# GPU 入门概论
摘要:本篇文章旨在为后续 LLM 文章做铺垫,通过本篇文章,我们可以理解:
1、GPU 核心架构及参数
2、2024 主流 GPU 规格及对比
3、NVIDIA 搞的一些奇妙技术
4、云厂商售卖的 GPU 都有啥
5、hands-on lab 自己安装驱动,实现跑开源模型!
PS: 本文中如果没有特值,GPU 均指 NVIDIA 的 GPU,本文不讨论华为昇腾 GPU 或 AMD 的 GPU
# 前置芝士
# PCIe 交换芯片
CPU、内存、存储(NVME)、GPU、网卡等支持 PCIe 的设备,都可以连接到 PCIe 总线或专门的 PCIe 交换芯片,实现互联互通。
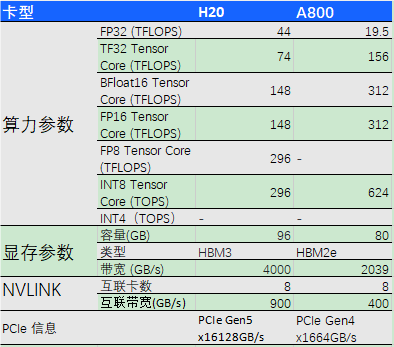
PCIe 目前有 5 代产品,最新的是 Gen5 。比如下面 H20 和 A800 的对比,H20 使用的是 PCIe Gen5,速度更快。
# 什么是显卡?
显卡(Video card,Graphics card)全称显示接口卡,又称显示适配器,是计算机最基本配置、最重要的配件之一。显卡作为电脑主机里的一个重要组成部分,是电脑进行数模信号转换的设备,承担输出显示图形的任务。显卡接在电脑主板上,它将电脑的数字信号转换成模拟信号让显示器显示出来,同时显卡还是有图像处理能力,可协助 CPU 工作,提高整体的运行速度。对于从事专业图形设计的人来说显卡非常重要。民用和军用显卡图形芯片供应商主要包括 AMD (超微半导体) 和 Nvidia (英伟达) 2 家。在科学计算中,显卡被称为显示加速卡。
# 什么是显存?
也被叫做帧缓存,它的作用是用来存储显卡芯片处理过或者即将提取的渲染数据。如同计算机的内存一样,显存是用来存储要处理的图形信息的部件。
# 显卡、显卡驱动、CUDA 之间的关系
显卡:(GPU),主流是 NVIDIA 的 GPU,因为深度学习本身需要大量计算。GPU 的并行计算能力,在过去几年里恰当地满足了深度学习的需求。AMD 的 GPU 基本没有什么支持,可以不用考虑。
驱动:没有显卡驱动,就不能识别 GPU 硬件,不能调用其计算资源。但是,NVIDIA 在 Linux 上的驱动安装特别麻烦。
CUDA:是显卡厂商 NVIDIA 推出的只能用于自家 GPU 的并行计算框架。只有安装这个框架才能够进行复杂的并行计算。主流的深度学习框架也都是基于 CUDA 进行 GPU 并行加速的,几乎无一例外。还有一个叫做 cudnn,是针对深度卷积神经网络的加速库。
# 显卡驱动与 cuda 的关系
NVIDIA 的显卡驱动器与 CUDA 并不是一一对应的,CUDA 本质上只是一个工具包而已,所以我可以在同一个设备上安装很多个不同版本的 CUDA 工具包,比如可以同时安装 CUDA 9.0、CUDA 9.2、CUDA 10.0 三个版本。一般情况下,我只需要安装最新版本的显卡驱动,然后根据自己的选择选择不同 CUDA 工具包就可以了,但是由于使用离线的 CUDA 总是会捆绑 CUDA 和驱动程序,所以在使用多个 CUDA 的时候就不要选择离线安装的 CUDA 了,否则每次都会安装不同的显卡驱动,这不太好,我们直接安装一个最新版的显卡驱动,然后在线安装不同版本的 CUDA 即可。
为什么 GPU 特别擅长处理图像数据呢?
这是因为图像上的每一个像素点都有被处理的需要,而且每个像素点处理的过程和方式都十分相似,GPU 就是用很多简单的计算单元去完成大量的计算任务,类似于纯粹的人海战术。GPU 不仅可以在图像处理领域大显身手,它还被用来科学计算、密码破解、数值分析,海量数据处理(排序,Map-Reduce 等),金融分析等需要大规模并行计算的领域。
# 带宽单位
大规模 GPU 训练的性能与数据传输速度有直接关系。这里面涉及到很多链路,比如 PCIe 带宽、内存带宽、NVLink 带宽、HBM 带宽、网络带宽等等。
- 网络习惯用
bits/second (b/s)表示之外,并且一般说的都是单向(TX/RX); - 其他模块带宽基本用
byte/sedond (B/s)或transactions/second (T/s)表示,并且一般都是双向总带宽。
# GPU 核心架构及参数
NVIDIA 数据中心级 GPU,目前在售产品有 B100、H200、L40S、A100、A800、H100、H800、V100。参考:
https://resources.nvidia.com/l/en-us-gpu?ncid=no-ncid
在了解 V100、A100、H100 这几款 GPU 的区别之前,我们先来简单了解下 NVIDIA GPU 的核心参数,这样能够更好地帮助我们了解这些 GPU 的差别和各自的优势。
# 算力指标
FLOPS(每秒浮点运算次数):
GPU 的算力指标主要指的是每秒可以执行的浮点运算次数,通常用 FLOPS(Floating Point Operations Per Second)来表示。 这是衡量 GPU 性能的关键参数之一。除了基本的 FLOPS,还有其他单位如 GFLOPS、TFLOPS 等,用于表示不同规模的浮点运算能力:
https://cloud.tencent.com/developer/article/1893665
1 个 MFLOPS (megaFLOPS) 等于每秒一百万 (=10^6) 次的浮点运算量
1 个 GFLOPS (gigaFLOPS) 等于每秒十亿 (=10^9) 次的浮点运算草量:
1 个 TFLOPS (teraFLOPS) 等于每秒一万亿 (=10^12) 次的浮点运算量
CUDA 核心和流处理器:
- CUDA 核心:NVIDIA GPU 中的基本处理单元,用于执行计算任务。
- 流处理器:在 AMD GPU 中相似的基本处理单元。
带宽和内存:
- 带宽:GPU 的内存带宽影响其数据传输速率,直接影响计算性能。
- 显存容量:较大的显存容量允许处理更大的数据集,特别是在高分辨率图形和大型数据集的计算中。
# 核心类型
在 NVIDIA 的通用 GPU 架构中,存在三种主要的核心类型:CUDA Core、Tensor Core 以及 RT Core
# CUDA Core
CUDA Core:CUDA Core 是 NVIDIA GPU 上的计算核心单元,用于执行通用的并行计算任务,是最常看到的核心类型。NVIDIA 通常用最小的运算单元表示自己的运算能力,CUDA Core 指的是一个执行基础运算的处理元件,我们所说的 CUDA Core 数量,通常对应的是 FP32 计算单元的数量。
# Tensor Core
Tensor Core:Tensor Core 是 NVIDIA Volta 架构及其后续架构(如 Ampere 架构)中引入的一种特殊计算单元。它们专门用于深度学习任务中的张量计算,如 [矩阵乘法] 和卷积运算。Tensor Core 核心特别大,通常与深度学习框架(如 TensorFlow 和 PyTorch)相结合使用,它可以把整个矩阵都载入寄存器中批量运算,实现十几倍的效率提升。
# RT Core
RT Core:RT Core 是 NVIDIA 的专用硬件单元,主要用于加速光线追踪计算。正常数据中心级的 GPU 核心是没有 RT Core 的,主要是消费级显卡才为光线追踪运算添加了 RTCores。RT Core 主要用于游戏开发、电影制作和虚拟现实等需要实时渲染的领域。
# NVIDIA GPU 架构的演进
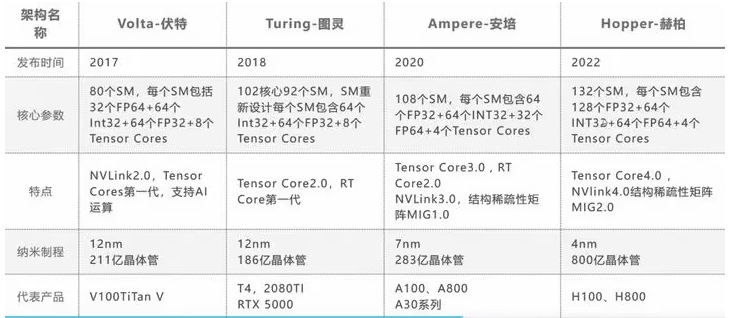
从上图中就可以看出,V100 是前一代的算力大哥 ,而 H100 则是新一代的大哥,这些架构区别:
Volta 架构:Volta 架构是 NVIDIA GPU 的第六代架构,发布于 2017 年。Volta 架构专注于深度学习和人工智能应用,并引入了 Tensor Core。
Turing 架构:Turing 架构是 NVIDIA GPU 的第七代架构,发布于 2018 年。Turing 架构引入了实时光线追踪(RTX)和深度学习超采样(DLSS)等重要功能。
Ampere 架构:Ampere 架构是 NVIDIA GPU 的第八代架构,2020 年发布。Ampere 架构在计算能力、能效和深度学习性能方面都有重大提升。Ampere 架构的 GPU 采用了多个 [流多处理器](SM)和更大的总线宽度,提供了更多的 CUDA Core 和更高的频率。它还引入了第三代 Tensor Core,提供更强大的深度学习计算性能。Ampere 架构的 GPU 还具有更高的内存容量和带宽,适用于大规模的数据处理和机器学习任务。
Hopper 架构:Hopper 架构是 NVIDIA GPU 的第九代架构,2022 年发布。相较于 Ampere,Hopper 架构支持第四代 Tensor Core,且采用新型流式处理器,每个 SM 能力更强。Hopper 架构在计算能力、深度学习加速和图形功能方面带来新的创新和改进。
NVIDIA 显卡从 Tesla 架构开始 (Tesla 架构是 Fermi 前一个架构),所有 GPU 都带有有 CUDA Core,但 Tensor Core 和 RT Core 却并非都具有。
在 Fermi 架构之前,GPU 的处理核心一直被叫做 Processor core (SPs),随着 GPU 中处理核心的增加,直到 2010 年 NVIDIA 的 Fermi 架构它被换了一个新的名字 CUDA Core。
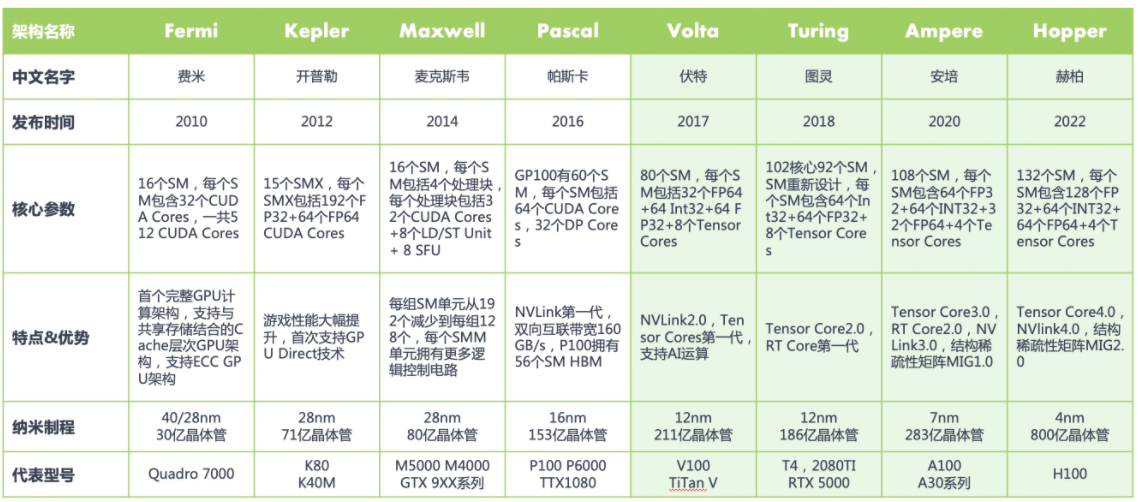
由于 CUDA core 在显卡里面是并行运算,也就是说大家分工计算。从逻辑上说,那么 CUDA core 越多,算力也就相应的会越强。所以说从 Fermi 架构开始,2012 年的 Kepler 架构和 2014 年的 Maxwell 架构,都在这个基础上疯狂加倍增加 Cuda Core。
到了 2016 年的 Pascal 架构,NVIDIA GPU 也开始往深度学习方向进行演进,NVLink 也是这个时候开始引入的。
到了 2017 年引入的 Volta 架构,引入了张量核 Tensor Core 模块,用于执行融合乘法加法,标志着第一代 Tensor Core 核心的诞生。
自从 Volta 架构搭载了首代 Tensor Core 以来,NVIDIA 在每一次的架构升级中都不断对 Tensor Core 进行优化和更新,每一轮的更新都带来了新的变化和提升。
# NVIDIA 的小玩意
# NVLink
在 GPU Direct P2P 技术中,多个 GPU 通过 PCle 直接与 CPU 相连,而 PCle 的双向带宽存在上限,当训练数据一直增长
时,PCle 的带宽显然满足不了训练需求。为进一步提升多 0GPU 之间的通信性能,充分发挥 GPU 的算力,NVIDIA 于
2016 年发布了全新架构的 NVLink。
NVLink 是服务器内部 GPU 之间点到点通讯的一种协议,主要目的的是为 GPU 互联提供一个高速点对点的网络。对比传
统网络不会有例如端到端报文重传、自适应路由、报文重组等开开销。极度简化的 NVLink 接口可以为 CUDA 提供从会话
层、表示层到应用层的加速,从而进一步减少因为通讯带来的网络开销
简单总结:同主机内不同 GPU 之间的一种高速互联方式,
- 是一种短距离通信链路,保证包的成功传输,更高性能,替代 PCIe,
- 支持多 lane,link 带宽随 lane 数量线性增长,
- 同一台 node 内的 GPU 通过 NVLink 以 full-mesh 方式(类似 spine-leaf)互联,
- NVIDIA 专利技术。
NVLink 演进:
主要区别是单条 NVLink 链路的 lane 数量、每个 lane 的带宽(图中给的都是双向带宽)等:
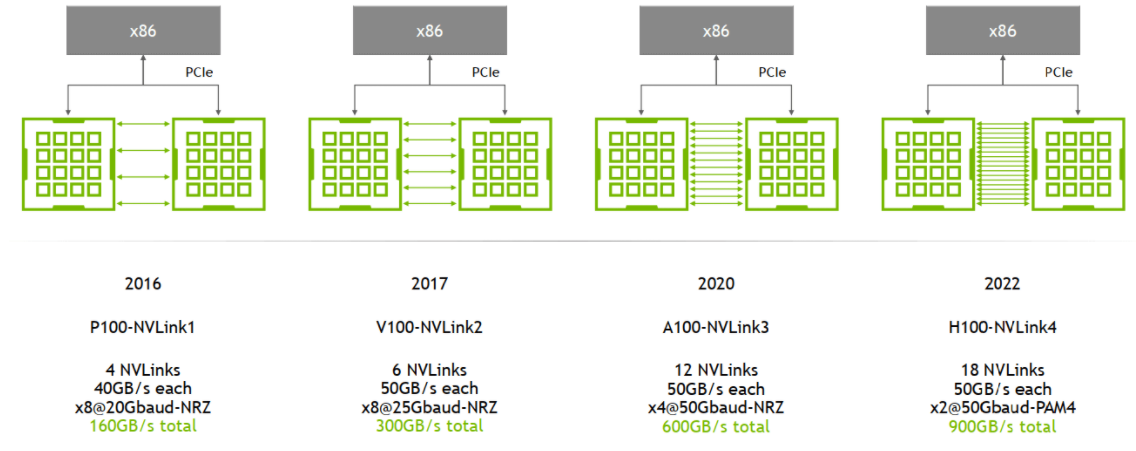
例如,
- A100 是
2 lanes/NVSwitch * 6 NVSwitch * 50GB/s/lane= 600GB/s双向带宽(单向 300GB/s)。注意:这是一个 GPU 到所有 NVSwitch 的总带宽; - A800 被阉割了 4 条 lane,所以是
8 lane * 50GB/s/lane = 400GB/s双向带宽(单向 200GB/s)。
# NVSwitch
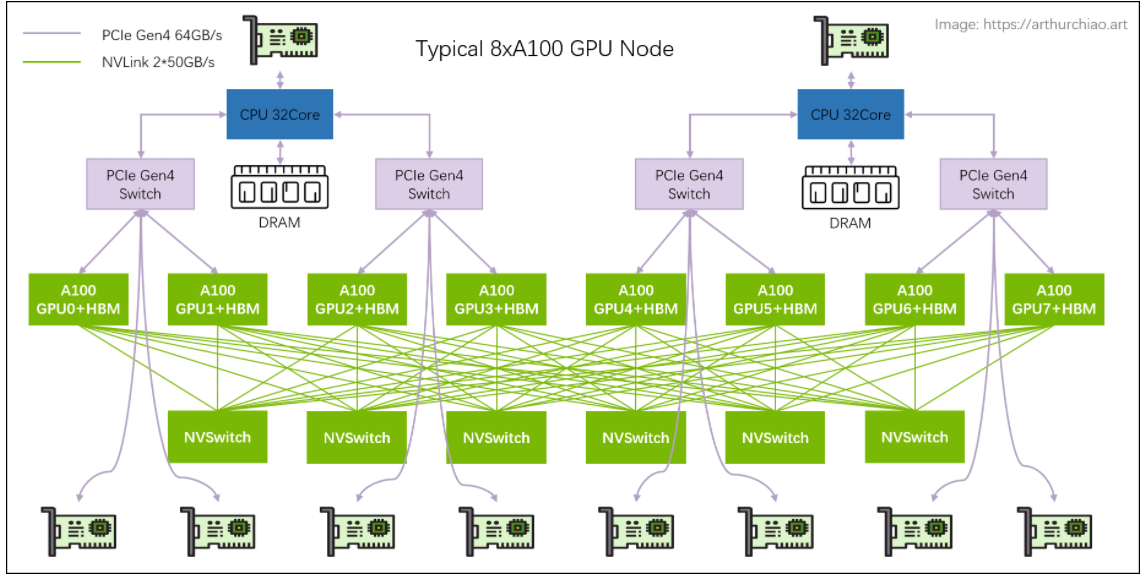
NVSwitch 是 NVIDIA 的一款交换芯片,封装在 GPU module 上,并不是主机外的独立交换机。
下面是真机图,浪潮的机器,图中 8 个盒子就是 8 片 A100,右边的 6 块超厚散热片下面就是 NVSwitch 芯片:


H100 的四个 nvswitch 的芯片
# NVLink Switch
NVSwitch 听名字像是交换机,但实际上是 GPU module 上的交换芯片,用来连接同一台主机内的 GPU。
2022 年,NVIDIA 把这块芯片拿出来真的做成了交换机,叫 NVLink Switch [3], 用来跨主机连接 GPU 设备。
# HBM (High Bandwidth Memory)
传统上,GPU 显存和普通内存(DDR)一样插在主板上,通过 PCIe 连接到处理器(CPU、GPU), 因此速度瓶颈在 PCIe,Gen4 是 64GB/s,Gen5 是 128GB/s。
因此,一些 GPU 厂商(不是只有 NVIDIA 一家这么做)将将多个 DDR 芯片堆叠之后与 GPU 芯片封装到一起 (后文讲到 H100 时有图),这样每片 GPU 和它自己的显存交互时,就不用再去 PCIe 交换芯片绕一圈,速度最高可以提升一个量级。 这种 “高带宽内存”(High Bandwidth Memory)缩写就是 HBM。
现在 CPU 也有用 HBM 的了,比如 Intel Xeon CPU Max Series 就自带了 64GB HBM2e。
| Bandwidth | Year | GPU | |
|---|---|---|---|
| HBM | 128GB/s/package | ||
| HBM2 | 256GB/s/package | 2016 | V100 |
| HBM2e | ~450GB/s | 2018 | A100, ~2TB/s; 华为 Ascend 910B |
| HBM3 | 600GB/s/site | 2020 | H100, 3.35TB/s |
| HBM3e | ~1TB/s | 2023 | H200, 4.8TB/s |
# RDMA
RDMA,即 Remote Direct Memory Access ,是一种绕过远程主机 OS kernel 访问其内存中数据的技术,概念源自于 DMA 技术。在 DMA 技术中,外部设备(PCIe 设备)能够绕过 CPU 直接访问 host memory ;而 RDMA 则是指外部设备能够绕过 CPU,不仅可以访问本地主机的内存,还能够访问另一台主机上的用户态内存。由于不经过操作系统,不仅节省了大量 CPU 资源,同样也提高了系统吞吐量、降低了系统的网络通信延迟,在高性能计算和深度学习训练中得到了广泛的应用。
随着软件定义数据中心、CPU 核心、PCIe、闪存等技术的发展,数据在计算和存储方面的瓶颈并没有太明显,而网络随着数据中心的发展逐渐成为了瓶颈,它直接影响到数据中心最大吞吐量和最小的延迟。
**TCP/IP 协议中的传输方式是以操作系统为中心来完成的。** 如下图所示,将一个应用服务器中的数据传输到另一个服务器中,数据在服务器的 Buffer 内多次拷贝,OS 在将消息发送给网络适配器并通过网络传输之前复制消息。同时在接收端,OS 再次处理数据。
这些操作既增加了数据传输时延,又消耗了大量的 CPU 资源,无法很好得满足高性能计算的需求。
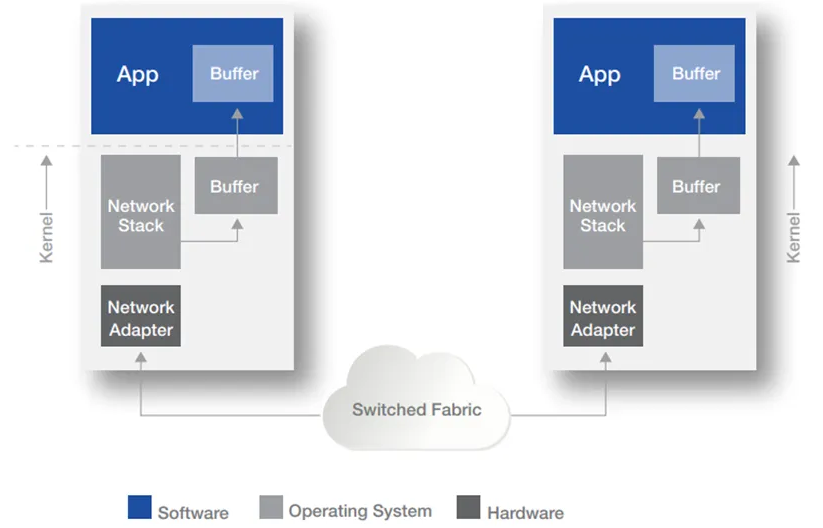
传统以太网卡通信过程:
1、首先,CPU 将数据从用户空间复制到内核空间,内核空间的网络协议栈给数据添加各协议的头部和校验信息;
2、发送端网卡通过 DMA 从主机内存中复制数据到硬件内部缓存中;
3、发送端网卡通过物理链路途径交换机将数据发送给对端的网卡;
4、接收端网卡接收到数据放到缓存中,并通过 DMA 拷贝到系统内存中;
5、CPU 对数据包进行逐层解析和校验,最后将数据复制到用户空间;
整个通信过程中,一共发生了 5 次数据拷贝,其中有 3 次是不可避免的 (按照现有计算机体系架构来说), 其中上图中
234 是不可避免的,而 1 和 5 都是属于系统内存内部中的拷贝。
使用 RDMA 后,RDMA 将服务器应用数据直接由内存传输到智能网卡(固化 RDMA 协议),由智能网卡硬件完成 RDMA 传输报文封装,解放了操作系统和 CPU。
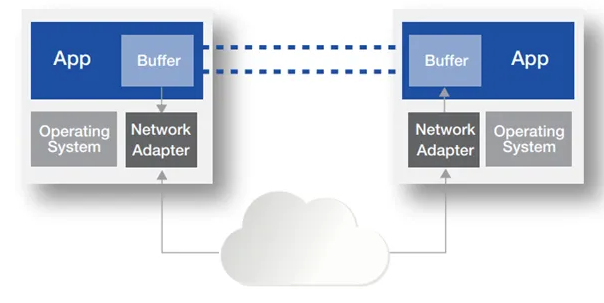
- 零拷贝 (Zero-copy) - 应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下。数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
- 内核旁路 (Kernel bypass) - 应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换。
- 不需要 CPU 干预 (No CPU involvement) - 应用程序可以访问远程主机内存而不消耗远程主机中的任何 CPU。远程主机内存能够被读取而不需要远程主机上的进程(或 CPU) 参与。远程主机的 CPU 的缓存 (cache) 不会被访问的内存内容所填充。
响应 RDMA 对硬件有更高的要求
1、发送端网卡通过 DMA 从用户空间内存复制数据到硬件内部缓存中,并给数据添加各协议层头部和校验信息;
2、发送端网卡通过物理链路途径交换机将数据发送给对端的网卡;
3、接收端网卡收到数据后,先把各协议头部和校验信息剥离,然后将硬件缓存中的数据通过 DMA 拷贝到用户空间。
目前 RDMA 有三种不同的技术实现方式:
InfiniBand(IB):IB 是一种高性能互连技术,它提供了原生的 RDMA 支持。IB 网络使用专用的 IB 适配器和交换机,通过 RDMA 操作实现节点之间的高速直接内存访问和数据传输。
RoCE(RDMA over Converged Ethernet):RoCE 是在以太网上实现 RDMA 的技术。它使用标准的以太网作为底层传输介质,并通过使用 RoCE 适配器和适当的协议栈来实现 RDMA 功能。
iWARP:iWARP 是基于 TCP/IP 协议栈的 RDMA 实现。它使用普通的以太网适配器和标准的网络交换机,并通过在 TCP/IP 协议栈中实现 RDMA 功能来提供高性能的远程内存访问和数据传输。
RDMA 架构与实践 (技术详解 (一):RDMA 概述)-CSDN 博客
RDMA
# 单机多卡 GPU 通信技术
# GPUDirect
GPUDirect 是 NVIDIA 开发的一项技术,可实现 GPU 与其他设备(例如网络接口卡 (NIC) 和存储设备)之间的直接通信和数据传输,而不涉及 CPU。
使用 GPUDirect,网络适配器和存储驱动器可以直接读写 GPU 内存,减少不必要的内存消耗,减少 CPU 开销并降低延迟,从而显著提高性能。
GPUDirect 技术已经逐渐完善,形成了包括 GPUDirect Storage、GPUDirect RDMA、GPUDirect P2P 和 GPUDirect Video 四组重要技术的组合。
1)GPUDirect Storage
对 AI 和 HPC 应用而言,随着数据规模的不断扩大,数据加载时间对系统性能影响越发显著。随着 GPU 计算速度的快速提升,系统 I/O(数据从存储读取到 GPU 显存)已经成为系统瓶颈。
GPUDirect Storage 提供本地存储(NVMe)/ 远程存储(NVMe over Fabric)与 GPU 显存的直接通路,它可以减少不必要的系统内存拷贝(通过 bounce buffer)。它可应用网卡 NIC 和存储系统附近的 DMA 引擎,直接向 GPU 显存写入 / 读取数据。
2)GPUDirect RDMA
RDMA (Remote direct memory access) 技术可使外围 PCIe 设备直接访问 GPU 显存。GPUDirect RDMA 被设计用来支持 GPU 间快速跨机通信。它能减轻 CPU 负载,同时也能减少不必要的通过系统内存进行的数据拷贝。
3)GPUDirect for Video
GPUDirect for Video 提供一个服务于 frame-based 的通过优化的流水线功能。设备包括:frame grabbers、video switchers、HD-SDI capture、CameraLink device,它可以把视频帧高效地向 GPU 显内中写入 / 读出。
4)GPUDirect P2P
GPUDirect P2P 支持 GPU 之间通过 memory fabric(PCIe 或 NVLink)直接进行数据拷贝。
# 多机之间 GPU 卡通信技术
GPUDirect RDMA
GPUDirect RDMA 结合了 GPU 加速计算和 RDMA(Remote Direct Memory Access)技术,实现了在 GPU 和 RDMA 网络设备之间直接进行数据传输和通信的能力。它允许 GPU 直接访问 RDMA 网络设备中的数据,无需通过主机内存或 CPU 的中介。
GPUDirect RDMA 通过绕过主机内存和 CPU,直接在 GPU 和 RDMA 网络设备之间进行数据传输,显著降低传输延迟,加快数据交换速度,并可以减轻 CPU 负载,释放 CPU 的计算能力。另外,GPUDirect RDMA 技术允许 GPU 直接访问 RDMA 网络设备中的数据,避免了数据在主机内存中的复制,提高了数据传输的带宽利用率
一文读懂 GPU 通信互联技术:到底什么是 GPUDirect、NVLink、RDMA?
聊透 GPU 通信技术 ——GPU Direct、NVLink、RDMA - 掘金
# NVIDIA GPU 详解
# A100/A800
主机内拓扑: 2-2-4-6-8-8
- 2 片 CPU(及两边的内存,NUMA)
- 2 张存储网卡(访问分布式存储,带内管理等)
- 4 个 PCIe Gen4 Switch 芯片
- 6 个 NVSwitch 芯片
- 8 个 GPU
- 8 个 GPU 专属网卡
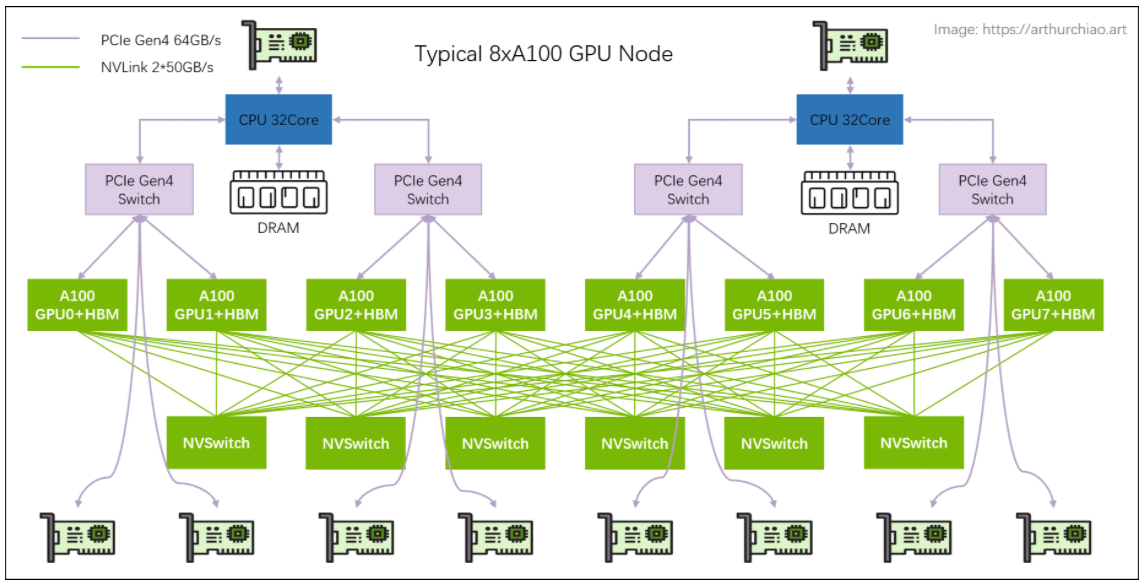
将所有部件画出来后,会更清晰些
# 存储网卡
通过 PCIe 直连 CPU。用途:
- 从分布式存储读写数据,例如读训练数据、写 checkpoint 等;
checkpoint"并不是指一个具体的文件或文件夹名,而是指在训练过程中保存的模型状态。具体来说,"Saving checkpoint at 8 epochs" 意味着在训练的第 8 个 epoch 结束时,程序自动保存了这个时刻模型的权重和状态。这样做是为了在后续的训练过程中,如果需要中断或重启训练,可以直接从这个 checkpoint 开始,而不必从头开始训练,这样可以大大节省时间和资源
- 正常的 node 管理,ssh,监控采集等等。
官方推荐用 BF3 DPU。但其实只要带宽达标,用什么都行。组网经济点的话用 RoCE,追求最好的性能用 IB。
# NVSwitch fabric:intra-node full-mesh
8 个 GPU 通过 6 个 NVSwitch 芯片 full-mesh 连接,这个 full-mesh 也叫 NVSwitch fabric ; full-mesh 里面的每根线的带宽是 n * bw-per-nvlink-lane,
- A100 用的 NVLink3,
50GB/s/lane,所以 full-mesh 里的每条线就是12*50GB/s=600GB/s,注意这个是双向带宽,单向只有 300GB/s。 - A800 是阉割版,12 lane 变成 8 lane,所以每条线 8*50GB/s=400GB/s,单向 200GB/s。
# smi topo
下面是一台 8*A800 机器上 nvidia-smi 显示的实际拓

- GPU 之间(左上角区域):都是
NV8,表示 8 条 NVLink 连接; - NIC 之间:
- 在同一片 CPU 上:
NODE,表示不需要跨 NUMA,但需要跨 PCIe 交换芯片; - 不在同一片 CPU 上:
SYS,表示需要跨 NUMA;
- 在同一片 CPU 上:
- GPU 和 NIC 之间:
- 在同一片 CPU 上,且在同一个 PCIe Switch 芯片下面:
PXB,表示只需要跨 PCIe 交换芯片; - 在同一片 CPU 上,且不在同一个 PCIe Switch 芯片下面:
NODE,表示需要跨 PCIe 交换芯片和 PCIe Host Bridge; - 不在同一片 CPU 上:
SYS,表示需要跨 NUMA、PCIe 交换芯片,距离最远;
- 在同一片 CPU 上,且在同一个 PCIe Switch 芯片下面:
# GPU 训练集群组网:IDC GPU fabirc
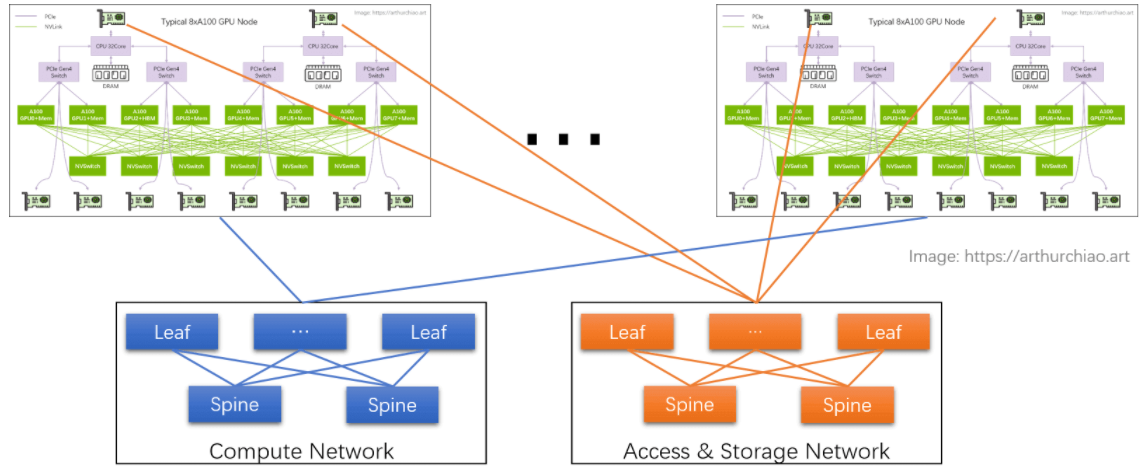
# 计算网络
GPU 网卡直连到置顶交换机(leaf),leaf 通过 full-mesh 连接到 spine,形成跨主机 GPU 计算网络。
- 这个网络的目的是 GPU 与其他 node 的 GPU 交换数据;
- 每个 GPU 和自己的网卡之间通过 PCIe 交换芯片连接:
GPU <--> PCIe Switch <--> NIC。
# 存储网络
直连 CPU 的两张网卡,连接到另一张网络里,主要作用是读写数据,以及 SSH 管理等等。
# 单机 8 卡 A100 GPU 主机带宽瓶颈分析
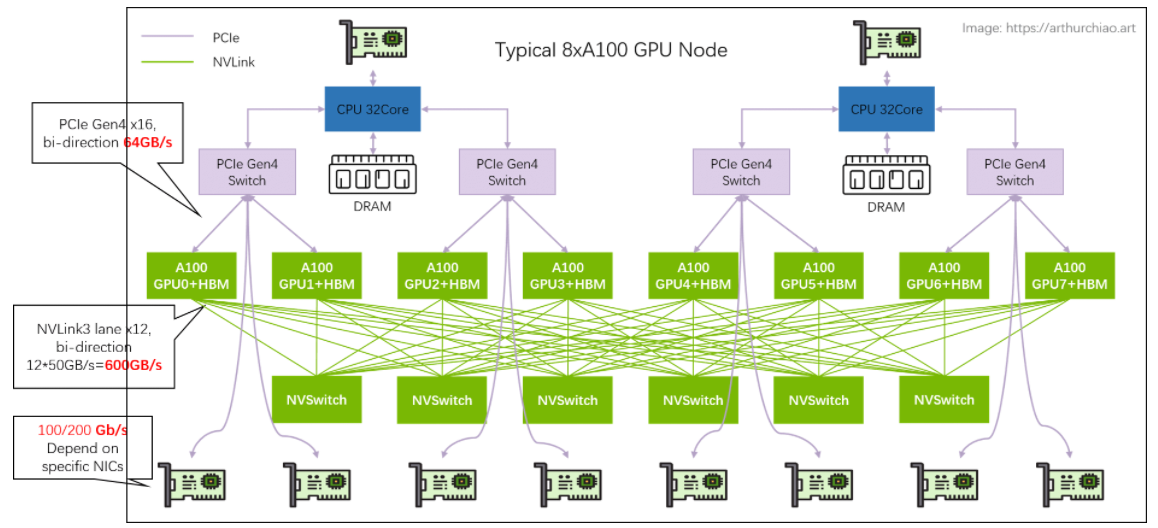
几个关键链路带宽都标在图上了,
- 同主机 GPU 之间:走 NVLink,双向 600GB/s,单向
300GB/s;- 同主机 GPU 和自己的网卡之间:走 PICe Gen4 Switch 芯片,双向 64GB/s,单向
32GB/s;- 跨主机 GPU 之间:需要通过网卡收发数据,这个就看网卡带宽了,目前国内 A100/A800 机型配套的主流带宽是(单向)
100Gbps=12.5GB/s。 所以跨机通信相比主机内通信性能要下降很多。
200Gbps==25GB/s:已经接近 PCIe Gen4 的单向带宽;400Gbps==50GB/s:已经超过 PCIe Gen4 的单向带宽。- 所以在这种机型里用 400Gbps 网卡作用不大,400Gbps 需要 PCIe Gen5 性能才能发挥出来。
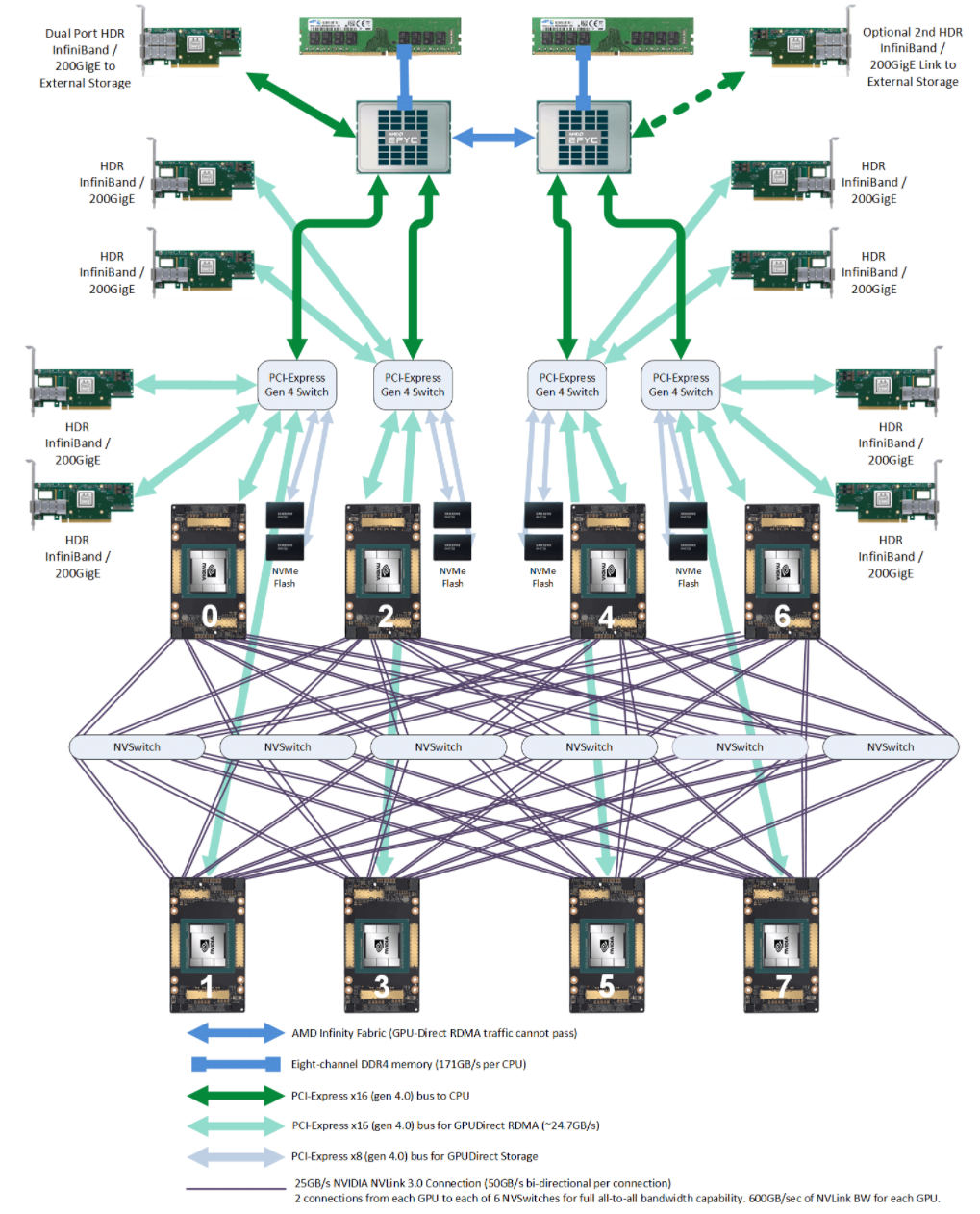
# H100/H800
# H100 芯片
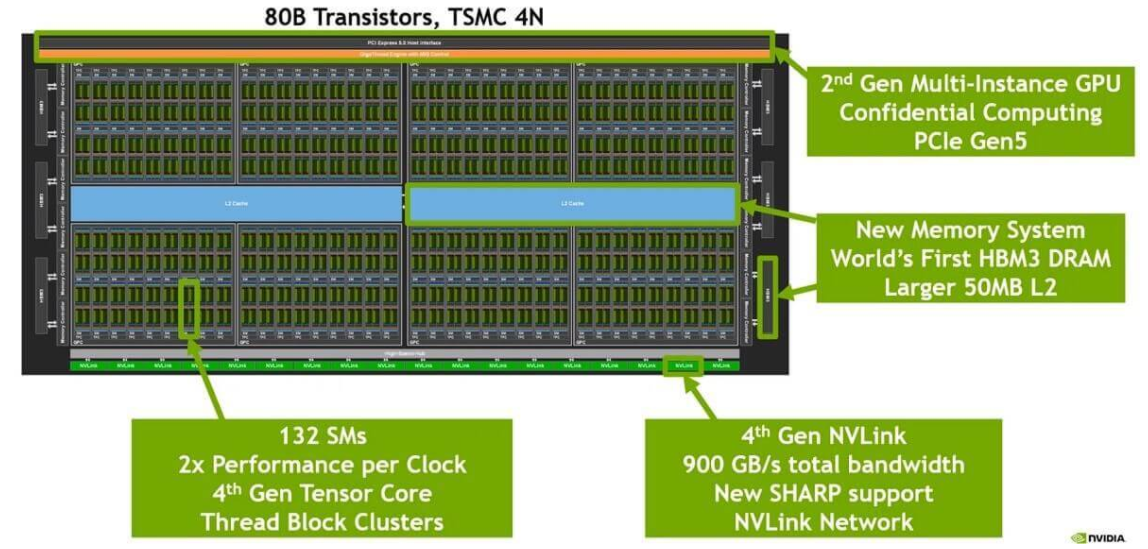
4nm工艺;- 最下面一排是 18 根 Gen4 NVLink;双向总带宽
18 lanes * 50GB/s/lane = 900GB/s; - 中间蓝色的是 L2 cache;
- 左右两侧是
HBM芯片,即显存;
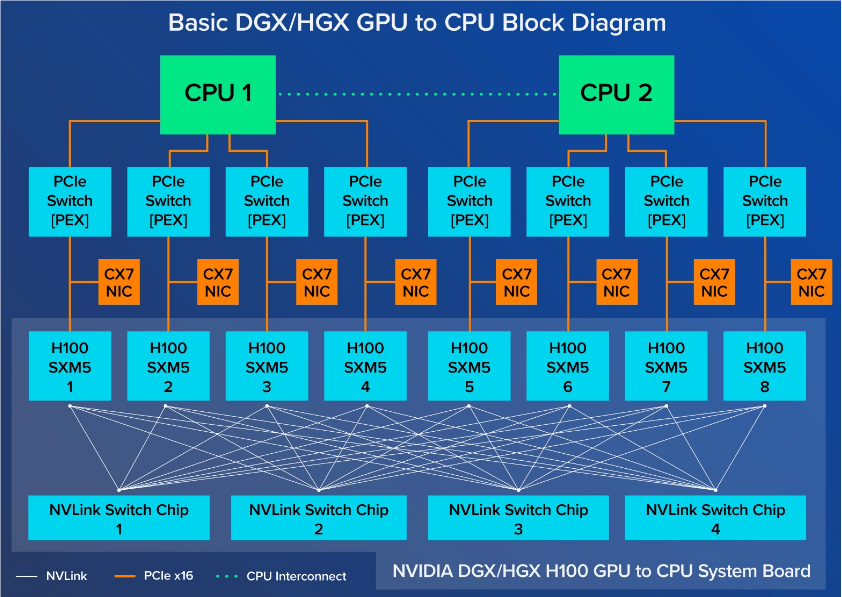
# 主机内硬件拓扑
跟 A100 8 卡机结构大致类似,区别:
- NVSwitch 芯片从 6 个减少到了 4 个

与 CPU 的互联从 PCIe Gen4 x16 升级到 PCIe Gen5 x16 ,双向带宽 128GB/s ;
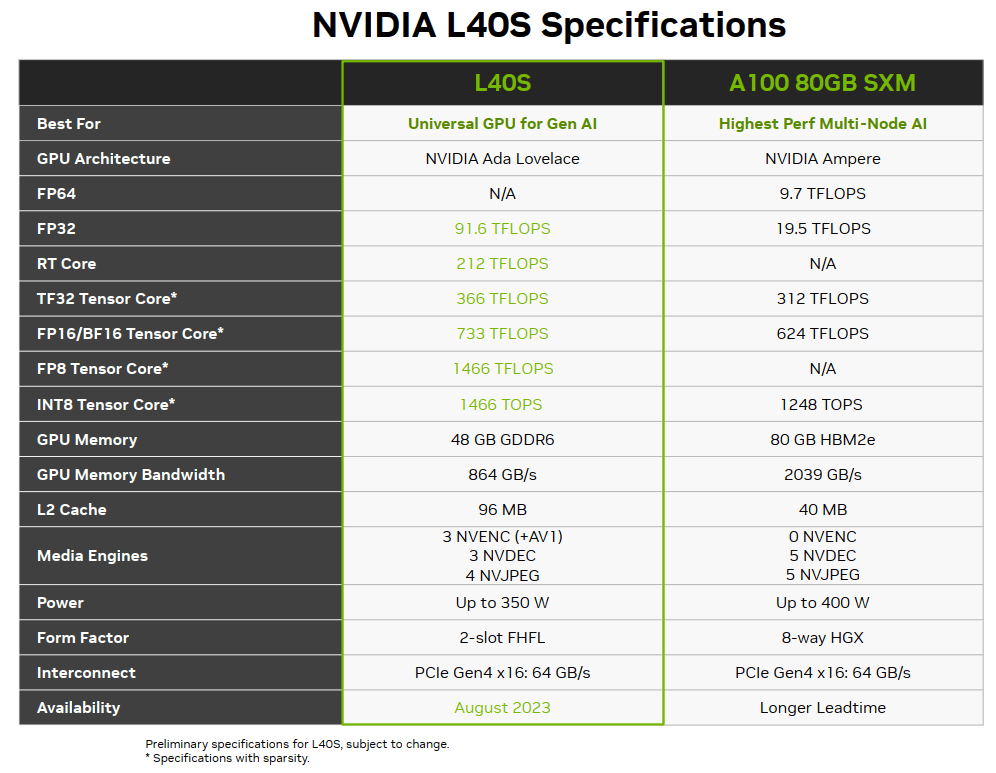
# L40S
对标 A100
# 架构
# 2-2-4
相比于 A100 的 2-2-4-6-8-8 架构, 官方推荐的 L40S GPU 主机是 2-2-4 架构,一台机器物理拓扑如下
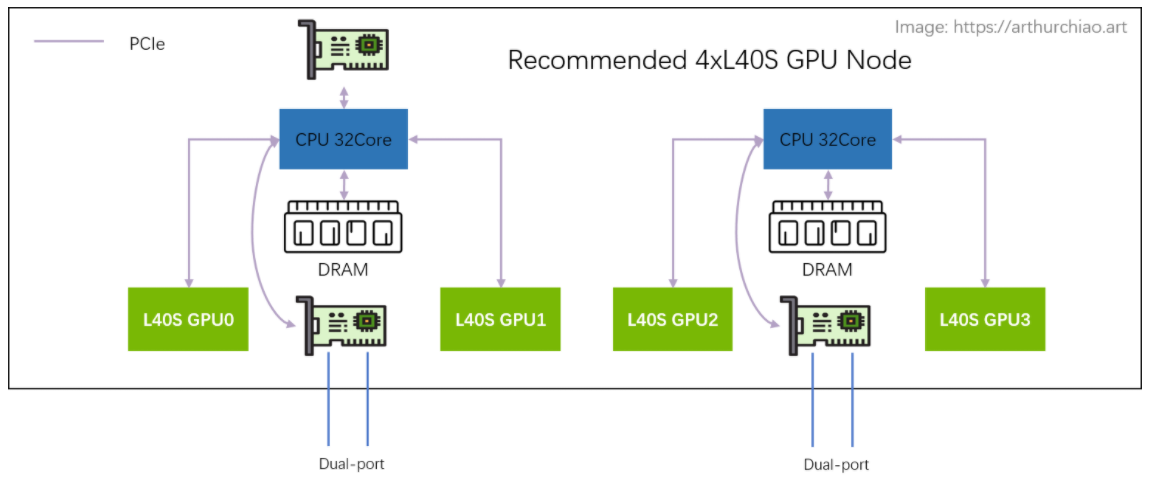
最明显的变化是去掉了 CPU 和 GPU 之间的 PCIe Switch 芯片, 网卡和 GPU 都是直连 CPU 上自带的 PCIe Gen4 x16(64GB/s),
- 2 片 CPU(NUMA)
- 2 张双口 CX7 网卡(每张网卡
2*200Gbps) - 4 片 L40S GPU
- 另外,存储网卡只配 1 张(双口),直连在任意一片 CPU 上
# 2-2-8
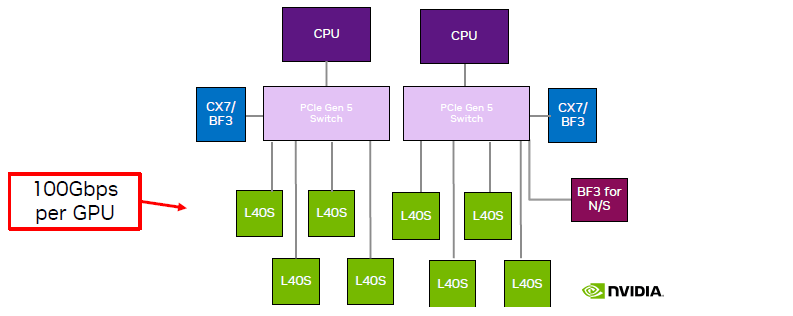
跟单机 4 卡相比,单机 8 卡需要引入两片 PCIe Gen5 Switch 芯片:
- 价格不划算;
- PCIe switch 只有一家在生产,产能受限,周期很长;
- 平摊到每片 GPU 的网络带宽减半;
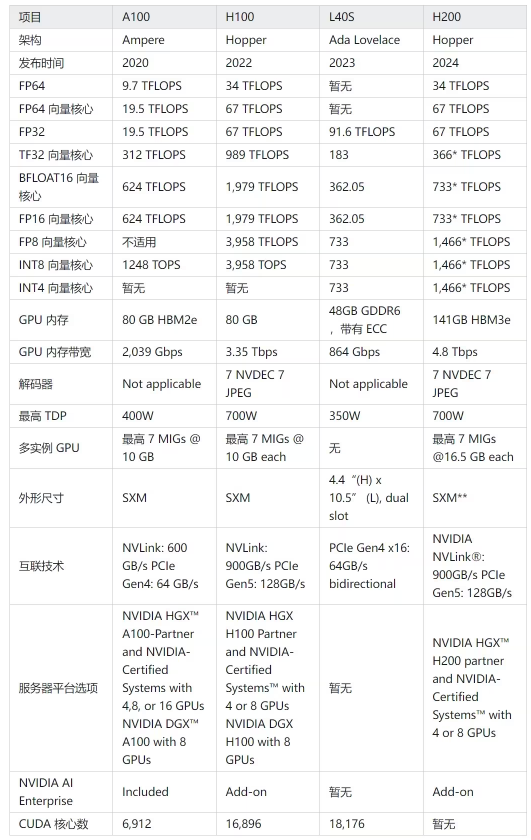
# V100,A100,H100,A800,L40S 对比
# 火山 GPU 云服务器概览
以下都是火山云服务器官方文档内容,有实效性~
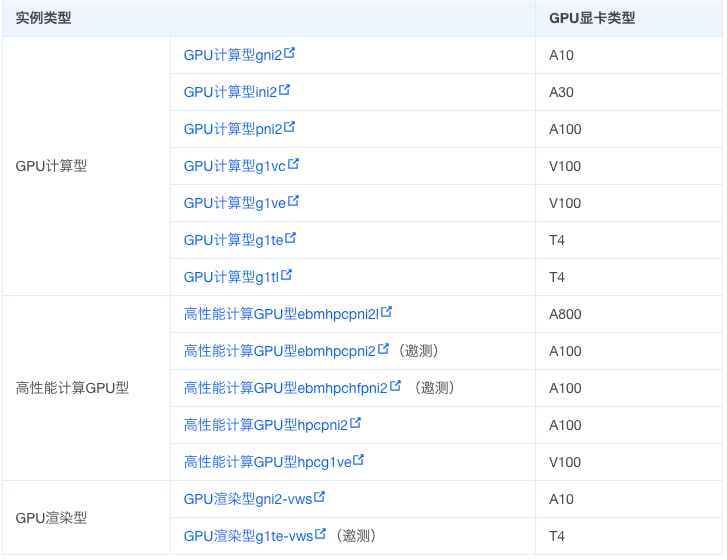
模型训练场景 V100、A100、A30 等类型的 GPU 显卡适用于 AI 模型训练场景,提供了大显存和高速访问能力,并叠加 NVLink 多卡互连,为多卡并行提供了超强计算能力。
应用推理场景 T4、A10 等类型的 GPU 显卡为 AI 推理提供了高效能比的加速能力,广泛应用于图像识别、语言翻译场景。
# 实例规格
# GPU 计算
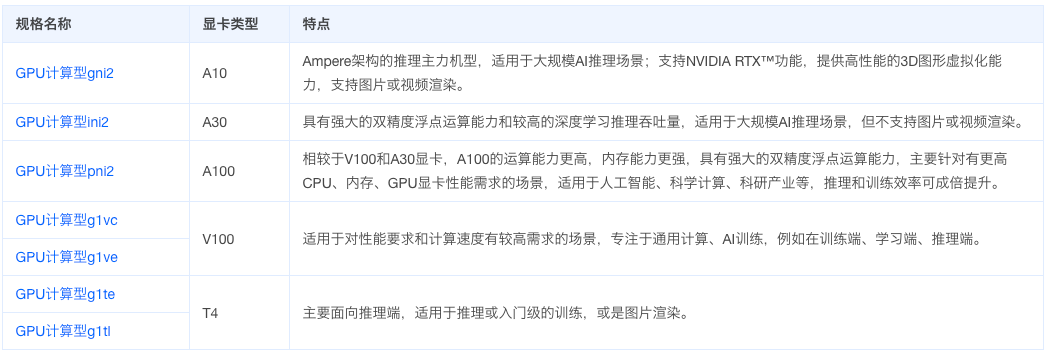
GPU 计算型实例基于多种 NVIDIA Tesla 显卡,在各类推理场景及分子计算场景下提供高性价比。适用于深度学习及 AI 推理训练,如图像处理、语音识别等人工智能算法的训练应用。
# 高性能计算
高性能计算 GPU 型规格在原有 GPU 型规格的基础上,加入 RDMA 网络,可大幅提升网络性能,提高大规模集群加速比,适用于高性能计算、人工智能、机器学习等业务场景。
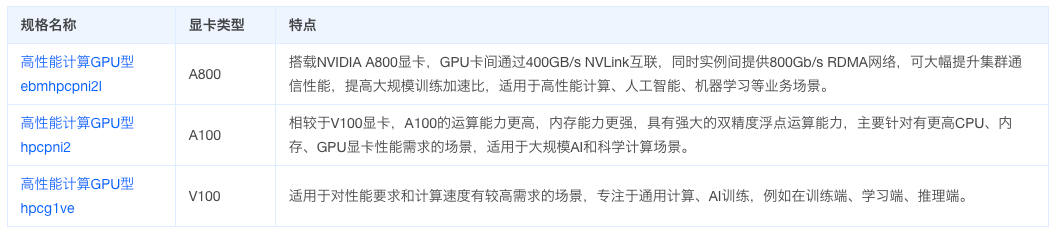
# GPU 渲染
GPU 渲染型实例安装了 NVIDIA GRID 驱动并配置了 License 服务器,适用于图形图像处理(3D 渲染,视频编码 / 解码),使用该实例,您可以免除手动配置 GPU 图形图像处理基础环境。
# NVIDIA 驱动安装
# CUDA,cuDNN,fabric-manager
英伟达官方对于 CUDA (Compute Unified Device Architecture) 的定义是:通用的并行计算平台 和 编程模型。这里的 “通用” 主要指的是可以适配 英伟达的各种产品。当然,现在也有其它厂商做显卡,并尝试适配 CUDA。
在我们给电脑接入 GPU 这个外接设备后,首先要做的事情就是安装 显卡驱动。只有安装上驱动后,才能保证程序的运行。在安装上驱动后,我们就可以使用
nvidia-smi指令查看显卡的运行状况了。还可以通过nvidia-smi -q查看显卡的基本信息。如果你是普通的玩家用户,安装完成 显卡驱动 就可以了。但是,如果你是开发者,那么就需要安装 CUDA Toolkit, 其内部包含了 nvcc 编译器和 Nvidia Nsight 工具集。在 Nvidia Nsight 中,包含有 CUDA 开发的 IDE, 程序性能分析工具等等。
如果你需要训练或者部署 深度学习 相关的模型,还需要安装 cuDNN, 它仅仅是一个库,和 cuBLAS, cuFFT 是同等级别的。英伟达完全可以将 cuDNN 放在 CUDA Toolkit 中,但是他可能为了强迫 深度学习 研究者买他们的专业卡,故意这么做的。不仅如此,下载 cuDNN 需要登陆账号,而下载 CUDA Toolkit 则不需要登陆账号。同时,安装 cuDNN 的过程就是将几个文件复制到 CUDA Toolkit 文件夹下,不需要干什么额外的事情。
需要注意的是,我们通常所说的安装 CUDA, 就是安装 CUDA Toolkit。不过,现在很多东西都简化了。目前,在最新的 PyTorch 安装包中,会自动包含 CUDA 相关的库文件,不需要自己单独安装了。只需要安装 显卡驱动 即可。
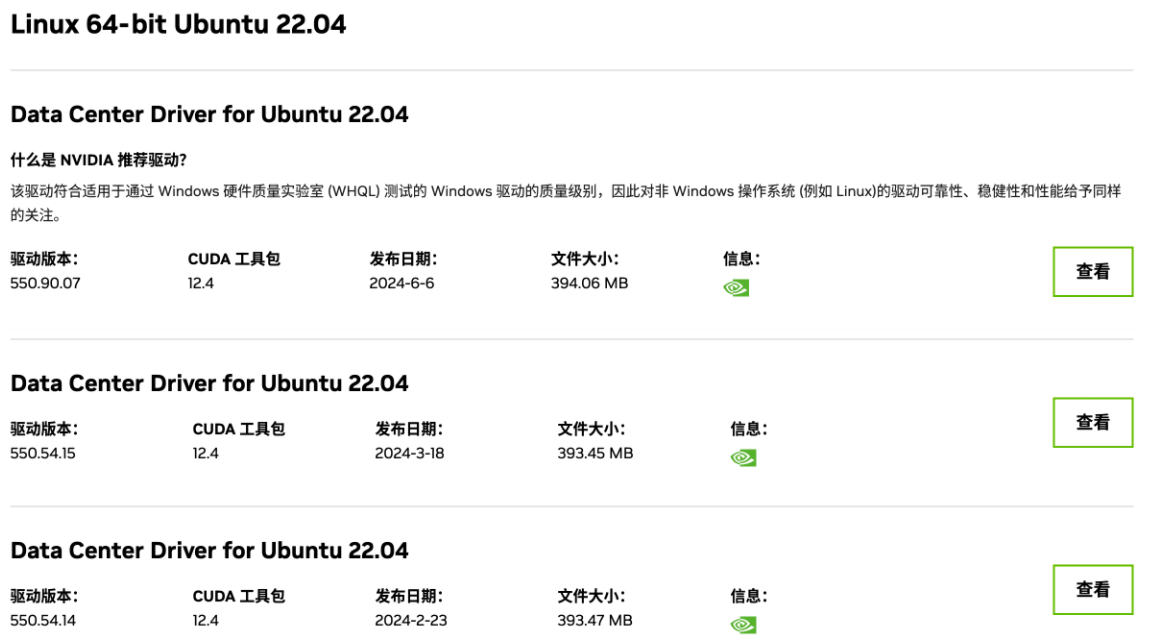
使用 nvidia-smi 命令可以看到一个 CUDA 的版本号,但这个版本号是 CUDA driver libcuda.so 的版本号,不是 CUDA Toolkit 的版本号。
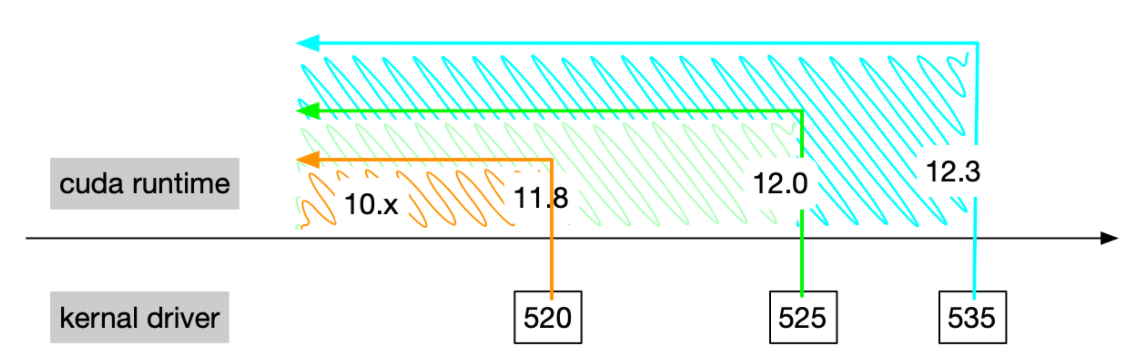
如上图 CUDA driver 是向后兼容的,即支持之前的 CUDA Toolkit 版本。
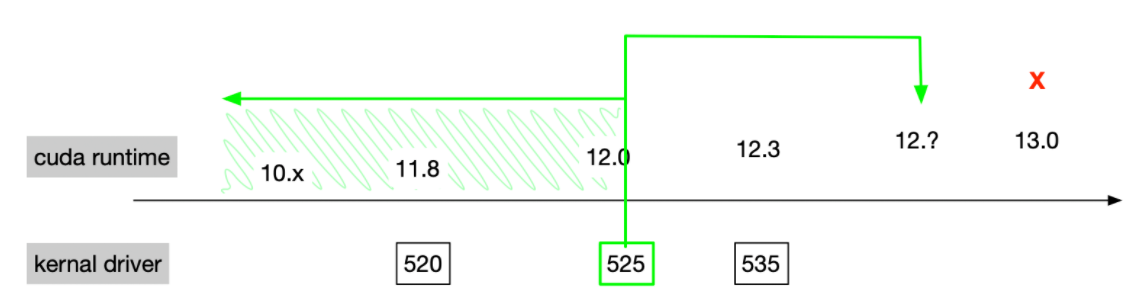
如上图,CUDA driver 支持向前的次要版本兼容,即大版本号相同就支持。
安装 fabric manager
如果装配了 NVLink 或者 NVSwitch ,还需要安装 nvidia-fabricmanager,否则无法正常工作。
FM 职责
- 配置 NVSwitch 端口之间的路由。
- 与 GPU 驱动程序配合初始化 GPU。
- 监控结构中的 NVLink 和 NVSwitch 错误。
# NVIDIA 驱动类型
NVIDIA 驱动程序是用来驱动 NVIDIA GPU 卡的程序,是硬件所对应的软件,用于提升操作系统对其芯片组的兼容性。当前火山引擎提供的 GPU 实例均为计算型,即 GPU 卡直通型,实例必须安装 GPU 驱动来驱动物理 GPU 卡,以获得 GPU 卡的能力。
GPU 实例当前支持安装以下两种 NVIDIA 驱动
| 驱动类型 | 驱动介绍 | 收费情况 |
|---|---|---|
| Tesla 驱动 | 用于驱动物理 GPU 卡,即调用 GPU 云服务器上的 GPU 卡获得通用计算能力,适用于深度学习、推理、AI 等场景。 您可以配合 CUDA、cuDNN 库更高效的使用 GPU 卡。 | 免费 |
| GRID 驱动 | 用于获得 GPU 卡的图形加速能力,适用于 OpenGL 等图形计算的场景。 | 需购买 NVIDIA GRID License |
# 多机多卡 nccl test
- OpenMPI
OpenMPI 是一个开源的 Message Passing Interface 实现,是一种高性能消息传递库,能够结合整个高性能计算社区的专业知识、技术和资源,建立现有的最佳 MPI 库。OpenMPI 在系统和软件供应商、应用开发者和计算机科学研究人员中有广泛应用。
- NCCL
NCCL(Nvidia Collective multi-GPU Communication Library,读作 “Nickel”)是一个提供 GPU 间通信基元的库,它具有拓扑感知能力,可以轻松集成到应用程序中。NCCL 做了很多优化,以在 PCIe、Nvlink、InfiniBand 上实现较高的通信速度。NCCL 支持安装在单个节点或多个节点上的大量 GPU 卡上,并可用于单进程或多进程(如 MPI)应用。
- NCCL Tests
NCCL Tests 是一个测试工具集,可以用来评估 NCCL 的运行性能和正确性。
- OFED
MLNX OFED(OpenFabrics Enterprise Distribution)是一组开源软件驱动、核心内核代码、中间件和支持 InfiniBand Fabric 的用户级接口程序,用于监视 InfiniBand 网络的运行情况,包括监视传输带宽和监视 Fabric 内部的拥塞情况。
nccl-test 使用指引
【教程】简介 nccl-test 工具 - CSDN 博客
如何理解 Nvidia 英伟达的 Multi-GPU 多卡通信框架 NCCL?
多机多卡运行 nccl-tests 对比分析
# Hands-on lab
https://zhuanlan.zhihu.com/p/692965752
https://openatomworkshop.csdn.net/664701d4b12a9d168eb6e4d1.html
https://arthurchiao.art/blog/gpu-advanced-notes-1-zh/#11-pcie - 交换芯片
https://blog.csdn.net/weixin_54106682/article/details/137375779
https://www.bilibili.com/read/cv30753871/
https://blog.csdn.net/xiaoxiaowenqiang/article/details/138278795
https://zhuanlan.zhihu.com/p/394352476
cuda:
https://zhuanlan.zhihu.com/p/686772546
https://scc.ustc.edu.cn/zlsc/user_doc/html/latex.html
https://zhuanlan.zhihu.com/p/680262016
https://blog.csdn.net/ygq13572549874/article/details/138469445