# hadoopHadoop 是 Apache 软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。
Hadoop 是基于 Java 语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中;
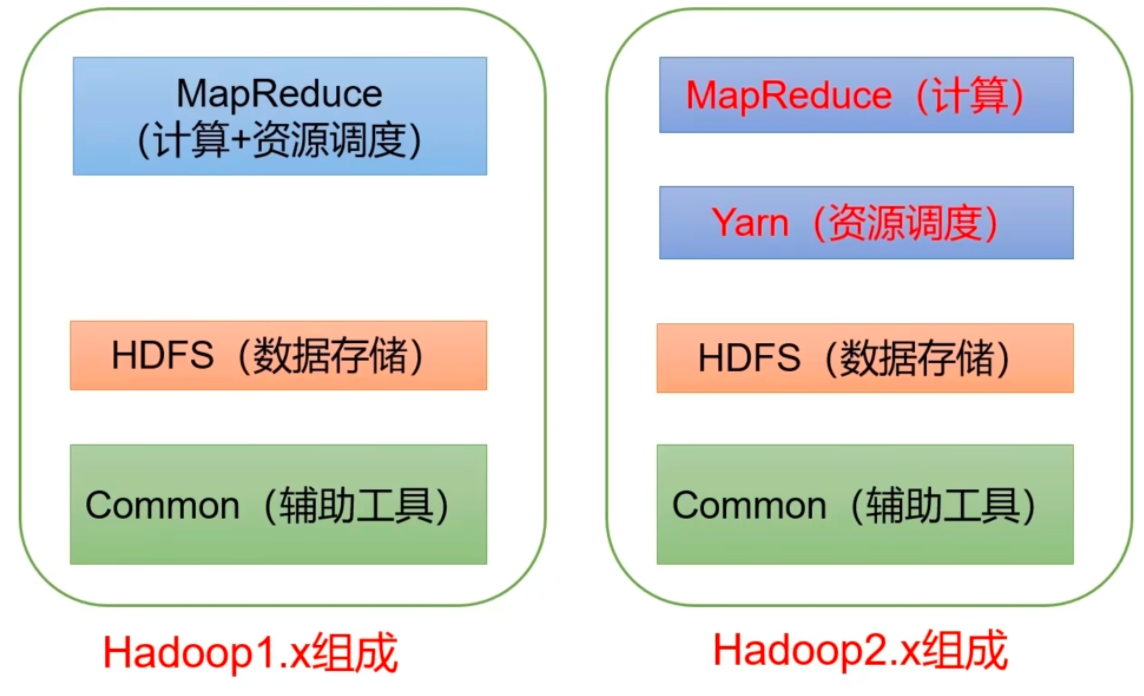
Hadoop 的核心是分布式文件系统 HDFS(Hadoop Distributed File System)和 MapReduce;
Hadoop 被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力;
解决海量数据存储和分析计算问题
优势: 维护多副本
在集群间分配任务数据,方便扩展
并行工作
自动将失败任务重新分配
# hadoop 版本演进Apache Hadoop 版本分为两代:第一代 Hadoop 称为 Hadoop 1.0,第二代 Hadoop 称为 Hadoop 2.0。
第一代 Hadoop 包含三个大版本,分别是 0.20.x、0.21.x、0.22.x 。
0.20.x 最后演化成 1.0.x,变成了稳定版。
0.21.x 和 0.22.x 则增加了 NameNode HA 等新的重大特性。
第二代 Hadoop 包含两个大版本,分别是 0.23.x、2.x 。
它们完全不同于 Hadoop 1.0,是一套全新的架构,均包含 HDFS Federation 和 YARN 两个系统。
相比于 0.23.x,2.x 增加了 NameNode HA 和 Wire-compatibility 两个重大特性。
# 组件HDFS
NameNode:
NameNode 是 HDFS 的主节点,负责管理文件系统的命名空间和元数据信息。
它维护了整个文件系统的目录树结构以及文件和数据块的映射关系。
NameNode 还负责处理客户端的读写请求,包括打开、关闭、重命名和删除文件等操作。
DataNode:
DataNode 是 HDFS 的数据节点,负责存储实际的数据块。
它接收来自客户端或其他 DataNode 的数据写入请求,并将数据块存储在本地磁盘上。
DataNode 还负责处理客户端的数据读取请求,将数据块传输给客户端。
Standby Namenode(2NN):
辅助 namenode。作为备用的 NameNode。当活动的 NameNode 失效时,Standby NameNode 可以接管其工作,从而提高了系统的可用性。
1) NameNode (nn): 存储文件的元数据,如文件名,文件目录结构,文件属性 (生成时间、副本数、文件权限), 以及每个文件的块列表和块所在 DataNode 等。
2) DataNode (dn): 在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode (2nn): 每隔一段时间对 NameNode 元数据备份
YARN 组件
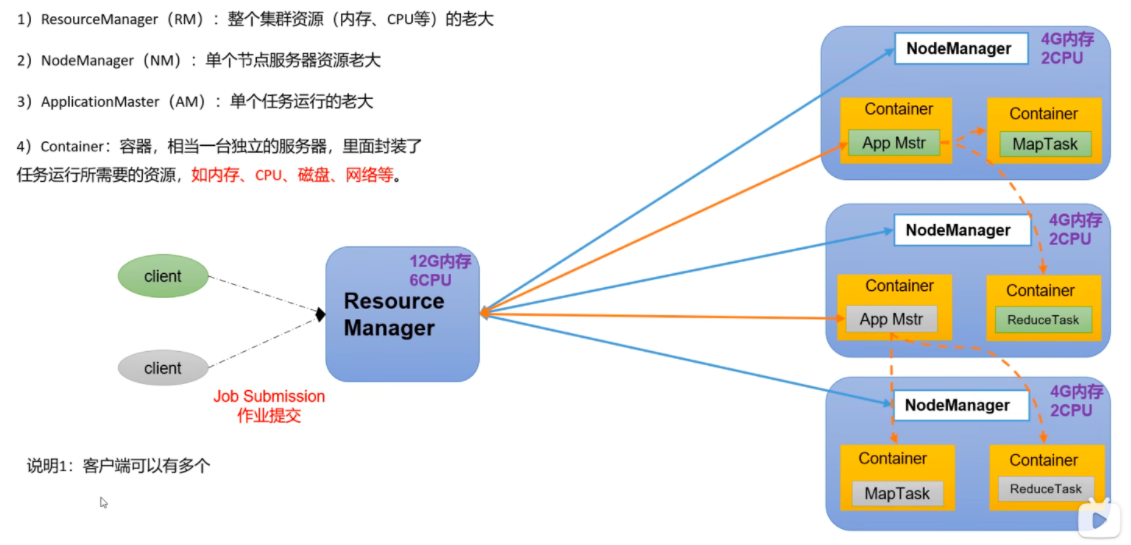
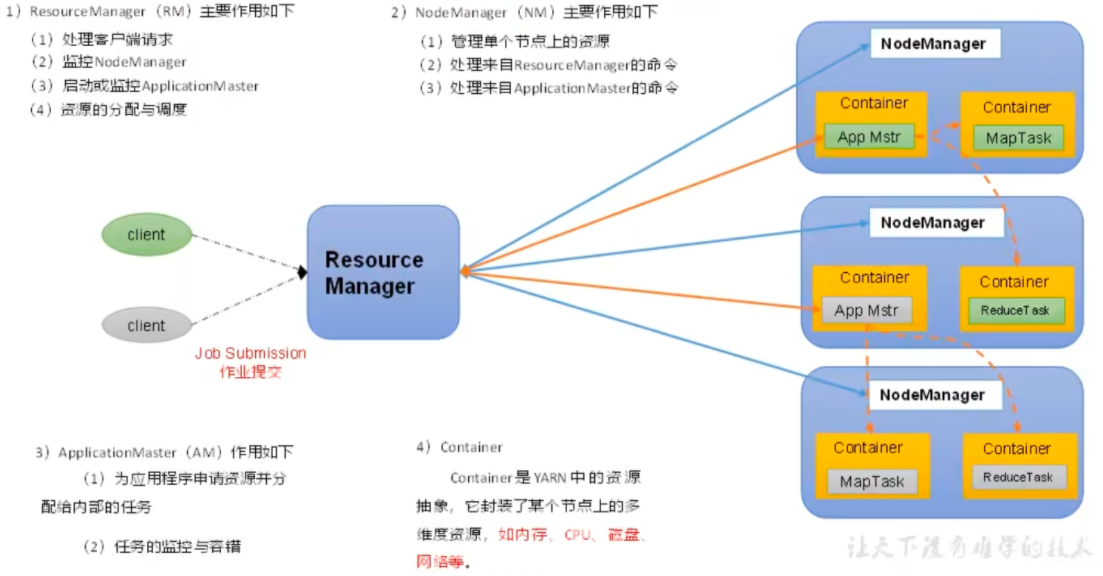
1) ResourceManager (RM): 整个集群资源 (内存、CPU 等) 的老大
2) NodeManager (NM): 单个节点服务器资源老大
3) ApplicationMaster (AM): 单个任务运行的老大
4) Container: 容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
说明 1: 客户端可以有多个
说明 2: 集群上可以运行多个 ApplicationMaster
说明 3: 每个 NodeManager 上可以有多个 Container
# 部署 hadoop1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 adduser hadoop vim /etc/sudoers %sudo ALL=(ALL:ALL) ALL hadoop ALL=(ALL:ALL) NOPASSWD:ALL hostnamectl vim /etc/hosts apt update apt install vim net-tools lrzsz bash-com* -y apt install openjdk-8-jre-headless wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz tar xzvf hadoop-3.3.6.tar.gz vim /etc/profile export HADOOP_HOME=/root/hadoop-3.3.6export PATH=$PATH :$HADOOP_HOME /binexport PATH=$PATH :$HADOOP_HOME /sbinexport JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64export PATH=$PATH :$JAVA_HOME /binsource /etc/profile
部署模式:
local: 数据存储在本地
pseudo-distributed:数据存储在 hdfs
fully-distributed:数据存储在 hdfs,多台服务器工作
本地运行 example wordcount
1 2 3 4 mkdir inputecho "aa bb cc cc dd dd dd ee ee" > input/111.txtbin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount input/ output/
# 完全分布式部署:NameNode 和 SecondaryNameNode 不要安装在同一台服务器
ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在同一台机器上
Hadoop 配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认。配置值时,才需要修改自定义配置文件,更改相应属性值。
默认配置文件
自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 四个配置文件存放在
SHADOOP_HOME/etc/kadop, 这个路径上,用户可以根据项目需求重新进行修改配置。
在集群上所有节点配置
core-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://hadoop100:8020</value > <description > The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.</description > </property > <property > <name > hadoop.tmp.dir</name > <value > /data/hadoop-${user.name}</value > <description > A base for other temporary directories.</description > </property > <property > <name > hadoop.http.staticuser.user</name > <value > root</value > <description > The user name to filter as, on static web filters while rendering content. An example use is the HDFS web UI (user to be used for browsing files). </description > </property > </configuration >
vim hdfs-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > dfs.namenode.http-address</name > <value > hadoop100:9870</value > <description > The address and the base port where the dfs namenode web ui will listen on. </description > </property > <property > <name > dfs.namenode.secondary.http-address</name > <value > hadoop102:9868</value > <description > The secondary namenode http server address and port. </description > </property > </configuration >
vim yarn-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <property> <description > A comma separated list of services where service name should only contain a-zA-Z0-9_ and can not start with numbers</description > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > <!--<value > mapreduce_shuffle</value > </property> <property > <description > The hostname of the RM.</description > <name > yarn.resourcemanager.hostname</name > <value > hadoop101</value > </property > <property > <description > Environment variables that containers may override rather than use NodeManager's default.</description > <name > yarn.nodemanager.env-whitelist</name > <value > JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRER_HOME</value > </property >
vim mapred-site.xml
1 2 3 4 5 6 7 <property> <name > mapreduce.framework.name</name > <value > yarn</value > <description > The runtime framework for executing MapReduce jobs. Can be one of local, classic or yarn. </description > </property>
vim worker
不能有空格
1 2 3 hadoop100 hadoop101 hadoop102
初始化 namenode
只有集群第一次启动需要初始化,此时会创建数据目录
启动集群
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 export HDFS_NAMENODE_USER =rootexport HDFS_DATANODE_USER =rootexport HDFS_SECONDARYNAMENODE_USER =rootexport YARN_RESOURCEMANAGER_USER =rootexport YARN_NODEMANAGER_USER =root# 只有在这里的java_home 他启动的时候才会认,他不认/etc/profile 和 ~/.bashrc vim etc/hadoop/hadoop-env.sh export JAVA_HOME =/root/ jdk8u352-b08sbin/start-dfs.sh jps确认 curl http : 启动resourcemanager export HDFS_NAMENODE_USER =rootexport HDFS_DATANODE_USER =rootexport HDFS_SECONDARYNAMENODE_USER =rootexport YARN_RESOURCEMANAGER_USER =rootexport YARN_NODEMANAGER_USER =root设置主机互信 sbin/start-yarn.sh 测试 hadoop fs -mkdir /input hadoop fs -put /root/hadoop-3.3 .6 /input/1. txt /input 存储位置 /data/hadoop-root/dfs/data/current/BP -897483346 -192.168 .13 .190 -1716822540714 /current/finalized/subdir0/subdir0 测试: hadoop jar /root/hadoop-3.3 .6 /share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3 .6 .jar wordcount /input /output 如果有报错,是需要往mapred-site.xml 中加东西的,那么添加如下字段,在重新执行 <property> <name > mapreduce.application.classpath</name > <value > $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value > </property> <property > <name > yarn.app.mapreduce.am.env</name > <value > HADOOP_MAPRED_HOME=${HADOOP_HOME}</value > </property > <property > <name > mapreduce.map.env</name > <value > HADOOP_MAPRED_HOME=${HADOOP_HOME}</value > </property > <property > <name > mapreduce.reduce.env</name > <value > HADOOP_MAPRED_HOME=${HADOOP_HOME}</value > </property >
https://www.cnblogs.com/miracle-luna/p/17785310.html
https://www.cnblogs.com/fanqisoft/p/17859086.html
# 故障处理:停进程,删除数据目录,格式化
# 记录历史运行情况启动 history server
mapred-site.xml
1 2 3 4 5 6 7 8 9 10 11 <property> <name>mapreduce.jobhistory.address</name> <value>hadoop100:10020</value> <description>MapReduce JobHistory Server IPC host:port</description> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop100:19888</value> <description>MapReduce JobHistory Server Web UI host:port</description> </property>
集群内同步该配置文件
重启 yarn
启动历史服务器,在 namenode
1 mapred --daemon start historyserver
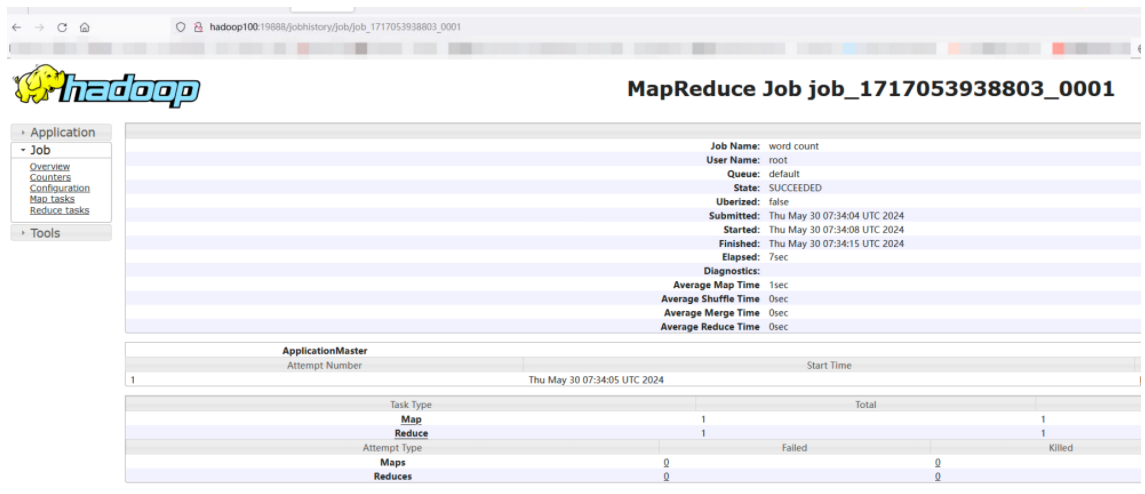
测试历史功能:
hadoop jar /root/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /input /output
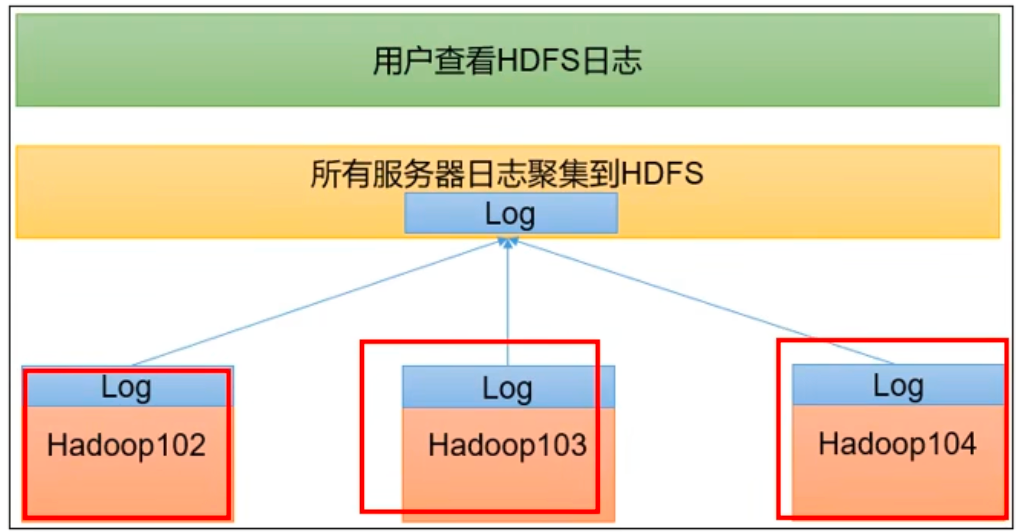
# 日志汇聚日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。
namenode:
yarn-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 <property > <description > Whether to enable log aggregation. Log aggregation collects each container's logs and moves these logs onto a file-system, for e.g. HDFS, after the application completes. Users can configure the "yarn.nodemanager.remote-app-log-dir" and "yarn.nodemanager.remote-app-log-dir-suffix" properties to determine where these logs are moved to. Users can access the logs via the Application Timeline Server. </description > <name > yarn.log-aggregation-enable</name > <value > true</value > </property > <property > <description > URL for log aggregation server </description > <name > yarn.log.server.url</name > <value > http://hadoop100:19888/jobhistory/logs</value > </property > <property > <description > How long to keep aggregation logs before deleting them. -1 disables. Be careful set this too small and you will spam the name node.</description > <name > yarn.log-aggregation.retain-seconds</name > <value > 604800</value > </property > mapred --daemon stop historyserver stop-yarn.sh start-yarn.sh mapred --daemon start historyserver
启新任务观察:
对于单个组件重启
1 2 3 4 5 6 7 8 9 (1)分别启动/停止HDFS组件e hdfs --daemon start/stop namenode/datanode/secoondarynamenode (2)启动/停止YARN yarn --daemon start/stop resourcemanager/nodemanager #! /bin/bash ssh hadoop100 "/root/hadoop-3.3.6/sbin/start-dfs.sh ssh hadoop101 "/root/hadoop-3.3.6/sbin/start-yarn.sh ssh hadoop100 "mapred --daemon start historyserver"
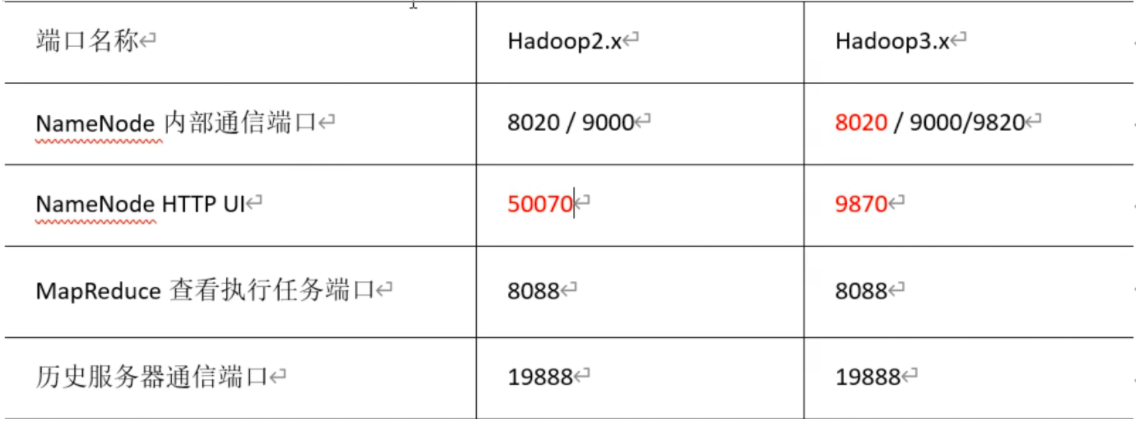
# 常用端口号
常用端口号
hadoop3.x
HDFS NameNode 内部通常端口:8020/9000/9820
HDFS NameNode 对用户的查询端口:9870
Yarn 查看任务运行情况的:8088
历史服务器:19888
hadoop2.x
HDFS NameNode 内部通常端口:8020/9000
HDFS NameNode 对用户的查询端口:50070
Yarn 查看任务运行情况的:8088
历史服务器:19888
常用的配置文件
3.x core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml workers
2.x core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml slaves
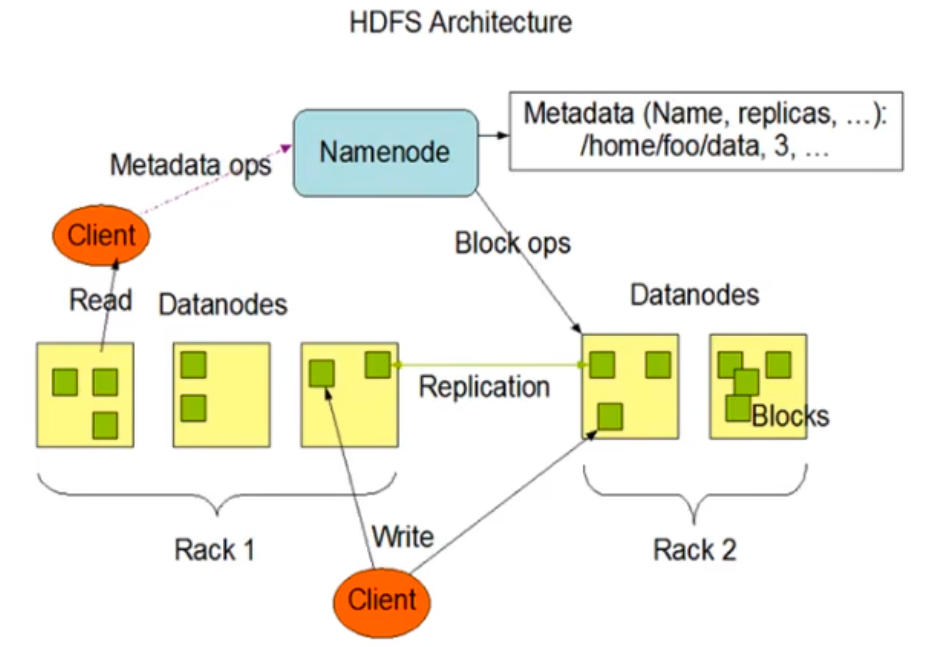
# hdfsHDFS (Hadoop Distributed File System), 它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起起来实现其功能,集群中的服务器有各自的角色。
HDFS 的使用场景:适合一次写入,多次读出的场景。一个个文件经过创建、写入和关闭之后就不能改变。
高容错性
数据自动保存多个副本。它通过增加副本的形式,提高容错性。
适合处理大数据
数据规模:能够处理数据规模达到 GB、TB、甚至 PB 级别的数据
文件规模:能够处理百万规模以上的文件数量,数量相当之大。
可构建在廉价机器上,通过多副本机制,提高可靠性。
不适合低延时数据访问,比如毫秒级的存储数据,是做不到到的
无法高效的对大量小文件进行存储。
存储大量小文件的话,它会占用 NameNode 大量的内存来存储文件目录和块信息。这样是不可取的,因为 NameNode 的内存总是有限的;
小文件存储的寻址时间会超过读取时间,它违反了 HDFS 的设计目标。
不支持并发写入、文件随机修改。
一个文件只能有一个写,不允许多个线程同时写;
仅支持数据 append (追加), 不支持文件的随机修改。
1) NameNode (nn): 就是 Master, 它是一个主管、管理者。
(1) 管理 HDFS 的名称空间;
(2) 配置副本策略;
(3) 管理数据块 (Block) 映射信息;
(4) 处理客户端读写请求。
DataNode: 就是 Slave。NameNode 下达命令,DataNode 执行实际的操作。
(1) 存储实际的数据块;
(2) 执行数据块的读 / 写操作。
3) Client: 就是客户端。
(1) 文件切分。文件上传 HDFS 的时候,Client 将文件切分成一个一个的 Block, 然后进行上传;
(2) 与 NameNode 交互,获取文件的位置信息;
(3) 与 DataNode 交互,读取或者写入数据;
(4) Client 提供一些命令来管理 HDFS, 比如 NameNode 格式化;
(5) Client 可以通过一些命令来访问 HDFS, 比如对 HDFS 增删查改操作;
4) Secondary NameNode: 并非 NameNode 的热备。当 NameNode 挂掉的时候,它并不
能马上替换 NameNode 并提供服务。
(1) 辅助 NameNode, 分担其工作量,比如定期合并 Fsimage 和 bEdits, 并推送给 NameNode;
(2) 在紧急情况下,可辅助恢复 NameNode。
HDFS 中的文件在物理上是分块存储 (Block), 块的大小可以通过配置参数 (dfs.blocksize) 来规定,默认大小在 Hadoop2.x/3.x 版本中是 128M,1.x 版本中是 64M。
磁盘速率更快的情况下,可以设置为 256M
(1) HDFS 的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
(2) 如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。
HDFS 块的大小设置主要取决于磁盘传输速率。
# hdfs shell1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 hadoop fs -mkdir /haha # 上传,剪切本地文件 hadoop fs -moveFromLocal ./README.txt /haha # 复制本地文件 hadoop fs -copyFromLocal ./README.txt /haha # 复制本地文件 hadoop fs -put ./README.txt /haha # 追加文件到另一个文件末尾 hadoop fs -appendToFile ./README.txt /haha/www.txt # 下载 hadoop fs -copyToLocal /haha/1.txt ./1111.txt # 下载 hadoop fs -get /haha/1.txt ./1111.txt # hadoop fs -ls / hadoop fs -cat /haha/111.txt hadoop fs -chown aaa:aaa /haha/1.txt hadoop fs -cp hadoop fs -mv /haha/1.txt /xixix/2.txt # 显示一个文件的末尾1kb数据 hadoop fs -tail /haha/1.txt # 删除文件或文件夹 hadoop fs -rm hadoop fs -rm -r # 查看文件夹下总大小 hadoop fs -du -s -h /haha # 查看文件下每个文件大小 hadoop fs -du -h /haha # 修改副本大小,副本数大于机器数量时,只会创建对应的副本数。后续集群内新增机器,会增加到对应的数量。但是永远保持每个机器上至多一个副本 hadoop fs -setrep 10 /haha/1.txt
# hadoop api1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 在windows下安装hadoop+winutils https://blog.csdn.net/shulianghan/article/details/132045605 # 配置maven https://blog.csdn.net/m0_46413065/article/details/116400168 https://blog.csdn.net/m0_46413065/article/details/116400995 hdfs-default < hdfs-site < resource < 代码里修改configuraion.set https://blog.csdn.net/m0_46413065/article/details/116400168 https://blog.csdn.net/weixin_50956145/article/details/130511265 https://mvnrepository.com/artifact/org.slf4j/slf4j-log4j12/1.7.30 https://www.bilibili.com/read/cv28415867/?jump_opus=1 https://www.cnblogs.com/linshengqian/p/15657694.html https://www.runoob.com/maven/maven-build-life-cycle.html https://www.cnblogs.com/xfeiyun/p/16740262.html https://blog.csdn.net/m0_46413065/article/details/116400995
mvn 处理依赖
https://blog.csdn.net/lixld/article/details/82284269
https://blog.csdn.net/qq_44886213/article/details/123461522
https://mvnrepository.com/artifact/org.slf4j/slf4j-reload4j/2.1.0-alpha1
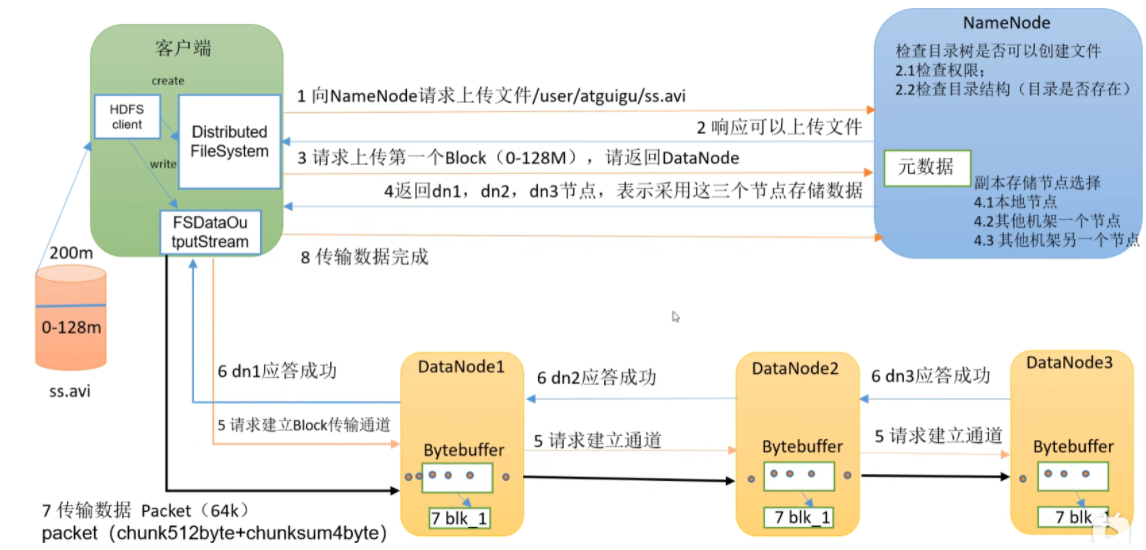
# hdfs 写流程
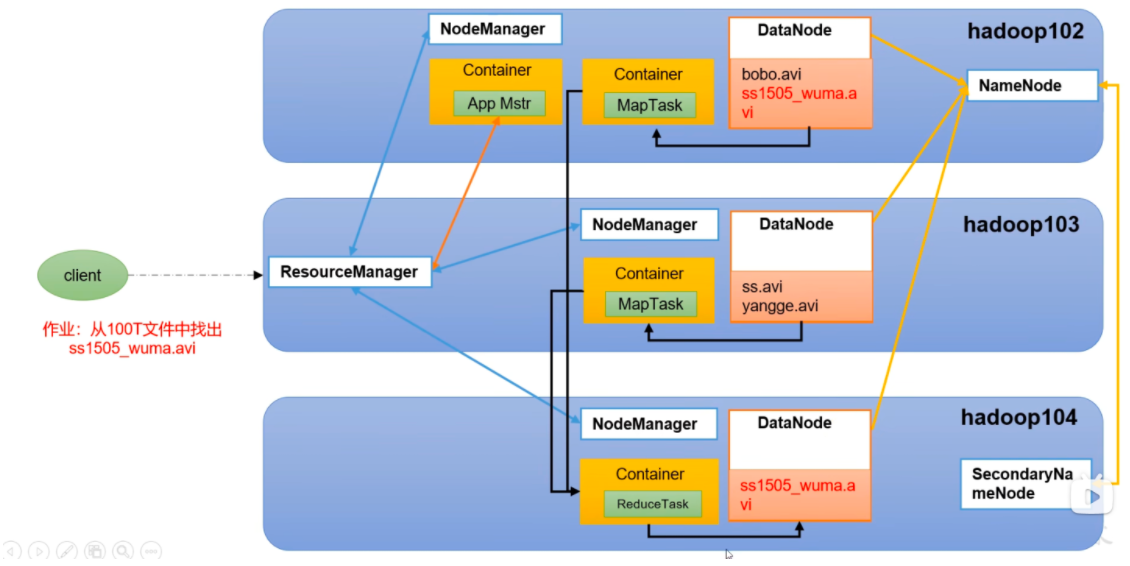
(1)客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件,NameNode 检查目标文件是否已存在,父目录是否存在。
(2)NameNode 返回是否可以上传。
(3)客户端请求第一个 Block 上传到哪几个 DataNode 服务器上。
(4)NameNode 返回 3 个 DataNode 节点,分别为 dn1、dn2、dn3。
(5)客户端通过 FSDataOutputStream 模块请求 dn1 上传数据,dn1 收到请求会继续调用 dn2,然后 dn2 调用 dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3 逐级应答客户端。
(7)客户端开始往 dn1 上传第一个 Block(先从磁盘读取数据放到一个本地内存缓存),以 Packet 为单位,dn1 收到一个 Packet 就会传给 dn2,dn2 传给 dn3;dn1 每传一个 packet 会放入一个应答队列等待应答。
(8)当一个 Block 传输完成之后,客户端再次请求 NameNode 上传第二个 Block 的服务器。(重复执行 3-7 步)。
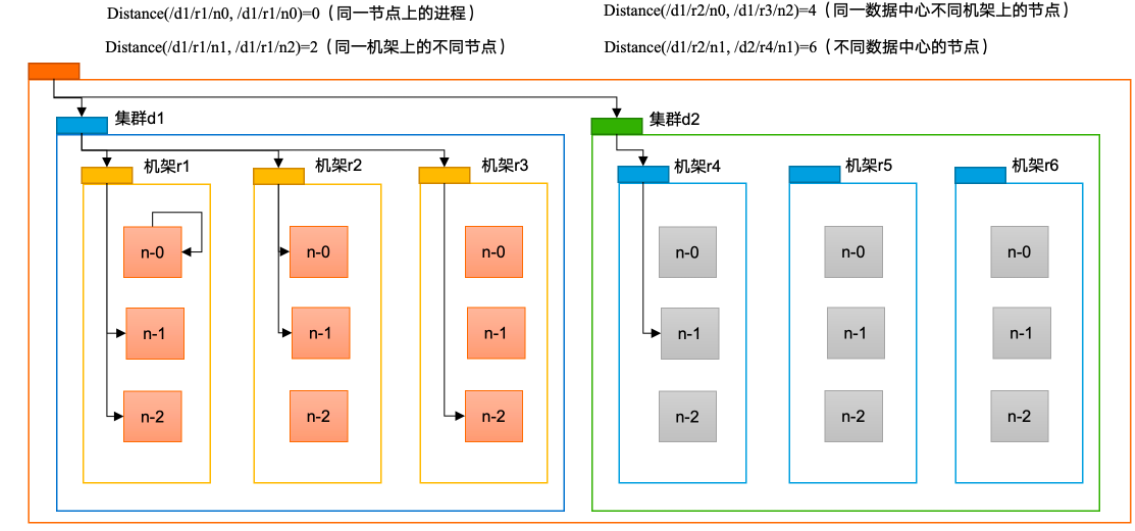
# 网络拓扑 - 节点距离计算在 HDFS 写数据的过程中,NameNode 会选择距离待上传数据最近距离的 DataNode 接收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和
第一个副本在 Client 所处的节点上。如果客户端在集群外,随机选一个
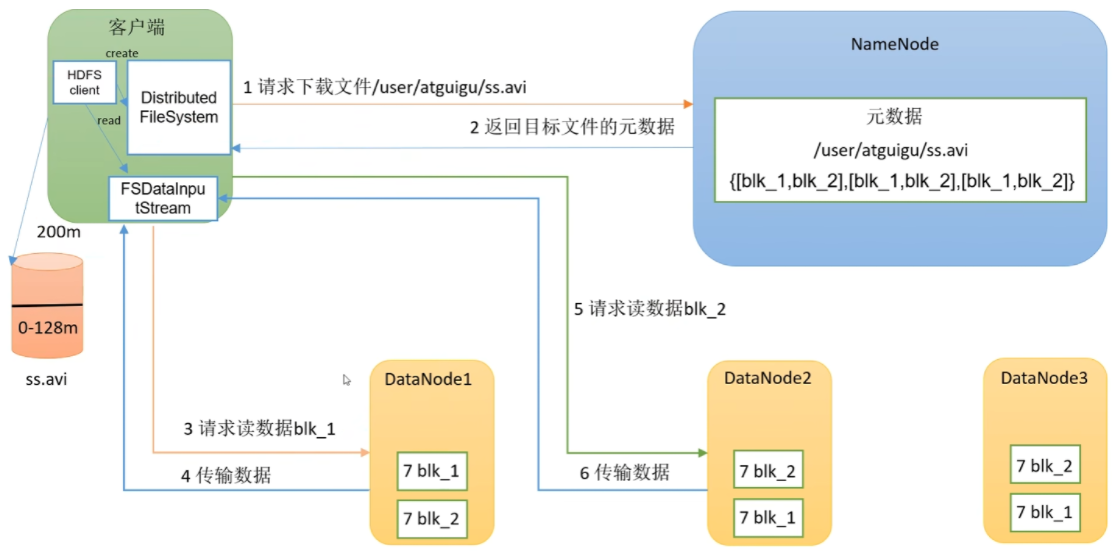
# hdfs 读流程
判断权限,文件是否存在
选择原则:节点距离,节点负载
串行读
(1)客户端通过 DistributedFileSystem 向 NameNode 请求下载文件,NameNode 通过查询元数据,找到文件块所在的 DataNode 地址。
(2)挑选一台 DataNode(就近原则,然后随机)服务器,请求读取数据。
(3)DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位来做校验)。
(4)客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。
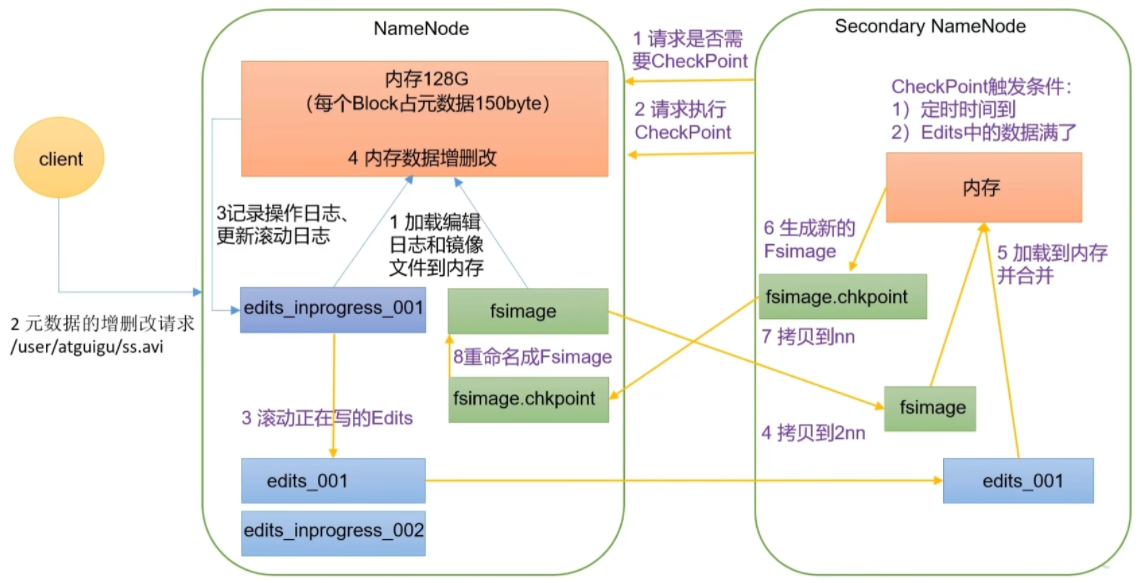
# nn & 2nn
(1) Fsimage 文件:HDFS 文件系统元数据的一个永久性的检查点其中包含 HDFS 文件系统的所有目录和文件 inode 的序列化信息。
Edits 文件:存放 HDFS 文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到 Edits 文件中。
(3) seen txid 文件保存的是一个数字,就是最后一个 edits 的数字
(4) 每次 NameNode 启动的时候都会将 Fsimage 文件读入内存,加载 Edits 里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成 NameNode 启动的时候就将 Fsimage 和 Edits 文件进行了合并。
查看镜像文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 hdfs oiv -p XML -i fsimage_0000000000000000517 -o /root/image.xml 2024 -06 -03 13 :21 :15 ,479 INFO offlineImageViewer.FSImageHandler : Loading 5 strings2024 -06 -03 13 :21 :15 ,494 INFO namenode.FSDirectory : GLOBAL serial map : bits=29 maxEntries=536870911 2024 -06 -03 13 :21 :15 ,494 INFO namenode.FSDirectory : USER serial map : bits=24 maxEntries=16777215 2024 -06 -03 13 :21 :15 ,494 INFO namenode.FSDirectory : GROUP serial map : bits=24 maxEntries=16777215 2024 -06 -03 13 :21 :15 ,494 INFO namenode.FSDirectory : XATTR serial map : bits=24 maxEntries=16777215 <?xml version="1.0" ?> <fsimage><version > <layoutVersion > -66</layoutVersion > <onDiskVersion > 1</onDiskVersion > <oivRevision > 1be78238728da9266a4f88195058f08fd012bf9c</oivRevision > </version > <NameSection > <namespaceId > 345030828</namespaceId > <genstampV1 > 1000</genstampV1 > <genstampV2 > 1040</genstampV2 > <genstampV1Limit > 0</genstampV1Limit > <lastAllocatedBlockId > 1073741864</lastAllocatedBlockId > <txid > 517</txid > </NameSection > <ErasureCodingSection > <erasureCodingPolicy > <policyId > 1</policyId > <policyName > RS-6-3-1024k</policyName > <cellSize > 1048576</cellSize > <policyState > DISABLED</policyState > <ecSchema > <codecName > rs</codecName > <dataUnits > 6</dataUnits > <parityUnits > 3</parityUnits > </ecSchema > </erasureCodingPolicy > <erasureCodingPolicy > <policyId > 2</policyId > <policyName > RS-3-2-1024k</policyName > <cellSize > 1048576</cellSize > <policyState > DISABLED</policyState > <ecSchema > <codecName > rs</codecName > <dataUnits > 3</dataUnits > <parityUnits > 2</parityUnits > </ecSchema > </erasureCodingPolicy > <erasureCodingPolicy > <policyId > 3</policyId > <policyName > RS-LEGACY-6-3-1024k</policyName > <cellSize > 1048576</cellSize > <policyState > DISABLED</policyState > <ecSchema > <codecName > rs-legacy</codecName > <dataUnits > 6</dataUnits > <parityUnits > 3</parityUnits > </ecSchema > </erasureCodingPolicy >
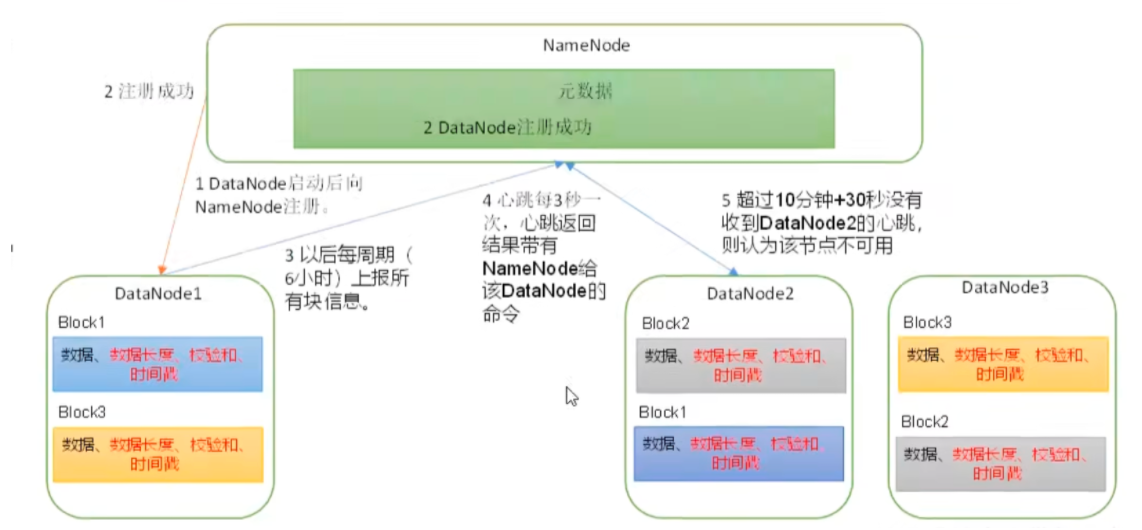
datanode 主动向 namenode 上报文件快信息
# 查看 edits 日志1 2 3 4 5 6 7 8 9 10 hdfs oev -p XML -i /data/hadoop-root/dfs/name/current/edits_inprogress_0000000000000000520 -o /root/image.xml 记录操作步骤,仅进行追加 每进行一小时进行合并 2nn没有edits_progres namenode 会把edit_Progress 后的合并 比如后面合并356 以后的
# checkpoint1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 <property > <name > dfs.namenode.checkpoint.period</name > <value > 3600</value > <description > The number of seconds between two periodic checkpoints. Support multiple time unit suffix(case insensitive), as described in dfs.heartbeat.interval.If no time unit is specified then seconds is assumed. </description > </property > <property > <name > dfs.namenode.checkpoint.txns</name > <value > 1000000</value > <description > The Secondary NameNode or CheckpointNode will create a checkpoint of the namespace every 'dfs.namenode.checkpoint.txns' transactions, regardless of whether 'dfs.namenode.checkpoint.period' has expired. </description > </property > <property > <name > dfs.namenode.checkpoint.check.period</name > <value > 60</value > <description > The SecondaryNameNode and CheckpointNode will poll the NameNode every 'dfs.namenode.checkpoint.check.period' seconds to query the number of uncheckpointed transactions. Support multiple time unit suffix(case insensitive), as described in dfs.heartbeat.interval.If no time unit is specified then seconds is assumed. </description > </property > 3600s每隔一小时执行一次 或者每100w次执行一次,每隔60s看下有没有到100w
# datanode
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <property > <name > dfs.blockreport.intervalMsec</name > <value > 21600000</value > <description > Determines block reporting interval in milliseconds.</description > </property > <property > <name > dfs.datanode.directoryscan.interval</name > <value > 21600</value > <description > Interval in seconds for Datanode to scan data directories and reconcile the difference between blocks in memory and on the disk. Support multiple time unit suffix(case insensitive), as described in dfs.heartbeat.interval.If no time unit is specified then seconds is assumed. </description > </property >
# 数据完整性1 2 3 4 5 6 如下是DataNode节点保证数据完整性的方法。 (1)当DataNode读取Block的时候,它会计算CheckSum。 (2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。 (3)Client读取其他DataNode上的Block。 (4)常见的校验算法crc(32),md5(128),shal(160) (5)DataNode在其文件创建后周期验证CheckSum。
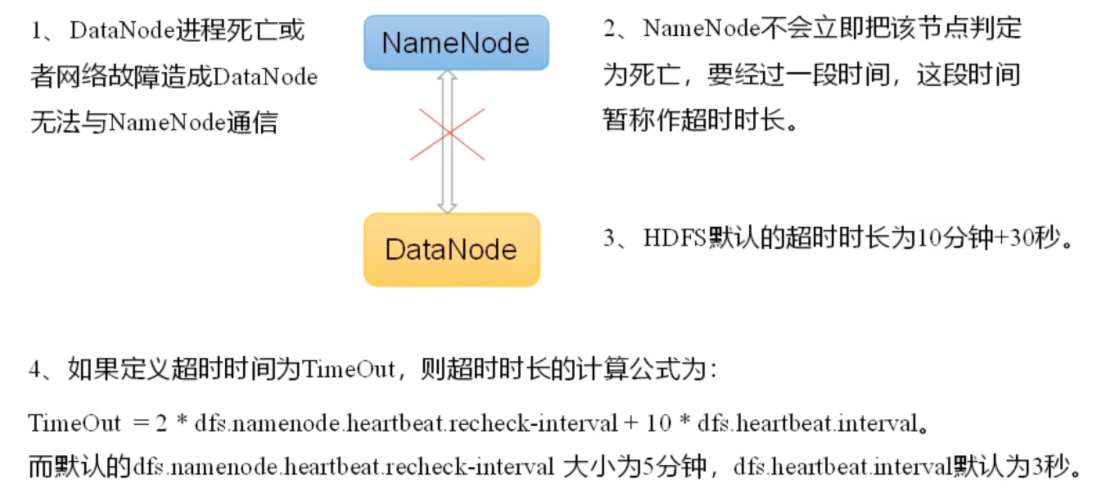
# 掉线参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 <property > <name > dfs.heartbeat.interval</name > <value > 3</value > <description > Determines datanode heartbeat interval in seconds. Can use the following suffix (case insensitive): ms(millis), s(sec), m(min), h(hour), d(day) to specify the time (such as 2s, 2m, 1h, etc.). Or provide complete number in seconds (such as 30 for 30 seconds). If no time unit is specified then seconds is assumed. </description > </property > <property > <name > dfs.namenode.heartbeat.recheck-interval</name > <value > 300000</value > <description > This time decides the interval to check for expired datanodes. With this value and dfs.heartbeat.interval, the interval of deciding the datanode is stale or not is also calculated. The unit of this configuration is millisecond. </description > </property > hdfs块大小 读写速度越快,块可以配置越大。一般是128M或者256M shell操作 读些流程
# mapreduceMapReduce 是一个分布式运算程序的编程框架,是用户开发 "基于 Hadoop 的数据分析应用" 的核心框架。
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。
MapReduce: 自己处理业务相关代码 + 自身的默认代码
优点:
1、易于编程。用户只关心,业务逻辑。实现框架的接口。
2、良好扩展性:可以动态增加服务器,解决计算资源不够问题
3、高容错性。任何一台机器挂擦,可以将任务转移到其他节点。
4、适合海量数据计算 (TB/PB) 几千台服务器共同计算。
重阳市公安局
トラスメット吉祥如意
半夏散文章
Праведая праведая我姓张却长不出你爱的模样
天下之忧而忧无虑
小麦小兜到了解那样的很美
多少年重阳节快乐成长庚子大吉
缺点:
1、不擅长实时计算。Mysql
2、不擅长流式计算。Sparkstreaming flink
3、不擅长 DAG 有向无环图计算。spark
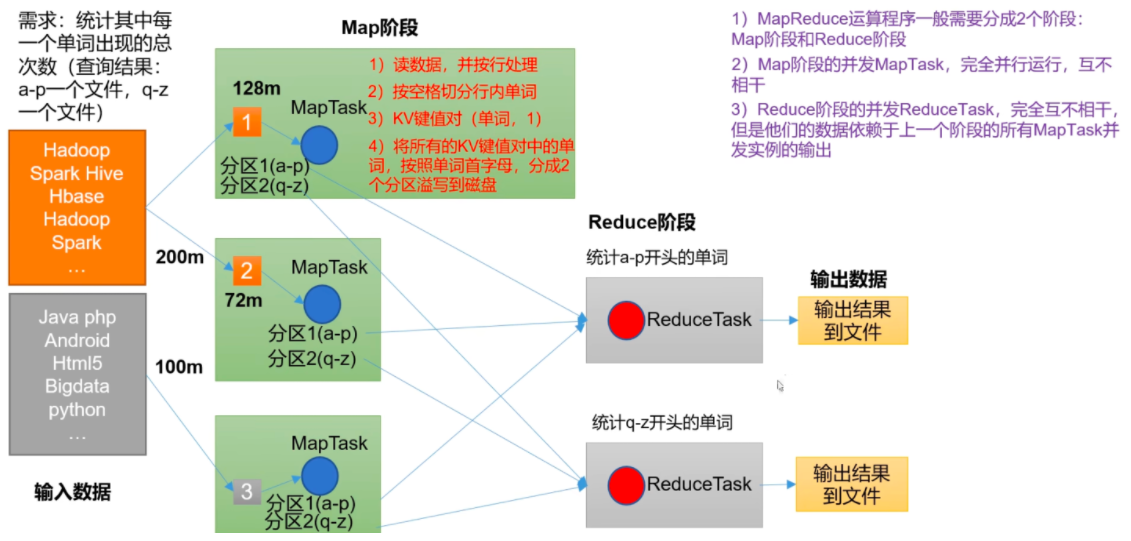
1) MapReduce 运算程序一般需要分成 2 个阶段:Map 阶段和 Reduce 阶段
2) Map 阶段的并发 MapTask, 完全并行运行,互不相干
3) Reduce 阶段的并发 ReduceTask, 完全互不相干,但是他们的数据依赖于上一个阶段的所有 MapTask 并发实例的输出
4) MapReduce 编程模型只能包含一个 Map 阶段和一个 Reduce 阶段,如果用户的业务逻辑非常复杂,那就只能多个 MapReduce 程序,串行运行
一个完整的 MapReduce 程序在分布式运行时有三类实例进程:
(1) MrAppMaster: 负责整个程序的过程调度及状态协调。
(2) MapTask: 负责 Map 阶段的整个数据处理流程。
(3) ReduceTask: 负责 Reduce 阶段的整个数据处理流程。
数据序列化类型
# mapreduce 编程规范1.Mapper 阶段
(1) 用户自定义的 Mapper 要继承自己的父类
(2) Mapper 的输入数据是 KV 对的形式 (KV 的类型可自定义)
(3) Mapper 中的业务逻辑写在 map () 方法中
(4) Mapper 的输出数据是 KV 对的形式 (KV 的类型可自定义)
(5) map () 方法 (MapTask 进程) 对每一个 < K,V > 调用一次
2.Reducer 阶段
(1) 用户自定义的 Reducer 要继承自己的父类
(2) Reducer 的输入数据类型对应 Mapper 的输出数据类型,也是 KV
(3) Reducer 的业务逻辑写在 reduce () 方法中
ReduceTask 进程对每一组相同 k 的 <k,v> 组调用一次 reduce () 方法法
3.Driver 阶段
相当于 YARN 集群的客户端,用于提交我们整个程序到 YARN 集群,提交的是
封装了 MapReduce 程序相关运行参数的 job 对象
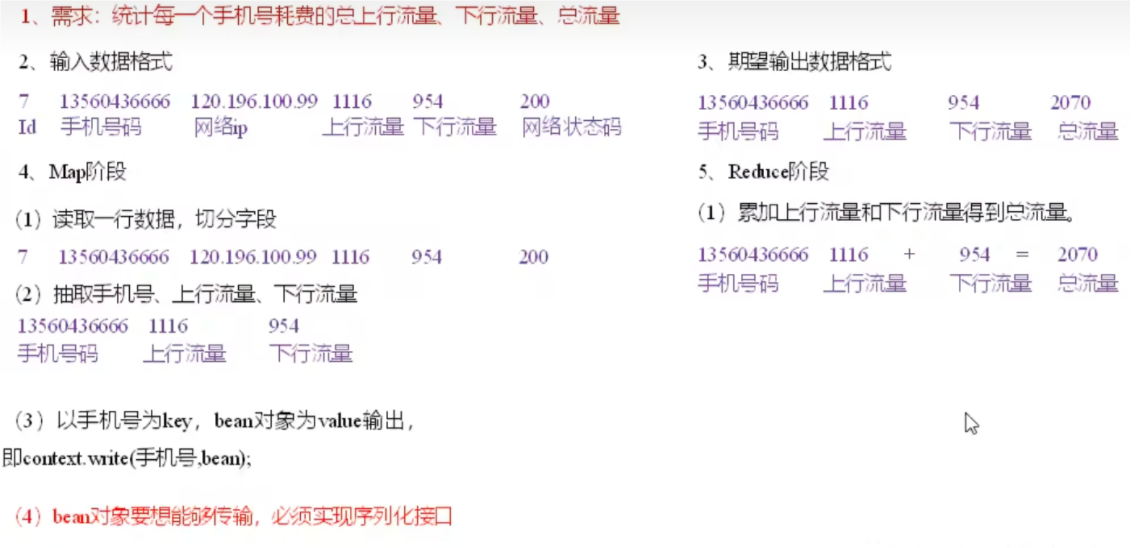
# wordcount1.mapper
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package org.example.wordcount2;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class WordCountMapper extends Mapper <LongWritable , Text, Text, IntWritable>{ private Text outk = new Text (); private IntWritable outv = new IntWritable (1 ); @Override protected void map (LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { String line = value.toString(); String[] words = line.split(" " ); for (String word:words){ outk.set(word); context.write(outk,outv); } } }
reducer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package org.example.wordcount2;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordCountReducer extends Reducer { private IntWritable outV = new IntWritable (); protected void reduce (Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0 ; for (IntWritable value : values) { sum += value.get(); } outV.set(sum); context.write(key,outV); } }
driver
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 package org.example.wordcount2;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCountDriver { public static void main (String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration (); Job job = Job.getInstance(conf); job.setJarByClass(WordCountDriver.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path (args[0 ])); FileOutputFormat.setOutputPath(job, new Path (args[1 ])); boolean result = job.waitForCompletion(true ); System.exit(result ? 0 : 1 ); } }
package,将没有依赖的包放到 hadoop 集群执行
1 hadoop jar MapReduceDemo-1.0 -SNAPSHOT.jar org.example.wordcount2.WordCountDriver /input /uuu
https://blog.csdn.net/m0_46413065/article/details/116419326
# 序列化
java 自带 serializable 很重,带了各种校验头信息。
hadoop 序列化:
紧凑:存储空间少
快速:传输速度快
互操作性:
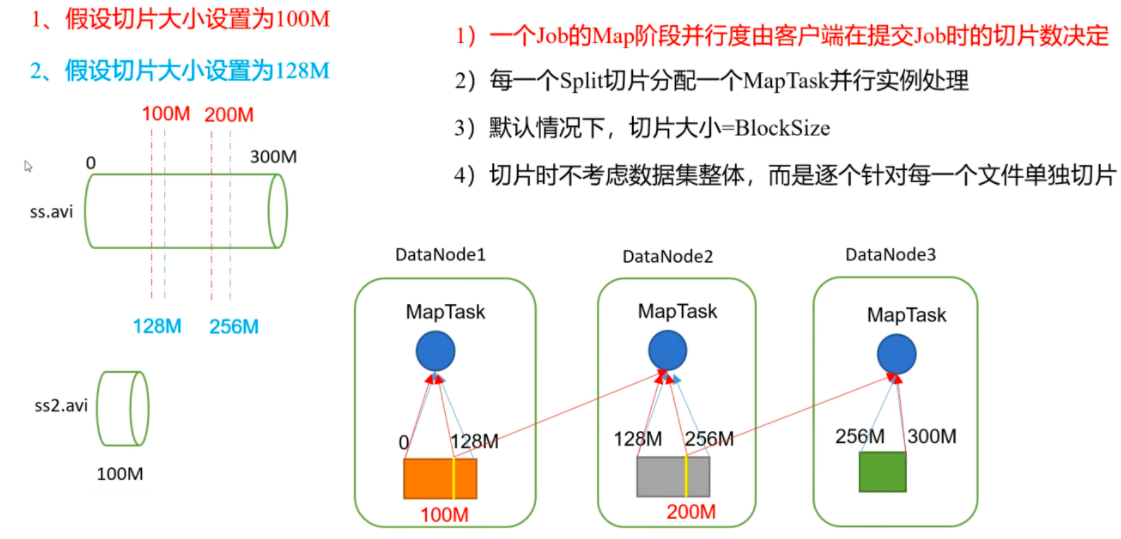
# mapreduce 框架原理MapTask 并行度决定机制
数据块:Block 是 HDFS 物理上把数据分成一块一块。数据块是 HDFS 存储数据单位。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是 MapReduce 程序计算输入数据的单位,一个切片会对应启动一个 MapTask。
(1) 源码中计算切片大小的公式
Math.max(minSize, Math.min(maxSize, blockSize));
mapreduce.input.fileinputformat.split.minsize=1 默认值为 1
mapreduce.input.fileinputformat.split.maxsize=Long.MAXValue 默认值 Long.MAXValue
因此,默认情况下,切片大小 = blocksize。
(2) 切片大小设置
maxsize (切片最大值): 参数如果调得比 blockSize 小,则会让切片变小,而且就等于配置的这个参数的值。
minsize (切片最小值): 参数调的比 blockSize 大,则可以让切片变得比 blockSize 还大。
(3) 获取切片信息 API
// 获取切片的文件名称
String name = inputSplit.getPath().getNamie ();
// 根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit) context.getInputsplit()
FileInputFormat 常见的接口实现类包括:TextInputFormat、KeyValuue TextInputFormat 、NLineInputFormat、CombineTextInputFormat 和自定义 InputFormat 等。
# textinputformat 切片机制TextInputFormat 是默认的 FileInputFormat 实现类。按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量,LongWritable 类型。值是这行的内容,不包括任何行终止符 (换行符和回车符),Text 类型。
# combinetextinputformat框架默认的 TextInputFormat 切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个 MapTask, 这样如果有大量小文件,就会产生大量的 MapTask, 处理效率极其低下。
1) 应用场景:
CombineTextInputFormat 用于小文件过多的场景,它可以将多个 / 小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个 MapTask 处理。T
2) 虚拟存储切片最大值设置 (
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
3) 切片机制~
生成切片过程包括:虚拟存储过程和切片过程二部分。
切片过程
(a) 判断虚拟存储的文件大小是否大于 setMaxInputSplitSize 值,大于等于则单独形成一个切片。
(b) 如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
1 2 3 4 5 6 7 8 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setInputFormatClass(CombineTextInputFormat.class); CombineTextInputFormat.setMaxInputSplitSize(job,4194034 ); FileInputFormat.setInputPaths(job, new Path (args[0 ])); FileOutputFormat.setOutputPath(job, new Path (args[1 ]));
# mapreduce 工作流程
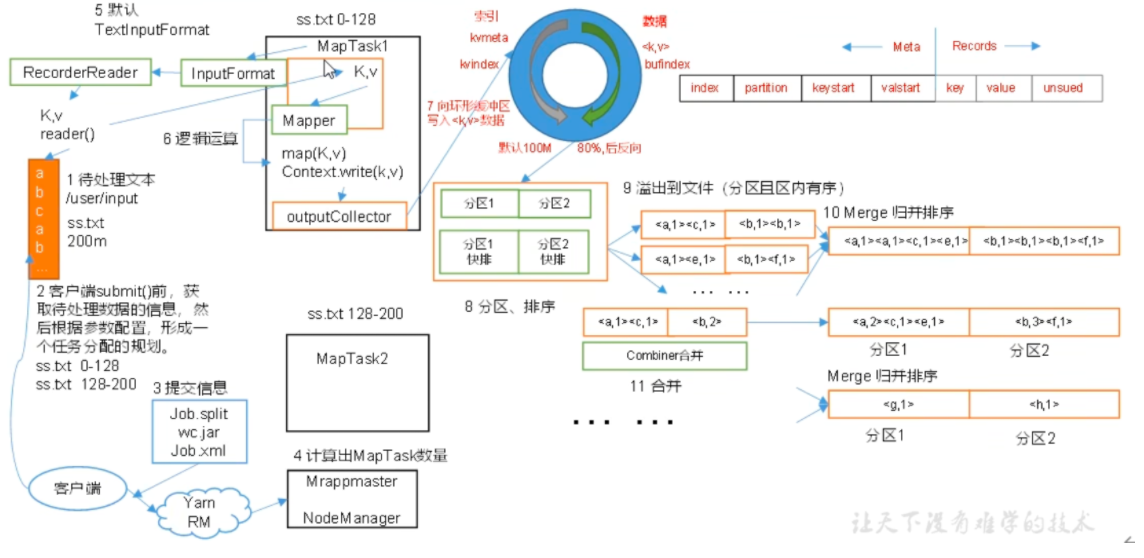
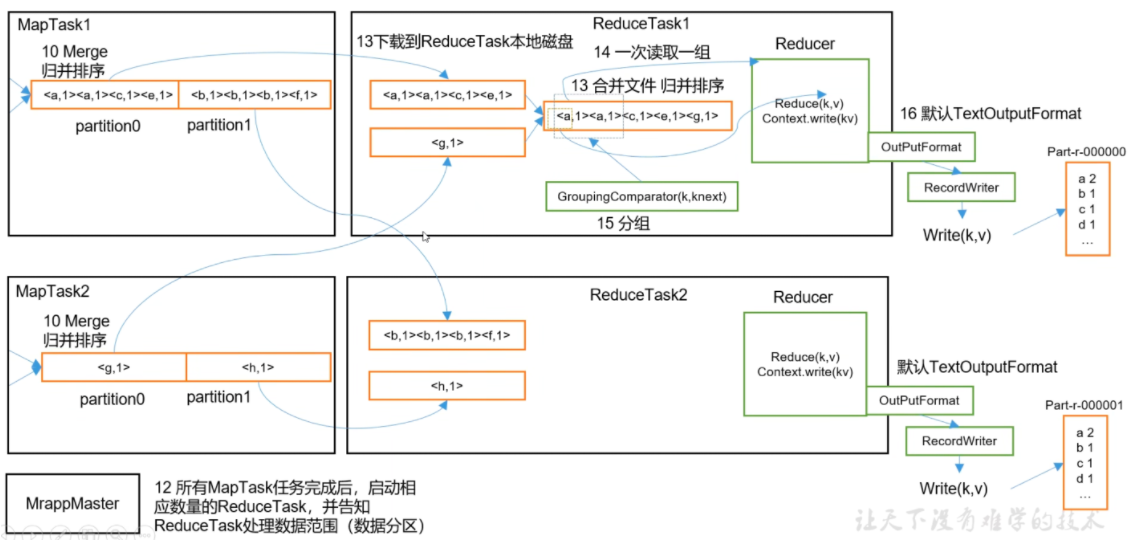
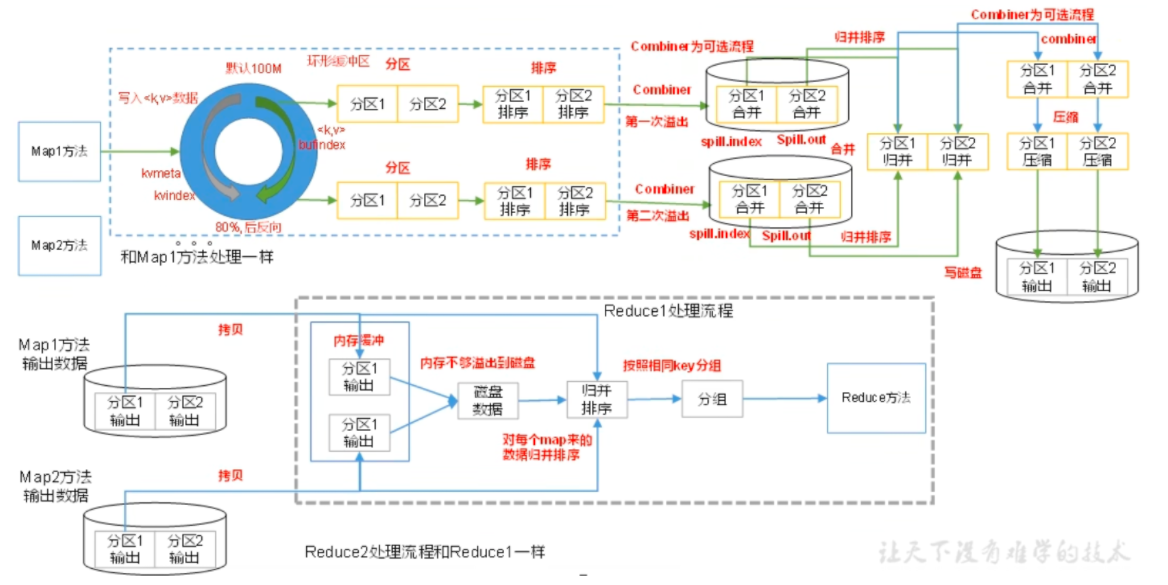
# shuffleMap 方法之后,Reduce 方法之前的数据处理过程称之为 Shuffle。
可以进行排序压缩等操作
maptask 阶段:
对 key 的索引按照字典序快排
# partition 分区要求将统计结果按照条件输出到不同文件中 (分区)
1 2 3 4 5 6 7 8 9 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setInputFormatClass(CombineTextInputFormat.class); job.setNumReduceTasks(2 ); public class HashPartitioner <K, V> extendss Partitioner<K, V> { public int getPartition (K key, V value, int 1humReduceTasks) return (key.hashCode() & Integer.MAX_VALUE)៖ numReduceTasks;
如果分区 > 1 才有 hash
否则直接 partition-1 = 0 只有 0 号分区
默认分区是根据 key 的 hashCode 对 ReduceTasks 个数取模得到的。用户没法控制哪个 key 存储到哪个分区。
自定义 partitoner
# 排序对于 MapTask, 它会将处理的结果暂时放到环形缓冲区中,当环不形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有有文件进行归并排序。
对于 ReduceTask, 它从每个 MapTask 上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内字中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask 统一对内存和磁盘上的所有数据进行一次师日并排序
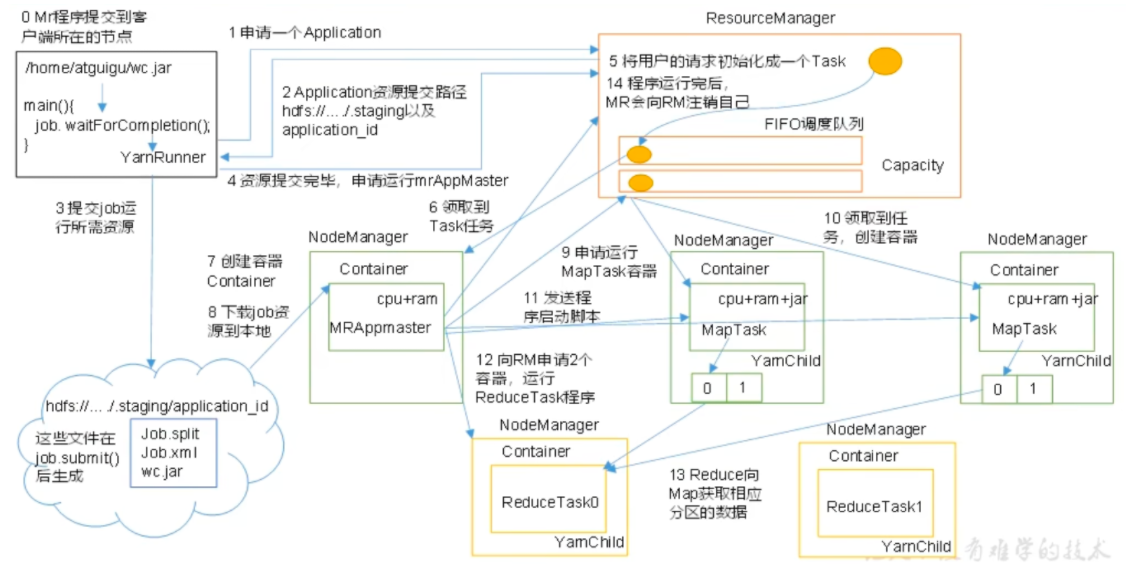
# yarnYam 是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而 MapReduce 等运算程序则相当于运行于操作系统之上的应用程序。
YARN 主要由 ResourceManager、NodeManager、ApplicationMaster 和 Container 等组件构成。
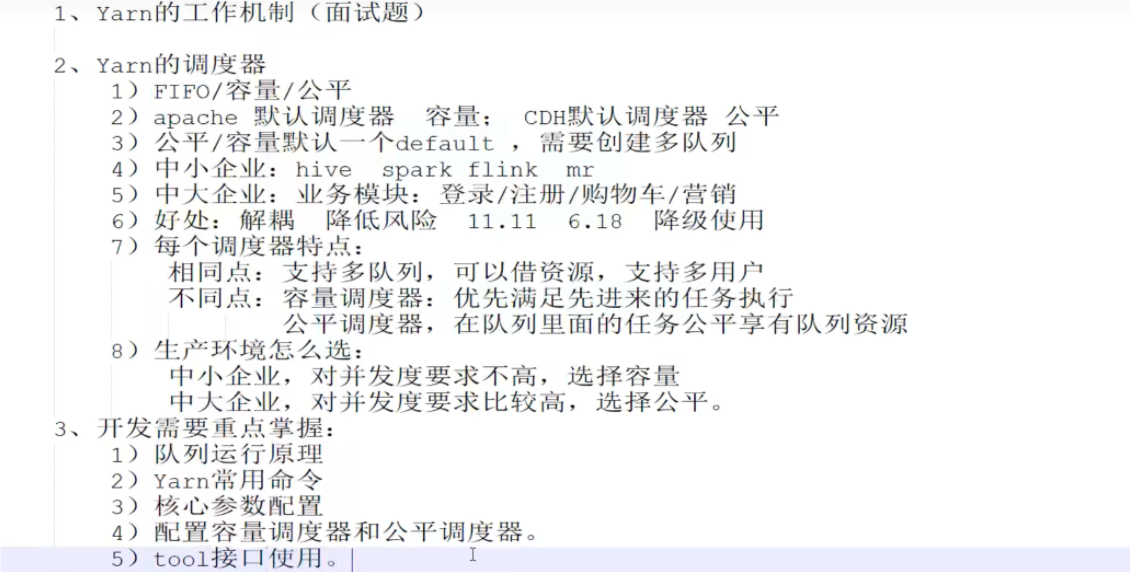
# yarn 调度器目前,Hadoop 作业调度器主要有三种:FIFO、容量 (CapacityScheduler) 和公平 (Fair Scheduler)。Apache Hadoop3.1.3 默认的资源调度器是 Capacity SScheduler
# FIFO 调度器(FirstInFirstOut) 单队列,根据提交作业的先后顺序,先来先服务
# 容量调度器1、多队列:每个队列可配置一定的资源量,每个队列采用 FIFO 调度策略。
2、容量保证:管理员可为每个队列设置资源最低保证和资源使用上限
3、灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。
4、多租户:支持多用户共享集群和多应用程序同时运行。为了防止同一个用户的作业独占队列中的资源,该调度器会又对同一用户提交的作业所占资源量进行限定。
1) 队列资源分配
从 root 开始,使用深度优先算法,优先选择资源占用率最低的队列分配资源。
2) 作业资源分配
默认按照提交作业的优先级和提交时间顺序分配资源。
3) 容器资源分配
按照容器的优先级分配资源;如果优先级相同,按照数据本地性原则:
(1) 任务和数据在同一节点
(2) 任务和数据在同一机架
(3) 任务和数据不在同一节点也不在同一机架
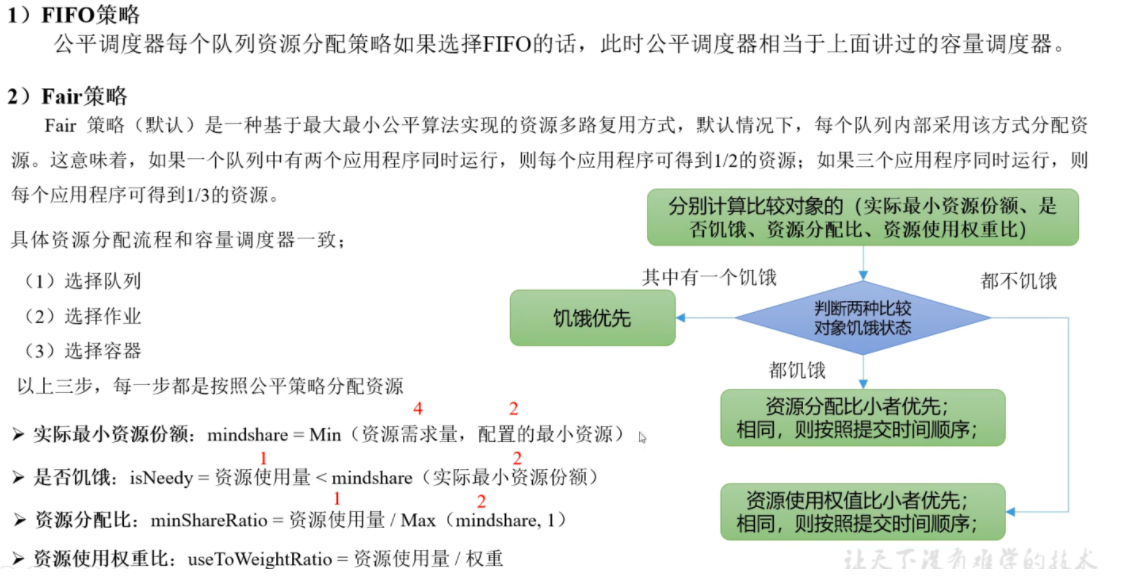
# 公平调度器同队列所有任务共享资源,在时间尺度上获得公平的资源
1) 与容量调度器相同点
(1) 多队列:支持多队列多作业
(2) 容量保证:管理员可为每个队列设置资源最低保证和资源使用上线
(3) 灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。
(4) 多租户:支持多用户共享集群和多应用程序同时运行;为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
2) 与容量调度器不同点
(1) 核心调度策略不同
容量调度器:优先选择资源利用率低的队列
公平调度器:优先选择对资源的缺额比例大的
(2) 每个队列可以单独设置资源分配方式
容量调度器:FIFO,DRF
公平调度器:FIFO,DRF,FAIR
公平调度器设计目标是:在时间尺度上,所有作业获得公平的的资源。某一时刻一个作业应获资源和实际获取资源的差距叫 "缺额"
调度器会优先为缺额大的作业分配资源
# DRFDRF (DominantResource Fairness), 我们之前说的资源,都那是单一标准,例如只考虑内存 (也是 Yam 默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU, 网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。
那么在 YARN 中,我们用 DRF 来决定如何调度:
假设集群一共有 100CPU 和 10T 内存,而应用 A 需要 (2CPU,300GB), 应用 B 需要 (6CPU,100GB)。则两个应用分别需要 A (2% CPU,3% 内存) 和 B (6% CPU,1% 为存) 的资源,这就意味着 A 是内存主导的,B 是 CPU 主导的,针对这种情况,我们可以选择 DRF 策略对不同应用进行不同资源 (CPU 和内存) 的一个不同比例的限制。
# yarn shell1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 root@hadoop100 :~# yarn application -list 2024 -06 -11 06 :34 :10 ,406 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop101/192.168 .13 .191 :8032 Total number of applications (application-types: [], states: [SUBMITTED, ACCEPTED, RUNNING] and tags: []) :1 Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL application_1717055365946_0004 word count MAPREDUCE root default RUNNING UNDEFINED 0 % http: root@hadoop100 :~# yarn application -list 2024 -06 -11 06 :34 :10 ,406 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop101/192.168 .13 .191 :8032 Total number of applications (application-types: [], states: [SUBMITTED, ACCEPTED, RUNNING] and tags: []) :1 Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL application_1717055365946_0004 word count MAPREDUCE root default RUNNING UNDEFINED 0 % http: root@hadoop100 :~# yarn application -kill application_1717055365946_0004 root@hadoop100 :~# yarn logs -applicationId application_1717055365946_0004 root@hadoop100 :~# yarn logs -applicationId application_1717055365946_0004 -containerId # 查看尝试运行的任务 yarn applicationattempt -list application_1717055365946_0004 # yarn applicationattempt -status application_1717055365946_0004 # yarn 容器状态,只有在任务运行中可以查看 yarn container -list yarn container -status yarn node -list -all # 加载队列配置 yarn rmadmin -refreshQueues # 查看队列 yarn queue -status default
# yarn 生产环境参数
# 多队列1) 在生产环境怎么创建队列?
(1) 调度器默认就 1 个 default 队列,不能满足生产要求。
(2) 按照框架:hive/spark/flink 每个框架的任务放入指定的队列 (企业用的不是特别多)
(3) 按照业务模块:登录注册、购物车、下单、业务部门 1、业务部门 2
2) 创建多队列的好处
(1) 因为担心员工不小心,写递归死循环代码,把所有资源全部耗尽。
(2) 实现任务的降级使用,特殊时期保证重要的任务队列资原充足。
业务部门 1 (重要)=》业务部门 2 (比较重要)=》下单 (一般)=》购物车 (一般)=》登录注册 (次要)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 vim capacity-scheduler.xml <property> <name>yarn.scheduler.capacity.root.queues</name> <value>default ,hive</value> <description> The queues at the this level (root is the root queue) . </description> </property> <property> <name>yarn.scheduler.capacity.root.default .capacity</name> <value>40 </value> <description>Default queue target capacity.</description> </property> <property> <name>yarn.scheduler.capacity.root.hive.capacity</name> <value>60 </value> <description>Default queue target capacity.</description> </property> <property> <name>yarn.scheduler.capacity.root.default .user-limit-factor</name> <value>0.7 </value> <description> Default queue user limit a percentage from 0.0 to 1.0 . </description> </property> <property> <name>yarn.scheduler.capacity.root.hive.user-limit-factor</name> <value>1 </value> <description> Default queue user limit a percentage from 0.0 to 1.0 . </description> </property> <property> <name>yarn.scheduler.capacity.root.default .maximum-capacity</name> <value>60 </value> <description> The maximum capacity of the default queue. </description> </property> <property> <name>yarn.scheduler.capacity.root.default .state</name> <value>RUNNING</value> <description> The state of the default queue. State can be one of RUNNING or STOPPED. </description> </property> <property> <name>yarn.scheduler.capacity.root.default .acl_submit_applications</name> <value>*</value> <description> The ACL of who can submit jobs to the default queue. </description> </property> <property> <name>yarn.scheduler.capacity.root.default .acl_administer_queue</name> <value>*</value> <description> The ACL of who can administer jobs on the default queue. </description> </property> <!-- 任务的超时时间设置:yarn application -appId appId -updateLifetimeTimeout 参考资料:https: <!-- 如果application指定了超时时间,则提交到该队列的application能够指定的最大超时时间不能超过该值。 --> <property> <name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime</name> <value>-1 </value> </property> <!-- 如果application没指定超时时间,则用default -application-lifetime作为默认值 --> <property> <name>yarn.scheduler.capacity.root.hive.default -application-lifetime</name> <value>-1 </value> </property> # 提交任务到不同队列 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-example-3.1 .3 .jar wordcount -D mapreduce.job.queuename=hive /input /outputttt # 或者在driver中 Configure conf = new Configure ();conf.set("mapreduce.job.queuename" ,"hive" );
# 任务优先级容量调度器,支持任务优先级的配置,在资源紧张时,优先吸高的任务将优先获取资源。默认情况,Yarn 将所有任务的优先级限制为 0,若想使用任务的优先级功能,须开放该限制。
1 2 3 4 5 6 7 8 <property> <name>yarn.cluster.max-application-priority</name> <value>5 </value> </property> hadoop jar hadoop-mapreduce-examples-3.1 .3 .jar pi -D mapreduce.job.priorit=5 5 20000 # 动态设置优先级 yarn application -appId xxx -upgradePriority 6
# 配置多队列公平调度器1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 vim yarn-site.xml <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> <description>配置使用公平调度器</description> </property> <property> <name>yarn.scheduler.fair.allocation.file</name> <value>/opt/module /hadoop-3.1 .3 /etc/hadoop/fair-scheduler.xml</value> <description>指明公平调度器队列分配配置文件</description> </property> <property> <name>yarn.scheduler.fair.preemption</name> <value>false </value> <description>禁止队列间资源抢占</description> </property> vim fair-scheduler.xml <?xml version="1.0" ?> <allocations> <!-- 单个队列中Application Master占用资源的最大比例,取值0 -1 ,企业一般配置0.1 --> <queueMaxAMShareDefault>0.5 </queueMaxAMShareDefault> <!-- 单个队列最大资源的默认值 test atguigu default --> <queueMaxResourcesDefault>4096mb,4vcores</queueMaxResourcesDefault> <!-- 增加一个队列test --> <queue name="test" > <!-- 队列最小资源 --> <minResources>2048mb,2vcores</minResources> <!-- 队列最大资源 --> <maxResources>4096mb,4vcores</maxResources> <!-- 队列中最多同时运行的应用数,默认50 ,根据线程数配置 --> <maxRunningApps>4 </maxRunningApps> <!-- 队列中Application Master占用资源的最大比例 --> <!-- <maxAMShare>0.5 </maxAMShare>--> <!-- 该队列资源权重,默认值为1.0 --> <weight>1.0 </weight> <!-- 队列内部的资源分配策略 --> <schedulingPolicy>fair</schedulingPolicy> </queue> <!-- 增加一个队列atguigu --> <queue name="atguigu" type="parent" > <!-- 队列最小资源 --> <minResources>2048mb,2vcores</minResources> <!-- 队列最大资源 --> <maxResources>4096mb,4vcores</maxResources> <!-- 队列中最多同时运行的应用数,默认50 ,根据线程数配置 --> <maxRunningApps>4 </maxRunningApps> <!-- 队列中Application Master占用资源的最大比例 --> <!-- <maxAMShare>0.5 </maxAMShare>--> <!-- 该队列资源权重,默认值为1.0 --> <weight>1.0 </weight> <!-- 队列内部的资源分配策略 --> <schedulingPolicy>fair</schedulingPolicy> </queue> <!-- 任务队列分配策略,可配置多层规则,从第一个规则开始匹配,直到匹配成功 --> <queuePlacementPolicy> <!-- 提交任务时指定队列,如未指定提交队列,则继续匹配下一个规则; false 表示:如果指定队列不存在,不允许自动创建--> <rule name="specified" create="false" /> <!-- 提交到root.group.username队列,若root.group不存在,不允许自动创建;若root.group.user不存在,允许自动创建 --> <rule name="nestedUserQueue" create="true" > <rule name="primaryGroup" create="false" /> </rule> <!-- 最后一个规则必须为reject或者default 。Reject表示拒绝创建提交失败,default 表示把任务提交到default 队列 --> <rule name="reject" /> </queuePlacementPolicy> </allocations> # 指定用户和不指定用户 hadoop jar hadoop-mapreduce-examples-3.1 .3 .jar pi -D mapreduce.job.queuename=root.test 1 1 hadoop jar hadoop-mapreduce-examples-3.1 .3 .jar pi 1 1
期望可以动态传参,结果报错,误认为是第一个输入参数。
[@hadoop102 hadoop-3.1.3]$ hadoop jar wc.jar com.atguigu.mapreduce.wordcount2.WordCountDriver -Dmapreduce.job.queuename=root.test /input /output1
1)需求:自己写的程序也可以动态修改参数。编写 Yarn 的 Tool 接口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 创建类WordCount并实现Tool接口: package com.atguigu.yarn; import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.Tool; import java.io.IOException; public class WordCount implements Tool { private Configuration conf; @Override public int run (String[] args) throws Exception { Job job = Job.getInstance(conf); job.setJarByClass(WordCountDriver.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path (args[0 ])); FileOutputFormat.setOutputPath(job, new Path (args[1 ])); return job.waitForCompletion(true ) ? 0 : 1 ; } @Override public void setConf (Configuration conf) { this .conf = conf; } @Override public Configuration getConf () { return conf; } public static class WordCountMapper extends Mapper <LongWritable, Text, Text, IntWritable> { private Text outK = new Text (); private IntWritable outV = new IntWritable (1 ); @Override protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] words = line.split(" " ); for (String word : words) { outK.set(word); context.write(outK, outV); } } } public static class WordCountReducer extends Reducer <Text, IntWritable, Text, IntWritable> { private IntWritable outV = new IntWritable (); @Override protected void reduce (Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0 ; for (IntWritable value : values) { sum += value.get(); } outV.set(sum); context.write(key, outV); } } }