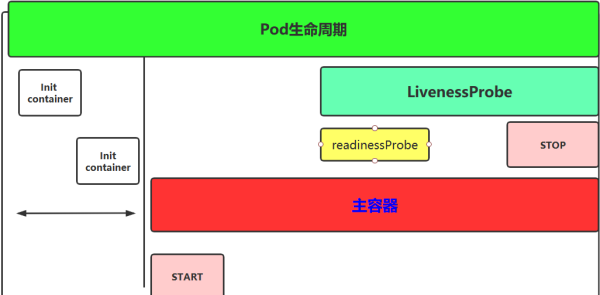
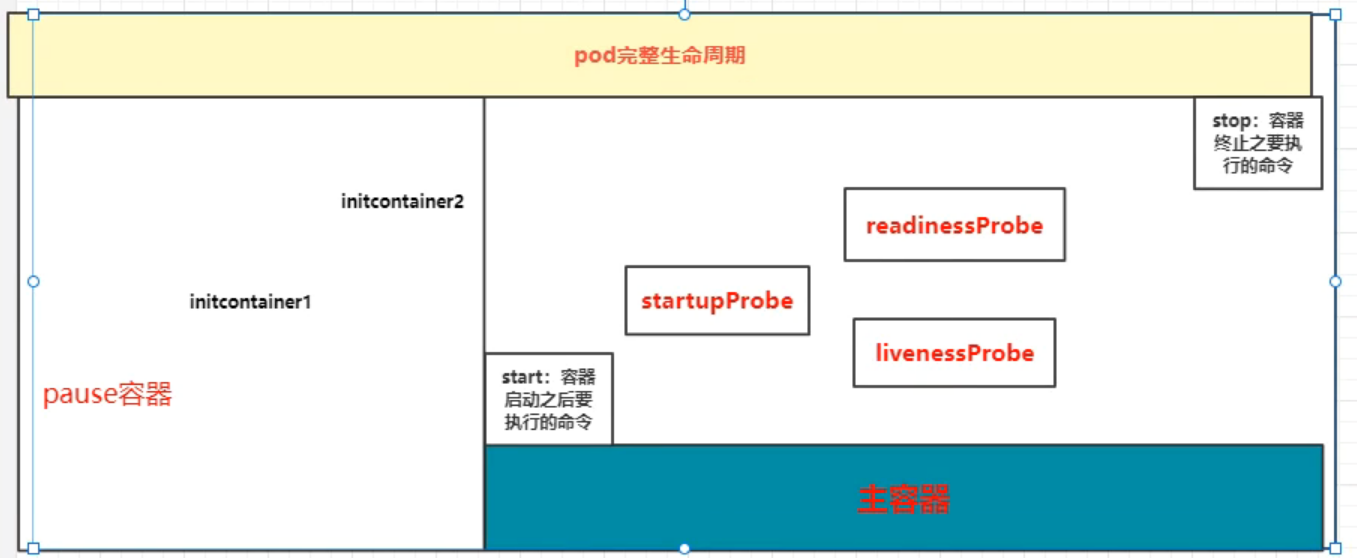
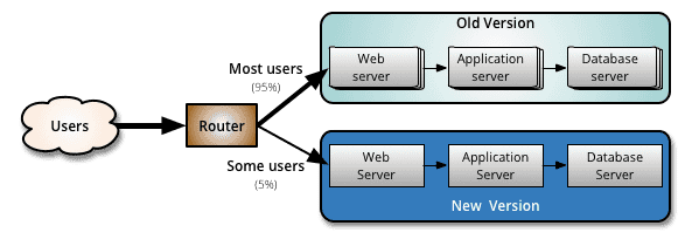

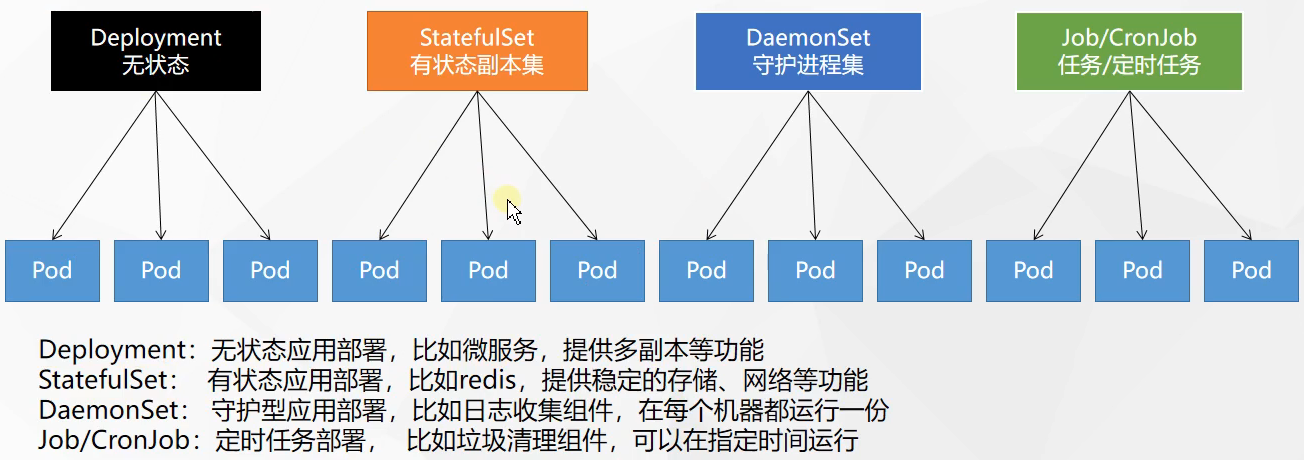
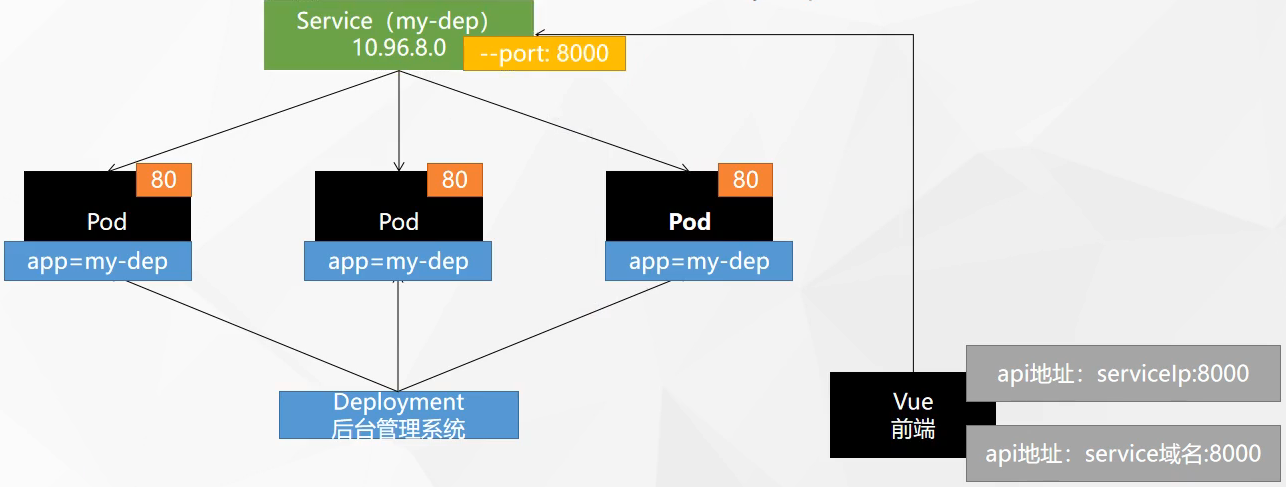
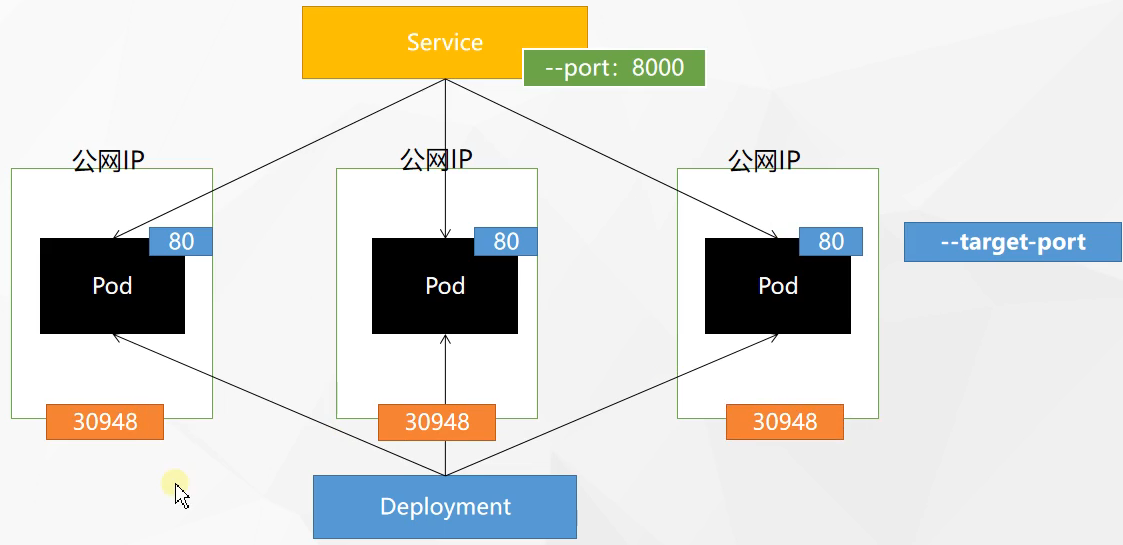
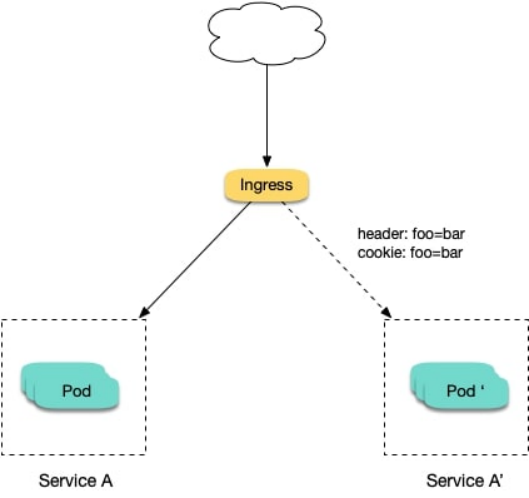
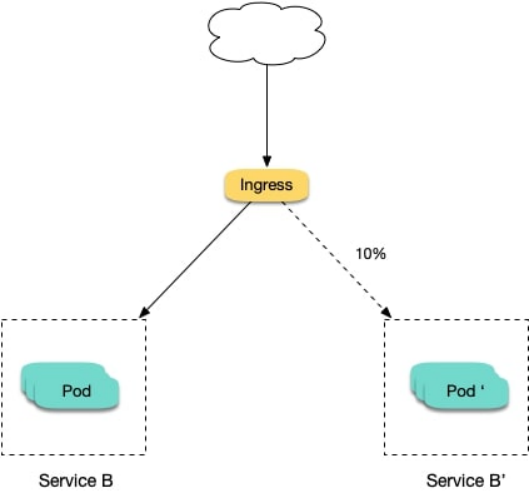
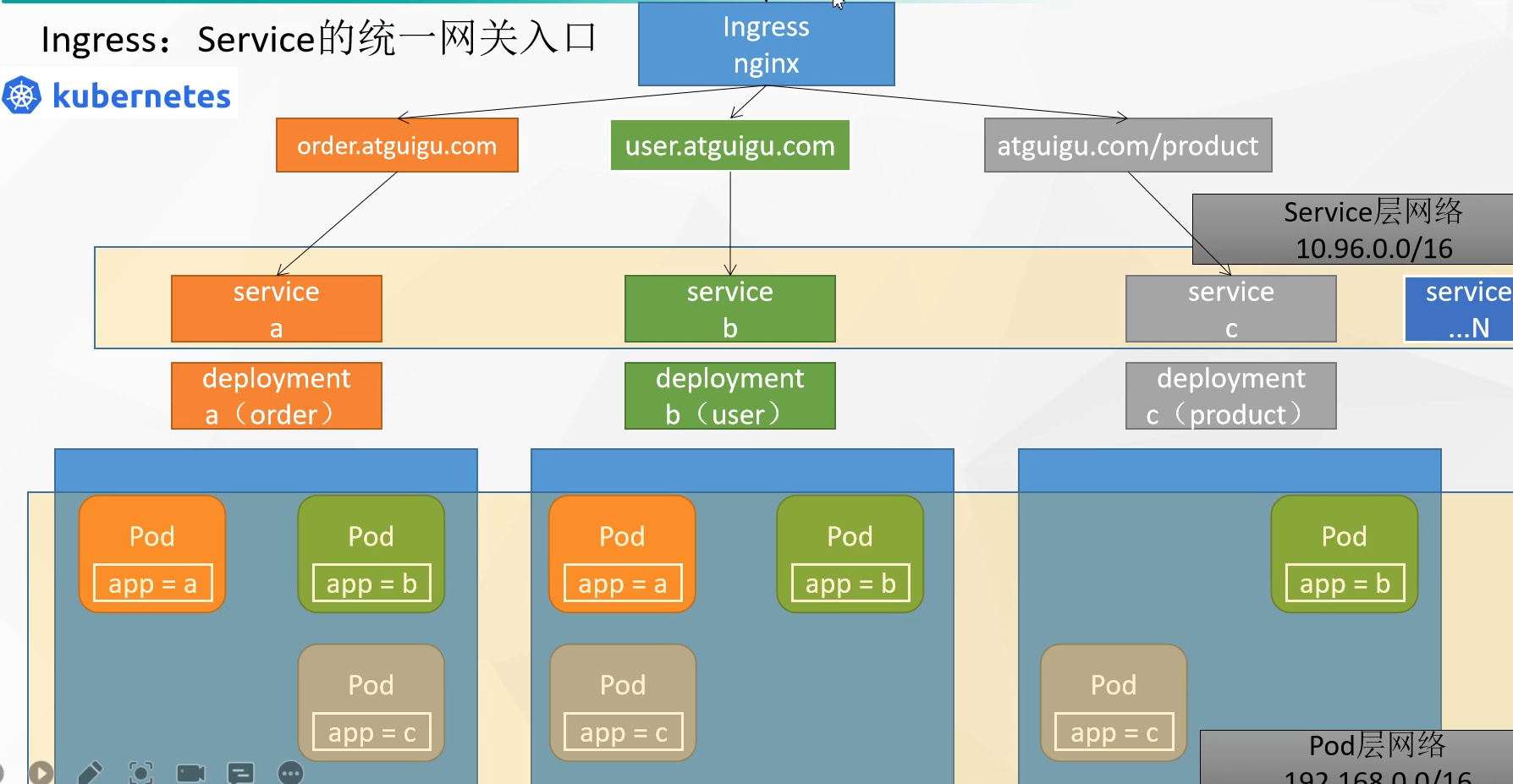
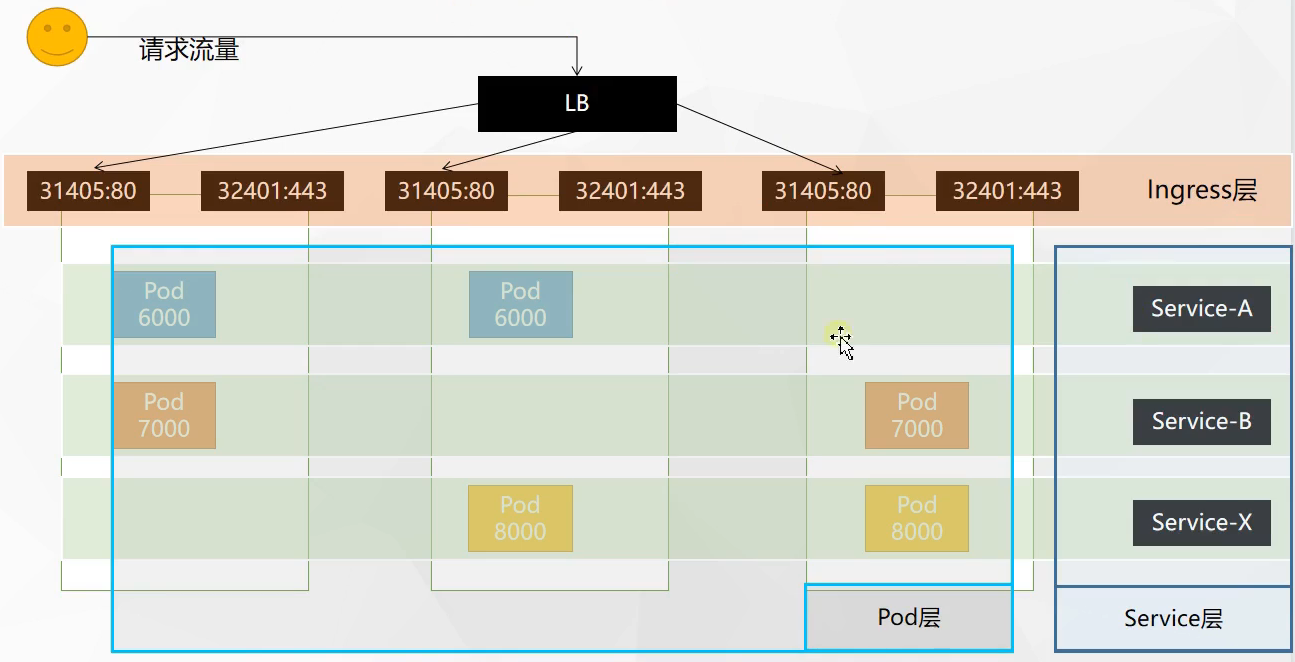
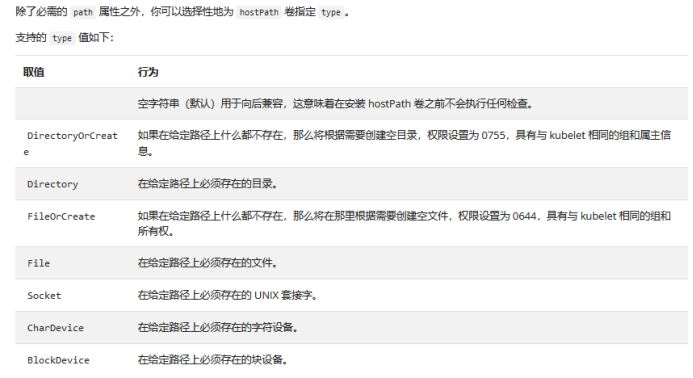
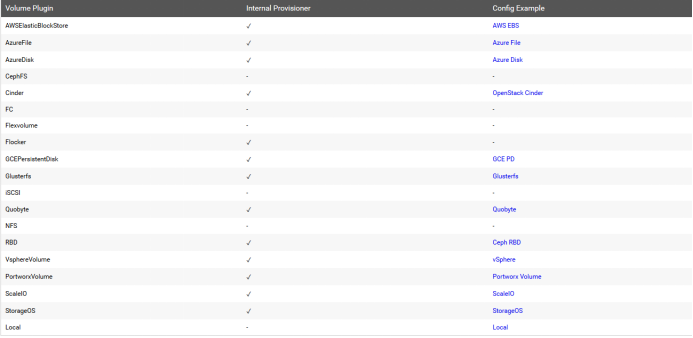
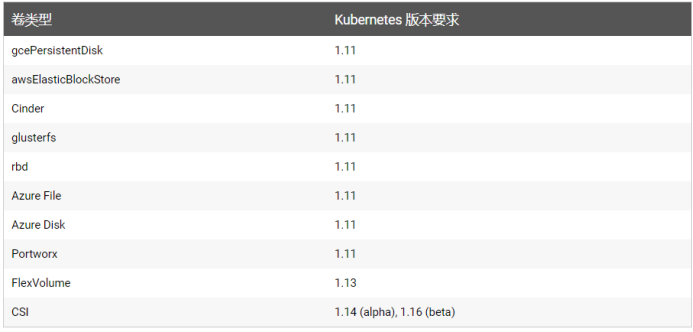
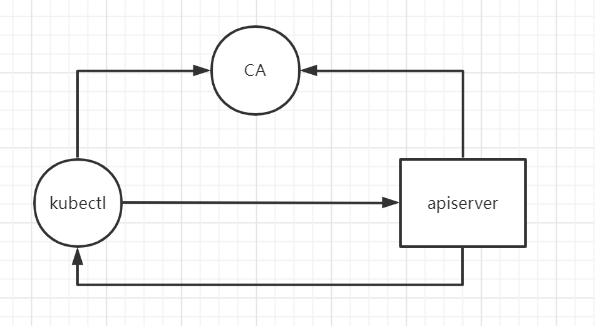
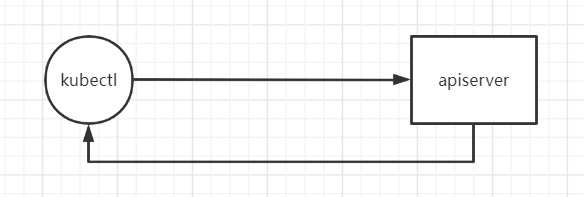
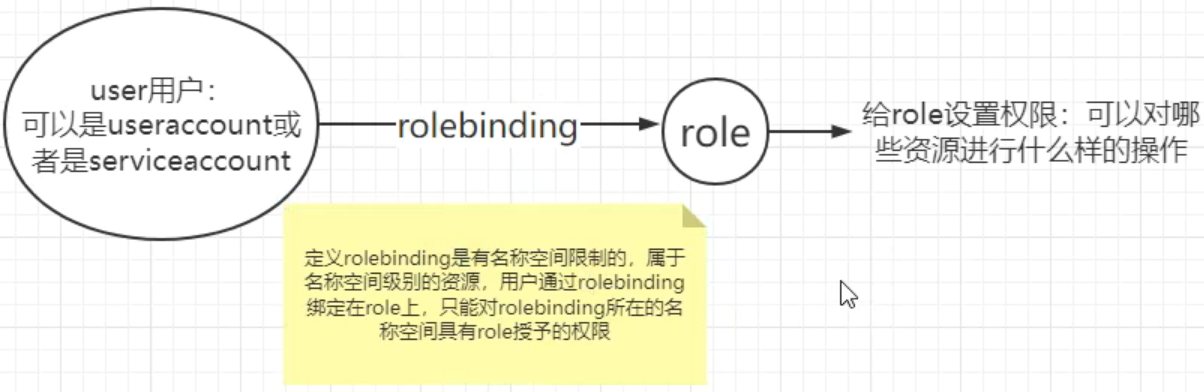
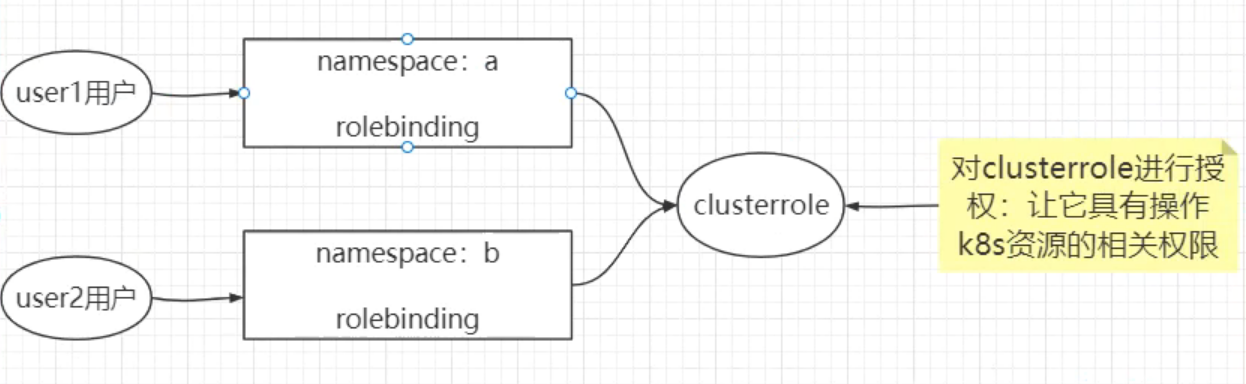

 ,选择编辑 YAML。
,选择编辑 YAML。