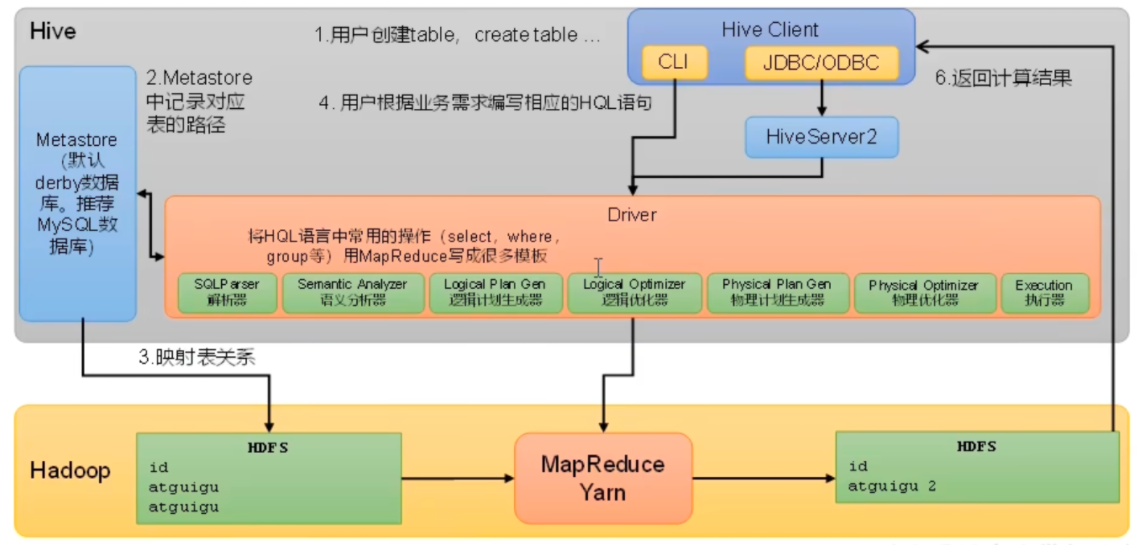
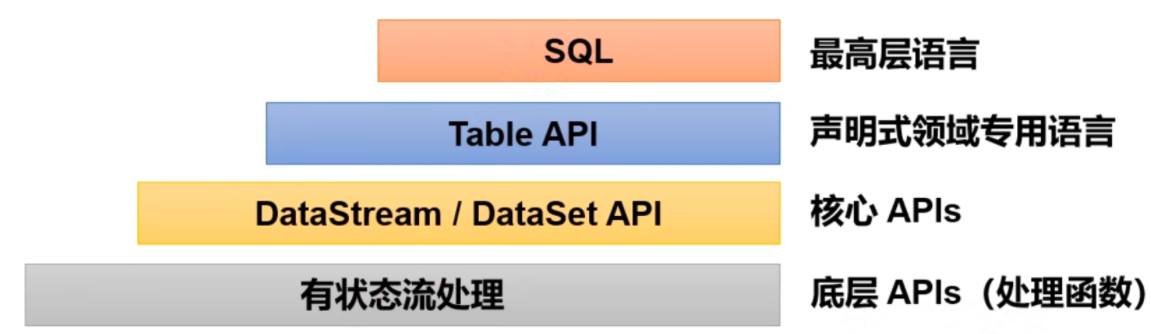
# hiveHive 是由 Facebook 开源,基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。
Hive 是一个 Hadoop 客户端,用于将 HQL (HiveSQL) 转化成 MapfReduce 程序。
(1) Hive 中每张表的数据存储在 HDFS
(2) Hive 分析数据底层的实现是 MapReduce (也可配置为 Sparl 或者 Tez)
(3) 执行程序运行在 Yarn 上
# 最小化安装1 2 3 4 5 6 7 8 9 10 11 12 wget http: tar xzvf apache-hive-3.1 .3 -bin.tar.gz cd apache-hive-3.1 .3 -bin/ #!/bin/bash export HIVE_HOME=/root/apache-hive-3.1 .3 -bin export PATH=$PATH:$HIVE_HOME/bin ./schematool -dbType derby -initSchema hive > show databases;
路径同一时刻,只能允许一个 derby 客户端使用
http://apache.mirror.iweb.ca/hive/hive-3.1.3/
# mysql-hive1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 # 卸载mariadb # 安装mysql apt install mysql-server systemctl enable mysql --now sudo mysql_secure_installation ALTER USER 'root' @'localhost' IDENTIFIED BY '123456' ; # hive存储元数据到mysql create database metastore; # 修改配置文件 hive-site.xml <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql: <description> JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql: </description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>Username to use against metastore database</description> </property> <property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456 </value> <description>password to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> <description>location of default database for the warehouse</description> </property> <property> SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/apache-hive-3.1 .3 -bin/lib/log4j-slf4j-impl-2.17 .1 .jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/hadoop-3.3 .6 /share/hadoop/common/lib/slf4j-reload4j-1.7 .36 .jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http: SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Metastore connection URL: jdbc:mysql: Metastore Connection Driver : com.mysql.cj.jdbc.Driver Metastore connection User: root org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version. Underlying cause: com.mysql.cj.jdbc.exceptions.CommunicationsException : Communications link failure The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server. SQL Error code: 0 org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version. at org.apache.hadoop.hive.metastore.tools.HiveSchemaHelper.getConnectionToMetastore(HiveSchemaHelper.java:94 ) at org.apache.hive.beeline.HiveSchemaTool.getConnectionToMetastore(HiveSchemaTool.java:169 ) at org.apache.hive.beeline.HiveSchemaTool.testConnectionToMetastore(HiveSchemaTool.java:475 ) at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:581 ) at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:567 ) at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1517 ) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62 ) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43 ) at java.lang.reflect.Method.invoke(Method.java:498 ) at org.apache.hadoop.util.RunJar.run(RunJar.java:328 ) at org.apache.hadoop.util.RunJar.main(RunJar.java:241 ) Caused by: com.mysql.cj.jdbc.exceptions.CommunicationsException: Communications link failure The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server. at com.mysql.cj.jdbc.exceptions.SQLError.createCommunicationsException(SQLError.java:175 ) at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:64 ) at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:825 ) at com.mysql.cj.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:446 ) at com.mysql.cj.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:239 ) at com.mysql.cj.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:188 ) at java.sql.DriverManager.getConnection(DriverManager.java:664 ) at java.sql.DriverManager.getConnection(DriverManager.java:247 ) at org.apache.hadoop.hive.metastore.tools.HiveSchemaHelper.getConnectionToMetastore(HiveSchemaHelper.java:88 ) ... 11 more Caused by: com.mysql.cj.exceptions.CJCommunicationsException: Communications link failure The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server. at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62 ) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45 ) at java.lang.reflect.Constructor.newInstance(Constructor.java:423 ) at com.mysql.cj.exceptions.ExceptionFactory.createException(ExceptionFactory.java:62 ) at com.mysql.cj.exceptions.ExceptionFactory.createException(ExceptionFactory.java:105 ) at com.mysql.cj.exceptions.ExceptionFactory.createException(ExceptionFactory.java:150 ) at com.mysql.cj.exceptions.ExceptionFactory.createCommunicationsException(ExceptionFactory.java:166 ) at com.mysql.cj.protocol.a.NativeSocketConnection.connect(NativeSocketConnection.java:89 ) at com.mysql.cj.NativeSession.connect(NativeSession.java:121 ) at com.mysql.cj.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:945 ) at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:815 ) ... 17 more Caused by: java.net.ConnectException: Connection refused (Connection refused) at java.net.PlainSocketImpl.socketConnect(Native Method) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350 ) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206 ) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188 ) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392 ) at java.net.Socket.connect(Socket.java:607 ) at com.mysql.cj.protocol.StandardSocketFactory.connect(StandardSocketFactory.java:153 ) at com.mysql.cj.protocol.a.NativeSocketConnection.connect(NativeSocketConnection.java:63 ) ... 20 more *** schemaTool failed *** 如果报错,注意,当前用户不是localhost mysql> use mysql; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> select host,user from user where user='root' ; +-----------+------+ | host | user | +-----------+------+ | localhost | root | +-----------+------+ 配置文件中不是127.0 .0 .1 通常情况下,这个配置文件位于/etc/mysql/mysql.conf.d/mysqld.cnf,找到bind-address这一项并将其更改为0.0 .0 .0 。然后重启mysql服务:sudo systemctl restart mysql。 配置文件中账号密码正确 已经下载mysql连接java驱动,并且复制到hive/lib下面 https: Relative path in absolute URI: ${system:java.io.tmpdir%7D /$%7Bsystem:user.name%7D https: 把上面文章中所有 $HIVE_HOME/iotmp 改为绝对路径,比如 /root/apache-hive-3.1 .3 -bin/iotmp 验证: hive show databases;
# hiveserver2Hive 的 hiveserver2 服务的作用是提供 jdbc/odbc 接口,为用户提供远程访问 Hive 数据的功能,例如用户期望在个人电脑中访问远程服务中的 Hive 数据,就需要用到 Hiveserver2
# 用户模拟功能在远程访问 Hive 数据时,客户端并未直接访问 Hadoop 集群,而是由 Hivesever2 代理访问。由于 Hadoop 集群中的数据具备访问权限控制,所以此时需考虑一个问题:那就是访问 Hadoop 集群的用户身份是谁?是 Hiveserver2 的启动用户?还是客户端的登录用户?
答案是都有可能,具体是谁,由 Hiveserver2 的 hive.server2.enable.doAs 参数决定,该参数的含义是是否启用 Hiveserver2 用户模拟的功能。若启用,则 Hiveserver2 会模拟成客户端的登录用户去访问 Hadoop 集群的数据,不启用,则 Hivesever2 会直接使用启动用户访问 Hadoop 集群数据。模拟用户的功能,默认是开启的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 vim core-site.yaml <!--配置所有节点的atguigu用户都可作为代理用户--> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <!--配置atguigu用户能够代理的用户组为任意组--> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <!--配置atguigu用户能够代理的用户为任意用户--> <property> <name>hadoop.proxyuser.root.users</name> <value>*</value> </property> scp core-site.xml root@192.168 .13 .191 :/root/hadoop-3.3 .6 /etc/hadoop scp core-site.xml root@192.168 .13 .192 :/root/hadoop-3.3 .6 /etc/hadoop hadoop-start.sh vim hive-site.yaml <!-- 指定hiveserver2连接的host --> <property> <name>hive.server2.thrift.bind.host</name> <value>hadoop100</value> </property> <!-- 指定hiveserver2连接的端口号 --> <property> <name>hive.server2.thrift.port</name> <value>10000 </value> </property> bin/hiveserver2 root@hadoop100 :~/apache-hive-3.1 .3 -bin# nohup hiveserver2 >/dev/null 2 >&1 & [1 ] 124804 root@hadoop100 :~/apache-hive-3.1 .3 -bin# jps 123633 NameNode124131 NodeManager124804 RunJar
测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 root@hadoop100 :~/apache-hive-3.1 .3 -bin# beeline SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/apache-hive-3.1 .3 -bin/lib/log4j-slf4j-impl-2.17 .1 .jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/hadoop-3.3 .6 /share/hadoop/common/lib/slf4j-reload4j-1.7 .36 .jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http: SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Beeline version 3.1 .3 by Apache Hive beeline> !connect jdbc:hive2: Connecting to jdbc:hive2: Enter username for jdbc:hive2: Enter password for jdbc:hive2: Connected to: Apache Hive (version 3.1 .3 ) Driver: Hive JDBC (version 3.1 .3 ) Transaction isolation: TRANSACTION_REPEATABLE_READ 0 : jdbc:hive2:
使用 datagrip 连接
Hive 的 metastore 服务的作用是为 Hive CLI 或者 Hiveserver2 提供元数据访问接口。
metastore 运行模式
metastore 有两种运行模式,分别为嵌入式模式和独立服务模式。
生产环境中,不推荐使用嵌入式模式。因为其存在以下两个问题:
(1)嵌入式模式下,每个 Hive CLI 都需要直接连接元数据库,当 Hive CLI 较多时,数据库压力会比较大。
(2)每个客户端都需要用户元数据库的读写权限,元数据库的安全得不到很好的保证。
# 独立模式部署1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Hadoop100 nohup hive --service metastore & Hadoop101 <property> <name>hive.metastore.uris</name> <value>thrift: <description/> </property> 需要删除jdbc相关参数 hive -e "insert into stu values(2,'aaa')" hive -f stu.sql hive -hiveconf mapreduce.job.x=10 ; hive> set mapreduce.x.x=10 hive> set mapreduce.x.x
配置文件 < 命令行参数 < 参数声明。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 <property> <name>hive.cli.print.header</name> <value>true </value> <description>Whether to print the names of the columns in query output.</description> </property> <property> <name>hive.cli.print.current.db</name> <value>true </value> <description>Whether to include the current database in the Hive prompt.</description> </property> 修改日志路径 vim hive-log4j2.properties # list of properties property.hive.log.level = INFO property.hive.root.logger = DRFA property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name} property.hive.log.file = hive.log property.hive.perflogger.log.level = INFO # 调整堆内存 vim hive-env.sh export HADOOP_HEAPSIZE=2048 在yarn-site.xml中关闭虚拟内存检查(虚拟内存校验 yarn-nodemanager.vmem-check-enabled false
# DDL# 库操作1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ### databases (1 )创建一个数据库,不指定路径 hive (default )> create database db_hive1; 注:若不指定路径,其默认路径为${hive.metastore.warehouse.dir}/database_name.db (2 )创建一个数据库,指定路径 hive (default )> create database db_hive2 location '/db_hive2' ; (2 )创建一个数据库,带有dbproperties hive (default ) > create database db_hive3 with dbproperties ('create_date' ='2022-11-18' ) ;show databases like 'db_hive*' ; desc database db_hive3; desc database extended db_hive3; 修改数据库location,不会改变当前已有表的路径信息,而只是改变后续创建的新表的默认的父目录。 ALTER DATABASE db_hive3 SET DBPROPERTIES ('create_date' ='2022-11-20' ) ; DROP DATABASE [IF EXISTS] database_name [RESTRICT|CASCADE]; 注:RESTRICT:严格模式,若数据库不为空,则会删除失败,默认为该模式。 CASCADE:级联模式,若数据库不为空,则会将库中的表一并删除。 use db1; ### tables
# 建表1TEMPORARY
临时表,该表只在当前会话可见,会话结束,表会被删除。
2EXTERNAL(重点)
外部表,与之相对应的是内部表(管理表)。管理表意味着 Hive 会完全接管该表,包括元数据和 HDFS 中的数据。而外部表则意味着 Hive 只接管元数据,而不完全接管 HDFS 中的数据。
3data_type(重点)
Hive 中的字段类型可分为基本数据类型和复杂数据类型。
基本数据类型如下:
Hive
说明
定义
tinyint
1byte 有符号整数
smallint
2byte 有符号整数
int
4byte 有符号整数
bigint
8byte 有符号整数
boolean
布尔类型,true 或者 false
float
单精度浮点数
double
双精度浮点数
decimal
十进制精准数字类型
decimal(16,2)
varchar
字符序列,需指定最大长度,最大长度的范围是 [1,65535]
varchar(32)
string
字符串,无需指定最大长度
timestamp
时间类型
binary
二进制数据
方式一:隐式转换
具体规则如下:
a. 任何整数类型都可以隐式地转换为一个范围更广的类型,如 tinyint 可以转换成 int,int 可以转换成 bigint。
b. 所有整数类型、float 和 string 类型都可以隐式地转换成 double。
c. tinyint、smallint、int 都可以转换为 float。
d. boolean 类型不可以转换为任何其它的类型。
方式二:显示转换
可以借助 cast 函数完成显示的类型转换
a. 语法
cast(expr as )
b. 案例
hive (default)> select ‘1’ + 2, cast(‘1’ as int) + 2;
数据仓库 (英语:Data Warehouse, 简称数仓、DW), 是一个月用于存储、分析、报告的数据系统。
数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持 (Decision Support)。
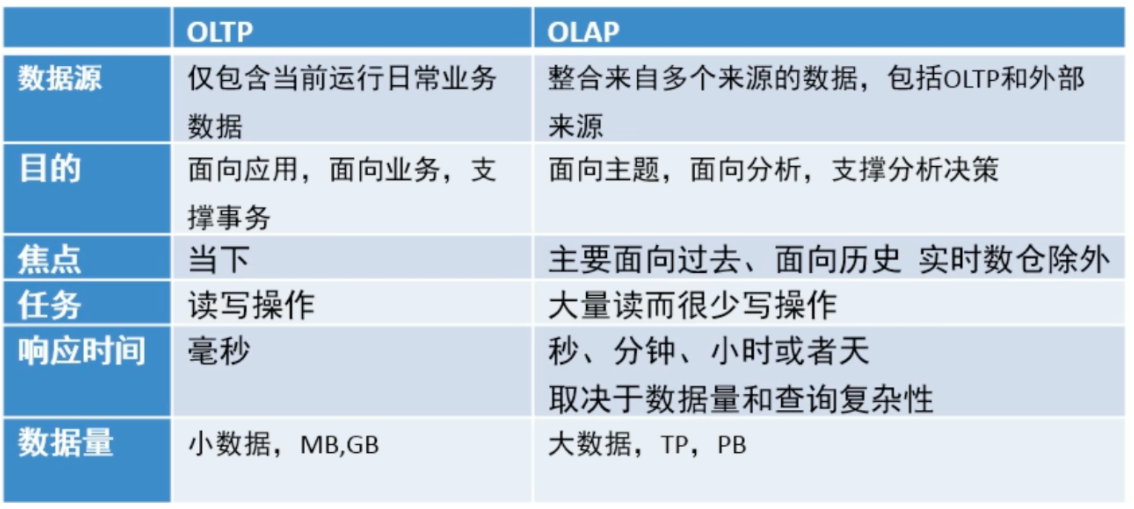
关系型数据库 (RDBMS) 是 OLTP 典型应用,比如:Oracle、MySQL、SQL Server 等。
面向分析、支持分析的系统称之为 OLAP (联机分析处理) 系统。数据仓库是 OLAP 一种。
联机事务处理 OLTP (On-Line Transaction Processing)。
传统 RDBMS,mysql,oracle,sqlserver
联机分析处理 OLAP (On-LineAnalytical Processing)。
数据仓库,主要用于开展数据分析
数据库与数据仓库的区别实际讲的是 OLTP 与 OLAP 的区别。
OLTP 系统的典型应用就是 RDBMS, 也就是我们俗称的数据库,当然这里要特别强调此数据库表示的是关系型数据库,
Nosql 数据库并不在讨论范围内。
OLAP 系统的典型应用就是 DW, 也就是我们俗称的数据仓库。
数据仓库,数据集市
数据仓库 (Data Warehouse) 是面向整个集团组织的数据,数据集市 (Data Mart) 是面向单个部门使用的。
可以认为数据集市是数据仓库的子集,也有人把数据集市叫做小型数据仓库。数据集市通常只涉及一个主题领域,例如市场营销或销售。因为它们较小且更具体,所以它们通常更易于管理和维护,并具有更灵活的结构。
下图中,各种操作型系统数据和包括文件在内的等其他数据作为数据源,经过 ETL (抽取转换加载) 填充到数据仓库中;数据仓库中有不同主题数据,数据集市则根据部门特点面向指定主题,比如 Purchasing (采购)、Sales 售)、Inventory (库存);
用户可以基于主题数据开展各种应用:数据分析、数据报表、数据挖掘。
数据仓库分层思想
ETL ELT
# flinkApache Flink 是一个框架和分布式处理引擎,用于对无异和有界数据流进行有状态计算。
1) 无界数据流:
有定义流的开始,但没有定义流的结束;
它们会无休止的产生数据;
无界流的数据必须持续处理,即数据被摄取后需要立刻处上理。
我们不能等到所有数据都到达再处理,因为输入是无限的。
2) 有界数据流:
有定义流的开始,也有定义流的结束;
有界流可以在摄取所有数据后再进行计算;
有界流所有数据可以被排序,所以并不需要有序摄取;
有界流处理通常被称为批处理。
把流处理需要的额外数据保存成一个 "状态", 然户后针对这条数据进行处理,并且更新状态。这就是所谓的 "有状态的流处理"。
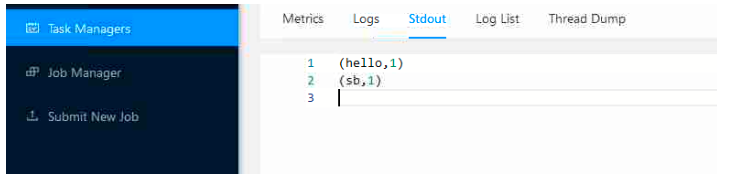
# wordcount1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 <properties> <flink.version>1.17 .0 </flink.version> </properties> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients</artifactId> <version>${flink.version}</version> </dependency> </dependencies> import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.java.ExecutionEnvironment;import org.apache.flink.api.java.operators.AggregateOperator;import org.apache.flink.api.java.operators.DataSource;import org.apache.flink.api.java.operators.FlatMapOperator;import org.apache.flink.api.java.operators.UnsortedGrouping;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.util.Collector;public class count { public static void main (String[] args) throws Exception { ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); DataSource<String> stringDataSource = env.readTextFile("data/input" ); FlatMapOperator<String, Tuple2<String, Integer>> stringTuple2FlatMapOperator = stringDataSource.flatMap(new FlatMapFunction <String, Tuple2<String, Integer>>() { @Override public void flatMap (String s, Collector<Tuple2<String, Integer>> collector) throws Exception { String[] s1 = s.split(" " ); for (String ss : s1) { Tuple2<String, Integer> stringIntegerTuple2 = Tuple2.of(ss, 1 ); collector.collect(stringIntegerTuple2); } } }); UnsortedGrouping<Tuple2<String, Integer>> tuple2UnsortedGrouping = stringTuple2FlatMapOperator.groupBy(0 ); AggregateOperator<Tuple2<String, Integer>> sum = tuple2UnsortedGrouping.sum(1 ); sum.print(); } } import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.java.functions.KeySelector;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.datastream.KeyedStream;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;public class count2 { public static void main (String[] args) throws Exception { StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> stringDataStreamSource = executionEnvironment.readTextFile("data/input" ); SingleOutputStreamOperator<Tuple2<String, Integer>> tuple2SingleOutputStreamOperator = stringDataStreamSource.flatMap(new FlatMapFunction <String, Tuple2<String, Integer>>() { @Override public void flatMap (String s, Collector<Tuple2<String, Integer>> collector) throws Exception { String[] s1 = s.split(" " ); for (String string : s1) { Tuple2<String, Integer> stringIntegerTuple2 = Tuple2.of(string, 1 ); collector.collect(stringIntegerTuple2); } } }); KeyedStream<Tuple2<String, Integer>, String> tuple2StringKeyedStream = tuple2SingleOutputStreamOperator.keyBy(new KeySelector <Tuple2<String, Integer>, String>() { @Override public String getKey (Tuple2<String, Integer> stringIntegerTuple2) throws Exception { return stringIntegerTuple2.f0; } }); SingleOutputStreamOperator<Tuple2<String, Integer>> sum = tuple2StringKeyedStream.sum(1 ); sum.print(); executionEnvironment.execute(); } }
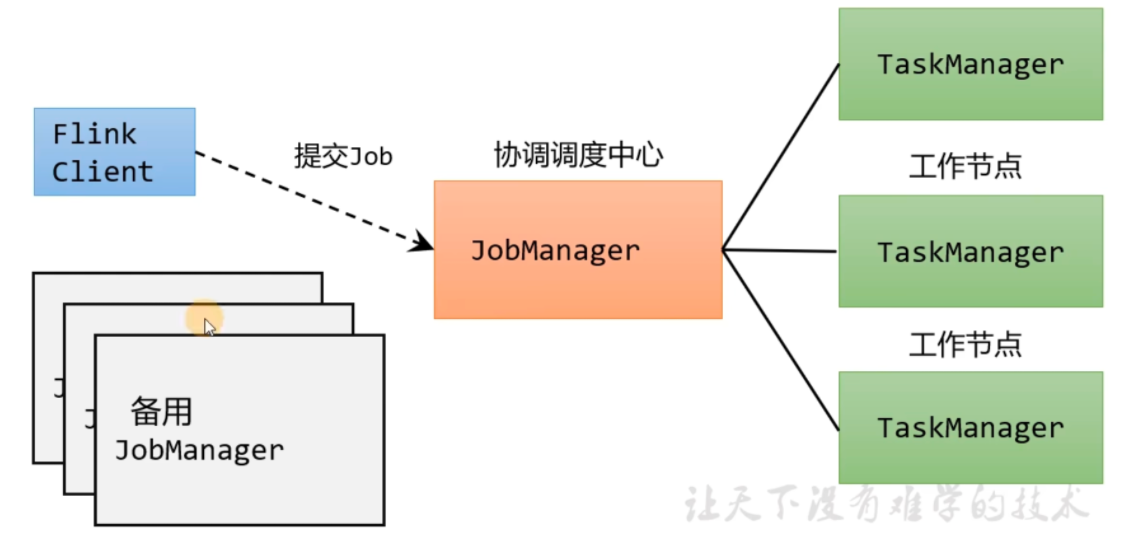
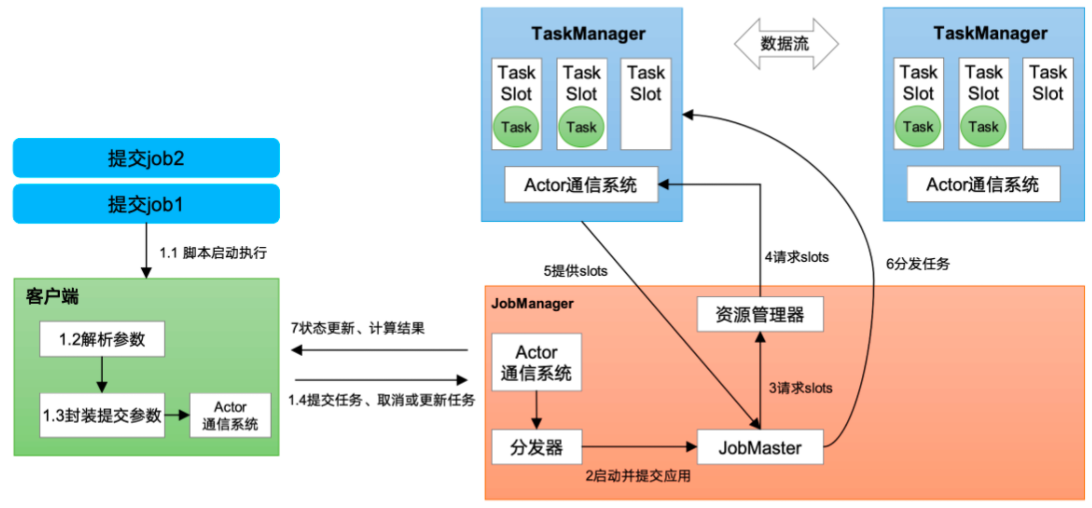
# flink 部署1 2 3 客户端(Client):代码由客户端获取并做转换,之后提交给JolManger JobManager就是Flink集群里的"管事人" ,对作业进行中央调度管理;而它获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的TaskManager。 TaskManager,就是真正"干活的人" ,数据的处理操作都是它它们来做的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 wget "https://dlcdn.apache.org/flink/flink-1.17.2/flink-1.17.2-bin-scala_2.12.tgz" tar xzvf flink-1.17 .2 -bin-scala_2.12 .tgz vim flink-conf.yaml jobmanager.rpc.address: hadoop100 jobmanager.rpc.port: 6123 jobmanager.bind-host: 0.0 .0 .0 rest.address: hadoop100 rest.bind-address: 0.0 .0 .0 taskmanager.bind-host: 0.0 .0 .0 taskmanager.host: hadoop100 vim worker hadoop100 hadoop101 hadoop102 vim master hadoop100:8081 分发到其他节点,修改flink-conf taskmanager.host: hadoop10x # 启动 start-cluster.sh root@hadoop100 :~# jps 140450 StandaloneSessionClusterEntrypoint140861 TaskManagerRunnerhttp:
# web 提交任务1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 import org.apache.flink.api.common.typeinfo.Types;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;import java.util.Arrays;public class SocketStreamWordCount { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> lineStream = env.socketTextStream("hadoop100" , 7777 ); SingleOutputStreamOperator<Tuple2<String, Long>> sum = lineStream.flatMap((String line, Collector<Tuple2<String, Long>> out) -> { String[] words = line.split(" " ); for (String word : words) { out.collect(Tuple2.of(word, 1L )); } }).returns(Types.TUPLE(Types.STRING, Types.LONG)) .keyBy(data -> data.f0) .sum(1 ); sum.print(); env.execute(); } } # 增加依赖 <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.2 .4 </version> <executions> <execution> <phase>package </phase> <goals> <goal>shade</goal> </goals> <configuration> <artifactSet> <excludes> <exclude>com.google.code.findbugs:jsr305</exclude> <exclude>org.slf4j:*</exclude> <exclude>log4j:*</exclude> </excludes> </artifactSet> <filters> <filter> <!-- Do not copy the signatures in the META-INF folder. Otherwise, this might cause SecurityExceptions when using the JAR. --> <artifact>*:*</artifact> <excludes> <exclude>META-INF 可以在前面的依赖中添加 <scope>provided</scope> 来不打包依赖 添加后需要在edit configuration中include provided,否则idea中无法编译
创建任务,submit
nc -lvvp 7777 发送数据查看效果
命令行提交作业
1 flink run -m hadoop100:8081 -c wordcount.SocketStreamWordCount ./xxx.jar
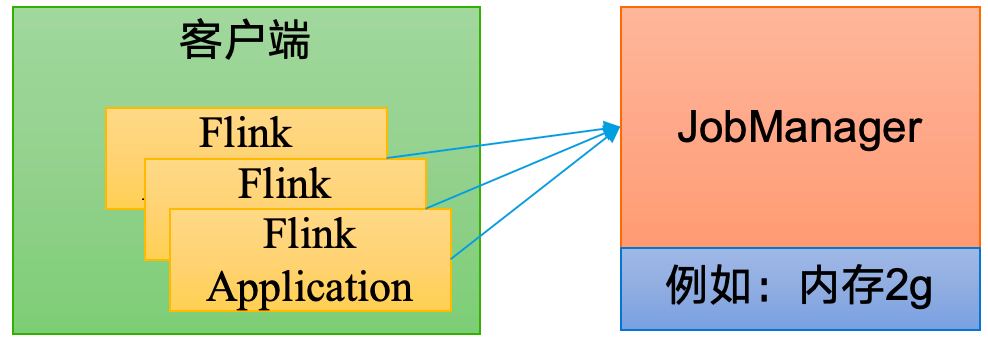
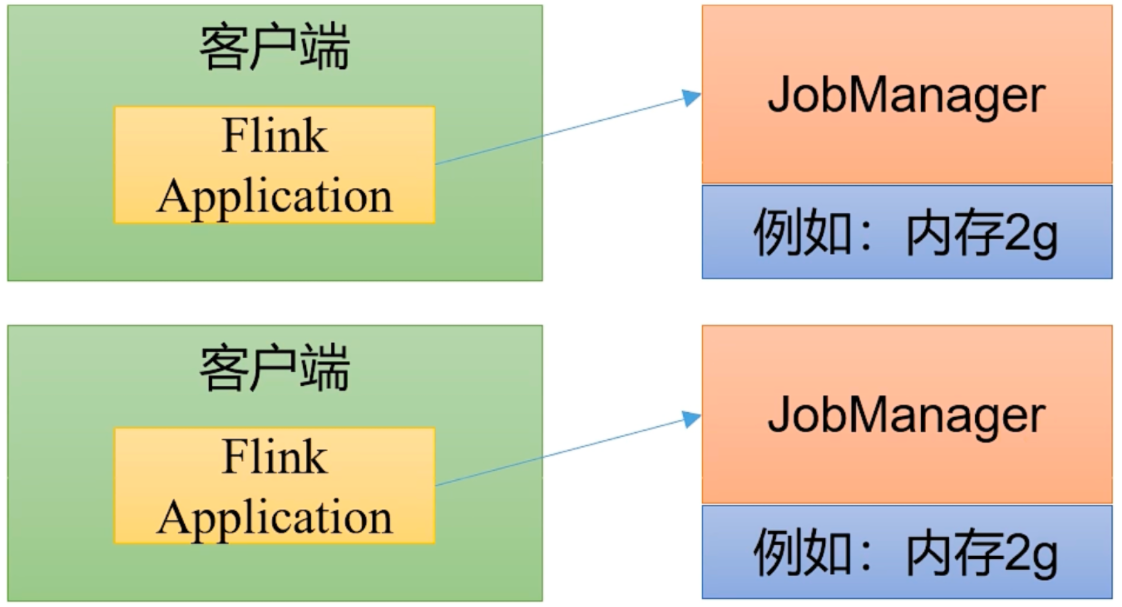
# 部署模式Flink 为各种场景提供了不同的部署模式,主要有以下三种:会话模式(Session Mode)、单作业模式(Per-Job Mode)、应用模式(Application Mode)。
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的 main 方法到底在哪里执行 —— 客户端(Client)还是 JobManager。
# 会话模式会话模式其实最符合常规思维。我们需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。
# 单作业模式会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,我们可以考虑为每个提交的作业启动一个集群,这就是所谓的单作业 (Per-Job) 模式。
需要注意的是,Flink 本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如 YARN、Kubernetes (K8S)。
# 应用模式直接把应用提交到 JobManger 上运行。而这也就代表着,我们需要为每一个提交的应用单独启动一个 JobManager, 也就是创建一个集群。这个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了,这就是所谓的应用模式。
应用模式与单作业模式,都是提交作业之后才创建集群;单单作业模式是通过客户端来提交的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由 JobManager 执行应用程序的。
# standlone 模式独立模式是独立运行的,不依赖任何外部的资源管理平台;当然独立也是有代价的:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式一般只用在开发测试或作业非常少的场景下。
会话模式部署
提前启动集群,并通过 Web 页面客户端提交任务(可以多个任务,但是集群资源固定)。
standlone 不支持单作业部署
应用模式部署
启动 jobmanager
bin/standalone-job.sh start --job-classname com.atguigu.wc.SocketStreamWordCount
启动 TaskManager, 需要在每个 taskmanager 上启动
taskmanager.sh start
停止
taskmanager.sh stop
standalone-job.sh stop
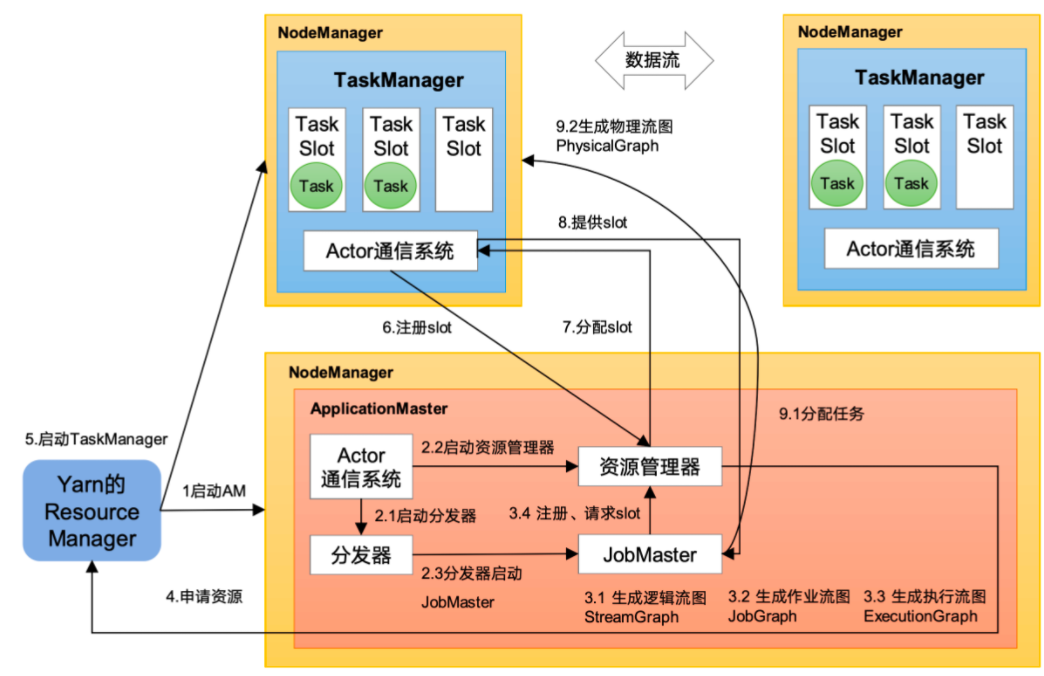
# yarn 模式客户端把 Flink 应用提交给 Yarn 的 ResourceManager,Yarn 的 ResourceManager 会向 Yarn 的 NodeManager 申请容器。在这些容器上,Flink 会部署 JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在 JobManger 上的作业所需要的 Slot 数量动态分配 TaskManager 资源。
1 2 3 4 5 6 7 vim /etc/profile # hadoop export HADOOP_HOME=/root/hadoop-3.3 .6 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_CLASSPATH=`hadoop classpath`
# yarn - 会话模式1 2 3 4 5 6 yarn-session.sh -d -nm name111 # 提交任务 flink run -c com.wordcount lib/1. jar
# yarn - 单作业模式1 2 3 4 5 6 7 8 9 10 11 12 flink run -d -t yarn-per-job -c com.wordcount lib/1. jar bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId> 消除classloader告警 vim flink-conf.yaml classloader.check-leaked-classloader: false
# yarn - 应用模式部署1 2 3 4 5 6 7 8 9 10 11 12 flink run-application -t yarn-application -c com.atguigu.wc.SocketStreamWordCount FlinkTutorial-1.0 -SNAPSHOT.jar 上传HDFS提交 可以通过yarn.provided.lib.dirs配置选项指定位置,将flink的依赖上传到远程。 (1 )上传flink的lib和plugins到HDFS上 [atguigu@hadoop102 flink-1.17 .0 ]$ hadoop fs -mkdir /flink-dist [atguigu@hadoop102 flink-1.17 .0 ]$ hadoop fs -put lib/ /flink-dist [atguigu@hadoop102 flink-1.17 .0 ]$ hadoop fs -put plugins/ /flink-dist (2 )上传自己的jar包到HDFS [atguigu@hadoop102 flink-1.17 .0 ]$ hadoop fs -mkdir /flink-jars [atguigu@hadoop102 flink-1.17 .0 ]$ hadoop fs -put FlinkTutorial-1.0 -SNAPSHOT.jar /flink-jars (3 )提交作业 [atguigu@hadoop102 flink-1.17 .0 ]$ bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://hadoop102:8020/flink-dist" -c com.atguigu.wc.SocketStreamWordCount hdfs:
配置历史服务器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 jobmanager.archive.fs.dir: hdfs: # The address under which the web-based HistoryServer listens. historyserver.web.address: hadoop100 # The port under which the web-based HistoryServer listens. historyserver.web.port: 8082 # Comma separated list of directories to monitor for completed jobs. historyserver.archive.fs.dir: hdfs: # Interval in milliseconds for refreshing the monitored directories. historyserver.archive.fs.refresh-interval: 10000 historyserver.sh start
# 系统架构
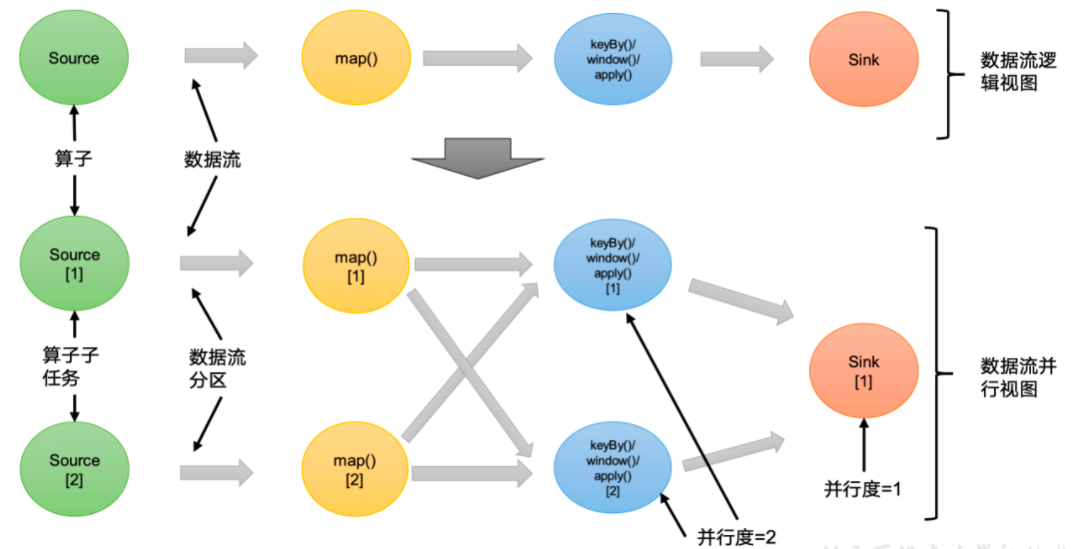
# 并行度一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-runtime-web</artifactId> <version>1.17 .0 </version> </dependency> public class SocketStreamWordCount { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration ()); DataStreamSource<String> lineStream = env.socketTextStream("hadoop100" , 7777 ); elineStream.flatMap((String line, Collector<Tuple2<String, Long>> out) -> { String[] words = line.split(" " ); for (String word : words) { out.collect(Tuple2.of(word, 1L )); } }).setParallelism(2 ) .returns(Types.TUPLE(Types.STRING, Types.LONG)) .keyBy(data -> data.f0) .sum(1 ); sum.print(); env.execute(); } } env.setParallelism(3 ); 算子优先级更高 > env > -p > flink-conf 提交作业时指定 命令行启动 参数 -p 2 配置文件 flink-conf.yaml parallelism.default : 1
# 算子链(1)一对一(One-to-one,forwarding)
这种模式下,数据流维护着分区以及元素的顺序。比如图中的 source 和 map 算子,source 算子读取数据之后,可以直接发送给 map 算子做处理,它们之间不需要重新分区,也不需要调整数据的顺序。这就意味着 map 算子的子任务,看到的元素个数和顺序跟 source 算子的子任务产生的完全一样,保证着 “一对一” 的关系。map、filter、flatMap 等算子都是这种 one-to-one 的对应关系。这种关系类似于 Spark 中的窄依赖。
(2)重分区(Redistributing)
在这种模式下,数据流的分区会发生改变。比如图中的 map 和后面的 keyBy/window 算子之间,以及 keyBy/window 算子和 Sink 算子之间,都是这样的关系。
每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。这些传输方式都会引起重分区的过程,这一过程类似于 Spark 中的 shuffle。
在 Flink 中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个 “大” 的任务(task)
将算子链接成 task 是非常有效的优化:可以减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
1 2 3 4 5 6 7 8 9 10 11 # 全局禁用算子链 env.disableOperatorChaining(); # 对某个算子禁用算子链 .sum(1 ).disableChaining(); 禁用算子链之后,只有这个算子相邻算子不能和自己链 # 从某个算子开启新链条 .sum(1 ).startNewChain(); 算子不与前面链,从当前开始正常链
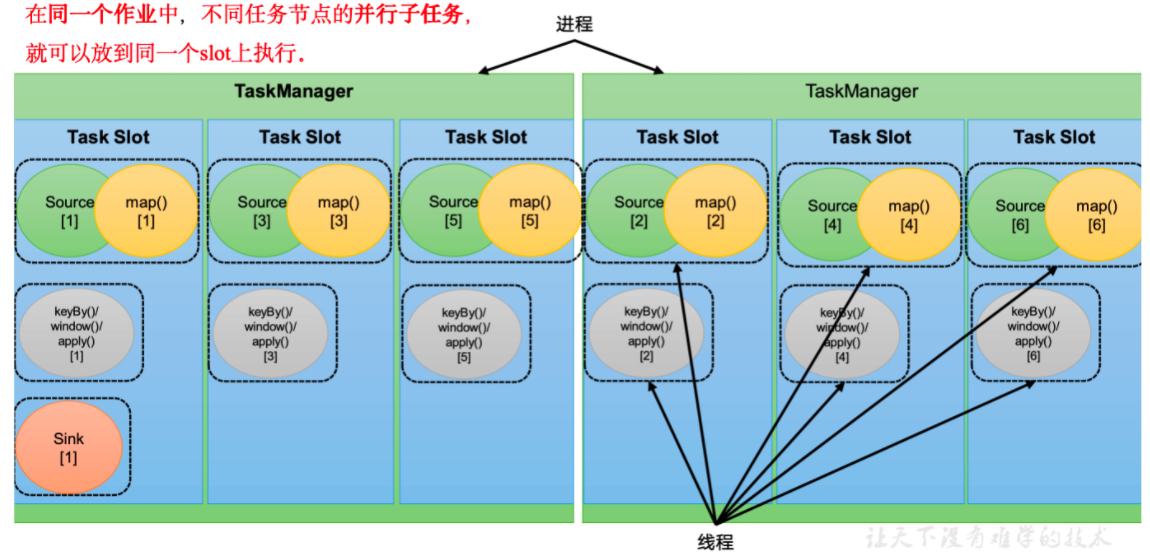
# 任务槽每个任务槽(task slot)其实表示了 TaskManager 拥有计算资源的一个固定大小的子集。这些资源就是用来独立执行一个子任务的。
1 2 # 每个tm slot数,默认是1 taskmanager.numberOfTaskSlots: 1
slot 目前仅仅用来隔离内存,不会涉及 CPU 的隔离。在具体应用时,可以将 slot 数量配置为机器的 CPU 核心数,尽量避免不同任务之间对 CPU 的竞争。这也是开发环境默认并行度设为机器 CPU 数量的原因。
同一个 job 中,不同算子的子任务,才可以共享一个 slot,slot 内是同时在运行的
属于同一个 slot 共享组,默认是 default
1 .sum(1 ).slotSharingGroup("aaa" );
slot 数量 与 并行度 的关系
1) slot 是一种静态的概念,表示最大的并发上限
并行度是一种动态的概念,表示实际运行 占用了几个
2) 要求:slot 数量 >=job 并行度 (算子最大并行度),job 才能运行
yarn 模式是动态申请
申请的 TM 数量 = job 并行度 / 每个 TM 的 slot 数,向上取整
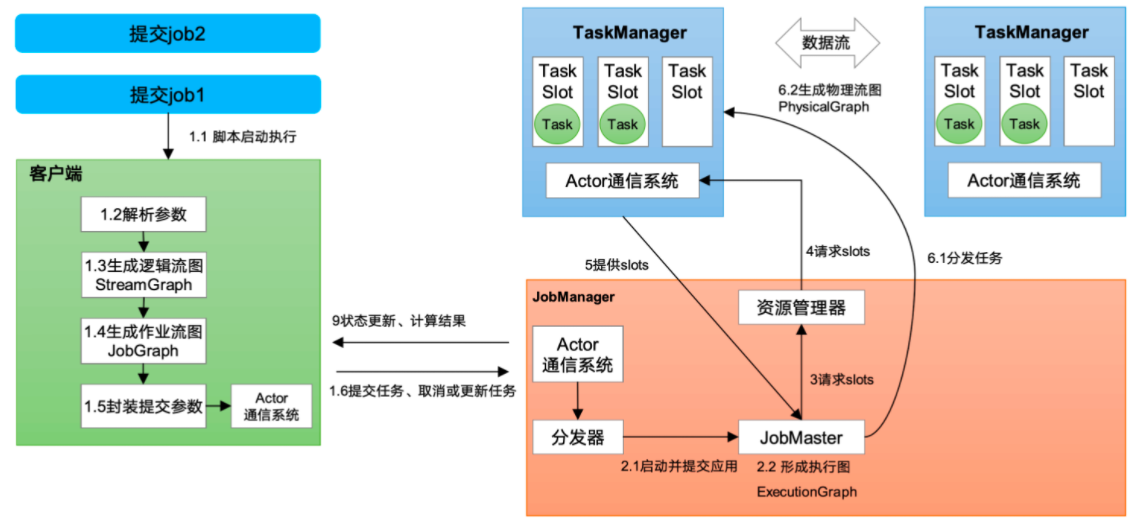
# 作业提交流程# standalone
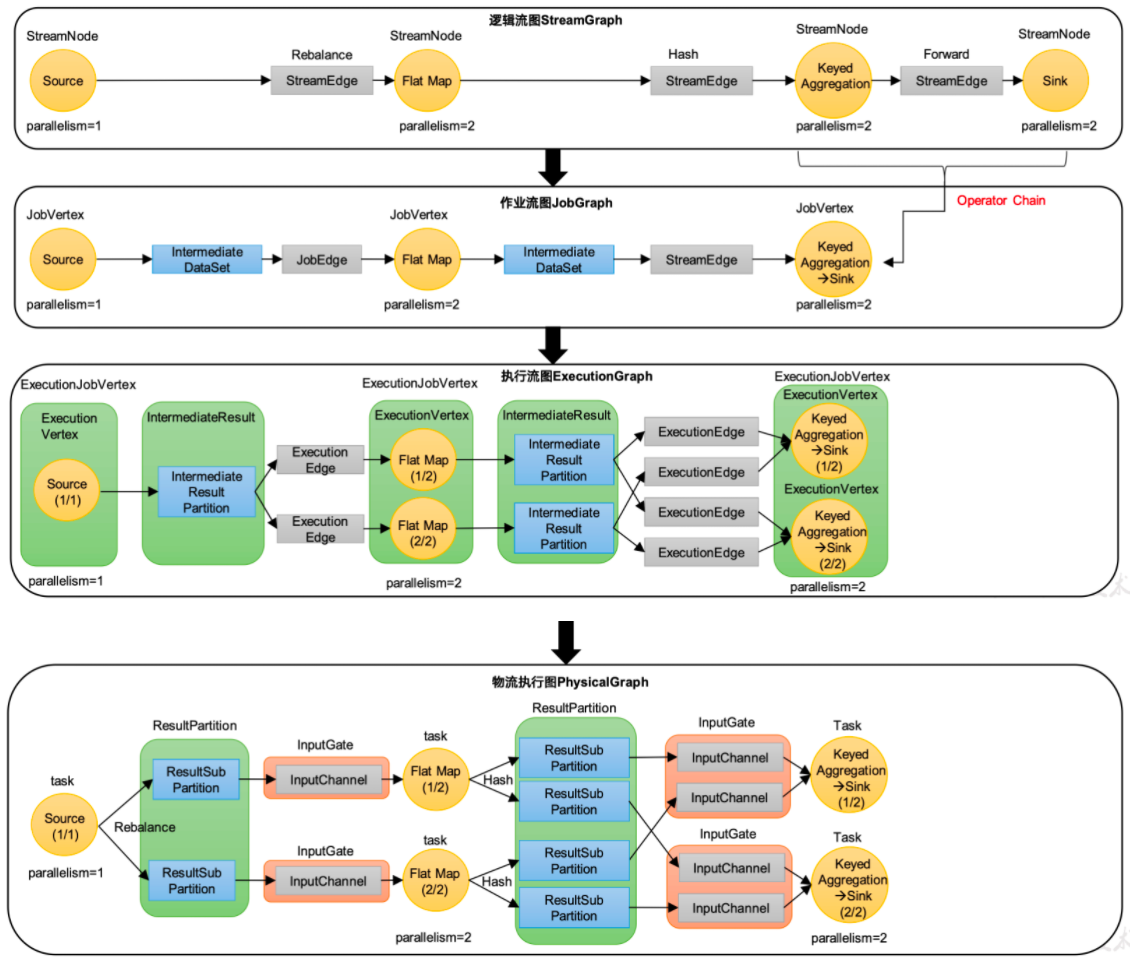
逻辑流图(StreamGraph)→ 作业图(JobGraph)→ 执行图(ExecutionGraph)→ 物理图(Physical Graph)
# yarn
# datastream api# 执行环境1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public static void main (String[] args) throws Exception { Configuration configuration = new Configuration (); configuration.set(RestOptions.BIND_PORT, "8082" ); StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(configuration); environment.setRuntimeMode(RuntimeExecutionMode.STREAMING); SingleOutputStreamOperator<Tuple2<String, Long>> sum = environment.socketTextStream("127.0.0.1" , 7777 ).flatMap((String line, Collector<Tuple2<String, Long>> out) -> { String[] words = line.split(" " ); for (String word : words) { out.collect(Tuple2.of(word, 1L )); } }) .returns(Types.TUPLE(Types.STRING, Types.LONG)) .keyBy(data -> data.f0) .sum(1 ); sum.print(); environment.execute(); environment.executeAsync(); }
# 读取数据# 从集合读取数据1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public static void main (String[] args) throws Exception { Configuration configuration = new Configuration (); configuration.set(RestOptions.BIND_PORT, "8082" ); StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(configuration); DataStreamSource<Integer> integerDataStreamSource = environment.fromCollection(Arrays.asList(1 , 2 , 3 , 4 , 5 )); DataStreamSource<Integer> dataStreamSource = environment.fromElements(1 , 2 , 3 ); integerDataStreamSource.print(); environment.execute(); }
# 文件1 2 3 4 5 6 7 8 9 <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-files</artifactId> <version>1.17 .0 </version> </dependency> FileSource<String> build = FileSource.forRecordStreamFormat(new TextLineInputFormat (), new Path ("input/1.txt" )).build(); DataStreamSink<String> aaaa = environment.fromSource(build, WatermarkStrategy.noWatermarks(), "aaaa" ).print();
# kafka1 2 3 4 5 6 7 8 9 10 11 <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka</artifactId> <version>1.17 .0 </version> </dependency> KafkaSource<String> build = KafkaSource.<String>builder().setBootstrapServers("hadoop100:9092" ).setGroupId("aaa" ).setTopics("topic_haha" ).setValueOnlyDeserializer(new SimpleStringSchema ()).setStartingOffsets(OffsetsInitializer.latest()).build(); environment.fromSource(build, WatermarkStrategy.noWatermarks(),"kafka" );
# 数据生成器读取1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(configuration);environment.setParallelism(1 ); DataGeneratorSource<String> stringDataGeneratorSource = new DataGeneratorSource <>(new GeneratorFunction <Long, String>() { @Override public String map (Long aLong) throws Exception { return "" + aLong; } }, Long.MAX_VALUE, RateLimiterStrategy.perSecond(1 ), Types.STRING); environment.fromSource(stringDataGeneratorSource, WatermarkStrategy.noWatermarks(),"datagen" ).print(); environment.execute();
# flink 数据类型Flink 使用 “类型信息”(TypeInformation)来统一表示数据类型。TypeInformation 类是 Flink 中所有类型描述符的基类。它涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化器、反序列化器和比较器。
泛型类型(GENERIC)
Flink 支持所有的 Java 类和 Scala 类。不过如果没有按照上面 POJO 类型的要求来定义,就会被 Flink 当作泛型类来处理。Flink 会把泛型类型当作黑盒,无法获取它们内部的属性;它们也不是由 Flink 本身序列化的,而是由 Kryo 序列化的。
在这些类型中,元组类型和 POJO 类型最为灵活,因为它们支持创建复杂类型。而相比之下,POJO 还支持在键(key)的定义中直接使用字段名,这会让我们的代码可读性大大增加。所以,在项目实践中,往往会将流处理程序中的元素类型定为 Flink 的 POJO 类型。
Flink 对 POJO 类型的要求如下:
类是公有(public)的
有一个无参的构造方法
所有属性都是公有(public)的
所有属性的类型都是可以序列化的
类型提示(Type Hints)
Flink 还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于 Java 中泛型擦除的存在,在某些特殊情况下(比如 Lambda 表达式中),自动提取的信息是不够精细的 —— 只告诉 Flink 当前的元素由 “船头、船身、船尾” 构成,根本无法重建出 “大船” 的模样;这时就需要显式地提供类型信息,才能使应用程序正常工作或提高其性能。
为了解决这类问题,Java API 提供了专门的 “类型提示”(type hints)。
1 2 3 .returns(new TypeHint <Tuple2<Integer, SomeType>>(){}) .returns(Types.TUPLE(Types.STRING, Types.LONG));
# 转换算子# map1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(configuration);environment.setParallelism(1 ); DataStreamSource<Integer> integerDataStreamSource = environment.fromElements(1 , 2 , 3 , 4 ); SingleOutputStreamOperator<Object> map = integerDataStreamSource.map(new MapFunction <Integer, Object>() { @Override public Object map (Integer integer) throws Exception { return integer; } }); map.print(); SingleOutputStreamOperator<Integer> map1 = integerDataStreamSource.map(num -> num * 2 );
# fliter \ flatmap1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 DataStreamSource<Integer> integerDataStreamSource = environment.fromElements(1 , 2 , 3 , 4 ); SingleOutputStreamOperator<Integer> filter = integerDataStreamSource.filter(new FilterFunction <Integer>() { @Override public boolean filter (Integer integer) throws Exception { return false ; } }); SingleOutputStreamOperator<Object> objectSingleOutputStreamOperator = integerDataStreamSource.flatMap(new FlatMapFunction <Integer, Object>() { @Override public void flatMap (Integer integer, Collector<Object> collector) throws Exception { collector.collect(integer); } }); objectSingleOutputStreamOperator.print();
# keyby1 2 3 4 5 6 7 8 9 10 11 12 13 DataStreamSource<Integer> integerDataStreamSource = environment.fromElements(1 , 2 , 3 , 4 ); KeyedStream<Integer, Tuple> integerObjectKeyedStream = integerDataStreamSource.keyBy(String.valueOf(new KeySelector <Integer, String>() { @Override public String getKey (Integer integer) throws Exception { return null ; } }));
# 简单聚合算子keyby 之后才能调用
做分组内聚合,对同一个 key 数据聚合
1 2 3 4 5 6 7 8 sum("title" ); min("vc" ) max() maxby()
# reduce1 2 3 4 、keyby之后调用 、输入类型=输出类型,类型不能变 、每个key的第一条数据来的时候,不会执行reduce方法,在起来,直接输出 reduce 方法中的参数,value1之前计算结果 value2 现在来的数据
# UDFFlink 暴露了所有 UDF 函数的接口,具体实现方式为接口或者抽象类,例如 MapFunction、FilterFunction、ReduceFunction 等。所以用户可以自定义一个函数类,实现对应的接口
1 2 3 4 5 6 7 8 9 10 11 12 13 DataStream<String> filter = stream.filter(new UserFilter ()); filter.print(); env.execute(); } public static class UserFilter implements FilterFunction <WaterSensor> { @Override public boolean filter (WaterSensor e) throws Exception { return e.id.equals("sensor_1" ); } } }
# RichXXXFunction多了生命周期管理方法
1 2 3 ............多亏你申请 open():每个子任务,在启动时,调用一次 close():每个子任务,在结束时,调用一次
多了运行时上下文,可以获取运行时环境信息,比如子任务编号,名称
无界流,如果 flink 程序异常终止,不会调用 close
正常调用 web ui cancel,会调用 close
# 分区算子1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public static void main (String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(2 ); DataStreamSource<String> localhost = environment.socketTextStream("localhost" , 7777 ); localhost.rescale().print(); localhost.broadcast().print(); localhost.global().print(); environment.execute(); }
# 自定义分区器1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class MyPart implements Partitioner <String> { @Override public int partition (String s, int i) { return Integer.parseInt(s) % i; } } public class custompartption { public static void main (String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(2 ); DataStreamSource<String> localhost = environment.socketTextStream("localhost" , 7777 ); localhost.partitionCustom(new MyPart (),num -> num).print(); environment.execute(); } }
# 分流1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 1. 使用process算子2. 定义outputtag对象3. 调用ctx.output4. 通过主流获取测流public class SplitStreamByOutputTag { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); SingleOutputStreamOperator<WaterSensor> ds = env.socketTextStream("hadoop102" , 7777 ) .map(new WaterSensorMapFunction ()); OutputTag<WaterSensor> s1 = new OutputTag <>("s1" , Types.POJO(WaterSensor.class)){}; OutputTag<WaterSensor> s2 = new OutputTag <>("s2" , Types.POJO(WaterSensor.class)){}; SingleOutputStreamOperator<WaterSensor> ds1 = ds.process(new ProcessFunction <WaterSensor, WaterSensor>() { @Override public void processElement (WaterSensor value, Context ctx, Collector<WaterSensor> out) throws Exception { if ("s1" .equals(value.getId())) { ctx.output(s1, value); } else if ("s2" .equals(value.getId())) { ctx.output(s2, value); } else { out.collect(value); } } }); ds1.print("主流,非s1,s2的传感器" ); SideOutputDataStream<WaterSensor> s1DS = ds1.getSideOutput(s1); SideOutputDataStream<WaterSensor> s2DS = ds1.getSideOutput(s2); s1DS.printToErr("s1" ); s2DS.printToErr("s2" ); env.execute(); } }
# 合流1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 # union合流的数据类型必须相同 public class unionn { public static void main (String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1 ); DataStreamSource<Integer> integerDataStreamSource1 = environment.fromElements(1 , 2 , 3 , 4 ); DataStreamSource<Integer> integerDataStreamSource = environment.fromElements(5 , 6 , 7 , 8 ); DataStream<Integer> union = integerDataStreamSource.union(integerDataStreamSource1); union.print(); environment.execute(); } } 多条流可以用 , 分割 source.union(source1,source2); 也可以用.union # 一次可以合并多条流 # connect合流数据类型可以不一样 DataStreamSource<Integer> integerDataStreamSource1 = environment.fromElements(1 , 2 , 3 , 4 ); DataStreamSource<Integer> integerDataStreamSource = environment.fromElements(5 , 6 , 7 , 8 ); DataStreamSource<String> stringDataStreamSource = environment.fromElements("111" , "222" ); ConnectedStreams<Integer, String> connect = integerDataStreamSource.connect(stringDataStreamSource); SingleOutputStreamOperator<String> map = connect.map(new CoMapFunction <Integer, String, String>() { @Override public String map1 (Integer value) throws Exception { return value.toString(); } @Override public String map2 (String value) throws Exception { return value; } }); map.print(); connect 一次只能连接两条流 连接后可以调用map等处理,但是各处理各的
# sink# 输出到外部系统Flink 作为数据处理框架,最终还是要把计算处理的结果写,入外部存储为外部应用提供支持。
Sink 多数情况下同样并不需要我们自己实现。之前我们一直在使用的 print 方法其实就是一种 Sink, 它表示将数据流写入标准控制台打印输出。Flink 官方为我们提供了一部分
# 输出到文件1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public static void main (String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1 ); environment.enableCheckpointing(2000 , CheckpointingMode.EXACTLY_ONCE); DataGeneratorSource<String> stringDataGeneratorSource = new DataGeneratorSource <>(new GeneratorFunction <Long, String>() { @Override public String map (Long aLong) throws Exception { return "" + aLong; } }, Long.MAX_VALUE, RateLimiterStrategy.perSecond(1 ), Types.STRING); DataStreamSource<String> stringDataStreamSource = environment.fromSource(stringDataGeneratorSource, WatermarkStrategy.noWatermarks(), "datagen" ); FileSink<String> build = FileSink.forRowFormat(new Path ("/Users/bytedance/Desktop" ), new SimpleStringEncoder <String>("UTF-8" )). withOutputFileConfig(OutputFileConfig.builder().withPartPrefix("==" ).withPartSuffix("++" ).build()). withBucketAssigner(new DateTimeBucketAssigner <>("yyyy-MM-dd HH" , ZoneId.systemDefault())). withRollingPolicy(DefaultRollingPolicy.builder().withRolloverInterval(Duration.ofSeconds(10 )).withMaxPartSize(new MemorySize (1024 * 1024 )).build()).build(); stringDataStreamSource.sinkTo(build); environment.execute(); }
# 输出到 kafka1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 public static void main (String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1 ); environment.enableCheckpointing(2000 , CheckpointingMode.EXACTLY_ONCE); DataGeneratorSource<String> stringDataGeneratorSource = new DataGeneratorSource <>(new GeneratorFunction <Long, String>() { @Override public String map (Long aLong) throws Exception { return "" + aLong; } }, Long.MAX_VALUE, RateLimiterStrategy.perSecond(1 ), Types.STRING); DataStreamSource<String> stringDataStreamSource = environment.fromSource(stringDataGeneratorSource, WatermarkStrategy.noWatermarks(), "datagen" ); KafkaSink<String> build = KafkaSink.<String>builder() .setBootstrapServers("hadoop100:9092,hadoop101:9092,hadoop102:9092" ) .setRecordSerializer( KafkaRecordSerializationSchema.<String>builder() .setTopic("aaaaa" ) .setValueSerializationSchema(new SimpleStringSchema ()) .build() ) .setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE) .setTransactionalIdPrefix("xxxxxx" ) .setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG,10 * 60 * 1000 + "" ) .build(); stringDataStreamSource.sinkTo(build); environment.execute(); } public static void main (String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1 ); environment.enableCheckpointing(2000 , CheckpointingMode.EXACTLY_ONCE); DataGeneratorSource<String> stringDataGeneratorSource = new DataGeneratorSource <>(new GeneratorFunction <Long, String>() { @Override public String map (Long aLong) throws Exception { return "" + aLong; } }, Long.MAX_VALUE, RateLimiterStrategy.perSecond(1 ), Types.STRING); DataStreamSource<String> stringDataStreamSource = environment.fromSource(stringDataGeneratorSource, WatermarkStrategy.noWatermarks(), "datagen" ); KafkaSink<String> build = KafkaSink.<String>builder() .setBootstrapServers("hadoop100:9092,hadoop101:9092,hadoop102:9092" ) .setRecordSerializer( new KafkaRecordSerializationSchema <String>() { @Nullable @Override public ProducerRecord<byte [], byte []> serialize(String s, KafkaSinkContext kafkaSinkContext, Long aLong) { String[] datas = s.split("," ); byte [] key = datas[0 ].getBytes(StandardCharsets.UTF_8); byte [] value = s.getBytes(StandardCharsets.UTF_8); return new ProducerRecord <>("aaa" , key, value); } } ) .setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE) .setTransactionalIdPrefix("xxxxxx" ) .setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 10 * 60 * 1000 + "" ) .build(); stringDataStreamSource.sinkTo(build); environment.execute(); }
输出到 mysql
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0 .30 </version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-jdbc</artifactId> <version>1.17 -SNAPSHOT</version> </dependency> <repositories> <repository> <id>apache-snapshots</id> <name>apache snapshots</name> <url>https: </repository> </repositories> SinkFunction<WaterSensor> jdbcSink = JdbcSink.sink( "insert into ws values(?,?,?)" , new JdbcStatementBuilder <WaterSensor>() { @Override public void accept (PreparedStatement preparedStatement, WaterSensor waterSensor) throws SQLException { preparedStatement.setString(1 , waterSensor.getId()); preparedStatement.setLong(2 , waterSensor.getTs()); preparedStatement.setInt(3 , waterSensor.getVc()); } }, JdbcExecutionOptions.builder() .withMaxRetries(3 ) .withBatchSize(100 ) .withBatchIntervalMs(3000 ) .build(), new JdbcConnectionOptions .JdbcConnectionOptionsBuilder() .withUrl("jdbc:mysql://hadoop102:3306/test?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8" ) .withUsername("root" ) .withPassword("000000" ) .withConnectionCheckTimeoutSeconds(60 ) .build() ); sensorDS.addSink(jdbcSink);
# 自定义 sink1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class Mysink extends RichSinkFunction <String> { @Override public void open (Configuration parameters) throws Exception { super .open(parameters); } @Override public void close () throws Exception { super .close(); } @Override public void invoke (String value, Context context) throws Exception { super .invoke(value, context); } }
# 时间和窗口Flink 是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的 "数据块" 进行处理,这就是所谓的 "窗口"(Window)。
在 Flink 中,窗口其实并不是一个 "框", 应该把窗口理解成一个 "桶"。在 Flink 中,窗口可以把流切割成有限大小的多个 "存储桶"。每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
Flink 中窗口并不是静态准备好的,而是动态创建 —— 当有落在这个窗口区间范围的数据达到时,才创建对应的窗口。
# 窗口分类窗口本身是截取有界数据的一种方式,所以窗口一个非常重要的信意其实就是 "怎样截取数据"。换句话说,就是以什么标准来开始和结束数据的截取,我们把它叫作窗口的 "驱动类型"。
# 1. 按照驱动类型分(1) 时间窗口 (TimeWindow)
时间窗口以时间点来定义窗口的开始 (start) 和结束 (end), 所以截取出的就是某一时间段的数据。到达结束时间时,窗口不再收集数据,触发计算输出结果,并将窗口关闭销毁。所以可以说基本思路就是 "定点发车"。
(2) 计数窗口 (CountWindow)
计数窗口基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。每个窗口截取数据的个数,就是窗口的大小。基本思路是 "人齐发车"。
# 2. 按照窗口分配数据的规则分类(1)滚动窗口
滚动窗口有固定的大小,是一种对数据进行 "均匀切片" 的划分方式。窗口之间没有重叠,也不会有间隔,是 "首尾相接" 的状态。这是最简单的窗口形式,每个数据都都会被分配到一个窗口,而且只会属于一个窗口。
(2)滑动窗口
滑动窗口的大小也是固定的。但是窗口之间并不是首尾相接的,而是可以 "错开" 一定的位置。定义滑动窗口的参数有两个:除去窗口大小 (windowsize) 之之外,还有一个 "滑动步长"(windowslide), 它其实就代表了窗口计算的频率。窗口在结束时间触发计算输出结果,那么滑动步长就代表了计算频率。
(3)会话窗口
会话窗口,是基于 "会话"(session) 来来对数据进行分分组的。会话窗口只能基于时间来定义。
会话窗口中,最重要的参数就是会话的超时时间,也就是两个会话窗口之间的最小距离。如果相邻两个数据到来的时间间隔 (Gap) 小于指定的大小 (size), 那说明还在保保持会话,它们就属于同一个窗口;如果 gap 大于 size, 那么新来的数据就应该属于新的会话窗口,而前一个窗口就应该关闭了。
(4)全局窗口
“全局窗口”, 这种窗口全局有效,会把相同 key 的所有数据都分配到同一个窗口中,这种窗口没有结束的时候,默认是不会做触发计算的。如果希望它能对数据进行计算处理,还需要自定义 "触发器"(Trigger)。
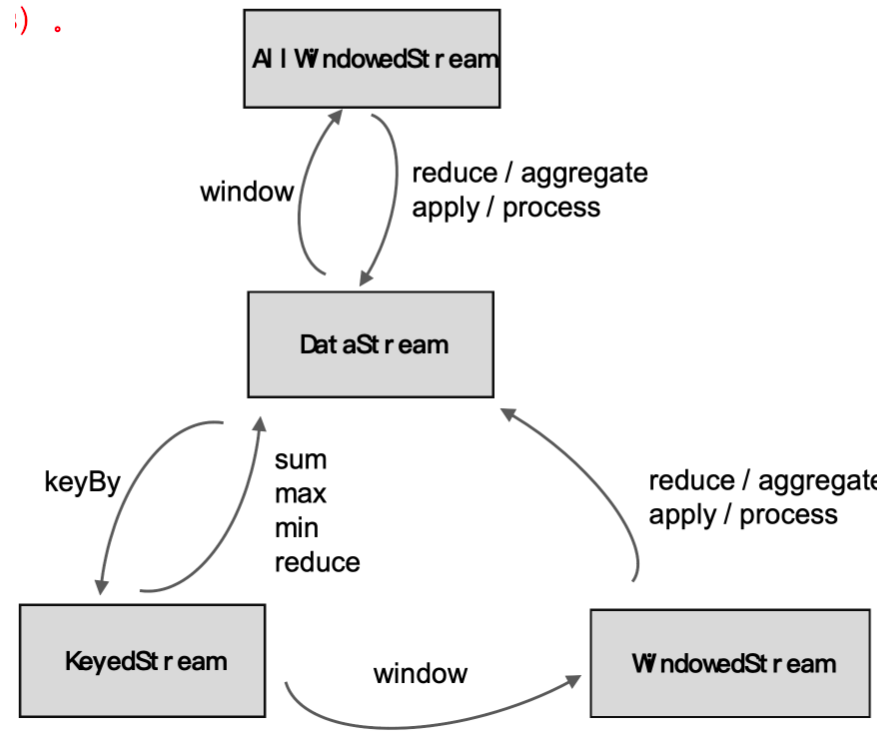
# 窗口 API# 带 keyby 和不带 keyby1.1 没有 keyby 的窗口:窗口内的所有数据进入同一个子任务,并行度只能为 1 //sensorDS.windowAll ()
1.2 有 keyby 的窗口:每个 key 上都定义了一组窗口,各自独立地进行统计计算 //sensorDS.window ()
1 2 3 4 5 6 7 8 9 10 11 sensorDS.windowAll() 基于时间的 sensorKS.window(TumblingProcessingTimeWindows.of(Time.seconds(10 ))) sensorKS.window(SlidingProcessingTimeWindows.of(Time.seconds(10 ),Time.seconds(2 ))) sensorKS.window(ProcessingTimeSessionWindows.wiithGap(Time.seconds(5 ))) sensorKS.countWindow(5 ) sensorKS.countWindow(5 ,2 ) sensorKS.window(Globalwindows.create()),_
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = localhost.keyBy(WaterSensor::getId); WindowedStream<WaterSensor, String, TimeWindow> window = waterSensorStringKeyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10 ))); WindowedStream<WaterSensor, String, TimeWindow> window1 = waterSensorStringKeyedStream.window(SlidingProcessingTimeWindows.of(Time.seconds(10 ), Time.seconds(2 ))); WindowedStream<WaterSensor, String, TimeWindow> window2 = waterSensorStringKeyedStream.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5 ))); WindowedStream<WaterSensor, String, GlobalWindow> waterSensorStringGlobalWindowWindowedStream = waterSensorStringKeyedStream.countWindow(5 ); WindowedStream<WaterSensor, String, GlobalWindow> waterSensorStringGlobalWindowWindowedStream1 = waterSensorStringKeyedStream.countWindow(5 , 2 ); WindowedStream<WaterSensor, String, GlobalWindow> window3 = waterSensorStringKeyedStream.window(GlobalWindows.create()); window.reduce(); window.aggregate(); window.process(); environment.execute();
# 窗口函数# 增量聚合 reduce1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();environment.setParallelism(1 ); environment.enableCheckpointing(2000 , CheckpointingMode.EXACTLY_ONCE); SingleOutputStreamOperator<WaterSensor> localhost = environment.socketTextStream("localhost" , 7777 ).map(new WaterSensorMapFunction ()); KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = localhost.keyBy(WaterSensor::getId); WindowedStream<WaterSensor, String, TimeWindow> window = waterSensorStringKeyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10 ))); SingleOutputStreamOperator<WaterSensor> reduce = window.reduce(new ReduceFunction <WaterSensor>() { @Override public WaterSensor reduce (WaterSensor waterSensor, WaterSensor t1) throws Exception { System.out.println("调用reduce," + waterSensor + "======" + t1); return new WaterSensor (waterSensor.getId(), t1.getTs(), waterSensor.getVc() + t1.getVc()); } }); reduce.print(); environment.execute();
# 聚合函数 aggregateReduceFunction 可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。
Flink WindowAPI 中的 aggregate 就突破了这个限制,可以定义务更加灵活的窗口聚合操作。
这个方法需要传入一个 AggregateFunction 的实现类作为参数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 public static void main (String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1 ); environment.enableCheckpointing(2000 , CheckpointingMode.EXACTLY_ONCE); SingleOutputStreamOperator<WaterSensor> localhost = environment.socketTextStream("localhost" , 7777 ).map(new WaterSensorMapFunction ()); KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = localhost.keyBy(WaterSensor::getId); WindowedStream<WaterSensor, String, TimeWindow> window = waterSensorStringKeyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10 ))); SingleOutputStreamOperator<String> aggregate = window.aggregate(new AggregateFunction <WaterSensor, Integer, String>() { @Override public Integer createAccumulator () { System.out.println("创建累加器" ); return 0 ; } @Override public Integer add (WaterSensor waterSensor, Integer integer) { System.out.println("调用add" ); return integer + waterSensor.getVc(); } @Override public String getResult (Integer integer) { System.out.println("result" ); return integer.toString(); } @Override public Integer merge (Integer integer, Integer acc1) { System.out.println("merge" ); return 0 ; } }); aggregate.print(); environment.execute(); }
# 全窗口函数1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 public static void main (String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1 ); environment.enableCheckpointing(2000 , CheckpointingMode.EXACTLY_ONCE); SingleOutputStreamOperator<WaterSensor> localhost = environment.socketTextStream("localhost" , 7777 ).map(new WaterSensorMapFunction ()); KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = localhost.keyBy(WaterSensor::getId); WindowedStream<WaterSensor, String, TimeWindow> window = waterSensorStringKeyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10 ))); SingleOutputStreamOperator<String> apply = window.apply(new WindowFunction <WaterSensor, String, String, TimeWindow>() { @Override public void apply (String s, TimeWindow window, Iterable<WaterSensor> input, Collector<String> out) throws Exception { } }); SingleOutputStreamOperator<String> process = window.process(new ProcessWindowFunction <WaterSensor, String, String, TimeWindow>() { @Override public void process (String s, ProcessWindowFunction<WaterSensor, String, String, TimeWindow>.Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { long start = context.window().getStart(); long end = context.window().getEnd(); DateFormatUtils.format(start,"yyyy-MM-dd HH:mm:ss.SSS" ); DateFormatUtils.format(end,"yyyy-MM-dd HH:mm:ss.SSS" ); long l = elements.spliterator().estimateSize(); out.collect(elements.toString()+l); } }); process.print(); environment.execute(); }
# 结合使用1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 public static void main (String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1 ); environment.enableCheckpointing(2000 , CheckpointingMode.EXACTLY_ONCE); SingleOutputStreamOperator<WaterSensor> localhost = environment.socketTextStream("localhost" , 7777 ).map(new WaterSensorMapFunction ()); KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = localhost.keyBy(WaterSensor::getId); WindowedStream<WaterSensor, String, TimeWindow> window = waterSensorStringKeyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10 ))); SingleOutputStreamOperator<String> aggregate1 = window.aggregate(new MyAgg (), new MyProcWin ()); aggregate1.print(); environment.execute(); } public static class MyAgg implements AggregateFunction <WaterSensor, Integer, String> { @Override public Integer createAccumulator () { System.out.println("创建累加器" ); return 0 ; } @Override public Integer add (WaterSensor waterSensor, Integer integer) { System.out.println("调用add" ); return integer + waterSensor.getVc(); } @Override public String getResult (Integer integer) { System.out.println("result" ); return integer.toString(); } @Override public Integer merge (Integer integer, Integer acc1) { System.out.println("merge" ); return 0 ; } } public static class MyProcWin extends ProcessWindowFunction <String,String,String,TimeWindow>{ @Override public void process (String s, ProcessWindowFunction<String, String, String, TimeWindow>.Context context, Iterable<String> elements, Collector<String> out) throws Exception { long start = context.window().getStart(); long end = context.window().getEnd(); DateFormatUtils.format(start,"yyyy-MM-dd HH:mm:ss.SSS" ); DateFormatUtils.format(end,"yyyy-MM-dd HH:mm:ss.SSS" ); long l = elements.spliterator().estimateSize(); out.collect(elements.toString()+l); } }
# 动态会话窗口1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public static void main (String[] args) { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1 ); environment.enableCheckpointing(2000 , CheckpointingMode.EXACTLY_ONCE); SingleOutputStreamOperator<WaterSensor> localhost = environment.socketTextStream("localhost" , 7777 ).map(new WaterSensorMapFunction ()); KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = localhost.keyBy(WaterSensor::getId); WindowedStream<WaterSensor, String, TimeWindow> window = waterSensorStringKeyedStream.window(ProcessingTimeSessionWindows.withDynamicGap( new SessionWindowTimeGapExtractor <WaterSensor>() { @Override public long extract (WaterSensor element) { return element.getTs() * 1000L ; } } )); }
# 计数窗口1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public static void main (String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1 ); environment.enableCheckpointing(2000 , CheckpointingMode.EXACTLY_ONCE); SingleOutputStreamOperator<WaterSensor> localhost = environment.socketTextStream("localhost" , 7777 ).map(new WaterSensorMapFunction ()); KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = localhost.keyBy(WaterSensor::getId); WindowedStream<WaterSensor, String, GlobalWindow> waterSensorStringGlobalWindowWindowedStream = waterSensorStringKeyedStream.countWindow(5 , 2 ); SingleOutputStreamOperator<String> process = waterSensorStringGlobalWindowWindowedStream.process(new ProcessWindowFunction <WaterSensor, String, String, GlobalWindow>() { @Override public void process (String s, ProcessWindowFunction<WaterSensor, String, String, GlobalWindow>.Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { long l = context.window().maxTimestamp(); long l1 = elements.spliterator().estimateSize(); out.collect(l + "===" + l1); } }); process.print(); environment.execute(); }
# 触发器 移除器触发器:触发计算和输出
窗口触发:
时间进展 >= 窗口的最大时间戳 (end-1ms)
移除器:
定义移除数据的逻辑
触发器和移除器都有默认实现,一般不需要自定义
以时间类型的滚动窗口为例,分析原理:
TODO1、窗口什么时候触发输出?
时间进展 >= 窗口的最大时间戳 (end-1ms)
TODO2、窗口是怎么划分的?
start = 向下取整,取窗口长度的整数倍
end=start + 窗口长度
窗口左闭右开 ==》
属于本窗口的最大时间戳 = end-1ms
TODO 3、窗口的生命周期?
创建:属于本窗口的第一条数据来的时候,现 new 的,放入一一个 singleton 单例的集合中
销毁 (关窗): 时间进展 >= 窗口的最大时间戳 (end-1ms)+ 允许迟到的时间 (默认 0)
# 时间事件时间:数据产生的时间
处理时间:数据被处理的时间
# 水位线具体实现上,水位线可以看作一条特殊的数据记录,它是插入到数据流中的一个标记点,主要内容就是一个时间戳!用来指示当前的事件时间。
2) 乱序流中的水位线
在分布式系统中,数据在节点间传输,会因为网络传输延迟的不确定性,导致顺序发生改变,这就是所谓的 "乱序数据"
乱序 + 数据量小:我们还是靠数据来驱动,每来一个数据就提取它的时间戳、插入一个水位线。不过现在的情况是数据乱序,所以插入新的水位线时,要先判断一了下时间戳是否比之前的大,否则就不再生成新的水位线。也就是说,只有数据的时间戳比当前时钟大,才能推动动时钟前进,这时才插入水位线。
乱序 + 数据量大:如果考虑到大量数据同时到来的处理效率,我们同样可以周期性地生成水位线。这时只需要保存一下之前所有数据中的最大时间戳,需要插入水位线时,就直接以它作为时间戳生成新的水位线。
乱序 + 迟到数据:我们无法正确处理 "迟到" 的数据。为了让窗口能够正确收集到迟到的数据,我们也可以等上一段时间,比如 2 秒;也就是用当前已有数据的最大大时间戳减去 2 秒,就是要插入的水位线的时间戳。这样的话,9 秒的数据到来之后,事件时钟不会直接推进到 9 秒,而是进展到了 7 秒;必须等到 11 秒的数据到来之后,事件时钟才会进展到 9 秒,这时迟到数据也都已收集齐,0~9 秒的窗口就可以正确计算结果了。
3) 水位线特性
水位线是插入到数据流中的一个标记,可以认为是一个特殊的数据
水位线主要的内容是一个时间戳,用来表示当前事件时间的进展
水位线是基于数据的时间戳生成的
水位线的时间戳必须单调递增,以确保任务的事件时间时钟一直向前推进
水位线可以通过设置延迟,来保证正确处理乱序数据
一个水位线 Watermark (t), 表示在当前流中事件时间已经达到了时间戳 t, 这代表 t 之前的所有数据都到齐了,之后流中不会出现时间戳 t’<t 的数据
水位线是 Flink 流处理中保证结果正确性的核心机制,它往往会跟窗口一起配合,完成对乱序数据的正确处理。
正确理解:在 Flink 中,窗口其实并不是一个 "框", 应该把窗口理解成一个 "桶"。在 Flink 中,窗口可以把流切割成有限大小的多个 "存储桶"(bucket); 每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
# 生成水位线一个水位线一旦出现,就表示这个时间之前的数据已经全部到齐、之后再也不会出现了。不过如果要保证绝对正确,就必须等足够长的时间,这会带来更高的延迟。
内置水位线,有序流水位线
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public class watermarkdemo { public static void main (String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1 ); environment.enableCheckpointing(2000 , CheckpointingMode.EXACTLY_ONCE); SingleOutputStreamOperator<WaterSensor> localhost = environment.socketTextStream("localhost" , 7777 ).map(new WaterSensorMapFunction ()); WatermarkStrategy<WaterSensor> waterSensorWatermarkStrategy = WatermarkStrategy .<WaterSensor>forMonotonousTimestamps() .withTimestampAssigner(new SerializableTimestampAssigner <WaterSensor>() { @Override public long extractTimestamp (WaterSensor waterSensor, long l) { System.out.println(waterSensor + "=======" + l); return waterSensor.getTs() * 1000L ; } }); SingleOutputStreamOperator<WaterSensor> waterSensorSingleOutputStreamOperator = localhost.assignTimestampsAndWatermarks(waterSensorWatermarkStrategy); SingleOutputStreamOperator<String> process = waterSensorSingleOutputStreamOperator.keyBy(WaterSensor::getId) .window(TumblingEventTimeWindows.of(Time.seconds(10 ))) .process(new ProcessWindowFunction <WaterSensor, String, String, TimeWindow>() { @Override public void process (String s, ProcessWindowFunction<WaterSensor, String, String, TimeWindow>.Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { long startTs = context.window().getStart(); long endTs = context.window().getEnd(); String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS" ); String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS" ); long count = elements.spliterator().estimateSize(); out.collect(windowStart + windowEnd); } }); environment.execute(); } }
内置 watermark 都是周期性生成的 environment.getConfig ().setAutoWatermarkInterval (); 默认 200 毫秒
有序流 watermark = 当前最大的事件时间 - 1ms
乱序流 watermark = 当前最大的事件时间 - 延迟时间 -1ms
升序 watermark 就是等待时间为 0 的乱序 watermark
乱序流设置水位线
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import java.time.Duration;public class watermarkOOOdemo { public static void main (String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1 ); environment.enableCheckpointing(2000 , CheckpointingMode.EXACTLY_ONCE); SingleOutputStreamOperator<WaterSensor> localhost = environment.socketTextStream("localhost" , 7777 ).map(new WaterSensorMapFunction ()); WatermarkStrategy<WaterSensor> waterSensorWatermarkStrategy = WatermarkStrategy .<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3 )) .withTimestampAssigner(new SerializableTimestampAssigner <WaterSensor>() { @Override public long extractTimestamp (WaterSensor waterSensor, long l) { System.out.println(waterSensor + "=======" + l); return waterSensor.getTs() * 1000L ; } }); SingleOutputStreamOperator<WaterSensor> waterSensorSingleOutputStreamOperator = localhost.assignTimestampsAndWatermarks(waterSensorWatermarkStrategy); SingleOutputStreamOperator<String> process = waterSensorSingleOutputStreamOperator.keyBy(WaterSensor::getId) .window(TumblingEventTimeWindows.of(Time.seconds(10 ))) .process(new ProcessWindowFunction <WaterSensor, String, String, TimeWindow>() { @Override public void process (String s, ProcessWindowFunction<WaterSensor, String, String, TimeWindow>.Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { long startTs = context.window().getStart(); long endTs = context.window().getEnd(); String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS" ); String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS" ); long count = elements.spliterator().estimateSize(); out.collect(windowStart + windowEnd); } }); environment.execute(); } }
水位线生成器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 public class MyPeriodWaterMark <T> implements WatermarkGenerator <T> { private long maxTs; private long delayTs; public MyPeriodWaterMark (long delayTs) { this .delayTs = delayTs; this .maxTs = Long.MIN_VALUE + this .delayTs + 1 ; } @Override public void onEvent (T t, long l, WatermarkOutput watermarkOutput) { maxTs = Math.max(maxTs, l); System.out.println("最大时间穿" + maxTs); } @Override public void onPeriodicEmit (WatermarkOutput watermarkOutput) { watermarkOutput.emitWatermark(new Watermark (maxTs-delayTs -1 )); System.out.println(maxTs-delayTs -1 ); } } public class watermarkCuustomdemo { public static void main (String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1 ); environment.enableCheckpointing(2000 , CheckpointingMode.EXACTLY_ONCE); environment.getConfig().setAutoWatermarkInterval(200 ); SingleOutputStreamOperator<WaterSensor> localhost = environment.socketTextStream("localhost" , 7777 ).map(new WaterSensorMapFunction ()); WatermarkStrategy<WaterSensor> waterSensorWatermarkStrategy = WatermarkStrategy .<WaterSensor>forGenerator(new WatermarkGeneratorSupplier <WaterSensor>() { @Override public WatermarkGenerator<WaterSensor> createWatermarkGenerator (Context context) { return new MyPeriodWaterMark <>(3000L ); } }) .withTimestampAssigner(new SerializableTimestampAssigner <WaterSensor>() { @Override public long extractTimestamp (WaterSensor waterSensor, long l) { System.out.println(waterSensor + "=======" + l); return waterSensor.getTs() * 1000L ; } }); SingleOutputStreamOperator<WaterSensor> waterSensorSingleOutputStreamOperator = localhost.assignTimestampsAndWatermarks(waterSensorWatermarkStrategy); SingleOutputStreamOperator<String> process = waterSensorSingleOutputStreamOperator.keyBy(WaterSensor::getId) .window(TumblingEventTimeWindows.of(Time.seconds(10 ))) .process(new ProcessWindowFunction <WaterSensor, String, String, TimeWindow>() { @Override public void process (String s, ProcessWindowFunction<WaterSensor, String, String, TimeWindow>.Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { long startTs = context.window().getStart(); long endTs = context.window().getEnd(); String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS" ); String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS" ); long count = elements.spliterator().estimateSize(); out.collect(windowStart + windowEnd); } }); environment.execute(); } }
# 断点式水位线生成器1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class MyPuntuatedPeriodWaterMark <T> implements WatermarkGenerator <T> { private long maxTs; private long delayTs; public MyPuntuatedPeriodWaterMark (long delayTs) { this .delayTs = delayTs; this .maxTs = Long.MIN_VALUE + this .delayTs + 1 ; } @Override public void onEvent (T t, long l, WatermarkOutput watermarkOutput) { maxTs = Math.max(maxTs, l); watermarkOutput.emitWatermark(new Watermark (maxTs - delayTs - 1 )); System.out.println( maxTs); System.out.println( maxTs - delayTs - 1 ); } @Override public void onPeriodicEmit (WatermarkOutput watermarkOutput) { } } WatermarkStrategy<WaterSensor> waterSensorWatermarkStrategy = WatermarkStrategy .<WaterSensor>forGenerator(ctx -> new MyPuntuatedPeriodWaterMark <>(3000L ))
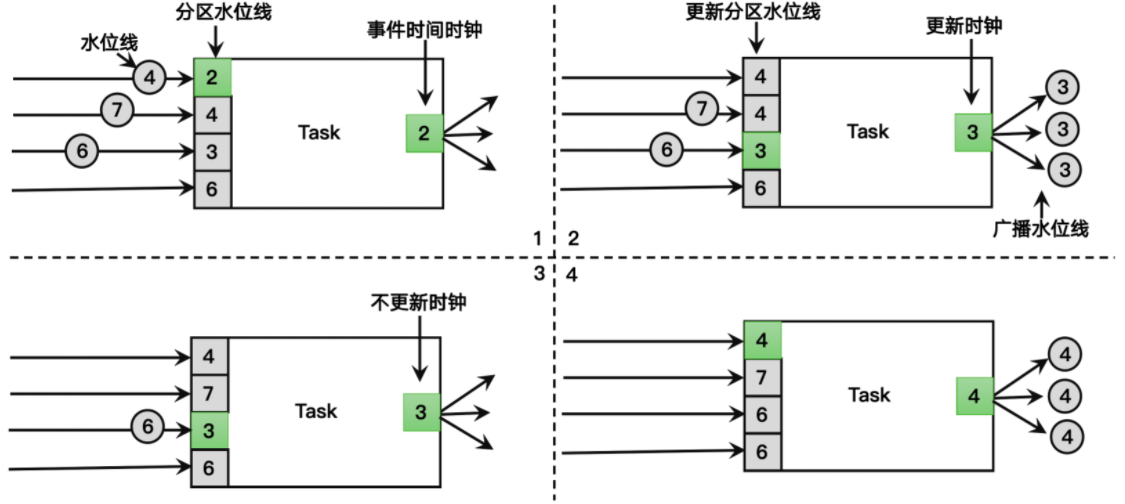
# 水位线传递
收到上游多个,取最小
往下游多个发送,广播
空闲等待:超过时间上有还没水位过来,后续不使用
1 2 3 4 5 6 7 8 SingleOutputStreamOperator<Integer> localhost = environment.socketTextStream("localhost" , 7777 ) .partitionCustom(new MyPart (), r -> r) .map(Integer::parseInt) .assignTimestampsAndWatermarks(WatermarkStrategy .<Integer>forMonotonousTimestamps() .withTimestampAssigner((r, ts) -> r * 1000L ) .withIdleness(Duration.ofSeconds(5 )));
允许迟到
推迟关窗时间,在关窗之前,会计算迟到数据,来一条计算一次。
关窗口迟到数据不会被计算
乱序:数据顺序乱了,出现时间小的比时间大的后来
迟到:当前数据的时间戳 < 当前的 watermark
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 SingleOutputStreamOperator<String> process = waterSensorSingleOutputStreamOperator.keyBy(WaterSensor::getId) .window(TumblingEventTimeWindows.of(Time.seconds(10 ))) .allowedLateness(Time.seconds(2 )) .process(new ProcessWindowFunction <WaterSensor, String, String, TimeWindow>() { @Override public void process (String s, ProcessWindowFunction<WaterSensor, String, String, TimeWindow>.Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { long startTs = context.window().getStart(); long endTs = context.window().getEnd(); String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS" ); String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS" ); long count = elements.spliterator().estimateSize(); out.collect(windowStart + windowEnd); } });
侧输出流
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 OutputTag<WaterSensor> latedata = new OutputTag <>("latedata" , Types.POJO(WaterSensor.class)); SingleOutputStreamOperator<String> process = waterSensorSingleOutputStreamOperator.keyBy(WaterSensor::getId) .window(TumblingEventTimeWindows.of(Time.seconds(10 ))) .allowedLateness(Time.seconds(2 )) .sideOutputLateData(latedata) .process(new ProcessWindowFunction <WaterSensor, String, String, TimeWindow>() { @Override public void process (String s, ProcessWindowFunction<WaterSensor, String, String, TimeWindow>.Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { long startTs = context.window().getStart(); long endTs = context.window().getEnd(); String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS" ); String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS" ); long count = elements.spliterator().estimateSize(); out.collect(windowStart + windowEnd); } }); process.getSideOutput(latedata).printToErr(); process.print();
# 合流# 基于时间的合流 - 双流联结窗口联结
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 SingleOutputStreamOperator<Tuple2<String, Integer>> operator1 = environment.fromElements(Tuple2.of("a" , 1 ),Tuple2.of("b" , 2 ),Tuple2.of("c" , 1 )) .assignTimestampsAndWatermarks(WatermarkStrategy .<Tuple2<String, Integer>>forMonotonousTimestamps() .withTimestampAssigner((value, ts) -> value.f1 * 1000L )); SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> operator2 = environment.fromElements(Tuple3.of("a" , 1 , 11 ), Tuple3.of("b" , 2 , 22 ), Tuple3.of("c" , 1 , 33 )) .assignTimestampsAndWatermarks(WatermarkStrategy .<Tuple3<String, Integer, Integer>>forMonotonousTimestamps() .withTimestampAssigner((value, ts) -> value.f1 * 1000L )); DataStream<String> apply = operator1.join(operator2) .where(r1 -> r1.f0) .equalTo(r2 -> r2.f0) .window(TumblingEventTimeWindows.of(Time.seconds(5 ))) .apply(new JoinFunction <Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() { @Override public String join (Tuple2<String, Integer> stringIntegerTuple2, Tuple3<String, Integer, Integer> stringIntegerIntegerTuple3) throws Exception { return stringIntegerTuple2 + "" + stringIntegerIntegerTuple3; } }); apply.print();
间隔联结
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 SingleOutputStreamOperator<Tuple2<String, Integer>> operator1 = environment.fromElements(Tuple2.of("a" , 1 ),Tuple2.of("b" , 2 ),Tuple2.of("c" , 1 )) .assignTimestampsAndWatermarks(WatermarkStrategy .<Tuple2<String, Integer>>forMonotonousTimestamps() .withTimestampAssigner((value, ts) -> value.f1 * 1000L )); SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> operator2 = environment.fromElements(Tuple3.of("a" , 1 , 11 ), Tuple3.of("b" , 2 , 22 ), Tuple3.of("c" , 1 , 33 )) .assignTimestampsAndWatermarks(WatermarkStrategy .<Tuple3<String, Integer, Integer>>forMonotonousTimestamps() .withTimestampAssigner((value, ts) -> value.f1 * 1000L )); KeyedStream<Tuple2<String, Integer>, String> tuple2StringKeyedStream = operator1.keyBy(r2 -> r2.f0); KeyedStream<Tuple3<String, Integer, Integer>, String> tuple3StringKeyedStream = operator2.keyBy(r2 -> r2.f0); SingleOutputStreamOperator<String> process = tuple2StringKeyedStream.intervalJoin(tuple3StringKeyedStream) .between(Time.seconds(-2 ), Time.seconds(2 )) .process(new ProcessJoinFunction <Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() { @Override public void processElement (Tuple2<String, Integer> left, Tuple3<String, Integer, Integer> right, ProcessJoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>.Context ctx, Collector<String> out) throws Exception { out.collect(left + "=====" + right); } }); process.print();
处理迟到数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 KeyedStream<Tuple2<String, Integer>, String> tuple2StringKeyedStream = operator1.keyBy(r2 -> r2.f0); KeyedStream<Tuple3<String, Integer, Integer>, String> tuple3StringKeyedStream = operator2.keyBy(r2 -> r2.f0); OutputTag<Tuple2<String, Integer>> tupleOutputTag = new OutputTag <>("ks1-late" , Types.TUPLE(Types.STRING, Types.INT)); OutputTag<Tuple3<String, Integer, Integer>> tupleOutputTag2 = new OutputTag <>("ks2-late" , Types.TUPLE(Types.STRING, Types.INT, Types.INT)); SingleOutputStreamOperator<String> process = tuple2StringKeyedStream.intervalJoin(tuple3StringKeyedStream) .between(Time.seconds(-2 ), Time.seconds(2 )) .sideOutputLeftLateData(tupleOutputTag) .sideOutputRightLateData(tupleOutputTag2) .process(new ProcessJoinFunction <Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() { @Override public void processElement (Tuple2<String, Integer> left, Tuple3<String, Integer, Integer> right, ProcessJoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>.Context ctx, Collector<String> out) throws Exception { out.collect(left + "=====" + right); } }); process.getSideOutput(tupleOutputTag).printToErr(); process.getSideOutput(tupleOutputTag2).printToErr(); process.print();
# 处理函数1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = waterSensorSingleOutputStreamOperator.keyBy(WaterSensor::getId); SingleOutputStreamOperator<String> process = waterSensorStringKeyedStream.process(new KeyedProcessFunction <String, WaterSensor, String>() { @Override public void processElement (WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception { Long timestamp = ctx.timestamp(); TimerService timerService = ctx.timerService(); timerService.registerEventTimeTimer(5000L ); System.out.println(timestamp + "===" ); } @Override public void onTimer (long timestamp, KeyedProcessFunction<String, WaterSensor, String>.OnTimerContext ctx, Collector<String> out) throws Exception { super .onTimer(timestamp, ctx, out); System.out.println(timestamp + "=======---" ); } });
定时器:
keyed 才有
事件时间定时器,通过 watermark 触发
watermark >= 注册时间
watermark = 当前最大时间 - 等待时间 - 1
在 process 中获取 watermark,显示的上一次的 watermaark,因为 process 还没收到这条新数据的 watermark
# 侧输出流1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 SingleOutputStreamOperator<WaterSensor> waterSensorSingleOutputStreamOperator = environment.socketTextStream("localhost" , 7777 ).map(new WaterSensorMapFunction ()) .assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3 )) .withTimestampAssigner((ele, ts) -> ele.getTs() * 1000L )); OutputTag<String> warn11 = new OutputTag <>("warn" , Types.STRING); SingleOutputStreamOperator<WaterSensor> process = waterSensorSingleOutputStreamOperator.keyBy(WaterSensor::getId) .process(new KeyedProcessFunction <String, WaterSensor, WaterSensor>() { @Override public void processElement (WaterSensor value, KeyedProcessFunction<String, WaterSensor, WaterSensor>.Context ctx, Collector<WaterSensor> out) throws Exception { if (value.getVc() > 10 ) { ctx.output(warn11, "sss" ); } out.collect(value); } }); process.getSideOutput(warn11).printToErr(); process.print();
# 状态管理在 Flink 中,算子任务可以分为无状态和有状态两种情况。
无状态的算子任务只需要观察每个独立事件,根据当前输入的数故据直接转换输出结果。我们之前讲到的基本转换算子,如 map、filter、flatMap, 计算时不依赖其他数据,就都属于无状态的算子。
而有状态的算子任务,则除当前数据之外,还需要一些其他也数据来得到计算结果。这里的 "其他数据", 就是所谓的状态 (state)。我们之前讲到的算子中,聚合算子、窗口算子都属于有状态的算子。
托管状态(Managed State)和原始状态(Raw State)
Flink 的状态有两种:托管状态(Managed State)和原始状态(Raw State)。托管状态就是由 Flink 统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由 Flink 实现,我们只要调接口就可以;而原始状态则是自定义的,相当于就是开辟了一块内存,需要我们自己管理,实现状态的序列化和故障恢复。
通常我们采用 Flink 托管状态来实现需求。
托管状态分为算子状态和按键分区状态
keyby 后的是按键分区状态,其他称为算子状态
算子状态(Operator State)和按键分区状态(Keyed State)
接下来我们的重点就是托管状态(Managed State)。
我们知道在 Flink 中,一个算子任务会按照并行度分为多个并行子任务执行,而不同的子任务会占据不同的任务槽(task slot)。由于不同的 slot 在计算资源上是物理隔离的,所以 Flink 能管理的状态在并行任务间是无法共享的,每个状态只能针对当前子任务的实例有效。
而很多有状态的操作(比如聚合、窗口)都是要先做 keyBy 进行按键分区的。按键分区之后,任务所进行的所有计算都应该只针对当前 key 有效,所以状态也应该按照 key 彼此隔离。在这种情况下,状态的访问方式又会有所不同。
基于这样的想法,我们又可以将托管状态分为两类:算子状态和按键分区状态。
算子状态可以用在所有算子上,使用的时候其实就跟一个本地变量没什么区别–因为本地变量的作用域也是当前任务实例。在使用时,我们还需进一步实现 ChneckpointedFunction 接口。
# 容错机制在流处理中,我们可以用存档读档的思路,就是将之前某个日时间点所有的状态保存下来,这份 "存档" 就是所谓的 "检查点"(checkpoint)。
1)周期性的触发保存
“随时存档” 确实恢复起来方便,可是需要我们不停地做存档操作。如果每处理一条数据就进行检查点的保存,当大量数据同时到来时,就会耗费很多资源来频繁做检查点,数据处理的速度就会受到影响。所以在 Flink 中,检查点的保存是周期性触发的,间隔时间可以进行设置。
2)保存的时间点
我们应该在所有任务(算子)都恰好处理完一个相同的输入数据的时候,将它们的状态保存下来。
这样做可以实现一个数据被所有任务(算子)完整地处理完,状态得到了保存。
如果出现故障,我们恢复到之前保存的状态,故障时正在处理的所有数据都需要重新处理;我们只需要让源(source)任务向数据源重新提交偏移量、请求重放数据就可以了。当然这需要源任务可以把偏移量作为算子状态保存下来,而且外部数据源能够重置偏移量
当发生故障时,就需要找到最近一次成功保存的检查点来恢复状态。
(1) 重启应用
遇到故障之后,第一步当然就是重启。我们将应用重新启动动后,所有任务的状态会清空。
(2) 读取检查点,重置状态
找到最近一次保存的检查点,从中读出每个算子任务状态的快照,分别填充到对应的状态中。这样,Flink 内部所有任务的状态,就恢复到了保存检查点的那一时刻,也就是刚好处理完第三个数据的时候。
(3) 重置偏移量
从检查点恢复状态后还有一个问题:如果直接继续处理数据,那么保存检查点之后、到发生故障这段时间内的数据,也就是第 4、5 个数据就相当于丢掉了;这会造成计算结果的错误。
为了不丢数据,我们应该从保存检查点后开始重新读取数据,这可以通过 Source 任务向外部数据源重新提交偏移量 (offset) 来实现。
(4) 继续处理数据
接下来,我们就可以正常处理数据了。首先是重放第 4、5 个一数据,然后继续读取后面的数据。
# Flink SQL