# docker 底层原理 + capability
# Capability
Linux 是一种安全的操作系统,它把所有的系统权限都赋予了一个单一的 root 用户,只给普通用户保留有限的权限。root 用户拥有超级管理员权限,可以安装软件、允许某些服务、管理用户等。
作为普通用户,如果想执行某些只有管理员才有权限的操作,以前只有两种办法:一是通过 sudo 提升权限,如果用户很多,配置管理和权限控制会很麻烦;二是通过 SUID(Set User ID on execution)来实现,它可以让普通用户允许一个 owner 为 root 的可执行文件时具有 root 的权限。
SUID 虽然可以解决问题,但却带来了安全隐患。当运行设置了 SUID 的命令时,通常只是需要很小一部分的特权,但是 SUID 给了它 root 具有的全部权限。这些可执行文件是黑客的主要目标,如果他们发现了其中的漏洞,就很容易利用它来进行安全攻击。简而言之, SUID 机制增大了系统的安全攻击面。
为了对 root 权限进行更细粒度的控制,实现按需授权,Linux 引入了另一种机制叫 capabilities 。
Capabilities 机制是在 Linux 内核 2.2 之后引入的,原理很简单,就是将之前与超级用户 root(UID=0)关联的特权细分为不同的功能组,Capabilites 作为线程(Linux 并不真正区分进程和线程)的属性存在,每个功能组都可以独立启用和禁用。其本质上就是将内核调用分门别类,具有相似功能的内核调用被分到同一组中。
这样一来,权限检查的过程就变成了:在执行特权操作时,如果线程的有效身份不是 root,就去检查其是否具有该特权操作所对应的 capabilities,并以此为依据,决定是否可以执行特权操作。
Capabilities 可以在进程执行时赋予,也可以直接从父进程继承。所以理论上如果给 nginx 可执行文件赋予了 CAP_NET_BIND_SERVICE capabilities,那么它就能以普通用户运行并监听在 80 端口上。
| capability 名称 | 描述 |
|---|---|
| CAP_AUDIT_CONTROL | 启用和禁用内核审计;改变审计过滤规则;检索审计状态和过滤规则 |
| CAP_AUDIT_READ | 允许通过 multicast netlink 套接字读取审计日志 |
| CAP_AUDIT_WRITE | 将记录写入内核审计日志 |
| CAP_BLOCK_SUSPEND | 使用可以阻止系统挂起的特性 |
| CAP_CHOWN | 修改文件所有者的权限 |
| CAP_DAC_OVERRIDE | 忽略文件的 DAC 访问限制 |
| CAP_DAC_READ_SEARCH | 忽略文件读及目录搜索的 DAC 访问限制 |
| CAP_FOWNER | 忽略文件属主 ID 必须和进程用户 ID 相匹配的限制 |
| CAP_FSETID | 允许设置文件的 setuid 位 |
| CAP_IPC_LOCK | 允许锁定共享内存片段 |
| CAP_IPC_OWNER | 忽略 IPC 所有权检查 |
| CAP_KILL | 允许对不属于自己的进程发送信号 |
| CAP_LEASE | 允许修改文件锁的 FL_LEASE 标志 |
| CAP_LINUX_IMMUTABLE | 允许修改文件的 IMMUTABLE 和 APPEND 属性标志 |
| CAP_MAC_ADMIN | 允许 MAC 配置或状态更改 |
| CAP_MAC_OVERRIDE | 忽略文件的 DAC 访问限制 |
| CAP_MKNOD | 允许使用 mknod () 系统调用 |
| CAP_NET_ADMIN | 允许执行网络管理任务 |
| CAP_NET_BIND_SERVICE | 允许绑定到小于 1024 的端口 |
| CAP_NET_BROADCAST | 允许网络广播和多播访问 |
| CAP_NET_RAW | 允许使用原始套接字 |
| CAP_SETGID | 允许改变进程的 GID |
| CAP_SETFCAP | 允许为文件设置任意的 capabilities |
| CAP_SETPCAP | 参考 capabilities man page |
| CAP_SETUID | 允许改变进程的 UID |
| CAP_SYS_ADMIN | 允许执行系统管理任务,如加载或卸载文件系统、设置磁盘配额等 |
| CAP_SYS_BOOT | 允许重新启动系统 |
| CAP_SYS_CHROOT | 允许使用 chroot () 系统调用 |
| CAP_SYS_MODULE | 允许插入和删除内核模块 |
| CAP_SYS_NICE | 允许提升优先级及设置其他进程的优先级 |
| CAP_SYS_PACCT | 允许执行进程的 BSD 式审计 |
| CAP_SYS_PTRACE | 允许跟踪任何进程 |
| CAP_SYS_RAWIO | 允许直接访问 /devport、/dev/mem、/dev/kmem 及原始块设备 |
| CAP_SYS_RESOURCE | 忽略资源限制 |
| CAP_SYS_TIME | 允许改变系统时钟 |
| CAP_SYS_TTY_CONFIG | 允许配置 TTY 设备 |
| CAP_SYSLOG | 允许使用 syslog () 系统调用 |
| CAP_WAKE_ALARM | 允许触发一些能唤醒系统的东西 (比如 CLOCK_BOOTTIME_ALARM 计时器) |
# 不同 capabilities 带来的安全问题
Linux Capabilities - HackTricks
# CAP_SYS_ADMIN
Among other things this allows to mount devices or abuse release_agent to escape from the container.
即有了该权限,可以挂载设备,比如通过挂载实现 /etc/passwd 文件的替换,来获取 root 权限
1 | getcap -r / 2>/dev/null |
1 | from ctypes import * |
替换 x 的位置之后,root 的密码就变成了在 /etc/passwd 里面的密码,可以通过 su + 自己创建的密码获取权限
也可以实现挂载宿主机文件并随意访问
1 | fdisk -l #Get disk name |
或者如果 ssh 是开放的,那么可以在容器内挂载,并且找到开放的端口,ssh 连接宿主机
1 | #Like in the example before, the first step is to mount the docker host disk |
# CAP_SYS_PTRACE
通过在宿主机运行的进程中注入 shellcode 实现逃逸,如果要访问宿主机进程,必须使用 ** --pid=host ** 参数运行容器
CAP_SYS_PTRACE allows to use ptrace(2) and recently introduced cross memory attach system calls such as process_vm_readv(2) and process_vm_writev(2) . If this capability is granted and the ptrace(2) system call itself is not blocked by a seccomp filter, this will allow an attacker to bypass other seccomp restrictions, see PoC for bypassing seccomp if ptrace is allowed or the following PoC:
# CAP_SYS_MODULE
CAP_SYS_MODULE 允许进程加载和卸载任意内核模块。
可以实现在主机的内核中插入 / 删除内核模块
1 | getcap -r / 2>/dev/null |
modprobe 检测 /lib/modules/$(uname -r) 目录中依赖关系和映射表,我们可以伪造一个虚假的 lib/modules 文件夹
1 | mkdir lib/modules -p |
编译内核模块并移动到这个文件夹
1 | cp reverse-shell.ko lib/modules/$(uname -r)/ |
最后通过 python 加载内核模块
1 | import kmod |
# CAP_DAC_READ_SEARCH
1 | CAP_DAC_READ_SEARCH允许进程绕过文件读取检查和目录读/执行检查 |
二进制文件可以读取任何文件,因此可以使用 tar 来读取 /etc/shadow 文件
1 | cd /etc |
# CAP_DAC_OVERRIDE
可以绕过对任何文件的写权限检查,造成任意写文件。可以通过覆盖很多文件来提权
比如修改 /etc/sudoers
1 | getcap -r / 2>/dev/null |
# CAP_CHOWN
可以改变文件的所有者
假设 python 具有这种能力,那么我们更改 /etc/shadow 文件的所有者,更改 root 密码,提权
1 | python -c 'import os;os.chown("/etc/shadow",1000,1000)' |
# CAP_FOWNER
可以改变任何文件的权限
假如 python 具有这种权限,那么可以改修 shadow 文件来逃逸
1 | python -c 'import os;os.chmod("/etc/shadow",0666) |
# CAP_SETUID
可以设置创建进程的 UID,造成逃逸
假如 python 具有这种权限
1 | import os |
# CAP_SETGID
设置创建文件的 SGID
1 | import os |
# CAP_SETFCAP
可以对文件或进程设置 capabilities
如果 python 有了这个 capability,可以实现 docker 逃逸
1 | import ctypes, sys |
# CAP_SYS_RAWIO
可以实现访问 /dev/mem , /dev/kmem or /proc/kcore,修改 mmap_min_addr 以及调用各种磁盘命令,这有助于权限提升和 docker 逃逸
# CAP_KILL
可以 kill 掉任何进程
假设 python 具有这种能力,可以修改服务和 socket 配置,那么可以进行后门操作,然后 kill 相关的进程,并通过后门操作等待新配置文件的执行
1 | #Use this python code to kill arbitrary processes |
# CAP_NET_BIND_SERVICE
可以在任何端口,甚至特权端口监听,但是不能直接使用这个 capability 提权、
如果 python 具有这个 capability,可以监听任意端口,甚至可以从该端口连接到其他端口,有些服务需要特权端口连接
1 | import socket |
# CAP_NET_RAW
可以为可用的命名空间创建 RAW 和 PACKET 套接字。这可以通过公开的网络接口产生和传输任意的数据数据包
可以嗅探流量,但不能直接提权。tcpdump 有这个 capability 可以获取网络数据包
1 | getcap -r / 2>/dev/null |
# CAP_NET_ADMIN + CAP_NET_RAW
允许修改暴露的命名空间的防火墙,路由表,套接字等权限。提供网络接口混杂模式,可以进行跨名称空间嗅探
如果 python 具有这种能力
1 | #Dump iptables filter table rules |
# CAP_LINUX_IMMUTABLE
可以修改 iNode 属性
如果 python 具有此功能,那么可以删除不可变的属性让他变得可修改
1 | #Check that the file is imutable |
1 | #Pyhton code to allow modifications to the file |
# CAP_SYS_CHROOT
允许使用 chroot (2) 进行系统调用,可以允许 chroot (2) 进行逃逸
# capabilities 的赋予和继承
Linux capabilities 分为进程 capabilities 和文件 capabilities。对于进程来说,capabilities 是细分到线程的,即每个线程可以有自己的 capabilities。对于文件来说,capabilities 保存在文件的扩展属性中。
# 线程的 capabilities
每一个线程,具有 5 个 capabilities 集合,每一个集合使用 64 位掩码来表示,显示为 16 进制格式。这 5 个 capabilities 集合分别是:
- Permitted
- Effective
- Inheritable
- Bounding
- Ambient
每个集合中都包含零个或多个 capabilities。
# Permitted 允许
定义了线程能够使用的 capabilities 的上限。线程可以通过系统调用 capset() 来从 Effective 或 Inheritable 集合中添加或删除 capability,前提是添加或删除的 capability 必须包含在 Permitted 集合中。
如果某个线程想向 Inheritable 集合中添加或删除 capability,首先它的 Effective 集合中得包含 CAP_SETPCAP 这个 capabiliy。
# Effective 有效
内核检查线程是否可以进行特权操作时,检查的对象便是 Effective 集合。如之前所说, Permitted 集合定义了上限,线程可以删除 Effective 集合中的某 capability,随后在需要时,再从 Permitted 集合中恢复该 capability,以此达到临时禁用 capability 的功能。
# Inheritable
当执行 exec() 系统调用时,能够被新的可执行文件继承的 capabilities,被包含在 Inheritable 集合中。这里需要说明一下,包含在该集合中的 capabilities 并不会自动继承给新的可执行文件,即不会添加到新线程的 Effective 集合中,它只会影响新线程的 Permitted 集合。
# Bounding
Bounding 集合是 - 集合的超集,如果某个 capability 不在 Bounding 集合中,即使它在 Permitted 集合中,该线程也不能将该 capability 添加到它的 Inheritable 集合中。
Bounding 集合的 capabilities 在执行 fork() 系统调用时会传递给子进程的 Bounding 集合,并且在执行 execve 系统调用后保持不变。
- 当线程运行时,不能向 Bounding 集合中添加 capabilities。
- 一旦某个 capability 被从 Bounding 集合中删除,便不能再添加回来。
- 将某个 capability 从 Bounding 集合中删除后,如果之前
Inherited集合包含该 capability,将继续保留。但如果后续从Inheritable集合中删除了该 capability,便不能再添加回来。
# Ambient
Linux 4.3 内核新增了一个 capabilities 集合叫 Ambient ,用来弥补 Inheritable 的不足。 Ambient 具有如下特性:
Permitted和Inheritable未设置的 capabilities,Ambient也不能设置。- 当
Permitted和Inheritable关闭某权限(比如CAP_SYS_BOOT)后,Ambient也随之关闭对应权限。这样就确保了降低权限后子进程也会降低权限。 - 非特权用户如果在
Permitted集合中有一个 capability,那么可以添加到Ambient集合中(也有了 A 权限),这样它的子进程便可以在Ambient、Permitted和Effective集合中获取这个 capability。
Ambient 的好处显而易见,举个例子,如果你将 CAP_NET_ADMIN 添加到当前进程的 Ambient 集合中,它便可以通过 fork() 和 execve() 调用 shell 脚本来执行网络管理任务,因为 CAP_NET_ADMIN 会自动继承下去。
# 文件的 capabilities
文件的 capabilities 被保存在文件的扩展属性中。如果想修改这些属性,需要具有 CAP_SETFCAP 的 capability。文件与线程的 capabilities 共同决定了通过 execve() 运行该文件后的线程的 capabilities。
文件的 capabilities 功能,需要文件系统的支持。如果文件系统使用了 nouuid 选项进行挂载,那么文件的 capabilities 将会被忽略。
类似于线程的 capabilities,文件的 capabilities 包含了 3 个集合:
- Permitted
- Inheritable
- Effective
# Permitted
这个集合中包含的 capabilities,在文件被执行时,会与线程的 Bounding 集合计算交集,然后添加到线程的 Permitted 集合中。
# Inheritable
这个集合与线程的 Inheritable 集合的交集,会被添加到执行完 execve() 后的线程的 Permitted 集合中。
# Effective
这不是一个集合,仅仅是一个标志位。如果设置开启,那么在执行完 execve() 后,线程 Permitted 集合中的 capabilities 会自动添加到它的 Effective 集合中
# 运行 execve () 后 capabilities 的变化
我们用 P 代表执行 execve() 前线程的 capabilities, P' 代表执行 execve() 后线程的 capabilities, F 代表可执行文件的 capabilities。那么:
1 | P'(ambient) = (file is privileged) ? 0 : P(ambient) |
- 如果用户是 root 用户,那么执行
execve()后线程的Ambient集合是空集;如果是普通用户,那么执行execve()后线程的Ambient集合将会继承执行execve()前线程的Ambient集合。- 执行
execve()前线程的Inheritable集合与可执行文件的Inheritable集合取交集,会被添加到执行execve()后线程的Permitted集合;线程执行前 bounding 集合与可执行文件的Permitted集合取交集,也会被添加到执行execve()后线程的Permitted集合;同时执行execve()后线程的Ambient集合中的 capabilities 会被自动添加到该线程的Permitted集合中。- 如果可执行文件开启了 Effective 标志位,那么在执行完
execve()后,线程Permitted集合中的 capabilities 会自动添加到它的Effective集合中。- 执行
execve()前线程的Inheritable集合会继承给执行execve()后线程的Inheritable集合。
下面我们用一个例子来演示上述公式的计算逻辑,以 ping 文件为例。如果我们将 CAP_NET_RAW capability 添加到 ping 文件的 Permitted 集合中(F (Permitted)),它就会添加到执行后的线程的 Permitted 集合中(P’(Permitted))。由于 ping 文件具有 capabilities 感知能力,即能够调用 capset() 和 capget() ,它在运行时会调用 capset() 将 CAP_NET_RAW capability 添加到线程的 Effective 集合中。
换句话说,如果可执行文件不具有 capabilities 感知能力,我们就必须要开启 Effective 标志位(F (Effective)),这样就会将该 capability 自动添加到线程的 Effective 集合中。具有 capabilities 感知能力的可执行文件更安全,因为它会限制线程使用该 capability 的时间。
我们也可以将 capabilities 添加到文件的 Inheritable 集合中,文件的 Inheritable 集合会与当前线程的 Inheritable 集合取交集,然后添加到新线程的 Permitted 集合中。这样就可以控制可执行文件的运行环境。
看起来很有道理,但有一个问题:如果可执行文件的有效用户是普通用户,且没有 Inheritable 集合,即 F(inheritable) = 0 ,那么 P(inheritable) 将会被忽略(P (inheritable) & F (inheritable))。由于绝大多数可执行文件都是这种情况,因此 Inheritable 集合的可用性受到了限制。我们无法让脚本中的线程自动继承该脚本文件中的 capabilities,除非让脚本具有 capabilities 感知能力。
要想改变这种状况,可以使用 Ambient 集合。 Ambient 集合会自动从父线程中继承,同时会自动添加到当前线程的 Permitted 集合中。举个例子,在一个 Bash 环境中(例如某个正在执行的脚本),该环境所在的线程的 Ambient 集合中包含 CAP_NET_RAW capability,那么在该环境中执行 ping 文件可以正常工作,即使该文件是普通文件(没有任何 capabilities,也没有设置 SUID)。
(这几条都是由上面的公式推导而来)
最后拿 docker 举例,如果你使用普通用户来启动官方的 nginx 容器,会出现以下错误:
1 | bind() to 0.0.0.0:80 failed (13: Permission denied) |
因为 nginx 进程的 Effective 集合中不包含 CAP_NET_BIND_SERVICE capability,且不具有 capabilities 感知能力(普通用户),所以启动失败。要想启动成功,至少需要将该 capability 添加到 nginx 文件的 Inheritable 集合中,同时开启 Effective 标志位,并且在 Kubernetes Pod 的部署清单中的 securityContext –> capabilities 字段下面添加 NET_BIND_SERVICE (这个 capability 会被添加到 nginx 进程的 Bounding 集合中),最后还要将 capability 添加到 nginx 文件的 Permitted 集合中。如此一来就大功告成了,参考公式:P’(permitted) = …|(F (permitted) & P (bounding)))|…,P’(effective) = F (effective) ? P’(permitted) : P’(ambient)。
如果容器开启了 securityContext/allowPrivilegeEscalation ,上述设置仍然可以生效。如果 nginx 文件具有 capabilities 感知能力,那么只需要将 CAP_NET_BIND_SERVICE capability 添加到它的 Inheritable 集合中就可以正常工作了。
# 查看和设置 capabilities
Linux 系统中主要提供了两种工具来管理 capabilities: libcap 和 libcap-ng 。 libcap 提供了 getcap 和 setcap 两个命令来分别查看和设置文件的 capabilities,同时还提供了 capsh 来查看当前 shell 进程的 capabilities。 libcap-ng 更易于使用,使用同一个命令 filecap 来查看和设置 capabilities。
# 1. libcap
安装很简单,以 CentOS 为例,可以通过以下命令安装:
1 | $ yum install -y libcap |
如果想查看当前 shell 进程的 capabilities,可以用 capsh 命令。下面是 CentOS 系统中的 root 用户执行 capsh 的输出:
1 | $ capsh --print |
解释一下:
- Current : 表示当前 shell 进程的 Effective capabilities 和 Permitted capabilities。可以包含多个分组,每一个分组的表示形式为
capability[,capability…]+(e|i|p),其中e表示 effective,i表示 inheritable,p表示 permitted。不同的分组之间通过空格隔开,例如:Current: = cap_sys_chroot+ep cap_net_bind_service+eip。再举一个例子,cap_net_bind_service+e cap_net_bind_service+ip和cap_net_bind_service+eip等价。 - Bounding set : 这里仅仅表示 Bounding 集合中的 capabilities,不包括其他集合,所以分组的末尾不用加上
+...。
这个命令输出的信息比较有限,完整的信息可以查看 /proc 文件系统,比如当前 shell 进程就可以查看 /proc/$$/status 。其中一个重要的状态就是 NoNewPrivs ,可以通过以下命令查看:
grep NoNewPrivs /proc/$$/status
自从 Linux 4.10 开始, /proc/[pid]/status 中的 NoNewPrivs 值表示了线程的 no_new_privs 属性。
# no_new_privs
一般情况下, execve() 系统调用能够赋予新启动的进程其父进程没有的权限,最常见的例子就是通过 setuid 和 setgid 来设置程序进程的 uid 和 gid 以及文件的访问权限。这就给不怀好意者钻了不少空子,可以直接通过 fork 来提升进程的权限,从而达到不可告人的目的。
为了解决这个问题,Linux 内核从 3.5 版本开始,引入了 no_new_privs 属性(实际上就是一个 bit,可以开启和关闭),提供给进程一种能够在 execve() 调用整个阶段都能持续有效且安全的方法。
- 开启了
no_new_privs之后,execve 函数可以确保所有操作都必须调用execve()判断并赋予权限后才能被执行。这就确保了线程及子线程都无法获得额外的权限,因为无法执行 setuid 和 setgid,也不能设置文件的权限。 - 一旦当前线程的
no_new_privs被置位后,不论通过 fork,clone 或 execve 生成的子线程都无法将该位清零。
# 管理 capabilities
可以通过 getcap 来查看文件的 capabilities,例如:
1 | $ getcap /bin/ping /usr/sbin/arping |
也可以使用 -r 参数来递归查询:
1 | $ getcap -r /usr 2>/dev/null |
如果想查看某个进程的 capabilities,可以直接使用 getpcaps ,后面跟上进程的 PID:
1 | $ getpcaps 1234 |
如果想查看一组相互关联的线程的 capabilities(比如 nginx),可以这么来看:
1 | $ getpcaps $(pgrep nginx) |
这里你会看到只有主线程才有 capabilities,子线程和其他 workers 都没有 capabilities,这是因为只有 master 才需要特殊权限,例如监听网络端口,其他线程只需要响应请求就好了。
设置文件的 capabilities 可以使用 setcap ,语法如下:
1 | $ setcap CAP+set filename |
例如,将 CAP_CHOWN 和 CAP_DAC_OVERRIDE capabilities 添加到 permitted 和 effective 集合:
1 | $ setcap CAP_CHOWN,CAP_DAC_OVERRIDE+ep file1 |
如果想移除某个文件的 capabilities,可以使用 -r 参数:
1 | $ setcap -r filename |
# 2. libcap-ng
安装也很简单,以 CentOS 为例:
1 | $ yum install libcap-ng-utils |
# 用法
libcap-ng 使用 filecap 命令来管理文件的 capabilities。有几个需要注意的地方:
- filecap 添加删除或查看 capabilities 时,capabilities 的名字不需要带
CAP_前缀(例如,使用NET_ADMIN代替CAP_NET_ADMIN); - filecap 不支持相对路径,只支持绝对路径;
- filecap 不允许指定 capabilities 作用的集合,capabilities 只会被添加到
permitted和effective集合。
查看文件的 capabilities:
1 | $ filecap /full/path/to/file |
递归查看某个目录下所有文件的 capabilities:
1 | $ filecap /full/path/to/dir |
例如:
1 | $ filecap /usr/bin |
递归查看整个系统所有文件的 capabilities:
1 | $ filecap / |
设置文件的 capabilities 语法如下:
1 | $ filecap /full/path/to/file cap_name |
移除某个文件的 capabilities:
1 | $ filecap /full/path/to/file none |
# capability 进阶
在 Ubuntu 18.04 上,以普通用户的身份运行 capsh 将会得到如下结果:
1 | $ capsh --print |
可以看到普通用户当前所在的 shell 进程没有任何 capabilities(即 Effective 集合为空), Bounding 集合包含了所有 capabilities。
这个命令输出的信息比较有限,完整的信息可以查看 /proc 文件系统,比如当前 shell 进程就可以查看 /proc/$$/status 。
1 | $ grep Cap /proc/$$/status |
输出中的 16 进制掩码表示对应集合中的 capabilities,可以使用 capsh 对其进行解码:
1 | $ capsh --decode=0000003fffffffff |
和 capsh --print 命令输出的结果一样。
如果是 root 用户,得到的结果和普通用户是不一样的:
1 | $ grep Cap /proc/$$/status |
所有的 capabilities 都包含在了 Permitted 、 Effective 和 Bounding 集合中,所以 root 用户可以执行任何内核调用。
1 | 在Ubuntu中Bnd是3fffffffff |
# 手动设置 capability
1 | $ setcap 'cap_net_raw+p' builddir/ping/ping |
1 | 这里再活学活用一下,为什么普通用户无法执行 `setcap` 呢?因为执行 `setcap` 的用户需要在 `effective` 集合中包含 `CAP_SETFCAP` capabilities,而普通用户不具备这个 capabilities,所以必须使用 root 用户。 |
其实 ping 在执行过程中会将 Permitted 集合中的 CAP_NET_RAW capabilities 加入 Effective 集合中,打开 Socket 之后再将该 capabilities 从 Effective 集合中移除,所以 grep 是看不到的。其中这就是我在 第一篇文章提到的 ping 文件具有 capabilities 感知能力。可以通过 stace 跟踪系统调用来验证:
如果 ping 二进制文件不具备 capabilities 感知能力,即没有调用 capset 和 capget 的权限,我们就必须要开启 Effective 标志位(F (Effective)),这样就会将该 capabilities 自动添加到进程的 Effective 集合中:
1 | $ setcap 'cap_net_raw+ep' builddir/ping/ping |
# docker
Linux 命名空间、控制组和 UnionFS 三大技术支撑了目前 Docker 的实现
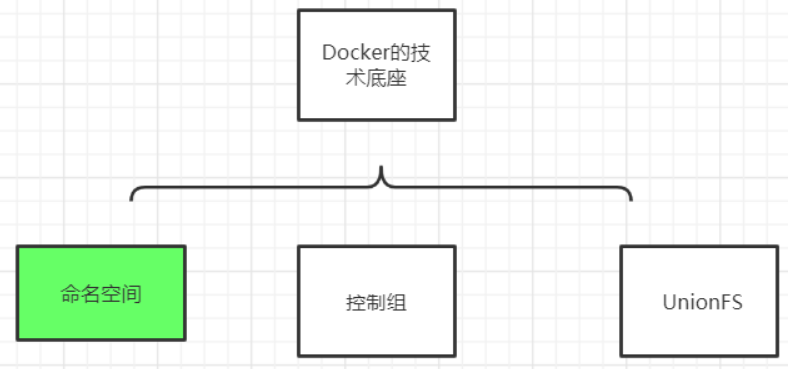
- namespace,命名空间
命名空间,容器隔离的基础,保证 A 容器看不到 B 容器.
6 个命名空间:User,Mnt,Network,UTS,IPC,Pid
- cgroups,Cgroups 是 Control Group 的缩写,控制组
cgroups 容器资源统计和隔离
主要用到的 cgroups 子系统:cpu,blkio,device,freezer,memory
实际上 Docker 是使用了很多 Linux 的隔离功能,让容器看起来像一个轻量级虚拟机在独立运行,容器的本质是被限制了的 Namespaces,cgroup,具有逻辑上独立文件系统,网络的一个进程。
- unionfs 联合文件系统
典型:aufs/overlayfs,分层镜像实现的基础
# unionfs
Docker Image 是有一个层级结构的,最底层的 Layer 为 BaseImage(一般为一个操作系统的 ISO 镜像),然后顺序执行每一条指令,生成的 Layer 按照入栈的顺序逐渐累加,最终形成一个 Image。
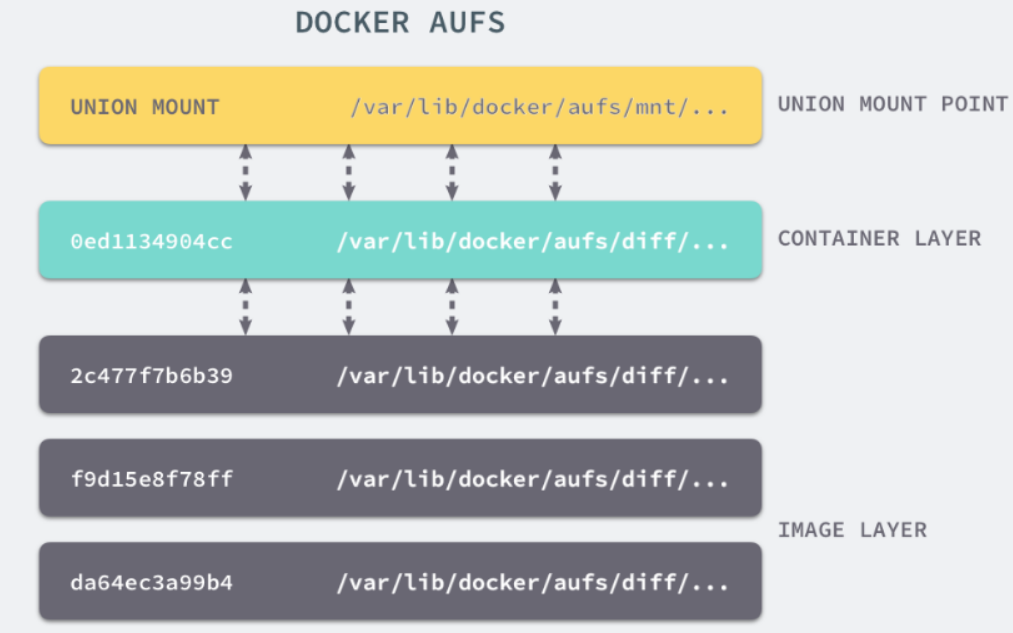
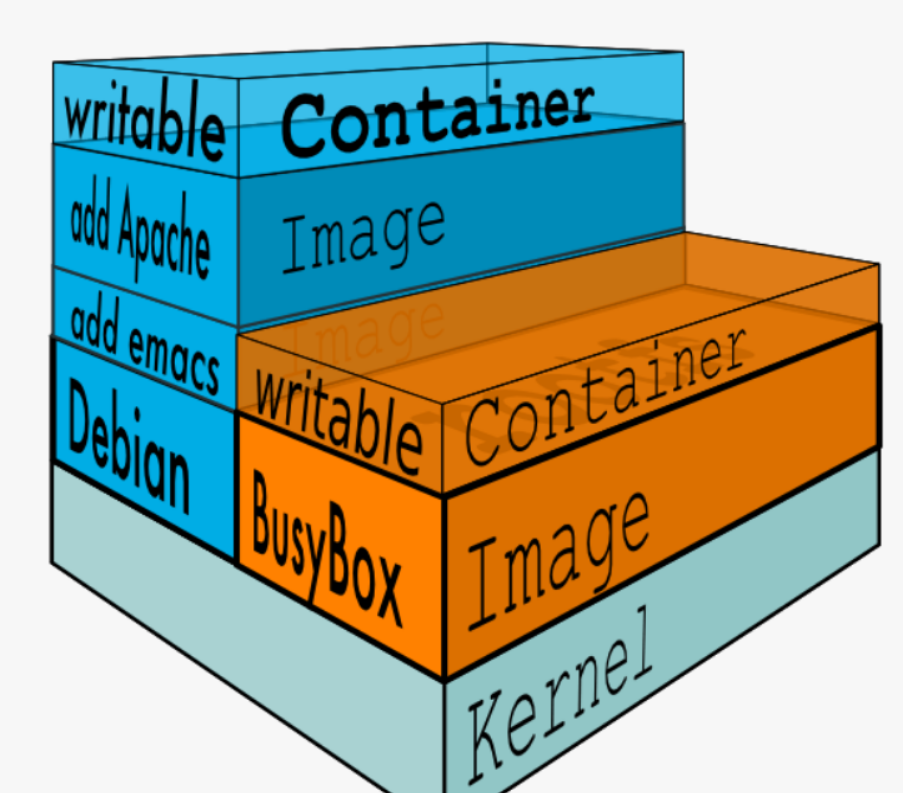
简单来说,一个 Image 是通过一个 DockerFile 定义的,然后使用 docker build 命令构建它。
DockerFile 中的每一条命令的执行结果都会成为 Image 中的一个 Layer。
这里,我们通过 Build 一个镜像,来观察 Image 的分层机制:
Dockerfile:
1 | # Use an official Python runtime as a parent image |
构建结果:
1 | root@rds-k8s-18-svr0:~/xuran/exampleimage |
构建的过程就是执行 Dockerfile 文件中我们写入的命令。构建一共进行了 7 个步骤,每个步骤进行完都会生成一个随机的 ID,来标识这一 layer 中的内容。 最后一行的 a5ccd4e1b15d 为镜像的 ID。
如果 DockerFile 中的内容没有变动,那么相应的镜像在 build 的时候会复用之前的 layer,以便提升构建效率。并且,即使文件内容有修改,那也只会重新 build 修改的 layer,其他未修改的也仍然会复用。
Docker 也正是通过 AUFS 来管理 Images 的。
# namespace
在 Linux 系统中,Namespace 是在内核级别以一种抽象的形式来封装系统资源,通过将系统资源放在不同的 Namespace 中,来实现资源隔离的目的。不同的 Namespace 程序,可以享有一份独立的系统资源。
命名空间(namespaces)是 Linux 为我们提供的用于分离进程树、网络接口、挂载点以及进程间通信等资源的方法。
Linux 的命名空间机制提供了以下七种不同的命名空间,包括 :
- CLONE_NEWCGROUP、
- CLONE_NEWIPC、
- CLONE_NEWNET、
- CLONE_NEWNS、
- CLONE_NEWPID、
- CLONE_NEWUSER
- CLONE_NEWUTS
| Namespace | Flag | Page | Isolates |
|---|---|---|---|
| Cgroup | CLONE_NEWCGROUP | cgroup_namespaces | Cgroup root directory |
| IPC | CLONE_NEWIPC | ipc_namespaces | System V IPC,POSIX message queues 隔离进程间通信 |
| Network | CLONE_NEWNET | network_namespaces | Network devices,stacks, ports, etc. 隔离网络资源 |
| Mount | CLONE_NEWNS | mount_namespaces | Mount points 隔离文件系统挂载点 |
| PID | CLONE_NEWPID | pid_namespaces | Process IDs 隔离进程的 ID |
| Time | CLONE_NEWTIME | time_namespaces | Boot and monotonic clocks |
| User | CLONE_NEWUSER | user_namespaces | User and group IDs 隔离用户和用户组的 ID |
| UTS | CLONE_NEWUTS | uts_namespaces | Hostname and NIS domain name 隔离主机名和域名信息 |
# PID 隔离
PID Namespaces,它其实是 Linux 创建新进程时的一个可选参数,在 Linux 系统中创建进程的系统调用是 clone () 方法。
通过调用这个方法,这个进程会获得一个独立的进程空间,它的 pid 是 1,并且看不到宿主机上的其他进程,这也就是在容器内执行 PS 命令的结果。
在子进程的 shell 中执行了 ps aux/top 之类的命令,发现还是可以看到所有父进程的 PID,那是因为我们还没有对文件系统进行隔离,ps/top 之类的命令调用的是真实系统下的 /proc 文件内容,看到的自然是所有的进程。
此外,与其他的 namespace 不同的是,为了实现一个稳定安全的容器,PID namespace 还需要进行一些额外的工作才能确保其中的进程运行顺利。
进程是 Linux 以及现在操作系统中非常重要的概念,它表示一个正在执行的程序,也是在现代分时系统中的一个任务单元。
在每一个 *nix 的操作系统上,我们都能够通过 ps 命令打印出当前操作系统中正在执行的进程
当前机器上有很多的进程正在执行,在上述进程中有两个非常特殊,一个是 pid 为 1 的 /sbin/init 进程,另一个是 pid 为 2 的 kthreadd 进程,这两个进程都是被 Linux 中的上帝进程 idle 创建出来的,其中前者负责执行内核的一部分初始化工作和系统配置,也会创建一些类似 getty 的注册进程,而后者负责管理和调度其他的内核进程。
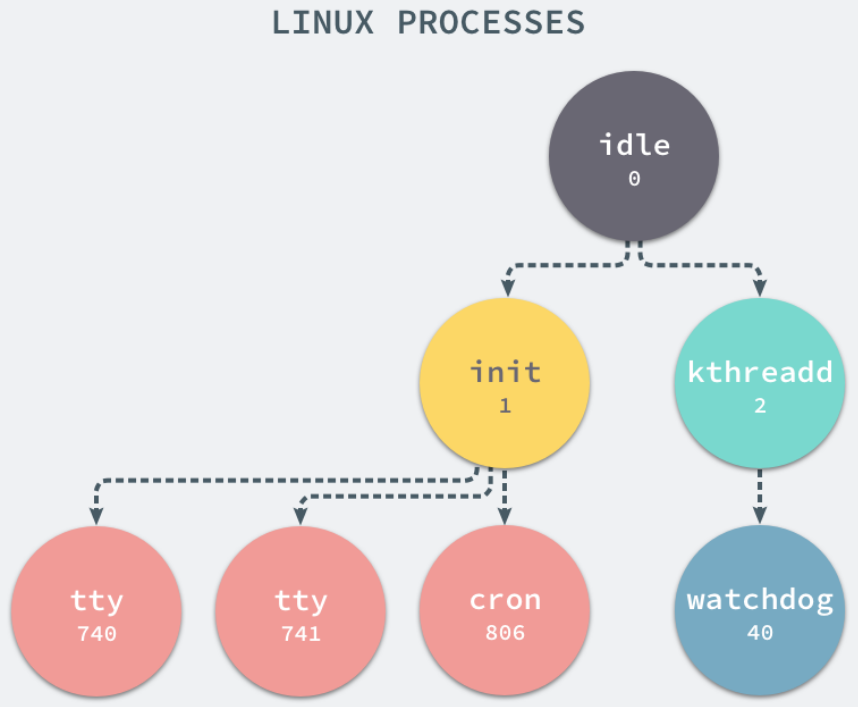
如果我们在当前的 Linux 操作系统下运行一个新的 Docker 容器,并通过 exec 进入其内部的 bash 并打印其中的全部进程,我们会得到以下的结果:
1 | UID PID PPID C STIME TTY TIME CMD |
在新的容器内部执行 ps 命令打印出了非常干净的进程列表,只有包含当前 ps -ef 在内的三个进程,在宿主机器上的几十个进程都已经消失不见了。
当前的 Docker 容器成功将容器内的进程与宿主机器中的进程隔离,如果我们在宿主机器上打印当前的全部进程时,会得到下面三条与 Docker 相关的结果:
在当前的宿主机器上,可能就存在由上述的不同进程构成的进程树:
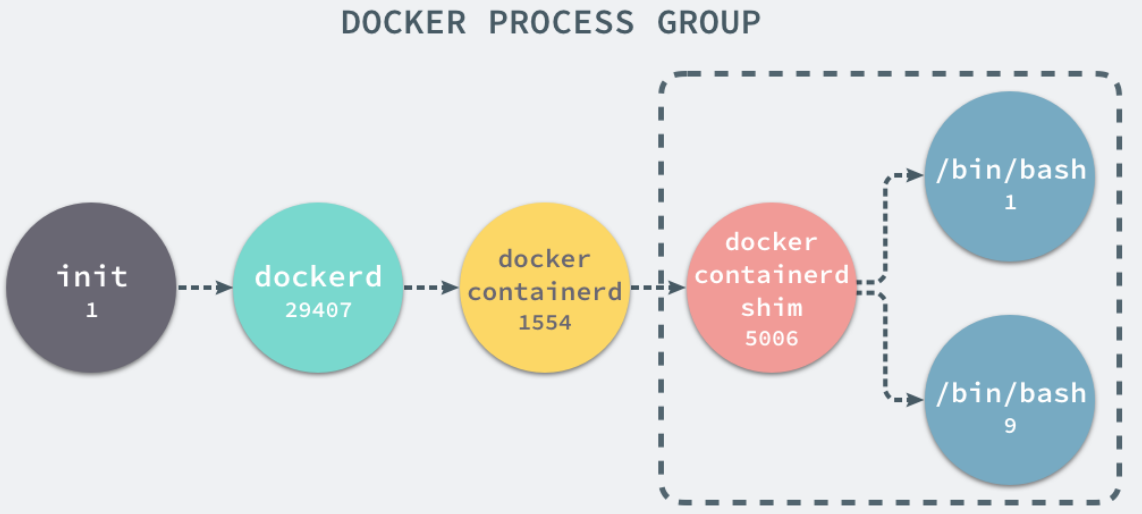
实际上,docker 容器的 pid 隔离,就是在使用 clone (2) 创建新进程时传入 CLONE_NEWPID 实现的,也就是使用 Linux 的命名空间实现进程的隔离,Docker 容器内部的任意进程都对宿主机器的进程一无所知。
Docker 的容器就是使用上述技术实现与宿主机器的进程隔离,当我们每次运行 docker run 或者 docker start 时,都会在下面的方法中创建一个用于设置进程间隔离的 Spec:
在 setNamespaces 方法中不仅会设置进程相关的命名空间,还会设置与用户、网络、IPC 以及 UTS 相关的命名空间:
PID namespace 隔离非常实用,它对进程 PID 重新标号,即两个不同 namespace 下的进程可以有同一个 PID。
每个 PID namespace 都有自己的计数程序。内核为所有的 PID namespace 维护了一个树状结构,最顶层的是系统初始时创建的,我们称之为 root namespace。他创建的新 PID namespace 就称之为 child namespace(树的子节点),而原先的 PID namespace 就是新创建的 PID namespace 的 parent namespace(树的父节点)。
通过这种方式,不同的 PID namespaces 会形成一个等级体系。所属的父节点可以看到子节点中的进程,并可以通过信号等方式对子节点中的进程产生影响。反过来,子节点不能看到父节点 PID namespace 中的任何内容。由此产生如下结论
- 每个 PID namespace 中的第一个进程 “PID 1“,都会像传统 Linux 中的 init 进程一样拥有特权,起特殊作用。
- 一个 namespace 中的进程,不可能通过 kill 或 ptrace 影响父节点或者兄弟节点中的进程,因为其他节点的 PID 在这个 namespace 中没有任何意义。
- 如果你在新的 PID namespace 中重新挂载 /proc 文件系统,会发现其下只显示同属一个 PID namespace 中的其他进程。
- 在 root namespace 中可以看到所有的进程,并且递归包含所有子节点中的进程。
不仅仅是 PID,当你启动启动容器之后,Docker 会为这个容器创建一系列其他 namespaces。
这些 namespaces 提供了不同层面的隔离。容器的运行受到各个层面 namespace 的限制。
Docker Engine 使用了以下 Linux 的隔离技术:
The pid namespace: 管理 PID 命名空间 (PID: Process ID).
The net namespace: 管理网络命名空间 (NET: Networking).
The ipc namespace: 管理进程间通信命名空间 (IPC: InterProcess Communication).
The mnt namespace: 管理文件系统挂载点命名空间 (MNT: Mount).
The uts namespace: Unix 时间系统隔离. (UTS: Unix Timesharing System).
通过这些技术,运行时的容器得以看到一个和宿主机上其他容器隔离的环境。
# 网络隔离
如果 Docker 的容器通过 Linux 的命名空间完成了与宿主机进程的网络隔离,但是却有没有办法通过宿主机的网络与整个互联网相连,就会产生很多限制。
所以 Docker 虽然可以通过命名空间创建一个隔离的网络环境,但是 Docker 中的服务仍然需要与外界相连才能发挥作用。
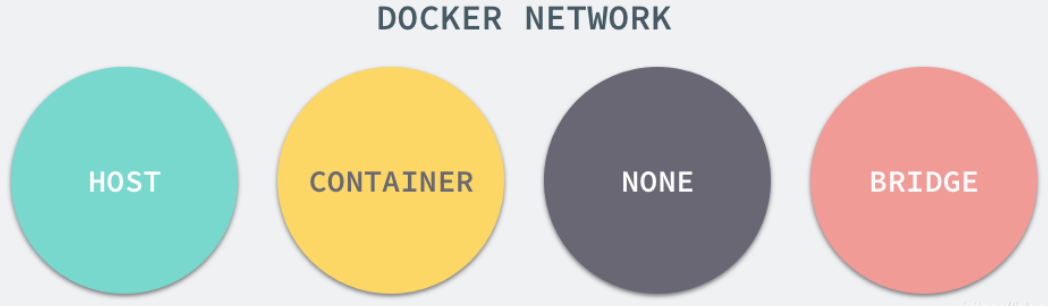
每一个使用 docker run 启动的容器其实都具有单独的网络命名空间,Docker 为我们提供了四种不同的网络模式,Host、Container、None 和 Bridge 模式。
当 Docker 服务器在主机上启动之后会创建新的虚拟网桥 docker0,随后在该主机上启动的全部服务在默认情况下都与该网桥相连。
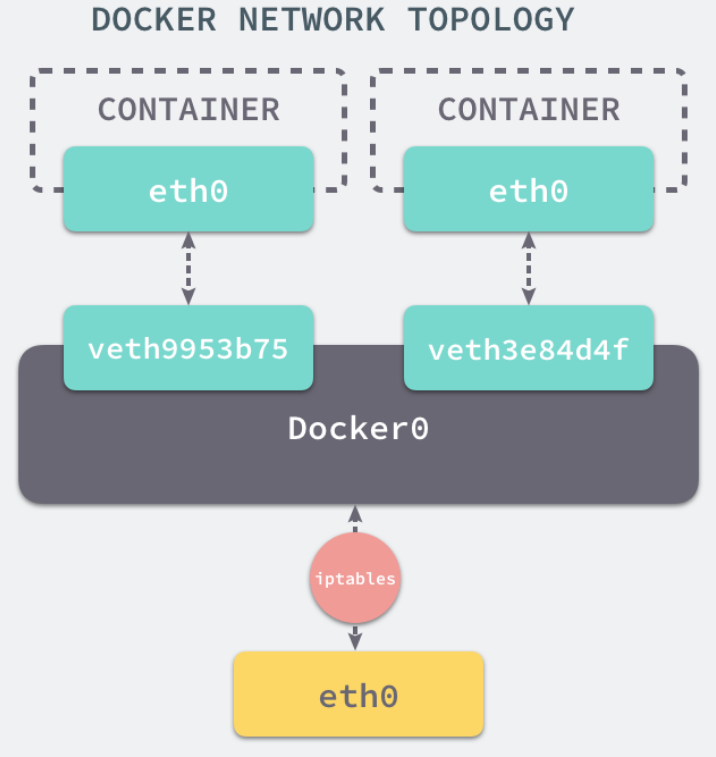
在默认情况下,每一个容器在创建时都会创建一对虚拟网卡,两个虚拟网卡组成了数据的通道,其中一个会放在创建的容器中,会加入到名为 docker0 网桥中。
我们可以使用如下的命令来查看当前网桥的接口:
1 | $ brctl show |
docker0 会为每一个容器分配一个新的 IP 地址并将 docker0 的 IP 地址设置为默认的网关。
网桥 docker0 通过 iptables 中的配置与宿主机器上的网卡相连,所有符合条件的请求都会通过 iptables 转发到 docker0 并由网桥分发给对应的机器。
1 | $ iptables -t nat -L |
我们在当前的机器上使用 docker run -d -p 6379:6379 redis 命令启动了一个新的 Redis 容器,在这之后我们再查看当前 iptables 的 NAT 配置就会看到在 DOCKER 的链中出现了一条新的规则:
1 | DNAT tcp -- anywhere anywhere tcp dpt:6379 to:192.168.0.4:6379 |
上述规则会将从任意源发送到当前机器 6379 端口的 TCP 包转发到 192.168.0.4:6379 所在的地址上。
这个地址其实也是 Docker 为 Redis 服务分配的 IP 地址,如果我们在当前机器上直接 ping 这个 IP 地址就会发现它是可以访问到的:
当有 Docker 的容器需要将服务暴露给宿主机器,就会为容器分配一个 IP 地址,同时向 iptables 中追加一条新的规则。
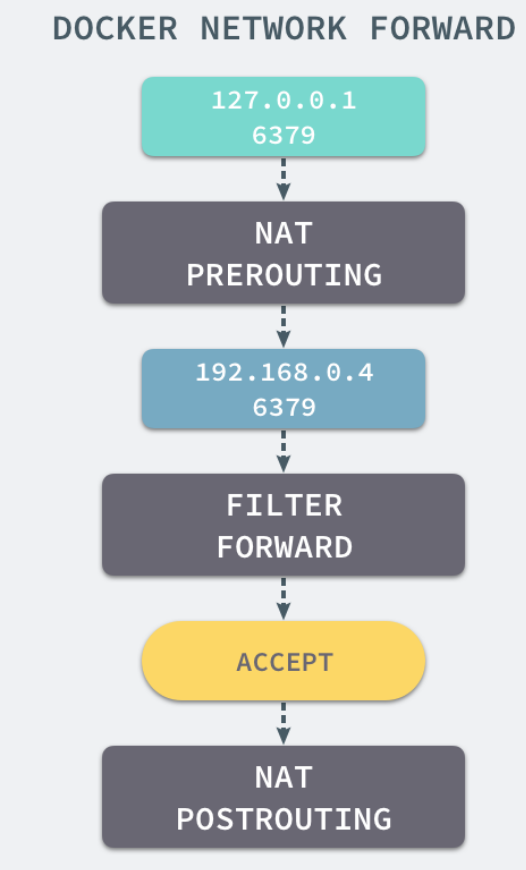
当我们使用 redis-cli 在宿主机器的命令行中访问 127.0.0.1:6379 的地址时,经过 iptables 的 NAT PREROUTING 将 ip 地址定向到了 192.168.0.4,重定向过的数据包就可以通过 iptables 中的 FILTER 配置,最终在 NAT POSTROUTING 阶段将 ip 地址伪装成 127.0.0.1,到这里虽然从外面看起来我们请求的是 127.0.0.1:6379,但是实际上请求的已经是 Docker 容器暴露出的端口了。
Docker 通过 Linux 的命名空间实现了网络的隔离,又通过 iptables 进行数据包转发,让 Docker 容器能够优雅地为宿主机器或者其他容器提供服务。
# Libnetwork
整个网络部分的功能都是通过 Docker 拆分出来的 libnetwork 实现的,它提供了一个连接不同容器的实现,同时也能够为应用给出一个能够提供一致的编程接口和网络层抽象的容器网络模型。
libnetwork 中最重要的概念,容器网络模型由以下的几个主要组件组成,分别是 Sandbox、Endpoint 和 Network:
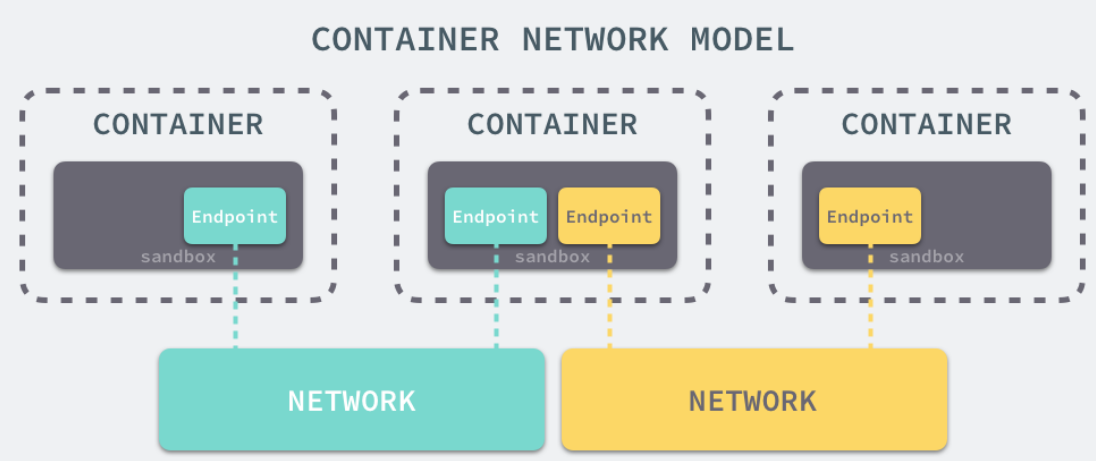
在容器网络模型中,每一个容器内部都包含一个 Sandbox,其中存储着当前容器的网络栈配置,包括容器的接口、路由表和 DNS 设置,Linux 使用网络命名空间实现这个 Sandbox,每一个 Sandbox 中都可能会有一个或多个 Endpoint,在 Linux 上就是一个虚拟的网卡 veth,Sandbox 通过 Endpoint 加入到对应的网络中,这里的网络可能就是我们在上面提到的 Linux 网桥或者 VLAN。
# 挂载点
在新的进程中创建隔离的挂载点命名空间需要在 clone 函数中传入 CLONE_NEWNS,这样子进程就能得到父进程挂载点的拷贝,如果不传入这个参数子进程对文件系统的读写都会同步回父进程以及整个主机的文件系统。
如果一个容器需要启动,那么它一定需要提供一个根文件系统(rootfs),容器需要使用这个文件系统来创建一个新的进程,所有二进制的执行都必须在这个根文件系统中。
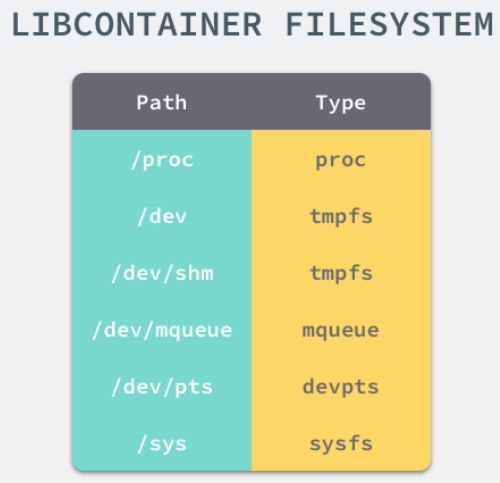
想要正常启动一个容器就需要在 rootfs 中挂载以上的几个特定的目录,除了上述的几个目录需要挂载之外我们还需要建立一些符号链接保证系统 IO 不会出现问题。
为了保证当前的容器进程没有办法访问宿主机器上其他目录,我们在这里还需要通过 libcotainer 提供的 pivor_root 或者 chroot 函数改变进程能够访问个文件目录的根节点。
1 | // pivor_root |
到这里我们就将容器需要的目录挂载到了容器中,同时也禁止当前的容器进程访问宿主机器上的其他目录,保证了不同文件系统的隔离。
在 Linux 系统中,系统默认的目录就都是以 / 也就是根目录开头的,chroot 的使用能够改变当前的系统根目录结构,通过改变当前系统的根目录,我们能够限制用户的权利,在新的根目录下并不能够访问旧系统根目录的结构个文件,也就建立了一个与原系统完全隔离的目录结构。
# cgroups
我们通过 Linux 的命名空间为新创建的进程隔离了文件系统、网络并与宿主机器之间的进程相互隔离,但是命名空间并不能够为我们提供物理资源上的隔离,比如 CPU 或者内存,如果在同一台机器上运行了多个对彼此以及宿主机器一无所知的『容器』,这些容器却共同占用了宿主机器的物理资源。
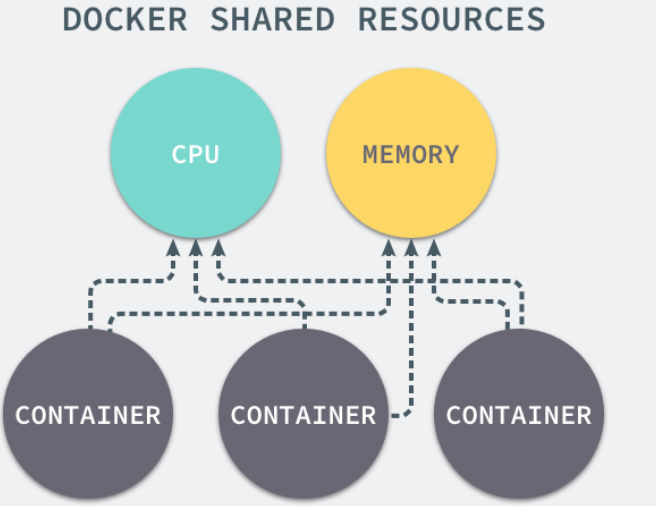
如果其中的某一个容器正在执行 CPU 密集型的任务,那么就会影响其他容器中任务的性能与执行效率,导致多个容器相互影响并且抢占资源。如何对多个容器的资源使用进行限制就成了解决进程虚拟资源隔离之后的主要问题,而 Control Groups(简称 CGroups)就是能够隔离宿主机器上的物理资源,例如 CPU、内存、磁盘 I/O 和网络带宽。
每一个 CGroup 都是一组被相同的标准和参数限制的进程,不同的 CGroup 之间是有层级关系的,也就是说它们之间可以从父类继承一些用于限制资源使用的标准和参数。
Linux 的 CGroup 能够为一组进程分配资源,也就是我们在上面提到的 CPU、内存、网络带宽等资源,通过对资源的分配。
Linux 使用文件系统来实现 CGroup,我们可以直接使用下面的命令查看当前的 CGroup 中有哪些子系统:
1 | $ lssubsys -m |
如果我们想要创建一个新的 cgroup 只需要在想要分配或者限制资源的子系统下面创建一个新的文件夹,然后这个文件夹下就会自动出现很多的内容,如果你在 Linux 上安装了 Docker,你就会发现所有子系统的目录下都有一个名为 Docker 的文件夹:
1 | ls cpu |
9c3057xxx 其实就是我们运行的一个 Docker 容器,启动这个容器时,Docker 会为这个容器创建一个与容器标识符相同的 CGroup,在当前的主机上 CGroup 就会有以下的层级关系:
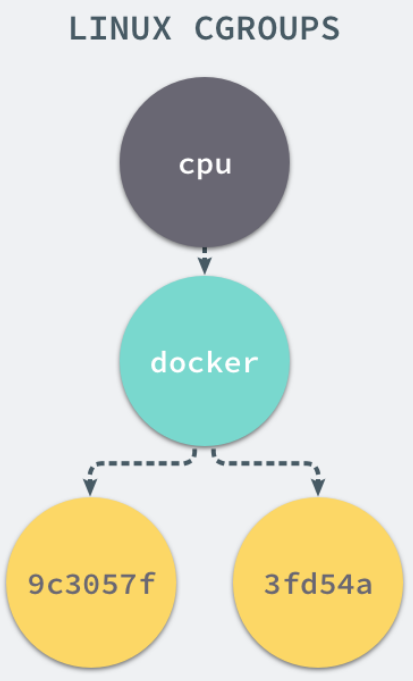
每一个 CGroup 下面都有一个 tasks 文件,其中存储着属于当前控制组的所有进程的 pid,作为负责 cpu 的子系统,cpu.cfs_quota_us 文件中的内容能够对 CPU 的使用作出限制,如果当前文件的内容为 50000,那么当前控制组中的全部进程的 CPU 占用率不能超过 50%。
如果系统管理员想要控制 Docker 某个容器的资源使用率就可以在 docker 这个父控制组下面找到对应的子控制组并且改变它们对应文件的内容,当然我们也可以直接在程序运行时就使用参数,让 Docker 进程去改变相应文件中的内容。
当我们使用 Docker 关闭掉正在运行的容器时,Docker 的子控制组对应的文件夹也会被 Docker 进程移除,Docker 在使用 CGroup 时其实也只是做了一些创建文件夹改变文件内容的文件操作,不过 CGroup 的使用也确实解决了我们限制子容器资源占用的问题,系统管理员能够为多个容器合理的分配资源并且不会出现多个容器互相抢占资源的问题。
从 3.8 版本的内核开始,用户就可以在 /proc/[pid]/ns 文件下看到指向不同 namespace 号的文件,效果如下所示,形如 [4026531839] 者即为 namespace 号。
1 | $ ls -l /proc/$$/ns <<-- 0="" 1="" 8="" $$="" 表示应用的pid="" total="" lrwxrwxrwx.="" mtk="" jan="" 04:12="" ipc="" -=""> ipc:[4026531839] |
如果两个进程指向的 namespace 编号相同,就说明他们在同一个 namespace 下,否则则在不同 namespace 里面。/proc/[pid]/ns 的另外一个作用是,一旦文件被打开,只要打开的文件描述符(fd)存在,那么就算 PID 所属的所有进程都已经结束,创建的 namespace 就会一直存在。那如何打开文件描述符呢?把 /proc/[pid]/ns 目录挂载起来就可以达到这个效果,命令如下。
1 | touch ~/uts |
如果你看到的内容与本文所描述的不符,那么说明你使用的内核在 3.8 版本以前。该目录下存在的只有 ipc、net 和 uts,并且以硬链接存在。
# 总结
docker 为 LXC+AUFS 组合:
- LXC 负责资源管理
- AUFS 负责镜像管理;
而 LXC 包括 cgroup,namespace,chroot 等组件,并通过 cgroup 资源管理
cgroup 是在底层落实资源管理,LXC 在 cgroup 上面封装了一层,随后,docker 有在 LXC 封装了一层;
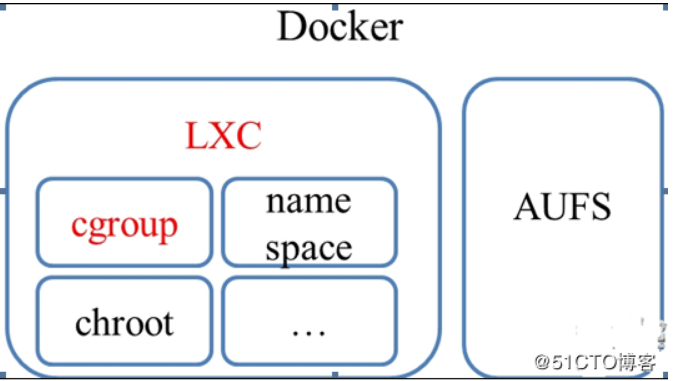
Cgroup 其实就是 linux 提供的一种限制,记录,隔离进程组所使用的物理资源管理机制;也就是说,Cgroup 是 LXC 为实现虚拟化所使用资源管理手段,我们可以这样说,底层没有 cgroup 支持,也就没有 lxc,更别说 docker 的存在了
我们提到 LXC 是建立在 cgroup 基础上的,我们可以粗略的认为 LXC=Cgroup+namespace+Chroot+veth + 用户控制脚本;LXC 利用内核的新特性(cgroup)来提供用户空间的对象,用来保证资源的隔离和对应用系统资源的限制;
Docker 容器的文件系统最早是建立在 Aufs 基础上的,Aufs 是一种 Union FS,简单来说就 ** 是支持将不同的目录挂载到同一个虚拟文件系统之下并实现一种 laver 的概念,** 由于 Aufs 未能加入到 linux 内核中,考虑到兼容性的问题,便加入了 Devicemapper 的支持,Docker 目前默认是建立在 Devicemapper 基础上,**devicemapper 用户控件相关部分主要负责配置具体的策略和控制逻辑,** 比如逻辑设备和哪些物理设备建立映射,怎么建立这些映射关系等,而具体过滤和重定向 IO 请求的工作有内核中相关代码完成,因此整个 device mapper 机制由两部分组成–内核空间的 device mapper 驱动,用户控件的 device mapper 库以及它提供的 dmsetup 工具;
Docker 底层原理(图解 + 秒懂 + 史上最全) - 疯狂创客圈 - 博客园 (cnblogs.com)