# k8s 高级# 环境配置1 2 3 4 5 docker load -i .tar.gz ctr -n=k8s.io images import .tar.gz ctr -n=k8s.io images pull docker.io/library/centos:latest docker save -o .tar.gz ctr -n=k8s.io import .tar.gz
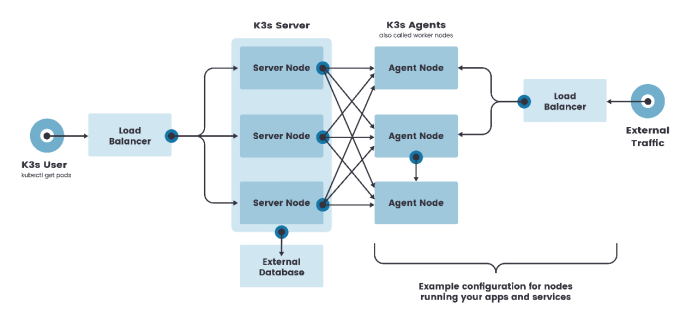
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 修改ip 配置主机名 配置hosts文件 配置免密登录 关闭交换分区 修改内核参数 关闭firewalld防火墙 关闭selinux 配置阿里云的安装docker的repo源 配置阿里云安装k8s的repo源 配置时间同步 开启ipvs 安装基础软件包 安装iptablese kubeadm join 192.168.13.180:6443 --token or2v2h.3vffzj49xx3yuvr6 \ --discovery-token-ca-cert-hash sha256:09c9428481b6f33c04537f0753472f38c16637b351123a1416e7771366ca837a 1.安装bash-completion工具 yum install bash-completion -y 否则报错: -bash: _get_comp_words_by_ref: command not found 2.执行bash_completion source /usr/share/bash-completion/bash_completion 3.加载kubectl completion source <(kubectl completion bash) # 在 bash 中设置当前 shell 的自动补全,要先安装 bash-completion 包。 echo "source <(kubectl completion bash)" >> ~/.bashrc # 在您的 bash shell 中永久的添加自动补全 您还可以为 kubectl 使用一个速记别名,该别名也可以与 completion 一起使用: cat >>/root/.bashrc<<EOF alias k=kubectl complete -F __start_kubectl k EOF source /root/.bashrc
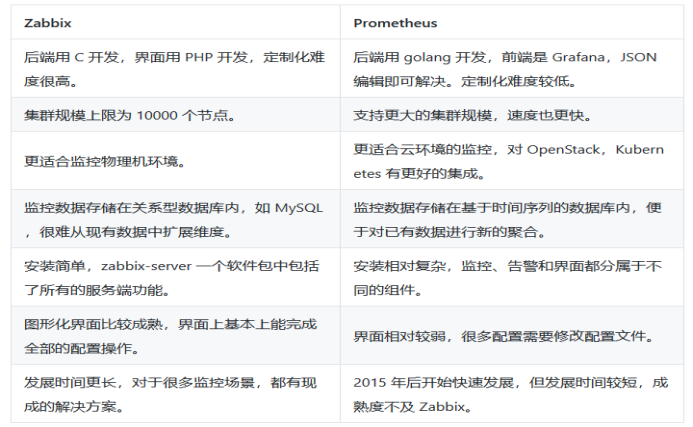
# Prometheus1 2 3 Prometheus是一个开源的系统监控和报警系统,现在已经加入到CNCF基金会,成为继k8s之后第二个在CNCF托管的项目,在kubernetes容器管理系统中,通常会搭配prometheus进行监控,同时也支持多种exporter采集数据,还支持pushgateway进行数据上报,Prometheus性能足够支撑上万台规模的集群。 zabbix,nagios,cattio
1 2 3 4 5 6 7 8 9 10 11 12 1.多维度数据模型 每一个时间序列数据都由metric度量指标名称和它的标签labels键值对集合唯一确定: 这个metric度量指标名称指定监控目标系统的测量特征(如:http_requests_total- 接收http请求的总计数)。labels开启了Prometheus的多维数据模型:对于相同的度量名称,通过不同标签列表的结合, 会形成特定的度量维度实例。(例如:所有包含度量名称为/api/tracks的http请求,打上method=POST的标签,则形成了具体的http请求)。这个查询语言在这些度量和标签列表的基础上进行过滤和聚合。改变任何度量上的任何标签值,则会形成新的时间序列图。 2.灵活的查询语言(PromQL) 可以对采集的metrics指标进行加法,乘法,连接等操作; 3.可以直接在本地部署,不依赖其他分布式存储; 4.通过基于HTTP的pull方式采集时序数据; 5.可以通过中间网关pushgateway的方式把时间序列数据推送到prometheus server端; 6.可通过服务发现或者静态配置来发现目标服务对象(targets)。 7.有多种可视化图像界面,如Grafana等。 8.高效的存储,每个采样数据占3.5 bytes左右,300万的时间序列,30s间隔,保留60天,消耗磁盘大概200G。 9.做高可用,可以对数据做异地备份,联邦集群,部署多套prometheus,pushgateway上报数据
1 2 3 4 5 6 7 8 9 10 11 样本 在时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成: 1、指标(metric):指标名称和描述当前样本特征的 labelsets; 2、时间戳(timestamp):一个精确到毫秒的时间戳; 3、样本值(value): 一个 folat64 的浮点型数据表示当前样本的值。 表示方式: 通过如下表达方式表示指定指标名称和指定标签集合的时间序列: <metric name>{<label name>=<label value>, ...} 例如,指标名称为 api_http_requests_total,标签为 method="POST" 和 handler="/messages" 的时间序列可以表示为: api_http_requests_total{method="POST", handler="/messages"}
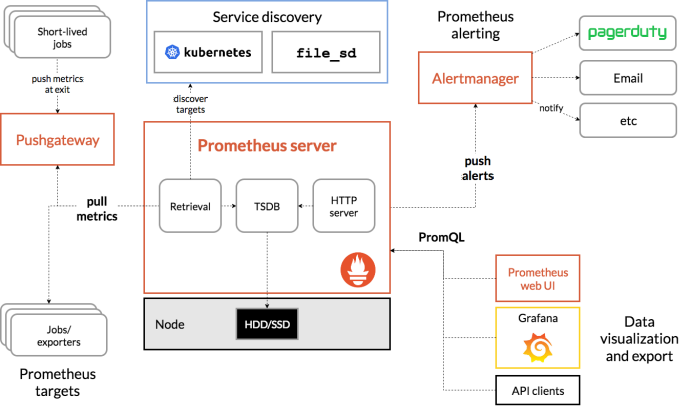
# 组件介绍1 2 3 4 5 6 7 1.Prometheus Server: 用于收集和存储时间序列数据。 2.Client Library: 客户端库,检测应用程序代码,当Prometheus抓取实例的HTTP端点时,客户端库会将所有跟踪的metrics指标的当前状态发送到prometheus server端。 3.Exporters: prometheus支持多种exporter,通过exporter可以采集metrics数据,然后发送到prometheus server端,所有向promtheus server提供监控数据的程序都可以被称为exporter 4.Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去重,分组,并路由到相应的接收方,发出报警,常见的接收方式有:电子邮件,微信,钉钉, slack等。 5.Grafana:监控仪表盘,可视化监控数据 6.pushgateway: 各个目标主机可上报数据到pushgateway,然后prometheus server统一从pushgateway拉取数据。
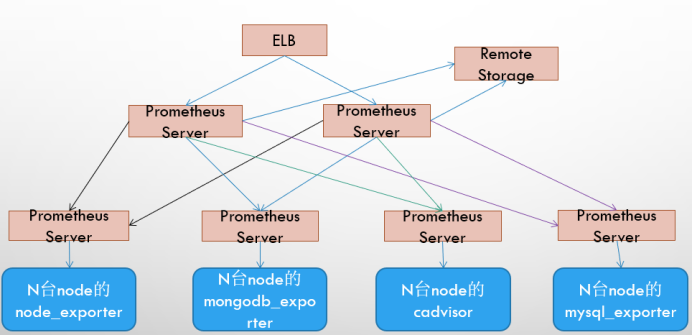
# 工作流程1.Prometheus server 可定期从活跃的(up)目标主机上(target)拉取监控指标数据,目标主机的监控数据可通过配置静态 job 或者服务发现的方式被 prometheus server 采集到,这种方式默认的 pull 方式拉取指标;也可通过 pushgateway 把采集的数据上报到 prometheus server 中;还可通过一些组件自带的 exporter 采集相应组件的数据;
2.Prometheus server 把采集到的监控指标数据保存到本地磁盘或者数据库;
3.Prometheus 采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发送到 alertmanager
4.Alertmanager 通过配置报警接收方,发送报警到邮件,微信或者钉钉等
5.Prometheus 自带的 web ui 界面提供 PromQL 查询语言,可查询监控数据
6.Grafana 可接入 prometheus 数据源,把监控数据以图形化形式展示出
# Prometheus 和 Zabbix 对比
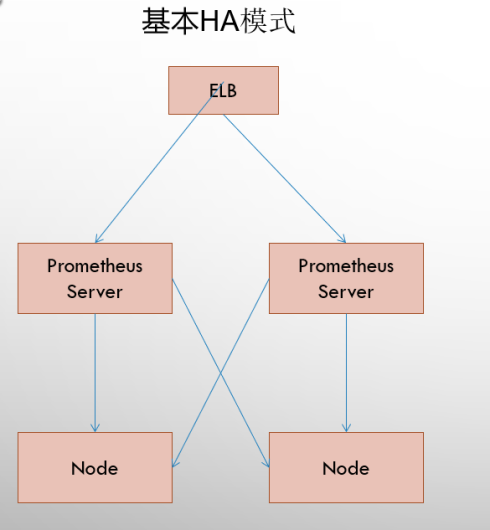
# 部署模式基本 HA
基本的 HA 模式只能确保 Promthues 服务的可用性问题,但是不解决 Prometheus Server 之间的数据一致性问题以及持久化问题 (数据丢失后无法恢复),也无法进行动态的扩展。因此这种部署方式适合监控规模不大,Promthues Server 也不会频繁发生迁移的情况,并且只需要保存短周期监控数据的场景。
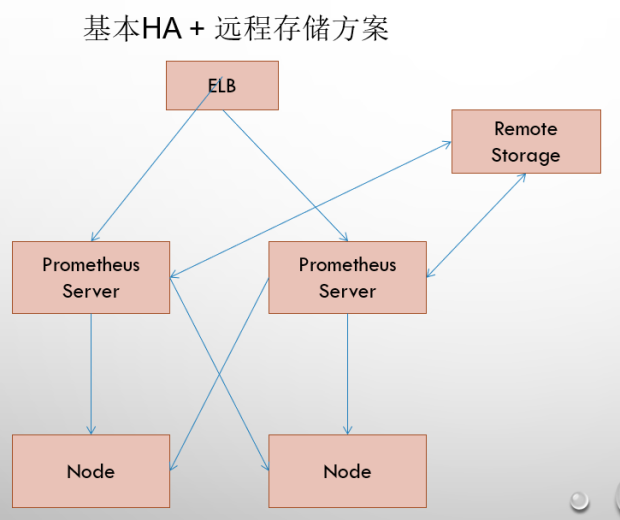
基本 HA + 远程存储
在解决了 Promthues 服务可用性的基础上,同时确保了数据的持久化,当 Promthues Server 发生宕机或者数据丢失的情况下,可以快速的恢复。 同时 Promthues Server 可能很好的进行迁移。因此,该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时能够确保 Promthues Server 的可迁移性的场景。
基本 HA + 远程存储 + 联邦集群
Promthues 的性能瓶颈主要在于大量的采集任务,因此用户需要利用 Prometheus 联邦集群的特性,将不同类型的采集任务划分到不同的 Promthues 子服务中,从而实现功能分区。例如一个 Promthues Server 负责采集基础设施相关的监控指标,另外一个 Prometheus Server 负责采集应用监控指标。再有上层 Prometheus Server 实现对数据的汇聚。
# 数据类型1 2 3 4 5 6 7 8 9 10 11 12 Counter是计数器类型: 1、Counter 用于累计值,例如记录请求次数、任务完成数、错误发生次数。 2、一直增加,不会减少。 3、重启进程后,会被重置。 例如:http_response_total{method="GET",endpoint="/api/tracks"} 100 http_response_total{method="GET",endpoint="/api/tracks"} 160 Counter 类型数据可以让用户方便的了解事件产生的速率的变化,在PromQL内置的相关操作函数可以提供相应的分析,比如以HTTP应用请求量来进行说明: 1、通过rate()函数获取HTTP请求量的增长率 rate(http_requests_total[5m]) 2、查询当前系统中,访问量前10的HTTP地址 topk(10, http_requests_total)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Gauge是测量器类型: 1、Gauge是常规数值,例如温度变化、内存使用变化。 2、可变大,可变小。 3、重启进程后,会被重置 例如: memory_usage_bytes{host="master-01"} 100 memory_usage_bytes{host="master-01"} 30 memory_usage_bytes{host="master-01"} 50 memory_usage_bytes{host="master-01"} 80 对于 Gauge 类型的监控指标,通过 PromQL 内置函数 delta() 可以获取样本在一段时间内的变化情况,例如,计算 CPU 温度在两小时内的差异: dalta(cpu_temp_celsius{host="zeus"}[2h]) 你还可以通过PromQL 内置函数 predict_linear() 基于简单线性回归的方式,对样本数据的变化趋势做出预测。例如,基于 2 小时的样本数据,来预测主机可用磁盘空间在 4 个小时之后的剩余情况: predict_linear(node_filesystem_free{job="node"}[2h], 4 * 3600) < 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 histogram是柱状图,在Prometheus系统的查询语言中,有三种作用: 1、在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中. 后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。 2、对每个采样点值累计和(sum) 3、对采样点的次数累计和(count) 度量指标名称: [basename]_上面三类的作用度量指标名称 1、[basename]_bucket{le="上边界"}, 这个值为小于等于上边界的所有采样点数量 2、[basename]_sum 3、[basename]_count 在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。 为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10ms 之间的请求数有多少,而 10~20ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram 和 Summary 都是为了能够解决这样问题的存在,通过 Histogram 和 Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。 Histogram 类型的样本会提供三种指标(假设指标名称为 <basename>): 样本的值分布在 bucket 中的数量,命名为 <basename>_bucket{le="<上边界>"}。解释的更通俗易懂一点,这个值表示指标值小于等于上边界的所有样本数量。 1、http 请求响应时间 <=0.005 秒 的请求次数为0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.005",} 0.0 2、http 请求响应时间 <=0.01 秒 的请求次数为0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.01",} 0.0 3、http 请求响应时间 <=0.025 秒 的请求次数为0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.025",} 0.0 所有样本值的大小总和,命名为 <basename>_sum。
1 2 3 4 5 6 7 8 9 10 11 summary 与 Histogram 类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算。它也有三种作用: 1、对于每个采样点进行统计,并形成分位图。(如:正态分布一样,统计低于60分不及格的同学比例,统计低于80分的同学比例,统计低于95分的同学比例) 2、统计班上所有同学的总成绩(sum) 3、统计班上同学的考试总人数(count) 样本值的分位数分布情况,命名为 <basename>{quantile="<φ>"}。 1、含义:http 请求中有 50% 的请求响应时间是 3.052404983s io_namespace_http_requests_latency_seconds_summary{path="/",method="GET",code="200",quantile="0.5",} 3.052404983 Histogram 需要通过 <basename>_bucket 来计算分位数,而 Summary 则直接存储了分位数的值。
1 2 3 4 5 6 7 Prometheus对kubernetes的监控 对于Kubernetes而言,我们可以把当中所有的资源分为几类: •基础设施层(Node):集群节点,为整个集群和应用提供运行时资源 •容器基础设施(Container):为应用提供运行时环境 •用户应用(Pod):Pod中会包含一组容器,它们一起工作,并且对外提供一个(或者一组)功能 •内部服务负载均衡(Service):在集群内,通过Service在集群暴露应用功能,集群内应用和应用之间访问时提供内部的负载均衡 •外部访问入口(Ingress):通过Ingress提供集群外的访问入口,从而可以使外部客户端能够访问到部署在Kubernetes集群内的服务
# node-exporter1 node-exporter可以采集机器(物理机、虚拟机、云主机等)的监控指标数据,能够采集到的指标包括CPU, 内存,磁盘,网络,文件数等信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 apiVersion: apps/v1 kind: DaemonSet metadata: name: node-exporter namespace: monitor-sa labels: name: node-exporter spec: selector: matchLabels: name: node-exporter template: metadata: labels: name: node-exporter spec: hostPID: true hostIPC: true hostNetwork: true containers: - name: node-exporter image: prom/node-exporter:latest imagePullPolicy: IfNotPresent ports: - containerPort: 9100 resources: requests: cpu: 0.15 securityContext: privileged: true args: - --path.procfs - /host/proc - --path.sysfs - /host/sys - --collector.filesystem.ignored-mount-points - '"^/(sys|proc|dev|host|etc)($|/)"' volumeMounts: - name: dev mountPath: /host/dev - name: proc mountPath: /host/proc - name: sys mountPath: /host/sys - name: rootfs mountPath: /rootfs tolerations: - key: "node-role.kubernetes.io/master" operator: "Exists" effect: "NoSchedule" volumes: - name: proc hostPath: path: /proc - name: dev hostPath: path: /dev - name: sys hostPath: path: /sys - name: rootfs hostPath: path: /1 curl 192.168 .13 .180 :9100/metrics curl 192.168 .13 .180 :9100/metrics | grep node_cpu_seconds % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0 node_cpu_seconds_total{cpu="0",mode="idle"} 14492.66 node_cpu_seconds_total{cpu="0",mode="iowait"} 19.3 node_cpu_seconds_total{cpu="0",mode="irq"} 0 node_cpu_seconds_total{cpu="0",mode="nice"} 0.48 node_cpu_seconds_total{cpu="0",mode="softirq"} 28.25
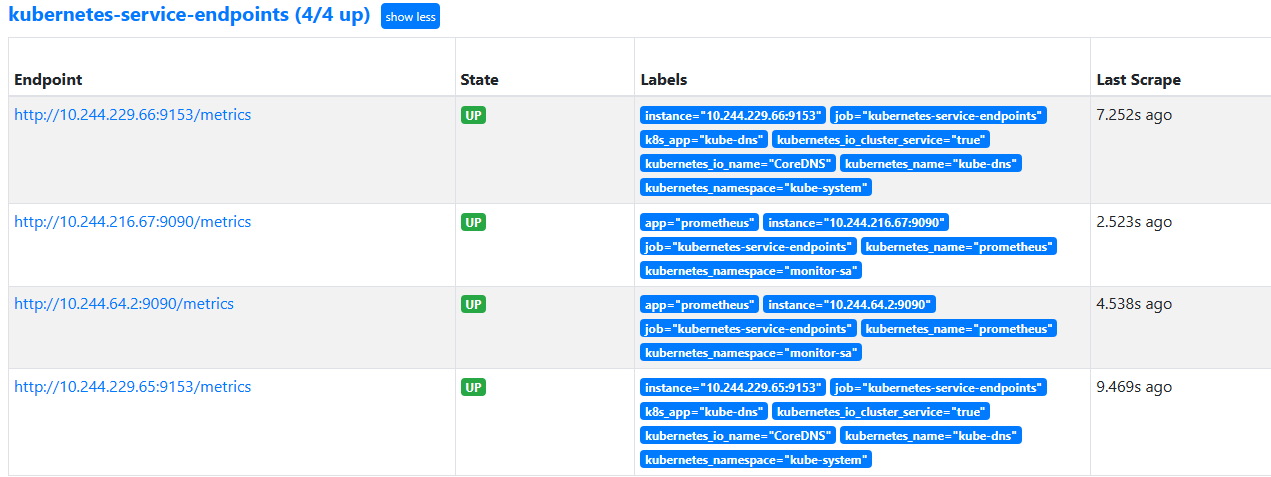
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 kubectl create serviceaccount monitor -n monitor-sa kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor kubectl create clusterrolebinding monitor-clusterrolebinding-1 -n monitor-sa --clusterrole=cluster-admin --user=system:serviceaccount:monitor:monitor-sa [root@prometheus-master ~ ] [root@prometheus-master ~ ] --- kind: ConfigMap apiVersion: v1 metadata: labels: app: prometheus name: prometheus-config namespace: monitor-sa data: prometheus.yml: | global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 1m scrape_configs: - job_name: 'kubernetes-node' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-node-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name
# 部署 Prothemeus1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 --- apiVersion: apps/v1 kind: Deployment metadata: name: prometheus-server namespace: monitor-sa labels: app: prometheus spec: replicas: 2 selector: matchLabels: app: prometheus component: server template: metadata: labels: app: prometheus component: server annotations: prometheus.io/scrape: 'false' spec: serviceAccountName: monitor containers: - name: prometheus image: prom/prometheus imagePullPolicy: IfNotPresent command: - prometheus - --config.file=/etc/prometheus/prometheus.yml - --storage.tsdb.path=/prometheus - --storage.tsdb.retention=720h - --web.enable-lifecycle ports: - containerPort: 9090 protocol: TCP volumeMounts: - mountPath: /etc/prometheus name: prometheus-config - mountPath: /prometheus/ name: prometheus-storage-volume volumes: - name: prometheus-config configMap: name: prometheus-config - name: prometheus-storage-volume hostPath: path: /data type: Directory [root@prometheus-master prome ] /prometheus $ cd /etc/prometheus/ /etc/prometheus $ ls prometheus.yml --- apiVersion: v1 kind: Service metadata: name: prometheus namespace: monitor-sa labels: app: prometheus spec: type: NodePort ports: - port: 9090 targetPort: 9090 protocol: TCP selector: app: prometheus component: server --- apiVersion: v1 kind: Service metadata: name: prometheus namespace: monitor-sa labels: app: prometheus annotations: prometheus.io/scrape: "true"
# Prothemeus 热加载1 2 3 4 5 6 7 8 9 10 curl -X POST http://pod-ip:9090/-/reload kubectl delete -f prometheus-cfg.yaml kubectl delete -f prometheus-deploy.yaml 然后再通过apply更新: kubectl apply -f prometheus-cfg.yaml kubectl apply -f prometheus-deploy.yaml 注意: 线上最好热加载,暴力删除可能造成监控数据的丢失
# GrafanaGrafana 是一个跨平台的开源的度量分析和可视化工具,可以将采集的数据可视化的展示,并及时通知给告警接收方。它主要有以下六大特点:
1、展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
2、数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch 和 KairosDB 等;
3、通知提醒:以可视方式定义最重要指标的警报规则,Grafana 将不断计算并发送通知,在数据达到阈值时通过 Slack、PagerDuty 等获得通知;
4、混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
5、注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记
# 安装 Grafana1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 apiVersion: apps/v1 kind: Deployment metadata: name: monitoring-grafana namespace: kube-system spec: replicas: 1 selector: matchLabels: task: monitoring k8s-app: grafana template: metadata: labels: task: monitoring k8s-app: grafana spec: containers: - name: grafana image: k8s.gcr.io/heapster-grafana-amd64:v5.0.4 imagePullPolicy: IfNotPresent ports: - containerPort: 3000 protocol: TCP volumeMounts: - mountPath: /etc/ssl/certs name: ca-certificates readOnly: true - mountPath: /var name: grafana-storage env: - name: INFLUXDB_HOST value: monitoring-influxdb - name: GF_SERVER_HTTP_PORT value: "3000" # The following env variables are required to make Grafana accessible via # the kubernetes api-server proxy. On production clusters, we recommend # removing these env variables, setup auth for grafana, and expose the grafana # service using a LoadBalancer or a public IP. - name: GF_AUTH_BASIC_ENABLED value: "false" - name: GF_AUTH_ANONYMOUS_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ORG_ROLE value: Admin - name: GF_SERVER_ROOT_URL # If you're only using the API Server proxy, set this value instead: # value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy value: / volumes: - name: ca-certificates hostPath: path: /etc/ssl/certs - name: grafana-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-grafana name: monitoring-grafana namespace: kube-system spec: # In a production setup, we recommend accessing Grafana through an external Loadbalancer # or through a public IP. # type: LoadBalancer # You could also use NodePort to expose the service at a randomly-generated port # type: NodePort ports: - port: 80 targetPort: 3000 selector: k8s-app: grafana type: NodePort
将其中的 container_last_seen 放到 Prometheus 中 query,如果显示 nodata 说明没有这项监控
# kube-metric1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 --- apiVersion: v1 kind: ServiceAccount metadata: name: kube-state-metrics namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: kube-state-metrics rules: - apiGroups: [""] resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"] verbs: ["list", "watch"] - apiGroups: ["extensions"] resources: ["daemonsets", "deployments", "replicasets"] verbs: ["list", "watch"] - apiGroups: ["apps"] resources: ["statefulsets"] verbs: ["list", "watch"] - apiGroups: ["batch"] resources: ["cronjobs", "jobs"] verbs: ["list", "watch"] - apiGroups: ["autoscaling"] resources: ["horizontalpodautoscalers"] verbs: ["list", "watch"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: kube-state-metrics roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kube-state-metrics subjects: - kind: ServiceAccount name: kube-state-metrics namespace: kube-system apiVersion: apps/v1 kind: Deployment metadata: name: kube-state-metrics namespace: kube-system spec: replicas: 1 selector: matchLabels: app: kube-state-metrics template: metadata: labels: app: kube-state-metrics spec: serviceAccountName: kube-state-metrics containers: - name: kube-state-metrics image: quay.io/coreos/kube-state-metrics:v1.9.0 imagePullPolicy: IfNotPresent ports: - containerPort: 8080 apiVersion: v1 kind: Service metadata: annotations: prometheus.io/scrape: 'true' name: kube-state-metrics namespace: kube-system labels: app: kube-state-metrics spec: ports: - name: kube-state-metrics port: 8080 protocol: TCP selector: app: kube-state-metrics 导入json https://grafana.com/grafana/dashboards/?search=kubernetes
# alert manager# 报警到 qq 邮箱WYCMUCTTXLOBSVYS
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 kind: ConfigMap kind: ConfigMap apiVersion: v1 metadata: name: alertmanager namespace: monitor-sa data: alertmanager.yml: |- global: resolve_timeout: 1m smtp_smarthost: 'smtp.163.com:25' smtp_from: 'kbshire@163.com' smtp_auth_username: 'kbshire@163.com' smtp_auth_password: 'WYCMUCTTXLOBSVYS' smtp_require_tls: false route: #用于配置告警分发策略 group_by: [alertname] # 采用哪个标签来作为分组依据 group_wait: 10s # 组告警等待时间。也就是告警产生后等待10s,如果有同组告警一起发出 group_interval: 10s # 上下两组发送告警的间隔时间 repeat_interval: 10m # 重复发送告警的时间,减少相同邮件的发送频率,默认是1h receiver: default-receiver #定义谁来收告警 receivers: - name: 'default-receiver' email_configs: - to: '183108913@qq.com'
1 2 3 4 5 6 7 8 9 10 报警处理流程如下: 1. Prometheus Server监控目标主机上暴露的http接口(这里假设接口A),通过Promethes配置的'scrape_interval'定义的时间间隔,定期采集目标主机上监控数据。 2. 当接口A不可用的时候,Server端会持续的尝试从接口中取数据,直到"scrape_timeout"时间后停止尝试。这时候把接口的状态变为“DOWN”。 3. Prometheus同时根据配置的"evaluation_interval"的时间间隔,定期(默认1min)的对Alert Rule进行评估;当到达评估周期的时候,发现接口A为DOWN,即UP=0为真,激活Alert,进入“PENDING”状态,并记录当前active的时间; 4. 当下一个alert rule的评估周期到来的时候,发现UP=0继续为真,然后判断警报Active的时间是否已经超出rule里的‘for’ 持续时间,如果未超出,则进入下一个评估周期;如果时间超出,则alert的状态变为“FIRING”;同时调用Alertmanager接口,发送相关报警数据。 5. AlertManager收到报警数据后,会将警报信息进行分组,然后根据alertmanager配置的“group_wait”时间先进行等待。等wait时间过后再发送报警信息。 6. 属于同一个Alert Group的警报,在等待的过程中可能进入新的alert,如果之前的报警已经成功发出,那么间隔“group_interval”的时间间隔后再重新发送报警信息。比如配置的是邮件报警,那么同属一个group的报警信息会汇总在一个邮件里进行发送。 7. 如果Alert Group里的警报一直没发生变化并且已经成功发送,等待‘repeat_interval’时间间隔之后再重复发送相同的报警邮件;如果之前的警报没有成功发送,则相当于触发第6条条件,则需要等待group_interval时间间隔后重复发送。 同时最后至于警报信息具体发给谁,满足什么样的条件下指定警报接收人,设置不同报警发送频率,这里有alertmanager的route路由规则进行配置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 kind: ConfigMap apiVersion: v1 metadata: labels: app: prometheus name: prometheus-config namespace: monitor-sa data: prometheus.yml: | rule_files: - /etc/prometheus/rules.yml alerting: alertmanagers: - static_configs: - targets: ["localhost:9093"] global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 1m scrape_configs: - job_name: 'kubernetes-node' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-node-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name - job_name: 'kubernetes-pods' kubernetes_sd_configs: - role: pod relabel_configs: - action: keep regex: true source_labels: - __meta_kubernetes_pod_annotation_prometheus_io_scrape - action: replace regex: (.+) source_labels: - __meta_kubernetes_pod_annotation_prometheus_io_path target_label: __metrics_path__ - action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 source_labels: - __address__ - __meta_kubernetes_pod_annotation_prometheus_io_port target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - action: replace source_labels: - __meta_kubernetes_namespace target_label: kubernetes_namespace - action: replace source_labels: - __meta_kubernetes_pod_name target_label: kubernetes_pod_name - job_name: 'kubernetes-etcd' scheme: https tls_config: ca_file: /etc/kubernetes/pki/etcd/ca.crt cert_file: /etc/kubernetes/pki/etcd/server.crt key_file: /etc/kubernetes/pki/etcd/server.key scrape_interval: 5s static_configs: - targets: ['192.168.13.180:2379'] rules.yml: | groups: - name: example rules: - alert: apiserver的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: apiserver的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: etcd的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: etcd的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: kube-state-metrics的cpu使用率大于80% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%" value: "{{ $value }}%" threshold: "80%" - alert: kube-state-metrics的cpu使用率大于90% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%" value: "{{ $value }}%" threshold: "90%" - alert: coredns的cpu使用率大于80% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%" value: "{{ $value }}%" threshold: "80%" - alert: coredns的cpu使用率大于90% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%" value: "{{ $value }}%" threshold: "90%" - alert: kube-proxy打开句柄数>600 expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kube-proxy打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-schedule打开句柄数>600 expr: process_open_fds{job=~"kubernetes-schedule"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-schedule打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-schedule"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-controller-manager打开句柄数>600 expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-controller-manager打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-apiserver打开句柄数>600 expr: process_open_fds{job=~"kubernetes-apiserver"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-apiserver打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-etcd打开句柄数>600 expr: process_open_fds{job=~"kubernetes-etcd"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-etcd打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-etcd"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: coredns expr: process_open_fds{k8s_app=~"kube-dns"} > 600 for: 2s labels: severity: warnning annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600" value: "{{ $value }}" - alert: coredns expr: process_open_fds{k8s_app=~"kube-dns"} > 1000 for: 2s labels: severity: critical annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000" value: "{{ $value }}" - alert: kube-proxy expr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: scheduler expr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kubernetes-controller-manager expr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kubernetes-apiserver expr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kubernetes-etcd expr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kube-dns expr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: HttpRequestsAvg expr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000" value: "{{ $value }}" threshold: "1000" - alert: Pod_restarts expr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0 for: 2s labels: severity: warnning annotations: description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的" value: "{{ $value }}" threshold: "0" - alert: Pod_waiting expr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中" value: "{{ $value }}" threshold: "1" - alert: Pod_terminated expr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除" value: "{{ $value }}" threshold: "1" - alert: Etcd_leader expr: etcd_server_has_leader{job="kubernetes-etcd"} == 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader" value: "{{ $value }}" threshold: "0" - alert: Etcd_leader_changes expr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变" value: "{{ $value }}" threshold: "0" - alert: Etcd_failed expr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败" value: "{{ $value }}" threshold: "0" - alert: Etcd_db_total_size expr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G" value: "{{ $value }}" threshold: "10G" - alert: Endpoint_ready expr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用" value: "{{ $value }}" threshold: "1" - name: 物理节点状态-监控告警 rules: - alert: 物理节点cpu使用率 expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90 for: 2s labels: severity: ccritical annotations: summary: "{{ $labels.instance }}cpu使用率过高" description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: 物理节点内存使用率 expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90 for: 2s labels: severity: critical annotations: summary: "{{ $labels.instance }}内存使用率过高" description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: InstanceDown expr: up == 0 for: 2s labels: severity: critical annotations: summary: "{{ $labels.instance }}: 服务器宕机" description: "{{ $labels.instance }}: 服务器延时超过2分钟" - alert: 物理节点磁盘的IO性能 expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!" description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})" - alert: 入网流量带宽 expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 流入网络带宽过高!" description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}" - alert: 出网流量带宽 expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 流出网络带宽过高!" description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}" - alert: TCP会话 expr: node_netstat_Tcp_CurrEstab > 1000 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!" description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)" - alert: 磁盘容量 expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!" description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
1 kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 --- apiVersion: apps/v1 kind: Deployment metadata: name: prometheus-server namespace: monitor-sa labels: app: prometheus spec: replicas: 1 selector: matchLabels: app: prometheus component: server template: metadata: labels: app: prometheus component: server annotations: prometheus.io/scrape: 'false' spec: serviceAccountName: monitor containers: - name: prometheus image: prom/prometheus imagePullPolicy: IfNotPresent command: - "/bin/prometheus" args: - "--config.file=/etc/prometheus/prometheus.yml" - "--storage.tsdb.path=/prometheus" - "--storage.tsdb.retention=24h" - "--web.enable-lifecycle" ports: - containerPort: 9090 protocol: TCP volumeMounts: - mountPath: /etc/prometheus name: prometheus-config - mountPath: /prometheus/ name: prometheus-storage-volume - name: k8s-certs mountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ - name: alertmanager image: prom/alertmanager imagePullPolicy: IfNotPresent args: - "--config.file=/etc/alertmanager/alertmanager.yml" - "--log.level=debug" ports: - containerPort: 9093 protocol: TCP name: alertmanager volumeMounts: - name: alertmanager-config mountPath: /etc/alertmanager - name: alertmanager-storage mountPath: /alertmanager - name: localtime mountPath: /etc/localtime volumes: - name: prometheus-config configMap: name: prometheus-config - name: prometheus-storage-volume hostPath: path: /data type: Directory - name: k8s-certs secret: secretName: etcd-certs - name: alertmanager-config configMap: name: alertmanager - name: alertmanager-storage hostPath: path: /data/alertmanager type: DirectoryOrCreate - name: localtime hostPath: path: /usr/share/zoneinfo/Asia/Shanghai
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 --- apiVersion: v1 kind: Service metadata: labels: name: prometheus kubernetes.io/cluster-service: 'true' name: alertmanager namespace: monitor-sa spec: ports: - name: alertmanager nodePort: 30066 port: 9093 protocol: TCP targetPort: 9093 selector: app: prometheus sessionAffinity: None type: NodePort
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 receivers: - name: 'prometheus' wechat_configs: - corp_id: wwa82df90a693abb15 to_user: '@all' agent_id: 1000003 api_secret: Ov5SWq_JqrolsOj6dD4Jg9qaMu1TTaDzVTCrXHcjlFs receivers: - name: cluster1 webhook_configs: - url: 'http://192.168.40.180:8060/dingtalk/cluster1/send' send_resolved: true
# PromQL 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 PromQL(Prometheus Query Language)是 Prometheus 自己开发的表达式语言,语言表现力很丰富,内置函数也很多。使用它可以对时序数据进行筛选和聚合。 PromQL 表达式计算出来的值有以下几种类型: 瞬时向量 (Instant vector): 一组时序,每个时序只有一个采样值 区间向量 (Range vector): 一组时序,每个时序包含一段时间内的多个采样值 标量数据 (Scalar): 一个浮点数 字符串 (String): 一个字符串,暂时未用 瞬时向量选择器用来选择一组时序在某个采样点的采样值。 最简单的情况就是指定一个度量指标,选择出所有属于该度量指标的时序的当前采样值。 可以通过在后面添加用大括号包围起来的一组标签键值对来对时序进行过滤。比如下面的表达式筛选出了 job 为 kubernetes-apiservers,并且 resource为 pod的时序:apiserver_request_total apiserver_request_total{job="kubernetes-apiserver",resource="pods"} 匹配标签值时可以是等于,也可以使用正则表达式。总共有下面几种匹配操作符: =:完全相等 != : 不相等 =~: 正则表达式匹配 !~ : 正则表达式不匹配 下面的表达式筛选出了container是kube-scheduler或kube-proxy或kube-apiserver的时序数据 container_processes{container=~"kube-scheduler|kube-proxy|kube-apiserver"} 区间向量选择器类似于瞬时向量选择器,不同的是它选择的是过去一段时间的采样值。可以通过在瞬时向量选择器后面添加包含在 [] 里的时长来得到区间向量选择器。比如下面的表达式选出了所有度量指标为apiserver_request_total且resource是pod的时序在过去1 分钟的采样值。 apiserver_request_total{job="kubernetes-apiserver",resource="pods"}[1m] 这个不支持Graph,需要选择Console,才会看到采集的数据 说明:时长的单位可以是下面几种之一: s:seconds m:minutes h:hours d:days w:weeks y:years 偏移向量选择器 前面介绍的选择器默认都是以当前时间为基准时间,偏移修饰器用来调整基准时间,使其往前偏移一段时间。偏移修饰器紧跟在选择器后面,使用 offset 来指定要偏移的量。比如下面的表达式选择度量名称为apiserver_request_total的所有时序在 5 分钟前的采样值。 apiserver_request_total{job="kubernetes-apiserver",resource="pods"} offset 5m 下面的表达式选择apiserver_request_total 度量指标在 1 周前的这个时间点过去 5 分钟的采样值。 apiserver_request_total{job="kubernetes-apiserver",resource="pods"} [5m ] offset 1w 聚合操作符 PromQL 的聚合操作符用来将向量里的元素聚合得更少。总共有下面这些聚合操作符: sum:求和 min:最小值 max:最大值 avg:平均值 stddev:标准差 stdvar:方差 count:元素个数 count_values:等于某值的元素个数 bottomk:最小的 k 个元素 topk:最大的 k 个元素 quantile:分位数 计算haha节点所有容器总计内存 sum(container_memory_usage_bytes{instance=~"haha"})/1024/1024/1024 计算haha节点最近1m所有容器cpu使用率 sum (rate (container_cpu_usage_seconds_total{instance=~"haha"}[1m])) / sum (machine_cpu_cores{ instance =~"haha"}) * 100 计算最近1m所有容器cpu使用率 sum (rate (container_cpu_usage_seconds_total{id!="/"}[1m])) by (id) 函数 Prometheus 内置了一些函数来辅助计算,下面介绍一些典型的。 abs():绝对值 sqrt():平方根 exp():指数计算 ln():自然对数 ceil():向上取整 floor():向下取整 round():四舍五入取整 delta():计算区间向量里每一个时序第一个和最后一个的差值 sort():排序
# prometheus 监控 tomcatnlighten/tomcat_exporter: A Prometheus exporter for Apache Tomcat (github.com)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 下面在k8s-master节点操作 (1)制作tomcat镜像,按如下步骤 mkdir /root/tomcat_image 把上面的war包和jar包传到这个目录下 cat Dockerfile FROM tomcat:8.5-jdk8-corretto ADD metrics.war /usr/local/tomcat/webapps/ ADD simpleclient-0.8.0.jar /usr/local/tomcat/lib/ ADD simpleclient_common-0.8.0.jar /usr/local/tomcat/lib/ ADD simpleclient_hotspot-0.8.0.jar /usr/local/tomcat/lib/ ADD simpleclient_servlet-0.8.0.jar /usr/local/tomcat/lib/ ADD tomcat_exporter_client-0.0.12.jar /usr/local/tomcat/lib/ docker build -t='/tomcat_prometheus:v1' . docker login username:xianchao password:1989317** docker push xianchao/tomcat_prometheus:v1 #上传镜像到hub仓库 docker pull xianchao/tomcat_prometheus:v1 #在k8s的node节点拉取镜像拉取镜像 (2)基于上面的镜像创建一个tomcat实例 cat deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: tomcat-deployment namespace: default spec: selector: matchLabels: app: tomcat replicas: 2 # tells deployment to run 2 pods matching the template template: # create pods using pod definition in this template metadata: labels: app: tomcat annotations: prometheus.io/scrape: 'true' spec: containers: - name: tomcat image: xianchao/tomcat_prometheus:v1 ports: - containerPort: 8080 securityContext: privileged: true kubectl apply -f deploy.yaml 创建一个service,可操作也可不操作 cat tomcat-service.yaml kind: Service #service 类型 apiVersion: v1 metadata: # annotations: # prometheus.io/scrape: 'true' name: tomcat-service spec: selector: app: tomcat ports: - nodePort: 31360 port: 80 protocol: TCP targetPort: 8080 type: NodePort kubectl apply -f tomcat-service.yaml
# prometheus 监控 redis1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 cat redis.yaml apiVersion: apps/v1 kind: Deployment metadata: name: redis namespace: kube-system spec: replicas: 1 selector: matchLabels: app: redis template: metadata: labels: app: redis spec: containers: - name: redis image: redis:4 resources: requests: cpu: 100m memory: 100Mi ports: - containerPort: 6379 - name: redis-exporter image: oliver006/redis_exporter:latest resources: requests: cpu: 100m memory: 100Mi ports: - containerPort: 9121 --- kind: Service apiVersion: v1 metadata: name: redis namespace: kube-system annotations: prometheus.io/scrape: "true" prometheus.io/port: "9121" spec: selector: app: redis ports: - name: redis port: 6379 targetPort: 6379 - name: prom port: 9121 targetPort: 9121 kubectl apply -f redis.yaml redis 这个 Pod 中包含了两个容器,一个就是 redis 本身的主应用,另外一个容器就是 redis_exporter 由于Redis服务的metrics接口在redis-exporter 9121 上,所以我们添加了prometheus.io/port=9121这样的annotation,在prometheus就会自动发现redis了 接下来我们刷新一下Redis的Service配置 [root@abcdocker prometheus ]
# prometheus 监控 mysql1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 yum install mysql -y yum install mariadb -y tar -xvf mysqld_exporter-0.10.0.linux-amd64.tar.gz cd mysqld_exporter-0.10.0.linux-amd64 cp -ar mysqld_exporter /usr/local/bin/ chmod +x /usr/local/bin/mysqld_exporter 2 .登陆mysql为mysql_exporter创建账号并授权 mysql> CREATE USER 'mysql_exporter' @'localhost' IDENTIFIED BY 'Abcdef123!.' ; mysql> GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'mysql_exporter' @'localhost'; 3 .创建mysql配置文件、运行时可免密码连接数据库: cd mysqld_exporter-0.10.0.linux-amd64 cat my.cnf [client ] user=mysql_exporter password=Abcdef123!. nohup ./mysqld_exporter --config.my-cnf=./my.cnf & 5 .修改prometheus-alertmanager-cfg.yaml文件,添加如下 - job_name: 'mysql' static_configs: - targets: ['192.168.40.180:9104' ] kubectl apply -f prometheus-alertmanager-cfg.yaml kubectl delete -f prometheus-alertmanager-deploy.yaml kubectl apply -f prometheus-alertmanager-deploy.yaml
# Prothemeus 监控 nginx1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 unzip nginx-module-vts-master.zip mv nginx-module-vts-master /usr/local/ tar zxvf nginx-1.15.7.tar.gz cd nginx-1.15.7 ./configure --prefix=/usr/local/nginx --with-http_gzip_static_module --with-http_stub_status_module --with-http_ssl_module --with-pcre --with-file-aio --with-http_realip_module --add-module=/usr/local/nginx-module-vts-master make && make install 修改nginx配置文件: vim /usr/local/nginx/conf/nginx.conf server下添加如下: location /status { vhost_traffic_status_display; vhost_traffic_status_display_format html; } http中添加如下: vhost_traffic_status_zone; nginx -s reload 访问192.168.124.16/status可以看到nginx监控数据 3 .安装nginx-vts-exporter unzip nginx-vts-exporter-0.5.zip mv nginx-vts-exporter-0.5 /usr/local/ chmod +x /usr/local/nginx-vts-exporter-0.5/bin/nginx-vts-exporter cd /usr/local/nginx-vts-exporter-0.5/bin nohup ./nginx-vts-exporter -nginx.scrape_uri http://192.168.124.16/status/format/json & 4 .修改prometheus-cfg.yaml文件 添加如下job: - job_name: 'nginx' scrape_interval: 5s static_configs: - targets: ['192.168.124.16:9913' ] kubectl apply -f prometheus-cfg.yaml kubectl delete -f prometheus-deploy.yaml kubectl apply -f prometheus-deploy.yaml
# prometheus 监控 mongodb1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 1.下载mongodb和mongodb_exporter镜像 docker pull mongo docker pull eses/mongodb_exporter 2.启动mongodb mkdir -p /data/dbdocker run -d --name mongodb -p 27017:27017 -v /data/db:/data/db mongo (1)登录到容器 docker exec -it 24f910190790ade396844cef61cc66412b7af2108494742922c6157c5b236aac mongo admin (2)设置密码 use admin db.createUser({ user: 'admin' , pwd : 'admin111111' , roles: [ { role: "userAdminAnyDatabase" , db: "admin" } ] }) docker run -d --name mongodb_exporter -p 30056:9104 percona/mongodb_exporter:0.34.0 --mongodb.uri mongodb://admin:admin111111@192.168.124.16:27017 注:admin:admin111111这个就是上面启动mongodb后设置的密码,@后面接mongodb的ip和端口 4.修改prometheus-cfg.yaml文件 添加一个job_name - job_name: 'mongodb' scrape_interval: 5s static_configs: - targets: ['192.168.124.16:30056' ] kubectl apply -f prometheus-cfg.yaml kubectl delete -f prometheus-deploy.yaml kubectl apply -f prometheus-deploy.yaml
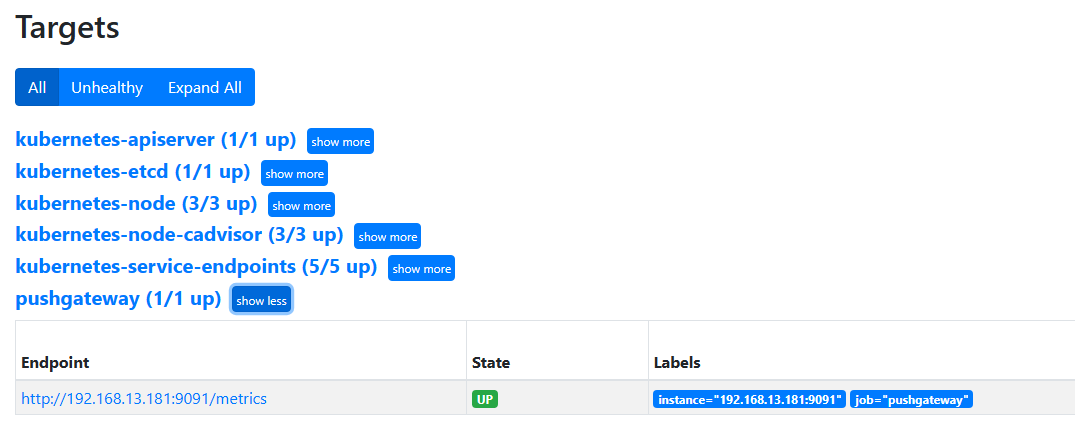
# pushgateway1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Pushgateway是prometheus的一个组件,prometheus server默认是通过exporter主动获取数据(默认采取pull拉取数据),pushgateway则是通过被动方式推送数据到prometheus server,用户可以写一些自定义的监控脚本把需要监控的数据发送给pushgateway, 然后pushgateway再把数据发送给Prometheus server Pushgateway优点: Prometheus 默认采用定时pull 模式拉取targets数据,但是如果不在一个子网或者防火墙,prometheus就拉取不到targets数据,所以可以采用各个target往pushgateway上push数据,然后prometheus去pushgateway上定时pull数据 在监控业务数据的时候,需要将不同数据汇总, 汇总之后的数据可以由pushgateway统一收集,然后由 Prometheus 统一拉取。 pushgateway缺点: Prometheus拉取状态只针对 pushgateway, 不能对每个节点都有效; Pushgateway出现问题,整个采集到的数据都会出现问题 监控下线,prometheus还会拉取到旧的监控数据,需要手动清理 pushgateway不要的数据。 docker push prom/pushgateway docker run -d --name pushgateway -p 9091:9091 prom/pushgateway - job_name: 'pushgateway' scrape_interval: 5s static_configs: - targets: ['192.168.13.181:9091' ] honor_labels: true kubectl apply -f prometheus-cfg.yaml kubectl delete -f prometheus-deploy.yaml kubectl apply -f prometheus-deploy.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 推送指定的数据格式到pushgateway 向 {job="test_job" } 添加单条数据: echo " metric 3.6" | curl --data-binary @- http://192.168.13.181:9091/metrics/job/test_job添加复杂数据 cat <<EOF | curl --data-binary @- http://192.168.13.181:9091/metrics/job/test_job/instance/test_instance node_memory_usage 36 node_memory_total 36000 EOF 删除某个组下某个实例的所有数据 curl -X DELETE http://192.168.13.181:9091/metrics/job/test_job/instance/test_instance 删除某个组下的所有数据: curl -X DELETE http://192.168.13.181:9091/metrics/job/test_job
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 把数据上报到pushgateway 在被监控服务所在的机器配置数据上报,想要把192.168.13.181这个机器的内存数据上报到pushgateway,下面步骤需要在192.168.40.181操作 cat push.shnode_memory_usages=$(free -m | grep Mem | awk '{print $3/$2*100}' ) job_name="memory" instance_name="192.168.13.181" cat <<EOF | curl --data-binary @- http://192.168.13.181:9091/metrics/job/$job_name/instance/$instance_name node_memory_usages $node_memory_usages EOF sh push.sh crontab -u root -e */1 * * * * /root/push.sh 注意:从上面配置可以看到,我们上传到pushgateway中的数据有job也有instance,而prometheus配置pushgateway这个job_name中也有job和instance,这个job和instance是指pushgateway实例本身,添加 honor_labels: true 参数, 可以避免promethues的targets列表中的job_name是pushgateway的 job 、instance 和上报到pushgateway数据的job和instance冲突。
# ELK1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 日志打印的常见级别: 日志打印通常有四种级别,从高到底分别是:ERROR、WARN、INFO、DEBUG。 在你的系统中如果开启了某一级别的日志后,就不会打印比它级别低的日志。例如,程序如果开启了INFO级别日志,DEBUG日志就不会打印,通常在生产环境中开启INFO日志。 1、DEBUG: DEBU可以打印出最详细的日志信息,主要用于开发过程中打印一些运行信息。 2、INFO: INFO可以打印一些你感兴趣的或者重要的信息,这个可以用于生产环境中输出程序运行的一些重要信息,但是不能滥用,避免打印过多的日志。 3、WARNING: WARNING 表明发生了一些暂时不影响运行的错误,会出现潜在错误的情形,有些信息不是错误信息,但是也要给程序员的一些提示 4、ERROR: ERROR 可以打印错误和异常信息,如果不想输出太多的日志,可以使用这个级别,这一级就是比较重要的错误了,软件的某些功能已经不能继续执行了。 通过查看INFO日志发现是由于自己操作失误,造成了程序结果和预期不符合,这种情况不是程序出错,所以并不是bug,不需要开发人员到场。 通过查看INFO日志发现自己的操作正确,根据INFO日志查看并不是操作失误造成,这个时候就需要开发人员到场确认。 ERROR和WARN的级别都比INFO要高,所以在设定日志级别在INFO时,这两者的日志也会被打印。根据上面INFO和DEBUG级别的区别以及适用人员可以知道,ERROR和WARN是同时给测试和开发、运维观察的。WARN级别称之为“警告”,这个“警告”实际上就有点含糊了,它不算错,你可以选择忽视它,但也可以选择重视它。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 常见的日志收集方案 EFK 在Kubernetes集群上运行多个服务和应用程序时,日志收集系统可以帮助你快速分类和分析由Pod生成的大量日志数据。Kubernetes中比较流行的日志收集解决方案是Elasticsearch、Fluentd和Kibana(EFK)技术栈,也是官方推荐的一种方案。 Elasticsearch是一个实时的,分布式的,可扩展的搜索引擎,它允许进行全文本和结构化搜索以及对日志进行分析。它通常用于索引和搜索大量日志数据,也可以用于搜索许多不同种类的文档。 Elasticsearch通常与Kibana一起部署,kibana可以把Elasticsearch采集到的数据通过dashboard(仪表板)可视化展示出来。Kibana允许你通过Web界面浏览Elasticsearch日志数据,也可自定义查询条件快速检索出elasticccsearch中的日志数据。 Fluentd是一个流行的开源数据收集器,我们在 Kubernetes 集群节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。 ELK E - Elasticsearch(简称:ES) L - Logstash K - Kibana Elasticsearch:日志存储和搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。 Logstash:是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用(支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作。)。 Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。 ELK+filebeat Filebeat(采集)—> Logstash(聚合、处理)—> ElasticSearch (存储)—>Kibana (展示) 2.4 其他方案 ELK日志流程可以有多种方案(不同组件可自由组合,根据自身业务配置),常见有以下: Logstash(采集、处理)—> ElasticSearch (存储)—>Kibana (展示) Logstash(采集)—> Logstash(聚合、处理)—> ElasticSearch (存储)—>Kibana (展示) Filebeat(采集、处理)—> ElasticSearch (存储)—>Kibana (展示) Filebeat(采集)—> Logstash(聚合、处理)—> ElasticSearch (存储)—>Kibana (展示) Filebeat(采集)—> Kafka/Redis(消峰) —> Logstash(聚合、处理)—> ElasticSearch (存储)—>Kibana (展示)
# efk 组件1 2 3 Elasticsearch 是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布。 Elasticsearch 以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件;Elastic Stack 是一套适用于数据采集、扩充、存储、分析和可视化的免费开源工具。 人们通常将 Elastic Stack 称为 ELK Stack(代指 Elasticsearch、Logstash 和 Kibana),目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据。
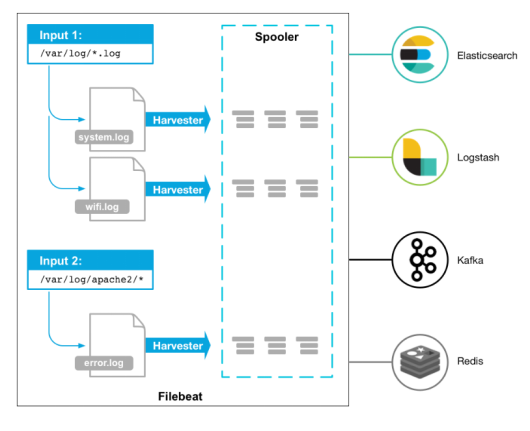
1 2 3 4 5 6 7 8 9 10 11 12 13 filebeat是Beats中的一员。 Beats是一个轻量级日志采集器,Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。 目前Beats包含六种工具: 1、Packetbeat:网络数据(收集网络流量数据) 2、Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据) 3、Filebeat:日志文件(收集文件数据) 4、Winlogbeat:windows事件日志(收集Windows事件日志数据) 5、Auditbeat:审计数据(收集审计日志) 6、Heartbeat:运行时间监控(收集系统运行时的数据) Filebeat是用于转发和收集日志数据的轻量级传送工具。Filebeat监视你指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash中。 Filebeat的工作方式如下:启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 Filebeat 有两个主要组件: harvester:一个harvester负责读取一个单个文件的内容。harvester逐行读取每个文件,并把这些内容发送到输出。每个文件启动一个harvester。 Input:一个input负责管理harvesters,并找到所有要读取的源。如果input类型是log,则input查找驱动器上与已定义的log日志路径匹配的所有文件,并为每个文件启动一个harvester。 Filebeat工作原理 在任何环境下,应用程序都有停机的可能性。 Filebeat 读取并转发日志行,如果中断,则会记住所有事件恢复联机状态时所在位置。 Filebeat带有内部模块(auditd,Apache,Nginx,System和MySQL),可通过一个指定命令来简化通用日志格式的收集,解析和可视化。 FileBeat 不会让你的管道超负荷。FileBeat 如果是向 Logstash 传输数据,当 Logstash 忙于处理数据,会通知 FileBeat 放慢读取速度。一旦拥塞得到解决,FileBeat将恢复到原来的速度并继续传播。 Filebeat保持每个文件的状态,并经常刷新注册表文件中的磁盘状态。状态用于记住harvester正在读取的最后偏移量,并确保发送所有日志行。Filebeat将每个事件的传递状态存储在注册表文件中。所以它能保证事件至少传递一次到配置的输出,没有数据丢失。 传输方案 1、output.elasticsearch 如果你希望使用 filebeat 直接向 elasticsearch 输出数据,需要配置 output.elasticsearch output.elasticsearch: hosts: ["192.168.40.180:9200"] 2、output.logstash 如果使用filebeat向 logstash输出数据,然后由 logstash 再向elasticsearch 输出数据,需要配置 output.logstash。 logstash 和 filebeat 一起工作时,如果 logstash 忙于处理数据,会通知FileBeat放慢读取速度。一旦拥塞得到解决,FileBeat 将恢复到原来的速度并继续传播。这样,可以减少管道超负荷的情况。 output.logstash: hosts: ["192.168.40.180:5044"] 3、output.kafka 如果使用filebeat向kafka输出数据,然后由 logstash 作为消费者拉取kafka中的日志,并再向elasticsearch 输出数据,需要配置 output.logstash output.kafka: enabled: true hosts: ["192.168.40.180:9092"] topic: elfk8stest
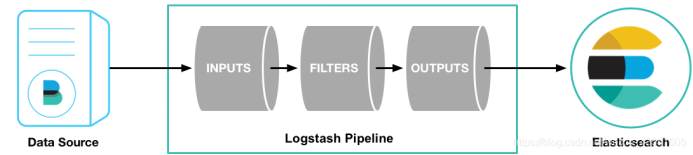
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 logstash组件介绍 Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。Logstash 是一个应用程序日志、事件的传输、处理、管理和搜索的平台。你可以用它来统一对应用程序日志进行收集管理,提供 Web 接口用于查询和统计。 输入:采集各种样式、大小和来源的数据 数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从你的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。 过滤器:实时解析和转换数据 数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。 Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响: 1、利用 Grok 从非结构化数据中派生出结构 2、从 IP 地址破译出地理坐标 3、将 PII 数据匿名化,完全排除敏感字段 4、整体处理不受数据源、格式或架构的影响 输出:选择你的存储,导出你的数据 尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。Logstash 提供众多输出选择,你可以将数据发送到你要指定的地方。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 Logstash 有两个必要元素:input 和 output ,一个可选元素:filter。 这三个元素,分别代表 Logstash 事件处理的三个阶段:输入 > 过滤器 > 输出 Input负责从数据源采集数据。 filter 将数据修改为你指定的格式或内容。 output 将数据传输到目的地。 在实际应用场景中,通常输入、输出、过滤器不止一个。Logstash 的这三个元素都使用插件式管理方式,可以根据应用需要,灵活的选用各阶段需要的插件,并组合使用。 常用input模块 file:从文件系统上的文件读取 syslog:在众所周知的端口514上侦听系统日志消息,并根据RFC3164格式进行解析 redis:从redis服务器读取,使用redis通道和redis列表。 Redis经常用作集中式Logstash安装中的“代理”,它将接收来自远程Logstash“托运人”的Logstash事件排队。 beats:处理由Filebeat发送的事件。 常用的filter模块 过滤器是Logstash管道中的中间处理设备。可以将条件过滤器组合在一起,对事件执行操作。 grok:解析和结构任意文本。 Grok目前是Logstash中将非结构化日志数据解析为结构化和可查询的最佳方法。 mutate:对事件字段执行一般转换。可以重命名,删除,替换和修改事件中的字段。 drop:完全放弃一个事件,例如调试事件。 clone:制作一个事件的副本,可能会添加或删除字段。 geoip:添加有关IP地址的地理位置的信息 常用output elasticsearch:将事件数据发送给 Elasticsearch(推荐模式)。 file:将事件数据写入文件或磁盘。 graphite:将事件数据发送给 graphite(一个流行的开源工具,存储和绘制指标, http://graphite.readthedocs.io/en/latest/)。 statsd:将事件数据发送到 statsd (这是一种侦听统计数据的服务,如计数器和定时器,通过UDP发送并将聚合发送到一个或多个可插入的后端服务)。 input { kafka { bootstrap_servers => "192.168.40.180:9092" auto_offset_reset => "latest" consumer_threads => 5 decorate_events => true topics => ["elktest"] } } output { elasticsearch { hosts => ["192.168.40.180:9200"] index => "elkk8stest-%{+YYYY.MM.dd}" } }
1 2 3 4 5 fluentd是一个针对日志的收集、处理、转发系统。通过丰富的插件系统,可以收集来自于各种系统或应用的日志,转化为用户指定的格式后,转发到用户所指定的日志存储系统之中。 fluentd 常常被拿来和Logstash比较,我们常说ELK,L就是这个agent。fluentd 是随着Docker和es一起流行起来的agent。 fluentd 比 logstash 更省资源; 更轻量级的 fluent-bid 对应 filebeat,作为部署在结点上的日志收集器; fluentd 有更多强大、开放的插件数量和社区。插件多,也非常灵活,规则也不复杂。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 fluentd、filebeat、logstash对比分析 Logstash Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。 优势 Logstash 主要的优点就是它的灵活性,主要因为它有很多插件,详细的文档以及直白的配置格式让它可以在多种场景下应用。我们基本上可以在网上找到很多资源,几乎可以处理任何问题。 劣势 Logstash 致命的问题是它的性能以及资源消耗(默认的堆大小是 1GB)。尽管它的性能在近几年已经有很大提升,与它的替代者们相比还是要慢很多的。这里有 Logstash 与 rsyslog 性能对比以及Logstash 与 filebeat 的性能对比。它在大数据量的情况下会是个问题。 另一个问题是它目前不支持缓存,目前的典型替代方案是将 Redis 或 Kafka 作为中心缓冲池: 因为 Logstash 自身的灵活性以及网络上丰富的资料,Logstash 适用于原型验证阶段使用,或者解析非常的复杂的时候。在不考虑服务器资源的情况下,如果服务器的性能足够好,我们也可以为每台服务器安装 Logstash 。我们也不需要使用缓冲,因为文件自身就有缓冲的行为,而 Logstash 也会记住上次处理的位置。 如果服务器性能较差,并不推荐为每个服务器安装 Logstash ,这样就需要一个轻量的日志传输工具,将数据从服务器端经由一个或多个 Logstash 中心服务器传输到 Elasticsearch: Filebeat 作为 Beats 家族的一员,Filebeat 是一个轻量级的日志传输工具,它的存在正弥补了 Logstash 的缺点:Filebeat 作为一个轻量级的日志传输工具可以将日志推送到中心 Logstash。 在版本 5.x 中,Elasticsearch 具有解析的能力(像 Logstash 过滤器)— Ingest。这也就意味着可以将数据直接用 Filebeat 推送到 Elasticsearch,并让 Elasticsearch 既做解析的事情,又做存储的事情。也不需要使用缓冲,因为 Filebeat 也会和 Logstash 一样记住上次读取的偏移,如果需要缓冲(例如,不希望将日志服务器的文件系统填满),可以使用 Redis/Kafka,因为 Filebeat 可以与它们进行通信。 优势 Filebeat 只是一个二进制文件没有任何依赖。它占用资源极少,尽管它还十分年轻,正式因为它简单,所以几乎没有什么可以出错的地方,所以它的可靠性还是很高的。它也为我们提供了很多可以调节的点,例如:它以何种方式搜索新的文件,以及当文件有一段时间没有发生变化时,何时选择关闭文件句柄。 劣势 Filebeat 的应用范围十分有限,所以在某些场景下我们会碰到问题。例如,如果使用 Logstash 作为下游管道,我们同样会遇到性能问题。正因为如此,Filebeat 的范围在扩大。开始时,它只能将日志发送到 Logstash 和 Elasticsearch,而现在它可以将日志发送给 Kafka 和 Redis,在 5.x 版本中,它还具备过滤的能力。 Fluentd Fluentd 创建的初衷主要是尽可能的使用 JSON 作为日志输出,所以传输工具及其下游的传输线不需要猜测子字符串里面各个字段的类型。这样,它为几乎所有的语言都提供库,这也意味着,我们可以将它插入到我们自定义的程序中。 优势 和多数 Logstash 插件一样,Fluentd 插件是用 Ruby 语言开发的非常易于编写维护。所以它数量很多,几乎所有的源和目标存储都有插件(各个插件的成熟度也不太一样)。这也意味这我们可以用 Fluentd 来串联所有的东西。 劣势 因为在多数应用场景下,我们会通过 Fluentd 得到结构化的数据,它的灵活性并不好。但是我们仍然可以通过正则表达式,来解析非结构化的数据。尽管,性能在大多数场景下都很好,但它并不是最好的,和 syslog-ng 一样,它的缓冲只存在与输出端,单线程核心以及 Ruby GIL 实现的插件意味着它大的节点下性能是受限的,不过,它的资源消耗在大多数场景下是可以接受的。对于小的或者嵌入式的设备,可能需要看看 Fluent Bit,它和 Fluentd 的关系与 Filebeat 和 Logstash 之间的关系类似。 Logagent Logagent 是 Sematext 提供的传输工具,它用来将日志传输到 Logsene(一个基于 SaaS 平台的 Elasticsearch API),因为 Logsene 会暴露 Elasticsearch API,所以 Logagent 可以很容易将数据推送到 Elasticsearch 。 优势 可以获取 /var/log 下的所有信息,解析各种格式(Elasticsearch,Solr,MongoDB,Apache HTTPD等等),它可以掩盖敏感的数据信息,例如,个人验证信息(PII),出生年月日,信用卡号码,等等。它还可以基于 IP 做 GeoIP 丰富地理位置信息(例如,access logs)。同样,它轻量又快速,可以将其置入任何日志块中。在新的 2.0 版本中,它以第三方 node.js 模块化方式增加了支持对输入输出的处理插件。重要的是 Logagent 有本地缓冲,所以不像 Logstash ,在数据传输目的地不可用时会丢失日志。 劣势 尽管 Logagent 有些比较有意思的功能(例如,接收 Heroku 或 CloudFoundry 日志),但是它并没有 Logstash 灵活。 logtail 阿里云日志服务的生产者,目前在阿里集团内部机器上运行,经过3年多时间的考验,目前为阿里公有云用户提供日志收集服务。 采用C++语言实现,对稳定性、资源控制、管理等下过很大的功夫,性能良好。相比于logstash、fluentd的社区支持,logtail功能较为单一,专注日志收集功能。 优势 logtail占用机器cpu、内存资源最少,结合阿里云日志服务的E2E体验良好。 劣势 logtail目前对特定日志类型解析的支持较弱,后续需要把这一块补起来。 rsyslog 绝大多数 Linux 发布版本默认的 syslog 守护进程,rsyslog 可以做的不仅仅是将日志从 syslog socket 读取并写入 /var/log/messages 。它可以提取文件、解析、缓冲(磁盘和内存)以及将它们传输到多个目的地,包括 Elasticsearch 。可以从此处找到如何处理 Apache 以及系统日志。 优势 rsyslog 是经测试过的最快的传输工具。如果只是将它作为一个简单的 router/shipper 使用,几乎所有的机器都会受带宽的限制,但是它非常擅长处理解析多个规则。它基于语法的模块(mmnormalize)无论规则数目如何增加,它的处理速度始终是线性增长的。这也就意味着,如果当规则在 20-30 条时,如解析 Cisco 日志时,它的性能可以大大超过基于正则式解析的 grok ,达到 100 倍(当然,这也取决于 grok 的实现以及 liblognorm 的版本)。 它同时也是我们能找到的最轻的解析器,当然这也取决于我们配置的缓冲。 劣势 rsyslog 的配置工作需要更大的代价(这里有一些例子),这让两件事情非常困难: 文档难以搜索和阅读,特别是那些对术语比较陌生的开发者。 5.x 以上的版本格式不太一样(它扩展了 syslogd 的配置格式,同时也仍然支持旧的格式),尽管新的格式可以兼容旧格式,但是新的特性(例如,Elasticsearch 的输出)只在新的配置下才有效,然后旧的插件(例如,Postgres 输出)只在旧格式下支持。
# 安装 elasticsearch1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 1 .创建一个kube-logging名称空间,将EFK组件安装到该名称空间中。 在这个名称空间下去安装日志收集组件efk,首先,我们需要部署一个有3个节点的Elasticsearch集群。我们使用3个Elasticsearch Pods可以避免高可用中的多节点群集中发生的“裂脑”的问题。 Elasticsearch脑裂可参考如下:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html#split-brain 2 .创建一个headless service的Kubernetes服务,服务名称是elasticsearch,这个服务将为3个Pod定义一个DNS域。headless service不具备负载均衡也没有IP。 kind: Service apiVersion: v1 metadata: name: elasticsearch namespace: kube-logging labels: app: elasticsearch spec: selector: app: elasticsearch clusterIP: None ports: - port: 9200 name: rest - port: 9300 name: inter-node 3 . 创建Storageclass,实现存储类动态供给 yum install nfs-utils -y systemctl enable nfs --now mkdir /data/v1 -p /data/v1 *(rw,no_root_squash) exportfs -arv systemctl restart nfs 4 .创建nfs作为存储的供应商 1 、创建sa apiVersion: v1 kind: ServiceAccount metadata: name: nfs-provisioner 2 、对sa做rbac授权 kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: nfs-provisioner-runner rules: - apiGroups: ["" ] resources: ["persistentvolumes" ] verbs: ["get" , "list" , "watch" , "create" , "delete" ] - apiGroups: ["" ] resources: ["persistentvolumeclaims" ] verbs: ["get" , "list" , "watch" , "update" ] - apiGroups: ["storage.k8s.io" ] resources: ["storageclasses" ] verbs: ["get" , "list" , "watch" ] - apiGroups: ["" ] resources: ["events" ] verbs: ["create" , "update" , "patch" ] - apiGroups: ["" ] resources: ["services" , "endpoints" ] verbs: ["get" ] - apiGroups: ["extensions" ] resources: ["podsecuritypolicies" ] resourceNames: ["nfs-provisioner" ] verbs: ["use" ] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: run-nfs-provisioner subjects: - kind: ServiceAccount name: nfs-provisioner namespace: default roleRef: kind: ClusterRole name: nfs-provisioner-runner apiGroup: rbac.authorization.k8s.io --- kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: leader-locking-nfs-provisioner rules: - apiGroups: ["" ] resources: ["endpoints" ] verbs: ["get" , "list" , "watch" , "create" , "update" , "patch" ] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: leader-locking-nfs-provisioner subjects: - kind: ServiceAccount name: nfs-provisioner namespace: default roleRef: kind: Role name: leader-locking-nfs-provisioner apiGroup: rbac.authorization.k8s.io vim /etc/kubernetes/manifests/kube-apiserver.yaml - --feature-gates=RemoveSelfLink=false kubectl apply -f /etc/kubernetes/manifests/kube-apiserver.yaml kubectl delete pod -n kube-system kube-apiserver 工作节点: docker load -i nfs-client-provisioner.tar.gz kind: Deployment apiVersion: apps/v1 metadata: name: nfs-provisioner spec: selector: matchLabels: app: nfs-provisioner replicas: 2 strategy: type: Recreate template: metadata: labels: app: nfs-provisioner spec: serviceAccount: nfs-provisioner containers: - name: nfs-provisioner image: registry.cn-hangzhou.aliyuncs.com/open-ali/xianchao/nfs-client-provisioner:v1 imagePullPolicy: IfNotPresent volumeMounts: - name: nfs-client-root mountPath: /persistentvolumes env: - name: PROVISIONER_NAME value: example.com/nfs - name: NFS_SERVER value: 192.168 .13 .180 - name: NFS_PATH value: /data/v1 volumes: - name: nfs-client-root nfs: server: 192.168 .13 .180 path: /data/v1 apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: do-block-storage provisioner: example.com/nfs docker load -i elasticsearch_7_2_0.tar.gz apiVersion: apps/v1 kind: StatefulSet metadata: name: es-cluster namespace: kube-logging spec: serviceName: elasticsearch replicas: 2 selector: matchLabels: app: elasticsearch template: metadata: labels: app: elasticsearch spec: containers: - name: elasticsearch image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0 imagePullPolicy: IfNotPresent resources: limits: cpu: 1000m requests: cpu: 100m ports: - containerPort: 9200 name: rest protocol: TCP - containerPort: 9300 name: inter-node protocol: TCP volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data env: - name: cluster.name value: k8s-logs - name: node.name valueFrom: fieldRef: fieldPath: metadata.name - name: discovery.seed_hosts value: "es-cluster-0.elasticsearch.kube-logging.svc.cluster.local,es-cluster-1.elasticsearch.kube-logging.svc.cluster.local,es-cluster-2.elasticsearch.kube-logging.svc.cluster.local" - name: cluster.initial_master_nodes value: "es-cluster-0,es-cluster-1,es-cluster-2" - name: ES_JAVA_OPTS value: "-Xms512m -Xmx512m" initContainers: - name: fix-permissions image: busybox imagePullPolicy: IfNotPresent command: ["sh" , "-c" , "chown -R 1000:1000 /usr/share/elasticsearch/data" ] securityContext: privileged: true volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data - name: increase-vm-max-map image: busybox imagePullPolicy: IfNotPresent command: ["sysctl" , "-w" , "vm.max_map_count=262144" ] securityContext: privileged: true - name: increase-fd-ulimit image: busybox imagePullPolicy: IfNotPresent command: ["sh" , "-c" , "ulimit -n 65536" ] securityContext: privileged: true volumeClaimTemplates: - metadata: name: data labels: app: elasticsearch spec: accessModes: [ "ReadWriteOnce" ] storageClassName: do-block-storage resources: requests: storage: 10Gi pod部署完成之后,可以通过REST API检查elasticsearch集群是否部署成功,使用下面的命令将本地端口9200转发到 Elasticsearch 节点(如es-cluster-0)对应的端口: kubectl port-forward es-cluster-0 9200 :9200 --namespace=kube-logging curl http://localhost:9200/_cat/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 apiVersion: v1 kind: Service metadata: name: kibana namespace: kube-logging labels: app: kibana spec: ports: - port: 5601 selector: app: kibana --- apiVersion: apps/v1 kind: Deployment metadata: name: kibana namespace: kube-logging labels: app: kibana spec: replicas: 1 selector: matchLabels: app: kibana template: metadata: labels: app: kibana spec: containers: - name: kibana image: docker.elastic.co/kibana/kibana:7.2.0 imagePullPolicy: IfNotPresent resources: limits: cpu: 1000m requests: cpu: 100m env : - name: ELASTICSEARCH_URL value: http://elasticsearch.kube-logging.svc.cluster.local:9200 ports: - containerPort: 5601
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 我们使用daemonset控制器部署fluentd组件,这样可以保证集群中的每个节点都可以运行同样fluentd的pod副本,这样就可以收集k8s集群中每个节点的日志,在k8s集群中,容器应用程序的输入输出日志会重定向到node节点里的json文件中,fluentd可以tail和过滤以及把日志转换成指定的格式发送到elasticsearch集群中。除了容器日志,fluentd也可以采集kubelet、kube-proxy、docker的日志。 apiVersion: v1 kind: ServiceAccount metadata: name: fluentd namespace: kube-logging labels: app: fluentd --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: fluentd labels: app: fluentd rules: - apiGroups: - "" resources: - pods - namespaces verbs: - get - list - watch --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd roleRef: kind: ClusterRole name: fluentd apiGroup: rbac.authorization.k8s.io subjects: - kind: ServiceAccount name: fluentd namespace: kube-logging --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd namespace: kube-logging labels: app: fluentd spec: selector: matchLabels: app: fluentd template: metadata: labels: app: fluentd spec: serviceAccount: fluentd serviceAccountName: fluentd tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule containers: - name: fluentd image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1 imagePullPolicy: IfNotPresent env: - name: FLUENT_ELASTICSEARCH_HOST value: "elasticsearch.kube-logging.svc.cluster.local" - name: FLUENT_ELASTICSEARCH_PORT value: "9200" - name: FLUENT_ELASTICSEARCH_SCHEME value: "http" - name: FLUENTD_SYSTEMD_CONF value: disable resources: limits: memory: 512Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers
# 测试 pod1 2 3 4 5 6 7 8 9 10 11 apiVersion: v1 kind: Pod metadata: name: counter spec: containers: - name: count image: busybox imagePullPolicy: IfNotPresent args: [/bin/sh , -c ,'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done' ]
[Kibana Query Language | Kibana Guide 7.2] | Elastic
# ceph1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ceph是一种开源的分布式的存储系统 包含以下几种存储类型: 块存储(rbd),对象存储(RADOS Fateway),文件系统(cephfs) 1.块存储(rbd): 块是一个字节序列(例如,512字节的数据块)。 基于块的存储接口是使用旋转介质(如硬盘,CD,软盘甚至传统的9轨磁带)存储数据的最常用方法;Ceph块设备是精简配置,可调整大小并存储在Ceph集群中多个OSD条带化的数据。 Ceph块设备利用RADOS功能,如快照,复制和一致性。 Ceph的RADOS块设备(RBD)使用内核模块或librbd库与OSD进行交互;Ceph的块设备为内核模块或QVM等KVM以及依赖libvirt和QEMU与Ceph块设备集成的OpenStack和CloudStack等基于云的计算系统提供高性能和无限可扩展性。 可以使用同一个集群同时运行Ceph RADOS Gateway,CephFS文件系统和Ceph块设备。 linux系统中,ls /dev/下有很多块设备文件,这些文件就是我们添加硬盘时识别出来的; rbd就是由Ceph集群提供出来的块设备。可以这样理解,sda是通过数据线连接到了真实的硬盘,而rbd是通过网络连接到了Ceph集群中的一块存储区域,往rbd设备文件写入数据,最终会被存储到Ceph集群的这块区域中; 总结:块设备可理解成一块硬盘,用户可以直接使用不含文件系统的块设备,也可以将其格式化成特定的文件系统,由文件系统来组织管理存储空间,从而为用户提供丰富而友好的数据操作支持。 2.文件系统cephfs Ceph文件系统(CephFS)是一个符合POSIX标准的文件系统,它使用Ceph存储集群来存储其数据。 Ceph文件系统使用与Ceph块设备相同的Ceph存储集群系统。 用户可以在块设备上创建xfs文件系统,也可以创建ext4等其他文件系统,Ceph集群实现了自己的文件系统来组织管理集群的存储空间,用户可以直接将Ceph集群的文件系统挂载到用户机上使用,Ceph有了块设备接口,在块设备上完全可以构建一个文件系统,那么Ceph为什么还需要文件系统接口呢? 主要是因为应用场景的不同,Ceph的块设备具有优异的读写性能,但不能多处挂载同时读写,目前主要用在OpenStack上作为虚拟磁盘,而Ceph的文件系统接口读写性能较块设备接口差,但具有优异的共享性。 3.对象存储 Ceph对象存储使用Ceph对象网关守护进程(radosgw),它是一个用于与Ceph存储集群交互的HTTP服务器。由于它提供与OpenStack Swift和Amazon S3兼容的接口,因此Ceph对象网关具有自己的用户管理。 Ceph对象网关可以将数据存储在用于存储来自Ceph文件系统客户端或Ceph块设备客户端的数据的相同Ceph存储集群中 使用方式就是通过http协议上传下载删除对象(文件即对象)。 老问题来了,有了块设备接口存储和文件系统接口存储,为什么还整个对象存储呢? Ceph的块设备存储具有优异的存储性能但不具有共享性,而Ceph的文件系统具有共享性然而性能较块设备存储差,为什么不权衡一下存储性能和共享性,整个具有共享性而存储性能好于文件系统存储的存储呢,对象存储就这样出现了。 分布式存储的优点: 高可靠:既满足存储读取不丢失,还要保证数据长期存储。 在保证部分硬件损坏后依然可以保证数据安全 高性能:读写速度快 可扩展:分布式存储的优势就是“分布式”,所谓的“分布式”就是能够将多个物理节点整合在一起形成共享的存储池,节点可以线性扩充,这样可以源源不断的通过扩充节点提升性能和扩大容量,这是传统存储阵列无法做到的
1 2 3 4 5 6 7 8 9 10 Ceph核心组件介绍 在ceph集群中,不管你是想要提供对象存储,块设备存储,还是文件系统存储,所有Ceph存储集群部署都是从设置每个Ceph节点,网络和Ceph存储开始 的。 Ceph存储集群至少需要一个Ceph Monitor,Ceph Manager和Ceph OSD(对象存储守护进程)。 运行Ceph Filesystem客户端时也需要Ceph元数据服务器。 Monitors:Ceph监视器(ceph-mon)维护集群状态的映射,包括监视器映射,管理器映射,OSD映射和CRUSH映射。这些映射是Ceph守护进程相互协调所需的关键集群状态。监视器还负责管理守护进程和客户端之间的身份验证。冗余和高可用性通常至少需要三个监视器。 Managers:Ceph Manager守护程序(ceph-mgr)负责跟踪运行时指标和Ceph集群的当前状态,包括存储利用率,当前性能指标和系统负载。 Ceph Manager守护进程还托管基于python的模块来管理和公开Ceph集群信息,包括基于Web的Ceph Dashboard和REST API。高可用性通常至少需要两名Managers。 Ceph OSD:Ceph OSD(对象存储守护进程,ceph-osd)存储数据,处理数据复制,恢复,重新平衡,并通过检查其他Ceph OSD守护进程来获取心跳,为Ceph监视器和管理器提供一些监视信息。冗余和高可用性通常至少需要3个Ceph OSD。 MDS:Ceph元数据服务器(MDS,ceph-mds)代表Ceph文件系统存储元数据(即,Ceph块设备和Ceph对象存储不使用MDS)。 Ceph元数据服务器允许POSIX文件系统用户执行基本命令(如ls,find等),而不会给Ceph存储集群带来巨大负担。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 yum install python-setuptools ceph-deploy -y yum install ceph ceph-radosgw -y [root@master1-admin ~] ceph version 10.2.11 (e4b061b47f07f583c92a050d9e84b1813a35671e) [root@master1-admin ceph ~] [root@master1-admin ceph] [root@master1-admin ceph] ceph.conf ceph-deploy-ceph.log ceph.mon.keyring rbdmap
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1. osd_pool_default_size = 2 mon clock drift allowed = 0.500 mon clock drift warn backoff = 10 mon clock drift allowed mon clock drift warn backoff ceph对每个mon之间的时间同步延时默认要求在0.05s之间,这个时间有的时候太短了。所以如果ceph集群如果出现clock问题就检查ntp时间同步或者适当放宽这个误差时间。 cephx是认证机制是整个 Ceph 系统的用户名/密码 2、配置初始monitor、收集所有的密钥 [root@master1-admin] [root@master1-admin] [root@master1-admin] ceph.bootstrap-mds.keyring ceph.bootstrap-mgr.keyring ceph.bootstrap-osd.keyring ceph.bootstrap-rgw.keyring ceph.client.admin.keyring ceph.mon.keyring
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 cd /etc/ceph/ceph-deploy osd prepare master1-admin:/dev/sdb ceph-deploy osd prepare node1-monitor:/dev/sdb ceph-deploy osd prepare node2-osd:/dev/sdb ceph-deploy osd activate master1-admin:/dev/sdb1 ceph-deploy osd activate node1-monitor:/dev/sdb1 ceph-deploy osd activate node2-osd:/dev/sdb1 ceph-deploy osd list master1-admin node1-monitor node2-osd 创建mds [root@ master1-admin ceph] 查看ceph当前文件系统 [root@ master1-admin ceph] No filesystems enabled 一个cephfs至少要求两个librados存储池,一个为data,一个为metadata。当配置这两个存储池时,注意: 1. 为metadata pool设置较高级别的副本级别,因为metadata的损坏可能导致整个文件系统不用 2. 建议,metadata pool使用低延时存储,比如SSD,因为metadata会直接影响客户端的响应速度。 创建存储池 [root@ master1-admin ceph] pool 'cephfs_data' created [root@ master1-admin ceph] pool 'cephfs_metadata' created 关于创建存储池 确定 pg_num 取值是强制性的,因为不能自动计算。下面是几个常用的值: *少于 5 个 OSD 时可把 pg_num 设置为 128 *OSD 数量在 5 到 10 个时,可把 pg_num 设置为 512 *OSD 数量在 10 到 50 个时,可把 pg_num 设置为 4096 *OSD 数量大于 50 时,你得理解权衡方法、以及如何自己计算 pg_num 取值 *自己计算 pg_num 取值时可借助 pgcalc 工具 随着 OSD 数量的增加,正确的 pg_num 取值变得更加重要,因为它显著地影响着集群的行为、以及出错时的数据持久性(即灾难性事件导致数据丢失的概率)。 创建文件系统 创建好存储池后,你就可以用 fs new 命令创建文件系统了 [root@ master1-admin ceph] new fs with metadata pool 2 and data pool 1 其中:new后的fsname 可自定义 [root@ master1-admin ceph] [root@ master1-admin ceph] [root@master1-admin ceph] cluster 66e0ffc8-fb71-40ee-bcc0-a6e87713ddac health HEALTH_WARN clock skew detected on mon.node2-osd
# k8s 挂载 ceph rbd1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 [root@master1-admin ] [root@master1-admin ] [root@masterk8s ~ ] [root@nodek8s ~ ] [root@master1-admin ~ ] [root@master1-admin ~ ] [root@master1-admin ~ ] [root@master1-admin ~ ] [root@master1-admin ~ ] apiVersion: v1 kind: Pod metadata: name: testrbd spec: containers: - image: nginx name: nginx imagePullPolicy: IfNotPresent volumeMounts: - name: testrbd mountPath: /mnt volumes: - name: testrbd rbd: monitors: - '192.168.13.201:6789' - '192.168.13.200:6789' - '192.168.13.202:6789' pool: k8srbd1 image: rbda fsType: xfs readOnly: false user: admin keyring: /etc/ceph/ceph.client.admin.keyring k8srbd1下的rbda被pod挂载了,那其他pod就不能占用这个k8srbd1下的rbda了 创建deployment的时候也只有一个能running,因为只有一个pod能用这个块设备
# ceph rbd 生成 pv1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 1 、创建ceph-secret这个k8s secret对象,这个secret对象用于k8s volume插件访问ceph集群,获取client.admin的keyring值,并用base64编码,在master1-admin(ceph管理节点)操作 [root@master1-admin ~ ] QVFEN0VIZGswYmZ1Q0JBQXhRK1hGUFV0d1BraTlCNjBSbndiYmc9PQ== apiVersion: v1 kind: Secret metadata: name: ceph-secret data: key: QVFBWk0zeGdZdDlhQXhBQVZsS0poYzlQUlBianBGSWJVbDNBenc9PQ== 3 .回到ceph 管理节点创建pool池 [root@master1-admin ~ ] pool 'k8stest' created [root@master1-admin ~ ] [root@master1-admin ~ ] apiVersion: v1 kind: PersistentVolume metadata: name: ceph-pv spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce rbd: monitors: - '192.168.13.201:6789' - '192.168.13.200:6789' - '192.168.13.202:6789' pool: k8stest image: rbda user: admin secretRef: name: ceph-secret fsType: xfs readOnly: false persistentVolumeReclaimPolicy: Recycle kind: PersistentVolumeClaim apiVersion: v1 metadata: name: ceph-pvc spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 2 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 volumeMounts: - mountPath: "/ceph-data" name: ceph-data volumes: - name: ceph-data persistentVolumeClaim: claimName: ceph-pvc 通过上面实验可以发现pod是可以以ReadWriteOnce共享挂载相同的pvc的 注意:ceph rbd块存储的特点 ceph rbd块存储能在同一个node上跨pod以ReadWriteOnce共享挂载 ceph rbd块存储能在同一个node上同一个pod多个容器中以ReadWriteOnce共享挂载 ceph rbd块存储不能跨node以ReadWriteOnce共享挂载 如果一个使用ceph rdb的pod所在的node挂掉,这个pod虽然会被调度到其它node,但是由于rbd不能跨node多次挂载和挂掉的pod不能自动解绑pv的问题,这个新pod不会正常运行 Deployment更新特性: deployment触发更新的时候,它确保至少所需 Pods 75 % 处于运行状态(最大不可用比例为 25 %)。故像一个pod的情况,肯定是新创建一个新的pod,新pod运行正常之后,再关闭老的pod。 默认情况下,它可确保启动的 Pod 个数比期望个数最多多出 25 % 问题: 结合ceph rbd共享挂载的特性和deployment更新的特性,我们发现原因如下: 由于deployment触发更新,为了保证服务的可用性,deployment要先创建一个pod并运行正常之后,再去删除老pod。而如果新创建的pod和老pod不在一个node,就会导致此故障。 解决办法: 1 ,使用能支持跨node和pod之间挂载的共享存储,例如cephfs,GlusterFS等 2 ,给node添加label,只允许deployment所管理的pod调度到一个固定的node上。(不建议,这个node挂掉的话,服务就故障了)
# 基于 storage 动态生成 pv1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 [root@master1-admin ] [root@node1-monitor ~ ] [root@node2-osd ] [root@\master~ ] [root@node ] [root@master1-admin ] [root@master1-admin ] [root@node1-monitor ~ ] [root@node1-monitor ~ ] [root@node2-osd ] [root@node2-osd ] [root@master~ ] [root@master ~ ] [root@node1 ] [root@node1 ~ ] 1 、创建rbd的供应商provisioner [root@xianchaonode1 ~ ] kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: rbd-provisioner rules: - apiGroups: ["" ] resources: ["persistentvolumes" ] verbs: ["get" , "list" , "watch" , "create" , "delete" ] - apiGroups: ["" ] resources: ["persistentvolumeclaims" ] verbs: ["get" , "list" , "watch" , "update" ] - apiGroups: ["storage.k8s.io" ] resources: ["storageclasses" ] verbs: ["get" , "list" , "watch" ] - apiGroups: ["" ] resources: ["events" ] verbs: ["create" , "update" , "patch" ] - apiGroups: ["" ] resources: ["services" ] resourceNames: ["kube-dns" ,"coredns" ] verbs: ["list" , "get" ] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: rbd-provisioner subjects: - kind: ServiceAccount name: rbd-provisioner namespace: default roleRef: kind: ClusterRole name: rbd-provisioner apiGroup: rbac.authorization.k8s.io --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: rbd-provisioner rules: - apiGroups: ["" ] resources: ["secrets" ] verbs: ["get" ] - apiGroups: ["" ] resources: ["endpoints" ] verbs: ["get" , "list" , "watch" , "create" , "update" , "patch" ] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: rbd-provisioner roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: rbd-provisioner subjects: - kind: ServiceAccount name: rbd-provisioner namespace: default --- apiVersion: apps/v1 kind: Deployment metadata: name: rbd-provisioner spec: selector: matchLabels: app: rbd-provisioner replicas: 1 strategy: type: Recreate template: metadata: labels: app: rbd-provisioner spec: containers: - name: rbd-provisioner image: quay.io/xianchao/external_storage/rbd-provisioner:v1 imagePullPolicy: IfNotPresent env: - name: PROVISIONER_NAME value: ceph.com/rbd serviceAccount: rbd-provisioner --- apiVersion: v1 kind: ServiceAccount metadata: name: rbd-provisioner 2 、创建ceph-secret [root@master1-admin ~ ] apiVersion: v1 kind: Secret metadata: name: ceph-secret-1 type: "ceph.com/rbd" data: key: QVFEN0VIZGswYmZ1Q0JBQXhRK1hGUFV0d1BraTlCNjBSbndiYmc9PQ== apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: k8s-rbd provisioner: ceph.com/rbd parameters: monitors: 192.168 .13 .201 :6789,192.168.13.202:6789,192.168.13.200:6789 adminId: admin adminSecretName: ceph-secret-1 pool: k8stest1 userId: admin userSecretName: ceph-secret-1 fsType: xfs imageFormat: "2" imageFeatures: "layering" kind: PersistentVolumeClaim apiVersion: v1 metadata: name: rbd-pvc spec: accessModes: - ReadWriteOnce volumeMode: Filesystem resources: requests: storage: 1Gi storageClassName: k8s-rbd apiVersion: v1 kind: Pod metadata: labels: test: rbd-pod name: ceph-rbd-pod spec: containers: - name: ceph-rbd-nginx image: nginx imagePullPolicy: IfNotPresent volumeMounts: - name: ceph-rbd mountPath: /mnt readOnly: false volumes: - name: ceph-rbd persistentVolumeClaim: claimName: rbd-pvc
# k8s 对接 cephfs1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 1 、创建ceph子目录 为了别的地方能挂载cephfs,先创建一个secretfile [root@master1-admin ~ ] 挂载cephfs的根目录到集群的mon节点下的一个目录,比如xianchao_data,因为挂载后,我们就可以直接在xianchao_data下面用Linux命令创建子目录了。 [root@master1-admin ~ ] [root@master1-admin ~ ] 在cephfs的根目录里面创建了一个子目录lucky,k8s以后就可以挂载这个目录 [root@master1-admin ~ ] [root@master1-admin xianchao_data ] [root@master1-admin xianchao_data ] 创建k8s连接ceph使用的secret 将/etc/ceph/ceph.client.admin.keyring里面的key的值转换为base64,否则会有问题 [root@master1-admin xianchao_data ] apiVersion: v1 kind: Secret metadata: name: cephfs-secret data: key: QVFCdkJkWmdzRFNaS3hBQWFuKzVybnNqcjJ6aUEvYXRxRm5RT0E9PQo= apiVersion: v1 kind: PersistentVolume metadata: name: cephfs-pv spec: capacity: storage: 1Gi accessModes: - ReadWriteMany cephfs: monitors: - 192.168 .40 .201 :6789 path: /lucky user: admin readOnly: false secretRef: name: cephfs-secret persistentVolumeReclaimPolicy: Recycle kind: PersistentVolumeClaim apiVersion: v1 metadata: name: cephfs-pvc spec: accessModes: - ReadWriteMany volumeName: cephfs-pv resources: requests: storage: 1Gi apiVersion: v1 kind: Pod metadata: name: cephfs-pod-1 spec: containers: - image: nginx name: nginx imagePullPolicy: IfNotPresent volumeMounts: - name: test-v1 mountPath: /mnt volumes: - name: test-v1 persistentVolumeClaim: claimName: cephfs-pvc
# devops1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 敏捷开发 提高开发效率,及时跟进用户需求,缩短开发周期。 敏捷开发包括编写代码和构建代码两个阶段,可以使用git或者svn来管理代码,用maven对代码进行构建 1.5.2 持续集成(CI) 持续集成强调开发人员提交了新代码之后,立刻自动的进行构建、(单元)测试。根据测试结果,我们可以确定新代码和原有代码能否正确地集成在一起。持续集成过程中很重视自动化测试验证结果,对可能出现的一些问题进行预警,以保障最终合并的代码没有问题。 常见的持续集成工具: 1. Jenkins Jenkins是用Java语言编写的,是目前使用最多和最受欢迎的持续集成工具,使用Jenkins,可以自动监测到git或者svn存储库代码的更新,基于最新的代码进行构建,把构建好的源码或者镜像发布到生产环境。Jenkins还有个非常好的功能:它可以在多台机器上进行分布式地构建和负载测试 2. TeamCity 3. Travis CI 4. Go CD 5. Bamboo 6. GitLab CI 7. Codeship 它的好处主要有以下几点: 1)较早的发现错误:每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,哪个环节出现问题都可以较早的发现 2)快速的发现错误:每完成一部分代码的更新,就会把代码集成到主干中,这样就可以快速的发现错误,比较容易的定位错误 3)提升团队绩效:持续集成中代码更新速度快,能及时发现小问题并进行修改,使团队能创造出更好的产品 4)防止分支过多的偏离主干:经常持续集成,会使分支代码经常向主干更新,当单元测试失败或者出现bug,如果开发者需要在没有调试的情况下恢复仓库的代码到没有bug的状态,只有很小部分的代码会丢失 持续集成的目的是提高代码质量,让产品快速的更新迭代。它的核心措施是,代码集成到主干之前,必须通过自动化测试。只要有一个测试用例失败,就不能集成。 Martin Fowler说过,"持续集成并不能消除Bug,而是让它们非常容易发现和改正。" 1.5.3 持续交付 持续交付在持续集成的基础上,将集成后的代码部署到更贴近真实运行环境的「类生产环境」(production-like environments)中。交付给质量团队或者用户,以供评审。如果评审通过,代码就进入生产阶段。 如果所有的代码完成之后一起交付,会导致很多问题爆发出来,解决起来很麻烦,所以持续集成,也就是没更新一次代码,都向下交付一次,这样可以及时发现问题,及时解决,防止问题大量堆积。 1.5.4 持续部署 持续部署是指当交付的代码通过评审之后,自动部署到生产环境中。持续部署是持续交付的最高阶段。 Puppet,SaltStack和Ansible是这个阶段使用的流行工具。容器化工具在部署阶段也发挥着重要作用。 Docker和k8s是流行的工具,有助于在开发,测试和生产环境中实现一致性。 除此之外,k8s还可以实现自动扩容缩容等功能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 K8S在DevOps中的核心作用 Docker和K8S的出现使DevOps变得更加普及,更加容易实现。在传统运维中我们服务时需要针对不同的环境去安装不同的版本,部署方式也杂、多。那么有了docker之后,一次构建、到处运行,我们只需要要构建一次镜像,那么只要有docker的主机,就可以基于镜像把应用跑起来。 在众多微服务中,我们每天可能需要去处理各种服务的崩溃,而服务间的依赖调用关系也及其复杂,这对我们解决问题带来了很大的复杂度。要很好的解决这个问题。我们就需要用到容器编排工具。 Kubernetes 的出现主宰了容器编排的市场,也进化了过去的运维方式,将开发与运维联系的更加紧密。而且让 DevOps 这一角色变得更加清晰,它是目前可用的很流行的容器解决方案之一。 3.1 自动化 敏捷开发->持续集成->持续交付->持续部署 3.2 多集群管理 可以根据客户需求对开发,测试,生产环境部署多套kubernetes集群,每个环境使用独立的物理资源,相互之间避免影响 3.3 多环境一致性 Kubernetes是基于docker的容器编排工具,因为容器的镜像是不可变的,所以镜像把 OS、业务代码、运行环境、程序库、目录结构都包含在内,镜像保存在我们的私有仓库,只要用户从我们提供的私有仓库拉取镜像,就能保证环境的一致性。 3.4 实时反馈和智能化报表 每次集成或交付,都会第一时间将结果通过多途径的方式反馈给你,也可以定制适合企业专用的报表平台。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 1 .安装nfs yum install nfs-utils -y systemctl start nfs systemctl enable nfs (2)在master1上创建一个nfs共享目录 mkdir /data/v2 -p vim /etc/exports /data/v1 *(rw,no_root_squash) /data/v2 *(rw,no_root_squash) exportfs -arv 1 .安装Jenkins kubectl create namespace jenkins-k8s apiVersion: v1 kind: PersistentVolume metadata: name: jenkins-k8s-pv spec: capacity: storage: 10Gi accessModes: - ReadWriteMany nfs: server: 192.168 .13 .180 path: /data/v2 kind: PersistentVolumeClaim apiVersion: v1 metadata: name: jenkins-k8s-pvc namespace: jenkins-k8s spec: resources: requests: storage: 10Gi accessModes: - ReadWriteMany (4)创建一个sa账号 kubectl create sa jenkins-k8s-sa -n jenkins-k8s (5)把上面的sa账号做rbac授权 kubectl create clusterrolebinding jenkins-k8s-sa-cluster -n jenkins-k8s --clusterrole=cluster-admin --serviceaccount=jenkins-k8s:jenkins-k8s-sa docker pull jenkins/jenkins docker load -i jenkins-slave-latest.tar.gz jenkins-slave-latest.tar.gz这个里面封装的镜像是jenkins-slave-latest:v1,这个jenkins-slave-latest:v1镜像制作方法如下: cd /root/slave cat dockerfile FROM jenkins/jnlp-slave:4.13.3-1-jdk11 USER root RUN apt-get update && apt-get install -y \ docker.io RUN usermod -aG docker jenkins RUN curl -LO https://dl.k8s.io/release/stable.txt RUN curl -LO https://dl.k8s.io/release/$(cat stable.txt)/bin/linux/amd64/kubectl RUN chmod +x kubectl RUN mv kubectl /usr/local/bin/ ENV DOCKER_HOST unix:///var/run/docker.sock docker build -t=jenkins-slave-latest:v1 . docker save -o jenkins-slave-latest.tar.gz jenkins-slave-latest:v1 chown -R 1000.1000 /data/v2/ kind: Deployment apiVersion: apps/v1 metadata: name: jenkins namespace: jenkins-k8s spec: replicas: 2 selector: matchLabels: app: jenkins template: metadata: labels: app: jenkins spec: serviceAccount: jenkins-k8s-sa containers: - name: jenkins image: jenkins/jenkins:2.401.1 imagePullPolicy: IfNotPresent ports: - containerPort: 8080 name: web protocol: TCP - containerPort: 50000 name: agent protocol: TCP resources: limits: cpu: 1000m memory: 1Gi requests: cpu: 500m memory: 512Mi livenessProbe: httpGet: path: /login port: 8080 initialDelaySeconds: 60 timeoutSeconds: 5 failureThreshold: 12 readinessProbe: httpGet: path: /login port: 8080 initialDelaySeconds: 60 timeoutSeconds: 5 failureThreshold: 12 volumeMounts: - name: jenkins-volume subPath: jenkins-home mountPath: /var/jenkins_home volumes: - name: jenkins-volume persistentVolumeClaim: claimName: jenkins-k8s-pvc apiVersion: v1 kind: Service metadata: name: jenkins-service namespace: jenkins-k8s labels: app: jenkins spec: selector: app: jenkins type: NodePort ports: - name: web port: 8080 targetPort: web nodePort: 30002 - name: agent port: 50000 targetPort: agent http://192.168.13.180:30002 查看初始密码
1 2 3 4 5 6 7 8 测试通过Jenkins部署应用发布到k8s开发环境、测试环境、生产环境 开发提交代码到代码仓库gitlab-jenkins检测到代码更新-调用k8s api在k8s中创建jenkins slave pod: Jenkins slave pod拉取代码---通过maven把拉取的代码进行构建成war包或者jar包--->上传代码到Sonarqube,进行静态代码扫描- -->基于war包构建docker image-->把镜像上传到harbor镜像仓库-->基于镜像部署应用到开发环境-->部署应用到测试环境--->部署应用到生产环境。 kubectl create ns devlopment kubectl create ns production kubectl create ns qatest
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 api_token 11e9faa9696f6e6b8ced2d7bcf7172a1a4 node('testing' ) { stage('Clone' ) { echo "1.Clone Stage" git url: "https://github.com/luckylucky421/jenkins-sample.git" script { build_tag = sh(returnStdout: true , script: 'git rev-parse --short HEAD' ).trim() } } stage('Test' ) { echo "2.Test Stage" } stage('Build' ) { echo "3.Build Docker Image Stage" sh "docker build -t kbshire/jenkins-demo:${build_tag} ." } stage('Push' ) { echo "4.Push Docker Image Stage" withCredentials([usernamePassword(credentialsId: '3774bc6b-f509-4c57-b913-c82d4f20aeb5' , passwordVariable: 'dockerHubPassword' , usernameVariable: 'dockerHubUser' )]) { sh "docker login -u ${dockerHubUser} -p ${dockerHubPassword} " sh "docker push kbshire/jenkins-demo:${build_tag} " } } stage('Deploy to dev' ) { echo "5. Deploy DEV" sh "sed -i 's/<BUILD_TAG>/${build_tag} /' k8s-dev.yaml" sh "sed -i 's/<BRANCH_NAME>/${env.BRANCH_NAME} /' k8s-dev.yaml" // sh "bash running-devlopment.sh" sh "kubectl apply -f k8s-dev.yaml --validate=false" } stage('Promote to qa' ) { def userInput = input( id : 'userInput' , message: 'Promote to qa?' , parameters: [ [ $class : 'ChoiceParameterDefinition' , choices: "YES\nNO" , name: 'Env' ] ] ) echo "This is a deploy step to ${userInput} " if (userInput == "YES" ) { sh "sed -i 's/<BUILD_TAG>/${build_tag} /' k8s-qa.yaml" sh "sed -i 's/<BRANCH_NAME>/${env.BRANCH_NAME} /' k8s-qa.yaml" // sh "bash running-qa.sh" sh "kubectl apply -f k8s-qa.yaml --validate=false" sh "sleep 6" sh "kubectl get pods -n qatest" } else { //exit } } stage('Promote to pro' ) { def userInput = input( id : 'userInput' , message: 'Promote to pro?' , parameters: [ [ $class : 'ChoiceParameterDefinition' , choices: "YES\nNO" , name: 'Env' ] ] ) echo "This is a deploy step to ${userInput} " if (userInput == "YES" ) { sh "sed -i 's/<BUILD_TAG>/${build_tag} /' k8s-prod.yaml" sh "sed -i 's/<BRANCH_NAME>/${env.BRANCH_NAME} /' k8s-prod.yaml" // sh "bash running-production.sh" sh "cat k8s-prod.yaml" sh "kubectl apply -f k8s-prod.yaml --record --validate=false" } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 : "${JENKINS_WAR:="/usr/share/jenkins/jenkins.war"} " : "${JENKINS_HOME:="/var/jenkins_home"} " : "${COPY_REFERENCE_FILE_LOG:="${JENKINS_HOME} /copy_reference_file.log"} " : "${REF:="/usr/share/jenkins/ref"} " touch "${COPY_REFERENCE_FILE_LOG} " || { echo "Can not write to ${COPY_REFERENCE_FILE_LOG} . Wrong volume permissions?" ; exit 1; }echo "--- Copying files at $(date) " >> "$COPY_REFERENCE_FILE_LOG " find "${REF} " \( -type f -o -type l \) -exec bash -c '. /usr/local/bin/jenkins-support; for arg; do copy_reference_file "$arg"; done' _ {} + if [[ $# -lt 1 ]] || [[ "$1 " == "--" * ]]; then effective_java_opts=$(sed -e 's/^ $//' <<<"$JAVA_OPTS $JENKINS_JAVA_OPTS " ) java_opts_array=() while IFS= read -r -d '' item; do java_opts_array+=( "$item " ) done < <([[ $effective_java_opts ]] && xargs printf '%s\0' <<<"$effective_java_opts " ) readonly agent_port_property='jenkins.model.Jenkins.slaveAgentPort' if [ -n "${JENKINS_SLAVE_AGENT_PORT:-} " ] && [[ "${effective_java_opts:-} " != *"${agent_port_property} " * ]]; then java_opts_array+=( "-D${agent_port_property} =${JENKINS_SLAVE_AGENT_PORT} " ) fi readonly lifecycle_property='hudson.lifecycle' if [[ "${JAVA_OPTS:-} " != *"${lifecycle_property} " * ]]; then java_opts_array+=( "-D${lifecycle_property} =hudson.lifecycle.ExitLifecycle" ) fi if [[ "$DEBUG " ]] ; then java_opts_array+=( \ '-Xdebug' \ '-Xrunjdwp:server=y,transport=dt_socket,address=*:5005,suspend=y' \ ) fi jenkins_opts_array=( ) while IFS= read -r -d '' item; do jenkins_opts_array+=( "$item " ) done < <([[ $JENKINS_OPTS ]] && xargs printf '%s\0' <<<"$JENKINS_OPTS " ) exec java -Duser.home="$JENKINS_HOME " -Dhudson.security.csrf.GlobalCrumbIssuerConfiguration.DISABLE_CSRF_PROTECTION=true "${java_opts_array[@]} " -jar "${JENKINS_WAR} " "${jenkins_opts_array[@]} " "$@ " fi exec "$@ "
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 node('testing' ) { stage('git clone' ) { git url: "https://github.com/kbshire/jenkins-rollout.git" sh "ls -al" sh "pwd" } stage('select env' ) { def envInput = input( id : 'envInput' , message: 'Choose a deploy environment' , parameters: [ [ $class : 'ChoiceParameterDefinition' , choices: "devlopment\nqatest\nproduction" , name: 'Env' ] ] ) echo "This is a deploy step to ${envInput} " sh "sed -i 's/<namespace>/${envInput} /' getVersion.sh" sh "sed -i 's/<namespace>/${envInput} /' rollout.sh" sh "bash getVersion.sh" // env.WORKSPACE = pwd () // def version = readFile "${env.WORKSPACE} /version.csv" // println version } stage('select version' ) { env.WORKSPACE = pwd () def version = readFile "${env.WORKSPACE} /version.csv" println version def userInput = input(id : 'userInput' , message: '选择回滚版本' , parameters: [ [ $class : 'ChoiceParameterDefinition' , choices: "$version \n" , name: 'Version' ] ] ) sh "sed -i 's/<version>/${userInput} /' rollout.sh" } stage('rollout deploy' ) { sh "bash rollout.sh" } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 Jenkins Pipeline介绍 Jenkins pipeline (流水线)是一套运行于jenkins上的工作流框架,将原本独立运行于单个或者多个节点的任务连接起来,实现单个任务难以完成的复杂流程编排与可视化。它把持续提交流水线(Continuous Delivery Pipeline)的任务集成到Jenkins中。 pipeline 是jenkins2.X 最核心的特性, 帮助jenkins 实现从CI到CD与DevOps的转变。 持续提交流水线(Continuous Delivery Pipeline)会经历一个复杂的过程: 从版本控制、向用户和客户提交软件,软件的每次变更(提交代码到仓库)到软件发布(Release)。这个过程包括以一种可靠并可重复的方式构建软件,以及通过多个测试和部署阶段来开发构建好的软件(称为Build)。 总结: 1.Jenkins Pipeline是一组插件,让Jenkins可以实现持续交付管道的落地和实施。 2.持续交付管道(CD Pipeline)是将软件从版本控制阶段到交付给用户或客户的完 整过程的自动化表现。 3.软件的每一次更改(提交到源代码管理系统)都要经过一个复杂的过程才能被发布。 本质上,Jenkins 是一个自动化引擎,它支持许多自动模式。 Pipeline向Jenkins中添加了一组强大的工具, 支持简单的CI到全面的CD pipeline。通过对一系列的相关任务进行建模, 用户可以利用pipeline的很多特性: 1、代码:Pipeline以代码的形式实现,使团队能够编辑,审查和迭代其CD流程。 2、可持续性:Jenkins重启或者中断后都不会影响Pipeline Job。 3、停顿:Pipeline可以选择停止并等待人工输入或批准,然后再继续Pipeline运行。 4、多功能:Pipeline支持现实复杂的CD要求,包括循环和并行执行工作的能力。 5、可扩展:Pipeline插件支持其DSL的自定义扩展以及与其他插件集成的多个选项。 DSL 是什么? DSL 其实是 Domain Specific Language 的缩写,中文翻译为领域特定语言(下简称 DSL);而与 DSL相对的就是GPL,这里的GPL并不是我们知道的开源许可证,而是 General Purpose Language的简称,即通用编程语言,也就是我们非常熟悉的 Objective-C、Java、Python 以及 C 语言等等。 pipeline脚本是由groovy 语言实现的 但无需专门学习 groovy pipeline支持两种语法: -Declarative:声明式 -Scripted pipeline :脚本式 声明式pipeline语法: 官网: https://www.jenkins.io/doc/book/pipeline/syntax/ 声明式语法包括以下核心流程: 1.pipeline : 声明其内容为一个声明式的pipeline脚本 2.agent: 执行节点(job运行的slave或者master节点) 3.stages: 阶段集合,包裹所有的阶段(例如:打包,部署等各个阶段) 4.stage: 阶段,被stages包裹,一个stages可以有多个stage 5.steps: 步骤,为每个阶段的最小执行单元,被stage包裹 6.post: 执行构建后的操作,根据构建结果来执行对应的操作 pipeline{ agent any stages{ stage("This is first stage" ){ steps("This is first step" ){ echo "1" } } } post{ always{ echo "The process is ending" } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 environment environment指令指定一系列键值对,这些键值对将被定义为所有step或stage-specific step的环境变量,具体取决于environment指令在Pipeline中的位置。该指令支持一种特殊的方法credentials(),可以通过其在Jenkins环境中的标识符来访问预定义的凭据。对于类型为“Secret Text”的凭据,该 credentials()方法将确保指定的环境变量包含Secret Text内容;对于“标准用户名和密码”类型的凭证,指定的环境变量将被设置为username:password并且将自动定义两个附加的环境变量:MYVARNAME_USR和MYVARNAME_PSW。 pipeline { agent any environment { CC = 'clang' } stages { stage('Example' ) { steps { sh 'printenv' } } } } options options指令允许在Pipeline本身内配置Pipeline专用选项。Pipeline本身提供了许多选项,例如buildDiscarder,但它们也可能由插件提供,例如 timestamps。 可用选项 buildDiscarder: pipeline保持构建的最大个数。用于保存Pipeline最近几次运行的数据,例如:options { buildDiscarder(logRotator(numToKeepStr: '1' )) } disableConcurrentBuilds: 不允许并行执行Pipeline,可用于防止同时访问共享资源等。例如:options { disableConcurrentBuilds() } skipDefaultCheckout:跳过默认设置的代码check out。例如:options { skipDefaultCheckout() } skipStagesAfterUnstable: 一旦构建状态进入了“Unstable”状态,就跳过此stage。例如:options { skipStagesAfterUnstable() } timeout : 设置Pipeline运行的超时时间,超过超时时间,job会自动被终止,例如:options { timeout (time: 1, unit: 'HOURS' ) } retry: 失败后,重试整个Pipeline的次数。例如:options { retry(3) } timestamps: 预定义由Pipeline生成的所有控制台输出时间。例如:options { timestamps() } pipeline { agent any options { timeout (time: 1, unit: 'HOURS' ) } stages { stage('Example' ) { steps { echo 'Hello World' } } } } parameters parameters指令提供用户在触发Pipeline时的参数列表。这些参数值通过该params对象可用于Pipeline stage中,具体用法如下: 作用域:被最外层pipeline所包裹,并且只能出现一次,参数可被全局使用 好处:使用parameters好处是能够使参数也变成code,达到pipeline as code,pipeline中设置的参数会自动在job构建的时候生成,形成参数化构建 可用参数 string A parameter of a string type , for example: parameters { string(name: 'DEPLOY_ENV' , defaultValue: 'staging' , description: '' ) } booleanParam A boolean parameter, for example: parameters { booleanParam(name: 'DEBUG_BUILD' , defaultValue: true , description: '' ) } 目前只支持[booleanParam, choice, credentials, file, text, password, run, string]这几种参数类型,其他高级参数化类型还需等待社区支持。 pipeline{ agent any parameters { string(name: 'haha' , defaultValue: 'sb' , description: 'haha' ) booleanParam(name: 'xixi' , defaultValue: true , description: 'xixi' ) } stages{ stage("stage1" ){ steps{ echo "$haha " echo "$xixi " } } } } triggers triggers指令定义了Pipeline自动化触发的方式。目前有三个可用的触发器:cron和pollSCM和upstream。 用域:被pipeline包裹,在符合条件下自动触发pipeline cron 接受一个cron风格的字符串来定义Pipeline触发的时间间隔,例如: triggers { cron('H 4/* 0 0 1-5' ) } pollSCM 接受一个cron风格的字符串来定义Jenkins检查SCM源更改的常规间隔。如果存在新的更改,则Pipeline将被重新触发。例如:triggers { pollSCM('H 4/* 0 0 1-5' ) } tools 通过tools可自动安装工具,并放置环境变量到PATH。如果agent none,这将被忽略。 pipeline { agent any tools { maven 'apache-maven-3.0.1' } stages { stage('Example' ) { steps { sh 'mvn --version' } } } } input stage 的 input 指令允许你使用 input step提示输入。 在应用了 options 后,进入 stage 的 agent 或评估 when 条件前,stage 将暂停。 如果 input 被批准, stage 将会继续。 作为 input 提交的一部分的任何参数都将在环境中用于其他 stage 配置项 message 必需的。 这将在用户提交 input 时呈现给用户。 id input 的可选标识符, 默认为 stage 名称。 ok `input`表单上的"ok" 按钮的可选文本。 submitter 可选的以逗号分隔的用户列表或允许提交 input 的外部组名。默认允许任何用户。 submitterParameter 环境变量的可选名称。如果存在,用 submitter 名称设置。 parameters 提示提交者提供的一个可选的参数列表。 pipeline { agent any stages { stage('Example' ) { input { message "Should we continue?" ok "Yes, we should." submitter "222" parameters { string(name: 'PERSON' , defaultValue: '111' , description: 'Who should I say hello to?' ) } } steps { echo "Hello, ${PERSON} , nice to meet you." } } } } when when指令允许Pipeline根据给定的条件确定是否执行该阶段。该when指令必须至少包含一个条件。如果when指令包含多个条件,则所有子条件必须为stage执行返回true 。这与子条件嵌套在一个allOf条件中相同(见下面的例子)。 更复杂的条件结构可使用嵌套条件建:not,allOf或anyOf。嵌套条件可以嵌套到任意深度。 内置条件 branch 当正在构建的分支与给出的分支模式匹配时执行,例如:when { branch 'master' }。请注意,这仅适用于多分支Pipeline。 environment 当指定的环境变量设置为给定值时执行,例如: when { environment name: 'DEPLOY_TO' , value: 'production' } expression 当指定的Groovy表达式求值为true 时执行,例如: when { expression { return params.DEBUG_BUILD } } not 当嵌套条件为false 时执行。必须包含一个条件。例如:when { not { branch 'master' } } allOf 当所有嵌套条件都为真时执行。必须至少包含一个条件。例如:when { allOf { branch 'master' ; environment name: 'DEPLOY_TO' , value: 'production' } } anyOf 当至少一个嵌套条件为真时执行。必须至少包含一个条件。例如:when { anyOf { branch 'master' ; branch 'staging' } } pipeline { agent any stages { stage('Example Build' ) { steps { echo 'Hello World' } } stage('Example Deploy' ) { when { allOf { branch 'production' environment name: 'DEPLOY_TO' , value: 'production' } } steps { echo 'Deploying' } } } } Parallel Declarative Pipeline近期新增了对并行嵌套stage的支持,对耗时长,相互不存在依赖的stage可以使用此方式提升运行效率。除了parallel stage,单个parallel里的多个step也可以使用并行的方式运行。 pipeline { agent any stages { stage('Non-Parallel Stage' ) { steps { echo 'This stage will be executed first.' } } stage('Parallel Stage' ) { when { branch 'master' } parallel { stage('Branch A' ) { agent { label "for-branch-a" } steps { echo "On Branch A" } } stage('Branch B' ) { agent { label "for-branch-b" } steps { echo "On Branch B" } } } } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Pipeline Scripted语法 Groovy脚本不一定适合所有使用者,因此jenkins创建了Declarative pipeline,为编写Jenkins管道提供了一种更简单、更有主见的语法。但是由于脚本化的pipeline是基于groovy的一种DSL语言,所以与Declarative pipeline相比为jenkins用户提供了更巨大的灵活性和可扩展性。 1.流程控制 pipeline脚本同其它脚本语言一样,从上至下顺序执行,它的流程控制取决于Groovy表达式,如if /else条件语句,举例如下: node { stage('Example' ) { if (env.BRANCH_NAME == 'master' ) { echo 'I only execute on the master branch' } else { echo 'I execute elsewhere' } } } Declarative pipeline和Scripted pipeline的比较 共同点: 两者都是pipeline代码的持久实现,都能够使用pipeline内置的插件或者插件提供的stage,两者都可以利用共享库扩展。 区别: 两者不同之处在于语法和灵活性。Declarative pipeline对用户来说,语法更严格,有固定的组织结构,更容易生成代码段,使其成为用户更理想的选择。但是Scripted pipeline更加灵活,因为Groovy本身只能对结构和语法进行限制,对于更复杂的pipeline来说,用户可以根据自己的业务进行灵活的实现和扩展。
1 2 3774bc6b-f509-4c57-b913-c82d4f20aeb5 kbshire/****** (dockerhun) 9511af49-48b7-4d13-90ad-0f6d8194b2d7 admin/****** (harbor)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 node('testing' ) { stage('Clone' ) { echo "1.Clone Stage" git url: "https://github.com/kbshire/jenkins-sample.git" script { build_tag = sh(returnStdout: true , script: 'git rev-parse --short HEAD' ).trim() } } stage('Test' ) { echo "2.Test Stage" } stage('Build' ) { echo "3.Build Docker Image Stage" sh "docker build -t 192.168.13.14:85/jenkins-demo/jenkins-demo:${build_tag} ." } stage('Push' ) { echo "4.Push Docker Image Stage" withCredentials([usernamePassword(credentialsId: '9511af49-48b7-4d13-90ad-0f6d8194b2d7' , passwordVariable: 'dockerHubPassword' , usernameVariable: 'dockerHubUser' )]) { sh "docker login 192.168.13.14:85 -u ${dockerHubUser} -p ${dockerHubPassword} " sh "docker push 192.168.13.14:85/jenkins-demo/jenkins-demo:${build_tag} " } } stage('Deploy to dev' ) { echo "5. Deploy DEV" sh "sed -i 's/<BUILD_TAG>/${build_tag} /' k8s-dev-harbor.yaml" sh "sed -i 's/<BRANCH_NAME>/${env.BRANCH_NAME} /' k8s-dev-harbor.yaml" // sh "bash running-devlopment.sh" sh "kubectl apply -f k8s-dev-harbor.yaml --validate=false" } stage('Promote to qa' ) { def userInput = input( id : 'userInput' , message: 'Promote to qa?' , parameters: [ [ $class : 'ChoiceParameterDefinition' , choices: "YES\nNO" , name: 'Env' ] ] ) echo "This is a deploy step to ${userInput} " if (userInput == "YES" ) { sh "sed -i 's/<BUILD_TAG>/${build_tag} /' k8s-qa-harbor.yaml" sh "sed -i 's/<BRANCH_NAME>/${env.BRANCH_NAME} /' k8s-qa-harbor.yaml" // sh "bash running-qa.sh" sh "kubectl apply -f k8s-qa-harbor.yaml --validate=false" sh "sleep 6" sh "kubectl get pods -n qatest" } else { //exit } } stage('Promote to pro' ) { def userInput = input( id : 'userInput' , message: 'Promote to pro?' , parameters: [ [ $class : 'ChoiceParameterDefinition' , choices: "YES\nNO" , name: 'Env' ] ] ) echo "This is a deploy step to ${userInput} " if (userInput == "YES" ) { sh "sed -i 's/<BUILD_TAG>/${build_tag} /' k8s-prod-harbor.yaml" sh "sed -i 's/<BRANCH_NAME>/${env.BRANCH_NAME} /' k8s-prod-harbor.yaml" // sh "bash running-production.sh" sh "cat k8s-prod-harbor.yaml" sh "kubectl apply -f k8s-prod-harbor.yaml --record --validate=false" } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 安装nexus 概念: Nexus服务器是一个代码包管理的服务器,可以理解 Nexus 服务器是一个巨大的 Library 仓库。Nexus 可以支持管理的工具包括 Maven , npm 等,对于 JAVA 开发来说,只要用到 Maven 管理就可以了。 Nexus服务器作用:因为传统的中央仓库在国外,其地理位置比较远,下载速度比较缓慢。因此,当公司开发人员数量越来越多时,如果不架设一台自己的Nexus服务器,会产生大量的流量阻塞带宽,并且在出现一些不可抗原因(光缆被挖断)导致无法连接到中央仓库时,开发就会因为无法下载相关依赖包而进度停滞。因此在本地环境部署一台私有的Nexus服务器来缓存所有依赖包,并且将公司内部开发的私有包也部署上去,方便其他开发人员下载,是非常有必要的。因为 Nexus 有权限控制,因此外部人员是无法得到公司内部开发的项目包的。 docker run -d -p 8081:8081 -p 8082:8082 -p 8083:8083 -v /etc/localtime:/etc/localtime --name nexus3 sonatype/nexus3 在日志中,会看到一条消息: Started Sonatype Nexus OSS 3.20.1-01 这意味着Nexus Repository Manager可以使用了。现在转到浏览器并打开 http://your-ip-addr:8081 第一步: 1、在 pom.xml 文件中声明发布的宿主仓库和 release 版本发布的仓库。 <!-- 发布构件到Nexus --> <distributionManagement> <repository> <id >releases</id> <name>nexus-releases</name> <url>http://192.168.40.133:8081/repository/maven-releases/</url> </repository> <snapshotRepository> <id >snapshots</id> <name>nexus-snapshots</name> <url>http://192.168.40.133:8081/repository/maven-snapshots/</url> </snapshotRepository> </distributionManagement> 第二步:在 settings.xml 文件中配置 由于用 Maven 分发构件到远程仓库需要认证,须要在~/.m2/settings.xml或者中加入验证信息: <servers> <server> <id >public</id> <username>admin</username> <password>123456</password> </server> <server> <id >releases</id> <username>admin</username> <password>123456</password> </server> <server> <id >snapshots</id> <username>admin</username> <password>123456</password> </server> </servers> 注意: settings.xml 中 server 元素下 id 的值必须与 POM 中 repository 或 snapshotRepository 下 id 的值完全一致 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 安装gitlab 在192.168.40.135上安装 docker run -d -p 443:443 -p 80:80 -p 222:22 --name gitlab --restart always -v /home/gitlab/config:/etc/gitlab -v /home/gitlab/logs:/var/log/gitlab -v /home/gitlab/data:/var/opt/gitlab gitlab/gitlab-ce gitlab/gitlab-ce 改配置: cat /home/gitlab/config/gitlab.rb增加如下三行: external_url 'http://192.168.40.135' gitlab_rails['gitlab_ssh_host' ] = '192.168.40.135' gitlab_rails['gitlab_shell_ssh_port' ] = 222 重启docker: docker restart gitlab 登录192.168.40.135即可登录: 第一次登录注册账号密码之后,报错如下: Your account is pending approval from your GitLab administrator and hence bl 可通过如下方法实现: [root@xianchaomaster1 ~] irb(main):004:0> u=User.where (id :1).first => irb(main):005:0> u.password='12345678' => "12345678" irb(main):006:0> u.password_confirmation='12345678' => "12345678" irb(main):007:0> u.save! => true 再次登录192.168.40.135 用户名是root 密码是12345678 在Jenkins安装git插件 系统管理-插件管理-可选插件-搜索git安装即可 在Jenkins上添加gitlab凭据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 jenkins-jnlp-v2.tar.gz这个压缩包封装的镜像带有mvn命令 node('testing' ) { stage('Clone' ) { echo "1.Clone Stage" git credentialsId: 'gitlab' , url: 'http://192.168.40.135/root/microservic-test.git ' script { build_tag = sh(returnStdout: true , script: 'git rev-parse --shortHEAD' ).trim() } } stage('Test' ) { echo "2.Test Stage" } stage('mvn' ) { sh "mvn clean package -D maven.test.skip=true" } stage('Build' ) { echo "3.Build Docker Image Stage" sh "cd /home/jenkins/agent/workspace/mvn-gitlab-harbor-springcloud/portal-service" sh "docker build --tag 192.168.40.132/microservice/jenkins-demo:v1 /home/jenkins/agent/workspace/mvn-gitlab-harbor-springcloud/portal-service/" } stage('Push' ) { echo "4.Push Docker Image Stage" withCredentials([usernamePassword(credentialsId: 'dockerharbor' ,passwordVariable: 'dockerHubPassword' , usernameVariable: 'dockerHubUser' )]) { sh "docker login 192.168.40.132 -u ${dockerHubUser} -p ${dockerHubPassword} " sh "docker push 192.168.40.132/microservice/jenkins-demo:v1" } } stage('Promoteto pro' ) { sh "kubectl apply -f /home/jenkins/agent/workspace/mvn-gitlab-harbor-springcloud/k8s/portal.yaml" } }
(88 条消息) Jenkins 持续集成结合 Docker Swarm 集群实现 Web 应用部署的发布_SWANSAN 的博客 - CSDN 博客
使用 jenkins pipeline 在代码合并后自动打包并部署到 docker swarm – MOCUISHLE (ley.best)
CI/CD 探索与实践 (二、Jenkins+Docker Swarm) - 夜色微光 - 博客园 (cnblogs.com)
(88 条消息) 最新最全最详细 jenkins pipeline+docker swarm+sonar+junit 实现 java maven 应用的 devops_淡远的博客 - CSDN 博客
# istio1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 官方文档:https://istio.io/docs/concepts/what-is-istio/ 中文官方文档:https://istio.io/zh/docs/concepts/what-is-istio/ Github地址:https://github.com/istio/istio/releases 1、连接(Connect):智能控制服务之间的调用流量,能够实现灰度升级、AB 测试和蓝绿部署等功能 2、安全加固(Secure):自动为服务之间的调用提供认证、授权和加密。 3、控制(Control):应用用户定义的 policy,保证资源在消费者中公平分配。 4、观察(Observe):查看服务运行期间的各种数据,比如日志、监控和 tracing,了解服务的运行情况。 Istio是ServiceMesh的产品化落地,可以通过在现有的服务器新增部署边车代理(sidecar proxy),应用程序不用改代码,或者只需要改很少的代码,就能实现如下基础功能: 1、帮助微服务之间建立连接,帮助研发团队更好的管理与监控微服务,并使得系统架构更加安全; 2、帮助微服务分层解耦,解耦后的proxy层能够更加专注于提供基础架构能力,例如: (1)服务发现(discovery); (2)负载均衡(load balancing); (3)故障恢复(failure recovery); (4)服务度量(metrics); (5)服务监控(monitoring); (6)A/B测试(A/B testing); (7)灰度发布(canary rollouts); (8)限流限速(rate limiting); (9)访问控制(access control); (10)身份认证(end-to-end authentication)。 RPC:RPC(Remote Procedure Call)远程过程调用,简单的理解是一个节点请求另一个节点提供的服务 负载均衡 把前端的请求分发到后台多个服务器 故障恢复 出现故障具备自恢复的能力 服务度量 对于 HTTP,HTTP/2 和 GRPC 流量,Istio 生成以下指标: 1、请求计数(istio_requests_total):这是一个用于累加每个由 Istio 代理所处理请求的 COUNTER 指标。 2、请求持续时间(istio_request_duration_seconds):这是一个用于测量请求的持续时间的 DISTRIBUTION 指标。 3、请求大小(istio_request_bytes):这是一个用于测量 HTTP 请求 body 大小的 DISTRIBUTION 指标。 4、响应大小(istio_response_bytes):这是一个用于测量 HTTP 响应 body 大小的 DISTRIBUTION 指标。 对于 TCP 流量,Istio 生成以下指标: 1、Tcp 发送字节数(istio_tcp_sent_bytes_total):这是一个用于测量在 TCP 连接下响应期间发送的总字节数的 COUNTER 指标。 2、Tcp 接收字节数(istio_tcp_received_bytes_total):这是一个用于测量在 TCP 连接下请求期间接收的总字节数的COUNTER指标。 3、Tcp 打开连接数(istio_tcp_connections_opened_total):这是一个用于累加每个打开连接的 COUNTER 指标。 4、Tcp 关闭连接数 (istio_tcp_connections_closed_total) : 这是一个用于累加每个关闭连接的 COUNTER 指标。 灰度发布 灰度发布也叫金丝雀发布,起源是,矿井工人发现,金丝雀对瓦斯气体很敏感,矿工会在下井之前,先放一只金丝雀到井中,如果金丝雀不叫了,就代表瓦斯浓度高。 Istio核心特性 1、流控(traffic management) 断路器(circuit breakers)、超时、重试、多路由规则、AB测试、灰度发布、按照百分比分配流量等。 2、安全(security) 加密、身份认证、服务到服务的权限控制、K8S里容器到容器的权限控制等。 3、可观察(observability) 追踪、监控、数据收集,通过控制后台全面了解上行下行流量,服务链路情况,服务运行情况,系统性能情况,国内微服务架构体系,这一块做得比较缺乏。 4、平台无关系(platform support) K8s,物理机,自己的虚机都没问题。 5、集成与定制(integration and customization) 可定制化扩展功能。 1.2.1 断路器 当电路发生故障或异常时,伴随着电流不断升高,并且升高的电流有可能能损坏电路中的某些重要器件,也有可能烧毁电路甚至造成火灾。若电路中正确地安置了保险丝,那么保险丝就会在电流异常升高到一定的高度和热度的时候,自身熔断切断电流,从而起到保护电路安全运行的作用。 断路器也称为服务熔断,在多个服务调用的时候,服务A依赖服务B,服务B依赖服务C,如果服务C响应时间过长或者不可用,则会让服务B占用太多系统资源,而服务A也依赖服B,同时也在占用大量的系统资源,造成系统雪崩的情况出现。 Istio 断路器通过网格中的边车对流量进行拦截判断处理,避免了在代码中侵入控制逻辑,非常方便的就实服务熔断的能力。
1 2 3 4 5 6 7 8 在微服务架构中,在高并发情况下,如果请求数量达到一定极限(可以自己设置阈值),超出了设置的阈值,断路器会自动开启服务保护功能,然后通过服务降级的方式返回一个友好的提示给客户端。假设当10个请求中,有10%失败时,熔断器就会打开,此时再调用此服务,将会直接返回失败,不再调远程服务。直到10s钟之后,重新检测该触发条件,判断是否把熔断器关闭,或者继续打开。 服务降级(提高用户体验效果) 比如电商平台,在针对618、双11的时候会有一些秒杀场景,秒杀的时候请求量大,可能会返回报错标志“当前请求人数多,请稍后重试”等,如果使用服务降级,无法提供服务的时候,消费者会调用降级的操作,返回服务不可用等信息,或者返回提前准备好的静态页面写好的信息。 超时 在生产环境中经常会碰到由于调用方等待下游的响应过长,堆积大量的请求阻塞了自身服务,造成雪崩的情况,通过超时处理来避免由于无限期等待造成的故障,进而增强服务的可用性。
1 2 重试 istio 重试机制就是如果调用服务失败,Envoy 代理尝试连接服务的最大次数。而默认情况下,Envoy 代理在失败后并不会尝试重新连接服务。
1 2 3 4 5 6 7 8 客户端调用 nginx,nginx 将请求转发给 tomcat。tomcat 通过故障注入而中止对外服务,nginx 设置如果访问 tomcat 失败则会重试 3 次。 多路由规则 1、HTTP重定向(HTTPRedirect) 2、HTTP重写(HTTPRewrite) 3、HTTP重试(HTTPRetry) 4、HTTP故障注入(HTTPFaultInjection) 5、HTTP跨域资源共享(CorsPolicy)
# 架构
1 2 3 4 5 6 7 8 1、数据平面由一组以Sidecar方式部署的智能代理(Envoy+Polit-agent)组成。这些代理承载并控制微服务之间的所有网络通信,管理入口和出口流量,类似于一线员工。 Sidecar 一般和业务容器绑定在一起(在Kubernets中以自动注入的方式注入到到业务pod中),来劫持业务应用容器的流量,并接受控制面组件的控制,同 时会向控制面输出日志、跟踪及监控数据。 Envoy 和 pilot-agent 打在同一个镜像中,即sidecar Proxy。 2、控制平面负责管理和配置代理来路由流量。 istio1.5+中使用了一个全新的部署模式,重建了控制平面,将原有的多个组件整合为一个单体结构istiod,这个组件是控制平面的核心,管理Istio的所有功能,主要包括Pilot、Mixer、Citadel等服务组件。 istiod是新版本中最大的变化,以一个单体组件替代了原有的架构,降低了复杂度和维护难度,但原有的多组件并不是被完全移除,而是在重构后以模块的形式整合在一起组成了istiod。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 1. 自动注入:在创建应用程序时自动注入 Sidecar代理Envoy程序。在 Kubernetes中创建 Pod时,Kube-apiserver调用控制面组件的 Sidecar-Injector服务,自动修改应用程序的描述信息并注入Sidecar。在真正创建Pod时,在创建业务容器的Pod中同时创建Sidecar容器。 2. 流量拦截:在Pod初始化时设置iptables 规则,基于配置的iptables规则拦截业务容器的Inbound流量和Outbound流量到Sidecar上。而应用程序感知不到Sidecar的存在,还以原本的方式 进行互相访问。上图中,流出frontend服务的流量会被 frontend服务侧的 Envoy拦截,而当流量到达forecast容器时,Inbound流量被forecast 服务侧的Envoy拦截。 3. 服务发现:服务发起方的 Envoy 调用控制面组件 Pilot 的服务发现接口获取目标服务的实例列表。上图中,frontend 服务侧的 Envoy 通过 Pilot 的服务发现接口得到forecast服务各个实例的地址。 4. 负载均衡:服务发起方的Envoy根据配置的负载均衡策略选择服务实例,并连接对应的实例地址。上图中,数据面的各个Envoy从Pilot中获取forecast服务的负载均衡配置,并执行负载均衡动作。 5. 流量治理:Envoy 从 Pilot 中获取配置的流量规则,在拦截到 Inbound 流量和Outbound 流量时执行治理逻辑。上图中, frontend 服务侧的 Envoy 从 Pilot 中获取流量治理规则,并根据该流量治理规则将不同特征的流量分发到forecast服务的v1或v2版本。 6. 访问安全:在服务间访问时通过双方的Envoy进行双向认证和通道加密,并基于服务的身份进行授权管理。上图中,Pilot下发安全相关配置,在frontend服务和forecast服务的Envoy上自动加载证书和密钥来实现双向认证,其中的证书和密钥由另一个管理面组件 Citadel维护。 7. 服务监测:在服务间通信时,通信双方的Envoy都会连接管理面组件Mixer上报访问数据,并通过Mixer将数据转发给对应的监控后端。上图中,frontend服务对forecast服务的访问监控指标、日志和调用链都可以通过这种方式收集到对应的监控后端。 8. 策略执行:在进行服务访问时,通过Mixer连接后端服务来控制服务间的访问,判断对访问是放行还是拒绝。上图中,Mixer 后端可以对接一个限流服务对从frontend服务到forecast服务的访问进行速率控制等操作。 9. 外部访问:在网格的入口处有一个Envoy扮演入口网关的角 色。上图中,外部服务通过Gateway访问入口服务 frontend,对 frontend服务的负载均衡和一些流量治理策略都在这个Gateway上执行。
1 2 3 4 5 6 7 8 9 10 11 istio组件详解 Istio服务组件有很多,从上面的流程中基本能看出每个组件如何协作的,下面具体讲解每个组件的具体用途和功能。 [root@xianchaomaster1 ~]# kubectl get svc -n istio-system |awk '{print $1}' istio-egressgateway istio-ingressgateway istiod 3.1 Pilot Pilot 是 Istio 的主要控制组件,下发指令控制客户端。在整个系统中,Pilot 完成以下任务: 1、从 Kubernetes 或者其他平台的注册中心获取服务信息,完成服务发现过程。 2、读取 Istio 的各项控制配置,在进行转换之后,将其发给数据面进行实施。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 Pilot 将配置内容下发给数据面的 Envoy,Envoy 根据 Pilot 指令,将路由、服务、监听、集群等定义信息转换为本地配置,完成控制行为的落地。 1)Pilot为Envoy提供服务发现 2)提供流量管理功能(例如,A/B 测试、金丝雀发布等)以及弹性功能(超时、重试、熔断器等); 3)生成envoy配置 4)启动envoy 5)监控并管理envoy的运行状况,比如envoy出错时pilot-agent负责重启envoy,或者envoy配置变更后reload envoy Envoy是用 C++ 开发的高性能代理,用于协调服务网格中所有服务的入站和出站流量。 Envoy有许多强大的功能,例如: 动态服务发现 负载均衡 TLS终端 HTTP/2与gRPC代理 断路器 健康检查 流量拆分 灰度发布 故障注入 Citadel 负责处理系统上不同服务之间的TLS通信。 Citadel充当证书颁发机构(CA),并生成证书以允许在数据平面中进行安全的mTLS通信。 Citadel是 Istio的核心安全组件,提供了自动生 成、分发、轮换与撤销密钥和证书功能。Citadel一直监听 Kube- apiserver,以 Secret的形式为每个服务都生成证书密钥,并在Pod创建时挂载到Pod上,代理容器使用这些文件来做服务身份认证,进而代 理两端服务实现双向TLS认证、通道加密、访问授权等安全功能。如图 所示,frontend 服 务对 forecast 服务的访问用到了HTTP方式,通过配置即可对服务增加认证功能,双方的Envoy会建立双向认证的TLS通道,从而在服务间启用双向认证的HTTPS。
Istio 为微服务应用提供了一个完整的解决方案,可以以统一的方式去检测和管理微服务。同时,它还提供了管理流量、实施访问策略、收集数据等功能,而所有这些功能都对业务代码透明,即不需要修改业务代码就能实现。
有了 Istio,就几乎可以不需要其他的微服务框架,也不需要自己去实现服务治理等功能,只要把网络层委托给 Istio,它就能帮助完成这一系列的功能。简单来说,Istio 就是一个提供了服务治理能力的服务网格。
对服务网格来讲,业务代码无侵入和网络层的全权代理是其重要的优势。
Istio 的架构从逻辑上分成数据平面(Data Plane)和控制平面(Control Plane)。
数据平面:由一组和业务服务成对出现的 Sidecar 代理(Envoy)构成,它的主要功能是接管服务的进出流量,传递并控制服务和 Mixer 组件的所有网络通信(Mixer 是一个策略和遥测数据的收集器,稍后会介绍)。
控制平面:主要包括了 Pilot、Mixer、Citadel 和 Galley 共 4 个组件,主要功能是通过配置和管理 Sidecar 代理来进行流量控制,并配置 Mixer 去执行策略和收集遥测数据(Telemetry)。
# Istio 的核心控件 # k8s 安装 istio1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 https://github.com/istio/istio/ 1、把压缩包上传到k8s的控制节点。手动解压: [root@ ~]# tar zxvf istio-1.13.1.tar.gz 2、切换到istio包所在目录下。tar zxvf istio-1.13.1.tar.gz解压的软件包包名是istio-1.13.1,则: cd istio-1.13.1 安装目录包含如下内容: 2)samples/目录下,有示例应用程序 3)bin/目录下,包含istioctl的客户端文件。istioctl工具用于手动注入Envoy sidecar代理。 3、将istioctl客户端路径增加到path环境变量中,macOS 或 Linux 系统的增加方式如下: export PATH=$PWD/bin:$PATH 4、把istioctl这个可执行文件拷贝到/usr/bin/目录 cd /root/istio-1.13.1/bin/ cp -ar istioctl /usr/bin/ 4.2 安装istio 1.下载镜像: 安装istio需要的镜像默认从官网拉取,但是官网的镜像我们拉取会有问题,可以从课件下载镜像,然后上传到自己k8s集群的各个节点,通过docker load -i手动解压镜像: docker load -i examples-bookinfo-details.tar.gz docker load -i examples-bookinfo-reviews-v1.tar.gz docker load -i examples-bookinfo-productpage.tar.gz docker load -i examples-bookinfo-reviews-v2.tar.gz docker load -i examples-bookinfo-ratings.tar.gz docker load -i examples-bookinfo-reviews-v3.tar.gz docker load -i pilot.tar.gz docker load -i proxyv2.tar.gz docker load -i httpbin.tar.gz master: istioctl install --set profile=demo -y 4.卸载istio集群,暂时不执行,记住这个命令即可 istioctl manifest generate --set profile=demo | kubectl delete -f -
# istio 核心资源 1 2 Gateway 在Kubernetes环境中,Ingress controller用于管理进入集群的流量。在Istio服务网格中 Istio Ingress Gateway承担相应的角色,它使用新的配置模型(Gateway 和 VirtualServices)完成流量管理的功能。通过下图做一个总的描述。
K8s 为何需要 Istio?较为深入地讨论 Istio—— 其历史发展、设计理念、核心功能原理及运行流程 - 知乎 (zhihu.com)
浅谈 Service Mesh: 其定义、起源、出现背景和设计理念及作用 - 知乎 (zhihu.com)
Istio 入门:什么是 Istio?Istio 的 4 个主要功能和实现原理 - 知乎 (zhihu.com)
# helm1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Helm是kubernetes的包管理工具,相当于linux环境下的yum/apg-get命令。 Helm中的一些概念: (1)helm:命令行客户端工具,主要用于Kubernetes应用中的chart的创建、打包、发布和管理。 (2)Chart:helm程序包,一系列用于描述k8s资源相关文件的集合,比方说我们部署nginx,需要deployment的yaml,需要service的yaml,这两个清单文件就是一个helm程序包,在k8s中把这些yaml清单文件叫做chart图表。 vlues.yaml文件为模板中的文件赋值,可以实现我们自定义安装 如果是chart开发者需要自定义模板,如果是chart使用者只需要修改values.yaml即可 repository:存放chart图表的仓库,提供部署k8s应用程序需要的那些yaml清单文件 chart--->通过values.yaml这个文件赋值-->生成release实例 helm也是go语言开发的 (3)Release:基于Chart的部署实体,一个chart被Helm运行后将会生成对应的一个release;将在k8s中创建出真实运行的资源对象。 总结: helm把kubernetes资源打包到一个chart中,制作并完成各个chart和chart本身依赖关系并利用chart仓库实现对外分发,而helm还可通过values.yaml文件完成可配置的发布,如果chart版本更新了,helm自动支持滚更更新机制,还可以一键回滚,但是不是适合在生产环境使用,除非具有定义自制chart的能力。 https://github.com/helm/helm/releases
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 tar zxvf helm-v3.8.1-linux-amd64.tar.gz mv linux-amd64/helm /usr/bin/ 配置国内存放chart仓库的地址 阿里云仓库(https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts) 官方仓库(https://hub.kubeapps.com/charts/incubator)官方chart仓库,国内可能无法访问。 微软仓库(http://mirror.azure.cn/kubernetes/charts/)这个仓库推荐,基本上官网有的chart这里都有,国内可能无法访问。 #添加阿里云的chart仓库 [root@ ~]# helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts helm repo add bitnami https://charts.bitnami.com/bitnami [root@prometheus-master ~]# helm repo list NAME URL aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts bitnami https://charts.bitnami.com/bitnami helm repo update helm repo remove xxx #查看阿里云chart仓库中的memcached [root@ ~]# helm search repo aliyun |grep memcached #查看chart信息 [root@ ~]# helm show chart aliyun/memcached #下载chart包到本地 [root@ ~]# helm pull aliyun/memcached [root@ ~]# tar zxvf memcached-2.0.1.tgz [root@ ~]# cd memcached [root@ memcached]# ls Chart.yaml README.md templates values.yaml Chart.yaml: chart的基本信息,包括版本名字之类 templates: 存放k8s的部署资源模板,通过渲染变量得到部署文件 values.yaml:存放全局变量,templates下的文件可以调用 [root@ memcached]# cd templates/ [root@ templates]# ls _helpers.tpl NOTES.txt pdb.yaml statefulset.yaml svc.yaml _helpers.tpl 存放能够复用的模板 NOTES.txt 为用户提供一个关于chart部署后使用说明的文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 apiVersion: apps/v1 kind: StatefulSet metadata: name: {{ template "memcached.fullname" . }} labels: app: {{ template "memcached.fullname" . }} chart: "{{ .Chart.Name }}-{{ .Chart.Version }}" release: "{{ .Release.Name }}" heritage: "{{ .Release.Service }}" spec: selector: matchLabels: app: {{ template "memcached.fullname" . }} chart: "{{ .Chart.Name }}-{{ .Chart.Version }}" release: "{{ .Release.Name }}" heritage: "{{ .Release.Service }}" serviceName: {{ template "memcached.fullname" . }} replicas: {{ .Values.replicaCount }} spec: containers: - name: {{ template "memcached.fullname" . }} image: {{ .Values.image }} imagePullPolicy: {{ default "" .Values.imagePullPolicy | quote }} command: - memcached docker pull memcache:1.4.36-alpine helm install memcache ./ [root@prometheus-master memcached]# kubectl get pod NAME READY STATUS RESTARTS AGE memcache-memcached-0 1/1 Running 0 2m13s memcache-memcached-1 1/1 Running 0 23s memcache-memcached-2 1/1 Running 0 13s [root@prometheus-master memcached]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 14d memcache-memcached ClusterIP None <none> 11211/TCP 2m43s [root@prometheus-master memcached]# kubectl get sts NAME READY AGE memcache-memcached 3/3 2m59s 测试: [root@prometheus-master memcached]# export POD_NAME=$(kubectl get pods --namespace default -l "app=memcache-memcached" -o jsonpath="{.items[0].metadata.name}") [root@prometheus-master memcached]# kubectl port-forward $POD_NAME 11211 [root@prometheus-master ~]# echo -e 'set mykey 0 60 5\r\nhello\r' | nc localhost 11211 STORED helm list helm delete memcache
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 当我们安装好helm之后我们可以开始自定义chart,那么我们需要先创建出一个模板如下: [root@ ~] [root@ ~] [root@ myapp] [root@prometheus-master myapp] . ├── charts ├── Chart.yaml ├── templates │ ├── deployment.yaml │ ├── _helpers.tpl │ ├── hpa.yaml │ ├── ingress.yaml │ ├── NOTES.txt │ ├── serviceaccount.yaml │ ├── service.yaml │ └── tests │ └── test-connection.yaml └── values.yaml 部署release [root@ myapp] 检查values语法格式 [root@ myapp] upgrade升级release [root@ myapp] 回滚release [root@ myapp] helm rollback myapp 1 打包Chart [root@ myapp]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 操作release命令 升级release版本 helm upgrade 回滚release版本 helm rollback 创建一个release实例 helm install 卸载release helm uninstall 查看历史版本 helm history 7.6 操作Chart命令 #检查Chat的语法 helm lint chart相关的 查看chart的详细信息 helm inspect 把chart下载下来 helm pull 把chart打包 helm package
# RancherRancher 简介
Rancher 和 k8s 的区别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 modprobe br_netfilter echo "modprobe br_netfilter" >> /etc/profilecat > /etc/sysctl.d/k8s.conf <<EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF sysctl -p /etc/sysctl.d/k8s.conf 在rancher上配置阿里云镜像源: mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backupwget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo yum install -y yum-utils device-mapper-persistent-data lvm2 wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack ntpdate 在rancher上安装docker yum install docker-ce docker-ce-cli containerd.io -y tee /etc/docker/daemon.json << 'EOF' { "registry-mirrors" :["https://rsbud4vc.mirror.aliyuncs.com" ,"https://registry.docker-cn.com" ,"https://docker.mirrors.ustc.edu.cn" ,"https://dockerhub.azk8s.cn" ,"http://hub-mirror.c.163.com" ,"http://qtid6917.mirror.aliyuncs.com" , "https://rncxm540.mirror.aliyuncs.com" ],"exec-opts" : ["native.cgroupdriver=systemd" ]} [root@rancher ~] [root@rancher ~] [root@rancher ~] 在rancher上操作如下命令: [root@node1 ~] [root@master1 ~] [root@rancher ~] [root@rancher ~] docker ps | grep rancher 注:unless-stopped,在容器退出时总是重启容器,但是不考虑在Docker守护进程启动时就已经停止了的容器
访问 rancher IP
1 2 3 4 5 NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES cattle-fleet-system fleet-agent-77c6d6f87-tw9q6 0/1 ContainerCreating 0 47s <none> prometheus-node1 <none> <none> cattle-system cattle-cluster-agent-778b4cb5cf-fvcrh 1/1 Running 0 78s 10.244.216.90 prometheus-node1 <none> <none> cattle-system cattle-cluster-agent-778b4cb5cf-g69nt 1/1 Running 0 66s 10.244.64.30 prometheus-node2 <none> <none>
# 管理已有集群
选择通用
接下来的创建资源的步骤和 kubernetes 自带的 dashboard 或者 kube-sphere 一样,都是图形化页面,不在赘述
# 二进制安装 k8s1 2 3 4 5 6 kubeadm和二进制安装k8s适用场景分析 kubeadm是官方提供的开源工具,是一个开源项目,用于快速搭建kubernetes集群,目前是比较方便和推荐使用的。kubeadm init 以及 kubeadm join 这两个命令可以快速创建 kubernetes 集群。Kubeadm初始化k8s,所有的组件都是以pod形式运行的,具备故障自恢复能力。 kubeadm是工具,可以快速搭建集群,也就是相当于用程序脚本帮我们装好了集群,属于自动部署,简化部署操作,自动部署屏蔽了很多细节,使得对各个模块感知很少,如果对k8s架构组件理解不深的话,遇到问题比较难排查。 kubeadm适合需要经常部署k8s,或者对自动化要求比较高的场景下使用。 二进制:在官网下载相关组件的二进制包,如果手动安装,对kubernetes理解也会更全面。 Kubeadm和二进制都适合生产环境,在生产环境运行都很稳定,具体如何选择,可以根据实际项目进行评估。
master1 192.168.13.200
master2 192.168.13.201
master3 192.168.13.202
work-node 192.168.13.203
virtual ip: 192.168.13.244
# 初始化1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 配置静态IP 配置主机名 配置/etc/hosts 配置免密登录 关闭firewalld 关闭selinux 关闭交换分区 修改内核参数 配置阿里云repo源 配置时间同步 安装并关闭iptables 开启ipvs 安装基础软件包 安装docker-ce 配置docker镜像加速
# 安装 etcd 集群1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 配置etcd工作目录 [root@ master1 ~] [root@ master1 ~] [root@ master2 ~] [root@ master2 ~] [root@ master3 ~] [root@ master3 ~] 安装签发证书工具cfssl [root@ master1 ~] [root@ master1 ~] [root@ master1 work] cfssl-certinfo_linux-amd64 cfssljson_linux-amd64 cfssl_linux-amd64 [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] 配置ca证书 [root@ master1 work] { "CN" : "kubernetes" , "key" : { "algo" : "rsa" , "size" : 2048 }, "names" : [ { "C" : "CN" , "ST" : "Hubei" , "L" : "Wuhan" , "O" : "k8s" , "OU" : "system" } ], "ca" : { "expiry" : "87600h" } } [root@ master1 work] [root@ master1 work] { "signing" : { "default" : { "expiry" : "87600h" }, "profiles" : { "kubernetes" : { "usages" : [ "signing" , "key encipherment" , "server auth" , "client auth" ], "expiry" : "87600h" } } } } 生成etcd证书 [root@ master1 work] { "CN" : "etcd" , "hosts" : [ "127.0.0.1" , "192.168.13.200" , "192.168.13.201" , "192.168.13.202" , "192.168.13.244" ], "key" : { "algo" : "rsa" , "size" : 2048 }, "names" : [{ "C" : "CN" , "ST" : "Hubei" , "L" : "Wuhan" , "O" : "k8s" , "OU" : "system" }] } [root@ master1 work] [root@ master1 work] etcd-key.pem etcd.pem 部署etcd集群 把etcd-v3.4.13-linux-amd64.tar.gz上传到/data/work目录下 [root@ master1 work] /data/work [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] ETCD_NAME="etcd1" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://192.168.13.200:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.13.200:2379,http://127.0.0.1:2379" ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.13.200:2380" ETCD_ADVERTISE_CLIENT_URLS="https://192.168.13.200:2379" ETCD_INITIAL_CLUSTER="etcd1=https://192.168.13.200:2380,etcd2=https://192.168.13.201:2380,etcd3=https://192.168.13.202:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new" [root@ master1 work] [Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target [Service] Type=notify EnvironmentFile=-/etc/etcd/etcd.conf WorkingDirectory=/var/lib/etcd/ ExecStart=/usr/local/bin/etcd \ --cert-file=/etc/etcd/ssl/etcd.pem \ --key-file=/etc/etcd/ssl/etcd-key.pem \ --trusted-ca-file=/etc/etcd/ssl/ca.pem \ --peer-cert-file=/etc/etcd/ssl/etcd.pem \ --peer-key-file=/etc/etcd/ssl/etcd-key.pem \ --peer-trusted-ca-file=/etc/etcd/ssl/ca.pem \ --peer-client-cert-auth \ --client-cert-auth Restart=on-failure RestartSec=5 LimitNOFILE=65536 [Install] WantedBy=multi-user.target [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master2 work] [root@ master3 work] [root@ master2 ~] ETCD_NAME="etcd2" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://192.168.13.201:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.13.201:2379,http://127.0.0.1:2379" ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.13.201:2380" ETCD_ADVERTISE_CLIENT_URLS="https://192.168.13.201:2379" ETCD_INITIAL_CLUSTER="etcd1=https://192.168.13.200:2380,etcd2=https://192.168.13.201:2380,etcd3=https://192.168.13.202:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new" [root@ master3 ~] ETCD_NAME="etcd3" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://192.168.13.202:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.13.202:2379,http://127.0.0.1:2379" ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.13.202:2380" ETCD_ADVERTISE_CLIENT_URLS="https://192.168.13.202:2379" ETCD_INITIAL_CLUSTER="etcd1=https://192.168.13.200:2380,etcd2=https://192.168.13.201:2380,etcd3=https://192.168.13.202:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new" [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master2 work] [root@ master2 work] [root@ master2 work] 启动etcd的时候,先启动 master1的etcd服务,会一直卡住在启动的状态,然后接着再启动 master2的etcd,这样 master1这个节点etcd才会正常起来 [root@ master3 work] [root@ master3 work] [root@ master3 work] [root@ master1] [root@ master2] [root@ master3] [root@ master1 work] [root@ master1 ~] +----------------------------+--------+-------------+-------+ | ENDPOINT | HEALTH | TOOK | ERROR | +----------------------------+--------+-------------+-------+ | https://192.168.13.200:2379 | true | 12.614205ms | | | https://192.168.13.201:2379 | true | 15.762435ms | | | https://192.168.13.202:2379 | true | 76.066459ms | | +----------------------------+--------+-------------+-------+ |
# 安装 kubernetes 组件1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 下载安装包 二进制包所在的github地址如下: https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/ #把kubernetes-server-linux-amd64.tar.gz上传到 master1上的/data/work目录下: [root@ master1 work]# tar zxvf kubernetes-server-linux-amd64.tar.gz [root@ master1 work]# cd kubernetes/server/bin/ [root@ master1 bin]# cp kube-apiserver kube-controller-manager kube-scheduler kubectl /usr/local/bin/ [root@ master1 bin]# rsync -vaz kube-apiserver kube-controller-manager kube-scheduler kubectl master2:/usr/local/bin/ [root@ master1 bin]# rsync -vaz kube-apiserver kube-controller-manager kube-scheduler kubectl master3:/usr/local/bin/ [root@ master1 bin]# scp kubelet kube-proxy node1:/usr/local/bin/ [root@ master1 bin]# cd /data/work/ [root@ master1 work]# mkdir -p /etc/kubernetes/ [root@ master1 work]# mkdir -p /etc/kubernetes/ssl [root@ master1 work]# mkdir /var/log/kubernetes
# 部署 apiserver 组件1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 部署apiserver组件 [root@ master1 work] $(head -c 16 /dev/urandom | od -An -t x | tr -d ' ' ),kubelet-bootstrap,10001,"system:kubelet-bootstrap" EOF [root@ master1 work] { "CN" : "kubernetes" , "hosts" : [ "127.0.0.1" , "192.168.13.200" , "192.168.13.201" , "192.168.13.202" , "192.168.13.203" , "192.168.13.244" , "10.255.0.1" , "kubernetes" , "kubernetes.default" , "kubernetes.default.svc" , "kubernetes.default.svc.cluster" , "kubernetes.default.svc.cluster.local" ], "key" : { "algo" : "rsa" , "size" : 2048 }, "names" : [ { "C" : "CN" , "ST" : "Hubei" , "L" : "Wuhan" , "O" : "k8s" , "OU" : "system" } ] } [root@ master1 work] [root@ master1 work] KUBE_APISERVER_OPTS="--enable-admission-plugins=NamespaceLifecycle,NodeRestriction,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota \ --anonymous-auth=false \ --bind-address=192.168.13.200 \ --secure-port=6443 \ --advertise-address=192.168.13.200 \ --insecure-port=0 \ --authorization-mode=Node,RBAC \ --runtime-config=api/all=true \ --enable-bootstrap-token-auth \ --service-cluster-ip-range=10.255.0.0/16 \ --token-auth-file=/etc/kubernetes/token.csv \ --service-node-port-range=30000-50000 \ --tls-cert-file=/etc/kubernetes/ssl/kube-apiserver.pem \ --tls-private-key-file=/etc/kubernetes/ssl/kube-apiserver-key.pem \ --client-ca-file=/etc/kubernetes/ssl/ca.pem \ --kubelet-client-certificate=/etc/kubernetes/ssl/kube-apiserver.pem \ --kubelet-client-key=/etc/kubernetes/ssl/kube-apiserver-key.pem \ --service-account-key-file=/etc/kubernetes/ssl/ca-key.pem \ --service-account-signing-key-file=/etc/kubernetes/ssl/ca-key.pem \ --service-account-issuer=https://kubernetes.default.svc.cluster.local \ --etcd-cafile=/etc/etcd/ssl/ca.pem \ --etcd-certfile=/etc/etcd/ssl/etcd.pem \ --etcd-keyfile=/etc/etcd/ssl/etcd-key.pem \ --etcd-servers=https://192.168.13.200:2379,https://192.168.13.201:2379,https://192.168.13.202:2379 \ --enable-swagger-ui=true \ --allow-privileged=true \ --apiserver-count=3 \ --audit-log-maxage=30 \ --audit-log-maxbackup=3 \ --audit-log-maxsize=100 \ --audit-log-path=/var/log/kube-apiserver-audit.log \ --event-ttl=1h \ --alsologtostderr=true \ --logtostderr=false \ --log-dir=/var/log/kubernetes \ --v=4" [root@ master1 work] [Unit] Description=Kubernetes API Server Documentation=https://github.com/kubernetes/kubernetes After=etcd.service Wants=etcd.service [Service] EnvironmentFile=-/etc/kubernetes/kube-apiserver.conf ExecStart=/usr/local/bin/kube-apiserver $KUBE_APISERVER_OPTS Restart=on-failure RestartSec=5 Type=notify LimitNOFILE=65536 [Install] WantedBy=multi-user.target [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master2 ~] [root@ master3 ~] [root@ master1 work] [root@ master2 work] [root@ master3 work] [root@ master1 work] [root@ master2 work] [root@ master3 work] [root@ master1 work] [root@ master2 work] [root@ master3 work] [root@ master1 work] [root@ master2 work] [root@ master3 work] [root@ master1 work] { "kind" : "Status" , "apiVersion" : "v1" , "metadata" : { }, "status" : "Failure" , "message" : "Unauthorized" , "reason" : "Unauthorized" , "code" : 401 } 上面看到401,这个是正常的的状态,还没认证
# 部署 kubectl 组件1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 可以设置一个环境变量KUBECONFIG [root@ master1 ~] 这样在操作kubectl,就会自动加载KUBECONFIG来操作要管理哪个集群的k8s资源了 也可以按照下面方法 [root@ master1 ~] [root@ master1 work] { "CN" : "admin" , "hosts" : [], "key" : { "algo" : "rsa" , "size" : 2048 }, "names" : [ { "C" : "CN" , "ST" : "Hubei" , "L" : "Wuhan" , "O" : "system:masters" , "OU" : "system" } ] } [root@ master1 work] [root@ master1 work] 配置安全上下文 1.设置集群参数 [root@ master1 work] 2.设置客户端认证参数 [root@ master1 work] 3.设置上下文参数 [root@ master1 work] 4.设置当前上下文 [root@ master1 work] [root@ master1 work] [root@ master1 work] 5.授权kubernetes证书访问kubelet api权限 [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master2 ~] [root@ master3 ~] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work]
# 创建 kube-controller-manager 组件1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 [root@ master1 work] { "CN" : "system:kube-controller-manager" , "key" : { "algo" : "rsa" , "size" : 2048 }, "hosts" : [ "127.0.0.1" , "192.168.13.200" , "192.168.13.201" , "192.168.13.202" , "192.168.13.244" ], "names" : [ { "C" : "CN" , "ST" : "Hubei" , "L" : "Wuhan" , "O" : "system:kube-controller-manager" , "OU" : "system" } ] } [root@ master1 work] 1.设置集群参数 [root@ master1 work] 2.设置客户端认证参数 [root@ master1 work] 3.设置上下文参数 [root@ master1 work] 4.设置当前上下文 [root@ master1 work] [root@ master1 work] KUBE_CONTROLLER_MANAGER_OPTS="--port=0 \ --secure-port=10252 \ --bind-address=127.0.0.1 \ --kubeconfig=/etc/kubernetes/kube-controller-manager.kubeconfig \ --service-cluster-ip-range=10.255.0.0/16 \ --cluster-name=kubernetes \ --cluster-signing-cert-file=/etc/kubernetes/ssl/ca.pem \ --cluster-signing-key-file=/etc/kubernetes/ssl/ca-key.pem \ --allocate-node-cidrs=true \ --cluster-cidr=10.0.0.0/16 \ --experimental-cluster-signing-duration=87600h \ --root-ca-file=/etc/kubernetes/ssl/ca.pem \ --service-account-private-key-file=/etc/kubernetes/ssl/ca-key.pem \ --leader-elect=true \ --feature-gates=RotateKubeletServerCertificate=true \ --controllers=*,bootstrapsigner,tokencleaner \ --horizontal-pod-autoscaler-use-rest-clients=true \ --horizontal-pod-autoscaler-sync-period=10s \ --tls-cert-file=/etc/kubernetes/ssl/kube-controller-manager.pem \ --tls-private-key-file=/etc/kubernetes/ssl/kube-controller-manager-key.pem \ --use-service-account-credentials=true \ --alsologtostderr=true \ --logtostderr=false \ --log-dir=/var/log/kubernetes \ --v=2" [root@ master1 work] [Unit] Description=Kubernetes Controller Manager Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=-/etc/kubernetes/kube-controller-manager.conf ExecStart=/usr/local/bin/kube-controller-manager $KUBE_CONTROLLER_MANAGER_OPTS Restart=on-failure RestartSec=5 [Install] WantedBy=multi-user.target [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master2] [root@ master2] [root@ master2] [root@ master2] [root@ master3] [root@ master3] [root@ master3] [root@ master3]
# 创建 kube-scheduler 组件1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 [root@ master1 work] { "CN" : "system:kube-scheduler" , "hosts" : [ "127.0.0.1" , "192.168.13.200" , "192.168.13.201" , "192.168.13.202" , "192.168.13.244" ], "key" : { "algo" : "rsa" , "size" : 2048 }, "names" : [ { "C" : "CN" , "ST" : "Hubei" , "L" : "Wuhan" , "O" : "system:kube-scheduler" , "OU" : "system" } ] } [root@ master1 work] 1.设置集群参数 [root@ master1 work] 2.设置客户端认证参数 [root@ master1 work] 3.设置上下文参数 [root@ master1 work] 4.设置当前上下文 [root@ master1 work] [root@ master1 work] KUBE_SCHEDULER_OPTS="--address=127.0.0.1 \ --kubeconfig=/etc/kubernetes/kube-scheduler.kubeconfig \ --leader-elect=true \ --alsologtostderr=true \ --logtostderr=false \ --log-dir=/var/log/kubernetes \ --v=2" [root@ master1 work] [Unit] Description=Kubernetes Scheduler Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=-/etc/kubernetes/kube-scheduler.conf ExecStart=/usr/local/bin/kube-scheduler $KUBE_SCHEDULER_OPTS Restart=on-failure RestartSec=5 [Install] WantedBy=multi-user.target [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master2] [root@ master2] [root@ master2] [root@ master2] [root@ master3] [root@ master3] [root@ master3] [root@ master3] [root@ node1 ~]
# 部署 kubelet 组件1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 创建kubelet-bootstrap.kubeconfig [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] "cgroupDriver" : "systemd" 要和docker的驱动一致。address替换为自己 node1的IP地址。 [root@ master1 work] { "kind" : "KubeletConfiguration" , "apiVersion" : "kubelet.config.k8s.io/v1beta1" , "authentication" : { "x509" : { "clientCAFile" : "/etc/kubernetes/ssl/ca.pem" }, "webhook" : { "enabled" : true , "cacheTTL" : "2m0s" }, "anonymous" : { "enabled" : false } }, "authorization" : { "mode" : "Webhook" , "webhook" : { "cacheAuthorizedTTL" : "5m0s" , "cacheUnauthorizedTTL" : "30s" } }, "address" : "192.168.13.203" , "port" : 10250, "readOnlyPort" : 10255, "cgroupDriver" : "systemd" , "hairpinMode" : "promiscuous-bridge" , "serializeImagePulls" : false , "featureGates" : { "RotateKubeletClientCertificate" : true , "RotateKubeletServerCertificate" : true }, "clusterDomain" : "cluster.local." , "clusterDNS" : ["10.255.0.2" ] } [root@ master1 work] [Unit] Description=Kubernetes Kubelet Documentation=https://github.com/kubernetes/kubernetes After=docker.service Requires=docker.service [Service] WorkingDirectory=/var/lib/kubelet ExecStart=/usr/local/bin/kubelet \ --bootstrap-kubeconfig=/etc/kubernetes/kubelet-bootstrap.kubeconfig \ --cert-dir=/etc/kubernetes/ssl \ --kubeconfig=/etc/kubernetes/kubelet.kubeconfig \ --config=/etc/kubernetes/kubelet.json \ --network-plugin=cni \ --pod-infra-container-image=k8s.gcr.io/pause:3.2 \ --alsologtostderr=true \ --logtostderr=false \ --log-dir=/var/log/kubernetes \ --v=2 Restart=on-failure RestartSec=5 [Install] WantedBy=multi-user.target [root@ node1 ~] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ node1 ~] [root@ node1 ~] [root@ node1 ~] [root@ node1 ~] [root@ node1 ~] [root@ node1 ~] 执行如下命令可以看到一个worker节点发送了一个 CSR 请求: [root@ master1 work] NAME AGE SIGNERNAME REQUESTOR CONDITION node-csr-SY6gROGEmH0qVZhMVhJKKWN3UaWkKKQzV8dopoIO9Uc 87s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending [root@ master1 work] [root@ master1 work] NAME AGE SIGNERNAME REQUESTOR CONDITION node-csr-SY6gROGEmH0qVZhMVhJKKWN3UaWkKKQzV8dopoIO9Uc 2m25s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued [root@ master1 work] NAME STATUS ROLES AGE VERSION node1 NotReady <none> 30s v1.20.7
# 部署 kube-proxy 组件1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 [root@ master1 work] { "CN" : "system:kube-proxy" , "key" : { "algo" : "rsa" , "size" : 2048 }, "names" : [ { "C" : "CN" , "ST" : "Hubei" , "L" : "Wuhan" , "O" : "k8s" , "OU" : "system" } ] } 生成证书 [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] [root@ master1 work] apiVersion: kubeproxy.config.k8s.io/v1alpha1 bindAddress: 192.168.13.203 clientConnection: kubeconfig: /etc/kubernetes/kube-proxy.kubeconfig clusterCIDR: 192.168.13.0/24 healthzBindAddress: 192.168.13.203:10256 kind: KubeProxyConfiguration metricsBindAddress: 192.168.13.203:10249 mode: "ipvs" [root@ master1 work] [Unit] Description=Kubernetes Kube-Proxy Server Documentation=https://github.com/kubernetes/kubernetes After=network.target [Service] WorkingDirectory=/var/lib/kube-proxy ExecStart=/usr/local/bin/kube-proxy \ --config=/etc/kubernetes/kube-proxy.yaml \ --alsologtostderr=true \ --logtostderr=false \ --log-dir=/var/log/kubernetes \ --v=2 Restart=on-failure RestartSec=5 LimitNOFILE=65536 [Install] WantedBy=multi-user.target [root@ master1 work] [root@ master1 work] [root@ node1 ~] [root@ node1 ~] [root@ node1 ~] [root@ node1 ~] [root@ node1 ~]
# 部署 calico 组件1 2 3 4 5 6 7 8 [root@ node1 ~] [root@ master1 work] [root@ master1 ~] [root@ master1 ~] NAME STATUS ROLES AGE VERSION node1 Ready <none> 73m v1.20.7
# 部署 coredns 组件1 2 3 4 5 6 7 8 9 [root@ master1 ~] [root@ master1 ~] NAME READY STATUS RESTARTS AGE calico-kube-controllers-6949477b58-qvn5b 1/1 Running 0 2m17s calico-node-lv6w4 1/1 Running 0 2m18s coredns-7bf4bd64bd-dt8dq 1/1 Running 0 51s [root@ master1 ~] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.255.0.2 <none> 53/UDP,53/TCP,9153/TCP 12m
# 查看集群状态1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@ master1 ~ ] NAME STATUS ROLES AGE VERSION node1 Ready <none> 38m v1.20.7 [root@ node1 ~ ] [root@ master1 ~ ] [root@ master1 ~ ] [root@ master1 ~ ] [root@ master1 ~ ] / / /
# keepalived+nginx 实现高可用1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 把epel.repo传到 master2、 master3、 node1上 [root@ master1 ~] [root@ master1 ~] [root@ master1 ~] 1、安装nginx主备: 在 master1和 master2上做nginx主备安装 [root@ master1 ~] [root@ master2 ~] 2、修改nginx配置文件。主备一样 [root@ master1 ~] [root@ master1 ~] 两个master上nginx配置文件一样 user nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /run/nginx.pid; include /usr/share/nginx/modules/*.conf; events { worker_connections 1024; } stream { log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent' ; access_log /var/log/nginx/k8s-access.log main; upstream k8s-apiserver { server 192.168.13.200:6443; server 192.168.13.201:6443; server 192.168.13.202:6443; } server { listen 16443; proxy_pass k8s-apiserver; } } http { log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"' ; access_log /var/log/nginx/access.log main; sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; types_hash_max_size 2048; include /etc/nginx/mime.types; default_type application/octet-stream; server { listen 80 default_server; server_name _; location / { } } } 主keepalived [root@ master1 ~] global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id NGINX_MASTER } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.13.244/24 } track_script { check_nginx } } [root@ master1 ~] count=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$" ) if [ "$count " -eq 0 ];then systemctl stop keepalived fi [root@ master1 ~] [root@ master2 ~] global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id NGINX_BACKUP } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 51 priority 90 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.13.244/24 } track_script { check_nginx } } [root@ master2 ~] count=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$" ) if [ "$count " -eq 0 ];then systemctl stop keepalived fi [root@ master2 ~] [root@ master1 ~] [root@ master1 ~] [root@ master1 ~] [root@ master1 ~] [root@ master1 ~] [root@ master2 ~] [root@ master2 ~] [root@ master2 ~] [root@ master2 ~] [root@ master2 ~] 改所有Worker Node(kubectl get node命令查看到的节点)组件配置文件,由原来192.168.13.200修改为192.168.13.244(VIP)。 在所有Worker Node执行: [root@ node1 ~] [root@ node1 ~] [root@ node1 ~] [root@ node1 ~] [root@ node1 ~] [root@ node1 ~]
# ACK&&CCE1 2 3 4 5 阿里云容器服务Kubernetes版(Alibaba Cloud Container Service for Kubernetes,简称容器服务ACK)是全球首批通过Kubernetes一致性认证的服务平台,提供高性能的容器应用管理服务,支持企业级Kubernetes容器化应用的生命周期管理,让您轻松高效地在云端运行Kubernetes容器化应用。 ACK包含了专有版Kubernetes(Dedicated Kubernetes)、托管版Kubernetes(Managed Kubernetes)、Serverless Kubernetes三种形态,方便按需选择。 https://www.aliyun.com/product/kubernetes
1 2 3 云容器引擎(Cloud Container Engine)提供高可靠高性能的企业级容器应用管理服务,支持Kubernetes社区原生应用和工具,简化云上自动化容器运行环境搭建,面向云原生2.0打造CCE Turbo容器集群,计算、网络、调度全面加速,全面加速企业应用创新。 https://www.huaweicloud.com/product/cce.html
使用 kubernetes 集群
1 2 3 4 只要有kubectl的机器即可,完成购买后他们会提供config 替换/root/.kube/config 即可访问集群,记得需要通过公网ip kubectl config view 查看是否替换为公网IP
# 基于 HPA 和 VPA 实现 Pod 自动扩缩容弹性伸缩是根据用户的业务需求和策略,自动 “调整” 其 “弹性资源” 的管理服务。通过弹性伸缩功能,用户可设置定时、周期或监控策略,恰到好处地增加或减少 “弹性资源”,并完成实例配置,保证业务平稳健康运行
在实际工作中,我们常常需要做一些扩容缩容操作,如:电商平台在 618 和双十一搞秒杀活动;由于资源紧张、工作负载降低等都需要对服务实例数进行扩缩容操作。
在 k8s 中扩缩容分为两种:
1、Node 层面:
2、Pod 层面:
# k8s 中自动伸缩的方案# HPA1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # HPA Kubernetes HPA(Horizontal Pod Autoscaling):Pod水平自动伸缩 通过此功能,只需简单的配置,便可以利用监控指标(cpu使用率、磁盘、自定义的等)自动的扩容或缩容服务中Pod数量,当业务需求增加时,系统将无缝地自动增加适量pod容器,提高系统稳定性。 HPA v1版本可以根据CPU使用率来进行自动扩缩容: 但是并非所有的系统都可以仅依靠CPU或者Memory指标来扩容,对于大多数 Web 应用的后端来说,基于每秒的请求数量进行弹性伸缩来处理突发流量会更加的靠谱,所以对于一个自动扩缩容系统来说,我们不能局限于CPU、Memory基础监控数据,每秒请求数RPS等自定义指标也是十分重要。 HPA v2版本可以根据自定义的指标进行自动扩缩容 hpa v1只能基于cpu做扩容所用 hpa v2可以基于内存和自定义的指标做扩容和缩容 如果我们的系统默认依赖Prometheus,自定义的Metrics指标则可以从各种数据源或者exporter中获取,基于拉模型的Prometheus会定期从数据源中拉取数据。 也可以基于metrics-server自动获取节点和pod的资源指标 K8s的HPA controller已经实现了一套简单的自动扩缩容逻辑,默认情况下,每30s检测一次指标,只要检测到了配置HPA的目标值,则会计算出预期的工作负载的副本数,再进行扩缩容操作。同时,为了避免过于频繁的扩缩容,默认在5min内没有重新扩缩容的情况下,才会触发扩缩容。 HPA本身的算法相对比较保守,可能并不适用于很多场景。例如,一个快速的流量突发场景,如果正处在5min内的HPA稳定期,这个时候根据HPA的策略,会导致无法扩容。
# KPA1 2 3 4 5 6 7 8 KPA(Knative Pod Autoscaler):基于请求数对Pod自动扩缩容,KPA 的主要限制在于它不支持基于 CPU 的自动扩缩容。 1、根据并发请求数实现自动扩缩容 2、设置扩缩容边界实现自动扩缩容 扩缩容边界指应用程序提供服务的最小和最大Pod数量。通过设置应用程序提供服务的最小和最大Pod数量实现自动扩缩容。 相比HPA,KPA会考虑更多的场景,其中一个比较重要的是流量突发的时候
# VPA1 2 kubernetes VPA(Vertical Pod Autoscaler),垂直 Pod 自动扩缩容,VPA会基于Pod的资源使用情况自动为集群设置资源占用的限制,从而让集群将Pod调度到有足够资源的最佳节点上。VPA也会保持最初容器定义中资源request和limit 的占比。 它会根据容器资源使用率自动设置pod的CPU和内存的requests,从而允许在节点上进行适当的调度,以便为每个 Pod 提供适当的可用的节点。它既可以缩小过度请求资源的容器,也可以根据其使用情况随时提升资源不足的容量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 HPA全称是Horizontal Pod Autoscaler,翻译成中文是POD水平自动伸缩, HPA可以基于CPU利用率对deployment中的pod数量进行自动扩缩容(除了CPU也可以基于自定义的指标进行自动扩缩容)。pod自动缩放不适用于无法缩放的对象,比如DaemonSets。 HPA由Kubernetes API资源和控制器实现。控制器会周期性的获取平均CPU利用率,并与目标值相比较后调整deployment中的副本数量。 HPA是根据指标来进行自动伸缩的,目前HPA有两个版本–v1和v2beta HPA的API有三个版本,通过kubectl api-versions | grep autoscal可看到 autoscaling/v1 autoscaling/v2beta1 autoscaling/v2beta2 autoscaling/v1只支持基于CPU指标的缩放; autoscaling/v2beta1支持Resource Metrics(资源指标,如pod内存)和Custom Metrics(自定义指标)的缩放; autoscaling/v2beta2支持Resource Metrics(资源指标,如pod的内存)和Custom Metrics(自定义指标)和ExternalMetrics(额外指标)的缩放,但是目前也仅仅是处于beta阶段 K8S从1.8版本开始,CPU、内存等资源的metrics信息可以通过 Metrics API来获取,用户可以直接获取这些metrics信息(例如通过执行kubect top命令),HPA使用这些metics信息来实现动态伸缩。 Metrics server: 1、Metrics server是K8S集群资源使用情况的聚合器 2、从1.8版本开始,Metrics server可以通过yaml文件的方式进行部署 3、Metrics server收集所有node节点的metrics信息 HPA的实现是一个控制循环,由controller manager的--horizontal-pod-autoscaler-sync-period参数指定周期(默认值为15秒)。每个周期内,controller manager根据每个HorizontalPodAutoscaler定义中指定的指标查询资源利用率。controller manager可以从resource metrics API(pod 资源指标)和custom metrics API(自定义指标)获取指标。 然后,通过现有pods的CPU使用率的平均值(计算方式是最近的pod使用量(最近一分钟的平均值,从metrics-server中获得)除以设定的每个Pod的CPU使用率限额)跟目标使用率进行比较,并且在扩容时,还要遵循预先设定的副本数限制:MinReplicas <= Replicas <= MaxReplicas。 计算扩容后Pod的个数:sum (最近一分钟内某个Pod的CPU使用率的平均值)/CPU使用上限的整数+1 流程: 1、创建HPA资源,设定目标CPU使用率限额,以及最大、最小实例数 2、收集一组中(PodSelector)每个Pod最近一分钟内的CPU使用率,并计算平均值 3、读取HPA中设定的CPU使用限额 4、计算:平均值之和/限额,求出目标调整的实例个数 5、目标调整的实例数不能超过1中设定的最大、最小实例数,如果没有超过,则扩容;超过,则扩容至最大的实例个数 6、回到2,不断循环
# metrics-server1 2 3 4 5 6 7 8 9 10 11 12 13 14 metrics-server是一个集群范围内的资源数据集和工具,同样的,metrics-server也只是显示数据,并不提供数据存储服务,主要关注的是资源度量API的实现,比如CPU、文件描述符、内存、请求延时等指标,metric-server收集数据给k8s集群内使用,如kubectl,hpa,scheduler等。 https://github.com/kubernetes-sigs/metrics-server/ docker load -i metrics-server-0.6.1.tar.gz vim /etc/kubernetes/manifests/kube-apiserver.yaml - --enable-aggregator-routing=true # 所有节点重启kubelet systemctl restart kubelet 在components.yaml中增加如下字段: kubectl apply -f components.yaml
# php-apache 利用 hpa 扩缩容1 2 3 4 5 6 7 php-apache服务正在运行,使用kubectl autoscale创建自动缩放器,实现对php-apache这个deployment创建的pod自动扩缩容,下面的命令将会创建一个HPA,HPA将会根据CPU,内存等资源指标增加或减少副本数,创建一个可以实现如下目的的hpa: 1 )让副本数维持在1-10个之间(这里副本数指的是通过deployment部署的pod的副本数) 2 )将所有Pod的平均CPU使用率维持在50%(通过kubectl run运行的每个pod如果是200毫核,这意味着平均CPU利用率为100毫核) [root@ ~ ] [root@ ~ ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 # 创建一个hpa,基于内存动态扩缩容 [root@ ~]# cat hpa-v1.yaml apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: nginx-hpa spec: maxReplicas: 10 minReplicas: 1 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: nginx-hpa metrics: - type: Resource resource: name: memory target: averageUtilization: 60 type: Utilization kubectl get hpa 扩展:查看v2版本的hpa如何定义? [root@ ~]# kubectl get hpa.v2beta2.autoscaling -o yaml > 1.yaml
# VPA1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 使用updateMode: "Off"模式,这种模式仅获取资源推荐值,但是不更新Pod apiVersion: autoscaling.k8s.io/v1beta2 kind: VerticalPodAutoscaler metadata: name: nginx-vpa namespace: vpa spec: targetRef: apiVersion: "apps/v1" kind: Deployment name: nginx updatePolicy: updateMode: "Off" resourcePolicy: containerPolicies: - containerName: "nginx" minAllowed: cpu: "500m" memory: "100Mi" maxAllowed: cpu: "2000m" memory: "2600Mi" kubectl get vpa -n vpa Lower Bound: 下限值 Target: 推荐值 Upper Bound: 上限值 Uncapped Target: 如果没有为VPA提供最小或最大边界,则表示目标利用率
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 updateMode: "Auto" 从输出信息可以看到,vpa执行了EvictedByVPA,自动停掉了nginx,然后使用 VPA推荐的资源启动了新的nginx ,我们查看下nginx的pod可以得到确认 随着服务的负载的变化,VPA的推荐值也会不断变化。当目前运行的pod的资源达不到VPA的推荐值,就会执行pod驱逐,重新部署新的足够资源的服务。 VPA使用限制: 不能与HPA(Horizontal Pod Autoscaler )一起使用 Pod比如使用副本控制器,例如属于Deployment或者StatefulSet VPA好处: Pod 资源用其所需,所以集群节点使用效率高。 Pod 会被安排到具有适当可用资源的节点上。 不必运行基准测试任务来确定 CPU 和内存请求的合适值。 VPA 可以随时调整 CPU 和内存请求,无需人为操作,因此可以减少维护时间。
# kubernetes cluster-autoscaler1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 Cluster Autoscaler (CA)是一个独立程序,是用来弹性伸缩kubernetes集群的。它可以自动根据部署应用所请求的资源量来动态的伸缩集群。当集群容量不足时,它会自动去 Cloud Provider (支持 GCE、GKE 和 AWS)创建新的 Node,而在 Node 长时间资源利用率很低时自动将其删除以节省开支。 在以下情况下,集群自动扩容或者缩放: 扩容:由于资源不足,某些Pod无法在任何当前节点上进行调度 缩容: Node节点资源利用率较低时,且此node节点上存在的pod都能被重新调度到其他node节点上运行 什么时候集群节点不会被 CA 删除? 1)节点上有pod被 PodDisruptionBudget 控制器限制。 2)节点上有命名空间是 kube-system 的pods。 3)节点上的pod不是被控制器创建,例如不是被deployment, replica set, job, stateful set创建。 4)节点上有pod使用了本地存储 5)节点上pod驱逐后无处可去,即没有其他node能调度这个pod 6)节点有注解:"cluster-autoscaler.kubernetes.io/scale-down-disabled": "true"(在CA 1.0.3或更高版本中受支持) 通过PodDisruptionBudget控制器可以设置应用POD集群处于运行状态最低个数,也可以设置应用POD集群处于运行状态的最低百分比,这样可以保证在主动销毁应用POD的时候,不会一次性销毁太多的应用POD,从而保证业务不中断 Horizontal Pod Autoscaler 会根据当前CPU负载更改部署或副本集的副本数。如果负载增加,则HPA将创建新的副本,集群中可能有足够的空间,也可能没有足够的空间。如果没有足够的资源,CA将尝试启动一些节点,以便HPA创建的Pod可以运行。如果负载减少,则HPA将停止某些副本。结果,某些节点可能变得利用率过低或完全为空,然后CA将终止这些不需要的节点。 如何防止节点被CA删除? 节点可以打上以下标签: "cluster-autoscaler.kubernetes.io/scale-down-disabled": "true" 可以使用 kubectl 将其添加到节点(或从节点删除): $ kubectl annotate node <nodename> cluster-autoscaler.kubernetes.io/scale-down-disabled=true
# python 调用 k8s api1 2 3 4 5 6 7 8 python操作kubernetes api需要如下两个条件: 1.前提是需要有个k8s集群环境 2.需要在windows上安装kubernetes模块 在windows下安装kubernetes pip install --ignore-installed kubernetes 认证:把k8s集群的控制节点上的/root/.kube/config传到自己的电脑指定路径下,我传到了C盘,注意:每个人config文件不一样,大家需要用自己k8s集群控制节点的config文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from kubernetes import client,configconfig.kube_config.load_kube_config(config_file='C:\config' ) v1 = client.CoreV1Api() for namespace in v1.list_namespace().items: print (namespace.metadata.name) for node in v1.list_node().items: print (node.metadata.name) services=v1.list_service_for_all_namespaces() for svc in services.items: print ('%s \t%s \t%s \t%s \n' %(svc.metadata.namespace,svc.metadata.name,svc.spec.cluster_ip,svc.spec.ports)) pods=v1.list_pod_for_all_namespaces() for i in pods.items: print ("%s\t%s\t%s" %(i.status.pod_ip,i.metadata.namespace,i.metadata.name)) v1_deploy=client.AppsV1Api() deploys=v1_deploy.list_deployment_for_all_namespaces() for i in deploys.items: print ("%s\t%s\t%s" %(i.metadata.name,i.metadata.namespace,i.spec.replicas))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from os import pathimport yamlfrom kubernetes import client,configdef main (): config.load_kube_config(config_file='C:\config' ) with open (path.join(path.dirname(__file__),"nginx-deploy.yaml" )) as f: dep=yaml.safe_load(f) k8s_apps_v1=client.AppsV1Api() resp = k8s_apps_v1.create_namespaced_deployment(body=dep,namespace='default' ) print ('deployment created,name=%s' %(resp.metadata.name)) if __name__ == '__main__' : main()
1 2 3 4 5 6 7 8 9 10 11 12 13 from os import pathimport yamlfrom kubernetes import client,configdef main (): config.load_kube_config(config_file='C:\config' ) k8s_core_v1=client.CoreV1Api() resp=k8s_core_v1.delete_namespaced_pod(namespace='default' ,name='busybox-test' ) print ('delete pod' ) main() 上面是删除自己linux机器上的k8s集群的默认名称空间下的busybox-test这个pod
1 2 3 4 5 6 7 8 9 10 11 12 13 from os import pathimport yamlfrom kubernetes import client,configdef main (): config.load_kube_config(config_file='C:\config' ) k8s_core_v1=client.CoreV1Api() old_resp=k8s_core_v1.read_namespaced_pod(namespace='default' ,name='busybox-test' ) old_resp.spec.containers[0 ].image='nginx' new_resp=k8s_core_v1.patch_namespaced_pod(namespace='default' ,name='busybox-test' ,body=old_resp) print (new_resp.spec.containers[0 ].image) if __name__=='__main__' : main()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from os import pathimport yamlfrom kubernetes import client,configdef main (): config.load_kube_config(config_file='C:\config' ) k8s_core_v1=client.CoreV1Api() resp=k8s_core_v1.read_namespaced_pod(namespace='default' ,name='busybox-test' ) print ('read pod' ) print (resp.spec.containers[0 ]) print (resp.spec.containers[0 ].image) if __name__=='__main__' : main()
# ephemeral1 2 3 4 5 6 7 8 临时容器与其他容器的不同之处在于,它们缺少对资源或执行的保证,并且永远不会自动重启,因此不适用于构建应用程序。临时容器使用与常规容器相同的 Container.Spec字段进行描述,但许多字段是不允许使用的。 临时容器没有端口配置,因此像 ports,livenessProbe,readinessProbe 这样的字段是不允许的。 Pod 资源分配是不可变的,因此 resources 配置是不允许的。 临时容器是使用 API 中的一种特殊的 ephemeralcontainers 处理器进行创建的, 而不是直接添加到 pod.spec 段,因此无法使用 kubectl edit 来添加一个临时容器。 与常规容器一样,将临时容器添加到 Pod 后,将不能更改或删除临时容器 当由于容器崩溃或容器镜像不包含调试实用程序而导致 kubectl exec 无用时,临时容器对于交互式故障排查很有用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 需要开启支持临时容器的特性: 修改kube-apiserver.yaml、kube-scheduler.yaml、kubelet配置。 [root@ ] apiVersion: v1 kind: Pod metadata: annotations: kubeadm.kubernetes.io/kube-apiserver.advertise-address.endpoint: 192.168 .40 .180 :6443 creationTimestamp: null labels: component: kube-apiserver tier: control-plane name: kube-apiserver namespace: kube-system spec: containers: - command: - kube-apiserver - --advertise-address=192.168.40.180 ……… - --feature-gates=RemoveSelfLink=false - --feature-gates=EphemeralContainers=true ……… [root@ ] apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: component: kube-scheduler tier: control-plane name: kube-scheduler namespace: kube-system spec: containers: - command: - kube-scheduler - --authentication-kubeconfig=/etc/kubernetes/scheduler.conf - --authorization-kubeconfig=/etc/kubernetes/scheduler.conf - --bind-address=192.168.40.180 - --kubeconfig=/etc/kubernetes/scheduler.conf - --leader-elect=true - --feature-gates=EphemeralContainers=true [root@master ] KUBELET_EXTRA_ARGS="--feature-gates=EphemeralContainers=true" [root@node~ ] KUBELET_EXTRA_ARGS="--feature-gates=EphemeralContainers=true" [root@ ] [root@ ~ ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 apiVersion: v1 kind: Pod metadata: name: tomcat-test namespace: default labels: app: tomcat spec: containers: - name: tomcat-java ports: - containerPort: 8080 image: tomcat-8.5-jre8 imagePullPolicy: IfNotPresent #创建临时容器 [root@xianchaomaster1]# kubectl debug -it tomcat-test --image=busybox:1.28 --target=tomcat-java [root@prometheus-master ~]# kubectl describe pod tomcat-test Containers: tomcat-java: Container ID: docker://b15184eb42acf60957e2d245a3e784ec20528f057adc55fdb944aee4ffcd968d Image: tomcat-8.5-jre8 Image ID: docker://sha256:4ac473a3dd922eecfc8e0dabd9f6c410871dfd913fea49bfed3fb99924839131 Port: 8080/TCP Host Port: 0/TCP State: Running Started: Sun, 11 Jun 2023 02:10:21 +0800 Ready: True Restart Count: 0 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-mhn6h (ro) Ephemeral Containers: debugger-tnspk: Container ID: docker://0d8d52ce48509f796aa591d7175242f34b00d0235e9d58710f0109dbce30683c Image: busybox:1.28 Image ID: docker://sha256:8c811b4aec35f259572d0f79207bc0678df4c736eeec50bc9fec37ed936a472a Port: <none> Host Port: <none> State: Running Started: Sun, 11 Jun 2023 02:12:52 +0800 Ready: False Restart Count: 0 Environment: <none> Mounts: <none> kubectl debug 每次都会创建一个新的临时容器,以前的临时容器不会删除,但也无法登录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 kubectl raw更新临时容器 kubectl applf -f tomcat.yaml vim a.json { "apiVersion": "v1" , "kind": "EphemeralContainers" , "metadata": { "name": "tomcat-test" }, "ephemeralContainers": [{ "command": [ "sh" ], "image": "busybox" , "imagePullPolicy": "IfNotPresent" , "name": "debugger" , "stdin": true , "tty": true , "targetContainerName": "tomcat-java" , "terminationMessagePolicy": "File" }] } kubectl replace --raw /api/v1/namespaces/default/pods/tomcat-test/ephemeralcontainers -f a.json kubectl attach -it -c debugger tomcat-test 附加退出后不能在进入临时容器 临时容器特别适合包含主容器剥离出来的一些调试工具,在需要的时候临时注入到目标pod中 在pod中添加临时容器之后,目前还无法删除,同时如果这时候临时容器已经退出,会导致无法再次attach,也不会被拉起(临时容器不支持probe),相关的issue:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 如果attach了临时容器,然后退出了容器主进程(和前面示例中展示的那样),会导致这个容器无法再attach,也无法重新启动。此时,如果要重复上述步骤再次进行调试,需要新创建一个临时容器,同时还需要保留老的配置,否则k8s会拒绝新的配置: { "apiVersion" : "v1" , "kind" : "EphemeralContainers" , "metadata" : { "name" : "tomcat-test" } , "ephemeralContainers" : [ { "command" : [ "sh" ] , "image" : "busybox" , "imagePullPolicy" : "IfNotPresent" , "name" : "debugger" , "stdin" : true , "tty" : true , "targetContainerName" : "tomcat-java" , "terminationMessagePolicy" : "File" } , { "command" : [ "sh" ] , "image" : "busybox" , "imagePullPolicy" : "IfNotPresent" , "name" : "debugger1" , "stdin" : true , "tty" : true , "targetContainerName" : "tomcat-java" , "terminationMessagePolicy" : "File" } ] } 配置文件需要做这样的修改,再新增一个临时容器。重新修改后pod的状态(describe结果): [ root@] # kubectl replace --raw /api/v1/namespaces/default/pods/tomcat-test/ephemeralcontainers -f a.json kubectl attach -it tomcat-test -c debugger1
# k3s1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 k3s是经过CNCF认证的由Rancher公司开发维护的一个轻量级的 Kubernetes 发行版,内核机制还是和 k8s 一样,但是剔除了很多外部依赖以及 K8s 的 alpha、beta 特性,同时改变了部署方式和运行方式,目的是轻量化 K8s,简单来说,K3s 就是阉割版 K8s,消耗资源极少。它主要用于边缘计算、物联网等场景。K3s 具有以下特点: 1 、安装简单,占用资源少,只需要512M内存就可以运行起来; 2 、apiserver 、schedule 等组件全部简化,并以进程的形式运行在节点上,把程序都打包为单个二进制文件,每个程序只需要占用100M内存; 3 、使用基于sqlite3的轻量级存储后端作为默认存储机制。同时支持使用etcd3、MySQL 和PostgreSQL作为存储机制; 4 、默认使用 local-path-provisioner 提供本地存储卷; 5 、默认安装了Helm controller 和 Traefik Ingress controller; 6 、所有 Kubernetes control-plane 组件的操作都封装在单个二进制文件和进程中,使 K3s 具有自动化和管理包括证书分发在内的复杂集群操作的能力。 7 、减少外部依赖,操作系统只需要安装较新的内核(centos7.6就可以,不需要升级内核)以及支持cgroup即可,k3s安装包已经包含了containerd、Flannel、CoreDNS,非常方便地一键式安装,不需要额外安装Docker、Flannel等组件。 K3s 适用于以下场景: 1 、边缘计算-Edge 2 、物联网-IoT 3 、CI:持续集成 4 、Development:开发 5 、ARM 6 、嵌入 K8s 由于运行 K3s 所需的资源相对较少,所以 K3s 也适用于开发和测试场景。在这些场景中,如果开发或测试人员需要对某些功能进行验证,或对某些问题进行重现,那么使用 K3s 不仅能够缩短启动集群的时间,还能够减少集群需要消耗的资源。与此同时,Rancher 中国团队推出了一款针对 K3s 的效率提升工具:AutoK3s。只需要输入一行命令,即可快速创建 K3s 集群并添加指定数量的 master 节点和 worker 节点。
# k3s 架构
1 2 3 4 5 k3s server节点是运行k3s server命令的机器(裸机或者虚拟机),而k3s Agent 节点是运行k3s agent命令的机器。 单点架构只有一个控制节点(在 K3s 里叫做server node,相当于 K8s 的 master node),而且K3s的数据存储使用 sqlite 并内置在了控制节点上 在这种配置中,每个 agent 节点都注册到同一个 server 节点。K3s 用户可以通过调用server节点上的K3s API来操作Kubernetes资源。
1 2 3 4 5 6 7 8 9 10 虽然单节点 k3s 集群可以满足各种用例,但对于 Kubernetes control-plane 的正常运行至关重要的环境,可以在高可用配置中运行 K3s。一个高可用 K3s 集群由以下几个部分组成: 1、K3s Server 节点:两个或者更多的server节点将为 Kubernetes API 提供服务并运行其他 control-plane 服务 2、外部数据库:外部数据存储(与单节点 k3s 设置中使用的嵌入式 SQLite 数据存储相反) k3s和k8s如何选择 K8s和k3s各有优劣。若是你要进行大型的集群部署,建议你选择使用K8s;若是你处于边缘计算等小型部署的场景或仅仅须要部署一些非核心集群进行开发/测试,那么选择k3s则是性价比更高的选择。 云计算场景用k8s 边缘计算场景用k3s
# 安装 k3s快速入门指南 | K3s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 在192.168.40.180和192.168.40.181新机器初始化操作你们自己去做: 参考安装k8s时候的初始化去做就可以了 配置yum源 关掉防火墙 关掉selinux 修改内核参数 关掉swap交换分区 在192.168.40.180和192.168.40.181上安装containerd [root@localhost ~ ] 启动containerd [root@localhost ~ ] 国内用户可以用如下方法:安装速度会更快 在192.168.40.180上操作: curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn sh - 提取join token 我们想要添加一对worker节点。在这些节点上安装K3s,我们需要一个join token。Join token存在于master节点的文件系统上。让我们复制并将它保存在某个地方,稍后我们可以获取它: cat /var/lib/rancher/k3s/server/node-token 获取到一串token: K1048a0844cf602b7c96a4ea98a0a3531298e78262ba19875bd31a92ffc56686f63::server:698e6bc453d5871cbb1a4741387824b0 在192.168.40.181上执行如下,把work节点加入k3s: curl -sfL http://rancher-mirror.cnrancher.com/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn K3S_URL=https://192.168.40.186:6443 K3S_TOKEN=K105914c0b8bc0c8056a958ae90d0c2e5bf755d470cda85626aef879c8956ba95e4::server:bcdeca25ed8372d9f1bc983f0efb119e sh - 验证work节点是否加入集群: 在192.168.40.180操作: k3s kubectl get nodes
# openshift1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 OpenShift 是红帽 Red Hat 公司开源的平台,是平台即服务(PaaS),是一种容器应用平台。允许开发人员构建、测试和部署应用。在 OpenShift 上可以进行开发、测试、部署、运维全流程,实现高度的自动化,满足企业中的应用持续集成和交付及部署的需求,同时也满足企业对于容器管理(Docker)、容器编排(K8S)的需求。 Openshift 是首个支持企业级 Java 的 PaaS 平台,支持 JEE6 与 JBoss 和其 Eclipse 集成开发环境以及 Maven 和 Jenkins 自动化。 OpenShift通常被称为容器应用平台,因为它是一个用于开发和部署容器的平台。OpenShift底层以Docker作为容器引擎驱动,以K8s作为容器编排引擎组件,并提供了开发语言,中间件,DevOps自动化流程工具和web console用户界面等元素,提供了一套完整的基于容器的应用云平台。 OpenShift功能 容器引擎:docker; 容器编排:kubernetes; 应用开发框架及中间件:Java、Python、Tomcat、MySQL、PHP、Ruby、MongoDB和JBoss等中间件; 应用及服务目录:用户可一键部署各类应用及服务; 自动化流程及工具:内置自动化流程工具S2I(Source to Image),用户可完成代码编译、构建和镜像发布; 软件定义网络:提供 OpenVSwitch,实现跨主机共享网络及多租户隔离网络模式; 性能监控及日志管理:内置 Prometheus 监控功能,用户可以通过 Grafana 仪表板上实时显示应用; 多用户接口:提供友好的 UI、命令行工具(oc,类似于 K8S 的 kubectl 以及 RESTful API,基本与 K8S 兼容); 自动化集群部署及管理:通过 Ansible 实现集群的自动化部署,为集群的自动化扩容提供接口。 OpenShift 与 K8S的区别 概念:OpenShift 是 PaaS(平台即服务),K8S 是 CaaS(容器即服务),OpenShift 内置了Kubernetes。OpenShift 底层以 Docker 作为容器引擎驱动,以 Kubernetes 作为容器编排引擎组件。 部署:OpenShift 可以安装在 RHEL(Red Hat Enterprise Linux)和 RHELAH(Red Hat Eneterprise Linux Atomic Host)、CentOS 和 Fedora上;K8S 最好在 Unbuntu、Fedora、centos 和 Debian上运行,可部署在任何主要的 IaaS 上,如 IBM、AWS、Azure、GCP 和阿里云等云平台上。 网络:OpenShift 提供了开箱即用的本机网络解决方案,即 OpenvSwitch,它提供三种不同的插件;K8S 没有本机网络解决方案,但提供可供第三方网络插件使用的接口。 OpenShift 与 K8S相同点 OpenShift 集成了原生的 K8S 作为容器编排组件,提供容器集群的管理,为业务应用可以提供: 容器调度:根据业务的要求,快速部署容器到达指定的目标状态; 弹性伸缩:应用可以快速的扩缩容pod的实例数量; 异常修复:在容器实例发生异常时,集群可以自动发现问题、处理并恢复应用服务的状态; 持久化卷:为集群中的不同机器上的容器提供持久化卷的对接功能; 服务发现:可以提供负载均衡及服务发现功能; 配置管理:为业务应用提供灵活的配置管理和分发规则。 Openshift基础组件 在OpenShift中,Kubernetes管理容器化应用程序,并为部署、维护和应用程序扩展提供机制。Kubernetes集群由一个或多个Master节点和一组Node节点组成。 Master节点 主控节点。包括API Server、Controller Manager Server和Etcd。主控节点管理其Kubernetes集群中的Node节点,并安排pod在这些节点上运行。 Node节点 Node节点为容器提供运行时环境。Kubernetes集群中的每个Node节点都有需要由Master节点管理的服务。该节点还具有运行pods所需的服务,包括容器运行时、kubelet和服务代理。 openshift基本概念 以下将提供有关使用OpenShift时将遇到的核心概念和对象的高级体系结构信息。其中许多对象来自Kubernetes, OpenShift对Kubernetes进行了扩展,以提供功能更丰富的开发生命周期平台。 Project Project是一个带有附加注释的Kubernetes名称空间,是管理普通用户访问资源的中心媒介。用户必须由管理员提供相关的权限,或者如果允许创建项目,则自动访问自己的项目。 Namespaces Kubernetes命名空间提供了一种用于划分集群中资源的机制。在OpenShift中,Project是带有附加注释的Kubernetes命名空间。 Users 与OpenShift交互的用户。OpenShift用户对象表示一个参与者,可以通过向其添加角色或向其组添加角色来授予该参与者在系统中的权限。 Pod 运行于Node节点上,若干相关容器的组合。Pod内包含的容器运行在同一宿主机上,使用相同的网络命名空间、IP地址和端口,能够通过localhost进行通信。Pod是Kurbernetes进行创建、调度和管理的最小单位,它提供了比容器更高层次的抽象,使得部署和管理更加灵活。一个Pod可以包含一个容器或者多个相关容器。 Service Service定义了Pod的逻辑集合和访问该集合的策略,是真实服务的抽象。Service提供了一个统一的服务访问入口以及服务代理和发现机制,关联多个相同Label的Pod,用户不需要了解后台Pod是如何运行。 Router Service提供了一个通往后端Pod集群的稳定入口,但是Service的IP地址只是集群内部的节点和容器可见。外部需通过Router(路由器)来转发。Router组件是Openshift集群中一个重要的组件,它是外界访问集群内容器应用的入口。用户可以创建Route(路由规则)对象,一个Route会与一个Service关联,并绑定一个域名。 Persistent Storage 容器默认是非持久化的,所有的修改在容器销毁时都会丢失。Docker提供了持久化卷挂载的能力,Openshift除了提供持久化卷挂载的能力,还提供了一种持久化供给模型即PV(Persistent Volume)和PVC(Persistent Volume Claim)。用户在部署应用时显示的声明对持久化的需求,创建PVC,在PVC中定义所需要的存储大小,访问方式。OpenShift集群会自动寻找符合要求的PV与PVC自动对接。 Registry Openshift内部的镜像仓库,主要用于存放内置的S2I构建流程所产生的镜像。 S2I Source to Image,负责将应用源码构建成镜像。
# 安装 openshift&ansible1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 安装ansible 初始化 1.1.12 修改网卡配置文件 [root@master ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33 最后追加如下内容: NM_CONTROLLED=yes 修改好之后重启网络 service network restart [root@node1~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33 最后追加如下内容: NM_CONTROLLED=yes 修改好之后重启网络 service network restart [root@node2 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33 最后追加如下内容: NM_CONTROLLED=yes 修改好之后重启网络 service network restart 1.1.13 停掉NetworkManager [root@master ~]# systemctl stop NetworkManager [root@master ~]# systemctl disable NetworkManager [root@node1 ~]# systemctl stop NetworkManager [root@node1 ~]# systemctl disable NetworkManager [root@node2 ~]# systemctl stop NetworkManager [root@node2 ~]# systemctl disable NetworkManager 1.1.14 安装ansible 把ansible-2.6.5-1.el7.ans.noarch.rpm上传到master、node1、node2上 [root@master ~]#yum install ansible-2.6.5-1.el7.ans.noarch.rpm -y [root@node1~]#yum install ansible-2.6.5-1.el7.ans.noarch.rpm -y 把openshift-ansible-release-3.10.zip上传到master节点,手动解压: [root@master ~]#unzip openshift-ansible-release-3.10.zip 1.2.2 安装和配置docker [root@master ~]#yum install -y docker-1.13.1 [root@node1~]#yum install -y docker-1.13.1 1)修改docker配置文件 [root@master ~]# vim /etc/sysconfig/docker 把之前的OPTIONS注释掉 #OPTIONS='--selinux-enabled --log-driver=journald --signature-verification=false' 新增如下内容: OPTIONS='--selinux-enabled --signature-verification=False' [root@node1~]# vim /etc/sysconfig/docker 把之前的OPTIONS注释掉 #OPTIONS='--selinux-enabled --log-driver=journald --signature-verification=false' 新增如下内容: OPTIONS='--selinux-enabled --signature-verification=False' 2)配置docker镜像加速器 [root@node1 ~]# systemctl start docker [root@node2 ~]# systemctl start docker [root@master ~]# cat /etc/docker/daemon.json {"registry-mirrors": ["http://6e9e5b27.m.daocloud.io","https://registry.docker-cn.com"], "insecure-registries":["192.168.40.180:5000"] } [root@node1 ~]# cat /etc/docker/daemon.json {"registry-mirrors": ["http://6e9e5b27.m.daocloud.io","https://registry.docker-cn.com"], "insecure-registries":["192.168.40.180:5000"] } 3)重启docker [root@master ~]# systemctl restart docker [root@node1~]# systemctl restart docker 4)配置私有镜像仓库 [root@master ~]# docker load -i registry.tar.gz [root@master ~]# yum install httpd -y [root@master ~]# systemctl start httpd [root@master ~]# systemctl enable httpd [root@master ~]# mkdir -p /opt/registry-var/auth/ [root@master ~]# docker run --entrypoint htpasswd registry:2.5 -Bbn xianchao xianchao >> /opt/registry-var/auth/htpasswd 设置配置文件 [root@master ~]# mkdir -p /opt/registry-var/config [root@master ~]# vim /opt/registry-var/config/config.yml version: "0.1" log: fields: service: registry storage: delete: enabled: true cache: blobdescriptor: inmemory filesystem: rootdirectory: /var/lib/registry http: addr: :5000 headers: X-Content-Type-Options: [nosniff] health: storagedriver: enabled: true interval: 10s threshold: 3 启动服务 docker run -d -p 5000:5000 --restart=always --name=registry -v /opt/registry-var/config/:/etc/docker/registry/ -v /opt/registry-var/auth/:/auth/ -e "REGISTRY_AUTH=htpasswd" -e "REGISTRY_AUTH_HTPASSWD_REALM=Registry Realm" -e REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd -v /opt/registry-var/:/var/lib/registry/ registry:2.5 1.2.3 登录镜像仓库 [root@master ~]#docker login 192.168.40.180:5000 用户名: 密码: [root@node1~]#docker login 192.168.40.180:5000 用户名: 密码: 1.2.4 修改docker存储 1)设置docker开机自启动 systemctl enable docker systemctl is-active docker 2)所有节点更改/etc/sysconfig/docker-storage-setup如下: DEVS=/dev/sdb VG=docker-vg 3)所有Node节点执行docker-storage-setup docker-storage-setup 1.2.5 解压镜像 [root@node1 ~]# docker load -i openshift_slave_3_10.tar.gz [root@node2 ~]# docker load -i openshift_slave_3_10.tar.gz 1.3、安装并访问openshift 1.3.1 配置ansible的hosts文件 [root@master ~]# cat /etc/ansible/hosts [OSEv3:children] masters nodes etcd [OSEv3:vars] openshift_deployment_type=origin ansible_ssh_user=root ansible_become=yes openshift_repos_enable_testing=true openshift_enable_service_catalog=false template_service_broker_install=false debug_level=4 openshift_clock_enabled=true openshift_version=3.10.0 openshift_image_tag=v3.10 openshift_disable_check=disk_availability,docker_storage,memory_availability,docker_image_availability,os_sdn_network_plugin_name=redhat/openshift-ovs-multitenant i openshift_master_identity_providers=[{'name': 'htpasswd_auth','login': 'true', 'challenge': 'true','kind': 'HTPasswdPasswordIdentityProvider'}] [masters] master [nodes] master openshift_node_group_name='node-config-master' node1 openshift_node_group_name='node-config-master' node2 openshift_node_group_name='node-config-master' [etcd] master 1.3.2 安装openshift 1)安装前预配置检查 [root@master ~]#ansible-playbook -i /etc/ansible/hosts openshift-ansible-release-3.10/playbooks/prerequisites.yml 3)安装 执行deploy时主机dns导致连外网失败(在执行上面deploy时,需要在每个节点ping www.baidu.com,如果ping不通,解决方案如下) 临时解决方案更改/etc/resolv.conf 当部署的时候看到retry,就需要在master和node节点执行下面命令,这样就可以继续ping通外网 [root@master ~]#echo nameserver 8.8.8.8 >>/etc/resolv.conf 可以写个计划任务: crontab -e * */1 * * * /usr/sbin/ntpdate cn.pool.ntp.org * * * * * /usr/bin/echo nameserver 8.8.8.8 >>/etc/resolv.conf [root@master ~]# ansible-playbook -i /etc/ansible/hosts openshift-ansible-release-3.10/playbooks/deploy_cluster.yml 需要给节点打标签 TASK [openshift_manage_node : Set node schedulability] 到这个task之后执行下面部分 [root@master ~]#oc label node node1 node-role.kubernetes.io/infra=true
# 登录 openshift1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 1.3.3 登录openshift 首次新建用户密码 htpasswd -cb /etc/origin/master/htpasswd admin admin 添加用户密码 htpasswd -b /etc/origin/master/htpasswd dev dev 以集群管理员登录 oc login -u system:admin 给用户分配一个集群管理员角色 oc adm policy add-cluster-role-to-user cluster-admin admin 浏览器登录openshift,配置自己电脑hosts文件 https://master:8443/console/catalog 1.3.4 openshift内部私有仓库使用 Master上执行如下,获取admin密码 oc login -n openshift admin/admin oc whoami -t eYtOZNGab9w4IO_LX2sHEHyoAZHOy1oxJ9gEsuJVMpI 每个节点执行如下登陆openshift私有镜像仓库 docker login docker-registry.default.svc:5000 用户:admin 密码:eYtOZNGab9w4IO_LX2sHEHyoAZHOy1oxJ9gEsuJVMpI
# openshift 部署应用程序 1 2 3 4 使用OpenShift时,可以通过多种方式添加应用程序。 主要方法是: 1.通过已经存在的docker镜像部署应用程序 2.使用Source-to-Image的方式部署应用程序(Source-to-Image简称S2I:从代码仓库拉取代码,构建成镜像,基于此镜像部署应用程序) 3.在dockerfile中通过指定git仓库地址构建程序
# openshift CICD1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 一、CI/CD工具链涉及到的组件介绍 1、gogs: Gogs 是一款极易搭建的自助 Git 服务,类似于github这种代码托管系统;以最简便的方式搭建简单、稳定和可扩展的自助 Git 服务。使用 Go 语言开发使得 Gogs 能够通过独立的二进制分发,并且支持 Go 语言支持的 所有平台,包括 Linux、macOS、Windows 以及 ARM 平台。 功能特性 官方文档 https://gogs.io/docs/intro github上的中文站点: https://github.com/gogs/gogs/blob/master/README_ZH.md 2、nexus是一个私服 为什么搭建nexus? 为什么要搭建nexus私服,原因很简单,有些公司都不提供外网给项目组人员,因此就不能访问maven中央仓库,或者公司内部的jar包在外网无法找到,所以很有必要在局域网里使用一台有外网权限的机器,搭建nexus私服,然后开发人员连到这台私服上,这样的话就可以通过这台搭建了nexus私服的电脑访问maven的远程仓库,或者从上面下载内部jar包,使得开发人员可以下载仓库中的内容,而且对于下载过的文件,局域网内下载会更加快速。还有一点优势在于,我们需要的jar包可能在中央仓库中没有,需要去其他地方下载,有了中央仓库,只需要一人找到jar包其他人就不用再去上网搜索jar包,十分方便。 3、sonarqube: 代码扫描工具 4、jenkins 二、创建CI/CD流 OpenShift DevOps/CICD工作流 1.从gogs或者gitlab克隆代码 2.通过maven构建war包 3.单元测试 4.Sonarqube静态代码扫描 5.war包归档到Nexus 6.构建docker image 7.把镜像上传到harbor镜像仓库 8.部署到dev(开发)环境 9.部署到测试环境-集成测试 10.管理员promote(同意) or abort(不同意) 11.部署到stage(生产)环境 官网地址: https://github.com/siamaksade/openshift-cd-demo/tree/origin-1.3
# 排错1 2 3 4 5 6 7 8 1 、两台机器部署Keepalive出现双vip,如何排查? 添加如下参数 unicast_src_ip 192.168 .0 .29 unicast_peer { 192.168 .0 .186 }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 2. jenkins 一定要最新的 3 、kubeadm初始化k8s集群报错failed to parse kernel config:unable to load kernel module:”configs 答: Kubeadm初始化k8s,会检测configs模块,configs模块现在centos操作系统不在维护了,可以忽略这个检查,那么kubeadm 初始化只需要加上参数--ignore-preflight-errors=SystemVerification即可 4 .浏览器显示非私密连接 在google浏览器中,在上图出现的页面任意位置,直接键盘敲入这11个字符:thisisunsafe,可以直接跳过安全报错进入页面 5. centos8的yum源无法使用(dockerfile基于centos构建镜像报错Failed to download metadata for repo ‘appstream’: Cannot prepare internal mirrorlist: No URLs in mirrorlist) vim Centos-vault-8.5.2111.repo [base ] name=CentOS-8.5.2111 - Base - mirrors.aliyun.com baseurl=http://mirrors.aliyun.com/centos-vault/8.5.2111/BaseOS/$basearch/os/ http://mirrors.aliyuncs.com/centos-vault/8.5.2111/BaseOS/$basearch/os/ http://mirrors.cloud.aliyuncs.com/centos-vault/8.5.2111/BaseOS/$basearch/os/ gpgcheck=0 gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-Official [extras ] name=CentOS-8.5.2111 - Extras - mirrors.aliyun.com baseurl=http://mirrors.aliyun.com/centos-vault/8.5.2111/extras/$basearch/os/ http://mirrors.aliyuncs.com/centos-vault/8.5.2111/extras/$basearch/os/ http://mirrors.cloud.aliyuncs.com/centos-vault/8.5.2111/extras/$basearch/os/ gpgcheck=0 gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-Official [centosplus ] name=CentOS-8.5.2111 - Plus - mirrors.aliyun.com baseurl=http://mirrors.aliyun.com/centos-vault/8.5.2111/centosplus/$basearch/os/ http://mirrors.aliyuncs.com/centos-vault/8.5.2111/centosplus/$basearch/os/ http://mirrors.cloud.aliyuncs.com/centos-vault/8.5.2111/centosplus/$basearch/os/ gpgcheck=0 enabled=0 gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-Official [PowerTools ] name=CentOS-8.5.2111 - PowerTools - mirrors.aliyun.com baseurl=http://mirrors.aliyun.com/centos-vault/8.5.2111/PowerTools/$basearch/os/ http://mirrors.aliyuncs.com/centos-vault/8.5.2111/PowerTools/$basearch/os/ http://mirrors.cloud.aliyuncs.com/centos-vault/8.5.2111/PowerTools/$basearch/os/ gpgcheck=0 enabled=0 gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-Official [AppStream ] name=CentOS-8.5.2111 - AppStream - mirrors.aliyun.com baseurl=http://mirrors.aliyun.com/centos-vault/8.5.2111/AppStream/$basearch/os/ http://mirrors.aliyuncs.com/centos-vault/8.5.2111/AppStream/$basearch/os/ http://mirrors.cloud.aliyuncs.com/centos-vault/8.5.2111/AppStream/$basearch/os/ gpgcheck=0 gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-Official 6 .云主机安全组放行端口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 删除kubeadm安装的k8s集群,重新搭建 在k8s集群的每个节点执行kubeadm reset即可,这个命令是重置k8s集群,会清空k8s所有组件和资源。 7. yum install 报错 yum clean all yum makecache -y yum install epel-release -y yum update -y 8 .删除k8s名称空间一直报错Terminating kubectl get namespace app-team1 -o json > temp.json 修改temp.json文件 删除框住的部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 再开启一个新的终端执行如下: root@master1:~# kubectl proxy 另一个终端执行如下: root@master1:~# curl -k -H "Content-Type: application/json" -X PUT --data-binary @temp.json http://127.0.0.1:8001/api/v1/namespaces/app-team1/finalize 11、基于kubectl run busybox2 --image busybox:1.28 --restart=Never --rm -it busybox – sh 创建的pod,无法ping www.baidu.com 首先把安装k8s的所有机器重启,然后重新创建pod,如果重启之后还是ping不通www.baidu.com,可以按照如下方法解决: 进入pod 打开/etc/resolv.conf,最后添加nameserver 8.8.8.8 在search这增加域名www.baidu.com即可 12.containerd如果作为容器运行时,用ctr拉取镜像,需要写镜像完成的路径才可以 ctr images pull docker.io/library/busybox:1.28
# pod1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 部分工作节点上的pod一直处于ContainerCreating的状态 kubectl get pods -o wide | grep tomcat NAME READY STATUS RESTARTS AGE IP NODE tomcat-pod 0 /1 ContainerCreating 0 106s 10.244 .1 .4 k8s-node1 kubectl describe pods tomcat-pod 一、pending状态 Pending是挂起状态:表示创建的Pod找不到可以运行它的物理节点,不能调度到相应的节点上运行,那么这种情况如何去排查呢?我门可以从两个层面分析问题: 1 .物理节点层面分析: 1 )查看节点资源使用情况:如free -m查看内存、top查看CPU使用率、df –h查看磁盘使用情况,这样就可以快速定位节点资源情况,判断是不是节点有问题 2 )查看节点污点:kubectl describe nodes master1(控制节点名字),如果节点定义了污点,那么Pod不能容忍污点,就会导致调度失败,如下: Taints: node-role.kubernetes.io/master:NoSchedule 这个看到的是控制节点的污点,表示不允许Pod调度(如果Pod定义容忍度,则可以实现调度) 2. Pod本身分析 1 )在定义pod时,如果指定了nodeName是不存在的,那也会调度失败 2 )在定义Pod时,如果定义的资源请求比较大,导致物理节点资源不够 如何排查,可按如下分析: 3 )在定于pod时,如果制定了node节点应亲和性或者nodeselector,那么没有满足的条件,也会pending状态 二、ImagePullBackOff状态 问题分析: 拉取镜像时间长导致超时: 配置的镜像有错误:如镜像名字不存在等 配置的镜像无法访问:如网络限制无法访问hub上的镜像 配置的私有镜像仓库参数错误:如imagePullSecret没有配置或者配置错误 dockerfile打包的镜像不可用 排查思路: kubectl get pods -o wide 显示如下: tomcat-pod 0 /1 ImagePullBackOff 0 105s 通过上面可以看到镜像拉取有问题,那可以进一步再排查错误 kubectl describe pods tomcat-pod 显示如下: Normal BackOff 96s (x7 over 6m15s) kubelet Back-off pulling image "atomcat:8.5-jre8-alpine" 可以在宿主机通过docker pull手动验证是否可以正常拉取镜像 docker pull atomcat:8.5-jre8-alpine 报错: Error response from daemon: pull access denied for atomcat, repository does not exist or may require 'docker login': denied: requested access to the resource is denied 那就说明我们使用的镜像有问题,需要重新更改镜像地址 三、CrashLoopBackOff状态 K8s中的pod正常运行,但是里面的容器可能退出或者多次重启或者准备删除,导致出现这个状态,这个状态具有偶发性,可能上一秒还是running状态,但是突然就变成CrashLoopBackOff状态了。 1 )kubectl logs 查看日志,出现如下: standard_init_linux.go:216: exec user process caused "exec format error“ 解决方案: 查看构建镜像用的代码是否有问题,如果代码没问题,再看环境变量是否有问题,可能权限问题:假如pod挂载了数据目录,这个数据目录,我们需要修改属主和属组,否则pod往这个目录写数据,可能没权限 2)kubectl describe pods 查看详细信息 四、Evicted状态 这个Evicted表示pod所在节点的资源不够了,pod被驱逐走了 五、Complete状态 这个状态表示pod里面的任务完成了,job或者cronjob创建pod的时候,如果pod任务完成了,会出现这个complete状态 六、error状态 15、pod健康探测 pod定义的存活性探测如下: livenessProbe: httpGet: path: / port: 8080 常见错误: Killing container with id docker://:Container failed probe.. Container will be killed and recreated. Liveness 如果在pod启动时遇到这种情况,一般是没有设置 initialDelaySeconds导致的 # 设置初始化延迟initialDelaySeconds。 livenessProbe: httpGet: path: / port: 8080 initialDelaySeconds: 15 # pod启动过15s开始探测 15、pod服务超时 K8S中Pod服务连接超时主要分以下几种情况: 1.Pod和Pod连接超时 2.Pod和虚拟主机上的服务连接超时 3.Pod和云主机连接超时 针对上面几种问题,排查思路可按下面方法: 网络插件层面: 查看calico或者flannel是否是running状态,查看日志提取重要信息 Pod层面: 检查Pod网络,测试Pod是否可以ping通同网段其他pod ip 物理机层面: 检查物理机网络,测试ping www.baidu.com,ping其他的pod ip 可以抓包测试有无异常 通过抓包修改内核参数 16、service代理pod出现问题 直接访问pod可以请求到,但是访问pod前端service,通过请求pod有问题,请求不到。 iptables: 重启iptables,重启iptables不可以,重启下机器 ipvs:重启机器
# Tekton1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 Tekton 是一个功能强大且灵活的 Kubernetes 原生开源框架,是谷歌开源的,功能强大且灵活,开源社区也正在快速的迭代和发展壮大,主要用于创建持续集成和交付(CI/CD)系统。通过抽象底层实现细节,用户可以跨多云平台和本地系统进行构建、测试和部署。另外,基于kubernetes CRD定义的pipeline流水线也是Tekton最重要的特征。 CRD全称是CustomResourceDefinition: 在 Kubernetes 中一切都可视为资源,Kubernetes 1.7 之后增加了对 CRD 自定义资源二次开发能力来扩展 Kubernetes API,通过 CRD 我们可以向 Kubernetes API 中增加新资源类型,而不需要修改 Kubernetes 源码来创建自定义的 API server,该功能大大提高了 Kubernetes 的扩展能力。当你创建一个新的CustomResourceDefinition (CRD)时,Kubernetes API服务器将为你指定的每个版本创建一个新的RESTful资源路径,我们可以根据该api路径来创建一些我们自己定义的类型资源。CRD可以是命名空间的,也可以是集群范围的,由CRD的作用域(scpoe)字段中所指定的,与现有的内置对象一样,删除名称空间将删除该名称空间中的所有自定义对象。customresourcedefinition本身没有名称空间,所有名称空间都可以使用。 持续集成是云原生应用的支柱技术之一,因此在交付基于云原生的一些支撑产品的时候,CICD 是非常好的方案。为了满足这种需要,自然而然会想到对Jenkins(X)或者 Gitlab 进行集成,也有创业公司出来的一些小工具比如 Argo Rollout。Tekton 是一款 k8s 原生的应用发布框架,主要用来构建 CI/CD 系统。它原本是 knative 项目里面一个叫做 build-pipeline 的子项目,用来作为 knative-build 的下一代引擎。然而,随着 k8s 社区里各种各样的需求涌入,这个子项目慢慢成长为一个通用的框架,能够提供灵活强大的能力去做基于 k8s 的构建发布。Tekton 其实只提供 Pipeline 这个一个功能,Pipeline 会被直接映射成 K8s Pod 等 API 资源。而比如应用发布过程的控制,灰度和上线策略,都是我们自己编写 K8s Controller来实现的,也就意味着 Tekton 不会在K8s 上盖一个”大帽子“,比如我们想看发布状态、日志等是直接通过 K8s 查看这个 Pipeline 对应的 Pod 的状态和日志,不需要再面对另外一个 API。 Tekton功能: 1. Kubernetes原生的Tekton的所有配置都是使用CRD方式进行编写存储的,非常易于检索和使用。 2 .配置和流程分离: Tekton的Pipeline和配置可以分开编写,使用名称进行引用。 3 .轻量级核心的Pipeline 非常轻便:适合作为组件进行集成,另外也有周边的 Dashboard、Trigger、CLI等工具,能够进一步挖掘其潜力。 4 .可复用、组合的 Pipeline 构建方式:非常适合在集成过程中对Pipeline进行定制。 这里的流程大致是: 1 、用户把需要部署的应用先按照一套标准的应用定义写成 YAML 文件(类似 Helm Chart); 2 、用户把应用定义 YAML 推送到 Git 仓库里; 3 、Tekton CD (一个 K8s Operator) 会监听到相应的改动,根据不同条件生成不同的 Tekton Pipelines; Tekton CD 的操作具体分为以下几种情况: 1 、如果 Git 改动里有一个应用 YAML 且该应用不存在,那么将渲染和生成 Tekton Pipelines 用来创建应用。 2 、如果 Git 改动里有一个应用 YAML 且该应用存在,那么将渲染和生成 Tekton Pipelines 用来升级应用。这里我们会根据应用定义 YAML 里的策略来做升级,比如做金丝雀发布、灰度升级。 3 、如果 Git 改动里有一个应用 YAML 且该应用存在且标记了“被删除”,那么将渲染和生成 Tekton Pipelines 用来删除应用。确认应用被删除后,我们才从 Git 里删除这个应用的 YAML。 安装Tekton [root@node1 ] [root@node1 ] [root@node2 ] [root@node2 ] [root@master1 ~ ] [root@master1 ~ ] NAME READY STATUS RESTARTS AGE tekton-pipelines-controller-d64889fb9-9b68f 1 /1 Running 0 52s tekton-pipelines-webhook-7c8664944c-ctsgf 1 /1 Running 0 52s [root@master1 ~ ] 找到下面这些东西,说明创建crd成功了: pipelineresources.tekton.dev 2021-08-21T13:52:16Z pipelineruns.tekton.dev 2021-08-21T13:52:16Z pipelines.tekton.dev 2021-08-21T13:52:16Z taskruns.tekton.dev 2021-08-21T13:52:16Z tasks.tekton.dev 2021-08-21T13:52:16Z [root@master1 ~ ] 看到下面说明apiversion创建成功了 tekton.dev/v1alpha1 tekton.dev/v1beta1 Tekton概念 Tekton 为Kubernetes 提供了多种 CRD 资源对象,可用于定义我们的流水线,主要有以下几个CRD资源对象: 1 )Task:表示执行命令的一系列步骤,task 里可以定义一系列的 steps,例如编译代码、构建镜像、推送镜像等,每个 step 实际由一个 Pod 里的容器执行。 2 )TaskRun:task只是定义了一个模版,taskRun 才真正代表了一次实际的运行,当然你也可以自己手动创建一个taskRun,taskRun创建出来之后,就会自动触发task描述的构建任务。 3 )Pipeline:一组任务,表示一个或多个task、PipelineResource 以及各种定义参数的集合。 4 )PipelineRun:类似task和taskRun的关系,pipelineRun也表示某一次实际运行的 pipeline,下发一个 pipelineRun CRD 实例到 Kubernetes后,同样也会触发一次 pipeline 的构建。 5 )PipelineResource:表示pipeline输入资源,比如github上的源码,或者pipeline 输出资源,例如一个容器镜像或者构建生成的jar包等。 我们测试一个简单的golang程序。应用程序代码,测试及dockerfile文件可在如下地址获取:https://github.com/luckylucky421/tekton-demo 3.8 .1 clone应用程序代码进行测试,创建一个task任务 [root@master1 ~ ] apiVersion: tekton.dev/v1beta1 kind: Task metadata: name: test spec: resources: inputs: - name: repo type: git steps: - name: run-test image: golang:1.14-alpine imagePullPolicy: IfNotPresent workingDir: /workspace/repo command: ["go" ] args: ["test" ] [root@master1 ~ ] task.tekton.dev/test created [root@master1 ~ ] NAME AGE test 23s resources定义了我们的任务中定义的步骤中需要输入的内容,这里我们的步骤需要 Clone 一个 Git 仓库作为 go test 命令的输入。Tekton 内置了一种 git 资源类型,它会自动将代码仓库 Clone 到 /workspace/$input_name 目录中,由于我们这里输入被命名成 repo,所以代码会被 Clone 到 /workspace/repo 目录下面。然后下面的 steps 就是来定义执行运行测试命令的步骤,这里我们直接在代码的根目录中运行 go test 命令即可,需要注意的是命令和参数需要分别定义。 创建pipelineresource资源对象 通过上面步骤我们定义了一个 Task 任务,但是该任务并不会立即执行,我们必须创建一个 TaskRun 引用它并提供所有必需输入的数据才行。这里我们就需要将 git 代码库作为输入,我们必须先创建一个 PipelineResource 对象来定义输入信息,创建一个名为 pipelineresource.yaml 的资源清单文件,内容如下所示: [root@master1 ~ ] apiVersion: tekton.dev/v1alpha1 kind: PipelineResource metadata: name: -tekton-example spec: type: git params: - name: url value: https://github.com/luckylucky421/tekton-demo - name: revision value: master [root@master1 ~ ] 创建taskrun任务 [root@master1 ~ ] apiVersion: tekton.dev/v1beta1 kind: TaskRun metadata: name: testrun spec: taskRef: name: test resources: inputs: - name: repo resourceRef: name: -tekton-example [root@master1 ~ ] 这里通过taskRef引用上面定义的Task和git仓库作为输入,resourceRef也是引用上面定义的PipelineResource资源对象。 [root@master1 ~ ] NAME SUCCEEDED REASON STARTTIME testrun Unknown Running 6s [root@master1 ~ ] NAME READY STATUS RESTARTS AGE testrun-pod-x9rkn 2 /2 Running 0 9s 当任务执行完成后, Pod 就会变成 Completed 状态了: [root@master1 ~ ] NAME READY STATUS RESTARTS AGE testrun-pod-x9rkn 0 /2 Completed 0 72s
# 创建自定义资源1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 apiVersion: apiextensions.k8s.io/v1 kind: CustomResourceDefinition metadata: name: crontabs.stable.example.com spec: group: stable.example.com versions: - name: v1 served: true storage: true schema: openAPIV3Schema: type: object properties: spec: type: object properties: cronSpec: type: string image: type: string replicas: type: integer scope: Namespaced names: plural: crontabs singular: crontab kind: CronTab shortNames: - ct Yaml文件注解: metadata.name 是用户自定义资源中自己自定义的一个名字。一般我们建议使用“顶级域名.xxx.APIGroup”这样的格式,名称必须与下面的spec.Group字段匹配,格式为: <plural>.<group> spec 用于指定该 CRD 的 group、version。比如在创建 Pod 或者 Deployment 时,它的 group 可能为 apps/v1 或者 apps/v1beta1 之类,这里我们也同样需要去定义 CRD 的 group。 group: stable.example.com versions: - name: v1 served: true storage: true scope: Namespaced names 指的是它的 kind 是什么,比如 Deployment 的 kind 就是 Deployment,Pod 的 kind 就是 Pod,这里的 kind 被定义为了CronTab plural 字段就是一个昵称,比如当一些字段或者一些资源的名字比较长时,可以用该字段自定义一些昵称来简化它的长度; singular: crontab shortNames: - ct apiVersion: "stable.example.com/v1" kind: CronTab metadata: name: my-new-cron-object spec: cronSpec: "* * * * * *" image: busybox
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 1 、项目地址 https://github.com/mongodb/mongodb-kubernetes-operator.git 把课件里的压缩包传到k8s控制节点上来,手动解压 unzip mongodb-kubernetes-operator-0.5.0.zip 2 、创建名称空间mongodb,并进入到mongodb-kubernetes-operator目录应用crd资源,创建自定义资源类型 [root@master1 ~ ] kubectl create ns mongodb [root@master1 ~ ] [root@master1 mongodb-kubernetes-operator-0.5.0 ] kubectl get crd/mongodbcommunity.mongodb.com 3 、安装operator [root@master1 mongodb-kubernetes-operator-0.5.0 ] 提示:mongodb-kubernetes-operator这个项目是将自定义控制器和自定义资源类型分开实现的;其operator只负责创建和监听对应资源类型的变化,在资源有变化时,实例化为对应资源对象,并保持对应资源对象状态吻合用户期望状态;上述四个清单中主要是创建了一个sa账户,并对对应的sa用户授权; 验证:查看operator是否正常运行 [root@master1 mongodb-kubernetes-operator-0.5.0 ] NAME READY STATUS RESTARTS AGE mongodb-kubernetes-operator-7f8c55db45-tmpk5 1 /1 Running 0 44s 验证:使用自定义资源类型创建一个mongodb 副本集集群 [root@master1 mongodb-kubernetes-operator-0.5.0 ] [root@master1 mongodb-kubernetes-operator-0.5.0 ] [root@master1 mongodb-kubernetes-operator-0.5.0 ] NAME READY STATUS RESTARTS AGE example-mongodb-0 0 /2 Pending 0 66s 提示:这里可以看到对应pod处于pending状态; 查看pod详细信息 提示:这里提示没有可以用的pvc; 删除mongodb名称空间下pvc kubectl get pvc -n mongodb kubectl delete pvc --all -n mongodb 创建pv和pvc [root@master1 ~ ] apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv-v1 labels: app: example-mongodb-svc spec: capacity: storage: 1Gi volumeMode: Filesystem accessModes: ["ReadWriteOnce" ,"ReadWriteMany" ,"ReadOnlyMany" ] persistentVolumeReclaimPolicy: Retain mountOptions: - hard - nfsvers=4.1 nfs: path: /data/p1 server: 192.168 .40 .180 --- apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv-v2 labels: app: example-mongodb-svc spec: capacity: storage: 1Gi volumeMode: Filesystem accessModes: ["ReadWriteOnce" ,"ReadWriteMany" ,"ReadOnlyMany" ] persistentVolumeReclaimPolicy: Retain mountOptions: - hard - nfsvers=4.1 nfs: path: /data/p2 server: 192.168 .40 .180 --- apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv-v3 labels: app: example-mongodb-svc spec: capacity: storage: 1Gi volumeMode: Filesystem accessModes: ["ReadWriteOnce" ,"ReadWriteMany" ,"ReadOnlyMany" ] persistentVolumeReclaimPolicy: Retain mountOptions: - hard - nfsvers=4.1 nfs: path: /data/p3 server: 192.168 .40 .180 [root@master1 ~ ] [root@master1 ~ ] [root@master1 ~ ] [root@master1 ~ ] /data/v1 *(rw,no_root_squash) /data/p1 *(rw,no_root_squash) /data/p2 *(rw,no_root_squash) /data/p3 *(rw,no_root_squash) [root@master1 ~ ] [root@master1 ~ ] 创建pvc资源 [root@master1 ~ ] apiVersion: v1 kind: PersistentVolumeClaim metadata: name: data-volume-example-mongodb-0 namespace: mongodb spec: accessModes: - ReadWriteMany volumeMode: Filesystem resources: requests: storage: 500Mi --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: data-volume-example-mongodb-1 namespace: mongodb spec: accessModes: - ReadWriteMany volumeMode: Filesystem resources: requests: storage: 500Mi --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: data-volume-example-mongodb-2 namespace: mongodb spec: accessModes: - ReadWriteMany volumeMode: Filesystem resources: requests: storage: 500M [root@master1 ~ ] [root@master01 ~ ] NAME READY STATUS RESTARTS AGE example-mongodb-0 2 /2 Running 0 8m example-mongodb-1 2 /2 Running 0 111s example-mongodb-2 2 /2 Running 0 48s mongodb-kubernetes-operator-7d557bcc95-th8js 1 /1 Running 0 9m19s